Kubernetes MIG(Multi Instance GPUs) 적용하기

Minikube Nvidia GPU 구축하고 파이프라인에 GPU를 활용해보자!
포스팅에 이어서 작성합니다.
MIG란?
위 포스팅처럼 GPU를 구축하는게 정석이고, 현재 k8s 공식문서에서 지원하는 전부이긴 하지만 포스팅에서 설명했듯 제약사항이 존재합니다.
컨테이너간의 GPU 공유가 불가능하고(순차적인 스케쥴링 필요), 1개의 GPU를 여러개로 쪼개어 분할 수행이 불가능하다는 점이죠.
이런 점 때문에 복잡한 파이프라인을 실행할 때 GPU를 기다리느라 Pod이 무한정 Pending 상태로 지속되어, 오히려 CPU로 파이프라인을 실행시킬 때보다 느려지거나, 아예 timeout이 발생해버리곤 했습니다.
이런 문제점을 해결 할 방법으로 Nvidia에서 지원을 시작한 것이 MIG(Multi Instance GPUs) 기능입니다.
GPU를 half(1/2), quarter(1/4), eighth(1/8) 혹은 메모리를 설정하여 나누어 할당하는 기능을 지원합니다.
아직 문서를 보며 사용방법을 파악하는 중인데,
이번 포스팅을 천천히 따라해보시면서 함께 해보시죠!
Prerequisites
GPU가 있는 클러스터에 하나 이상의 노드가 있고 표준 NVIDIA 드라이버 가 이미 설치되어 있다고 가정합니다.
이전 포스팅에서 Nvidia 관련 설정과 클러스터 생성을 모두 따라오셨다면 문제없이 진행하실 수 있습니다.
(+수정) NVIDIA A100, A30이 아니라면 MIG 기능이 지원되지 않습니다. 해당 GPU 이외의 것을 사용하는데 GPU를 분할 사용하고 싶다면 다음 포스팅을 참고해주세요!
또한 정상적인 기능 설치를 위해 Helm이 다운로드 되어있어야 합니다.
Helm 설치 지침은 여기를 확인하세요!
Nvidia-device-plugin 배포
이전 포스팅에서 yaml 파일을 이용해 배포한 디바이스 플러그인을 제거하고 헬름을 통해 배포합니다.
1. kubectl delete -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/master/nvidia-device-plugin.yml
- 레포를 추가하고 search를 통해 나오는 최신 버전을 설치해주세요.(저는 0.11.0으로 진행합니다)
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm search repo nvdp --devel- MIG 정책 버전을 선택해서 export 해주세요. 저는 single로 진행하겠습니다.
export MIG_STRATEGY=<none | single | mixed>
helm install \
--version=0.11.0 \
--generate-name \
--set migStrategy=${MIG_STRATEGY} \
nvdp/nvidia-device-plugin
node-feature-discovery(NFD) 배포
주의! 아래에서 Helm으로 GFD를 설치할 떄 NFD가 함께 설치되니 바로 GFD 설치 파트로 넘어가셔도 됩니다!!
첫 번째 단계는 레이블을 지정하려는 모든 노드에서 노드 기능 검색 이 실행되고 있는지 확인하는 것 입니다.
NVIDIA GPU 기능 검색은 local 소스를 사용하므로 볼륨을 마운트해야 합니다.
NFD 설치는 GFD와 병행하니 아래는 참고만 해주시고, GFD 설치로 넘어가셔도 됩니다.
node-feature-discovery(NFD)는 하드웨어 기능 및 시스템 구성을 감지하기 위한 Kubernetes add-on입니다.
GPU 노드 준비
GPU 노드에 nvidia-docker2 가 설치되어 있고 Docker 기본 런타임이 nvidia로 설정되어 있는지 확인하세요.https://github.com/NVIDIA/nvidia-docker/wiki/Advanced-topics#default-runtime 혹은 이전 포스팅을 참조하세요!
NVIDIA GPU 기능 검색(GFD) 배포
혹시 미리 NFD 설치를 진행하셨다면 kubectl delete -k https://github.com/kubernetes-sigs/node-feature-discovery/deployment/overlays/default?ref=v0.10.1 로 삭제해주세요!
- 헬름 레포지터리를 추가합니다.
- MIG 깃 허브에 yaml로 리소스를 생성하는 구문이 있는데 테스트용으로만 사용합니다.
- 프로덕션용으로는 헬름에 배포된 NFD, GFD를 사용합니다.
$ helm repo add nvgfd https://nvidia.github.io/gpu-feature-discovery
$ helm repo update
- 헬름으로 GFD, NFD를 설치합니다.(GFD에 NFD가 포함되어 설치됩니다)
$ helm install \
--version=0.5.0 \
--generate-name \
--set migStrategy=${MIG_STRATEGY} \
nvgfd/gpu-feature-discovery
-
리소스들이 정상 생성되었는지 확인합니다.
kubectl -n node-feature-discovery get all
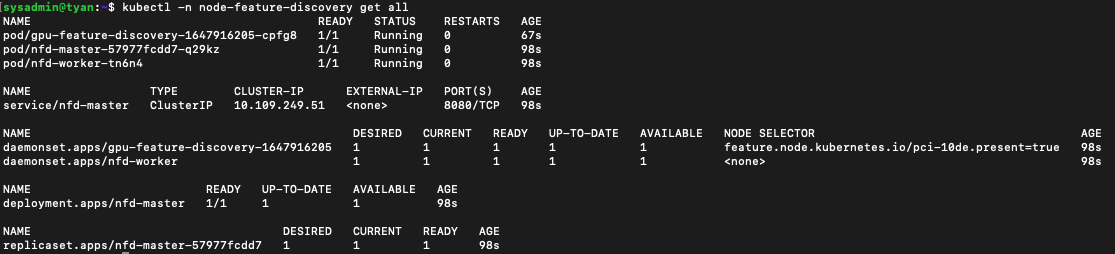
-
하드웨어 정보를 잘 가져오는지 수 있는지 확인합니다.
kubectl get no -o json | jq .items[].metadata.labels
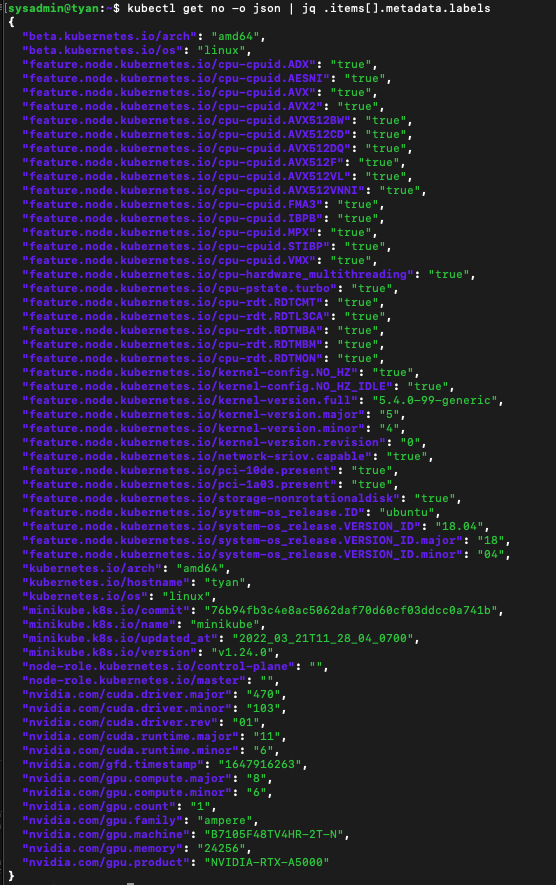
-
모든 것이 작동하는지 확인
- NFD와 GFD를 모두 배포하고 실행하면 GPU가 설치된 모든 노드에 GPU 관련 레이블이 표시되는 것을 볼 수 있습니다.(metadata.labels 쪽을 확인해보세요!)
kubectl get nodes -o yaml
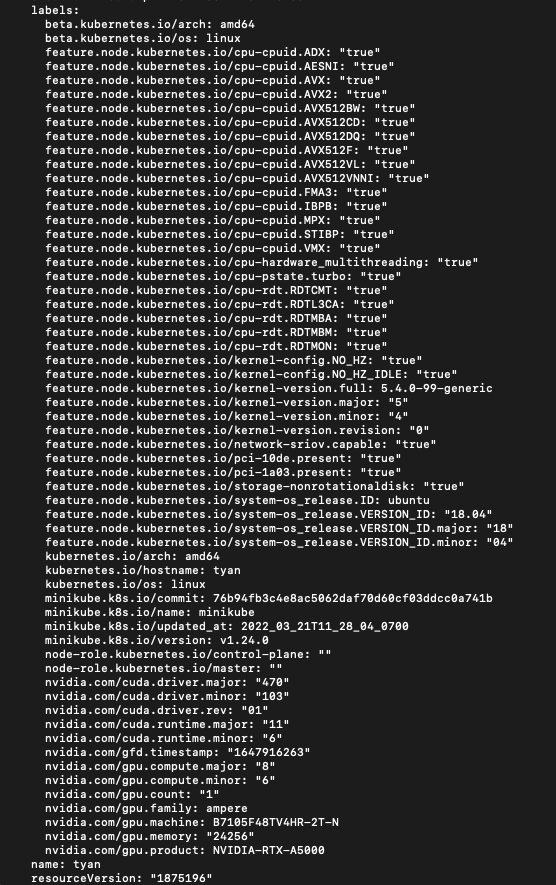
- 각 레이블에 대해선 아래서 살펴봅시다.
생성된 레이블의 의미
다음은 NVIDIA GPU Feature Discovery에 의해 생성된 레이블 목록과 그 의미입니다.
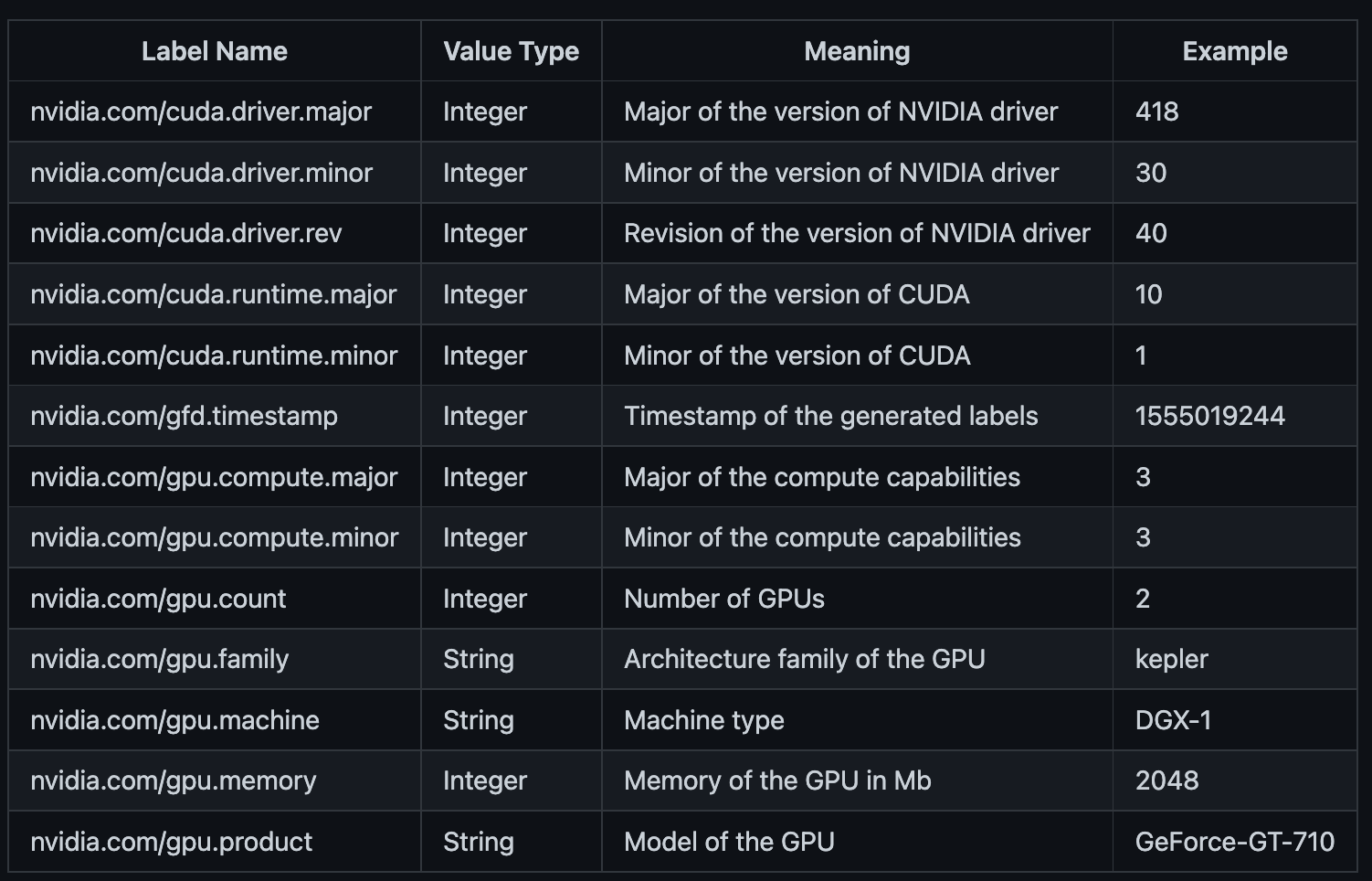
사용된 MIG 전략에 따라 다음 레이블 집합을 사용할 수도 있습니다.(또는 위에 나열된 레이블 중 일부의 기본값을 재정의)
MIG 전략
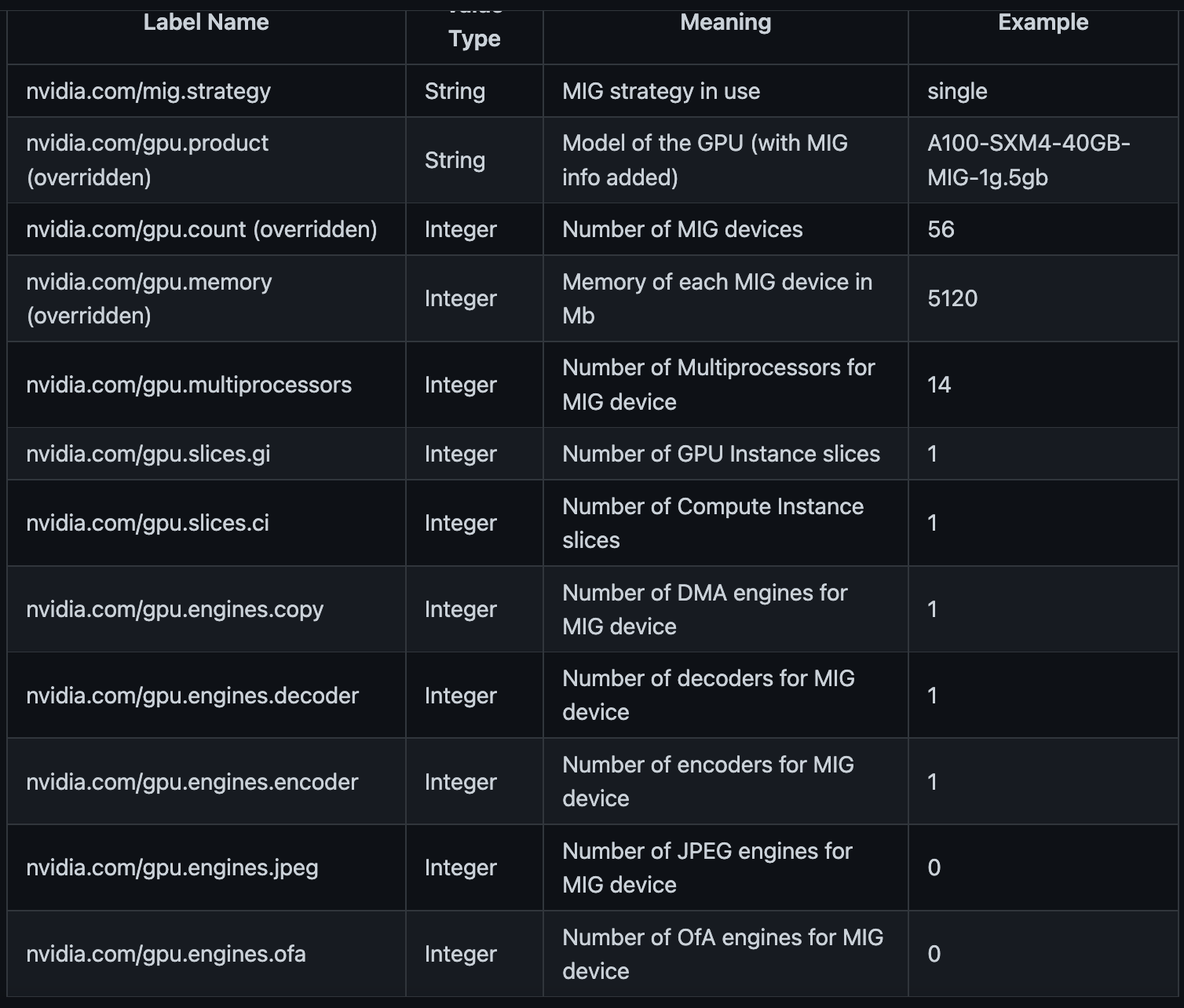
MIG 'single' strategy
single 전략을 사용하면 전체 GPU가 아닌 노드의 MIG 장치에 대한 정보를 제공하기 위해 단일 nvidia.com/gpu 레이블이 오버로드됩니다.
이전 포스팅에서 resource로 nvidia.com/gpu:1를 주면 전체(1개)의 GPU가 Pod에 할당되었죠?
이를 MIG에서 나눈 (1개를 정확히 1/n으로 나눈)크기로 오버로드할 수 있다는 이야기입니다.
노드의 모든 GPU가 동일한 크기의 동일한 파티션으로 분할되었다고 가정합시다.
아래 예는 8개의 전체 GPU가 있는 시스템에 대한 정보를 보여줍니다. 각 GPU는 7개의 동일한 크기의 MIG 장치(총 56개)로 분할됩니다.
MIG 'mixed' strategy
mixed 전략을 사용하면 각 MIG 장치 유형에 대해 별도의 레이블 집합이 생성됩니다. 각 MIG 장치 유형의 이름은 다음과 같이 정의됩니다.
MIG_TYPE=mig-<slice_count>g.<memory_size>.gb
e.g. MIG_TYPE=mig-3g.20gb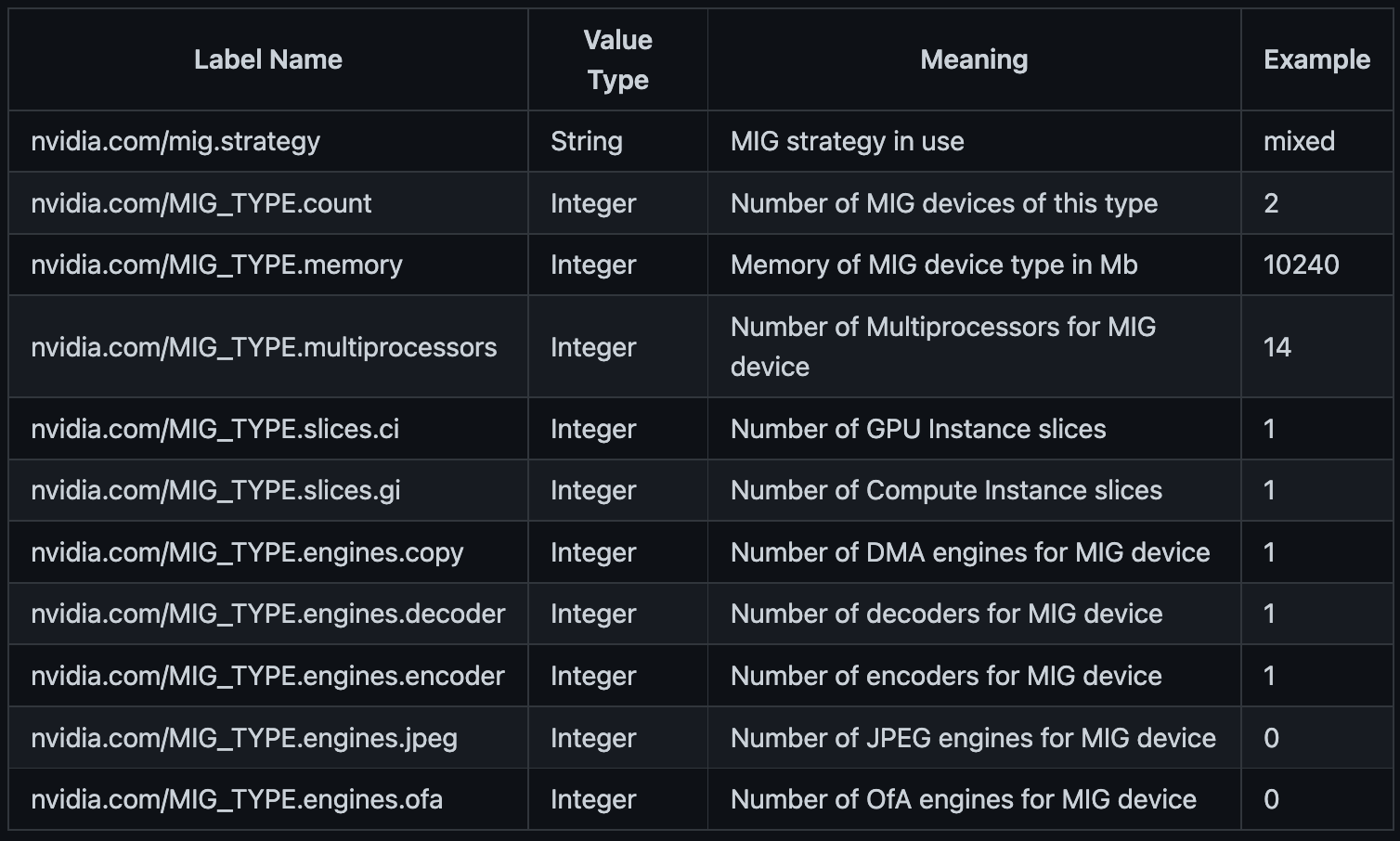
k8s 리소스에 MIG 적용하기
진행하기에 앞서 이전 포스팅과, 이번 포스팅에서 nvidia-device-plugin 과 gpu-feature-discovery를 정상적으로 설치하셨는지 확인해보세요!
위에서 설명한 전략을 혼합하여 사용하는 것은 추가적인 설정이 필요합니다.
일단 간단하게 GPU를 나누어보고자 하니 저는 진행하지 않겠습니다. 필요하신 분은 여기를 참고해주세요.
나중에 필요해지면 추가 포스팅 하도록 하겠습니다!
The none strategy
none 전략
none 전략은 k8s-device-plugin이 항상 그랬던 것처럼 계속 실행되도록 설계되었습니다.
MIG가 활성화된 GPU를 구분하지 않으며 시스템의 모든 GPU를 기꺼이 열거하고 nvidia.com/gpu 리소스 유형을 통해 사용할 수 있도록 합니다.
참고: 이 모드를 실행할 때 GPU에서 MIG를 활성화한 경우, 작업 부하를 실행하는 관점에서 볼 때 쓸모없는 GPU에 대한 액세스 권한이 부여될 수 있습니다.
이 전략은 MIG 지원 GPU가 없는 것이 확실한 환경에서만 주의해서 사용해야 합니다.
이 전략을 테스트하기 위해 MIG가 활성화되거나 활성화되지 않은 GPU 열거를 확인하고 두 경우 모두에서 볼 수 있는지 확인합니다.
테스트에서는 클러스터의 단일 노드에 단일 GPU가 있다고 가정합니다.
-
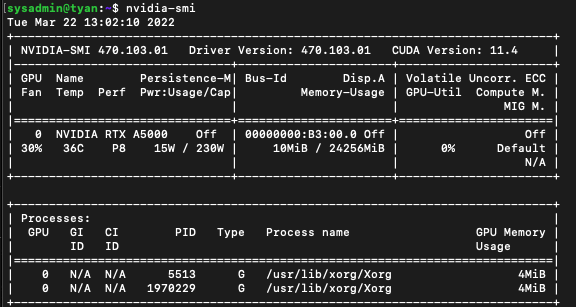
Verify that MIG is disabled on the GPU
nvidia-smi
상단 테이블 MIG M. 행에 대한 결과가 N/A임을 확인하실 수 있습니다.
disabled로 되어있을 수도 있습니다.
- (추가) 진행해보니 MIG M.이N/A이면 진행이 안됩니다. A100 등disabled로 뜨면 MIG를 사용할 수 있습니다.(default가 disabled입니다)
-
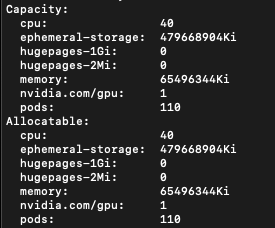
리소스 유형이 nvidia.com/gpu인 노드에서 1개의 GPU를 사용할 수 있는지 확인합니다.
kubectl describe node
-
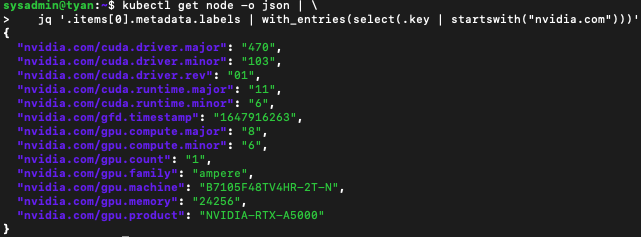
MIG 전략에 적절한 레이블 집합이 적용되었는지 확인합니다.
kubectl get node -o json | jq '.items[0].metadata.labels | with_entries(select(.key | startswith("nvidia.com")))'
-
GPU를 사용하고 nvidia-smi를 실행하는 파드를 배포합니다.
kubectl run -it --rm \
--image=nvidia/cuda:11.0-base \
--restart=Never \
--limits=nvidia.com/gpu=1 \
mig-none-example -- nvidia-smi -L- GPU에서 MIG 활성화(먼저 모든 GPU 클라이언트를 중지해야 합니다)
GPU 클라이언트를 종료할 때 kubelet을 먼저 종료해서 삭제한 pod가 재생성되지 않도록 하세요!
파드를 삭제할 때 kubectl get pods -A을 이용해서 파드가 속한 네임스페이스와 파드명을 이용하시길 바랍니다.
kubelet을 stop했을 경우 아래처럼 명령어를 입력하면 당연히 Terminating을 완료할 kubelet이 죽어있기 때문에 진행이 되지 않습니다. ctrl+c를 눌러 나와서 이어서 진행해주세요.
$ sudo systemctl stop kubelet
$ kubectl delete pod nvidia-device-plugin-daemonset-w55tx -n kube-system
$ kubectl delete pod gpu-feature-discovery-1647916205-cpfg8 -n node-feature-discovery
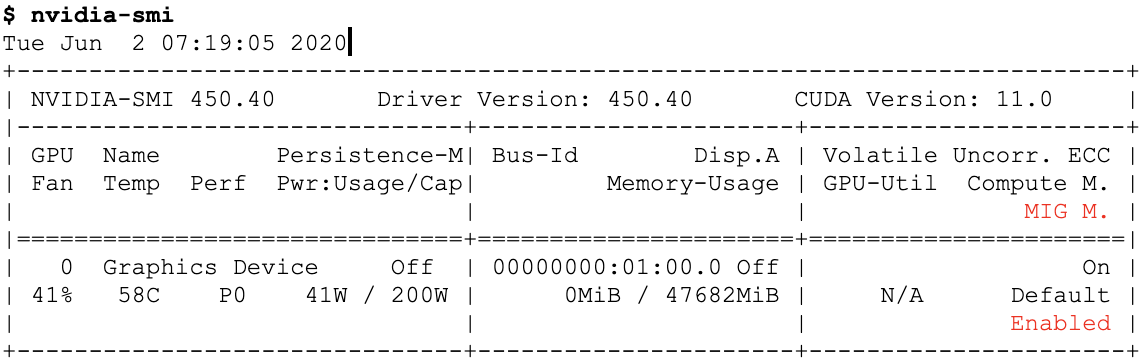
$ nvidia-smi -mig 1
Enabled MIG Mode for GPU 00000000:01:00.0
$ systemctl start kubelet
$ ... restart the k8s-device-plugin ...
$ ... restart gpu-feature-discovery ...
$ nvidia-smi아무리 정보를 찾아봐도 제가 쓰고있는 NVIDIA A5000 GPU가 MIG를 지원한다는 정보를 못찾겠네요..
위에서 봤듯이 nvidia-smi 실행 시 MIG M. 정보가 disabled였다가 enabled로 바뀌어야 하는데, 전 N/A 였고 위처럼 nvidia-smi -mig 1 명령어 실행 시 지원되지 않는다고 뜹니다.

일단 A100만 사용가능한 것으로 보이는데, 잘 아시는 분이 있다면 댓글 남겨주시면 감사하겠습니다!
저는 진행이 불가능하지만 사용하실 분들을 위해 나머지 자료도 정리합니다.
일단 위에서 변경 후 enable이 아래와 같이 뜨셔야합니다.
The single strategy
single 전략은 쿠버네티스에서 GPU 작업에 대한 사용자 경험을 예전과 동일하게 유지하도록 설계되었습니다.
MIG 장치는 이전과 마찬가지로 nvidia.com/gpu 리소스 유형으로 열거됩니다.
그러나 해당 리소스 유형과 연결된 속성은 이제 전체 GPU 대신 해당 노드에서 사용 가능한 MIG 장치에 매핑됩니다.
이 전략을 테스트하기 위해 단일 유형의 MIG 장치가 기존 nvidia.com/gpu 리소스 유형을 사용하여 열거되는지 확인합니다.
테스트에서는 MIG가 이미 활성화된 클러스터의 단일 노드에 단일 GPU가 있다고 가정합니다.
-
GPU에서 MIG가 활성화되어 있고 현재 MIG 장치가 없는지 확인합니다.
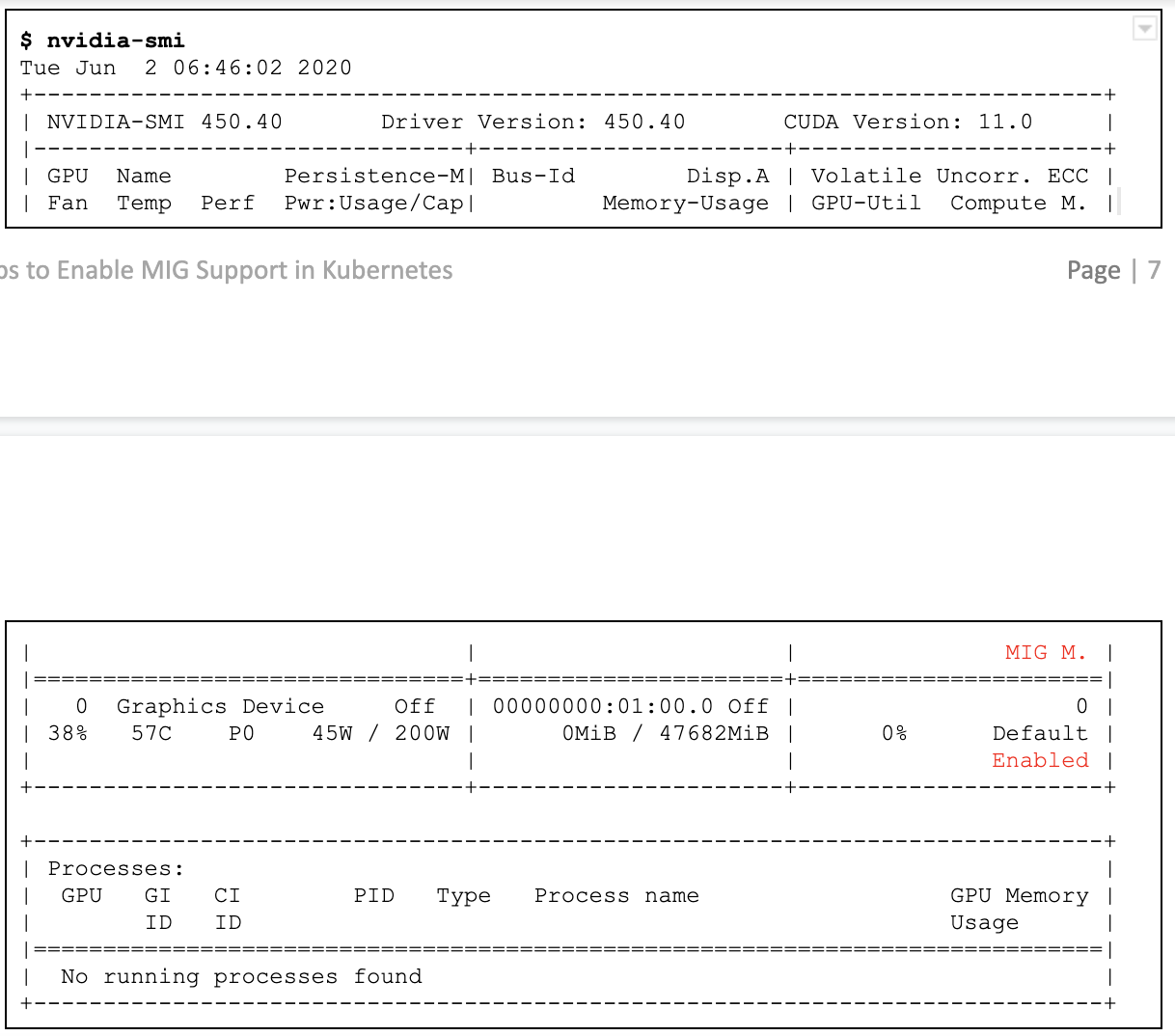
-
GPU에서 7개의 단일 슬라이스 MIG 장치 생성
$ nvidia-smi mig -cgi 19,19,19,19,19,19,19
$ nvidia-smi mig -cci
$ nvidia-smi -L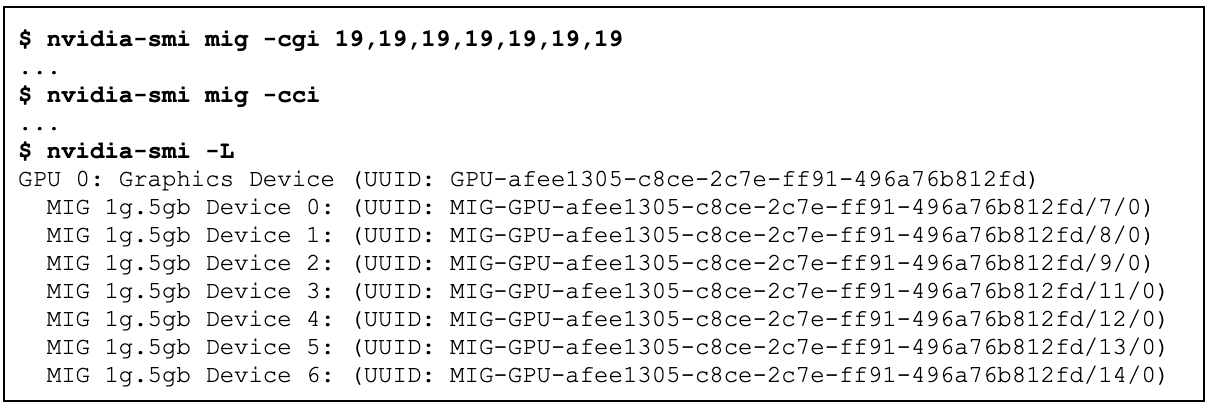
-
이전 섹션에서 설명한 대로 단일 전략으로 엔비디아 장치 플러그인 시작
(이미 실행 중인지 확인하고 다시 시작하십시오, 헬름 설치 시 export를 single로 했는지 확인해주세요) -
리소스 유형이 nvidia.com/gpu인 노드에서 7개의 MIG 장치를 사용할 수 있는지 확인합니다.
kubectl describe node

-
이전 섹션에서 설명한 대로 단일 전략으로 gpu-feature-discovery를 시작합니다(이미 실행 중인지 확인하고 다시 시작).
-
이 MIG 전략에 적절한 레이블 집합이 적용되었는지 확인합니다.
kubectl get node -o json | \
jq '.items[0].metadata.labels | with_entries(select(.key | startswith("nvidia.com")))'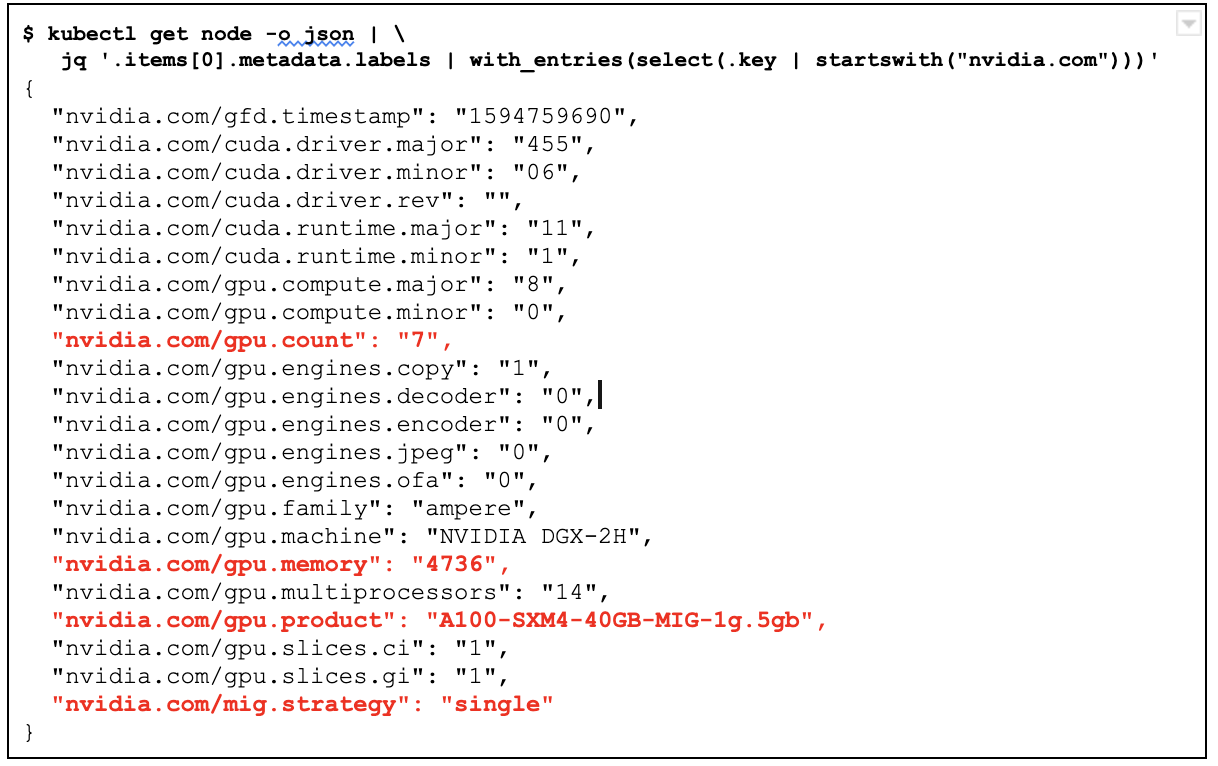
- 각각 하나의 MIG 장치를 사용하는 7개의 포드 배포(그런 다음 로그를 읽고 삭제)
- 생성
for i in $(seq 7); do
kubectl run \
--image=nvidia/cuda:9.0-base \
--restart=Never \
--limits=nvidia.com/gpu=1 \
mig-single-example-${i} -- bash -c "nvidia-smi -L; sleep infinity"
done- 로그 출력
for i in $(seq 7); do
echo "mig-single-example-${i}";
kubectl logs mig-single-example-${i}
echo "";
done- 삭제
for i in $(seq 7); do
kubectl delete pod mig-single-example-${i};
doneThe mixed strategy
The mixed strategy는 자료로 대신합니다.
번외
- 쿠버네티스의 pod에 resource.limit을 지정해서 사용하는 위와 환경 말고, 단순히 TF/pytorch를 돌리는 경우에는(쿠버네티스 활용X) 그냥 해당 프레임워크의 메서드로 GPU를 나눠쓸 수 있습니다..
- Pytorch(> v1.8): https://pytorch.org/docs/stable/cuda.html에서
torch.cuda.set_per_process_memory_fraction메서드를 사용하면 됩니다. - TF(v1, v2 모두 가능): https://www.tensorflow.org/api_docs/python/tf/config/LogicalDeviceConfiguration를 참고하세요. tf.config.LogicalDeviceConfiguration의 설정으로 MB 단위로 설정가능합니다. (현재는 GPU 일때만 지원)
- Pytorch(> v1.8): https://pytorch.org/docs/stable/cuda.html에서
- NVIDIA에서 공식 지원하는 위의 방법 말고, GPU의 VRAM을 나누어 커스텀 리소스로 등록하고 resource.limit에 작성할 수 있다고 합니다. 해당 방법은 다음 포스팅에서 이어서 진행해보겠습니다!
- A100, A30을 사용할 여력이 없는 저 같은 분들은 다음 포스팅까지 잘 따라와주세요,, 우리도 GPU 함 나눠 써보자구요 😂


이렇게 설정을 해두면 데이터 학습시에 바로 사용가능한건가요?