Spring 심화는 Spring security, AOP, QueryDSL, 테스트 코드에 대해 배운다. 배우는 내용만 보면 꽤 어려운 내용들이지만 다뤄보고 싶었던 내용들이긴 하다.
하지만 공부 기간이 짧고 다음 주에 바로 숙련 프로젝트 기간에 들어가서 이거 영 제대로 따라갈 수는 있을지 모르겠다. 이번에도 머리가 많이 아플 거라 생각한다. 성공적인 정착을 위해서는 고민을 조금 줄이고 레퍼런스 조사를 정말 많이 해봐야할 것 같다.
휴일에 아무 것도 안하긴 하지만 멍하니 쉬는 맛이 있는데 어째 반납할 각이 자꾸만 보이는 것 같다.
Kakao / Naver oauth 과제 진행하기
저번에 Kakao 소셜 로그인은 진행했었는데 프로젝트에 심느라 테이블도 제대로 안바꾸고 엉성하게나마 진행한 거라 Repository를 나눠서 네이버 구현도 진행하고 DB도 Supabase에서 테스트하기 쉽게 In memory H2로 옮겨서 작업했다.
우선 User는 다른 정보는 다 빼고 랜덤한 패스워드로 생성되는 식으로 provider, provider_id를 같이 저장해서 조금 더 유니크하게 찾을 수 있게 변경했다.
그리고 기존에 String으로 받아 ObjectMapper로 값을 얻어오던 방식도 Dto로 제대로 바꾸게 진행했다. 이러니 한결 하드코딩스러운 코드가 줄어들었다.
다만 로직을 제대로 구분하진 못했는데 그냥 올바른 방향으로 피드백 받고 싶어서 Controller 안에서만 OAuth 로직이 돌아가게끔 구현했고 회원가입 / 로그인만 유저 서비스가 담당하게 구현했다. 내 생각대로 구현해보고 피드백이랑 비교하는게 당연히 좋겠지만 심화 과제도 오늘 발제돼서 마음이 영 급했다.
고민한 점 / 어려운 점에 대해 적어내는 부분이 있길래
고민한 점에는 '회원가입할 때 Provider마다 제공 정보가 다르고 동의를 하지 않았을 때 추가 정보를 처리할 로직이 잘 떠오르지 않는다'
어려운 점에는 'OAuth 과정에서 구체적인 요청 로직을 분리하려는데 잘 상상이 안돼서 Controller에서 다 작성했다' 라고 작성했다.
Controller가 config을 주입받으면 안됐나 싶다가도 이걸 굳이 분리해도 의미가 크게 없다는 느낌도 받고 그래서 이렇게 한 것 같다.
Spring AOP (Aspect-Oriented Programming) 알아보기
한 10일 전에 AOP를 이용해서 유저에 대한 권한 체크를 위임하는 걸 조사한 적 있는데 마침 심화과정에서 배우는 내용이다. 일단 이것도 만만찮게 개념이 복잡해서 구현도 복잡하게만 느껴진다.
핵심 로직에 들어가야 하지만 서비스의 도메인과는 다른 관심사인 부가 기능들(인가같이)을 어플리케이션 전반적으로 재사용할 수 있게 모듈화하는 것이다.
나도 마지막 프로젝트에서 도메인 로직에 관련 없는 부가기능중 인증 기능이 있었고 auth service를 주입받아 처리하긴 했지만 코드의 중복이 정말 많긴 했다.
Cross-Cutting이라는 키워드가 중요한데 레퍼런스에서는 횡단 관심사라고 부른다. 여러 서비스에 걸쳐서 동작하는 코드라는 뜻이다. 부가 기능은 대표적으로 로깅, 보안, 그리고 지금도 쓰고 있던 트랜잭션이 있다.
@Transactional 어노테이션이 없었다면 Entity manager에서 getTransaction을 진행하고 begin, commit을 하는 과정이 있었겠지만 어노테이션을 사용함으로써 코드의 중복을 줄였다.
사진으로 보면 되게 이해가 쉬웠는데 Service A, Service B의 로직이 각각 진행되는 과정은 OOP지만 Service A, Service B의 로직중 중복되는 기능이 있는지 보는 것은 AOP가 된다.
AOP의 주요 개념
- Aspect
부가 기능들을 모듈화한 단위다. - Pointcut
Aspect가 적용될 프로그램상의 실제 위치다. 우리가 직접 쓴 @Transactional 어노테이션이 실제 위치를 맡는다고 볼 수 있다. - JoinPoint
Aspect가 적용될 수 있는 위치들(PointCut)의 후보군이다. Method가 호출되는 시점, 생성자가 호출되는 시점, Exception이 호출되는 시점등이 후보군이 될 수 있다. 사실상 Application 내라면 대부분 될 수 있다고 생각할 수도 있다. - Advice
@AdviceController가 존재하는 것처럼 부가 기능이 존재하는 코드를 말하고 그 코드를 객체로 정의하면 Advice라고 한다. - Weaving
위에서 작성한 Aspect를 실제 코드에 적용해서 원하는 로직대로 적용하는걸 의미한다.
개념 키워드는 좀 까다롭긴 한데 실제로는 부가 기능을 어플리케이션 전반적으로 사용할 수 있게 모듈화하고 코드에서 필요한 부분에 찾아 적용하는 것이다.
Spring AOP vs AspectJ
AOP는 프로그래밍 기법일 뿐이고 이걸 실제로 구현하는 건 각 프레임워크에서 맡게 된다. Spring에서는 위 두 개가 대표적이라 볼 수 있다.
두 프레임워크의 가장 큰 차이는 실제로 모듈을 코드에 적용하는 Weaving 방법이다.
우선 Weaving 방법을 크게 세가지로 나눌 수 있다.
-
Compile-time weaving
컴파일 시점에 클래스 자체를 Aspect를 적용해서 바꿔버린다. -
Load-time Weaving
컴파일 후 JVM에 클래스를 로드할 때 Java byte code를 바꾸기 때문에 기존 클래스는 건드리지 않는다. -
Run-time Weaving
객체에 직접 접근하지 않고 중간에 가짜 객체인 프록시를 두고 프록시를 거쳐가게 해서 변경한다.
AspectJ는 위 두가지 방법을 지원한다. Spring AOP는 Run-time Weaving만 진행한다.
이에 따라 두 프레임워크의 특징과 성능 차이도 존재하는데
- 성능은 AspectJ가 8~35배정도 빠르다고 한다. Spring AOP는 프록시 객체를 거쳐가기 때문에 오버헤드가 필연적으로 발생할 수밖에 없다.
- JoinPoint는 모든 부분에 JoinPoint 적용이 가능하지만 Spring AOP는 프록시 패턴이라 프록시에 해당하는 클래스를 만들어야 한다.
그 중에서도 java의 final, kotlin의 일반 class는 상속을 받을 수 없기 때문에 적용이 안되고 일반 Method만이 JoinPoint로 사용할 수 있다.
또한 Spring의 Bean으로만 작동하기도 한다.
단점같아 보이지만 AOP를 쉽게 만들고자 하는 접근이라 볼 수 있다. - AspectJ는 별도의 컴파일러나 weaver를 만들어서 세팅을 해줘야 작동을 하는 구조고 AOP는 Aspect라고 정의만 해주면 알아서 처리되기 때문에 간단하다.
성능에 대한 요구사항이 있다면 복잡하더라도 AspectJ를 통한 AOP 구현이 훨씬 좋은 것 같고 간단한 구조로 빠르게 적용하기엔 Spring AOP가 훨씬 단순하고 쉽다고 생각할 수 있다.
강의에선 성능에 대한 요구사항이 없기 때문에 Spring AOP를 사용한다.
Spring AOP 써보기
의존성에 implementation("org.springframework.boot:spring-boot-starter-aop")을 추가하고 Application에 @EnableAspectJAutoProxy를 설정해야 proxy 기반 AOP를 쓸 수 있다.
Spring AOP도 AspectJ를 차용해서 만들었기 때문에 AspectJ가 들어가게 된다.
Aspect의 역할을 할 클래스는 @Aspect 어노테이션을 적용하면 되고 Bean으로만 사용이 가능하기 때문에 @Component 또한 필요하다.
클래스 내부엔 Advice method를 정의하고 argument로 joinPoint: ProceedingJoinPoint로 받아 구현을 시작하면 부가기능의 실제 역할을 할 수 있게 된다.
JoinPoint가 적용된 부분을 실행하려면 joinPoint.proceed()를 하면 되고 AOP를 시작하려면 proceed의 전후로 무언가 수행할 역할을 붙인다고 보면 될 것 같다.
Transactional이었다면 Entity manager가 proceed 이전에 begin하고 proceed 이후엔 commit 하는 느낌일 것이다.
이제 Advice의 작성이 끝났으면 메소드에 @Around로 AOP 코드가 지정된 joinPoint의 앞뒤에서 수행하는지 명시해주고 PointCut을 정확히 작성해주면 되는데 PointCut 표현식은 아예 따로 존재한다.
이거는 따로 공부해야 하는데 주로 Execution 또는 Annotation을 사용한다고 한다.
Execution은 AOP를 상세하게 다뤄야할 때 좋고 Annotation은 그냥 어노테이션 기반으로 간단히 적용할 때 쓴다.
광범위하게 적용할 때 *을 사용할 수도 있고 파일을 정확히 적어서 특정 함수에만 적용되게도 가능한데 Advice가 적용될 범위를 특별히 제한할 수 있으니 필요할 때 표현식을 참고해서 적용하면 될 것 같다.
어노테이션이 어지간해선 편하겠지만 어노테이션은 남발하면 예측이 어렵고 휴먼 에러의 위험성도 있으니 Execution을 쓰는 이유도 이해가 된다.
번외: @Transactional은 왜 별도의 Config 없이 Proxy 기반 AOP가 가능했을까?
Spring boot가 내부적으로 사용하는 @EnableTransactionManagement 에서 트랜잭션 관리를 위해 Proxy 기반 AOP를 사용하고 있다.
즉 이미 Spring boot는 어느정도 Spring AOP를 내장하고 있다는 뜻인데 강의에서 @EnableAspectJAutoProxy를 추가로 Application에 정의하는 이유는 Execution, Annotation같은 포인트컷 표현식을 사용하기 위해 AspectJ를 활성화해야 하기 때문이라고 생각할 수 있다.
알아두면 좋은 어노테이션
위에서 사용한 @Around처럼 Advice의 적용 시점을 정의하는 어노테이션은 총 5개가 있다.
- Around: 메소드 실행 전후로 동작
- Before: 메소드 호출 전에 실행됨
- After: 메소드 결과와 상관 없이 메소드가 끝나면 실행됨
- AfterReturning: 메소드가 정상적으로 반환됐을 때만 실행됨
- AfterThrowing: 메소드가 예외를 발생시킬 때만 실행됨
어노테이션의 경우 어노테이션 적용 시점이 따로 존재한다.
- @Target
AnnotationTarget.{CASE}의 형태로 어노테이션이 적용될 대상을 말한다.
FUNCTION이면 메소드고 CLASS면 클래스고 PROPERTY면 필드고 ANNOTATION_CLASS처럼 다른 어노테이션도 가능하다. - @Retention
AnnotationRetention.{CASE}의 형태로 어노테이션이 어느 시점까지 사용될 수 있는지를 정하는 것이다.
일반적으로는 실행중일 때를 의미하는 RUNTIME을 사용하고 RUNTIME이 DEFAULT고 거의 대부분 이걸 사용한다.
SOURCE, BYTECODE도 있긴 한데 이런건 Weaving 의 시점이 다른 것처럼 특정 시점까지만 제한하는 거지만 거의 런타임까지 가져간다.
강의에선 @StopWatch 어노테이션을 정의해서 StopWatchAspect를 정의하고 @Around로 JoinPoint의 실행 앞뒤로 시간 측정을 붙여서 JoinPoint의 실행 시간을 측정하는 Advice를 만들어 적용했다. 이런 식으로 사용하면 코드의 중복을 정말 많이 줄일 수 있을 것 같다.
Spring AOP의 단점과 순수 Kotlin AOP
Spring AOP는 생산성을 크게 높일 수 있지만 몇 가지 단점도 있다고 느낄 수 있다.
-
구현할 때 어노테이션 정의하고 Advice 정의하고 Around 쓰고 필요한 함수에 Annotation 정의까지 하다보면 상당히 번거롭다고 생각할 수 있다. 추가로 Pointcut 표현식도 어렵고 많은 곳에 쓰다보면 실제로 잘 적용했는지 검증도 복잡해지고 명시적이지 않아진다.
-
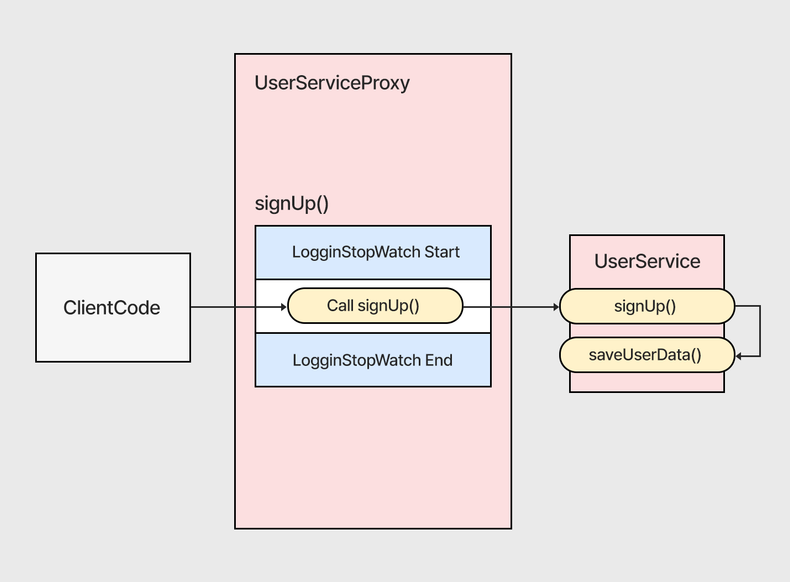
함수 안의 내부 함수도 AOP를 사용중이라면 AOP가 제대로 동작하지 않는다. Proxy로 이미 한 번 묶인 함수가 내부에서 다른 내부 함수를 호출하면 해당 함수가 AOP더라도 해당 파일의 Proxy를 이미 거친 상태라 바로 실행하기 때문에 서비스를 분리해야만 AServiceProxy, BServiceProxy 같은 식으로 처리가 된다.
-
Pointcut 표현식은 컴파일 단계에서 검증을 못해서 런타임에서 예외가 발생할 수 있다. 표현식의 대상이 패키지, 클래스명이 변경된다면 execution 표현식은 런타임 예외를 발생시키고 코드의 변경도 없이 예외가 발생할 수 있다는 점은 치명적이다.
-
JoinPoint에서 args로 값을 획득하는 방식도 Any로만 식별할 수 있어 인자의 타입과 순서를 주의해야 한다. 인자명이나 순서만 변경되어도 런타임 예외가 발생할 수 있다.
-
배우진 않았지만 @Cacheable 이라는 어노테이션도 표현식을 사용하기 때문에 컴파일에서 검증할 수 없다.
생산성은 뛰어나지만 런타임 에러의 발생 확률이 높다는 점에서 꽤 위험하다는 생각이 들었다. 그래서 해당 레퍼런스는 Kotlin의 Trailing Lambdas를 쓰는 방법을 공유하고 있다.
fun <T> loggingStopWatch(function: () -> T): T {
val startAt = LocalDateTime.now()
logger.info("Start At : $startAt")
val result = function.invoke()
val endAt = LocalDateTime.now()
logger.info("End At : $endAt")
logger.info("Logic Duration : ${Duration.between(startAt, endAt).toMillis()}ms")
return result
}
fun signUp() = loggingStopWatch{
// .. Business Logic..
}다음과 같은 형태로 명시적인 함수를 사용하기 때문에 Spring AOP가 작동하는 방식을 그대로 갖고 있지만 컴파일 레벨에서 사용 가능하고 평소 작성하던 대로 전역, 내부 함수로 정의해서 응집도를 관리하기도 쉽다.
위에서 지적당한 단점인 내부 함수의 문제점도 해당 함수 자체가 Trailing Lambdas를 항상 거쳐서 실행되기 때문에 Proxy 객체를 거치지 않고 함수 단위로 이루어져서 내부 함수끼리도 정상 작동한다.
레퍼런스에서는 이걸로 @Transactional을 대체하는 방법까지도 공유해줬는데 여러모로 Spring AOP의 단점을 해소한다고 볼 수 있다.
꽤 괜찮은 대안이고 굳이 Transactional을 대체하지 않더라도 구현 난이도도 쉽고 런타임 에러를 방지하기 좋다는 점에서 Trailing Lambdas를 이용한 Lambda는 알아두고 써먹어보는게 좋을 것 같다.
다만 이러한 방식이 널리 알려져서 레퍼런스가 많은 편은 아닌 것 같고 고민 없이 많은 기능과 레퍼런스가 넘치는 건 현재까지는 Spring AOP가 무난하다고 생각할 수 있기도 하다. 많은 서비스가 위에서 언급된 단점을 감안하고 세세한 설정, 테스트와 검증을 거쳐서 사용하는게 일반적이라고 한다.
코드카타 - 프로그래머스 바탕화면 정리
코딩테스트를 준비하는 머쓱이는 프로그래머스에서 문제를 풀고 나중에 다시 코드를 보면서 공부하려고 작성한 코드를 컴퓨터 바탕화면에 아무 위치에나 저장해 둡니다. 저장한 코드가 많아지면서 머쓱이는 본인의 컴퓨터 바탕화면이 너무 지저분하다고 생각했습니다. 프로그래머스에서 작성했던 코드는 그 문제에 가서 다시 볼 수 있기 때문에 저장해 둔 파일들을 전부 삭제하기로 했습니다.
컴퓨터 바탕화면은 각 칸이 정사각형인 격자판입니다. 이때 컴퓨터 바탕화면의 상태를 나타낸 문자열 배열 wallpaper가 주어집니다. 파일들은 바탕화면의 격자칸에 위치하고 바탕화면의 격자점들은 바탕화면의 가장 왼쪽 위를 (0, 0)으로 시작해 (세로 좌표, 가로 좌표)로 표현합니다. 빈칸은 ".", 파일이 있는 칸은 "#"의 값을 가집니다. 드래그를 하면 파일들을 선택할 수 있고, 선택된 파일들을 삭제할 수 있습니다. 머쓱이는 최소한의 이동거리를 갖는 한 번의 드래그로 모든 파일을 선택해서 한 번에 지우려고 하며 드래그로 파일들을 선택하는 방법은 다음과 같습니다.
드래그는 바탕화면의 격자점 S(
lux,luy)를 마우스 왼쪽 버튼으로 클릭한 상태로 격자점 E(rdx,rdy)로 이동한 뒤 마우스 왼쪽 버튼을 떼는 행동입니다. 이때, "점 S에서 점 E로 드래그한다"고 표현하고 점 S와 점 E를 각각 드래그의 시작점, 끝점이라고 표현합니다.점 S(
lux,luy)에서 점 E(rdx,rdy)로 드래그를 할 때, "드래그 한 거리"는 |rdx-lux| + |rdy-luy|로 정의합니다.점 S에서 점 E로 드래그를 하면 바탕화면에서 두 격자점을 각각 왼쪽 위, 오른쪽 아래로 하는 직사각형 내부에 있는 모든 파일이 선택됩니다.
예를 들어 wallpaper = [".#...", "..#..", "...#."]인 바탕화면을 그림으로 나타내면 다음과 같습니다.

이러한 바탕화면에서 다음 그림과 같이 S(0, 1)에서 E(3, 4)로 드래그하면 세 개의 파일이 모두 선택되므로 드래그 한 거리 (3 - 0) + (4 - 1) = 6을 최솟값으로 모든 파일을 선택 가능합니다.

(0, 0)에서 (3, 5)로 드래그해도 모든 파일을 선택할 수 있지만 이때 드래그 한 거리는 (3 - 0) + (5 - 0) = 8이고 이전의 방법보다 거리가 늘어납니다.
머쓱이의 컴퓨터 바탕화면의 상태를 나타내는 문자열 배열 wallpaper가 매개변수로 주어질 때 바탕화면의 파일들을 한 번에 삭제하기 위해 최소한의 이동거리를 갖는 드래그의 시작점과 끝점을 담은 정수 배열을 return하는 solution 함수를 작성해 주세요. 드래그의 시작점이 (lux, luy), 끝점이 (rdx, rdy)라면 정수 배열 [lux, luy, rdx, rdy]를 return하면 됩니다.
fun solution(wallpaper: Array<String>): IntArray {
var rowMin = Int.MAX_VALUE
var colMin = Int.MAX_VALUE
var rowMax = Int.MIN_VALUE
var colMax = Int.MIN_VALUE
wallpaper.forEachIndexed { index, row ->
if (row.contains("#")) {
row.forEachIndexed { subIndex, column ->
if (column == '#') {
if (index < rowMin) rowMin = index
if (index > rowMax) rowMax = index
if (subIndex < colMin) colMin = subIndex
if (subIndex > colMax) colMax = subIndex
}
}
}
}
return intArrayOf(rowMin, colMin, rowMax + 1, colMax + 1)
}못생겼지만 최소 시간복잡도를 만족해서 그러려니 했다. 사실 크게 고민한 건 아니고 이전에 비슷한 풀이의 문제가 있었던 것 같은데 정확히 기억은 나지 않았다.
처음엔 좌표 리스트를 저장하고 minOrNull, maxOrNull로 전부 처리했었는데 하다보니 순회를 줄일 수 있을 것 같아서 지금의 코드가 됐다.
로그를 찍어보면 rowMax, colMax가 1씩 부족하길래 잠깐 표를 들여다보니 파일의 왼쪽위 좌표를 가리키고 있다고 판단하면 되기 때문에 마우스 포인터의 시점이니 오른쪽 아래를 가리키게끔 max는 1씩 더해졌다고 판단하면 된다.
요즘 부쩍 짧은 코드보다는 명확하고 중복이 적게 짜다보니 내장함수를 적게 쓴 면이 있고 아마 이번 제출은 분명 압축한 짧은 코드가 있을 거라고 생각했는데 의외로 다 비슷한 방식으로 풀어서 조금 놀랜 측면이 있었다.
