Web crawling
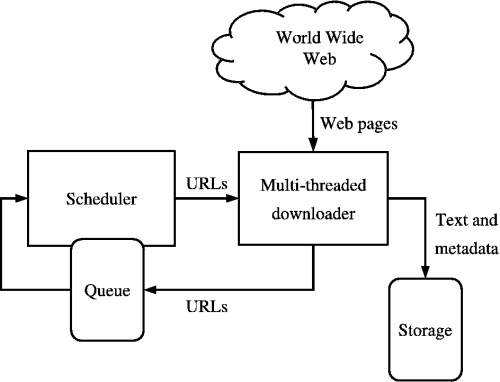
웹 크롤링이란?
웹 크롤링이란 웹상에서 존재하는 정보들을 수집하는 작업을 말한다.
웹 크롤러(web crawler)는 조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램이다. 웹 클로러에 대한 다른 용어로는 앤트(ant), 자동 인덱서(automatic indexers), 봇(bots), 웜(worms), 웹 스파이더(web spider), 웹 로봇(web robot) 등이 있다.
웹 크롤러는 봇이나 소프트웨어 에이전트의 한 형태이다
웹 크롤러가 하는 작업을 웹 크롤링(web crawling)혹은 스파이더링(spidering)이라 부른다. 검색 엔진과 같은 여러 사이트에서는 데이터의 최신 상태 유지를 위해 웹 크롤링한다.
웹 크롤러는 전문 검색을 제공하는 최초의 웹 검색 엔진이었다. 1995년 6월 1일 아메리카 온라인에 의해 인수되었다가 1997년 4월 1일 익사이트에 판매되었다. 웹 크롤러는 익사이트가 파산한 이후 2001년 인포스페이스에 인수되었다. 인포스페이스는 메타 검색 엔진 도그파일과 메타 크롤러를 소유하고 운영한다.
기능
웹 크롤러는 대체로 방문한 사이트의 모든 페이지의 복사본을 생성하는 데 사용되며, 검색엔진은 이렇게 생성된 페이지를 보다 빠른 검색을 위해 인덱싱한다. 또한 크롤러는 링크 체크나 HTML 코드 검증과 같은 웹 사이트의 자동 유지 관리 작업을 위해 사용 되기도 하며, 자동 이메일 수집과 같은 웹 페이지의 특정 형태의 정보를 수집하는 데도 사용된다.
웹 크롤러는 봇이나 소프트웨어 에이전트의 한 형태이다. 웹 크롤러는 대개 시드(seeds)라고 불리는 URL 리스트에서부터 시작하는데, 페이지의 모든 하이퍼링크를 인식하여 URL리스트를 갱신한다. 갱한된 URL 리스트는 재귀적으로 다시 방문한다. 이때 한 페이지만 방문하는 것이 아니라 그 페이지에 링크되어 있는 또 다른 페이지를 차례대로 방문하고 이처럼 링크를 따라 웹을 돌아다니는 모습이 마치 거미와 비슷하다고 해서 스파이더라고 부르기도 합니다. 엄청난 분량의 웹문서를 사람이 일일이 구별해서 모으는 일은 불가능에 가깝습니다. 때문에 웹 문서 검색에서는 사람이 일일이 하는 대신 이를 자동으로 수행해 줍니다. 웹 크롤러 크롤링의 다른 명칭은 'Web Scraping', 'web harvesting','web data extraction'입니다.
머신러닝, 딥러닝에서 학습데이터를 구하기 위해 빅데이터, 데이터 분석에 대한 수요가 증가하고 이에 따라 자료를 얻는 원천으로 웹을 많이 이용합니다. 웹에서 데이터를 수집하고 분석을 위한 형태로 자료의 형태로 바꾸는 것이 바로 웹 크롤링입니다.
파이썬에서 웹 크롤링을 하기 위해서는 BeautifulSoup, Selenium과 같은 도구를 사용해야 합니다. BeautifulSoup은 HTML및 XML 파일에서 원하느 데이터를 손쉽게 Parsing 할 수 있는 Python라이브러리 입니다. 웹 문서의 구조를 찾아내는 파서를 이용해 찾고자 하는 데이터의 위치를 찾아 내어 값을 추출합니다.
크롤링을 활용한 사례
기업의 고객정보 및 마케팅 정보, 금융 데이터, 국내 지리정보와 같은 데이터들의 공통점은 무엇일까요?
바로 데이터의 양이 어마어마하다는 것입니다. 이러한 데이터를 분석하는 과정에서의 단순 반복과정을 기술의 도움없이 진행한다면 일의 효율성이 떨어지게 될 것입니다. 각종 비즈니스 모델을 만드는 것의 시작은 데이터를 수집하는 것으로부터 시작하는 만큼 크롤링은 4차 산업혁명 시대의 주요한 대응 전량으로 손꼽히고 있습니다.
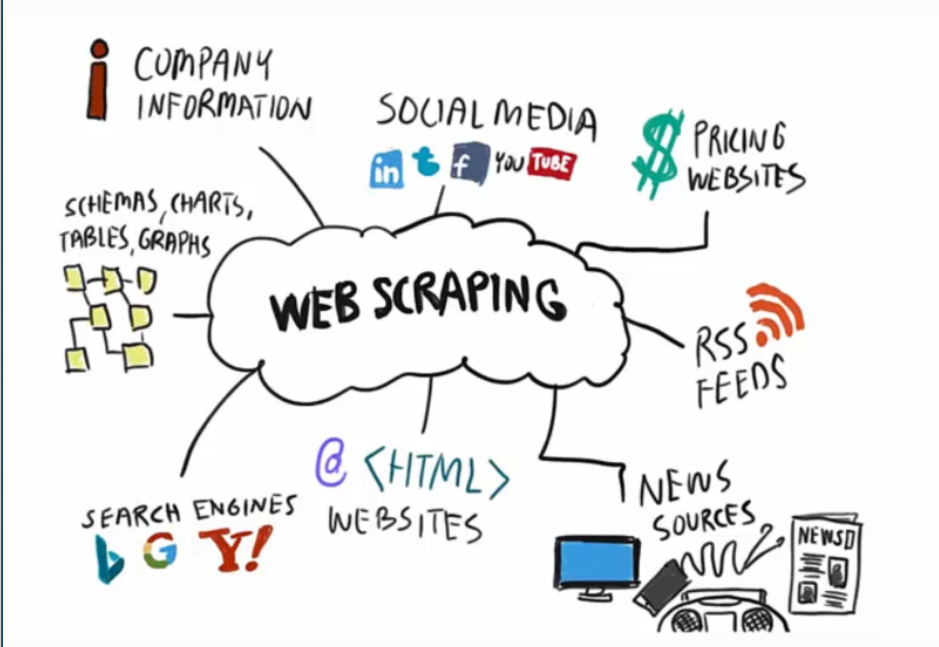
웹 크롤링을 통해 가지고 올 수 있는 정보의 종류에는 HTML 기반의 웹 사이트, 이미지, 문서 등이 있습니다. 얻을 수 있는 정보의 종류와 양이 많아 활용 분야도 다양합니다.
자동으로 대량의 정보를 수집할 수 있는 크롤링의 장점을 활용해 다양한 대화 지식이 필요한 챗봇 구현이나 빅데이터 분석 연구에도 활용할 수 있습니다. 우리가 자주 이용하는 구글과 네이버가 다양한 검색 서비스를 제공 할 수 있는 이유도 수많은 웹 사이트를 크롤링하기 때문입니다.
