Generate rather than Retrieve: Large Language Models are Strong Context Generators
ICLR 2023
분야 및 배경지식
- retrieval (검색; 회수)
- 일반적으로 지식을 많이 필요로 하는 태스크(e.g. open-domain QA) 등에 사용되는 방식
- 질문에 답을 할 수 있는 관련있는 문서들을 위키피디아 등으로부터 검색하여 가져온 후(retrieval) 이를 활용해 언어모델이 답을 하도록 함
- 일반적으로 검색 모델(e.g. BM25, ORQA, DPR)과 언어 모델이 분리되어 있음
문제점
- 도메인이나 세상에 대한 지식이 필요한 태스크에서 일반적으로 많이 사용하는 retrieve-then-read(검색 후 읽기) 방식은 한계 존재
- 검색하여 얻은 후보 문서들은 뭉치로 고정되어 있으며, 연관없는 정보(noisy information)을 포함할 수 있음
- 질문과 문서의 표현(representation)이 독립적으로 얻어져 둘 사이의 상호관계가 긴밀하지 않을 수 있음
- 거대한 코퍼스로부터 문서를 검색하는 모델은 각 문서의 표현(representation)을 저장하고 있어야 함
해결책
GenRead (Generate-then-Read)
- 생성(Generate)
- 검색(Retrieval) 모델을 사용하지 않음
- 대신 거대한 언어모델(large language model; LLM)로 하여금 주어진 질문과 관련있는(contextual) 문서를 생성하도록 함
- 거대한 언어모델에 파라미터 내에 충분한 양의 지식을 학습하였다는 점을 이용
- 읽기(Read)
- 해당 문서들을 언어모델에 인풋으로 제공해줌으로써 질문에 대한 답을 생성하도록 함
클러스터링 기반 프롬프팅

- 생성한 문서의 다양성을 위해 클러스터링 기반 프롬프팅을 도입
- 질문 당 하나의 문서를 생성
- 언어모델을 활용할 경우 하나의 문서를 생성, 검색 모델(Retriever)을 활용할 경우 위키피디아 등에서 문서를 가져오도록 함
- 질문-문서의 쌍(pair) 생성
- 각 문서를 인코딩한 후 k-means 클러스터링 실시
- 언어모델을 활용해 질문-문서 쌍을 인코딩
- K-means를 활용하여 임베딩 벡터를 군집화, K개의 군집 생성
- K개 문서 샘플링 및 생성
- 각 군집(클러스터)에서 n개의 질문-문서 쌍을 샘플링
- 해당 질문-문서 쌍들을 연결하여 하나의 문서를 생성하도록 함
- 최종적으로 K개의 다양한 문서 생성
평가
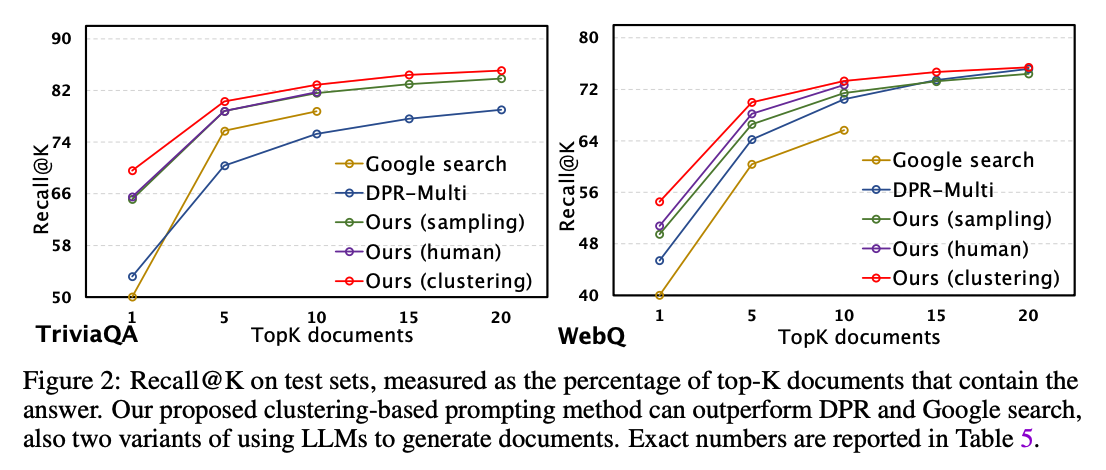
- 태스크
- open-domain QA (오픈 도메인 질의응답)
- 데이터셋: NQ, TriviaQA, WebQ
- 평가기준: EM (exact match), Recall@K
- fact checking (사실 확인)
- 데이터셋: FEVER, FM2
- 평가기준: 정확성
- open-domain dialogue (오픈 도메인 대화)
- 데이터셋: WoW
- 평가기준: F1 / Rouge-L
- open-domain QA (오픈 도메인 질의응답)
- 모델
- InstructGPT
- 실험
- zero-shot setting
- 프롬프트와 질문만 주어졌을 때 대비 뛰어난 성능 향상
- v.s. GPT-3, Gopher, FLAN, GLaM, Chinchilla, PaLM, InstructGPT
- 프롬프트, 관련 문서, 질문이 주어졌을 때 대비 비슷하거나 더 좋은 성능
- v.s. BM25/Contriever, Google, DPR + InstructGPT
- 프롬프트와 질문만 주어졌을 때 대비 뛰어난 성능 향상
- supervised setting
- 10개 이하의 문서일 경우 DPR, Google Search와 비교했을 때 뛰어난 성능 향상 (QA)
- 사실 확인 태스크의 경우 유사한 성능, 대화 태스크의 경우 더 뛰어난 성능
- v.s. DPR, RAG, FiD
- 생성한 문서와 검색한 문서를 함께 사용했을 경우 성능이 훨씬 좋아짐
- zero-shot setting
한계
- 문서의 수가 증가함에 따라 성능 곡선이 완만해짐
- 여러 개의 문서를 생성함에 따라 토큰 분포의 유사도가 높아지거나 (generate)
- 혹은 검색으로 얻은 문서들이 주어진 질문에 관련도가 높지 않아서임 (retrieval)
- 지식을 업데이트하거나 새로운 도메인에 적용할 수 없음
- 언어모델이 학습한 지식에 의존하는 방식이기 때문에, 새로운 지식에는 적용 불가한 방법
의의
- 기존에 많이 사용되던 retrieval 방식을 넘어서 지식이 필요한 태스크에 거대한 언어모델을 효과적으로 사용할 수 있는 방법을 제시

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab