다중 레이블 분류
이미지 내에 포함된 하나 이상의 물체 범주를 식별하는 문제
물체가 여러 종류 존재할 수도 있고, 전혀 없을 수 도 있다.
데이터
from fastai.vision.all import *
path = untar_data(URLs.PASCAL_2007)
df = pd.read_csv(path/'train.csv')
df.head()
fname labels is_valid
0 000005.jpg chair True
1 000007.jpg car True
2 000009.jpg horse person True
3 000012.jpg car False
4 000016.jpg bicycle True데이터가 파일명이나 폴더로 구조화가 아닌 이미지 파일명과 레이블 정보를 기록한 csv 파일 구조
데이터블록(DataBlock) 구성하기
Dataset - 단일 데이터를 표현하는 독립변수 및 종속변수 튜플을 반환합니다.
DataLoader - 미니배치 스트림을 제공하는 반복자로, 각 미니배치는 여러 독립변수와 종속변수에 대한 튜플로 구성됩니다.
fastai는 이 두 클래스를 기반으로 학습용 및 검증용 데이터셋을 함께 다루는 별도의 두 클래스를 제공한다.
Datasets
학습용 및 검증용 Dataset을 포함하는 반복자입니다.
DataLoaders
학습용 및 검증용 DataLoader를 포함하는 객체입니다.
데이터블록(Datablock) 단계적으로 구성하기
dblock = DataBlock()
디폴트 파라미터로 구성된 데이터블록(Datablock) 생성
dsets = dblock.datasets(df)
Datablock 객체로 Datasets 객체를 생성할 수 있다.
len(dsets.train),len(dsets.valid)
(4009, 1002)Datasets은 train과 valid라는 속성을 가지고 있다.
x,y = dsets.train[0]
x,y
(fname 008663.jpg
labels car person
is_valid False
Name: 4346, dtype: object, fname 008663.jpg
labels car person
is_valid False
Name: 4346, dtype: object)dblock = DataBlock(get_x = lambda r: r['fname'], get_y = lambda r: r['labels'])
dsets = dblock.datasets(df)
dsets.train[0]
('005620.jpg', 'aeroplane')get_x에는 입력을 get_y에는 타깃필드를 가져오는 함수를 인자로 지정
def get_x(r): return r['fname']
def get_y(r): return r['labels']
dblock = DataBlock(get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0]
('002549.jpg', 'tvmonitor')위와 동일하나 파이썬의 lambda 키워드는 간단하게 함수를 정의하고 참조하는 방법이다.
위에 처럼 함수를 정의하는 방식이 이상적인 방식이다.
def get_x(r): return path/'train'/r['fname']
def get_y(r): return r['labels'].split(' ')
dblock = DataBlock(get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0]
(Path('/root/.fastai/data/pascal_2007/train/002844.jpg'), ['train'])이미지를 열려면 완전한 경로로 X(독립변수)를 구성해야 한다.
레이블은 여러개로 구성되기때문에 파이썬 split 함수를 이용하여 쪼개서 목록으로 구성한다.
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
dsets.train[0]
(PILImage mode=RGB size=500x375,
TensorMultiCategory([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]))실제 모델에 넣기위해서는 이미지 파일을 텐서로 변환하는 여러가지 과정을 거쳐야 한다.
fastai에서는 이를 처리하는 여러가지 블록이 있고, 이미지는 imageblock을 통해서 이를 처리한다. categoryBlock은 단일 레이블 분류만 가능하므로, MulticategoryBlock을 통해서 다중 레이블을 반환한다.
idxs = torch.where(dsets.train[0][1]==1.)
dsets.train.vocab
(#1) ['car']다중레이블의 원-핫 인코딩 벡터가 어떤 범주를 표현하는지 확인
def splitter(df):
train = df.index[~df['is_valid']].tolist()
valid = df.index[df['is_valid']].tolist()
return train,valid
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock),
splitter=splitter,
get_x=get_x,
get_y=get_y)
dsets = dblock.datasets(df)
dsets.train[0]
(PILImage mode=RGB size=500x333,
TensorMultiCategory([0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]))spliter와 is_valid 속성을 활용하여 학습용과 검증용 데이터셋을 구분한다.
dls.show_batch(nrows=2, ncols=5)

show_batch를 통해서 표본 출력
이진 교차 엔트로피(Binary Cross-Entropy)
learn = cnn_learner(dls, resnet18)
x,y = to_cpu(dls.train.one_batch())
activs = learn.model(x)
activs.shape
torch.Size([64, 20])DataLoader에서 미니배치를 하나 가져와서 모델에 주입하여 출력하는 활성값을 확인
activs[0]
TensorBase([-0.2755, 1.6981, -0.3815, -3.3111, 2.8863, 1.7865, 1.5819, 0.5152, 0.1063, 0.2559, 0.6732, -1.1454, 2.5230, 1.6622, -1.3969, 1.1609, 3.6548, -3.2479, -1.0142, 0.4776],
grad_fn=<AliasBackward0>)active모양은 설정한 배치 크기가 64이고, 범주 20개에 대한 확률이기 때문에 (64,20)의 모양을 가진다.
def binary_cross_entropy(inputs, targets):
inputs = inputs.sigmoid()
return -torch.where(targets==1, 1-inputs, inputs).log().mean()
이진 교차 엔트로피는 4장에서 MNIST 손실 함수에 log를 추가한 버전이다.
원-핫 인코딩 된 종속변수에는 nll_loss나 소프트맥스를 즉시 사용할 수 없다.
단계별로 수식을 적용해보겠다.
activs[0].sigmoid()
TensorBase([0.4316, 0.8453, 0.4058, 0.0352, 0.9472, 0.8565, 0.8295, 0.6260, 0.5266, 0.5636, 0.6622, 0.2413, 0.9257, 0.8405, 0.1983, 0.7615, 0.9748, 0.0374, 0.2662, 0.6172], grad_fn=<AliasBackward0>)- 시그모이드 적용(sigmoid())
binary_cross_entropy(activs[0], y[0])
TensorMultiCategory([-0.8403, -0.1681, -0.9020, -3.3469, -2.9406, -0.1549, -0.1870, -0.4684, -0.6414, -0.5734, -0.4121, -1.4216, -0.0772, -0.1737, -0.2210, -0.2725, -0.0255, -3.2860, -1.3237, -0.4826],
grad_fn=<AliasBackward0>)- 로그적용(log)
binary_cross_entropy(activs[0], y[0])
TensorMultiCategory(-0.8959, grad_fn=<AliasBackward0>)- 평균값 적용(mean)
binary_cross_entropy(activs[0], y[0])
TensorMultiCategory(0.8959, grad_fn=<AliasBackward0>)- -값적용
loss_func = nn.BCEWithLogitsLoss()
loss = loss_func(activs, y)
loss
TensorMultiCategory(0.8739, grad_fn=<AliasBackward0>)원-핫 인코딩 -> 시그모이드 및 이진 교차 엔트로피가 모두 포함된 손실함수 F.binary_cross_entropy_with_logits 나 nn.BCEWithLogitsLoss를 사용한다.
def accuracy(inp, targ, axis=-1):
"Compute accuracy with `targ` when `pred` is bs * n_classes"
pred = inp.argmax(dim=axis)
return (pred == targ).float().mean()
def accuracy_multi(inp, targ, thresh=0.5, sigmoid=True):
"Compute accuracy when `inp` and `targ` are the same size."
if sigmoid: inp = inp.sigmoid()
return ((inp>thresh)==targ.bool()).float().mean()다중 분류의 경우 가장 높은 출력 활성을 반환하는 argmax를 사용할 수 없다. 따라서 임계점(threshold)을 선택하고 그 값을 넘는 활성을 모두 1로 하고, 나머지는 0으로 한다.
def say_hello(name, say_what="Hello"): return f"{say_what} {name}."
say_hello('Jeremy'),say_hello('Jeremy', 'Ahoy!')
('Hello Jeremy.', 'Ahoy! Jeremy.')파이썬의 parital을 통해서 일부 인자에 고정값을 다시 할당한 새로운 버전의 함수를 생성
f = partial(say_hello, say_what="Bonjour")
f("Jeremy"),f("Sylvain")
learn = cnn_learner(dls, resnet50, metrics=partial(accuracy_multi, thresh=0.2))
learn.fine_tune(3, base_lr=3e-3, freeze_epochs=4)
epoch train_loss valid_loss accuracy_multi time
0 0.950316 0.701723 0.229183 00:28
1 0.826105 0.562375 0.287669 00:28
2 0.604178 0.200890 0.827131 00:28
3 0.362162 0.124872 0.941593 00:28
epoch train_loss valid_loss accuracy_multi time
0 0.134713 0.115197 0.947032 00:28
1 0.119107 0.107229 0.949482 00:28
2 0.097963 0.105007 0.950498 00:28
임계점을 0.2로 설정하여 모델을 학습시켜본다.
올바른 임계점 설정을 매우 중요하다.
너무 낮게 설정하면 레이블링 된 물체를 선택하지 못한다.
반대로 너무 높게 설정하면 자신있는 물체 단 하나만 선택할 가능성이 높다.
learn.metrics = partial(accuracy_multi, thresh=0.1)
learn.validate()
[0.10500721633434296,0.9279481768608093]learn.metrics = partial(accuracy_multi, thresh=0.99)
learn.validate()
[0.10500721633434296,0.9424302577972412]검증용 데이터셋의 손실과 평가지표를 반환하는 validate 메소드를 통해서 확인한다.
preds,targs = learn.get_preds()
get_preds 함수를 통해서 예측값을 얻는다.
accuracy_multi(preds, targs, thresh=0.9, sigmoid=False)
TensorBase(0.9566)평가 지표함수를 직접 호출하여 최적의 임계점을 찾는다. ( get_preds 함수가 sigmoid를 적용하므로 여기서는 적용하지 않는다 )
xs = torch.linspace(0.05,0.95,29)
accs = [accuracy_multi(preds, targs, thresh=i, sigmoid=False) for i in xs]
plt.plot(xs,accs);
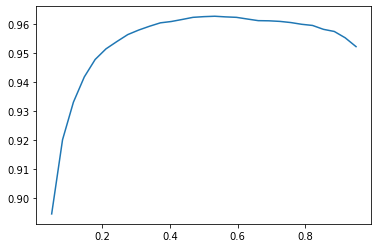
검증용 데이터셋을 사용하여 최적의 임계값을 찾으려고 했다.(하이퍼파라미터 선택) 시도를 많이 하는 과정에서 검증용 데이터셋에 과적합될 문제도 있지만, 그래프에서 보이는것과 같이 부드러운 곡선 형태로 나와있으니 부적합한 이상치를 선택하지 않을 가능성이 높다.
이미지 회귀
사람의 이미지에서 특정 위치를 의미하는 키 포인트를 찾는 모델을 만든다.
path = untar_data(URLs.BIWI_HEAD_POSE)
Path.BASE_PATH = pathBiwi Kinect Head Pose dataset을 사용한다. 데이터를 불러오고, 기본 경로로 설정한다.
path.ls().sorted()
(#50) [Path('01'),Path('01.obj'),Path('02'),Path('02.obj'),Path('03'),Path('03.obj'),Path('04'),Path('04.obj'),Path('05')1부터 24까지 숫자에 해당하는 디렉터리 24개와 obj파일이 담겨있다.
(path/'01').ls().sorted()
(#1000) [Path('01/depth.cal'),Path('01/frame_00003_pose.txt'),Path('01/frame_00003_rgb.jpg'),Path('01/frame_00004_pose.txt'),Path('01/frame_00004_rgb.jpg'),Path('01/frame_00005_pose.txt'),Path('01/frame_00005_rgb.jpg'),Path('01/frame_00006_pose.txt'),Path('01/frame_00006_rgb.jpg')숫자1 디렉토리 내부를 살펴보겠다.
서로 다른 프레임을 나타내는 데이터가 있다.
img_files = get_image_files(path)
def img2pose(x): return Path(f'{str(x)[:-7]}pose.txt')
img2pose(img_files[0])
Path('03/frame_00401_pose.txt')포즈 파일명을 반환하는 함수
im = PILImage.create(img_files[0])
im.shape
(480, 640)
im.to_thumb(160)

첫 번째 이미지를 살펴본다.
cal = np.genfromtxt(path/'01'/'rgb.cal', skip_footer=6)
def get_ctr(f):
ctr = np.genfromtxt(img2pose(f), skip_header=3)
c1 = ctr[0] * cal[0][0]/ctr[2] + cal[0][2]
c2 = ctr[1] * cal[1][1]/ctr[2] + cal[1][2]
return tensor([c1,c2])
get_ctr(img_files[0])
tensor([399.4738, 261.1201])머리의 중심 위치를 추출하는 함수
-> 좌표 요소가 둘인 텐서를 반환한다.
biwi = DataBlock(
blocks=(ImageBlock, PointBlock),
get_items=get_image_files,
get_y=get_ctr,
splitter=FuncSplitter(lambda o: o.parent.name=='13'),
batch_tfms=[*aug_transforms(size=(240,320)),
Normalize.from_stats(*imagenet_stats)]
)
데이터블록을 통해서 데이터셋 구조화
종속변수가 좌표이므로 pointblock을 두 번째 블록으로 설정
라벨은 get_ctr 함수를 통해서 설정
splitter는 특정 한 사람의 이미지에서만 검증데이터가 구성되도록 설정
dls = biwi.dataloaders(path)
dls.show_batch(max_n=9, figsize=(8,6))

이미지와 레이블 데이터가 정상인지 show_batch를 통해서 확인
xb,yb = dls.one_batch()
xb.shape,yb.shape
(torch.Size([64, 3, 240, 320]), torch.Size([64, 1, 2]))
yb[0]
TensorPoint([[-0.3421, 0.3127]], device='cuda:0')텐서의 실제값 확인 -> 미니 배치의 모양이 왜 이런지 꼭 확인 !
64 - 배치의 크기
3 - 이미지이므로 채널의 개수 (RGB)
240*320 - 이미지의 크기
1*2 - 좌표의 구조
모델 학습
learn = cnn_learner(dls, resnet18, y_range=(-1,1))
y_lange를 통해서 좌표값이 -1~1 사이가 되도록 설정한다.
def sigmoid_range(x, lo, hi): return torch.sigmoid(x) * (hi-lo) + lo
plot_function(partial(sigmoid_range,lo=-1,hi=1), min=-4, max=4)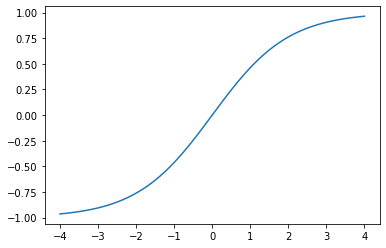
fastai에서는 sigmoid_range 함수로 y_range를 구현한다.
dls.loss_func
FlattenedLoss of MSELoss()모델은 좌표에 가능한 한 가까운 값을 예측하려고 하므로 fastiai에서는 MSELoss 손실 함수를 사용한다.
learn.lr_find()
SuggestedLRs(valley=0.0014454397605732083)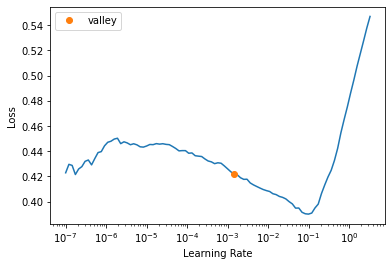
학습률 발견자로 적당한 학습률 발견
lr = 1e-2
learn.fine_tune(3, lr)
epoch train_loss valid_loss time
0 0.053167 0.006918 01:56
epoch train_loss valid_loss time
0 0.008187 0.003447 02:02
1 0.003328 0.000542 02:00
2 0.001454 0.000084 02:01적당한 학습률로 모델 학습 진행
learn.show_results(ds_idx=1, nrows=3, figsize=(6,8))

show_results 메소드를 통해서 검증용 데이터를 대상으로 결과를 시각적으로 확인
좌측은 실제 좌표, 우측은 모델 예측 좌표
fastai의 손실 함수
단일 레이블 분류 문제(single-label classification) - nn.CrossEntropyLoss
다중 레이블 분류 문제(multi-label classification) - nn.BCEWithLogitsLoss
회귀(regression) - nn.MSELoss
