[Oracle] 함수
(1) LENGTH/LENGTHB 숫자세기
SELECT LENGTH('오라클'), LENGTHB('오라클') FROM DUAL; --DUAL 가상테이블 / LENGTH 글자수 / LENGTHB 바이트크기
SELECT LENGTH(EMAIL), LENGTHB(EMAIL) FROM EMPLOYEE; --한글은 3BYTE이고 영어/특수문자/숫자는 1BYTE(2) INSTR 문자열에서 문자 위치 찾기
INSTR (문자열, 검색할 문자, 시작지점, n번째 검색단어)
SELECT INSTR ('AABAACAABBAA','B') FROM DUAL; --3
SELECT INSTR ('AABAACAABBAA','A') FROM DUAL; --1
SELECT INSTR ('AABAACAABBAA','Z') FROM DUAL; --0
SELECT INSTR ('AABAACAABBAA','B',7) FROM DUAL; --7번째부터 시작해서 B가 처음나오는 위치 --9
SELECT INSTR ('AABAACAABBAA','B',-1) FROM DUAL; -- 끝에서 1번째부터 읽기 시작해서 처음 나오는 B의 위치 --10
SELECT INSTR ('AABAACAABBAA','A',-3) FROM DUAL; -- 끝에서 3번째부터 읽기 시작해서 처음 나오는 A의 위치(3) LTRIM/RTRIM/TRIM 공백제거
TRIM("문자열")
문자열의 양쪽 공백(스페이스바)을 제거한다.
SELECT TRIM (' KH ') N FROM DUAL; --양쪽으로 삭제
--SELECT TRIM('ZZZKHZZZZ', 'Z') FROM DUAL;
SELECT TRIM('Z' FROM 'ZZZKHZZZ') FROM DUAL;
SELECT TRIM ('123' FROM '123321KH321331') FROM DUAL; --TRIM은 하나 문자만 가지가 있어야함
SELECT TRIM(LEADING 'Z' FROM 'ZZZ123456ZZZZ') FROM DUAL; -- LTRIM
SELECT TRIM(TRAILING 'Z' FROM 'ZZZ123456ZZZ') FROM DUAL; -- ZZZ123456
SELECT TRIM (BOTH 'Z' FROM 'ZZZ123456ZZZ') FROM DUAL; -- 123456LTRIM("문자열", "옵션")
문자열의 왼쪽(좌측) 공백 제거, 문자 왼쪽 반복적인 문자를 제거를 한다.
RTRIM("문자열", "옵션")
문자열의 오른쪽(우측) 공백 제거, 문자 왼쪽 반복적인 문자를 제거를 한다.
SELECT LTRIM(' KH') , RTRIM('KH ') A FROM DUAL;
SELECT LTRIM(' KH ') A , RTRIM(' KH ') B FROM DUAL;
SELECT LTRIM('000123456','0'), RTRIM('123456000','0') FROM DUAL;
SELECT LTRIM('123123KH123', '123') , RTRIM('123123KH123','123') FROM DUAL; -- KH123/123123KH 계속 돌아서 삭제
SELECT LTRIM('ACABACCKH','ABC'), RTRIM('KHACABACC','ABC') FROM DUAL; --KH/KH , 왼쪽부터 문자가 ABC 중에 포함되어 있는것은 지우기
SELECT EAMIL, RTRIM (EMAIL, '@kh.or.kr') FROM EMPLOYEE; --아이디를 추출하기엔 잘못된 방식임(4) SUBSTR 문자열 자르기
SUBSTR("문자열", "시작위치", "길이")
--문자열 자르기 SUBSTR (String.substring()) -- SUBSTR("문자열", "시작위치", "길이")
SELECT SUBSTR('HELLOMYGOODFRIENDS',7) FROM DUAL; -- 7번째이후로 끝까지 다가져옴 (인자가 2개인 경우) --YGOODFRIENDS
SELECT SUBSTR('HELLOMYGOODFRIENDS',5, 2) FROM DUAL; --OM
SELECT SUBSTR('HELLOMYGOODFRIENDS',5, 0) FROM DUAL; --NULL
SELECT SUBSTR('HELLOMYGOODFRIENDS',-10, 2) FROM DUAL; --끝에서 10번째 2개 문자 가져오기 --OO ※OG아님!
--EMPLOYEE테이블에서 이름, 이메일, @이후를 제외한 아이디 조회
SELECT EMP_NAME, EMAIL, SUBSTR( EMAIL, 1, INSTR(EMAIL, '@')-1) -- 1. 골뱅이 위치를 INSTR로 찾아주고 2. @ 위치 전까지 출력
FROM EMPLOYEE;
--EMPLOYEE테이블에서 이름, 주민등록번호에서 성별을 나타내는 부분 조회
SELECT EMP_NAME, EMP_NO, SUBSTR(EMP_NO, INSTR(EMP_NO, '-')+1, 1)
-- SUBSTR (EMP_NO,8,1)
FROM EMPLOYEE;
--EMPLOYEE테이블에서 남자만 조회
SELECT EMP_NAME
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, INSTR(EMP_NO, '-')+1, 1) = 1;
--WHERE SUBSTR(EMP_NO, INSTR(EMP_NO, '-')+1, 1) IN (1,3);
--EMPLOYEE 테이블에서 여자만 조회
SELECT EMP_NAME
FROM EMPLOYEE
WHERE SUBSTR(EMP_NO, INSTR(EMP_NO, '-')+1, 1) = 2;
--EMPLOYEE테이블에서 직워들의 주민번호를 이용하여 사원 명, 생년, 생월, 생일 조회
SELECT EMP_NAME, SUBSTR(EMP_NO,1,2) AS "생년" , SUBSTR(EMP_NO,3,2) 생월, SUBSTR (EMP_NO, 5,2) 생일
FROM EMPLOYEE;(5) LOWER, UPPER, INITCAP 대문자/소문자 변경
SELECT LOWER ('Welcome TO My World'),
UPPER ('Welcome TO My World'),
INITCAP ('welcome to my world')
FROM DUAL;(6) CONTACT
전달받은 두개의 인자를 합쳐줌
SELECT CONCAT ('가나다라', 'ABCD') FROM DUAL;
SELECT '가나다라' || 'ABCD' FROM DUAL;(7) REPLACE
REPLACE("컬럼명 or 문자열", "찾을문자", "치환문자")
SELECT REPLACE('서울시 강남구 역삼동', '역삼동', '삼성동') FROM DUAL;
SELECT REPLACE('박신우 강사님은 오늘 분홍색 옷을 입었습니다', '강사님', '선생님') FROM DUAL;
SELECT REPLACE ('박신우강사님은 B강의장 강사님입니다.', '강사님', '직원') FROM DUAL;(8) 숫자관련함수
8-1) ABS 절대값
SELECT ABS(10.9), ABS(-10.9) FROM DUAL;
-- 10.9 / 10.98-2) MOD 나머지
SELECT MOD(10, 3), MOD(10, -3) , MOD(-10, 3), MOD(10.9, 3)
FROM DUAL;
-- 1 / 1 / -1 / 1.98-3) ROUND 반올림 / FLOOR 올림 / TRUNC 절삭/ CEIL 내림
ROUND
SELECT ROUND (123.456) , ROUND(123.678), ROUND(123.456, 0) , ROUND(123.456, 1), ROUND (123.456, -1)
FROM DUAL;
-- 123 / 124 / 123 / 123.5 / 120 FLOOR
ELECT FLOOR(123.456), FLOOR(123.678) FROM DUAL; --원하는 자리에서 내림 불가
-- 123 / 123TRUNC
SELECT TRUNC (123.678,0) , TRUNC(123.678, 2), TRUNC(123.679, -1) FROM DUAL;
-- 123 / 123.67 / 120CEIL
SELECT CEIL(123.456), CEIL(123.678) FROM DUAL; -- 원하는 자리에서 올림 불가
-- 124 / 124(9) 날짜 관련 함수
9-1) SYSDATE 오늘 날짜
SELECT SYSDATE FROM DUAL;
9-2) MONTHS_BETWEEN 개월 수 사이
SELECT EMP_NAME, HIRE_DATE, MONTHS_BETWEEN(SYSDATE, HIRE_DATE)
FROM EMPLOYEE;SELECT EMP_NAME, HIRE_DATE, CEIL(MONTHS_BETWEEN(SYSDATE, HIRE_DATE)) || '개월차'
FROM EMPLOYEE;9-3) ADD_MONTHS 기준날짜에서 개월 더하기
SELECT ADD_MONTHS(SYSDATE, 2) , ADD_MONTHS(SYSDATE, 5) FROM DUAL;
-- 23/09/19 기준
23/11/19 , 24/02/199-4) NEXT_DAY 기준 날짜로 가장 가까운 요일
SELECT SYSDATE, NEXT_DAY(SYSDATE, '목요일') FROM DUAL;
SELECT NEXT_DAY (SYSDATE, '목'), NEXT_DAU(SYSDATE, 5) FROM DUAL;
--1 = 일, 2 = 월, 3 = 화, 4 = 수, 5 = 목, 6 = 금, 7 = 토
SELECT NEXT_DAY (SYSDATE, '화난다') FROM DUAL; -- 헛소리 써도 화요일로 인지...
SELECT NEXT_DAY (SYSDATE, '난화가야') FROM DUAL; -- 무조건 맨앞이 화가 나와야함
SELECT NEXT_DAY (SYSDATE, ' THURSDASY') FROM DUAL;
ALTER SESSION SET NLS_LANGUAGE = AMERICAN;
-- 영어로 변경
SELECT NEXT_DAY (SYSDATE, 'THURSDASY'), NEXT_DAY(SYSDATE, 'THU') FROM DUAL;
ALTER SESSION SET NLS_LANGUAGE = KOREAN;
-- 영어로 변경10) EXTRACT 데이터 추출
-- EMPLOYEE 테이블에서 사원의 이름, 입사 년, 입사 일 조회
SELECT EMP_NAME,
EXTRACT(YEAR FROM HIRE_DATE),
EXTRACT(MONTH FROM HIRE_DATE),
EXTRACT(DAY FROM HIRE_DATE)
FROM EMPLOYEE;11) 형변환 함수
11-1) TO_CHAR 숫자나 날짜 데이터를 문자로 형변환
정의
SELECT TO_CHAR(1234) , 1234 숫자데이터입니다 FROM DUAL; --숫자는 오른쪽 정렬, 문자는 왼쪽 정렬
SELECT TO_CHAR(1234, '99999') FROM DUAL; --다섯칸을 만들어 놓고 비어있는 칸은 9로 채워두겠다.
SELECT TO_CHAR(1234, '00000') FROM DUAL; --다섯칸을 만들어 놓고 비어있는 칸은 0으로 채워두겠다.
SELECT TO_CHAR(1234, 'L99999'), TO_CHAR(1234, 'FML99999') FROM DUAL; -- 설정 언어의 화폐 표기
SELECT TO_CHAR(1234, '$99999'), TO_CHAR(1234, 'FM$99999') FROM DUAL; --FM : 문자열의 공백 제거
SELECT TO_CHAR(1234, '99,999'), TO_CHAR(1234, 'FM99,999') FROM DUAL;
SELECT TO_CHAR(1234,'999') FROM DUAL; -- 자릿수가 넘어가면 --####EMPLOYEE 테이블에서 사원 명, 급여 조회(급여는 /9,000,000 형식으로 표시)
SELECT EMP_NAME, TO_CHAR (SALARY, 'L999,999,999')
FROM EMPLOYEE;시간 (숫자/날짜를 문자 형식으로)
SELECT TO_CHAR(SYSDATE, 'PM HH:MI:SS') , TO_CHAR(SYSDATE, 'AM HH24:MI:SS') FROM DUAL; -- 24 는 24시간을 표현하고 싶을 때
SELECT TO_CHAR(SYSDATE, 'MON DY,YYYY') , TO_CHAR(SYSDATE, 'YYYY-FMMM-DD')FROM DUAL; --0 지워주고 싶을 때
SELECT TO_CHAR(SYSDATE, 'YYYY'), TO_CHAR(SYSDATE, 'YY'), TO_CHAR (SYSDATE, 'YEAR')
FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'MM') , TO_CHAR(SYSDATE, 'MONTH'), TO_CHAR(SYSDATE, 'MON'), TO_CHAR(SYSDATE, 'RM') --RM 로마자
FROM DUAL;
SELECT TO_CHAR(SYSDATE, 'DDD'), TO_CHAR(SYSDATE, 'DD'), TO_CHAR(SYSDATE, 'D')
-- DDD올해 1년 기준으로 며칠 지났는지, DD한 달 기준으로 며칠이 지났는지, D 일주일 기준으로 며칠 지났는지
FROM DUAL;
SELECT TO_CHAR(SYSDATE,'Q'), TO_CHAR(SYSDATE, 'DAY'), TO_CHAR(SYSDATE, 'DY')
--Q 분기, DAY 요일 , DY 요일
FROM DUAL;
--EMPLOYEE 테이블에서 이름, 입사일 조회
SELECT EMP_NAME, TO_CHAR (HIRE_DATE, 'YYYY"년" MM"월" DD"일" (DY)') --형식 지정, 대신 "" 사용해주어야함
FROM EMPLOYEE;
11-2) TO_DATE 문자나 숫자를 날짜 형식으로 변환
SELECT TO_DATE('20230918', 'YYYYMMDD') FROM DUAL;
SELECT TO_DATE(20230918, 'YYYYMMDD') FROM DUAL;
SELECT TO_CHAR(TO_DATE('240124 175000', 'YYMMDD HH24MISS'), 'YY-MM-DD PM HH:MI:SS DY') FROM DUAL;
SELECT TO_CHAR(TO_DATE('980630','YYMMDD'), 'YYYYMMDD') YY98, --YY는 무조건 현재 세기(21세기)
-- 20980630
TO_CHAR(TO_DATE('140918', 'YYMMDD'), 'YYYYMMDD') YY14,
--20140918
TO_CHAR(TO_DATE('980630', 'RRMMDD'), 'YYYYMMDD') RR98, --RR은 50년도 이상이면 이 전 세기, 50년도 이하면 현재 세기
--19980630
TO_CHAR(TO_DATE('140918', 'RRMMDD'), 'YYYYMMDD') RR14
--20140918
FROM DUAL;요일 알고 싶을 때
-- 1. 2020년 12월 25일의 요일 조회
SELECT TO_CHAR(TO_DATE('201225','YYMMDD'),'DAY') -- DAY 혹은 DY
FROM DUAL;11-3) TO_NUMBER 문자만 숫자로 바꿔줌
SELECT '123' + '456' FROM DUAL;
-- 579
SELECT '123' + '234E' FROM DUAL;
-- 안됨
SELECT '2,000' + '3,000' FROM DUAL;
--안됨
SELECT TO_NUMBER('2,000' , '999,999') + TO_NUMBER('3,000', '9,999') FROM DUAL;
--500012) NVL("값", "지정값")
NVL : 값이 NULL인 경우 지정값을 출력하고, NULL이 아니면 원래 값을 그대로 출력
💡타입이 맞춰서 들어가야함 (BONUS, '없음') 불가 , BONUS가 숫자타입이기 때문에
-- 1.
SELECT EMP_NAME, BONUS, NVL(BONUS, 0) -- BONUS 내 NULL을 0으로 바꿔주겠다.)
FROM EMPLOYEE;
-- 2. EMPLOYEE 테이블에서 직원 명, 연봉, 보너스를 추가한 연봉 조회
SELECT EMP_NAME, SALARY12, (SALARY(1+NVL(BONUS, 0))) * 12
FROM EMPLOYEE;
--3.
SELECT EMP_NAME, DEPT_CODE, NVL(DEPT_CODE, '없습니다') -- ★DEPT_CODE가 문자타입이기 때문에 가능
FROM EMPLOYEE;13) 선택함수
13-1) DECODE (계산식 OR 컬럼명, 조건값1, 선택값, 조건값2, 선택값2, ...)
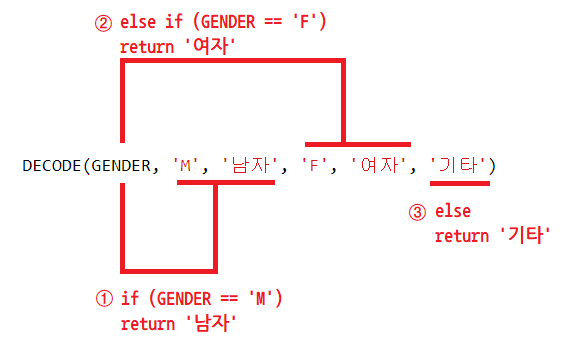
SELECT EMP_ID, EMP_NAME, EMP_NO,
DECODE(SUBSTR(EMP_NO, INSTR(EMP_NO, '-')+1, 1), 1, '남' , 2 , '여') 성별
FROM EMPLOYEE;
SELECT EMP_ID, EMP_NAME, EMP_NO,
DECODE(SUBSTR(EMP_NO, INSTR(EMP_NO, '-')+1, 1), 1, '남' , '여') 성별 -- 위와 같은 결과값
FROM EMPLOYEE;
SELECT EMP_NAME, JOB_CODE, SALARY,
DECODE(JOB_CODE, 'J7', SALARY1.1 ,
'J6', SALARY1.15 ,
'J5', SALARY1.2 ,
SALARY1.05) "인상된 급여"
FROM EMPLOYEE;
SELECT EMP_NAME, JOB_CODE, SALARY,
SALARY*(1 + DECODE(JOB_CODE, 'J7' , 0.1, 'J6', 0.15, 'J5', 0.2, 0.05)) "인상된 급여"
FROM EMPLOYEE;13-2) CASE WHEN
CASE WHEN 조건식 THEN 결과값
WHEN 조건식 THEN 결과값
ELSE 결과값
END
1) 새로운 열을 생성하는 경우
2) 열을 집계하는 경우 (집계함수와 함꼐 사용)
ex) SELECT 집계함수((DISTICT) CASE WHEN 기존 열 = 조건 THEN 집계 열(ELSE 값) END) AS 새로운 열
SELECT EMP_ID, EMP_NAME, EMP_NO,
CASE WHEN SUBSTR (EMP_NO, INSTR(EMP_NO, '-')+1, 1) = 1 THEN '남'
ELSE '여' -- 1 아니면 2니까 ELSE 써서 짧게 단축
END 성별
FROM EMPLOYEE;--범위 비교는 CASE WHEN 만 가능 DECODE는 불가
SELECT EMP_ID, EMP_NAME, SALARY,
CASE WHEN SALARY >= 5000000 THEN '고급'
WHEN SALARY >= 3000000 THEN '중급'
ELSE '초급'
END
FROM EMPLOYEE;
14) 그룹함수
14-1) SUM 합계
전체 사원 중 남자들 월급 합계
SELECT SUM (SALARY)
FROM EMPLOYEE
WHERE SUBSTR (EMP_NO, 8, 1) = 1; --남자들 월급 합계14-2) AVG 평균
SELECT AVG(SALARY) FROM EMPLOYEE; -- 전체 급여의 평균
SELECT AVG(BONUS) FROM EMPLOYEE; -- NULL을 제외한 평균
SELECT AVG(BONUS), AVG(NVL(BONUS, 0)) FROM EMPLOYEE; -- NULL을 포함한 평균14-3) MIN / MAX
SELECT MAX(EMP_NAME), MAX(SALARY), MAX(HIRE_DATE) FROM EMPLOYEE;
SELECT MIN(EMP_NAME), MIN(SALARY), MIN(HIRE_DATE) FROM EMPLOYEE;14-4) COUNT 개수
-- 총 행의 개수, 컬럼 개수(NULL은 카운팅 제외)
SELECT COUNT(*), COUNT(DEPT_CODE)
FROM EMPLOYEE;
나의 코딩 다이어리🖥️👾✨