Scaling neural machine translation to 200 languages (link, Nature)
문제점
- 기계번역의 품질을 높이기 위해서는 수많은 언어 쌍의 데이터셋이 필요 (parallel bilingual data)
- 모든 언어들 사이의 pair dataset 확보 어려움
- 장기적으로 자원이 많은 언어에 연구가 집중되어 디지털 불평등을 심화시킬 수 있음
해결책
No Language Left Behind (NLLB-200)
- 언어들에 대해 전이 학습 (transfer learning)을 수행한 다국어 모델
- 200개의 다국어 처리 가능
- 다양한 언어를 커버할 뿐만 아니라 BLEU의 경우 평균적으로 이전의 SOTA 모델보다 약 44%의 성능 개선을 보임
학습 데이터 구축: LASER3
- distillation(증류)에 기반한 문장 인코딩 테크닉
- 자원이 적은 언어의 데이터 마이닝에 효과적
- 데이터 마이닝 단계
- 단일한 언어에 대해 데이터셋 수집
- 웹에서 데이터를 크롤링할 때, 어떤 언어인지 감지(Language IDentification; LID)하는 성능이 중요
- 문장 유사도 (semantic sentence similarity) 기반의 지표를 활용해 다른 언어에서 의미적으로 동등할 확률이 높은 문장들을 식별
- teacher-student 기법을 활용해 LASER 임베딩 공간을 확장, 해당 임베딩을 활용
- 학습 시 데이터셋은 이러한 마이닝 방식으로 구축한 데이터셋 이외에도 오픈 소스, 역번역(back-translation) 등 다양하게 사용
모델링: Sparse Gated Mixtures-of-Experts
- 관련 있는 언어에 대해 언어간(cross-lingual) 전이를 가능케 함
- 관련 없는 언어 사이의 간섭은 늘리지 않음
- Mixture of Experts (MoE)
- 몇 개의 feedforward network 레이어가 MoE 레이어로 대체됨
- MoE 레이어는 feedforward network로 표현되는 expert와, 인풋 토큰을 어떤 expert로 라우팅할 지를 결정하는 gating network로 구성
- label-smoothed cross entropy와 auxiliary load balancing loss의 조합을 최적화하는 방향으로 라우팅 학습
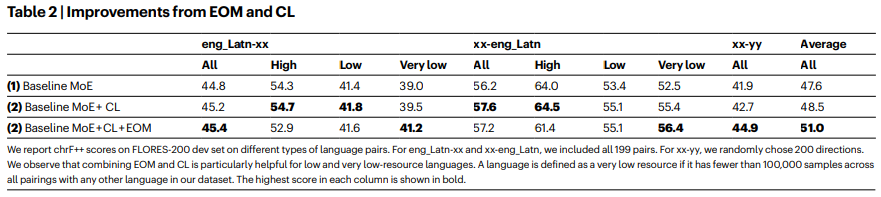
- Expert Output Masking (EOM)
- 자원이 적은 언어의 경우, MoE의 오버피팅 문제 발생
- 이를 해결하기 위해 regularization으로 EOM 적용
- Curriculum Learning
- 오버피팅을 추가적으로 막기 위해, 언어쌍을 단계적으로 학습에 사용
- Pairs that empirically overfit within K updates are introduced with K updates before the end of training.
- curriculum learning이란, 학습 시 데이터의 순서 등을 조정하는 것
- 오버피팅을 추가적으로 막기 위해, 언어쌍을 단계적으로 학습에 사용
평가: FLORES-200
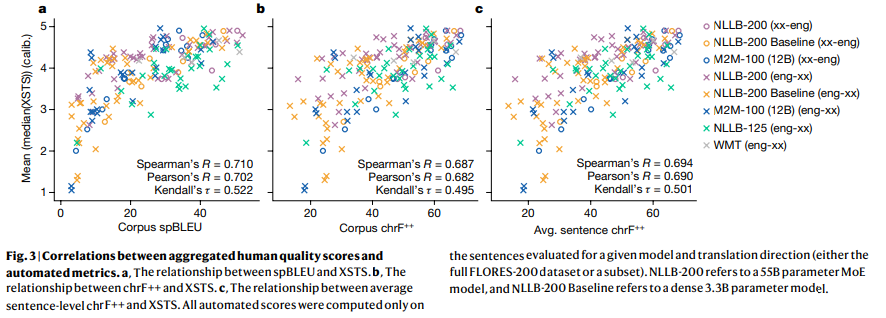
- 200개 언어 X 200개 언어의 번역 품질을 평가할 수 있는 다국어 벤치마크
- 두 개의 평가지표 추가
- Cross-lingual Semantic Text Similarity (XSTS)
- 유창성보다 의미의 보존을 강조하는 사람 평가 프로토콜
- 언어 간, 평가자 간 평가 일관성을 위한 calibration 조치 도입
- Evaluation of Toxicity (ETOX)
- 유해 단어 목록을 통해 유해한 단어가 번역 시 추가되었을 경우 이를 감지
- Cross-lingual Semantic Text Similarity (XSTS)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab