Language Models as Knowledge Bases?
EMNLP 2019
분야 및 배경지식
Knowledge Base, Language Model
- Unidirectional Language Model: 주어진 일련의 단어들을 기반으로 다음 단어를 예측하는 모델. fairseq-fconv, Transformer-XL 등
- Bidirectional Language Model: 오직 이전 단어들뿐만이 아니라, 문장 혹은 문단의 전체적인 문맥을 바탕으로 단어를 예측하는 모델. BERT, ELMo 등
문제점
- 기존 Knowledge Base의 한계: 아래 해결책 - knowledge base 대비 장점 항목 참고
- Linguistic knowledge 위주의 연구: 이전 LM 관련 연구들은 word representation의 언어적, 의미론적인 특성에 초점을 맞춰 이러한 지식이 downstream task에 얼마나 잘 전달되었는가에 초점, LM이 저장하고 있는 factual knowledge/commonsense knowledge에 대한 연구는 미비
해결책
대량의 코퍼스로 학습한 사전학습 언어모델(PLM)
- linguistic knowledge(언어학적 지식)뿐만 아니라 relational knowledge을 저장
- 별도의 finetuning 없이도 factual knowledge를 불러올 수 있음
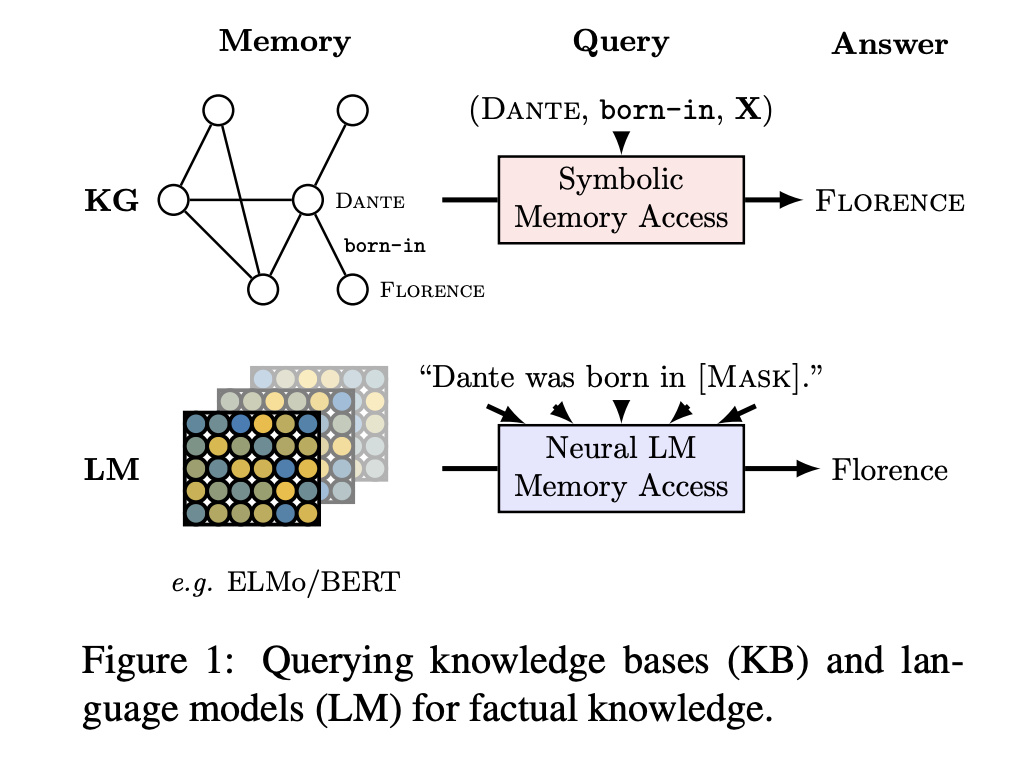
- 기존의 knowledge base 대비 여러 장점을 갖고 있음
- schema engineering과 학습을 위한 사람의 supervision이 필요 없음 (knowledge base 학습을 위해서는 텍스트나 다른 modality에서 관계형 데이터를 추출해 가공해야 하며, 복잡한 NLP 파이프라인을 필요로 하고, 오류가 퍼지기 쉬움)
- 실무자들이 open class of relations로 질문을 던질 수 있음 (기존 구조화된 knowledge base에서는 정해진 형식/구조로 질문을 던져야 하는데(query 예: born-in) LM은 그럴 필요가 없다는 뜻으로 이해함)
LAMA (LAnguage Model Analysis) Probe
- 여러 knowledge sources에서 사실관계로 이루어진 데이터를 이용해 만듦
- "Dante was born in ____"와 같이 사실을 나타내는 cloze sentence의 masked object(빈칸)를 제대로 예측할 수 있다면 LM이 [주어, 관계, 목적어(Dante, borin-in, Florence)]라는 사실을 알고 있다고 정의 (fact는 주어-관계-목적어의 Triple 혹은 질문-응답 pair의 형태로 이루어짐)
- Knowledge Sources
- Google-RE: 60K facts, 출생장소, 출생날짜, 사망장소 등 세 개의 관계 고려
- T-REx: Wikidata triple의 subset으로, 41개의 관계와 관계 당 최대 1000개의 사실을 고려
- ConceptNet: Open Mind Common Sense (OMCS) 문장들을 이용해 구축된 다언어(multilingual) knowledge base. 영어 데이터, 16개의 관계 고려 (단일 토큰 목적어)
- SQuAD: 유명한 질의응답 데이터셋. 단일 토큰 대답을 가진 305개의 context-intensive 질문들 선택
- 고려사항
- Manually defined templates: 목적어를 쿼리하는 템플릿을 수동으로 정의
- Single token: 예측 목표는 단일 토큰으로 이루어진 목적어
- Object slot: triple에서 오직 목적어 부분만을 쿼리
평가
- 비교 모델: fairseq-fconv, Transformer-XL Large, ELMo original, ELMo 5.5B, BERT-base, BERT-large 등
- vocabulary: 모델들 간의 정확한 비교를 위해, 모든 모델들이 공통으로 가지고 있는 vocab의 intersection을 활용 (~21K case-sensitive tokens)
- metrics: 평균 정확도(mean precision)
- BERT-large가 전반적으로 가장 좋은 성능을 보임
한계
- GPT2는 연구에 미포함 (GPT3 이상은 BERT보다 더 많은 Knowledge 담고 있을 수 있음)
의의
- BERT-large 모델이 정확한 relational knowledge를 가장 잘 저장하고 있으며, robust한 성능을 보임 (특히 open-domain QA에서 뛰어난 성능, 답을 맞추지 못하더라도 일반적으로 type은 정확하게 맞춤)
- 몇몇 관계에 대해서는 성능이 매우 떨어지나, 대개 사전학습된 언어모델에서 factual knowledge가 성공적으로 복구됨을 확인
- BERT를 Pearson correlation coefficient로 분석한 결과 1) 학습 데이터에 목적어가 얼마나 자주 사용되었는지가 성능과 양의 상관관계를 보이며, 2) subject의 경우 그렇지 않고, 3) 예측의 log probabilty가 p@1과 강한 상관관계를 보임 (= BERT가 예측에 높은 confidence를 가질 때 대개 정확함)(cosine similarity와도 높은 상관관계)
- ELMo original의 경우 학습과정에서 Wikipedia를 보지 않았음에도 BERT의 성능과 크게 다르지 않음
- Language models trained on ever growing corpora might become a viable alternative to traditional knowledge bases extracted from text in the future

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab