통계공부
분산
: 데이터가 평균을 중심으로 얼마나 흩어져 있는지를 표현하는 개념
각 값과 평균 사이의 거리를 제곱한 후 합산한 값 / 데이터 개수
: 분산은 제곱된 단위다 보니 해석하기 어려운 면이 있어서 제곱근을 씌운 표준 편차를 사용
표준 편차, Standard Deviation
: 분산의 제곱 근
평균, 표준 편차
표본의 평균 : 모집단의 평균을 추정
표준 편차 : 추정의 정확성을 판단
모수와 통계량
추론 통계 : 표본의 특성을 바탕으로 모집단의 특성을 추론하는 과정
모수, Parameter
: 모집단의 특성을 나타내는 수치
통계량, Statistic
: 표본의 특성을 나타내는 수치
추론 통계
: 표본의 통계량으로 모수를 추정하는 과정
모평균 : 모집단의 평균
표본평균 : 표본의 평균
표본을 통한 모집단의 추정
- 모집단에서 표본을 추춣해 표본의 값을 관찰한다
- 관찰된 결과가 특정 모집단 아래에서 어느 정도의 확률로 나타날 수 있는지 생각한다.
- 데이터의 배후에 있는 모집단에 대해 추정한다
" 불확실성을 인정하고 가장 확률이 높은 쪽으로 추정하는 사고방식 "
확률 변수, Random Variable
: 특정 상황에서 발생할 수 있는 결과를 숫자로 표현하는 규칙
ex) 동전 던지기의 경우 앞면을 1, 뒷면을 0으로 표현하면 그게 확률변수가 됨.
이산확률변수, Discrete Random Variable
: 동전던지기, 주사위 던지기 처럼 값이 딱딱 떨어지는 경우
연속확률변수, Continous Random Variable
: 사람의 키처럼 연속적인 경우
정규분포, Normal Distribution(보통의 분포)
(가우스 분포, Gaussian Distribution)
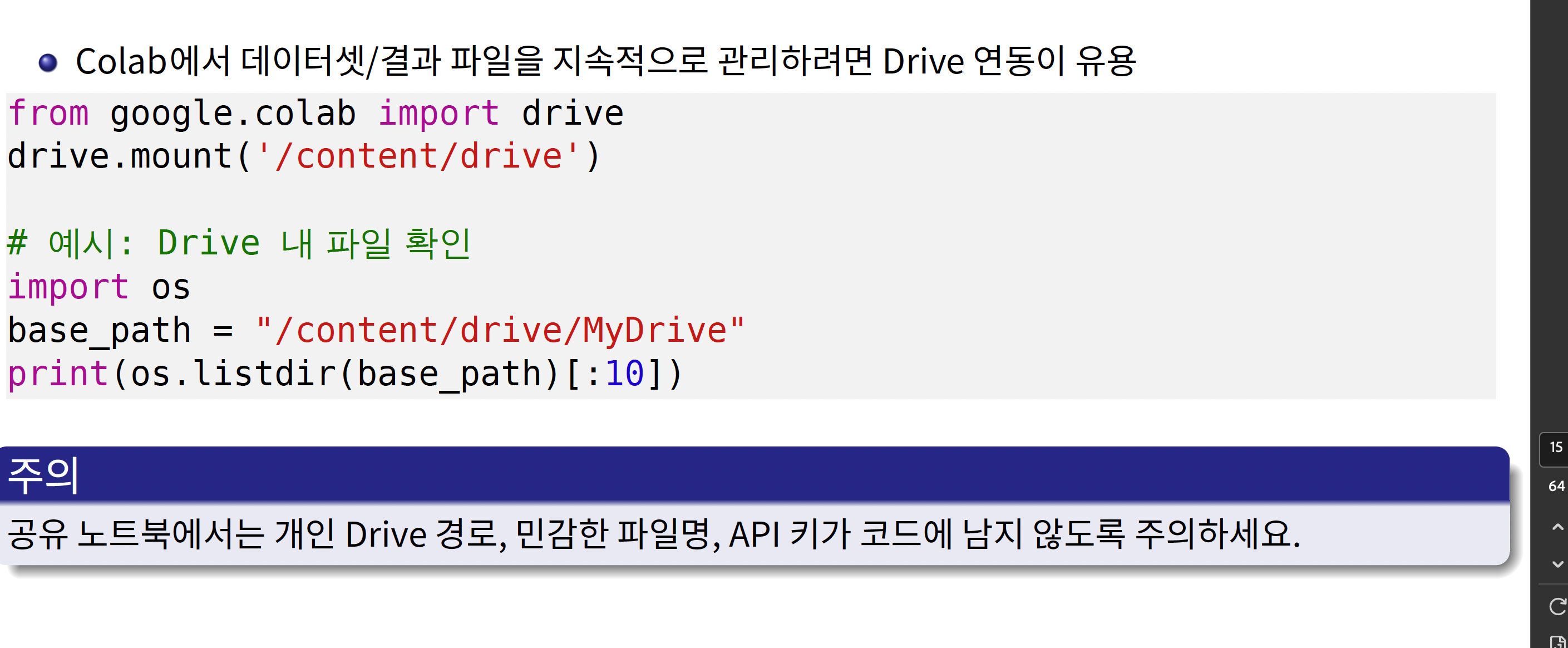
중심극한정리, CLT, Central Limit Theorem
: 모집단의 분포와 관계없이, 이 모집단에서 추출된 표본의 크기가 충분히 크다면 반복적으로 추출된 표본평균의 분포는 정규분포에 가까워진다.
표본의 크기
: 표본에 포함된 data의 수
보통 30개 이상이면 충분히 크다고 판단
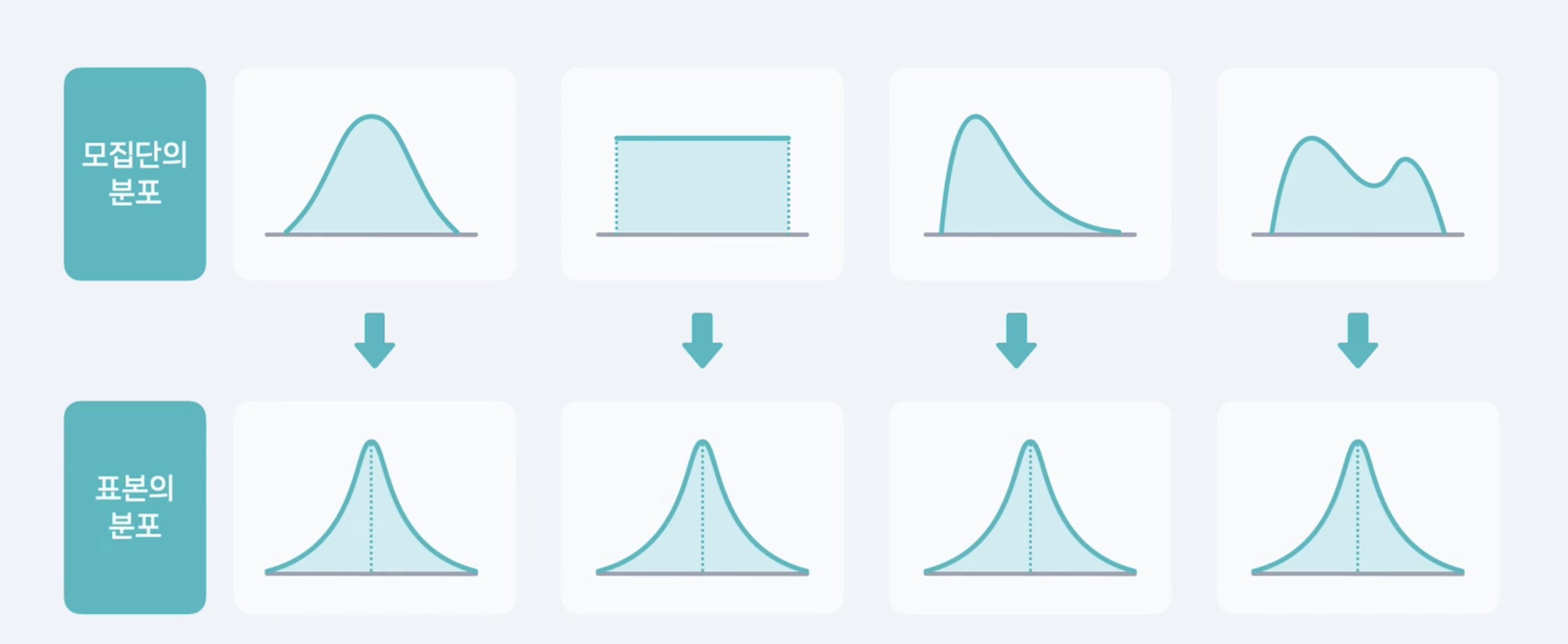
표본이 충분히 크다면 그 표본 자체의 분포가 정규분포에 가까워진다는 뜻이 아님.
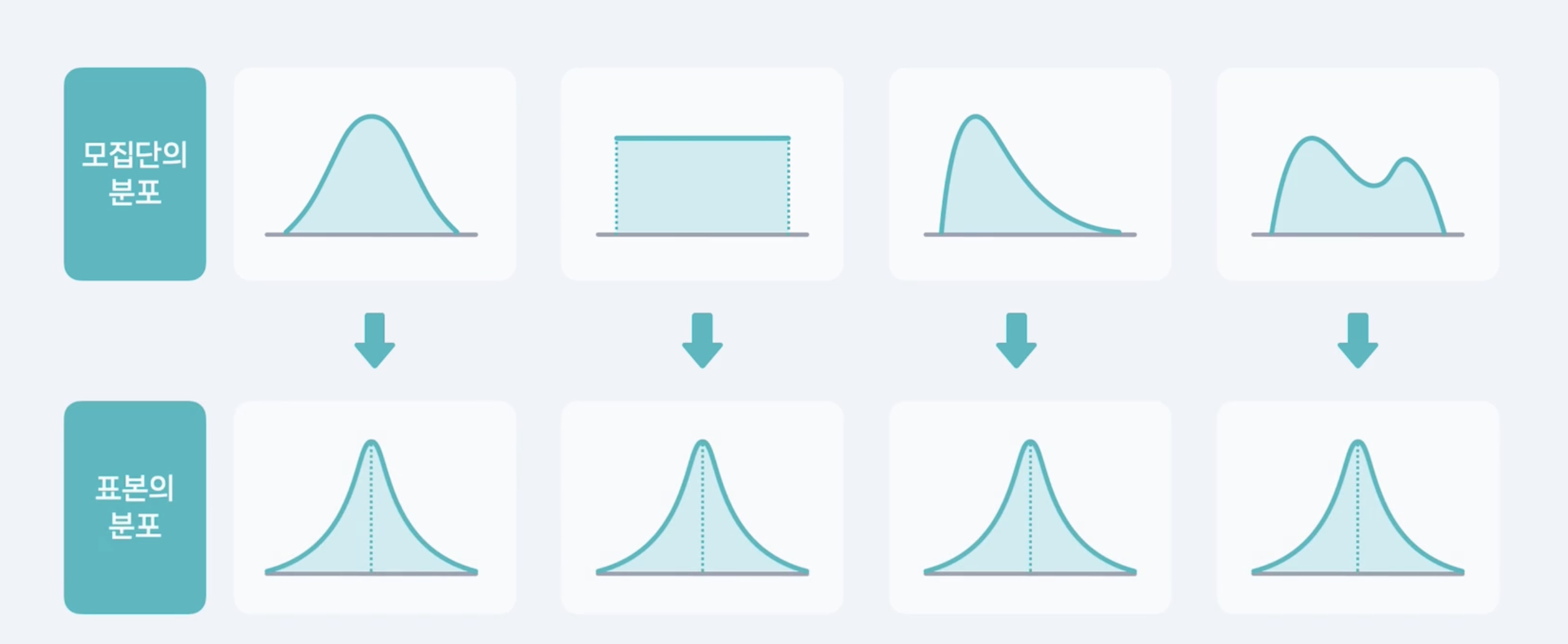
모집단에서 표본을 여러 번 뽑으면 각 표본마다 평균이 다를 텐데
그 표본평균들의 분포가 정규분포를 따른다는 얘기임.
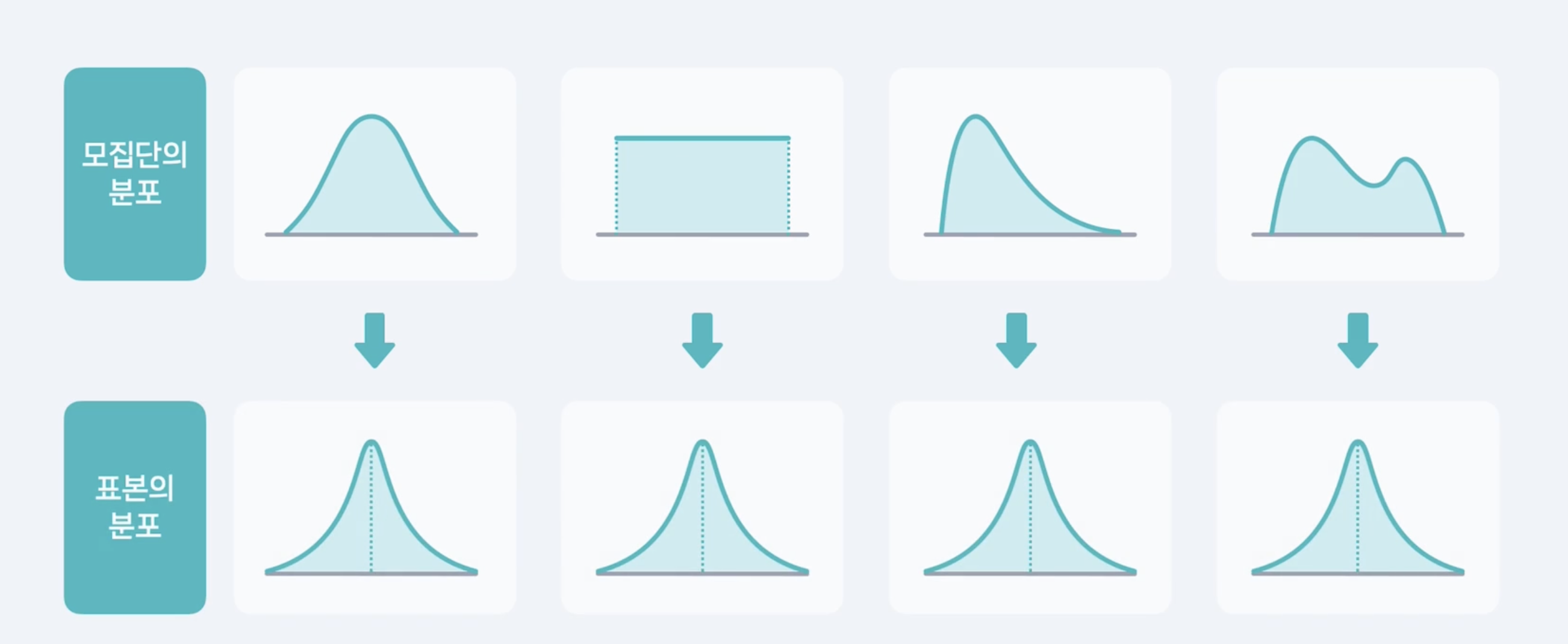
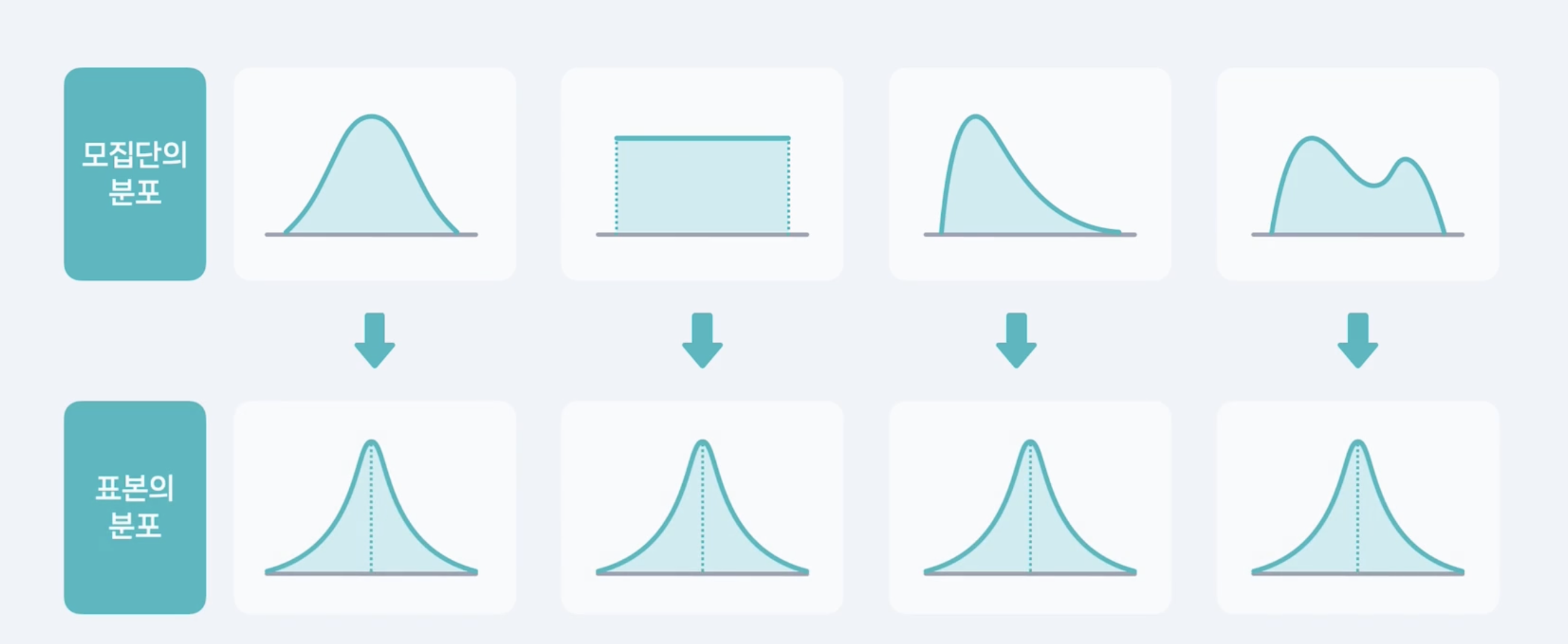
- 표본의 크기가 커질수록 수집된 표본의 평균이
- 중심극한정리에 의해 모평균 u에 가까워 진다는 것임.
-> 이 개념이 바로 추론 통계의 핵심 원리.
중심극한정리
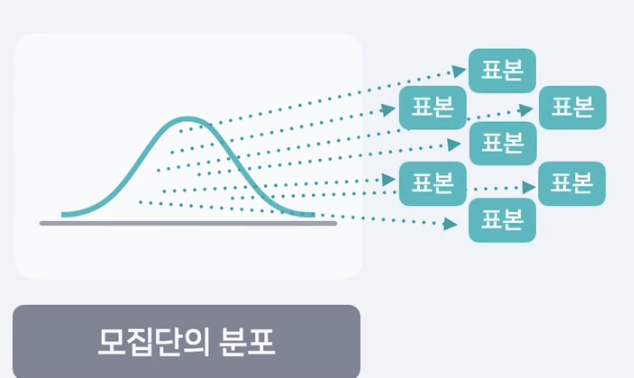
- 모집단에서 표본을 여러 번 뽑고
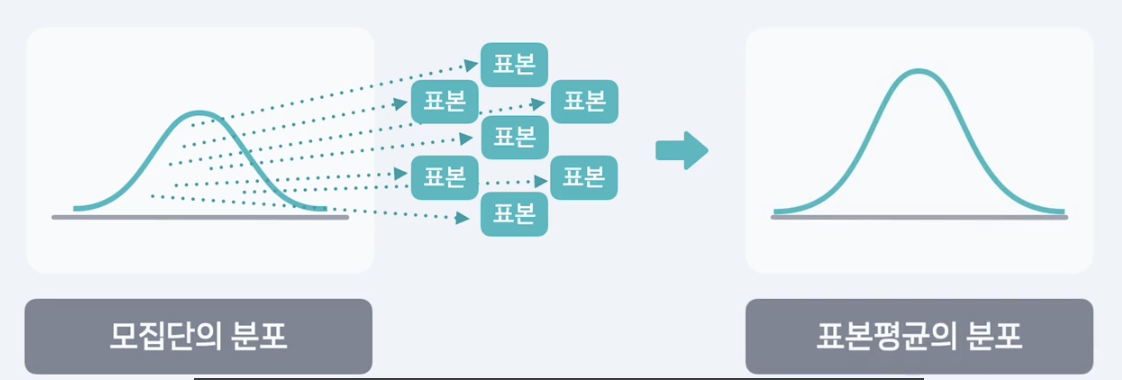
- 그 표본들의 평균을 모으면 평균이 모평균 u이고
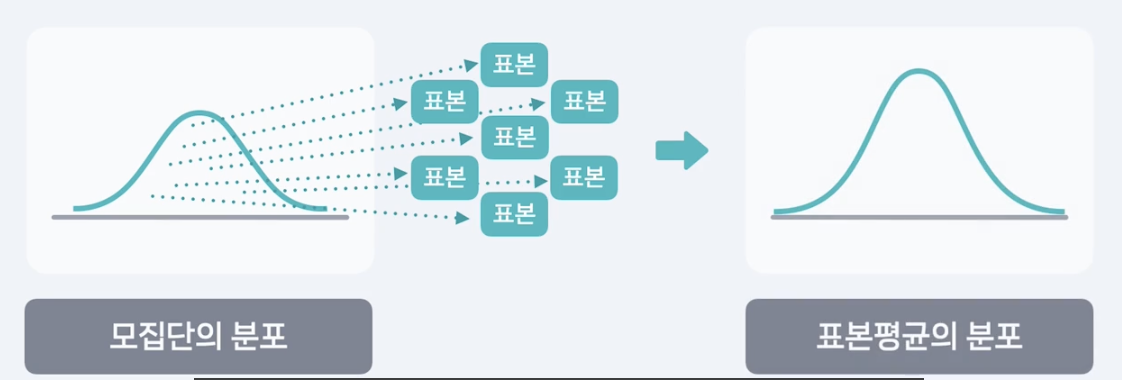
3. 표준편차가 시그마/루트n 인 정규분포에 가까워짐.
-> 통계학에서는 표본평균의 표준편차를 부르는 용어가 '표준오차'
표준오차, Standard Error
: 표본평균이 모평균에서 얼마나 떨어져 있는지 간접적으로 보여주는 지표
-> 표본평균의 표준편차니까, 특정 표본의 평균이 모평균에서 얼마나 떠ㅓㄹ어져 있는지를 간접적으로 보여 주는 지표가 됨.
그럼 표본을 하나 뽑았을 ㄹ때 표본평균과 표준 오차를 알면 모평균이 어디쯤 있는지 추정할 수 있음
(문제가 있음)

중심극한정리에서 봤듯 이론적으로 평균의 표준오차는 시그마/루트n 으로 계산됨
But, 모집단은 우리가 모르기 때문에 알고 싶은 대상임.
그래서 보통은 모집단의 표준편차인 시그마 대신,

표본의 표준편차인 s를 사용해서 추정함

표본의 크기가 클수록,
표준편차가 작을수록
표준오차가 작아짐
표준오차가 작다는 건
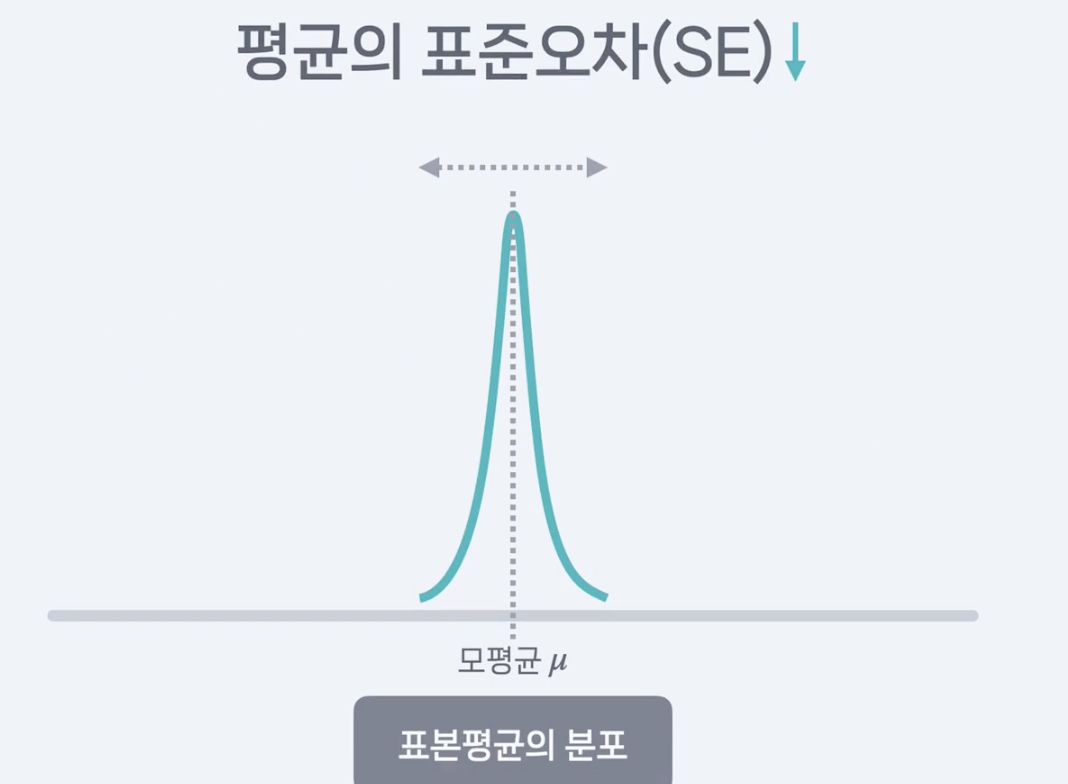
표본평균이 모평균에 가까이 있을 확률이 높다는 뜻.
? 구체적으로 표본평균이 모평균과 얼마나 가까이 있는지는 어떻게 표현가능한가? -> '신뢰구간' 개념을 배워야함
신뢰구간, Confidence Interval
: 모집단의 값이 포함될 것으로 예상되는 구간을 뜻함
보통 '몇 % 신뢰구간'이라고 이야기함
95% 신뢰구간
: 이 방식으로 구간을 여러 번 구할 때, 그 구간이 모집단의 값을 포함할 확률이 95%이다
평균에 대한 85% 신뢰구간
