
[ 다형성 쿼리 ]
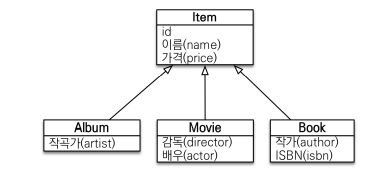
Item이 부모 객체로 다형성을 구현한 구조
1. TYPE
- 조회 대상을 특정 자식으로 한정한다.
- Ex)
Item중에Book,Movie를 조회해라.
//JPQL
select i from Item i
where type(i) IN (Book, Movie)
//SQL
select i from i
where i.DTYPE in ('B', 'M')2. TREAT (JPA 2.1)
- 자바의 타입 캐스팅과 유사하다.
- 상속 구조에서 부모 타입을 특정 자식 타입으로 다룰 때 사용한다.
- FROM, WHERE, SELECT(하이버네이트 지원)를 사용한다.
- Ex) 부모인
Item과 자식Book이 있다.
//JPQL
select i from Item i
where treat(i as Book).auther = 'kim'
//SQL
select i.* from Item i
where i.DTYPE = 'B' and i.auther = 'kim'[ 엔티티 직접 사용 ]
JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용한다.
[ Named 쿼리 ]
미리 정의해서 이름을 부여해두고 사용하는 JPQL
- 정적 쿼리만 가능하다.
- 어노테이션, XML에 정의한다.
- 어플리케이션 로딩 시점에 초기화 후 재사용할 수 있다.
- 어플리케이션 로딩 시점에 쿼리를 검증한다. ⭐
1. 어노테이션
@Entity
@NamedQuery(
name = "Member.findByUsername",
query="select m from Member m where m.username = :username")
public class Member {
...
}
List<Member> resultList =
em.createNamedQuery("Member.findByUsername", Member.class)
.setParameter("username", "회원1")
.getResultList();2. XML에 정의
//[META_INF?persistence.xml]
<persistence-unit name="jpabook">
<mapping-file>META-INF/ormMember.xml</mapping-file>
//[META-INF/ormMember.xml]
<?xml version="1.0" encoding="UTF-8"?>
<entity-mappings xmlns="htt://xmlns.jcp.org/xml/ns/persistence/orm" version="2.1">
<named-query name="Member.findByUsername">
<query>
<![CDATA[ select m from Member m where m.username = :username]]
</query>
</named-query>
</entity-mappings>📌 Named 쿼리 환경에 따른 설정
- XML이 항상 우선권을 가진다.
- 어플리케이션 운영 환경에 따라 다른 XML을 배포할 수 있다.
[ 벌크 연산 ]
SQL의 UPDATE/DELETE를 생각하면 된다!
1. 벌크 연산
재고가 10개 미만인 모든 상품의 가격을 10% 높여야 하는 경우를 가정해보자.
JPA 변경 감지 기능으로 실행하려면 너무 많은 SQL이 실행되어야 한다.
① 재고가 10개 미만인 상품을 리스트로 조회한다.
② 상품 엔티티의 가격을 10% 증가한다.
③ 트랜잭션 커밋 시점에 변경 감지가 동작한다.
만약 변경된 데이터가 100건이라면 100번의 UPDATE SQL이 실행된다!!
2. 벌크 연산 예제
- 벌크 연산은 쿼리 한 번으로 여러 테이블 로우를 변경할 수 있다.
executeUpdate()의 결과는 영향받은 엔티티 수를 반환한다.- UPDATE, DELETE 지원
INSERT(insert into .. select, 하이버네이트 지원)
3. 벌크 연산 주의
벌크 연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리를 날린다.
그래서
- 벌크 연산을 먼저 실행하거나,
- 벌크 연산 수행 후 영속성 컨텍스트를 초기화해줘야 한다.

🚧 https://coji.tistory.com/ 🏠