서론
Spring Batch를 실행시키려면 Spring Batch Job과 스케쥴러, 그리고 파이프라인과 모니터링 등이 필요하다.
기존에는 Spring Batch Admin과 Jenkins를 이용해 구현했지만 배치 어드민은 2017년 12월 31일자로 서비스를 종료하여 deprecated 되었다.
그 후에 Spring은 대체제로 Spring Cloud Data Flow의 사용을 권고하고 있다.
스케쥴러는 Cloud Foundry 및 Kubernetes에서만 제공되고 있으므로 스케쥴러 테스트를 위해 Kubernetes 위에 Spring Cloud Data Flow를 설치하였다.
Spring Cloud Data Flow
Spring Cloud Data Flow 는 Cloud Foundry 및 Kubernetes에서 스트리밍 및 일괄 데이터 처리 파이프라인을 구축하기 위한 마이크로서비스 기반 툴킷
Spring Cloud Data Flow 설치
기본적으로 Spring Cloud Data Flow는 Local, Cloud Foundry, Kubernetes 설치 방법을 제공하고 있으며 공식 document에 설치 방법이 자세하게 적혀있다.
Kubernetes 설치 시 로컬에서는 minikube를 설치하는 방법도 있었지만 직접 Master 1대, Worker 1대의 클러스터를 구성을 하였으며
서버의 리소스 부족한 경우 grafana, prometeus 등은 설치하지 않아도 무방하다.
또한 Spring Batch 연동을 위해 Spring Cloud Data Flow의 Task 기능만 활용할 예정이므로 Kafka 혹은 RabbitMQ는 설치하지 않아도 될 것 같다.
결론! Data Flow Server, Skipper, MySQL(없으면 h2 실행)은 필수로 설치가 필요한 pod 이므로 꼭 설치하자.
설치 방법은 아래 URL을 참고한다.
내부 테스트 서버에는 별도의 Kubernetes 용 로드밸런서가 설정되어 있지 않아 외부 접속을 위해 강제로 externalIps를 지정해주었다.
또한 Spring Cloud Data Flow를 실행할 때 ServiceAccount를 지정하지 않으면 권한 에러가 발생하니 꼭꼭 설정하길 바란다. 아마 가이드대로 설치했다면 정상적으로 적용되어 있을 것이다.
[root@k8s-master server]# cat /root/spring-cloud-dataflow/src/kubernetes/server/server-svc.yaml
kind: Service
apiVersion: v1
metadata:
name: scdf-server
labels:
app: scdf-server
spring-deployment-id: scdf
spec:
# If you are running k8s on a local dev box or using minikube, you can use type NodePort instead
type: LoadBalancer
ports:
- port: 80
name: scdf-server
selector:
app: scdf-server
** externalIPs:
- IP 입력**
설치가 완료되었다면 kubectl get all을 입력해 쿠버네티스 정보를 확인한다.
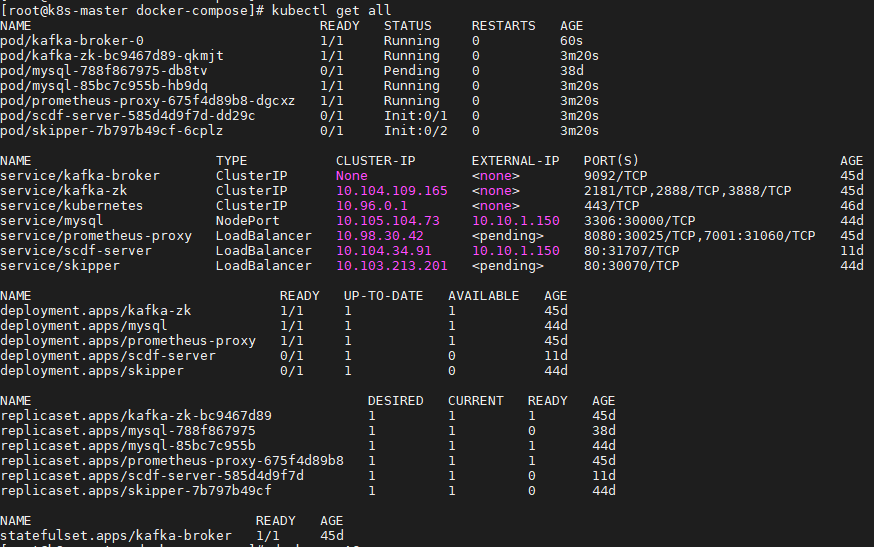
http://IP:PORT/dashboard 로 접속해본다.
위 화면이 나온다면 설치 성공!
쿠버네티스의 configMap 기능을 이용하여 스프링 데이터 플로우의 application.yml 파일을 수정할 수 있다.
prometeus의 proxy 정보, grafana url 정보, DB 접근 정보 등을 변경하고 싶다면 아래 파일을 수정한다.
[root@k8s-master server]# cat /root/spring-cloud-dataflow/src/kubernetes/server/server-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: scdf-server
labels:
app: scdf-server
data:
application.yaml: |-
management:
metrics:
export:
prometheus:
enabled: true
rsocket:
enabled: true
host: prometheus-proxy
port: 7001
spring:
cloud:
dataflow:
container:
registry-configurations:
default:
registry-host:
metrics.dashboard:
url:
task:
platform:
kubernetes:
accounts:
default:
deploymentServiceAccountName: scdf-sa
imagePullPolicy: Always
limits:
memory: 1024Mi
datasource:
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/mysql
username: root
password: ${mysql-root-password}
driverClassName: org.mariadb.jdbc.Driver
testOnBorrow: true
validationQuery: "SELECT 1"
한가지 조심할 점은 configMap을 수정하면 pod을 재시작해주어야 하는데 쿠버네티스에는 재시작의 개념이 없어 rolling restart를 진행해주면 된다.
더 많은 property 정보는 아래 URL을 참고한다.
Remote Partition 소스 작성
먼저 Kubernetes로 Spring Cloud Data Flow를 설치하면 당연하겠지만 Docker Image를 사용하여야 한다.
Spring Cloud Data Flow의 Task 등록
위 사이트에서 Kubernetes로 설치 시 Docker Image로 Task 등록 방법을 소개하고 있으며, 테스트를 위한 Spring Batch Task 예제 소스가 있으니 해당 소스로 Docker Image를 생성해 테스트해도 좋을 것 같다.
나는 Remote Partition 테스트를 위해 아래 URL을 참고하였다.
이제 Spring Batch의 Partition 기능을 Kubernetes를 이용해 원격으로 실행시키는 것을 테스트 할 것이다.
작성한 소스를 DockerFile을 이용해 도커 이미지를 생성한다.
[root@k8s-master partition]# cat Dockerfile
FROM openjdk:17-alpine
VOLUME /tmp
EXPOSE 8090
ARG JAR_FILE=target/*.jar
ADD ${JAR_FILE} partition.jar
ENTRYPOINT ["java","-jar","/partition.jar"]이제 Docker Image를 만들어보자.
docker build -t {NEXUS IP:PORT}/partition .Docker를 Private Registry인 Nexus에 Push 한다.
docker push {NEXUS IP:PORT}/partition아래처럼 Push 되었다면 성공!
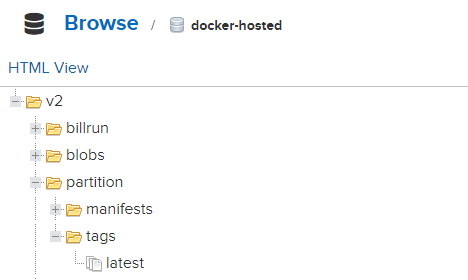
기본적으로 Spring Cloud Data Flow는 공식 Docker Hub를 통해 이미지를 Push/Pull 하는 것이 테스트하기에 더 좋다고 생각하니 앵간하면 Nexus가 아닌 Docker Hub를 이용하자.
Spring Batch Task 등록 및 실행
이제 Batch Application을 Task로 등록해보자
Spring Cloud Data Flow의 Dashboard에서 Application -> Register one or more applications를 클릭한다.
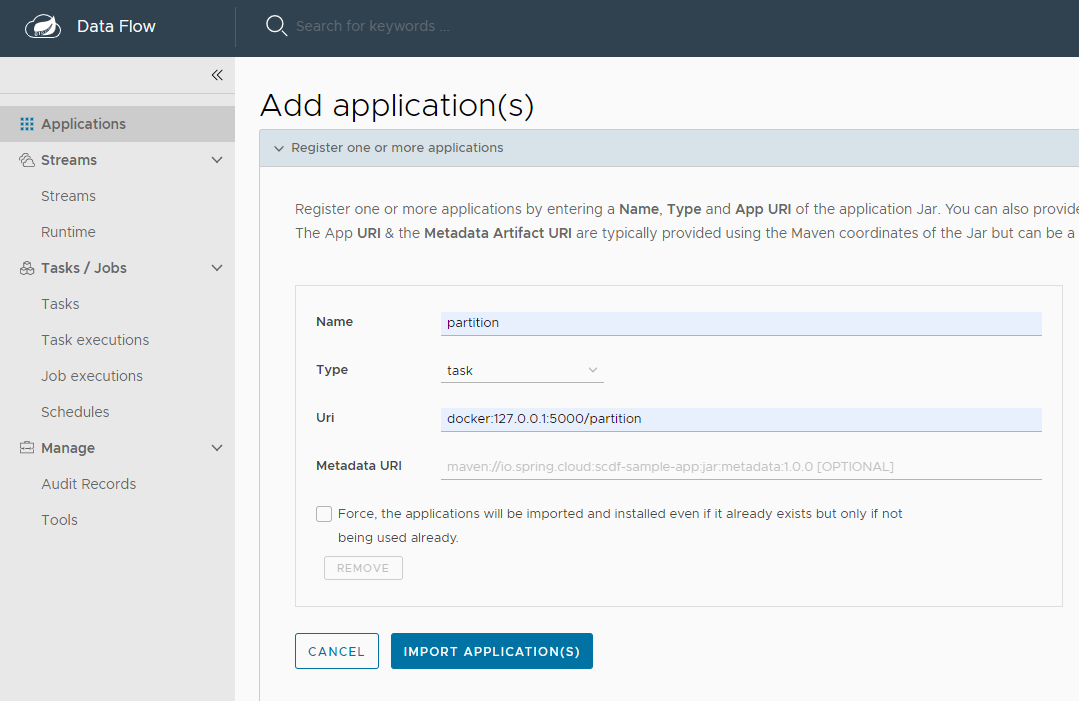
이제 Task을 생성해본다. Tasks -> CREATE TASK를 클릭한다.
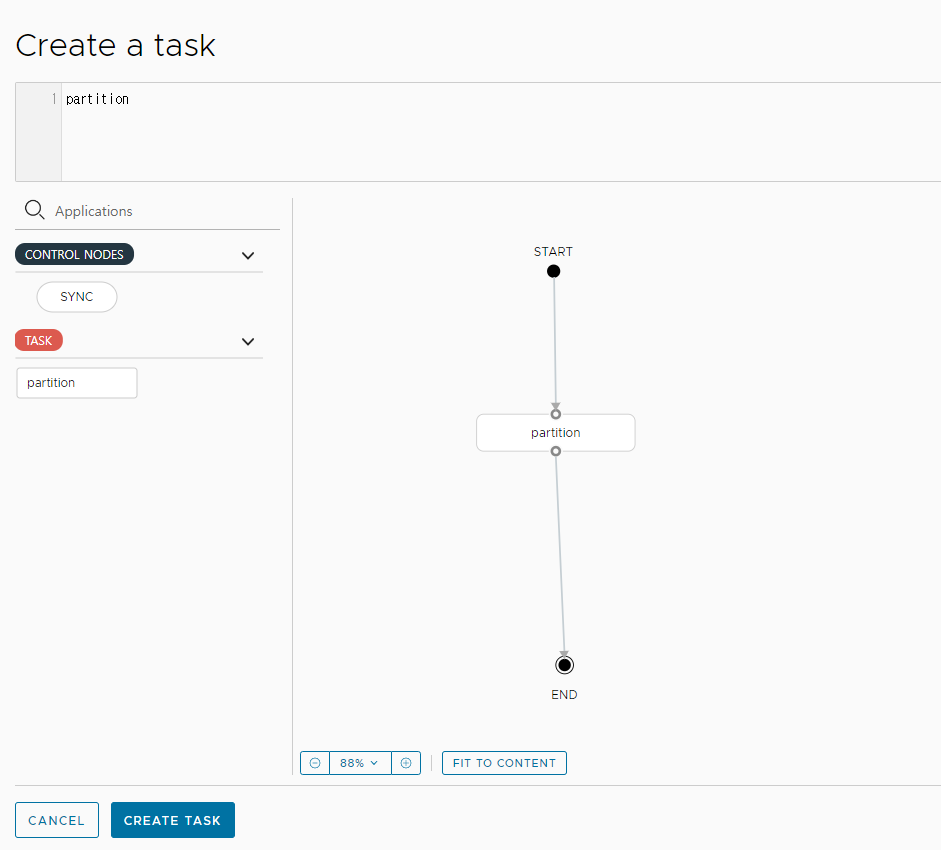
생성된 Task 목록의 왼쪽의 ...(세로)를 클릭해 목록 중 Launch를 선택한다.
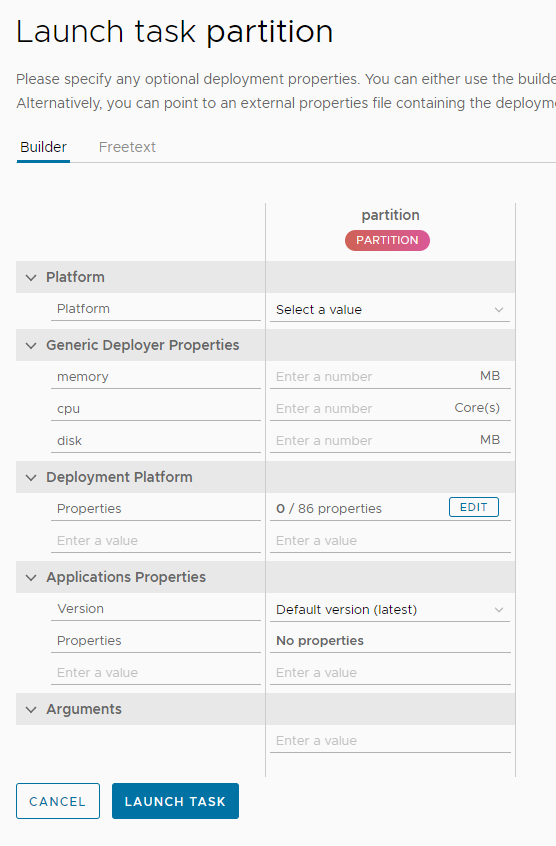
LAUNCH TASK를 클릭하면 Kubernets의 Master 노드는 Task를 실행할 Worker 노드를 지정할것이며 Worker 노드는 Application에 등록한 Docker 경로에 따라 Nexus에서 도커 이미지를 Pull해서 Task를 실행할 것이다.
Remote Partition을 이용한 Task를 생성하였기 때문에 Master가 설정한 파티션 갯수만큼 Slave를 생성하였을 것이다. Kubernetes 정보를 확인해보자.

pod/partition-x7oe3g1w99 은 Batch Master이며
pod/partitionedbatchjobtask-v0wmqzwod8 은 Master에 의해 생성된 Slave이다.
모두 배치가 정상적으로 실행된 후 completed로 종료된 것을 확인할 수 있다.
(서버 리소스 부족으로 Slave 생성 갯수를 1개로 제한하였다.)

Status도 Unknown -> Running -> Complete로 변경된 것을 확인할 수 있다.
문제점
Private Registry SSL 설정 문제
기본적으로 Kubernetes는 Docker Image의 Pull 시 https를 사용한다.
테스트를 위해 SSL이 설치되지 않은 Nexus를 사용했으며 http로 요청할 수 있도록 insecure-registries를 등록하였다.
[root@k8s-master partition]# cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"insecure-registries" : [
"10.10.1.150:5000",
"10.10.1.150:5001"
],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}그러나 문제점은 서버에서 직접 Docker 명령어로 push 및 pull 시 http로 요청이 가능했지만 스프링 데이터 플로우에서는 자꾸만 https로 요청하는 것이었다 (ㅠㅠ)
Nexus가 아닌 Privite Registry를 설치해서 사설 인증서도 설치해봤지만 Fail...
따라서 일단은 테스트를 위해 https 요청이 accept 되도록 127.0.0.1 요청으로 변경하여 테스트를 진행했다.
이 부분은 조금 더 확인해봐야할 문제이다...
Completed 상태인 Pod은 종료되지 않는걸까?
Remote Partition 실행이 되고 완료된 Pod 들은 시간이 지나도 remove 되지 않고 남아있었다.
지금은 테스트라 문제없지만 운영에서 종료된 Completed를 삭제시키는 방법을 생각해봐야할 것 같다.
결론
Spring Cloud Data Flow는 UI가 직관적이여 사용하기 편리하다는 느낌을 받았다.
또한 스케쥴러도 기존 Cron 방식을 사용하기 때문에 사용 방식이 어렵지 않았다.
Task만 테스트를 진행해봤지만 Spring Cloud Data Flow의 핵심 기능은 Streams가 아닐까 한다. (나중에 이 부분은 꼭 테스트 해보고 싶다!)
다만 아직 Reference가 부족해 문제가 발생하였을 경우 해결해나가는 방법이 순탄하지는 않았다.
또한 공식적으로 Oracle Database를 지원하지 않아 운영에서 Oracle을 사용한다면 Oracle Driver를 포함하여 Rebuild 및 MySQL, MariaDB 등의 Database 변경이 필요할 것 같다.
다음은 Spring Batch Remote Partition을 Kafka와 연계하여 테스트하는 방법을 진행해볼 예정이다.
