@Transactional 톺아보기
@Transactional은 여태까지 자주 사용했지만 JPA를 배우면 배울수록 내부적으로 조심해야 한다는 이야기를 많이 들었다. 버그의 발생 문제도 있고 어플리케이션의 시간도 많이 소비하게 될 수 있기 때문에 튜터님은 실전에서 겪으며 느낀 주의사항을 한번에 정리해주셨다.
Transactional의 전파방식
@Transactional 은 중첩되는 경우는 어떻게 동작하는지 알 필요가 있다.
fun main() {
firstTransactionMethod()
}
@Transactional
fun firstTransactionMethod() {
secondTransactionMethod()
}
@Transactional
fun secondTransactionMethod() {
/*...*/
}이것처럼 @Transactional이 중첩되는 경우는 최근 프로젝트에서도 자주 겪었다. 가급적 중첩없는게 좋지 않나? 라는 생각은 해본 적 있는데 다른 Service에서도 여러 Repository와 통신을 하다보니 제거하고 개발을 하기엔 노하우가 너무 부족했다.
마침 강의에서 이런 부분을 짚어줬고 Transactional의 중첩은 어떻게 처리되는지 공부해봤다.
Transactional은 이런 중첩에 대해 사실 한 가지 처리 방법만 제공하지 않고 전파방식(Propagation)을 7가지나 지원해준다.
REQUIRED- defaultREQUIRES_NEWMANDATORYNESTEDNEVERSUPPORTSNOT_SUPPORTED
다 외우기는 힘들고 REQUIRED, REQUIRES_NEW, NOT_SUPPORTED 에 대해서 중점적으로 먼저 공부하고 나머지 키워드를 습득하는걸 추천하셨다.
내용 설명에 쓰는 키워드
부모 Transaction :
기존에 존재하던 트랜잭션으로 위 예제에서는 firstTransactionMethod 가 부모 트랜잭션이 된다.
자식 Transaction :
이미 트랜잭션에 포함된채로 새로운 트랜잭션 메소드가 호출될 경우 새롭게 호출되는 트랜잭션으로 위 예제에서는 secondTransactionMethod 가 자식 트랜잭션이 된다.
REQUIRED - default
- 부모 트랜잭션이 있다면 해당 트랜잭션에 합류한다.
- 부모 트랜잭션이 없다면 새로운 트랜잭션을 생성한다.
@Transactional에 아무런 전파방식을 지정해주지 않으면 해당 전파방식이 적용된다.- 중첩으로 호출된 모든 메소드가 하나의 트랜잭션으로 동작하기 때문에, 커밋 및 롤백 범위도 전체다!!
REQUIRES_NEW
- 부모 트랜잭션과 상관없이 무조건 새로운 트랜잭션을 생성한다.
- 부모 트랜잭션과 자식 트랜잭션을 독립적으로 분리하고 싶을 때 사용한다. (실무에서도 많이 사용됨!)
- 자식 트랜잭션에서 에러가 발생하더라도 부모 트랜잭션에 영향(Rollback 등)을 주고싶지 않을 때
- 부모 트랜잭션이 커밋되기 전까지 기다리지 않고 자식 트랜잭션을 즉시 커밋하고 싶을 때
- 부모 트랜잭션이 실패하더라도 자식 트랜잭션이 성공했다면 자식 트랜잭션에 대한 결과를 커밋하고 싶을 때
@Transactional
fun congratulationBirthday(members: List<Member>) {
for (member in members) {
member.addPoint(5000)
memberRepository.save(member)
sendEmailService.sendBirthDayMail(member)
}
}
@Transactional
fun sendBirthDayMail(member: Member) {
// ...
if (member.id == 997) {
throw RuntimeException("내가 임의로 발생시킨 에러다!")
}
}
/*
997명째에서 에러가 발생하면 메일은 발송했으나
모든 포인트는 Rollback 처리되어 메일만 발송한 상황이 된다.
*/
=>
@Transactional(propagation = Propagation.REQUIRES_NEW)
fun sendBirthDayMail(member: Member) {
// ...
if (member.id == 997) {
throw RuntimeException("내가 임의로 발생시킨 에러다!")
}
}
/*
997명째에서 에러가 발생해도 전체 트랜잭션이 롤백되는 일은 없다.
하지만 997명에 대한 롤백은 이뤄져서 근본적인 해결은 되지 않는다.
*/
=>
@Transactional
fun congratulationBirthday(members: List<Member>) {
for (member in members) {
member.addPoint(5000)
memberRepository.save(member)
try {
sendEmailService.sendBirthDayMail(member)
} catch(ex: RuntimeException) {
member.minusPoint(5000)
memberRepository.save(member)
// 발생한 예외가 회복된다!!
}
}
}
/*
sendBirthDayMail() 에서 발생한 예외가
congratulationBirthday() 로 전파가 되기 때문에
예외를 try-catch로 회복시켜서 문제를 방지할 수 있다.
*/이렇게 처리함으로써 997번째 회원을 제외한 모두에게 포인트 지급과 메일을 정상적으로 발신할 수 있게 된다.
정말 Transcational을 쓸 때 비즈니스 로직적으로 생각을 잘 해야겠다는 생각이 든다.
MANDATORY
- 부모 트랜잭션이 있다면 REQUIRED 방식과 동일하게 합류한다.
- 부모 트랜잭션이 없다면 IllegalTransactionStateException 에러를 발생시킨다.

NESTED
- 부모 트랜잭션이 있다면 중첩 트랜잭션을 생성한다.
- 부모 트랜잭션이 없다면 새로운 트랜잭션을 생성한다.
REQUIRES_NEW전파방식이랑 헷갈리기 딱 좋다!!!- 커밋(Commit) 과 롤백(Rollback) 범위를 기준으로 차이점을 기억하면 도움이 될거라 생각한다.
REQUIRES_NEW전파방식과 공통점/차이점을 살펴보자.- 자식 트랜잭션이 끝나도 즉시 커밋되지 않고 부모 트랜잭션이 끝날 때 같이 커밋된다. (차이점)
- 부모 트랜잭션이 롤백되면 자식 트랜잭션도 함께 롤백된다. (차이점)
- 자식 트랜잭션이 롤백되었을 때 부모 트랜잭션에 전파되지 않는다. (공통점)
NEVER
- 부모 트랜잭션이 있다면 예외를 발생시킨다.
- 부모 트랜잭션이 없으면 그냥 트랜잭션이 없는채로 로직을 실행한다.
- 즉, 해당 로직에 대한 트랜잭션 자체를 허용하지 않는다.
SUPPORTS
- 부모 트랜잭션이 있다면
REQUIRED,MANDATORY와 동일하게 합류한다. - 부모 트랜잭션이 없다면
NEVER와 동일하게 트랜잭션이 없는채로 로직을 실행한다.
NOT_SUPPORTED
- 부모 트랜잭션이 있다면 해당 트랜잭션을 보류하고 트랜잭션이 없는채로 로직을 실행한다.
- 부모 트랜잭션이 없다면
NEVER,SUPPORTS와 동일하게 트랜잭션이 없는채로 로직을 실행한다. NEVER와 마찬가지로 해당 로직에 대한 트랜잭션을 허용하지 않는다!
NEVER는 트랜잭션이 있을 때 에러를 발생시키지만NOT_SUPPORTED는 보류하고 로직을 실행한다는데 차이가 있다.
@DataJpaTest
class MemberServiceTest {
@Test
@Transactional(propagation = Propagation.NOT_SUPPORTED)
fun noTransactionTest() {
// ...
}
}테스트 코드를 작성할 때 @DataJpaTest의 @Transactional 설정을 무시하기 위해 사용할 수 있다.
동작 방식을 다 정리해놓고 보니 꽤 어려운 것 같다.
내부 호출 문제
내부 호출은 @Transactional의 문제만은 아니고 Spring AOP 방식의 문제라 볼 수 있다.
@Service
class MemberService(
private val memberRepository: MemberRepository
) {
fun register(req: MemberRegisterRequest): MemberResponse {
if (this.checkDuplicateEmail(req.email)) {
throw RuntimeException("중복된 이메일입니다!")
}
// ...
}
@Transactional
fun checkDuplicateEmail(email: String): Boolean {
// ...
}위 코드에서 register() 내에서 checkDuplicateEmail() 를 호출하고 있다.
이처럼 하나의 객체 내에서 다른 메소드를 호출하는 것을 내부호출이라고 한다.
이전에 Spring AOP만 따로 배울 때 배운 것처럼 Proxy 방식으로 동작하기 때문에 @Transactional은 적용되지 않는다.
최근엔 IntelliJ에서 컴파일할 때 내부 호출에 대한 경고를 해주기도 한다고 한다.
해결법 - Refactoring
내부 호출이 필요하지 않은 구조로 리팩토링 하는것으로 가능하다면 이 방식이 가장 바람직하다.
내부호출문제가 발생하는 이유중 하나는 하나의 객체에 너무 많은 메소드(책임)가 할당되어있기 때문이다.
각각의 메소드를 책임이 맞는 객체로 나눠서 할당하다보면 내부호출문제가 해결되는 경우가 많다!
관심사의 분리를 적극적으로 고민해보자.
해결법 - AopContext
fun register(req: MemberRegisterRequest): MemberResponse {
val service = (AopContext.currentProxy() as MemberService)
if (service.checkDuplicateEmail(req.email)) {
throw RuntimeException("중복된 이메일입니다!")
}
// ...
}
@Transactional
fun checkDuplicateEmail(email: String): Boolean {
// ...
}위 코드와 같이 AopContext 를 이용해 Proxy 객체를 직접 꺼내올 수 있고 해당 Proxy 객체를 통해 호출을 하게된다면 더 이상 내부호출이 아니게된다.
다만 문법상으로 매력적인 선택지는 아닌 것 같다. 몰라도 되는 프록시 객체가 로직에 등장하고 다운 캐스팅은 항상 불안함이 존재한다.
해결법 - AspectJ Weaving
내부호출문제는 Spring AOP Weaving 방식 자체의 문제기 때문에 AspectJ Weaving 방식으로 변경하는 해결책이다.
AspectJ Weaving 은 바이트 코드를 직접 조작하는 방식이기 때문에 내부호출문제가 발생하지 않는다!
AspectJ Weaving 을 사용하기 위해 별도 라이브러리를 구성해줘야하고, 해당 라이브러리에 대한 러닝커브가 필요하다는 문제가 있다.
해결법 - Trailing Lambda를 이용한 Kotlin AOP
이전에도 다뤘던 내용으로 크게 문제를 발생시키지 않는다.
튜터님은 실전에서 대부분 리팩토링 또는 Trailing Lambda를 통해 해결하셨다고 한다.
N+1 문제
JPA를 이용할 때 연관관계에 있는 테이블의 데이터까지 조회하게 되면서 N+1 문제는 자주 겪게 됐다. 기본적으로 JOIN으로 조회하는게 아니라 기본 SELECT 쿼리만 발생하기 때문에 번거로운 문제다.
강의에선 LAZY로 N+1 문제를 보류해둘 수는 있지만 사용하게 되는 순간 즉시 발생하게 되므로 원천적인 해결책은 아니라고 하셨다. 그래서 이에 대한 트러블 슈팅 목록을 제공해주셨다.
Batch size
spring.jpa.properties.hibernate.defalt_batch_fetch_size: 1000이미 이전에도 다뤘지만 근본적인 해결책은 아니고 In Query로 묶어서 쿼리의 개수를 줄이게끔 자동으로 만들어주는 것이다.
나는 이걸 사용하지 않고 있었는데 N+1 문제의 해결을 놓친 부분에 있어서 방지가 되기 때문에 N+1에 대한 최소한의 방어책이니 사용을 권장하셨다.
Fetch Join
튜터님은 N+1 문제를 해결하는 근본적인 해결책으로 FETCH JOIN을 말씀하셨다. 실제 DB에서 SQL문을 만들 때도 JOIN을 의도했던 것이니 JPA의 객체 관계를 유지하며 JOIN해주는 FETCH JOIN은 의도에 맞는다고 볼 수 있다.
EntityGraph
@Repository
interface TodoRepository : JpaRepository<Todo, Long> {
@EntityGraph(attributePaths = ["comments"])
@Query("SELECT todo FROM Todo todo")
fun findAllWithEntityGraph(): List<Todo>
}@EntityGraph 를 이용해 해당 Entity 의 연관관계에 대한 정보를 넣어주는 방식이다.
Fetch join처럼 한 개의 쿼리만 발생하지만 Outer Join 으로 처리하기 때문에 사용시 주의해야 하고
연관관계가 복잡해졌을 경우 EntityGraph의 내용도 많아지기 때문에 복잡도가 급증하는 문제도 존재한다.
- Left Join 은 Left Outer Join 의 약자다.
- Outer Join 특성상 상황에 따라 중복 데이터가 나올 수 있다.
Set<>자료구조를 사용하거나distinct키워드를 통해 중복을 제거할 수 있다.
Lazy Loading
JPA는 FetchType.LAZY를 사용하면 지연 조회를 구현할 수 있다. 잘 사용하면 연관관계의 데이터가 필요하지 않을 때는 불필요한 조회 쿼리를 발생시키지 않을 수 있다.
Lazy Loading에 사용하는 방식은 해당 객체를 Proxy 객체로 먼저 초기화 해놓고 필요할 때 Proxy 객체가 쿼리를 발생시켜 실제 데이터로 바꾸는 것이다.
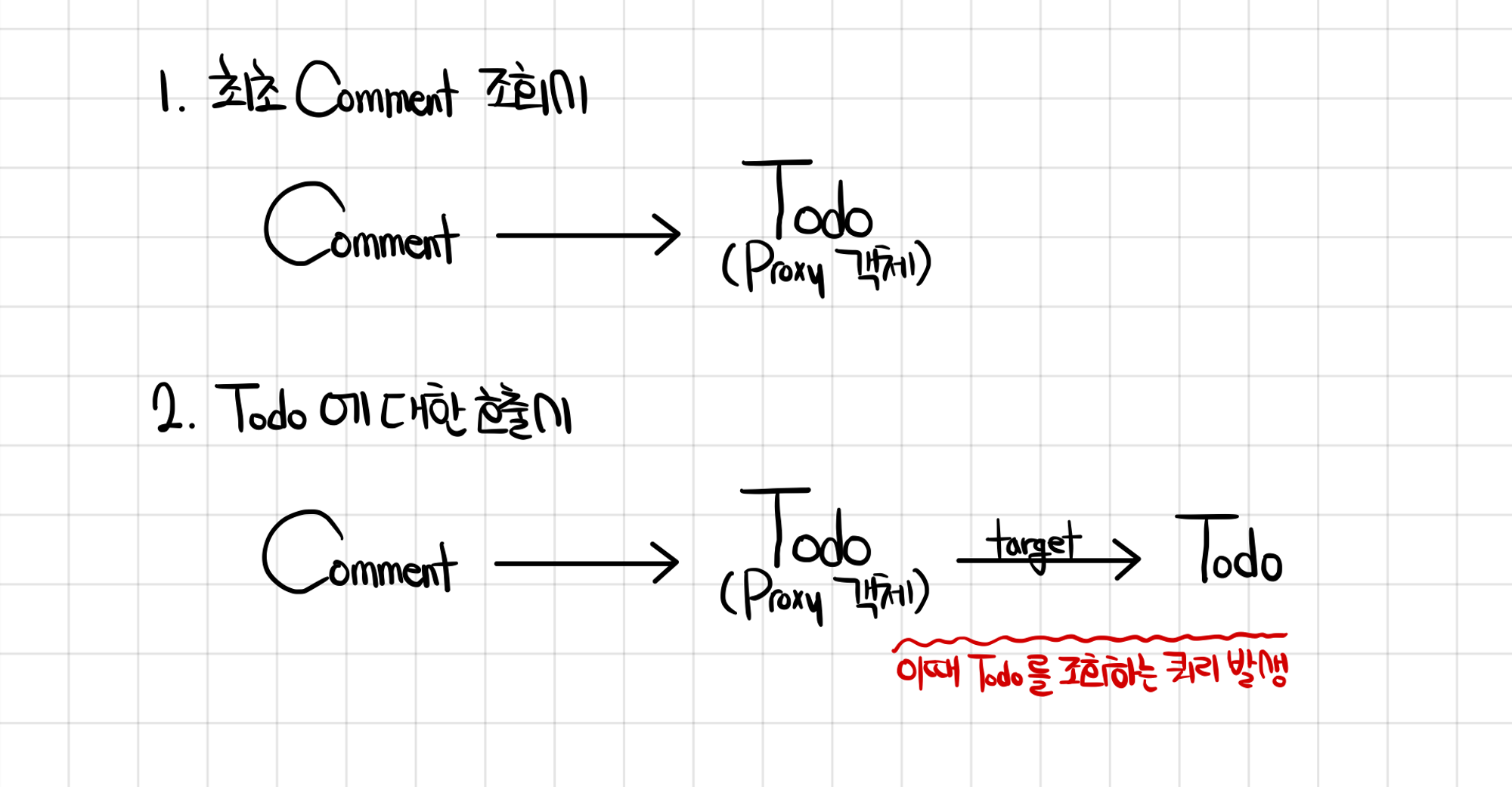
LazyInitializationException
Lazy loading을 처리할 때 주의점은 Entity가 영속성 컨텍스트가 관리중인 영속 상태일때만 처리가 된다.
그렇기에 우리가 흔히 쓰는 DTO의 .from 을 통한 Entity -> DTO 변환을 Transactional에서 벗어난 Controller 같은 곳에서 처리하면 영속성 컨텍스트는 이미 사라지고 준영속 상태가 된 Entity이기 때문에 변환시 LazyInitializationException이 발생한다.
@GetMapping("/comments/{commentId}")
fun retrieveCommentById(@PathVariable commentId: Long): CommentResponse {
return commentService.retrieve(commentId) // Entity를 반환함
.let { CommentResponse.from(it) } // Entity -> DTO 매핑 과정에서 Lazy Loading 발생!!
}Open Session In View(OSIV)
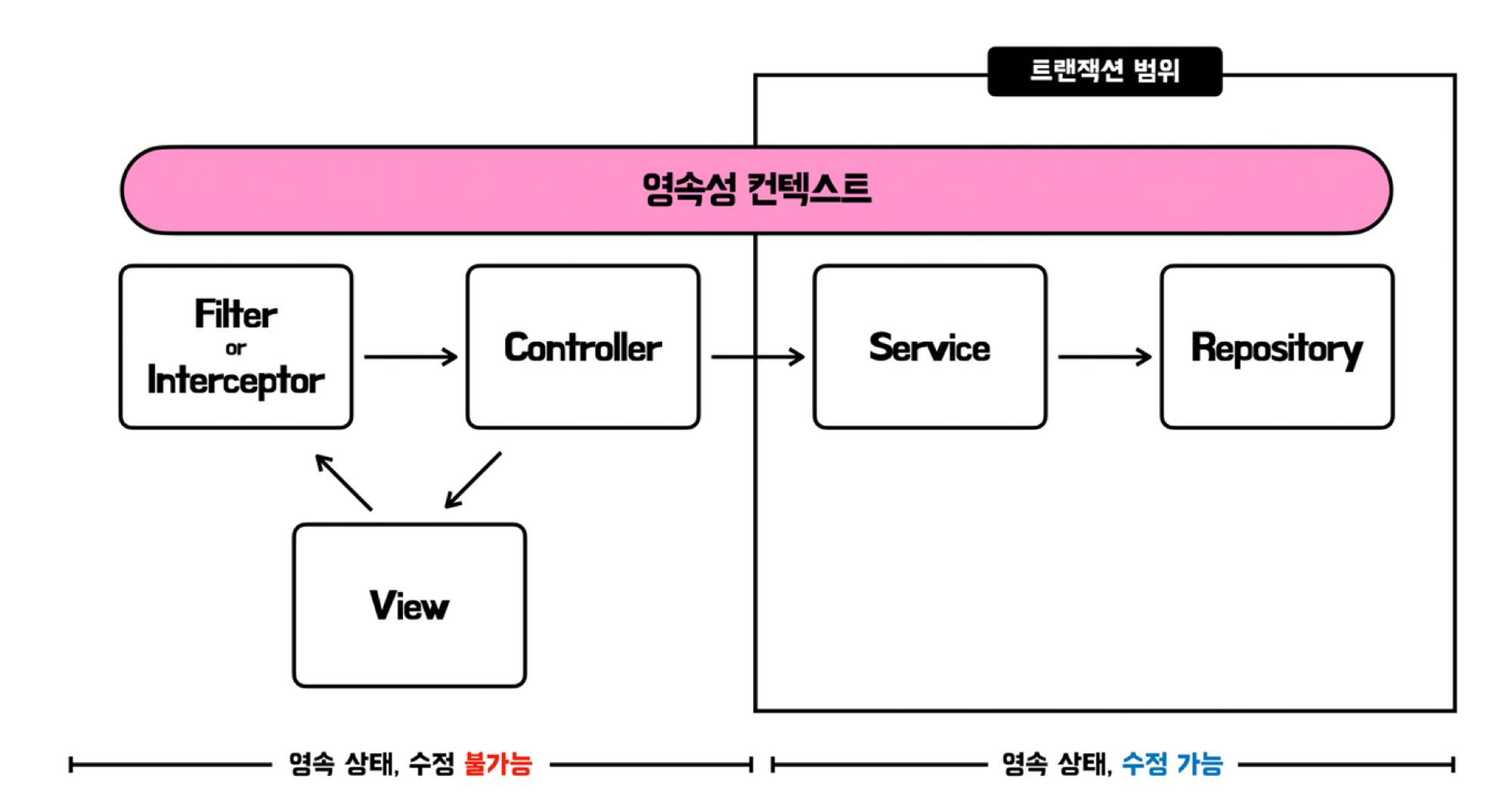
OSIV는 Session을 MVC중 View까지 열어두는 것을 의미하고원래 Transactional이 닫히면 종료됐을 영속성 컨텍스트의 생명주기도 변경이 된다. Session은 DB와 연결을 할 수 있는 영속성 컨텍스트를 상상하면 된다.
원래는 그림의 트랜잭션 범위만큼이 우리가 의도한 내용이었지만 OSIV는 위에 핑크색 영속성 컨텍스트처럼 생존 범위가 커지게 된다. 디테일하게 영속 상태를 수정할 수 없게 설정은 되어있지만 세션이 굉장히 오래 남게 된다.
현재 OSIV 설정은 기본적으로 TRUE로 설정되어 있지만 튜터님은 비활성화 하는것이 좋다고 하셨다. Spring data JPA도 아래와 같은 경고를 발생시킨다.
WARN 24996 --- [ main] JpaBaseConfiguration$JpaWebConfiguration : spring.jpa.open-in-view is enabled by default. Therefore, database queries may be performed during view rendering. Explicitly configure spring.jpa.open-in-view to disable this warning
DB Connection 관점의 단점
영속성 컨텍스트는 만들어진 이후 데이터베이스 연결이 필요한 시점에 DB Connection Pool 에서 새로운 Connection 을 획득한다. Connection은 DB와 통신하기위해 점유하고 있는 리소스라고 생각하면 된다.
이후 영속성 컨텍스트가 유지되는동안 획득한 DB Connection 을 유지한다. (변경 x, 신규 획득 x)
이는 두 가지 문제를 야기한다.
- DB Connection 은 제한된 리소스인데 불필요하게 너무 오래 점유할 수 있다.
이전에 Supabase 사용할 때도 팀원이 다 같은 Supabase를 사용하니 HikariCP의 기본 Connection pool size인 10개씩 쓰다보니
supabase의 maximum connection pool을 초과하게 되는 문제 상황이 있었고 Connection은 과하게 사용하지 않게 하는 것도 리소스의 효율을 늘린다고 생각한다. - 2개의 DB(Master - Slave)를 사용하는 경우 하나의 요청 내에서 서로 다른 DB 에 대한 요청이 불가능해진다.
왜냐하면 하나의 영속성 컨텍스트 내에서 획득한 DB Connection 은 교체가 불가능하기 때문이다.
설계 관점의 단점
OSIV 를 활성화한다는 것은 영속(Managed) 상태의 Entity 를 Controller 의 반환 타입으로 사용하겠다는 것을 의미한다.
하지만 Entity 를 반환하는 것은 설계적으로 좋지 않다.
- Client 에게 불필요하게 많은 응답이 반환될 수 있다.
예를 들어, 회원정보를 조회했는데 패스워드까지 다 응답으로 내려가게 될 수 있다. 그렇기에 우리는 민감정보, 다른 Entity의 정보등을 고려해서 이미 DTO를 사용하고 있었다. - Entity 객체가 너무 많은 Layer 를 관통해 유지보수에 취약해진다.
Entity의 Scheme가 변경되면 클라이언트가 사용하는 정보도 변경되며 클라이언트 개발자도 변경에 함께 대응해야하는 문제가 생긴다.
이런 이유로 비활성화 해주는게 좋다. 설계 관점에서 아예 Controller에서 Entity를 쓸 수 있을지도 모른다는 여지를 남기지 않는게 좋을 것 같다.
spring:
jpa:
open-in-view: falseOSIV와 LazyInitializationException의 관계
이렇게 공부했으니 LazyInitializationException 에러가 발생했을 때 OSIV 활성화를 떠올릴 수 있지만 그러면 좋지 않다.
OSIV 를 활성화하면 Session 이 요청의 끝인 View 까지 열려있기 때문에 문제가 해결되기는 한다.
다만 하나의 문제를 해결하기위해 Spring Boot 어플리케이션 전반에 영향을 줄 수 있는 옵션을 활성화하는 것은 너무나 과한 대처가 맞긴 하다.
OSIV와 LazyInitializationException을 배우면서 영속성 컨텍스트의 Life cycle을 얼추 알았으니 근본적인 해결을 우선시 하는 걸 권장하셨다.
