Learning Better Masking for Better Language Model Pre-training
ACL 2023
분야 및 배경지식
- Masked Language Modeling (MLM)
- BERT와 같은 모델을 사전학습할 때 널리 사용되는 목적함수
- 양방향의 정보를 활용하여 [MASK]로 가려진 부분을 예측
문제점
- 기존의 MLM 연구들은 1) 학습동안 고정된 마스킹 비율을 사용하였으며 2) 다른 내용들을 동일한 확률로 마스킹 (time-invariant)
- 시간에 따라 변화하는(time-variant) 마스킹 비율(ratio)과 마스킹 내용(content)에 대한 연구가 부족
해결책
Masking Ratio Decay (MRD)
- 마스킹 비율(masking ratio)
- 학습 초반에는 높은 마스킹 비율이 다운스트림 태스크 성능을 높이는 데에 주효
- 학습 후반에는 낮은 마스킹 비율이 성능을 높이는 데에 주효
- 위와 같은 실험 결과를 바탕으로, 시간이 지남에 따라 마스킹 비율이 감소하는 전략 생성
- Simulated Annealing (SA) 알고리즘과 유사하게, 높은 마스킹 비율은 인풋에 정보가 부족하다는 것을 의미해 더 많은 가능성을 탐구하게 하며, 낮은 마스킹 비율은 모델로 하여금 global minima을 찾을 수 있도록 도와줌
- linear, cosine 중에서 cosine이 더욱 좋은 성능을 보여주는데, 이는 높은 마스킹 비율을 더 오래 유지하고 빠르게 감소하는 것이 성능 향상에 유리함을 의미
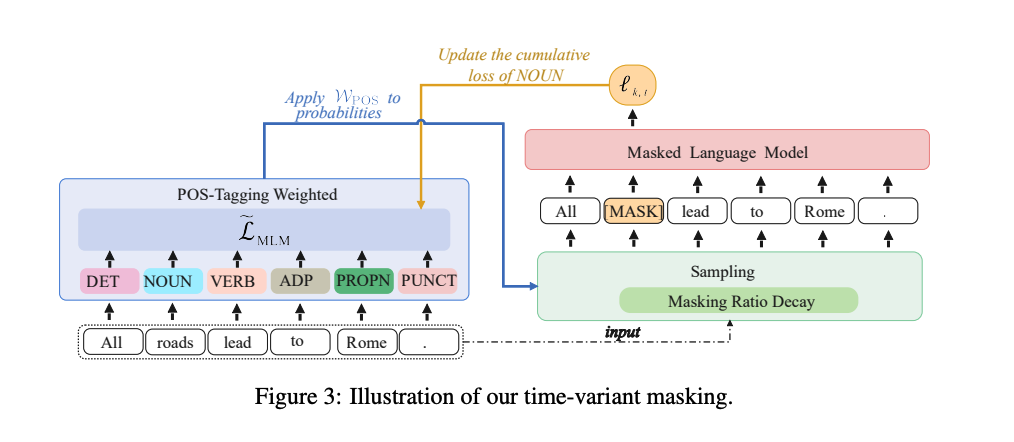
POS-Tagging Weighted (PTW) Masking

- 마스킹 내용(masked content)
- 모델은 비기능어(non-function word; 문법보다 의미가 중요한 단어)를 학습하는 데에 더욱 어려움을 겪으며, 이를 학습함으로써 더 많은 이득을 얻음
- 참고: 기능어(function workd) = 의미보다 문법적 기능이 중요한 단어
- 모델은 비기능어(non-function word; 문법보다 의미가 중요한 단어)를 학습하는 데에 더욱 어려움을 겪으며, 이를 학습함으로써 더 많은 이득을 얻음
- 위와 같은 실험 결과를 바탕으로, 학습 상태에 따라 다른 종류의 단어들의 마스킹 확률을 적응적으로(adaptively) 조정
- loss가 높은 단어들이 가려질(masked) 확률이 높음
- 이를 통해 학습 후반부로 갈수록 모델이 중요한 단어를 가림으로써 더 많은 지식을 외울 수 있도록 함
평가
- 모델
- BERT-base, BERT-large
- 데이터셋
- 사전학습: English Wikipedia
- 파인튜닝: GLUE, SQuAD v1.1, CoNLL-2003
한계
- BERT에 대해서만 실험
- learning rate decay와 마찬가지로 masking ratio decay 또한 초기값과 종료값이 중요 (튜닝의 영역)
의의
- MLM에 대해서 그동안 고려되지 않았던 time-invariant 전략을 고려하였으며, 이러한 학습 방식이 더욱 좋은 성능을 가져온다는 사실을 보여줌

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab