[논문 정리][작성중] Multiple Instance Active Learning for Object Detection(MI-AOD)
Multiple Instance Active Learning for Object Detection
언제쯤 벨로그 버리고 다른 블로그로 갈아타지...
딥러닝은 언제나 데이터가 문제.
현실 문제를 딥러닝으로 해결하고자 할 때 우리가 쉽게 맞닥뜨릴 수 있는 데이터 관련 문제들은 지금 생각나는 것만 해도
- 데이터가 부족함
- 라벨링 비용
- 불균형한 클래스 분포
등이 있으나, 사실 이것 말고도 굉장히 많을 것.
Active Learning 같은 경우 이 중 2번의 상황에 주안점을 둔다고 볼 수 있을 것이다.
"일단 데이터를 많이 모아두긴 했는데, 이를 전부 라벨링하기엔 시간과 인력이 너무 많이 들어. 중요한 데이터 위주로 먼저 라벨링을 할 수 없을까?"
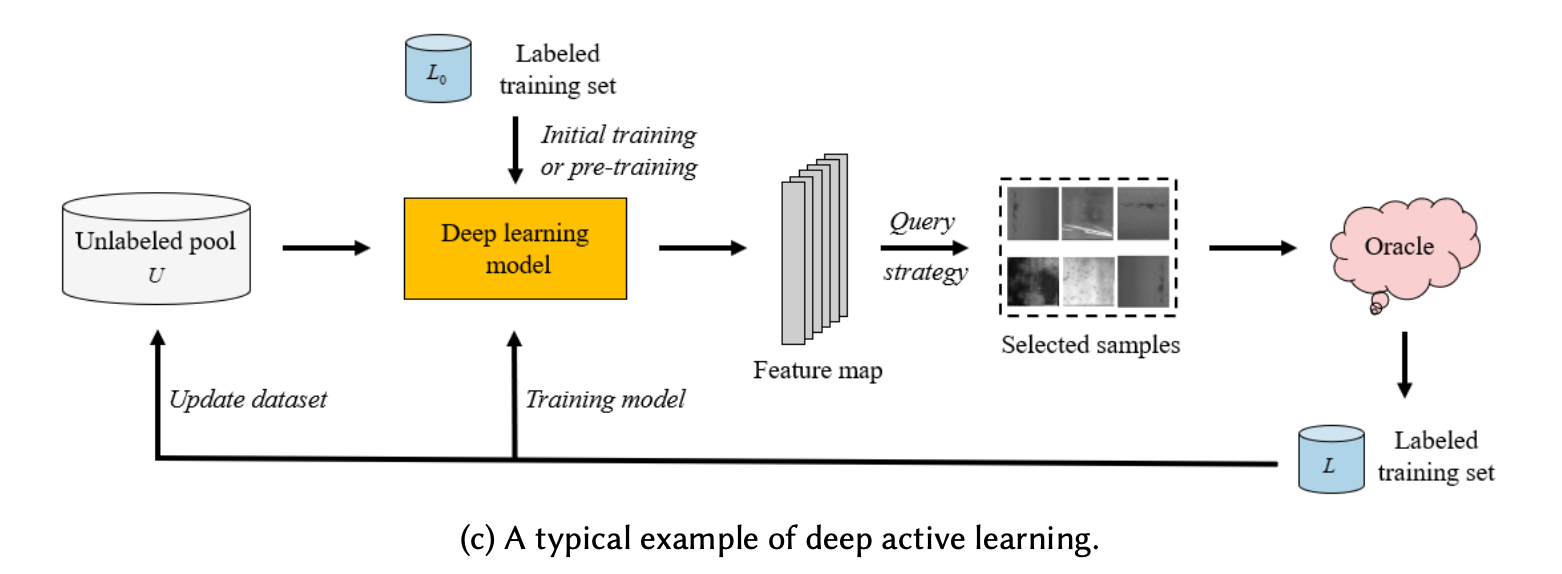 그림 출처 : A Survey of Deep Active Learning
그림 출처 : A Survey of Deep Active Learning
Active Learning은
1. 기존 라벨링된 데이터를 사용하여 먼저 모델을 학습시키고
2. 라벨링되지 않은 데이터의 모델 추론 결과를 바탕으로
3. 모델 성능 향상에 도움이 될 것 같은 데이터를 적절한 기준과 전략 (query strategy)을 사용하여 선택한 후 이를 Annotator(Oracle)에게 보내 피드백 요청.
4. Annotator가 이를 라벨링하고, 새로 라벨링된 데이터를 포함하여 1번부터 다시 반복.
의 과정으로 이루어지는데
이 적절한 기준과 전략 을 찾는 것이 대부분의 Active Learning 연구의 핵심..이 되는 것 같다.
어쨌든 여기서 정리하고자 하는 논문은 (이름대로) Active Learning을 Object Detection에 적용한 연구.
개요
Active Learning에서 "라벨링할 데이터를 고르는 적절한 기준과 전략 (Query Strategy)" 을 어떻게 세우면 좋을까?
흔히들 Active Learning은 "문제집이 진짜 드럽게 두꺼워서 다 풀긴 귀찮은데 이 중 어떤 문제 위주로 풀어야 시험 성적이 올라갈까?" 에 비유가 많이 되곤 한다. 이 때 생각해 볼 수 있는 전략 중 하나는 "아.. 이거 좀 헷갈리는데..." 하는 문제를 주로 선택하는 전략이다. Active Leaning에서는 이를 "Uncertainty-based method" 라고 한다.
그렇다면, 이 "Uncertainty"를 어떻게 정의하냐...도 보면 굉장히 다양한데, 모델 추론 결과로 나온 posterior의 entropy를 사용하는 방법부터 Loss 자체를 추정하는 방법 까지 여러 metric이 제안되어왔다. Vision task의 경우 uncertainty가 한장의 이미지마다 계산되고, active learning 과정에서는 이 uncertainty가 높은 이미지들 위주로 라벨링해달라고 annotator에게 요청할 수 있을 것이다.
Object Detection Task는 이미지상에서 특정한 객체(instance)의 위치와 클래스를 예측하는 작업이다. 마찬가지로 active object detection에서도 적절한 기준과 전략을 사용하여 informative한 이미지를 골라야 할 것이다.
informative한, 그러니까 중요한 이미지를 잘 선택하기 위해서는 image-level uncertainty가 잘 정의되어 있어야 한다. 하지만 앞서 말했다시피 object detection은 image-level이 아닌 instance-level로 예측을 진행하기 때문에 (사진 한 장 단위로 분류하면 되는) vision classification에서보다 이를 정의하기가 조금 더 까다로울 것이다. 본 논문에서는, 기존 active object detection 연구들이 하나의 이미지에서 검출된 여러 instance-level uncertainty를 단순히 평균내는 방식으로 image-level uncertainty를 구하고 있고, 이렇게 얻은 image-level uncertainty의 경우 negative instance로 인한 noise가 굉장히 심해 진짜 중요한(informative) 이미지를 놓칠 가능성이 크다고 지적한다.
- 많은 Object Detection Model의 경우 이미지 한 장 예측의 결과값으로 10k~100k의 anchor가 나오는데, 이 중 실제 instance에 매칭되는 anchor는 극소수고 대부분은 negative instance이다.
따라서 본 논문에서는 instance-level uncertainty와 image-level uncertainty의와의 간극을 줄일 수 있는 방법을 제시한다.
Instance uncertainty learning(IUL)
본 논문에서는 이미지 하나를 여러 객체들이 들어있는 객체 가방(Instance bag)으로 간주한다.
그리고 객체들의 데이터 분포와 관련하여 본 논문에서 깔고 들어가는 가정은 다음과 같다
"labeled set에 있는 데이터 분포는 실제 데이터 분포와 비교하여 편향(bias)되어 있을 것이다. "
따라서 unlabeled set에 존재하는 객체들 중 informative한(=라벨링할 가치가 있는) 객체는 labeled set의 데이터 분포와 거리가 있는 지점에 존재할 것이고, 이 부분에 존재하는 객체들을 잘 골라내는 어떤 기준을 설정하는 것이 중요하다고 할 것이다.
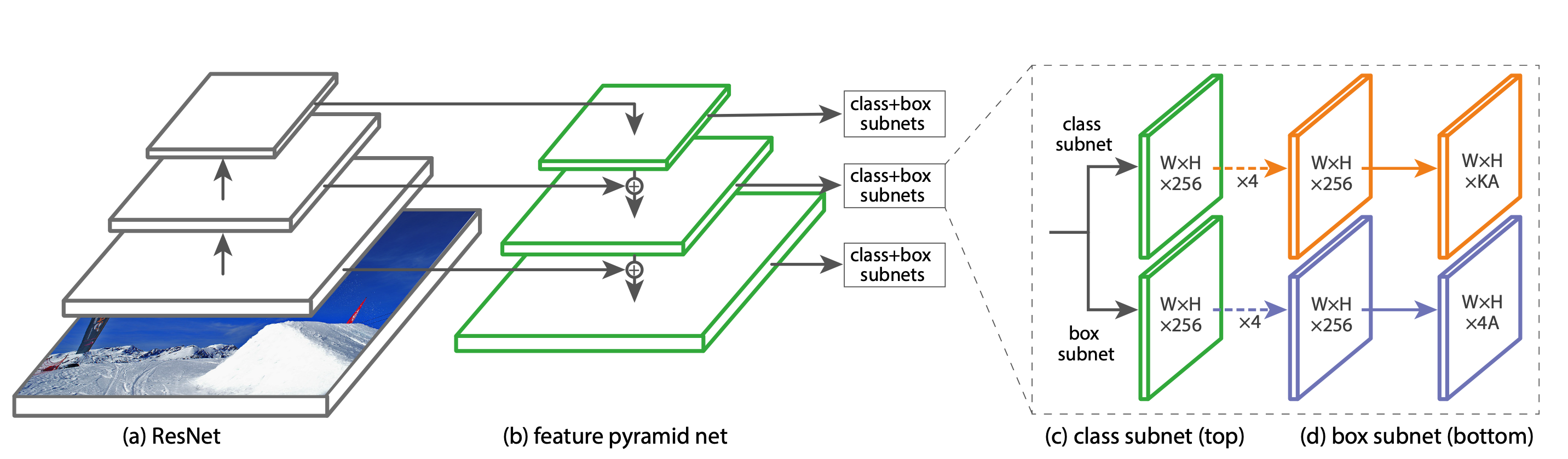
RetinaNet(Baseline)
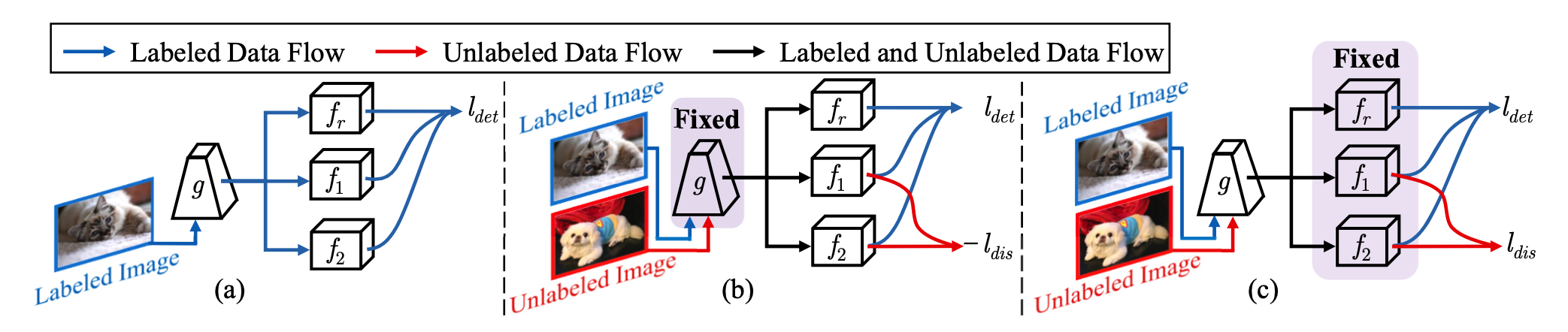
MI-AOD
따라서 본 논문에서는 IUL을 위해 (기존 baseline인 retinanet과 달리) Adversarial한 두개의 Class Classification Network , 를 정의한다. 은 기존의 box regression network과 대동소이하다.
Labeled Set Training
먼저, Labeled Set에 대해서는 다음과 같은 Loss를 사용하여 평범하게 feature extractor , 그리고 , , 을 학습시킨다.
은 focal loss fuctionm, 은 smooth L1 loss function을 의미한다.
Maximizing Instance Uncertainty.
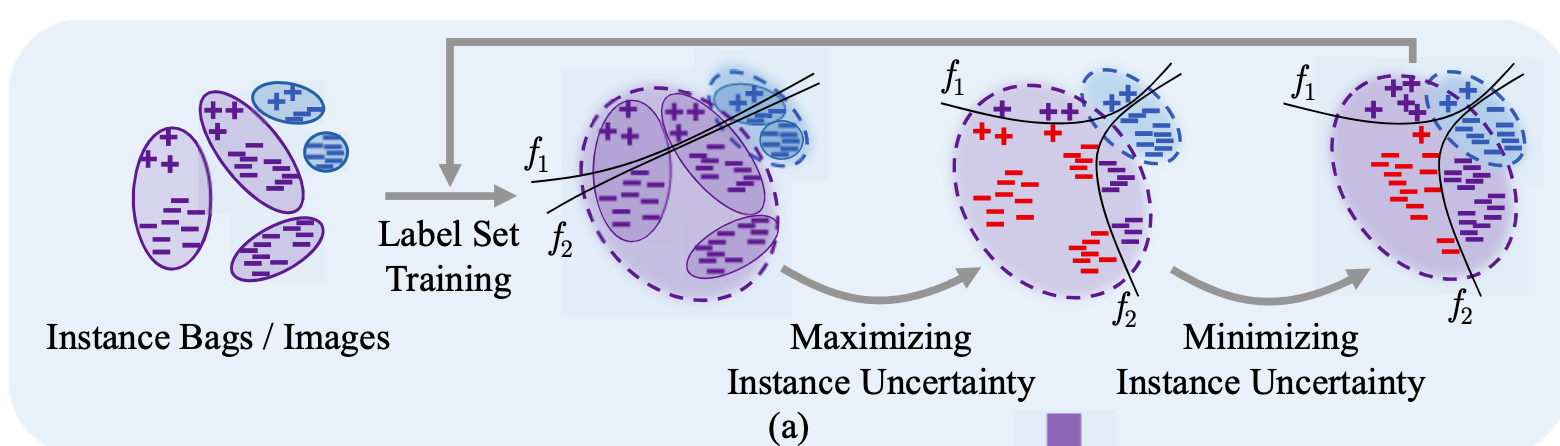
앞서 언급한것처럼, 먼저 라벨링할 가치가 있는 Instance들은 기존 Labeled set에서 떨어진 곳에 분포하는 instance 라는 가정을 세운 바 있다. 그리고 과 는 단순히 classifier 역할만 하는 것이 아닌 instance가 labeled set에 대해 얼마나 떨어져있는지도 학습하는 adversarial network이다.
이 단계에서는 feature extractor network 의 weight들이 고정되고, Labeled data와 Unlabeled data 전부에 대해 , , 을 다음과 같이 학습한다.
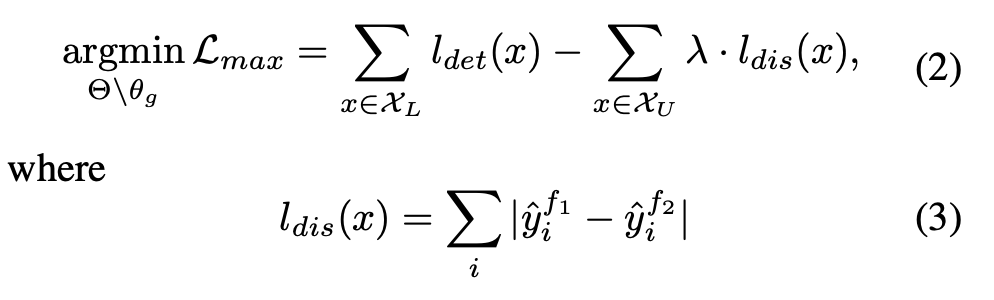
는 labeled set에 대해서만 계산되며, 는 unlabeled set에 대해서만 계산된다.
여기서 가 바로 두 adversarial network , 의 output의 "차이"로 나타내어진 uncertainty metric이다.
왜 uncertainty metric이 될 수 있을까?
- 일단, 두 네트워크 , 는 labeled set data에 대해서는 classification network로 학습이 되어 있기 때문에, labeled set 의 분포에 있는 데이터에 대해서는 비슷한 classification output을 보일 것이다. 하지만, unlabeled, 즉 기존 학습 데이터의 분포 바깥의 데이터에 대해서는 두 네트워크의 output 거리 사이가 멀어지도록 학습이 진행된다. 즉, labeled set의 분포와 거리가 멀수록(=기존에 못 보던 분포일수록=더 중요할수록!) 는 커질 것이라고 볼 수 있다.
