벤치마크란
- 특정 태스크에 대한 시스템의 성능을 평가하기 위한 측정 도구로써의 데이터셋
- 성능이 주요 화두로 떠오른 최근 딥러닝의 연구동향에서, 다른 연구와의 성능을 비교하기 위해선 모두가 공유하고 있는 공통의 기준이 필요
- 벤치마크 데이터셋은 이를 위한 비교 기준을 제공
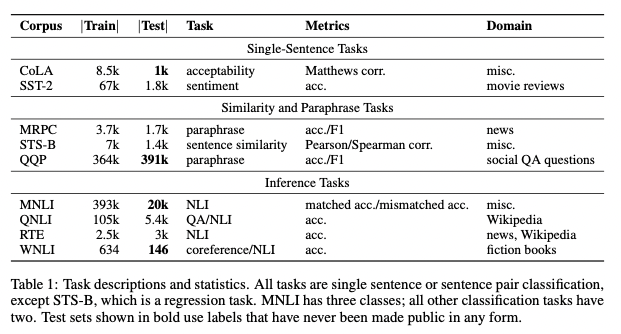
GLUE (General Language Understanding Evaluation)
- 다양한 NLU 태스크들에 대해 모델의 성능을 평가하기 위한 도구의 모음
- 태스크 전반에 걸쳐 일반적인 언어적 지식을 공유하고 있는 모델의 성능을 더욱 높이 평가하는 방식으로 고안
- 총 9개의 데이터셋 제공
SuperGLUE
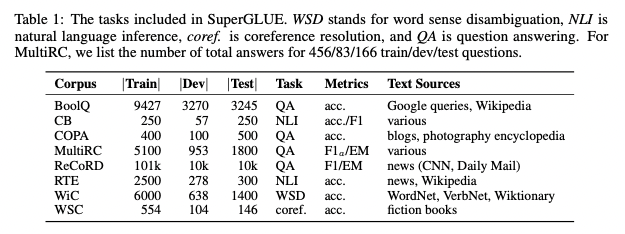
- GLUE가 나오고 약 1년 후에 등장한 새로운 벤치마크
- GLUE는 다양한 태스크들에서의 성능 향상을 단일 숫자로 요약한 측정방법(metric)을 사용
- 딥러닝의 비약적인 발전에 따라 GLUE 벤치마크에 대한 모델들의 성능이 비전문가인 사람의 수준을 넘어서게 됨
- 이에 따라 더 어려운 NLU 태스크들의 성능을 판단할 수 있는 SuperGLUE가 탄생
GLUE 대비 개선사항
- 더욱 어려운 태스크 (More challenging tasks)
- GLUE에서 가장 어려운 2개의 태스크는 유지
- 현재 NLP 연구에서 어렵다고 판단되는 방향에 기반해 태스크를 선택
- 더욱 다양한 태스크 포맷 (More diverse task formats)
- GLUE가 문장 혹은 문장쌍 단위의 분류(classification)에 국한되었던 반면, SuperGLUE는 QA(Question Answering)와 coreference resolution 형태 또한 추가
- 포괄적인 사람 기준선(Comprehensive human baselines)
- 모든 벤치마크 태스크에 대해서 사람의 퍼포먼스 추정치를 포함
- 사람이 해당 태스크를 얼마나 잘 수행하는가는 모델의 성능을 파악할 때 좋은 비교 지점
- 이 밖에도 개선된 코드 지원(Improved code support), 개정된 사용방법(Refined usage rules) 등을 설명
SQuAD (Stanford Question Answering Dataset)
- GLUE, SuperGLUE와 마찬가지로 딥러닝에서 모델의 성능을 파악할 때 사용하는 벤치마크 중 하나
- 독해(Reading Comprehension) 특화 데이터셋
- 위키피디아 데이터를 바탕으로 제기된 질문에 대해 정답에 상응하는 글의 일부를 발췌해 답변을 하는 형식
- SQuAD 2.0에서 좋은 성능을 내기 위해서 시스템은 질문에 대한 답을 잘 해야 할뿐만 아니라, 주어진 문단에 정답이 존재하는지 여부까지 판단해야 함
- 측정 방법으로는 Exact Match (EM; 정확히 일치하는지 여부)와 F1 사용

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab