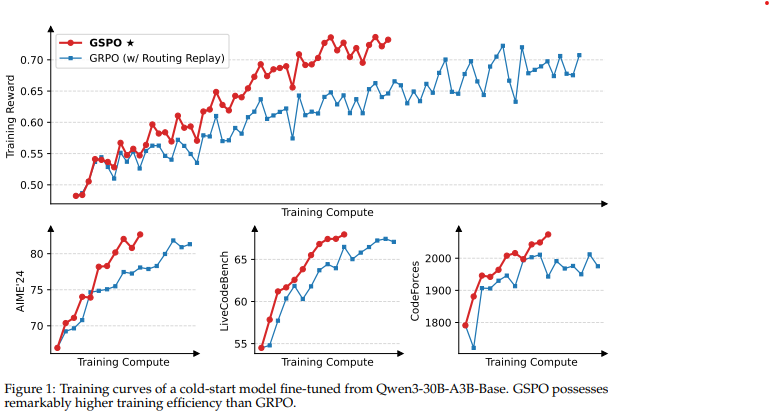
Group Sequence Policy Optimization by Qwen
배경지식
강화학습 관련 기본개념
- Reinforcement Learning (강화학습)
- 경시대회 수학, 프로그래밍 등 복잡한 문제들을 해결하는 역량을 언어모델에게 부여하는 학습 단계
- 더 깊고 긴 추론(reasoning) 역량을 부여
- Reward (보상)
- 에이전트가 환경과 상호작용하며 특정 행동을 했을 때, 환경으로부터 즉각적으로 받는 피드백
- 에이전트가 궁극적으로 최대화하고자 하는 목표
- e.g. +1이면 긍정적 보상, -1이면 부정적 보상
- Advantage (이점)
- 보상을 넘어, 특정 행동이 얼마나 좋은지를 상대적으로 평가하는 척도
- 어떤 상태에서 특정 행동을 선택했을 때 얻는 보상이, 그 상태에서 평균적으로 기대되는 가치보다 얼마나 더 좋은지를 알려줌
- e.g. 어떤 행동을 취했을 때 즉각적인 보상이 +100이나, 다른 행동을 하더라도 평균 +90의 보상을 기대할 수 있다면 이 행동의 이점은 +10
- Importance Sampling Weight (중요도 샘플링 가중치)
- Off-policy 학습에서, 데이터의 편향을 보정하기 위해 사용되는 가중치
- 데이터를 수집할 때 사용한 정책(=모델)과 현재 학습하고 있는 정책(=모델) 간의 확률적 차이를 보정
- e.g. 과거 수집한 데이터에서 특정 행동을 선택할 확률이 낮았지만, 새로운 정책이 그 행동을 매우 중요하게 생각한다면 중요도 샘플링 가중치는 매우 큰 값이 됨
- Importance ratio (중요도 비율) 이라고 일컬어지기도 함
- Off-policy (오프 정책)
- 오프 정책이란, 응답이 최적화되고 있는 현재의 정책이 아니라 예전의 정책으로부터 샘플링되어 사용되는 방식을 의미
- 모델의 크기, Sparsity (e.g. MoE), 응답 길이가 커짐에 따라 거대한 롤아웃 배치 데이터가 필요로 해짐
- 롤아웃이란, 에이전트가 특정 정책을 따라 환경에서 한 번 상호작용하는 과정을 의미. 롤아웃을 통해 에이전트는 상태(state), 행동(action), 보상(reward), 다음 상태(state)로 구성된 경험을 얻음
- 샘플 효율성을 위해, 큰 배치 데이터를 여러 개의 미니 배치로 구성하는 게 일반화되었고, 이는 off-policy 학습이 등장하는 배경이 됨
- Clipping
- Off-policy 학습이 널리 사용됨에 따라, 이전 정책으로부터 너무 멀리 떨어지지 않도록 업데이트 폭을 제한하는 메커니즘
강화학습 알고리즘
PPO (Proximal Policy Optimization)
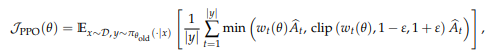
- Clipping mechanism을 통해 예전 정책의 근접 영역(proximal region) 내로 정책(=모델)이 업데이트되도록 하는 알고리즘
- 토큰에 대한 중요도 비율(Importance ratio)은 아래와 같이 정의됨
- 이점(Advantage)은 별도의 가치 모델로 측정됨
- 별도의 가치 모델이 필요하다는 점이 PPO의 가장 큰 어려움 중 하나
- 정책 모델과 유사한 크기이기 때문에 메모리와 연산 비용 커짐
- 알고리즘의 효과성이 가치 측정에 크게 의존적
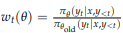
GRPO (Group Relative Policy Optimization)
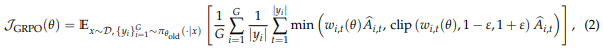
- 별도의 가치 모델이 필요없는 알고리즘
- 동일한 쿼리에 대해 여러 개의 응답을 생성하고, 각 응답의 상대적 이점을 계산해 가치 모델을 대신함
- 토큰에 대한 중요도 비율(Importance ratio), 이점(Advantage)은 아래와 같이 계산
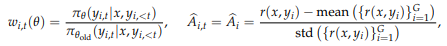
문제점
- GRPO로 거대한 언어 모델을 학습할 때, 복구 불가능할 정도로 모델이 붕괴되는 (=model collapse) 현상이 발생
- 이는 GRPO가 중요도 샘플링 가중치를 "토큰" 단위로 적용하기 때문
- 최적화 함수의 단위가 보상의 단위와 일치해야 하나, 시퀀스 단위로 주어지는 보상과 다르게 토큰 단위로 보상이 주어지기 때문에 문제가 발생
- the unit of optimization objective should match the unit of reward
해결책
GSPO (Group Sequence POlicy Optimization)
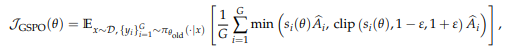
- sequence likelihood 기반의 중요도 비율 사용
- 시퀀스 길이에 대한 정규화 또한 적용함
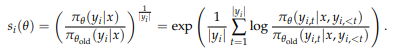
장점 1. 학습 안정성, 효율성, 성능 향상
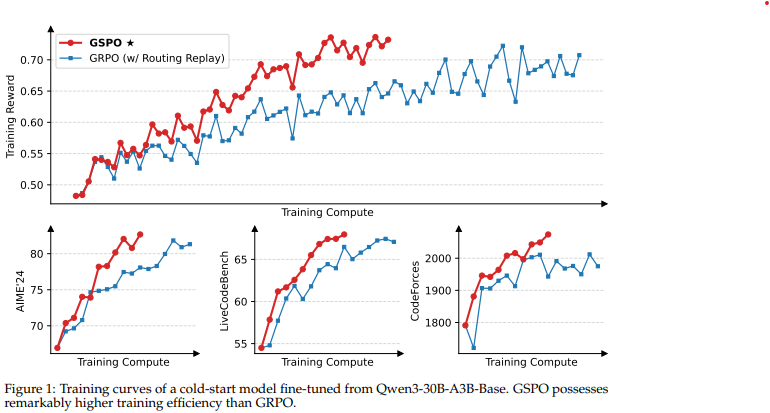
- GRPO에서는 토큰이 각각의 중요도 비율에 따라 가중치가 적용되는 데에 반해, GSPO는 응답의 모든 토큰에 대해 동일한 가중치를 부여
- the fundamental distinction between GSPO and GRPO lies in how they weight the gradients of
the log likelihoods of tokens
- the fundamental distinction between GSPO and GRPO lies in how they weight the gradients of
- 이를 통해 학습이 안정적으로 진행되고, 성능 또한 좋았다고 밝힘
장점 2. MoE 학습에 유용
- MoE (Mixture-of-Experts) 모델에서, expert-activation volatility는 모델 강화학습에서 수렴(convergence)을 어렵게 하는 요인
- 이는 gradient update 이후에 동일한 응답에 대해 활성화되는 전문가들이 크게 변경될 수 있음을 의미
- 이를 해결하기 위해, 이전에는 Routing Replay 도입
- 이전 정책에서 활성화되는 전문가를 캐싱하고, 중요도 비율을 계산할 때 이러한 라우팅 모드를 재사용(replay)
- 이를 통해 각 토큰에 대해 이전 정책과 현재 정책이 동일한 활성화된 네트워크를 공유하도록 함
- GSPO를 사용한다면 Routing Replay를 사용할 필요가 없음
장점 3. RL 인프라 단순화 가능
- 이전에는 학습 엔진(e.g. 메가트론)과 추론 엔진(e.g. SGLang, vLLM)의 precision discrepancy로 인해 학습 엔진으로 하여금 예전 정책에서 샘플링된 응답의 확률(likelihood)을 다시 계산하도록 해야 했음
- GSPO는 시퀀스 단위로 작동하기 때문에 precision discrepancy에 더욱 강건해, 추론 엔진이 리턴하는 확률(likelihood)을 직접 사용 가능
- 학습 엔진의 재연산 필요 없어짐

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab
감사합니다 잘 읽었습니다.