The following was created with the help of ChatGPT4.
Practice Exercises
Q. How do clustered systems differ from multiprocessor systems? What is required for two machines belonging to a cluster to cooperate to provide a highly available service?
Clustered systems and multiprocessor systems are both types of parallel computing architectures, but they differ in several key aspects:
Multiprocessor Systems:
-
Hardware: Multiprocessor systems consist of multiple CPUs or processor cores within a single computer system or server. These CPUs can be integrated on a single chip (multicore processors) or multiple chips on the same motherboard.
-
Shared memory: In a multiprocessor system, all processors typically share the same main memory and I/O resources. This enables fast communication between processors, but also requires careful synchronization and coordination to manage concurrent access to shared resources.
-
Granularity: Multiprocessor systems usually operate at a finer level of granularity, with tasks or threads being distributed among the available processors. This allows for efficient parallel execution of individual processes or parts of a single application.
-
Scalability: Scaling a multiprocessor system usually involves adding more processor cores or chips to the same server, which can be limited by factors like hardware design or memory and I/O bottlenecks.
Clustered Systems:
-
Hardware: Clustered systems are composed of multiple independent computer systems or servers (called nodes) connected through a high-speed network. Each node has its own processors, memory, and I/O resources.
-
Distributed memory: In a clustered system, each node has its own separate memory and I/O resources. Communication between nodes occurs over the network, which can be slower compared to shared memory in multiprocessor systems.
-
Granularity: Clustered systems typically operate at a coarser level of granularity, with entire processes or applications running on separate nodes. This allows for load balancing, fault tolerance, and increased availability of services.
-
Scalability: Scaling a clustered system can be more straightforward, as it generally involves adding more nodes to the cluster. This can provide a more flexible and cost-effective way to scale compared to expanding a multiprocessor system.
To enable two machines belonging to a cluster to cooperate and provide a highly available service, several requirements must be met:
-
Communication: The nodes must be connected through a high-speed network that facilitates efficient communication and data exchange between them.
-
Coordination: The nodes must have a mechanism to coordinate their activities and manage tasks, such as load balancing, process distribution, or resource sharing. This may involve using distributed algorithms, middleware, or cluster management software.
-
Failover and fault tolerance: To ensure high availability, the cluster must be able to detect node or service failures and automatically reassign tasks or resources to other nodes. This may involve implementing redundant components, heartbeat monitoring, or failover mechanisms.
-
Data consistency: If the nodes in the cluster share data or access shared resources (e.g., databases, file systems), a mechanism must be in place to ensure data consistency and integrity across the nodes. This may involve using distributed file systems, replication, or other synchronization techniques.
By fulfilling these requirements, clustered systems can provide highly available services by distributing workloads, ensuring fault tolerance, and maintaining data consistency across multiple nodes.
Q. Consider a computing cluster consisting of two nodes running a database. Describe two ways in which the cluster software can manage access to the data on the disk. Discuss the benefits and disadvantages of each.
In a computing cluster with two nodes running a database, there are several ways in which the cluster software can manage access to the data on the disk. Two common approaches are shared-disk architecture and shared-nothing architecture.
- Shared-Disk Architecture:
In a shared-disk architecture, both nodes in the cluster have access to the same shared storage device, such as a SAN (Storage Area Network) or a NAS (Network-Attached Storage). The database files reside on the shared storage, and both nodes can read and write data to it.
Benefits:
- Simplified data management: Since the data resides in a single location, it is easier to manage backups, replication, and data consistency.
- Easier failover: In case one node fails, the other node can seamlessly take over the database operations, as it already has access to the same shared storage.
- Load balancing: Both nodes can actively process database queries, allowing for better utilization of resources and load balancing.
Disadvantages:
- Single point of failure: The shared storage can become a single point of failure if it is not designed with sufficient redundancy and fault tolerance.
- Performance bottlenecks: Contention for the shared storage resources can lead to performance bottlenecks, especially in high-traffic scenarios or when concurrent access is required.
- Scalability: Scaling the system may require expensive upgrades to the shared storage infrastructure or more sophisticated data management techniques.
- Shared-Nothing Architecture:
In a shared-nothing architecture, each node in the cluster has its own local storage, and the data is partitioned or sharded across the nodes. Each node is responsible for managing its own portion of the data, and communication between nodes is done over the network.
Benefits:
- Scalability: The shared-nothing architecture can scale more easily, as adding more nodes also increases storage capacity and processing power.
- Performance: Since each node manages its own data, there is less contention for storage resources, which can lead to better performance and throughput.
- No single point of failure: Each node operates independently, which reduces the risk of a single point of failure affecting the entire system.
Disadvantages:
- Data consistency: Ensuring data consistency across the nodes can be more challenging, as updates need to be propagated between nodes or managed through distributed transactions.
- Complex data management: Data management tasks such as backups, replication, or re-sharding can be more complex due to the distributed nature of the data.
- Failover complexity: Implementing failover mechanisms may require more sophisticated techniques, such as data replication or distributed consensus algorithms, to ensure that the nodes can take over each other's responsibilities in case of failure.
In summary, the shared-disk architecture provides a more centralized approach to data management, with both nodes having access to the same storage, while the shared-nothing architecture relies on a distributed approach with each node managing its own local storage. Each architecture has its own set of benefits and disadvantages, and the choice between them depends on factors such as scalability, performance, fault tolerance, and data management requirements.
Q. 인터럽트의 목적은 무엇인가요? 인터럽트와 트랩의 차이점은 무엇인가요? 사용자 프로그램에서 의도적으로 트랩을 생성할 수 있나요? 그렇다면 어떤 목적으로 사용되나요?
인터럽트의 목적은 프로세서가 현재 실행 중인 작업을 일시 중지하고 긴급하거나 중요한 이벤트를 처리할 수 있도록 하는 것입니다. 이를 통해 프로세서는 예기치 않은 상황에 신속하게 대응하거나 입출력 장치와 같은 주변 장치와 효율적으로 상호 작용할 수 있습니다.
인터럽트와 트랩의 주요 차이점은 발생 원인과 사용 목적입니다. 인터럽트는 보통 외부 이벤트(예: 주변 장치로부터의 신호)에 의해 발생하며, 시스템이 해당 이벤트를 처리하기 위해 현재 작업을 중지해야 할 때 사용됩니다. 반면 트랩은 주로 소프트웨어에서 발생한 예외 상황이나 사용자 프로그램에서 명시적으로 발생시키는 이벤트에 의해 발생합니다.
네, 사용자 프로그램은 의도적으로 트랩을 생성할 수 있습니다. 일반적으로 이러한 목적으로 사용되는 경우는 다음과 같습니다:
-
시스템 호출: 사용자 프로그램이 운영 체제의 서비스를 요청할 때, 트랩을 사용하여 커널 모드로 전환하고 운영 체제의 관련 루틴을 실행할 수 있습니다.
-
디버깅 및 오류 처리: 사용자 프로그램에서 예외 상황이 발생할 경우 트랩을 사용하여 오류를 검출하고 처리할 수 있습니다. 이를 통해 프로그램이 안정적으로 실행되도록 보장하거나 디버깅 정보를 제공할 수 있습니다.
이처럼 인터럽트와 트랩은 시스템에서 발생하는 다양한 이벤트를 처리하기 위한 메커니즘으로 사용되며, 각각 외부 및 내부 이벤트에 대응하는 역할을 담당합니다.
Q. 리눅스 커널 변수 HZ와 jiffies를 사용하여 시스템이 부팅된 이후 실행된 초 단위 시간을 어떻게 결정할 수 있는지 설명하십시오.
리눅스 커널에서 HZ와 jiffies 변수는 시스템의 시간 추적에 사용됩니다. 이 변수들은 시스템이 부팅된 이후 실행된 시간을 계산하는 데 사용할 수 있습니다.
HZ는 리눅스 커널에서 사용하는 타이머 인터럽트 빈도를 나타내는 값입니다. HZ 값은 초당 타이머 인터럽트가 발생하는 횟수를 의미합니다. 예를 들어, HZ가 100이라면, 커널은 초당 100번의 타이머 인터럽트를 처리합니다.
jiffies는 커널이 부팅된 이후 발생한 타이머 인터럽트의 횟수를 저장하는 변수입니다. 시스템이 부팅될 때 0으로 초기화되고, HZ 값에 따라 초당 일정한 횟수만큼 증가합니다.
따라서 HZ와 jiffies 값을 사용하여 시스템이 부팅된 이후 실행된 시간(초 단위)을 계산할 수 있습니다. 계산 방법은 다음과 같습니다:
- jiffies 값을 HZ 값으로 나눕니다.
- 결과는 시스템이 부팅된 이후 경과한 초 단위 시간입니다.
예를 들어, HZ가 100이고 jiffies 값이 50,000이라면, 시스템이 부팅된 이후 약 500초(50,000 / 100)가 경과한 것입니다.
이렇게 HZ와 jiffies 변수를 사용하면, 시스템이 부팅된 이후 경과한 시간을 쉽게 계산할 수 있습니다.
Q. 직접 메모리 액세스(DMA)는 고속 입출력 장치를 위해 사용되며, 이를 통해 CPU의 실행 부하를 증가시키지 않습니다.
a. CPU는 전송을 조정하기 위해 장치와 어떻게 인터페이스를 맺습니까?
b. CPU는 메모리 작업이 완료되었음을 어떻게 알 수 있습니까?
c. DMA 컨트롤러가 데이터를 전송하는 동안 CPU는 다른 프로그램을 실행할 수 있습니다. 이 프로세스가 사용자 프로그램의 실행과 상호 작용합니까? 그렇다면 어떤 형태의 간섭이 발생합니까?a. CPU는 전송을 조정하기 위해 DMA 컨트롤러와 인터페이스를 맺습니다. CPU는 초기에 DMA 컨트롤러에 명령을 전달하여 전송을 시작하게 합니다. 이 명령에는 소스 및 대상 메모리 주소, 전송할 데이터의 크기, 전송 방향(읽기 또는 쓰기) 등의 정보가 포함됩니다. 이후 DMA 컨트롤러가 전송을 직접 관리하고, CPU는 다른 작업을 계속 수행할 수 있습니다.
b. 메모리 작업이 완료되면 DMA 컨트롤러는 인터럽트를 발생시켜 CPU에 알립니다. 이 인터럽트를 통해 CPU는 전송이 완료되었음을 인지하고, 필요한 후속 작업을 수행할 수 있습니다.
c. DMA 컨트롤러가 데이터를 전송하는 동안 CPU는 다른 프로그램을 실행할 수 있지만, 이 프로세스는 사용자 프로그램의 실행과 일부 상호 작용할 수 있습니다. 상호 작용의 주요 형태는 다음과 같습니다:
- 메모리 대역폭 경쟁: DMA 전송과 사용자 프로그램이 동시에 메모리에 액세스하려고 할 때 메모리 대역폭에 대한 경쟁이 발생할 수 있습니다. 이로 인해 사용자 프로그램의 실행 속도가 저하될 수 있습니다.
- 캐시 일관성 문제: DMA 전송이 캐시 메모리와 메인 메모리 간의 데이터 일관성 문제를 일으킬 수 있습니다. 사용자 프로그램이 최신 데이터에 액세스하려면 캐시 일관성을 유지키는 메커니즘이 필요합니다. 이러한 메커니즘은 사용자 프로그램의 실행에 추가적인 오버헤드를 발생시킬 수 있습니다.
이렇게 DMA 전송 과정이 사용자 프로그램의 실행과 상호 작용할 수 있지만, 이러한 상호 작용은 일반적으로 CPU가 입출력 작업을 직접 처리하는 것보다 훨씬 더 적은 부하를 발생시킵니다. 따라서 시스템 전체의 성능과 효율성이 향상됩니다.
Q. 일부 컴퓨터 시스템은 하드웨어에서 특권 모드를 제공하지 않습니다. 이러한 컴퓨터 시스템에 대해 안전한 운영 체제를 구축할 수 있을까요? 가능하다는 주장과 불가능하다는 주장을 모두 제시하십시오.
가능하다는 주장:
특권 모드가 없는 컴퓨터 시스템에서도 소프트웨어 기반의 보안 메커니즘을 사용하여 상대적으로 안전한 운영 체제를 구축할 수 있습니다. 이러한 메커니즘에는 시스템 호출을 통한 리소스 액세스 제어, 애플리케이션 간 격리, 메모리 보호 및 인증을 사용하여 민감한 데이터를 보호하는 것이 포함될 수 있습니다. 소프트웨어 기반의 보안 메커니즘은 하드웨어 기반의 특권 모드만큼 강력하지는 않겠지만, 적절한 정책과 프로세스를 구현하면 시스템의 보안을 어느 정도 향상시킬 수 있습니다.
불가능하다는 주장:
특권 모드가 없는 컴퓨터 시스템에서는 안전한 운영 체제를 완전히 구축하기 어렵습니다. 특권 모드는 사용자 프로그램과 운영 체제 간에 명확한 경계를 제공하며, 이를 통해 리소스에 대한 무단 액세스와 시스템의 악용을 방지할 수 있습니다. 특권 모드가 없는 경우, 사용자 프로그램이 운영 체제의 리소스와 데이터에 대한 무제한 액세스 권한을 가질 수 있으며, 이로 인해 보안이 크게 저하됩니다. 소프트웨어 기반의 보안 메커니즘은 하드웨어 지원이 없는 상황에서는 제한적인 효과만을 발휘할 수 있으며, 시스템을 완벽하게 보호하기 어렵습니다.
결론적으로, 특권 모드가 없는 컴퓨터 시스템에서 완전한 보안을 제공하는 것은 매우 어렵지만, 소프트웨어 기반의 메커니즘을 사용하여 시스템의 보안 수준을 어느 정도 개선할 수 있습니다. 그러나 이러한 소프트웨어 기반의 보안 메커니즘은 하드웨어에서 지원되는 특권 모드만큼 강력하지 않아 완벽한 보안을 제공하는 데 한계가 있습니다. 따라서 특권 모드가 없는 컴퓨터 시스템에서 안전한 운영 체제를 구축하는 것은 어렵지만, 최선의 보안 방법과 정책을 적용함으로써 가능한 한 보안 수준을 높일 수 있습니다.
Q. 많은 SMP 시스템에는 캐시의 다양한 수준이 있습니다. 한 수준은 각 처리 코어에 로컬로 있고, 다른 수준은 모든 처리 코어간에 공유됩니다. 캐싱 시스템이 왜 이렇게 설계되었을까요?
캐싱 시스템은 이러한 방식으로 설계되어 처리 속도를 높이고 전체 시스템 성능을 향상시키기 위함입니다. 캐시에는 다음과 같은 이점이 있습니다:
-
로컬 캐시: 각 처리 코어에 로컬 캐시가 있는 경우, 해당 코어에서 실행되는 프로세스는 로컬 캐시를 통해 빠르게 데이터에 액세스할 수 있습니다. 로컬 캐시를 사용하면 메모리 대역폭을 절약하고 해당 코어의 데이터 접근 지연을 최소화하여 성능을 향상시킵니다.
-
공유 캐시: 모든 처리 코어 사이에 공유되는 공유 캐시는 코어 간의 데이터 공유를 촉진하며, 다양한 코어에서 사용되는 공통 데이터를 더 효율적으로 캐싱할 수 있습니다. 공유 캐시를 통해 여러 코어가 동시에 동일한 데이터를 사용할 때 발생할 수 있는 메모리 접근 경쟁을 줄일 수 있습니다.
이러한 계층적 캐시 설계는 처리 코어 간의 효율적인 데이터 공유와 동시에 개별 코어의 성능을 향상시키기 위해 사용됩니다. 이를 통해 전체 시스템의 성능과 확장성이 높아집니다.
Q. 다음 저장 시스템을 가장 느린 것부터 가장 빠른 것까지 순서대로 나열하십시오:
a. 하드디스크 드라이브
b. 레지스터
c. 광 디스크
d. 주 메모리
e. 비휘발성 메모리
f. 자기 테이프
g. 캐시저장 시스템의 속도 순위는 다음과 같습니다:
1. f. 자기 테이프
2. c. 광 디스크
3. a. 하드디스크 드라이브
4. e. 비휘발성 메모리
5. d. 주 메모리
6. g. 캐시
7. b. 레지스터이 순서는 일반적인 경우에 해당되며, 각 기술의 구현에 따라 성능 차이가 있을 수 있습니다.
Q. 그림 1.8과 유사한 SMP 시스템을 고려해 보십시오. 메모리에 있는 데이터가 각 로컬 캐시에서 실제로 다른 값을 가질 수 있는 방법을 예를 들어 설명하십시오.
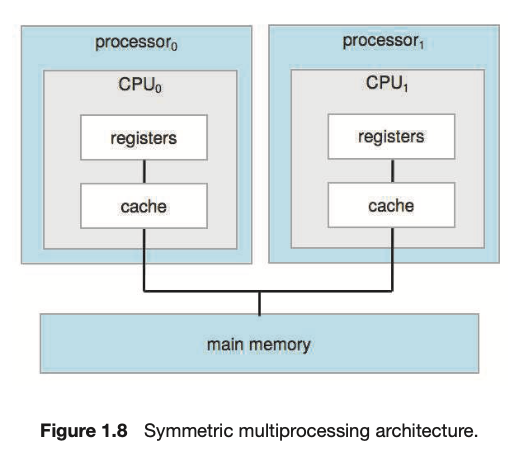
SMP 시스템에서 각 처리 코어는 고유한 로컬 캐시를 가지고 있습니다. 이로 인해 메모리에 있는 데이터가 각 로컬 캐시에서 다른 값을 가질 수 있습니다. 예를 들어 다음과 같은 상황을 생각해 보겠습니다.
메모리 주소 A에 데이터 값 X가 저장되어 있습니다. 코어 1과 코어 2가 이 값을 처음 읽을 때, 각각의 로컬 캐시에 주소 A의 값으로 X가 저장됩니다. 이후 코어 1이 주소 A의 값을 X에서 Y로 변경하고자 한다면, 코어 1의 로컬 캐시에서만 값이 변경되고 메모리와 코어 2의 로컬 캐시에는 여전히 이전 값인 X가 남아 있게 됩니다.
이 상황에서 코어 2가 다시 주소 A를 읽으면, 자신의 로컬 캐시에 있는 이전 값인 X를 읽게 되므로, 코어 1의 로컬 캐시에서는 값 Y가 있고, 코어 2의 로컬 캐시에서는 값 X가 있게 됩니다.
이러한 일관성 문제를 해결하기 위해 캐시 일관성 프로토콜들이 존재합니다. 이 프로토콜들은 여러 코어의 로컬 캐시 사이에서 데이터의 일관성을 유지하도록 설계되어 있습니다.
Q. 다음 처리 환경에서 캐시된 데이터의 일관성을 유지하는 문제가 어떻게 나타나는지 예를 들어 설명하십시오:
a. 단일 프로세서 시스템
b. 다중 프로세서 시스템
c. 분산 시스템a. 단일 프로세서 시스템:
단일 프로세서 시스템에서 캐시 일관성 문제는 상대적으로 간단합니다. 프로세서는 메모리와 I/O 장치 사이에 캐시를 사용하여 데이터에 빠르게 액세스할 수 있습니다. 캐시가 최신 상태를 유지하도록 관리되면, 일관성 문제는 발생하지 않습니다. 예를 들어, 프로세서가 메모리에서 데이터를 수정한 후에는 캐시의 해당 항목을 업데이트하거나 무효화하면 됩니다.
b. 다중 프로세서 시스템:
다중 프로세서 시스템에서는 각 프로세서가 자체 캐시를 가지므로, 캐시 일관성 문제가 복잡해집니다. 여러 프로세서가 동일한 메모리 위치에 액세스하고 수정할 경우, 각 프로세서의 캐시에 다른 값이 저장될 수 있습니다. 이 문제를 해결하기 위해 캐시 일관성 프로토콜이 필요합니다. 예를 들어, 메시 프로토콜이나 스누피 버스 프로토콜과 같은 프로토콜을 사용하여 캐시 간의 데이터 일관성을 유지할 수 있습니다.
c. 분산 시스템:
분산 시스템에서는 여러 컴퓨터가 네트워크를 통해 연결되어 있어 데이터 일관성 유지가 더 어렵습니다. 각 컴퓨터가 자체 캐시와 메모리를 가지므로, 네트워크를 통해 공유되는 데이터의 일관성을 유지하는 것이 중요합니다. 분산 시스템에서 데이터 일관성을 유지하기 위해 분산 락이나 분산 트랜잭션과 같은 메커니즘이 사용됩니다. 예를 들어, 분산 데이터베이스에서는 데이터 레플리케이션 및 쿼럼 기반의 동의 프로토콜을 사용하여 데이터 일관성을 유지할 수 있습니다. 또한 분산 시스템에서는 두 단계 커밋 프로토콜과 같은 트랜잭션 관리 메커니즘을 사용하여 여러 노드 간의 데이터 일관성을 보장합니다.
요약하면, 캐시된 데이터의 일관성을 유지하는 문제는 처리 환경에 따라 다양한 방식으로 나타납니다. 단일 프로세서 시스템에서는 캐시 일관성 관리가 비교적 간단하지만, 다중 프로세서 시스템과 분산 시스템에서는 캐시 일관성 프로토콜 및 분산 데이터 관리 메커니즘이 필요합니다. 이러한 메커니즘을 통해 시스템 전체에서 데이터 일관성을 보장하고 성능을 향상시킬 수 있습니다.
Q. 다른 프로그램과 관련된 메모리를 수정하는 것을 방지하기 위해 메모리 보호를 강제하는 메커니즘을 설명하십시오.
메모리 보호를 강제하는 한 가지 메커니즘은 '페이지 테이블'과 '페이지 디렉토리'를 사용하는 가상 메모리 시스템입니다. 이 메커니즘은 논리적 주소를 물리적 주소로 변환하는 과정에서 메모리 접근 권한을 확인하여 메모리 보호를 제공합니다.
페이지 테이블에는 각 페이지에 대한 정보와 함께 접근 권한이 포함되어 있습니다. 접근 권한은 읽기, 쓰기, 실행 등이 포함될 수 있습니다. 프로세스가 메모리에 액세스하려고 할 때, 가상 메모리 시스템은 먼저 페이지 테이블을 참조하여 해당 프로세스가 요청한 메모리 주소에 대한 권한을 확인합니다. 권한이 없는 경우, 페이지 폴트가 발생하고 운영 체제가 이를 처리합니다.
이렇게 하면 프로세스가 다른 프로세스와 관련된 메모리 영역을 읽거나 수정하는 것을 방지할 수 있습니다. 예를 들어, 프로세스 A가 프로세스 B의 메모리 영역에 액세스하려고 할 때, 페이지 테이블을 확인하여 프로세스 A가 해당 메모리 영역에 대한 접근 권한이 없음을 발견하고 액세스를 거부할 것입니다. 이 방식을 통해 메모리 보호가 강화되어 시스템의 안전성이 향상됩니다.
Q. 다음 환경에 가장 적합한 네트워크 구성 - LAN 또는 WAN -은 무엇일까요?
a. 캠퍼스 학생회관
b. 전국적인 대학 체제를 가로질러 여러 캠퍼스 위치
c. 이웃 동네a. 캠퍼스 학생회관:
학생회관은 일반적으로 한 건물 또는 캠퍼스 내의 가까운 건물들로 구성되어 있습니다. 이러한 경우 LAN(지역 네트워크)이 이러한 환경에 가장 적합합니다. LAN은 건물 내에서 높은 데이터 전송 속도와 저렴한 비용으로 효율적인 네트워크 연결을 제공합니다.
b. 전국적인 대학 체제를 가로질러 여러 캠퍼스 위치:
여러 지역에 분산된 캠퍼스 위치의 경우 WAN(광역 네트워크)이 더 적합합니다. WAN은 광대역 인터넷 및 전용 회선을 사용하여 거리가 먼 지점 간에 네트워크 연결을 제공합니다. 이를 통해 여러 캠퍼스 간의 통신 및 데이터 공유가 가능해집니다.
c. 이웃 동네:
이웃 동네의 경우 LAN과 WAN 중 어떤 것이 더 적합한지는 동네의 크기와 구성에 따라 달라집니다. 작은 이웃이나 아파트 단지와 같은 경우 LAN이 적합할 수 있습니다. 그러나 도시 전체를 포함하는 규모가 큰 이웃의 경우, WAN이 더 적합할 수 있습니다. 이러한 경우에는 인터넷 서비스 제공자(ISP)를 통해 인터넷 접속 및 외부 네트워크 연결을 제공하는 것이 일반적입니다.
Q. 모바일 기기용 운영 체제를 설계하는 것이 전통적인 PC용 운영 체제를 설계하는 것과 비교하여 어떤 도전이 있는지 설명하십시오.
모바일 기기용 운영 체제를 설계할 때 전통적인 PC용 운영 체제와 비교하여 다음과 같은 몇 가지 도전이 있습니다.
-
자원 제한: 모바일 기기는 전통적인 PC에 비해 제한된 처리 능력, 메모리 및 저장 공간을 가지고 있습니다. 따라서 모바일 운영 체제는 이러한 제한된 자원을 효율적으로 관리해야 합니다.
-
에너지 효율: 모바일 기기는 배터리로 작동하기 때문에 에너지 효율이 매우 중요합니다. 운영 체제는 저전력 모드, 백그라운드 앱 관리 및 하드웨어 자원 사용 최적화와 같은 기능을 통해 에너지 소비를 최소화해야 합니다.
-
사용자 인터페이스: 모바일 기기는 작은 화면 크기와 터치 스크린을 통한 상호 작용을 특징으로 합니다. 이러한 특성으로 인해, 모바일 운영 체제는 사용자 친화적이고 직관적인 인터페이스를 제공해야 합니다.
-
센서 관리: 모바일 기기는 GPS, 가속도계, 자이로스코프 등 다양한 센서를 내장하고 있습니다. 운영 체제는 이러한 센서들과 상호 작용하고, 앱이 이러한 센서를 효율적으로 사용할 수 있도록 관리해야 합니다.
-
보안 및 개인 정보 보호: 모바일 기기는 개인 정보가 저장되고 공유되는 중요한 플랫폼이므로, 운영 체제는 데이터 보안 및 개인 정보 보호에 중점을 둬야 합니다. 이는 암호화, 권한 관리 및 보안 업데이트와 같은 다양한 메커니즘을 통해 이루어집니다.
-
앱 생태계: 모바일 운영 체제는 다양한 앱과 호환되어야 하며, 앱 개발자가 쉽게 앱을 개발하고 배포할 수 있는 플랫폼을 제공해야 합니다. 이를 위해 운영 체제는 개발 도구, API 및 앱 스토어와 같은 인프라를 구축해야 합니다.
-
네트워크 연결: 모바일 기기는 다양한 네트워크 연결 옵션을 제공하며(셀룰러, Wi-Fi, Bluetooth 등), 이러한 연결을 통한 통신을 효율적으로 관리해야 합니다. 운영 체제는 네트워크 연결 상태를 모니터링하고, 끊김 없는 통신을 위해 자동 전환 기능을 제공해야 합니다.
-
업데이트 관리: 모바일 기기는 사용자가 손쉽게 시스템 및 앱 업데이트를 받을 수 있어야 합니다. 따라서 운영 체제는 업데이트 프로세스를 간소화하고, 사용자에게 최신 보안 패치와 기능 개선을 제공해야 합니다.
이러한 도전을 극복함으로써, 모바일 기기용 운영 체제는 사용자에게 효율적이고 안전한 컴퓨팅 환경을 제공할 수 있습니다.
Q. 피어 투 피어 시스템이 클라이언트-서버 시스템보다 가지는 몇 가지 장점은 무엇인가요?
피어 투 피어(P2P) 시스템은 클라이언트-서버 시스템에 비해 다음과 같은 몇 가지 장점을 가지고 있습니다:
-
분산 처리: 피어 투 피어 시스템은 여러 노드가 서로 협력하여 처리를 수행하기 때문에 단일 서버에 대한 의존성이 없습니다. 이를 통해 시스템의 내구성과 가용성이 높아집니다.
-
확장성: 피어 투 피어 시스템은 새로운 노드가 쉽게 추가되거나 제거될 수 있으므로, 시스템의 규모를 빠르게 확장하거나 축소할 수 있습니다.
-
자원 공유: 피어 투 피어 시스템에서는 각 노드가 자원을 제공하고 사용할 수 있기 때문에, 전체 시스템의 자원 사용 효율이 높아집니다.
-
비용 절감: 전용 서버의 구축과 유지 비용이 높은 반면, 피어 투 피어 시스템에서는 노드 간의 직접적인 통신을 통해 이러한 비용을 절감할 수 있습니다.
-
부하 분산: 피어 투 피어 시스템에서는 요청이 여러 노드로 분산되므로, 단일 서버에 부하가 집중되는 것을 방지할 수 있습니다. 이를 통해 시스템의 전체 성능이 향상됩니다.
-
결함 허용성: 피어 투 피어 시스템에서는 한 노드가 실패하더라도 다른 노드가 해당 작업을 수행할 수 있으므로, 시스템의 결함 허용성이 높아집니다.
그러나 피어 투 피어 시스템은 보안, 데이터 무결성 및 중앙 집중식 관리의 어려움과 같은 몇 가지 단점도 가지고 있습니다. 이러한 단점을 고려하여 특정 애플리케이션에 가장 적합한 시스템을 결정해야 합니다.
피어 투 피어 시스템은 적절한 사용 사례에 맞게 설계되고 구현된 경우 많은 장점을 제공할 수 있습니다. 그러나 이러한 장점이 항상 클라이언트-서버 시스템보다 우월하다고 할 수는 없으며, 각 시스템의 특성과 요구 사항에 따라 적절한 구조를 선택해야 합니다.
Q. 피어 투 피어 시스템에 적합한 분산 애플리케이션을 설명하십시오.
피어 투 피어(P2P) 시스템에 적합한 몇 가지 분산 애플리케이션은 다음과 같습니다:
-
파일 공유: 파일 공유 애플리케이션(예: BitTorrent)은 사용자가 서로에게 직접 파일을 전송하고 공유할 수 있는 P2P 기반 시스템입니다. 이를 통해 대량의 파일을 빠르게 전송할 수 있으며, 중앙 서버에 의존하지 않습니다.
-
분산 컴퓨팅: 분산 컴퓨팅 프로젝트(예: SETI@home, Folding@home)는 여러 컴퓨터의 처리 능력을 활용하여 복잡한 문제를 해결하는 데 사용됩니다. 이러한 시스템은 피어 투 피어 아키텍처를 사용하여 처리 작업을 여러 노드로 분산시킬 수 있습니다.
-
메시 네트워킹: 메시 네트워크는 무선 기기 간에 직접적인 통신 경로를 구축하여 데이터 전송을 가능하게 하는 피어 투 피어 기반 시스템입니다. 이를 통해 전통적인 인터넷 인프라에 의존하지 않고 통신할 수 있습니다.
-
콘텐츠 전송 네트워크(CDN): 콘텐츠 전송 네트워크는 웹 콘텐츠를 전세계의 여러 노드에 분산시켜 가까운 노드에서 사용자에게 전달하는 시스템입니다. 피어 투 피어 기반의 CDN은 사용자가 서로의 콘텐츠를 공유하고 전송하는 데 도움이 됩니다.
-
분산 데이터 저장소: 분산 데이터 저장소(예: InterPlanetary File System)는 데이터를 여러 노드에 분산시켜 저장하는 피어 투 피어 기반 시스템입니다. 이를 통해 데이터의 가용성과 내구성이 향상됩니다.
피어 투 피어 시스템은 이러한 분산 애플리케이션에 적합한 구조를 제공급하며, 중앙 서버에 대한 의존성을 줄이고 확장성을 높입니다. 이러한 시스템은 사용자와 리소스가 동적으로 변화할 때 특히 유용하며, 적절한 관리와 보안 조치가 적용되면 고성능의 분산 시스템을 구축할 수 있습니다. 그러나 피어 투 피어 시스템은 사용자 및 리소스가 고르게 분산되어 있지 않을 경우 성능 저하, 보안 문제 등의 단점이 있을 수 있으므로, 특정 애플리케이션에 맞는 적절한 시스템 구조를 선택하는 것이 중요합니다.
Q. 오픈소스 운영 체제의 몇 가지 장점과 단점을 찾아보고, 각 측면을 장점 또는 단점으로 생각하는 사람들의 유형을 파악하십시오.
오픈소스 운영 체제의 장점:
- 비용 절감: 오픈소스 운영 체제는 무료로 사용할 수 있어 비용을 절감할 수 있습니다. 이는 개인 사용자, 학생, 중소기업, 비영리 기관 등에게 이점이 될 수 있습니다.
- 사용자 정의 가능: 오픈소스 운영 체제는 소스 코드에 액세스할 수 있기 때문에 사용자가 시스템을 필요에 따라 자유롭게 수정하고 개선할 수 있습니다. 이는 개발자, 연구원, 시스템 관리자 등에게 유용할 수 있습니다.
- 커뮤니티 지원: 오픈소스 운영 체제는 전 세계 개발자 및 사용자들이 참여하는 커뮤니티에서 지원을 받습니다. 이는 문제 해결, 기능 개선 등에 도움이 될 수 있습니다. 이는 일반 사용자, 개발자, 시스템 관리자 등에게 이점이 될 수 있습니다.
오픈소스 운영 체제의 단점:
- 제한된 기술 지원: 오픈소스 운영 체제는 대형 기업의 상용 운영 체제만큼 공식 기술 지원이 제한적일 수 있습니다. 이는 기업, 정부 기관 등 공식 지원이 필요한 조직에게 단점이 될 수 있습니다.
- 호환성 문제: 오픈소스 운영 체제는 상용 운영 체제만큼 완벽한 하드웨어 및 소프트웨어 호환성을 보장하지 않을 수 있습니다. 이는 일반 사용자, 기업, 시스템 관리자 등에게 문제가 될 수 있습니다.
- 학습 곡선: 오픈소스 운영 체제는 종종 새로운 사용자에게 익숙하지 않은 사용자 인터페이스 및 도구를 사용할 수 있어 학습 곡선이 높을 수 있습니다. 이는 비전문가 사용자에게 단점이 될 수 있습니다.
