semantic segmentation 학습 환경 구축하기

학습환경 구축
- 환경 정리
- EC2 접속정보(퍼블릭 IP) : 13.209.10.252
- 다양한 백본을 시도해볼 수 있는 open-MMlab : MMSegmentation을 기반으로 구축하였습니다.
- conda env name : mmsemantic
- python 3.7
- PyTorch 1.6.0
- CUDA 10.1
- mmcv
- jupyter notebook
prepare EC2, select Algorithm
- 준비된 EC2를 실행상태로 만들어줍니다.
- Elastic IP 기능을 사용하지 않기 때문에 중지 후 재시작했을 땐 퍼블릭 IP가 변경됩니다. 이번 아이피는 13.209.10.252이군요.
- 준비된 EC2에 접속하기 위한 세션을 저장해줍니다.(저는 Terminus를 이용합니다.)
- 호스트를 추가해줍니다. 레이블은 자유롭게, Address는 퍼블릭 IP를 사용합니다.
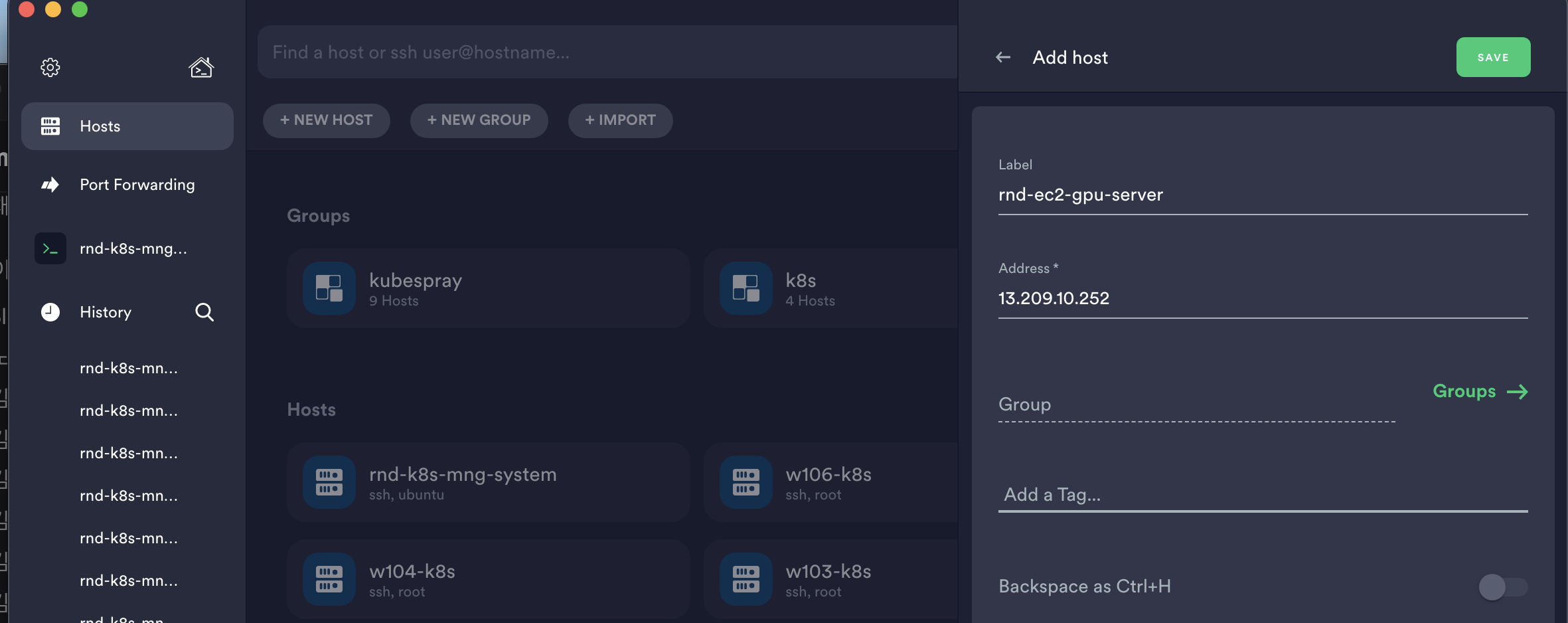
- ssh 접속을 활성화하고 Password 대신 root 키파일을 사용합니다. (Keys 섹션에 .pem 파일을 등록하시면 됩니다. 이외의 것은 입력하실 필요 없습니다.)
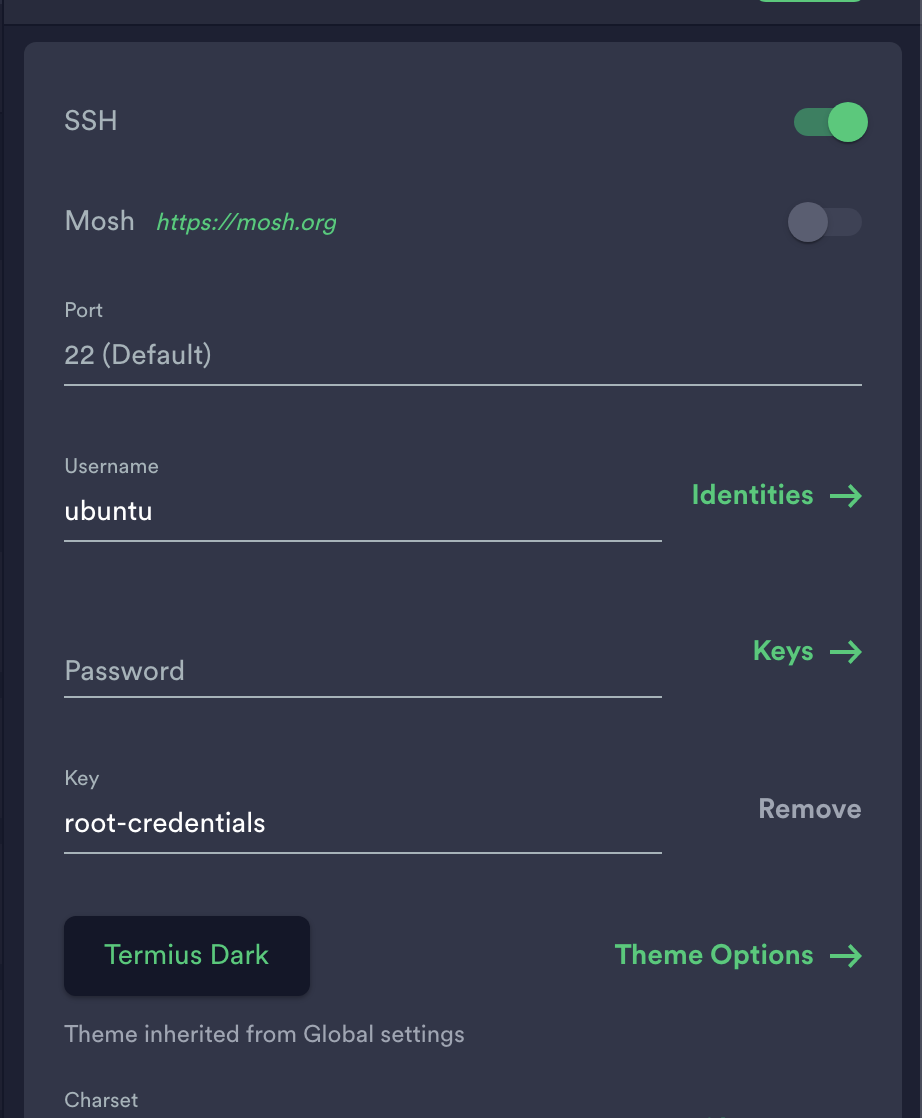
- save해서 세션 접속 정보를 저장하고 ec2에 접속합니다.
- 호스트를 추가해줍니다. 레이블은 자유롭게, Address는 퍼블릭 IP를 사용합니다.
- 이제 어떤 방법을 이용해서 semantic segmentation 모델을 학습시킬 것인지 결정해야 합니다.
- 이번 프로젝트는 내산복(산을 막아주는 방호복)을 갖춰입은 사람을 찾는 것이 목적이기 때문에, 해당 픽셀이 사람인지 아닌지 판단할 수 있는 모델이 필요합니다.
- SOTA를 검색해보고, 해당 모델을 쉽게 구축할 수 있는 방법을 찾아보았습니다. mmsegmentaion(mmdetection등 mm 계열은 다양한 백본을 지원하고, 구현이 용이하기 때문에 애용합니다.)을 이용해보겠습니다.
- 몇 달전에 구현해봤기 때문에 어느정도 익숙하게 할 수 있지 않을까 하는데.. 오늘 내로 끝낼 수 있을까요 ㅎㅎ...
Prerequisites
- MMSegmentation 사전 환경 설정 준비
- 해당 링크를 참고해주세요.
- 버전 관리
- Linux or macOS (Windows is in experimental support)
- Python 3.6+
- PyTorch 1.3+
- CUDA 9.2+ (If you build PyTorch from source, CUDA 9.0 is also compatible)
- GCC 5+
- MMCV(호환되는 MMSegmentation 및 MMCV 버전은 다음과 같습니다. 설치 문제를 방지하려면 올바른 버전의 MMCV를 설치하십시오.)
Installation
-
콘다 가상환경을 만들고 실행시킵니다.
conda create -n mmsemantic python=3.7 -y conda activate mmsemantic -
공식 지침에 따라 PyTorch와 torchvision을 설치하십시오 . 여기서는 PyTorch 1.6.0 및 CUDA 10.1을 사용합니다. 버전 번호를 지정하여 다른 버전으로 전환할 수도 있습니다.
- 저는 open-mmlab : MMSegmentation README.md에 따라 해당 버전 그대로 사용해서 진행해보겠습니다.
-conda install pytorch=1.6.0 torchvision cudatoolkit=10.1 -c pytorch -
MMCV를 다음과 같은 공식 지침에 따라 설치합니다.
- mmcv 또는 mmcv-full 둘 중 하나를 설치합니다. mmcv는 MMSegmentation과 호환되지만 CCNet 및 PSANet과 같은 방법의 경우 CUDA 연산을 위해 mmcv-full이 필요합니다.
- 리눅스는 다음과 같이 설치합니다.
-pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu101/torch1.6.0/index.html -
MMSegmentation을 설치합니다.
- 최신 릴리즈 설치 :
pip install mmsegmentation
- 최신 릴리즈 설치 :
-
데이터세트 경로를 연결합니다.
- 심볼릭 링크를 이용해서 데이터세트 경로의 링크를 만들어서 사용하면 편합니다. (
ln -s $DATA_ROOT <링크>)
- 심볼릭 링크를 이용해서 데이터세트 경로의 링크를 만들어서 사용하면 편합니다. (
Verification
설치가 정상적으로 이루어졌는지 데모 코드를 통해 확인해보도록 합시다.
-
해당 깃허브를 클론해옵니다.
mkdir mmseg cd mmseg git clone https://github.com/open-mmlab/mmsegmentation.git .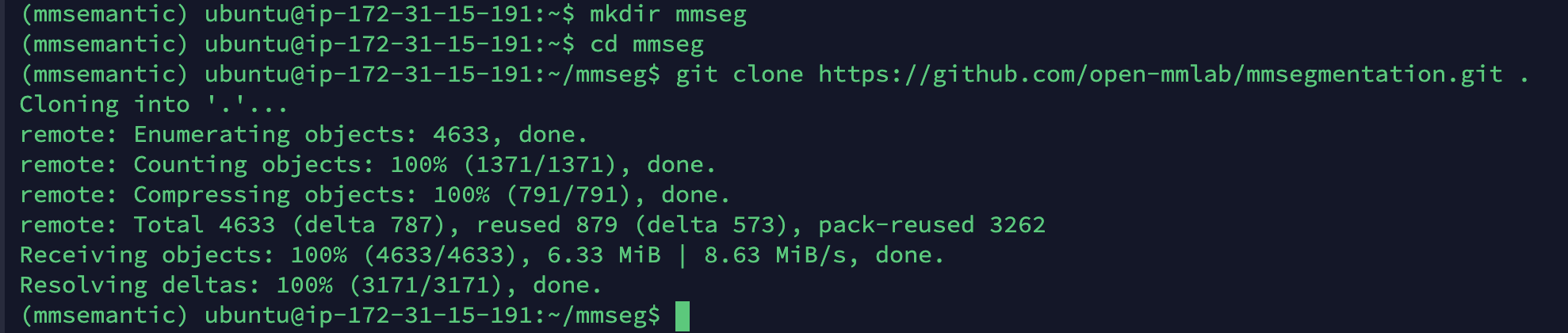
-
inference_demo.ipynb를 실행하기 위해 주피터 노트북을 설치해줍니다.
conda install jupyter -yjupyter-notebook
-
inference_demo.ipynb에서 사용해보고자 하는 모델과 해당 모델의 config파일을 수정해서 확인해봅시다.
- 해당 모델과 config 파일은 config 폴더 내의 각 모델 폴더의 README.md를 통해 확인할 수 있습니다.
- 사전학습된 모델은 모델 다운로드를 오른쪽 클릭해서 링크 주소 복사하여 wget으로 얻어옵니다.
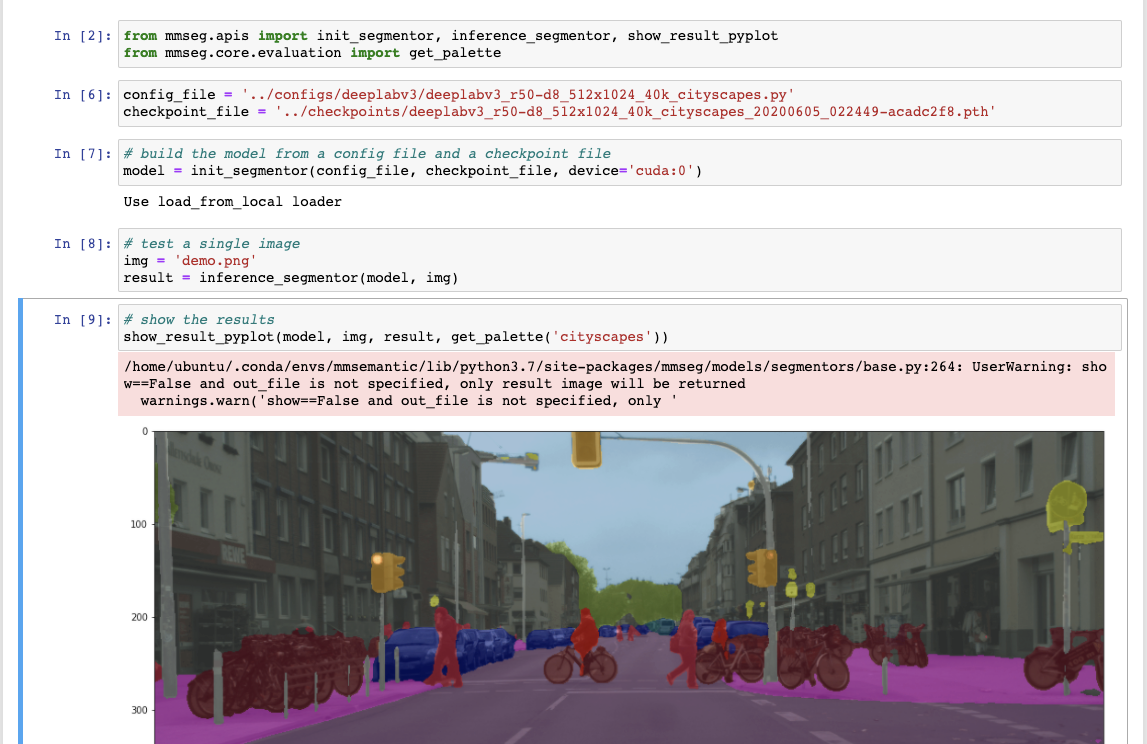
-
video_demo.py를 만들어 비디오에 대한 추론을 실험해보고 싶은데 ec2로 접속했기 때문에 디스플레이에 띄울 방법이 필요합니다.
- ipynb 방식으로 진행해서 비디오를 띄워보겠습니다. vnc를 이용해서 ec2의 디스플레이를 띄워봤으나 python 파일을 실행할 IDE도 필요하기 때문에 번거로울 것 같습니다.
- 여담으로 vnc 실행방법은vncserver :1, 종료방법은vncserver kill :1입니다. 본인이 까먹을까봐 적어둡니다.
- FileZilla로 동영상 파일을 옮기고 테스트 데모를 돌려봅시다. MMSegmentation에서 공식적으로 지우너하는 비디오 데모 코드는 동작하지 않아서 아래 코드로 py파일을 만드신 후 터미널에서 실행해 결과 파일을 생성하시길 바랍니다.(argument로 show를 주면 display가 없어서 오류 발생합니다. 파일 생성하고 SFTP로 옮겨서 확인해주세요.
import argparse import cv2 import mmcv from mmseg.apis import inference_segmentor, init_segmentor - ipynb 방식으로 진행해서 비디오를 띄워보겠습니다. vnc를 이용해서 ec2의 디스플레이를 띄워봤으나 python 파일을 실행할 IDE도 필요하기 때문에 번거로울 것 같습니다.
def parse_args():
parser = argparse.ArgumentParser(description='MMDetection video demo')
parser.add_argument('video', help='Video file')
parser.add_argument('config', help='Config file')
parser.add_argument('checkpoint', help='Checkpoint file')
parser.add_argument(
'--device', default='cuda:0', help='Device used for inference')
parser.add_argument(
'--score-thr', type=float, default=0.7, help='Bbox score threshold')
parser.add_argument('--out', type=str, help='Output video file')
parser.add_argument('--show', action='store_true', help='Show video')
parser.add_argument(
'--wait-time',
type=float,
default=1,
help='The interval of show (s), 0 is block')
args = parser.parse_args()
return args
def main():
args = parse_args()
assert args.out or args.show, \
('Please specify at least one operation (save/show the '
'video) with the argument "--out" or "--show"')
model = init_segmentor(args.config, args.checkpoint, device=args.device)
video_reader = mmcv.VideoReader(args.video)
video_writer = None
if args.out:
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(
args.out, fourcc, video_reader.fps,
(video_reader.width, video_reader.height))
for frame in mmcv.track_iter_progress(video_reader):
result = inference_segmentor(model, frame)
frame = model.show_result(frame, result)
#frame = model.show_result(frame, result, score_thr=args.score_thr)
if args.show:
cv2.namedWindow('video', 0)
mmcv.imshow(frame, 'video', args.wait_time)
if args.out:
video_writer.write(frame)
if video_writer:
video_writer.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
main()
```
- `python video_demo.py "./demo_video/video_20s_cut.mp4" ../configs/hrnet/fcn_hr48_512x1024_160k_cityscapes.py ../checkpoints/fcn_hr48_512x1024_160k_cityscapes_20200602_190946-59b7973e.pth --out="hrnet_fcn_20s.mp4"`- 결과
- velog에 동영상을 올릴 수가 없어서 캡쳐본으로 대신합니다. 해당 테스크 특성상 성능이 높다고 볼 수 없지만, 모델에 따라서 성능이 차이납니다. 학습시킨 데이터셋에 따라서도 다릅니다.
- 저는 OCRnet, HRnet, FCN, DeeplabV3 등을 기반으로한 모델들을 사용했습니다.



학습
MMSegmentation을 활용한 학습 방법은 차후 수정해 포스팅하겠습니다.

안녕하세요 하람님
포스트글 보고 많이 배워갑니다 ㅎㅎ
혹시 mmsegmentation 데이터셋 구성 및 학습방법은
언제 업로드 되는지 알 수 있을까요?