아이디어 출발점이었던 Embedding에 대한 이런저런 과정을 열심히 거쳐서 어떻게든 시스템스러운 무언가가 완성이라도 된게 참 다행이었다.
이 튜닝 과정에선 사실 전문성이 조금이라도 있었다면 하지 않았을 실수들이 있었다고 생각하지만 자연어 처리라는 내용에 대한 이해도도 늘었고 일단 내가 재밌었고 성취감 있었으니 만족스러운 부분이 더 큰 것 같다.
와추 PPT
로직에 들어간 값
- 당도 0~5
- 산도 0~5
- 바디 0~5
- 타닌 0~5
- 타입 레드, 화이트, 스파클링, 로제, 주정강화, 기타 총 6가지
- 가격
- 향기
여기에 와인 종류(Kind), 국가(Country)를 넣을까도 고민하다가 와인에 대해선 해박하지 않다보니 와인 애주가분들이 종류, 국가도 따지는지 몰라 넣지 않았다.
맛과 타입 데이터
총 6가지 경우의 수만 존재하므로 3차원 벡터 데이터를 임의로 직접 지정해 코사인 유사도를 비교하는 방식을 선택했다.
근접한 레벨과 0.16666 정도의 코사인 유사도가 나오게 설정되어 있다.
"level:0": [
1.0,
0.0,
0.0
],
"level:1": [
0.85,
0.1,
0.0
],
"level:2": [
0.7,
0.2,
0.1
],
"level:3": [
0.55,
0.3,
0.2
],
"level:4": [
0.4,
0.4,
0.3
],
"level:5": [
0.25,
0.5,
0.4
], /* 그 외 type도 6가지로 분류되므로 type:RED, type:WHITE 등도 동일 */가격 데이터
Min-Max Scaling으로 0~1 사이의 값으로 정규화 진행 후 1 - abs(선호가격 - 비교가격)으로 가격 값이 비슷할 수록 1에 가깝게 설정
Min-Max Scaling을 위해서는 와인의 최소가격, 최대가격을 알아와야했기 때문에 Price를 기준으로 Limit 1로 정렬해 최소, 최대값을 함께 불러올 필요가 있었다.
수식:
(price - minPrice).toDouble() / (maxPrice - minPrice)
향기 데이터
크롤링해온 향기 데이터의 기존 모양은 다음과 같았다:
{apple=[자두, 복숭아, 서양배], lemon=[시트러스], flower=[흰꽃, 꽃], stone=[미네랄]}해석하자면 자두, 복숭아, 서양배 향이 apple스러운 향기라고 태그가 달려있는 느낌이다. 임의로 설정한 건 아니고 크롤링해온 사이트의 향기 구분방법이었다.
그래서 이 향기 태그를 key로 적극적으로 삼아 인풋으로 넣어 Embedding API의 도움을 적극 받았다.
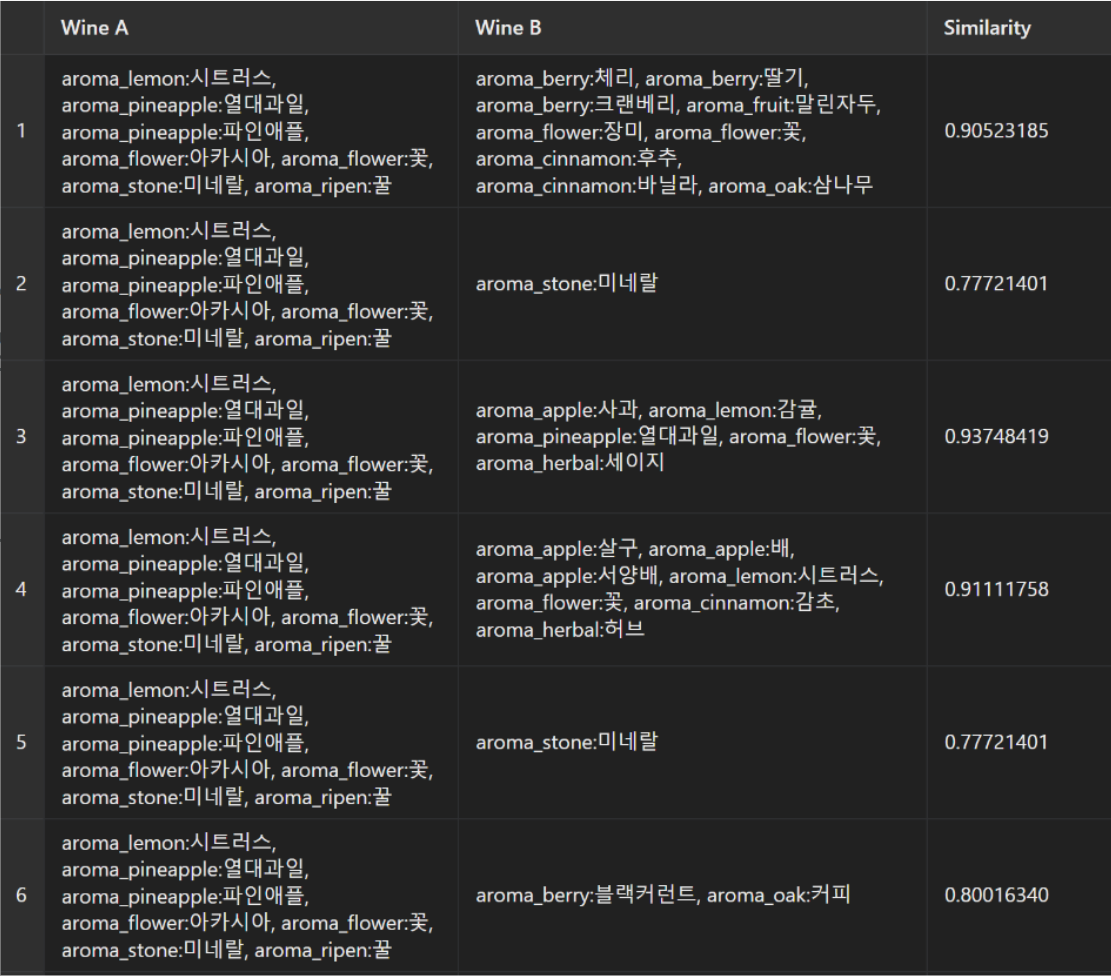
인풋은 다음과 같은 모양이 된다.
aroma_lemon:시트러스
aroma_pineapple:열대과일
aroma_pineapple:파인애플
aroma_flower:아카시아
aroma_flower:꽃
aroma_stone:미네랄
aroma_ripen:꿀이 값들을 한줄씩 변경한 후 평균을 내어 향의 방향성을 코사인 유사도로 비교하는 방식으로 향기 추천을 선택했다.
아무래도 자연어 처리를 잘 몰라서 처음엔 이 방식이 향기 유사도라고 볼 수 있을지 의구심이 들었으나 여러 번의 테스트 결과 결과적으로는 비슷한 향 태그가 많을 수록 유사도가 높아져서 비슷한 방향성을 가질 수 있었다.
가중치
추천도(유사도)가 분리가 된 만큼 사용자에게 입력을 추가로 받아 최대 50%까지 추천 결과에 영향을 줄 수 있게 변경했다.
단순하게 (1 + 가중치)를 곱해서 만약 99%면 148%까지 오를 수 있는 방식이지만 98~99%의 추천도를 보이는 1~5위 와인을 제외하고는 나름 결과가 밑에서는 조금씩 바뀌긴 했었다.
회고
이렇게 해서 제출한게 이번 최종프로젝트의 와인 추천 시스템 로직이었다. 잘 모르고 쓴 자연어 관련 부분인 만큼 엉성하다고 느껴지는 부분도 있었지만 이 접근 방식이나 튜닝 방식에 있어서 개성적이고 창의적이라는 평가를 들어 다행이었다.
자연어 처리를 더 공부하기엔 실력이 영 부족한 감이 있어 OpenAI API가 제공해주는 편의적인 부분에서는 미리 튜닝을 적용해 응용해볼 수도 있겠다 라는 생각이 들긴 했다.
그리고 추천 시스템을 이번엔 순수히 크롤링한 데이터 기반으로 했지만 공부하다보니 이렇게 정보를 미리 채워놓고 추천에 사용하는 점은 CBF 알고리즘으로 분류가 가능할 것도 같은데 도메인에 대한 지식이 부족한 점은 아쉬웠다.
추가로 사용자가 많은 실서비스였다면 사용자가 조회하고 어떤 와인을 들어가는지, 좋아요/싫어요를 도입한다던지 같은 부분으로 조금 더 많은 데이터를 로직에 사용하면 멋진 개선이 가능할 것 같다는 생각도 들었다.
