Filter에 관한 URI
내가 클라이언트에서 API를 호출할 때도 Filter, Sort, Pagination 설정은 항상 관리를 했었는데 막상 짜려니 어떤게 좋은 패턴이었고 편했는지 기억이 가물가물하다.
우선 과제의 요구사항인 작성자 필터링을 고민해봤는데 일단 작성자 이름 필터링은 효율적인가부터 고민하기로 했다.
현재 작성자 이름(닉네임)은 Unique가 아니긴 하지만 Unique를 걸 예정이고 인덱스는 걸지 않을 거라서 굳이 작성자 이름을 필터 Param으로 받는 건 좋지 않다. 그렇다고 userId를 받아도 되는 지는 한 번 더 고민을 해야했다. userId가 Param에 노출되는 건 괜찮은지 우려가 됐기 때문이다.
이 점에 대해 여러번 찾아봤는데 userId 자체가 노출되는 건 보안적인 부분을 잘 체크하면 써도 괜찮은 패턴이라고 해서 아직 인증/인가 처리는 없지만 나중에 로직으로 잘 처리를 진행하기로 하고 쓰기로 했다.
그리고 두 번째는 여러 이용자의 필터링 여부인데 여러 param 값을 처리하는 것도 그냥 List로 떼우면 가능해서 꽤 지원이 잘 되어있고 이 배열을 쓰는 Repository 작성도 쉬워서 여러 개의 user id 값을 받아 처리하기로 했다. 클라이언트가 쓸 때도 userId는 필수로 들고 있을 거고 param에는 그대로 넘겨주기만 하면 되니 Rest API 디자인적으로도 괜찮은 것 같다.
추가로 몰랐는데 uri 디자인에 snake case를 적용할 때는 _가 아니라 -를 쓰고 Param은 URI와 구분하기 위해 camelCase를 권장한다는 문서를 봤다. 내가 쓸 때는 그냥 snake case로 통일이었던 것 같은데 신기했다.
Sort의 확장과 분리
정렬을 추가하긴 했었는데 정렬을 다루는 방법은 좀 확실히 하지 못한 점이 있어 이참에 정리를 해보기로 했다.
기존에는 JpaRepository 에서 OrderBy~~를 구현한 내용과 Spring의 Sort 객체를 이용한 방법 두 가지가 다 있었는데 일반적으로 선호되는 방식으로 통일하기로 했다.
그 중에서 나는 확장성을 고려해서 Sort 객체를 적극 활용하기로 했다. Repository에 정의하는 방식은 추가적인 객체를 요구하지 않고 명확한 메소드명을 지니고 있어 사용성에 있어서는 뛰어나지만 확장과 분리에 있어서 Sort 객체를 이용하면 이용이 쉽고 Repository의 매개변수로 넣어두면 알아서 Order by 처리도 되기 때문에 이용하게 됐다.
특히 Service 로직에서 sort를 구분해 Repository를 다르게 사용하는 것은 관심사의 분리에도 어긋난다고 생각이 들었다. Service는 최대한 비즈니스 로직 구현에만 집중하고 싶은데 단순한 정렬을 when 으로 구분해서 Repository의 호출을 달리 하는 것은 너무나도 쓸모없는 부분으로 여겨졌다.
그렇기에 query 패키지에 작성한 Sort enum class에 확장 함수로 convertToSort 를 만들었고 이를 Controller 에서 변환해 Service에 Sort 객체로 넘겨주는 방식을 선택했다. 이렇게 하니 실제로 클라이언트의 요청을 받은 Controller가 자신의 책임을 다 하고 Service가 비즈니스 로직에만 신경 쓸 수 있는 구조가 마련돼서 나름 마음에 들었다.
이것보다 더 좋은 방식은 아마 있을 거라 생각은 하는데 낮은 구현 비용에서는 제일 간단한 방법을 잘 고른 것 같다.
@ManyToOne 단방향 맵핑의 N+1 Query
N+1 Query에 대해 조사해보는 것도 과제에 있어서 한 번 조사해봤는데 나는 순환참조 비슷한 느낌인줄 알고 단방향 ManyToOne 구조라 상관없지않나? 하고 알아보니 좀 다른 점이 있었다.
N+1 쿼리의 문제는 하나의 주 엔티티를 조회할 때 연관된 엔티티를 별도의 쿼리로 조회하는 문제라 N+1 쿼리라 부른다. 즉 하나의 쿼리가 아닌 별도의 쿼리가 생성되어 관리되면 문제가 있는 것이다.
내가 진행중인 과제에서 Entity 관계에 따라 발생하려면 Comment에 들어있는 Todo를 이용할 때 발생할 수 있다.
물론 FetchType.EAGER가 아닌 FetchType.LAZY를 쓰고 있어서 이는 일차적으로 방지가 된 상태고 만약 Comment가 지속적으로 Todo를 참조해야 한다면 사실상 N+1 문제를 겪고 있는 것이기에 @EntityGraph 같은 옵션을 설정하여 연관 관계를 하나의 쿼리로 묶어 해결할 수 있다.
그런데 찾아보면 @EntityGraph를 쓰거나 JOIN FETCH를 쓰는 건 OneToMany, 양방향에서 발생하는 코드밖에 찾지 못해서 현재 Todo에 Comment가 선택적으로 추가 조회되는 상황은 필연적으로 발생하는 것도 아니고 Comment가 Todo를 이용할 때 추가 쿼리가 들어가는 것도 필연적인 일이 아니니 지금의 구조 자체가 문제가 될 것 같지는 않다. 이건 현재 구조에서 발생할 여지가 잘 보이지 않아 어렵게 느껴진다.
불변성 검증과 유효성 검증의 차이
바로 어제 불변성 검증 하고 유효성 검증 실컷 나눠놓고 또 정리하는 이유는 두 개가 검증하는 영역이 다름을 확실히 하고 싶어서 그렇다.
불변성 검증은 시스템의 상태를 판단하는 검증이고 도메인 모델이 필수적으로 지켜야 하는 조건을 일관적으로 체크하기 위해 사용하는 것이고
유효성 검증은 사용자의 값의 품질을 보증하기 위한 것이다.
예시로 봐서 뭔가로 돈 계산을 하는 로직이 있을때 유효성 검증은 사용자가 보낸 돈 수치를 검증하는 것이고 불변성 검증은 돈 계산 로직 이후의 Entity에 저장할 때의 돈 수치를 검증하는 것이다. 둘 다 돈 수치가 마이너스가 되면 안된다 같은 조건이 있다면 유효성과 불변성은 검사하는 시점때문에 실제로 검사하는 돈 수치는 다른 값이 된다.
지금 내 로직도 불변성 검증이 사실상 유효성 검증이나 다를 바 없지만 만약 비즈니스 로직이 추가된다면 의미 있어지는 검증이 된다고 여기면 될 것 같다.
Service가 주입받아야 하는 의존성은 어떤 것인가? (Aggregate의 경계)
회고에서 팀원 분이 튜터님께 들은 피드백중 Todo Aggregate의 도메인이 아닌 Repository를 주입받는 것은 결합도가 높고 다른 도메인을 참고해야 한다면 그 Service를 주입받으라는 얘기를 해주셨다.
Service 계층간에 서로 의존성이 생기게 되면 DDD 패턴을 위반하게 되는 것이 아닌가? 라는 생각이 들어서 나는 줄곧 깊은 계층에 존재하는 Repository를 참조하는게 옳다고 여겨왔는데 이는 DDD를 쓴다기 보단 계층을 분리했다고 여기는게 맞다고 레퍼런스는 이야기하고 있다.
DDD는 어디까지나 Domain 별로 책임을 분리하므로 다른 Aggregate의 도메인을 직접적으로 들여다보게 되는 Todo - User의 경우 Repository를 참조하는게 아니라 도메인의 책임을 명확히 지고 있는 Service를 주입받아서 Service를 통해 유저 정보를 받아오는 게 결합도가 낮고 도메인의 책임 분리가 명확해진다.
레퍼런스에서는 이를 Aggregate 경계가 독립적으로 존재하면서 Service를 주입받으면 협력 관계성으로 의존성을 주입받았다고 본다고 한다.
이는 이전에 나도 튜터님께 받았던 Aggregate Root에서 서브 엔티티를 제어한다 라는 피드백대로 Repository를 Aggregate 별로 구분을 확실하게 해서 책임을 분리한다는 바람직한 모습을 이룬다.
여담으로 조사하다보니 요즘엔 Domain별로 JpaRepository로 만들어 도메인 관리를 쉽게 퉁치는데 DDD 원칙상으론 Repository도 Aggregate Root만 Repository를 가지고 영속성을 관리하는게 권장되는 패턴이라고 한다. 상상만해도 구현 비용이 쌜 것 같다는 생각이 들었다.
관심사의 분리 - Spring 특강
이번 Spring 공부를 하면서 관심사의 분리에 대한 고민을 관습적으로만 쓰다가 처음으로 많이 하기 시작했는데 마침 그에 대한 특강도 진행이 되어서 내용을 기록해두기로 했다.
Spring MVC는 View가 없는데 왜 Spring MVC인가?
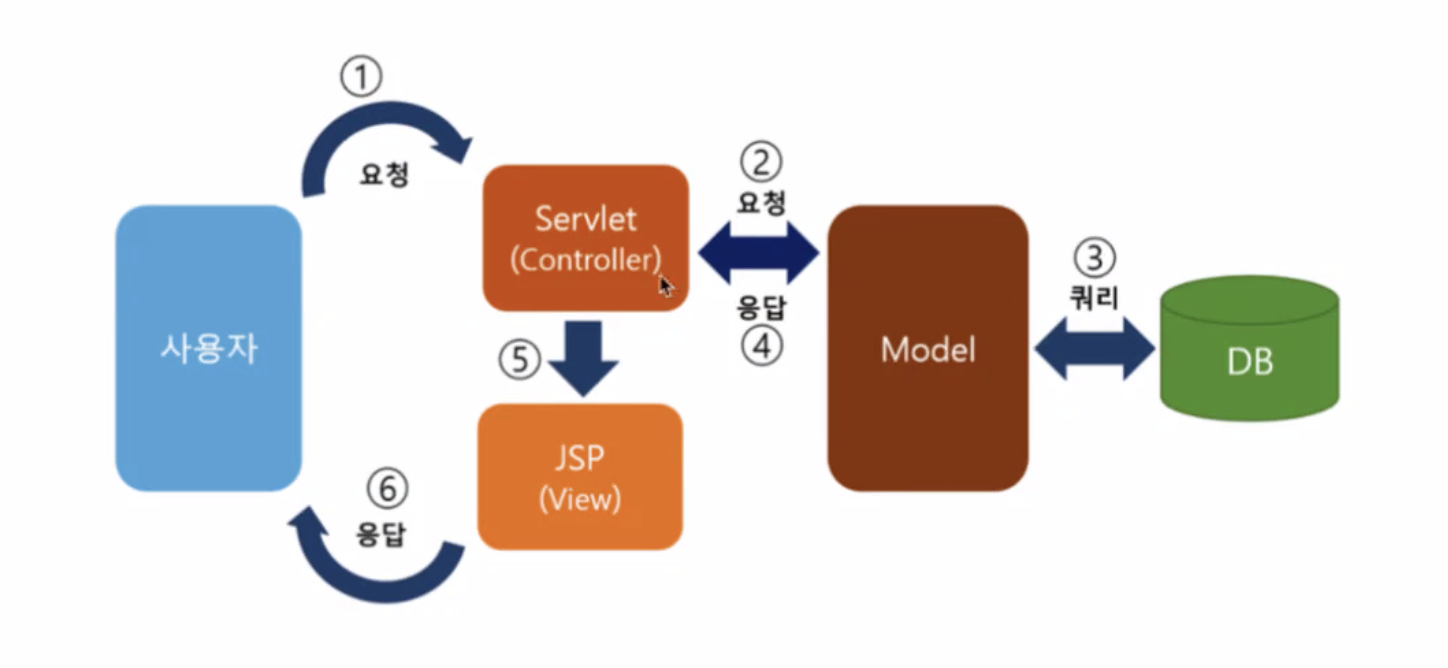
Java server page (JSP) 로 소통하던 시절의 여파다. 현재는 json을 위주로 통신하지만 원래는 Data를 화면에 붙이기 위한 준비가 되어있고 이를 데이터를 View page에 붙여 반환한다고 생각하면 된다.
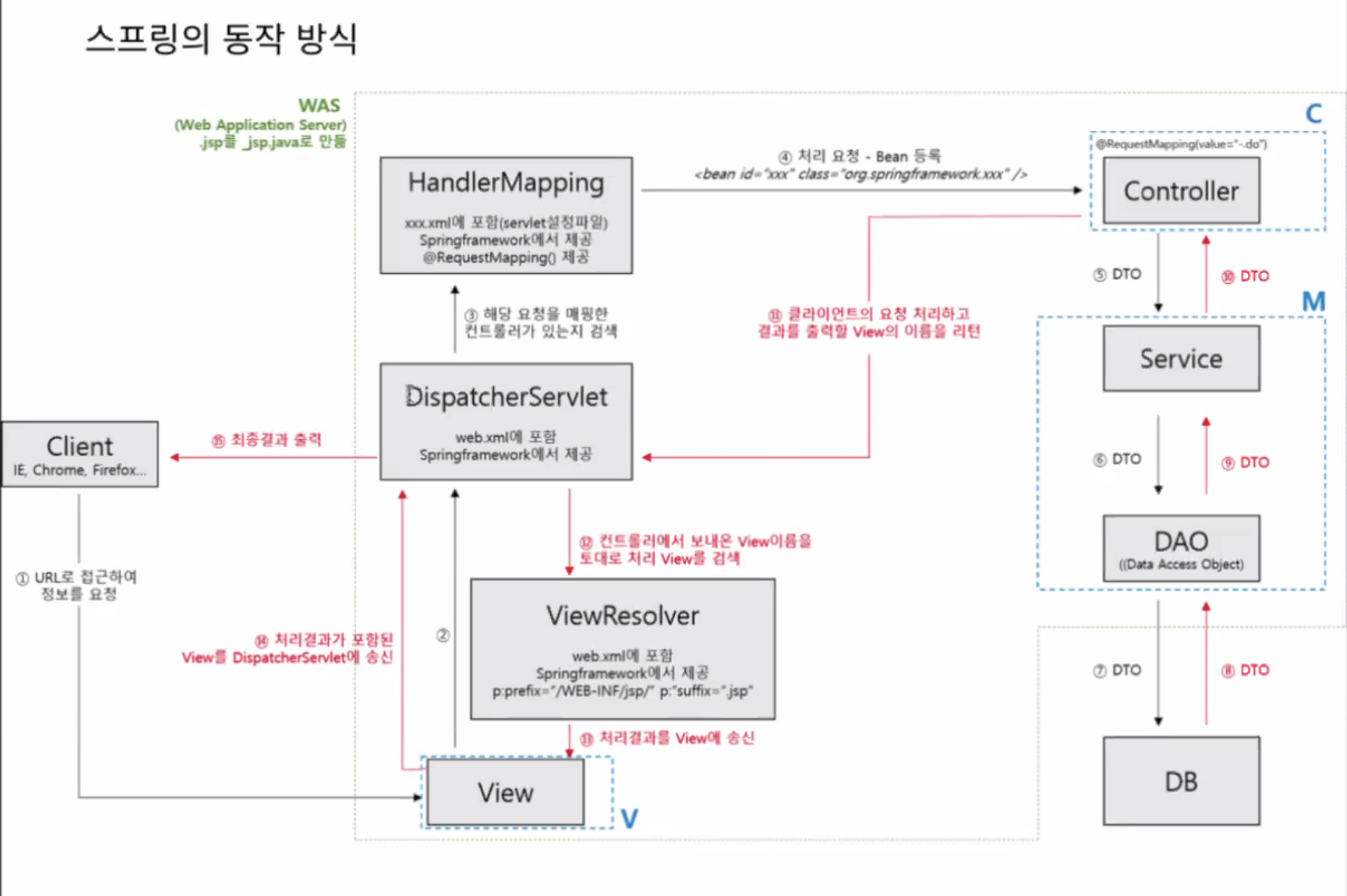
이전에 강의에서도 배웠던 DispatcherServlet이 적당한 Controller를 찾고 요청에 대한 결과를 반환받았을 때 View를 검색하고 처리하는 과정도 진행해준다. View와 SSR을 지원하기 위해서라면 Controller는 적절한 View의 이름을 반환할 것이다. 이를 Rest API로 바꾼게 @ResponseBody 어노테이션이다. (현재는 @RestController가 이 역할을 포함해준다.)
이처럼 DispatcherServlet이 MVC 기반을 잘 지원해준다.
그렇다고 ResponseBody 자체가 View를 대체한다고 해석하면 안되고 (View와는 명백히 다르다) Spring 자체가 MVC Framework 라서 Spring을 사용하면 MVC 기반 프로젝트인 것은 맞다고 볼 수 있지만 View를 쓰지 않았다면 MVC 모델, 패턴으로 프로젝트를 짰다고는 말할 수 없다. 다른 용어라 보면 될 것 같다.
관심사의 분리
현재는 Presentation layer 구성 요소로 Controller만 작성하고 있지만 DispatcherServlet, View, HandlerMapping도 여기 포함된다.
클라이언트에서 들어온 요청의 검증을 빠르게 처리하고 값을 유연하게 변환하는 역할을 맡는다.
비즈니스 로직, 캐싱, 권한같은 부분은 Service layer에서 처리하게 된다. 지금 습관적으로 쓰고 있는 비즈니스 로직은 사용자의 요청에 맞는 결과를 도출하기 위한 일련의 과정을 조율한다고 보면 될 것 같다.
그리고 알다시피 DB와 통신하는 부분은 전적으로 Repository layer에서 처리하게 된다.
그런데 Service가 비즈니스 로직을 너무 많이 처리하면 지나치게 무거워진다. 이를 방지하기 위해서 Entity, Controller에 적절히 로직을 분배하고 Service가 조율을 하게끔 하면 이 문제를 줄일 수 있다.
Service는 가장 무거울 것 같은 layer지만 이를 가볍게 하기 위해 분리할 수 있는지 항상 고민해보면 좋은 구조가 작성될 수도 있다.
코드카타 - 프로그래머스 옹알이 (2)
머쓱이는 태어난 지 11개월 된 조카를 돌보고 있습니다. 조카는 아직 "aya", "ye", "woo", "ma" 네 가지 발음과 네 가지 발음을 조합해서 만들 수 있는 발음밖에 하지 못하고 연속해서 같은 발음을 하는 것을 어려워합니다. 문자열 배열 babbling이 매개변수로 주어질 때, 머쓱이의 조카가 발음할 수 있는 단어의 개수를 return하도록 solution 함수를 완성해주세요.
fun solution(babblings: Array<String>): Int {
val babuList = listOf("aya", "ye", "woo", "ma")
var answer = 0
babblings.forEach {
var babu = it
if (!it.hasConsecutiveKeywords(babuList)) {
babuList.forEach { actualBabu ->
babu = babu.replace(actualBabu, "?")
}
if (babu.replace("?", "").isEmpty()) answer++
}
}
return answer
}
fun String.hasConsecutiveKeywords(keywords: List<String>): Boolean {
keywords.forEach { keyword ->
if (this.contains(keyword + keyword)) return true
}
return false
}이번 문제의 핵심인 줄 알았던 Replace에 대해 많이 바꿔보는 시간을 가졌다.
첫 코드는 금방 보냈는데 실패 케이스가 꽤 있었고 반례를 너무 모르겠어서 질문하기와 블로그 레퍼런스에서 대체 이 문제가 요구한 테스트 케이스를 파악하는 것부터 시작했다.
찾아보니 우선 키워드의 중복, 그리고 Replace의 올바른 사용 이 핵심인 걸로 파악했다.
처음에 고생한 건 키워드의 중복을 체크하는 거였다. replace를 하면 "yeyeyeyeye"를 줘도 정답이라고 체크해버릴테니 이걸 사전에 차단해야 했는데 이 부분에서 정규표현식을 채용한 풀이가 정말 많았다.
그런데 정규표현식에 의존하지 않아도 되는 패턴의 일부같아서 고민을 좀 했는데 키워드가 중복되는게 있는지 체크하는 확장함수인 hasConsecutiveKeywords을 만들어서 이를 해결했다.
처음에는 removeConsecutiveKeywords 로 작성해서 문자열에서 중복을 제거하고 돌려주는 함수를 썼었는데 일단 드럽게 무겁고 복잡해지기도 하고 문제는 중복된 키워드가 있으면 애초에 옹알이 할 수 없는 상태이기에 has로 바꿔서 처리하니 가벼워졌다.
이렇게 키워드의 중복을 체크하고 나서는 사실 문제가 다 풀린 줄 알았다. 그런데도 테스트케이스 6개쯤인가가 줄줄이 실패하길래 반례를 찾아보니 "ayamayaa" 라는 치명적인 반례가 있었다.
replace를 생각없이 쓰다보면 aya: "ayamayaa" -> ma: "ma" -> "" 순서로 제거가 되면서 문장이 이어져버리는 대참사가 나게 된다. 이를 방지하기 위해 첫 replace는 ? 로 대체하고 그 다음 대체를 한 번 더 하는 식으로 바꿔 접근하니 드디어 문제가 해결됐다.
문제가 정말 간단해보여서 첫 replace를 이용한 알고리즘은 정말 빨리 썼는데도 반례를 한참 고민하다가 결국 질문하기, 레퍼런스까지 뒤져보고 나서야 그 진실을 알게 돼서 많이 아쉬운 문제였다.
정규표현식을 쓰지 않은 이유는 굳이 안써도 될 문제라 생각해서였는데 다른 풀이와 비교해보니 실행시간이 10배정도 차이가 나긴 해서 결국 정규표현식을 이용한 풀이가 더 효율적이었다고 생각할 수 있을 것 같다.
가장 단순하고 빠른 정규표현식은 아래와 같았다.
"^(aya(?!aya)|ye(?!ye)|woo(?!woo)|ma(?!ma))+$"
aya 뒤에 (?!aya) 로 연속되는 키워드인지를 검사해 모든 키워드를 검사했고 매치되는 패턴만 count해서 계산했다.
