[Article Summary] Xu et al., 2018, A Skeleton-Based Model for Promoting Coherence Among Sentences in Narrative Story Generation
0
Story Generation Articles
목록 보기
1/2
Jingjing Xu, Xuancheng Ren, Yi Zhang, Qi Zeng, Xiaoyan Cai, and Xu Sun. 2018. A Skeleton-Based Model for Promoting Coherence Among Sentences in Narrative Story Generation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4306–4315, Brussels, Belgium. Association for Computational Linguistics.
Introduction
- Most of the SOTA approaches are based on Seq2Seq models
- But it is hard for these models to find semantic dependency among sentences
- The connection is mainly reflected through key phrases
- Skeleton — the phrases to express the key meanings of a sentence
- Other words like modifiers redundant and make the dependency sparse
- Human writing is also first made from a skeleton and then reorganized into a fluent sentence
- The skeleton helps machines learn the dependency of sentences
- It avoids the interference of irrelevant information
- Model: a skeleton-based generative module + a skeleton extraction module
- The generative module
- Input-to-skeleton component — associates inputs and skeletons
- Skeleton-to-sentence component — expands a skeleton to a sentence
- The skeleton extraction module
- Generates sentence skeletons
- Automatically explores sentence skeletons (it is hard to establish rules to extract skeletons)
- A reinforcement learning method to build the connection between the skeleton extraction module and the generative module
Related work
- For simplification, many existing story generation models rely on given materials (do not generate from scratch)
- But this paper works on the complete story generation task
- Seq2Seq is widely used for the task but is weak on generating inter-related sentences (for coherence)
- Because of this, there are some models to build the mid-level sentence semantic representation to simplify the dependency among sentences
- But the unified rules these models use are non-flexible and tend to generate over-simplified representations
- So the paper uses a reinforcement learning method to automatically extract sentence skeletons for simplifying the dependency of sentences
Skeleton-based model
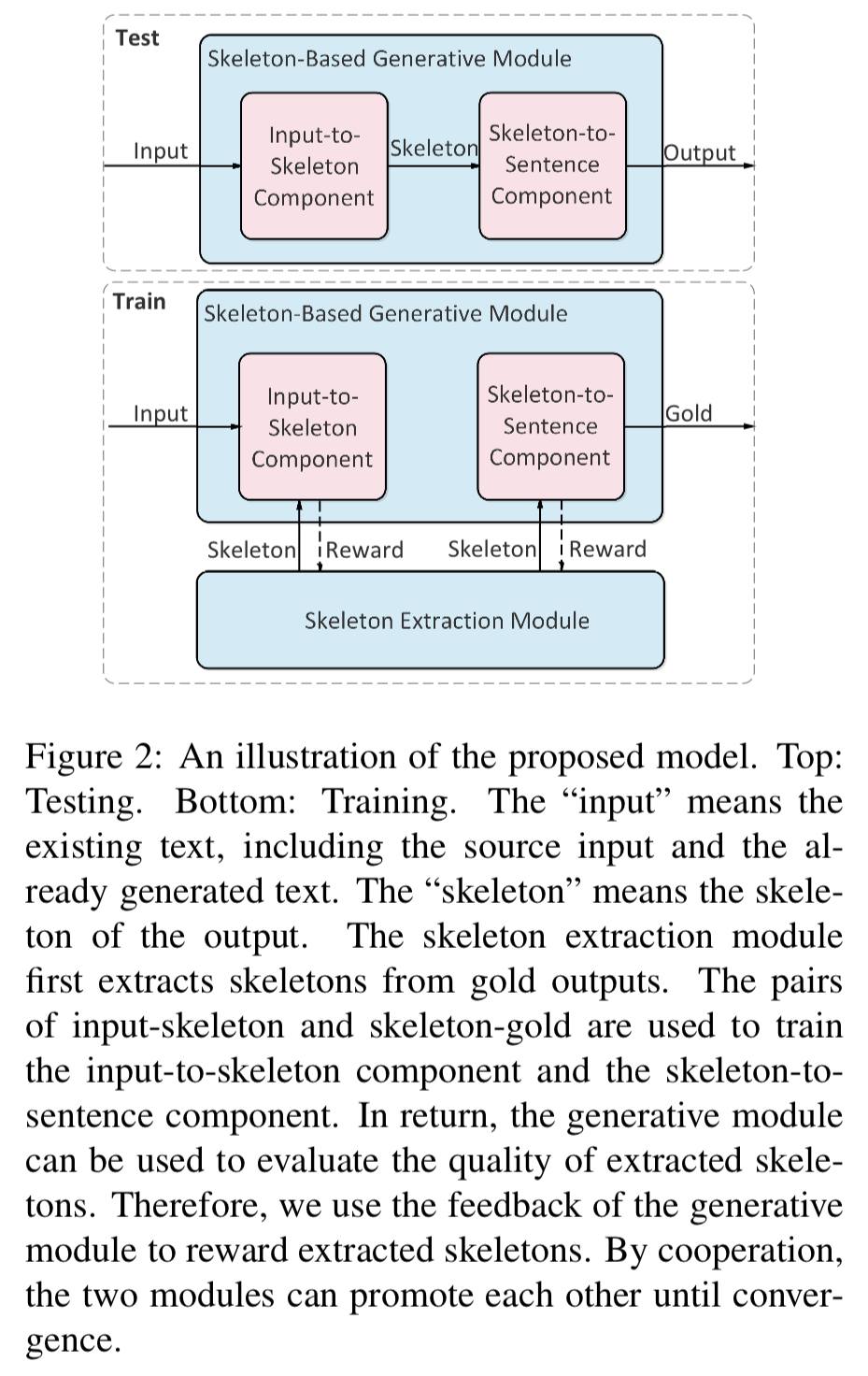
- : a skeleton-based generative module
- Generates a story sentence by sentence
- Input-to-skeleton component — generates a story based on the existing text
- Skeleton-to-sentence component
- : a skeleton extraction module
- A weakly supervised method for the initial extraction ability
- Training process
- Use extracted skeletons to train the generative module
- The output from the generative module is used to evaluate the extracted skeletons, refining the skeleton extraction module
Skeleton-based generative module
Input-to-skeleton component
- Seq2Seq structure
- A hierarchical encoder (Li et al., 2015) and an attention-based decoder (Bahdanau et al., 2014)
- Encoding
- Obtain sentence representations via a word-level LSTM network
- Generate a compressed vector , which then goes through the decoder to generate a skeleton
- input , skeleton (extracted by the skeleton extraction module)
- : parameters of the input-to-skeleton component
Skeleton-to-sentence component
- Seq2Seq structure
- Both the encoder and the decoder being one-layer LSTM networks with the attention mechanism
- Input: skeleton , target sentence
- : parameters of the skeleton-to-sentence component
Skeleton extraction module
- Seq2Seq model with the attention mechanism
- Both the encoder and the decoder are based on LSTM structures
- Initialized with a weakly supervised method
- Skeleton extraction formulated as a sentence compression problem
- But the style of the sentenc compression dataset and that of the narrative story dataset are very different → noise occurs
- Input: original text , the compressed version
- : parameters of the skeleton extraction module
Reinforcement learning method

- To build a connection between the skeleton extraction module and the skeleton-based generative module
- Use policy gradient (Sutton et al., 1999) for training
- Calculate a reward on the feedback of the generative module
- Optimize the parameters through policy gradient
- The expected reward maximized
- Trains the skeleton extraction module
- : the original sentence
- : the skeleton generated by a sampling mechanism
Reward
- Define what is a good skeleton
- That contain all key information and ignore other information
- Bad skeletons contain too much detailed information and lack necessary information
- Good skeletons, incomplete skeletons, redundant skeletons
- : the upper bound of the reward
- and : cross entropy losses in the input-to-skeleton component and the skeleton-to-sentence component
Experiment
Dataset
- Visual storytelling dataset (Huang et al., 2016)
- Use only the text data
- Data split into two parts
- First sentence as the input text
- Following sentences as the target text
- Sentence compression dataset (Filippova and Altun, 2013)
- For pre-training the skeleton extraction module
Baselines
- Clark et al., 2018: Entity-Enhanced Seq2Seq Model
- Cao et al., 2018: Dependency-Tree Enhanced Seq2Seq Model
- Martin et al., 2018: Generalized-Template Enhanced Seq2Seq Model
Metrics
Automatic evaluation
- BLEU
- To compare the similarity between the output by the machine and the references by human
- All stop words removed for precise results
Human evaluation
- 100 items for evaluation randomly chosen
- Fluency (correct in grammar)
- Coherence
Results
- BLEU: best
- Fluency: second to GE-Seq2Seq model
- Generalized templates help achieve higher fluency, sacrificing the expressive power
- In fact, the proposed model produces much more unique phrases than the GE-Seq2Seq
- Coherence: best
- GE-Seq2Seq performs worst
Incremental analysis
- The skeleton extraction module is effective in leaving only the essential information
BLEU
- With only the Seq2Seq model → lowest
- + skeleton extraction module → slightly improved
- + reinforcement learning → outperforms Seq2Seq by 40%
Human evaluation
- + skeleton extraction module → lower than Seq2Seq
- The dataset for training the module is different from the narrative story datast
- + reinforcement learning → outperforms Seq2Seq by 14%
Error analysis
- Dimensions in coherence
- Scene-specific relevance
- Temporal connection
- Non-recurrence
- When the input is short and the model is familiar with the input → better coherence
- But extracting the key semantics reduces the decrease in coherence
