이전 포스팅에선 쿠버네티스의 애플리케이션 빌드와 배포를 자동화해 컨테이너 환경에서 애플리케이션을 효율적으로 관리하는 방법을 알아봤습니다.
이렇게 배포된 애플리케이션은 충분히 검증을 거친 상태지만, 상용 환경에서는 여러 가지 예외 상황이 발생할 수 있습니다.
예를 들어 노드에서 하드웨어적으로 문제가 생기거나, 컨테이너 관점에서 가용하는 리소스보다 많은 요청이 발생해 문제가 생기는 경우 등이 있습니다.
따라서 구축한 환경 자체를 모니터링하고, 문제가 생길 경우 적절한 조치를 빠르게 취해야 합니다.
그래서 지금까지 우리가 구축한 컨테이너 인프라 환경을 안정적으로 관리하고 운영하기 위한 마지막 단계로 모니터링을 살펴봅시다!
이번 포스팅에서는 프로메테우스와 그라파나를 이용해 컨테이너 인프라 환경에 주요 요소를 수집하고, 수집된 데이터를 한눈에 파악할 수 있도록 대시보드를 작성해 효과적인 모니터링 시스템을 구축해보겠습니다.
그리고 이상을 감지하면 알려주는 서비스를 추가해 컨테이너 인프라 환경을 완성하겠습니다.
컨테이너 인프라 환경 모니터링하기
모니터링이 어떤 것인지 간단히 살펴보겠습니다.
m-k8s 노드에서 bpytop 명령을 실행하면 다음 그림과 같이 시스템 상태 정보가 보입니다.
화면에서 리소스의 상태 및 문제가 될 가능성이 있는 정보를 한눈에 파악할 수 있습니다.
bpytop
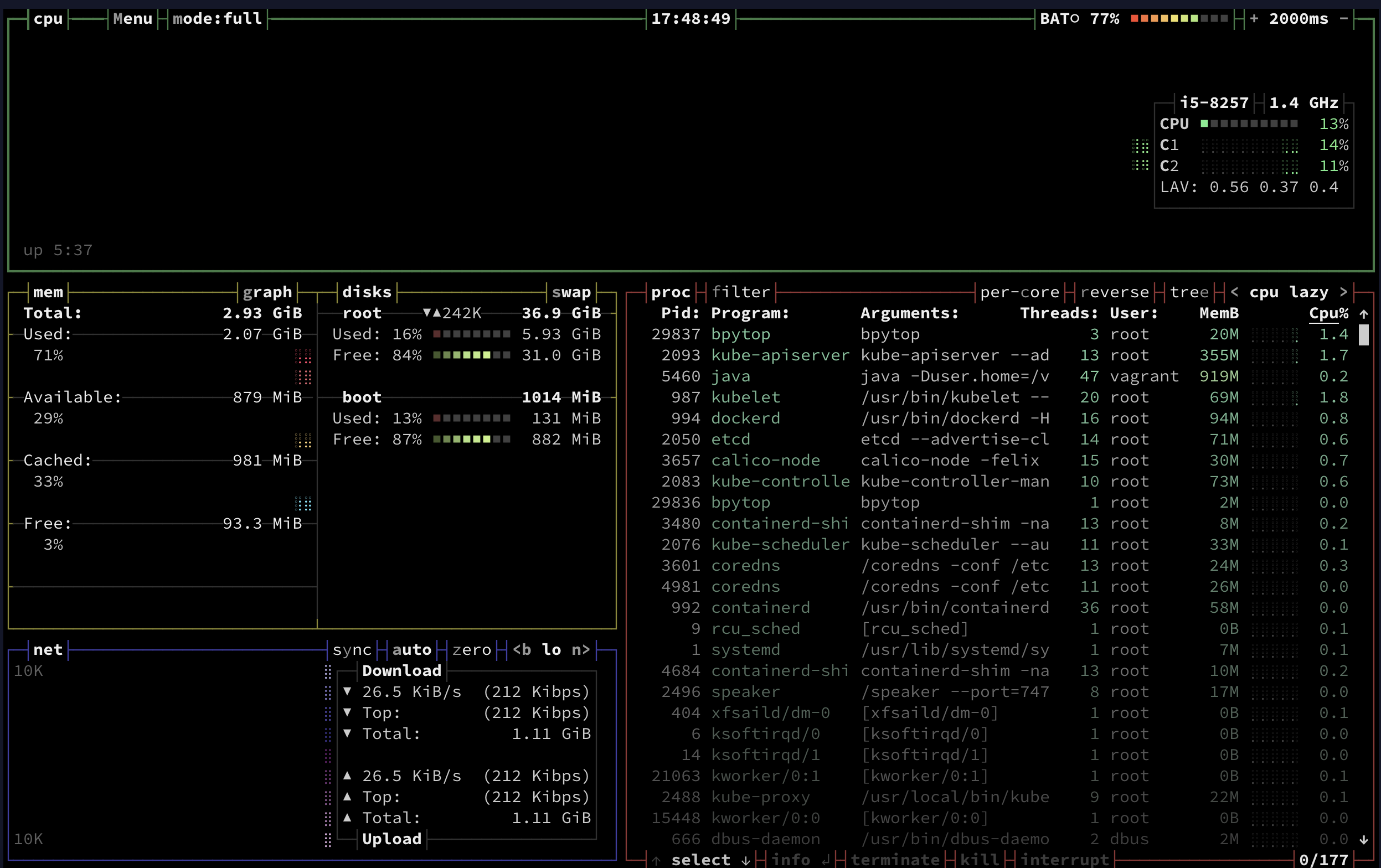
그러나 bpytop은 현재 노드에 대한 정보만 보여줄 뿐,
다수의 노드로 구성된 클러스터 정보를 모두 표현하기는 어렵습니다.
그래서 이러한 정보를 수집하고 분류해서 따로 저장해야 합니다.
거의 모든 모니터링 도구는 다음과 같이 수집 -> 통합 -> 시각화 구조로 돼 있습니다.
우리가 구축한 컨테이너 인프라 환경에서는 모니터링 데이터를 프로메테우스로 수집하고,
수집한 정보를 한 곳에 모아(통합), 그라파나로 시각화합니다.
모니터링 도구 선택하기
여기서 사용하는 프로메테우스와 그라파나는 오픈 소스 도구입니다.
오픈 소스는 가능한 한 단일 도구에서 단일 기능만을 구현하는 것을 선호합니다.
데이터 수집과 통합, 시각화는 서로 다른 영역이므로 이를 함꼐 구현하지 않으려는 경향이 있습니다.
물론 서비스형 모니터링 도구는 사용자 편의를 위해 이러한 기능을 모아서 한꺼번에 제공합니다.
그런데 왜 하나의 도구로 처리하지 않고 이런 혼합 구조를 사용할까요?
프로메테우스와 그라파나의 혼합 구조를 사용하는 이유는 크게 두 가지입니다.
- 비용 : 모니터링 대상마다 라이선스(License) 관련 비용이 발생하고, 클라우드 같은 과금제 서비스를 이용하면 네트워크와 저장 공간에 따른 추가 비용이 발생합니다.
- 보안 : 서비스형 모니터링 도구들은 대부분 외부에 데이터를 저장해 모니터링합니다. 보안에 민감해서 내부에서 모든 데이터를 처리하려는 경우에는 사용하기 어렵습니다.
그럼 다른 데이터 수집과 통합, 시각화에 사용하는 도구들은 무엇이 있을까요?
데이터 수집과 통합 도구
여러 모니터링 도구를 비교하며 프로메테우스를 선택한 이유를 알아보겠습니다.
-
프로메테우스(Prometheus)
- 사운드클라우드(SoundCloud)에서 자사 서비스의 모니터링을 위해 개발한 도구- 현재는 오픈 소스로 전환돼 CNCF에서 관리, 2018년 8월 졸업 프로젝트가 됨
- 시계열 DB를 내장하고 있고, 자체적인 질의 페이지 외에 시각화 기능은 없으나 그라파나와 연계하면 현업에서 사용할 수 있는 시각화 기능 제공 가능
- 중앙 서버에서 에이전트의 데이터를 수집하는 풀(Pull) 방식을 사용하므로 쿠버네티스 환경에서 설치된 에이전트를 통해 노드와 컨테이너 상태를 모두 수집해 모니터링 가능
- 에이전트를 통해 내부 메트릭을 외부로 노출하기 때문에 사용자가 수집 대상에 접속할 수만 있다면 개인 컴퓨터에서도 메트릭을 가져올 수 있음, 따라서 모니터링과 관련된 개발을 하기 용이함
- 일회성으로 모니터링 대상에 대한 세부적인 메트릭도 간단하게 웹 브라우저로 확인 가능
- 완전한 오픈 소스 모델을 선택해 사용자 층이 넓고 자료가 풍부하며 각종 대시보드 도구나 메신저 등이 프로메테우스와의 연계를 지원하므로 직접 모니터링 시스템을 구축할 때 좋음
-
데이터톡(Datadog)
- 모니터링 데이터를 업체에서 관리하는 경우를 서비스형이라고 하고, 데이터를 사용자가 직접 관리하는 경우를 설치형이라고 하는데, 데이터독은 서비스형 소프트웨어(SaaS) 형태로 제공- 웹사이트에서 모니터링 대상을 관리할 수 있고 쿠버네티스를 비롯해 여러 클라우드 서비스나 애플리케이션과 연결이 쉬우므로 관리 부담이 적음
- 모니터링 대상마다 요금을 부과하기 때문에 모니터링 대상이 늘면 비용이 커지는 단점이 존재
-
뉴 렐릭(New Relic)
- 데이터독과 같은 Saas, 다만 데이터독과 비교했을 때 애플리케이션 성능 모니터링(APM, Application Performance Monitoring)에 더 특화됌- 데이터독과 마찬가지로 모니터링 대상이 많을수록 비용 증가
-
인플럭스DB(InfluxDB)
- 2013년 인플럭스데이터(InFluxdata)에서 개발한 시계열 DB- 오픈소스로 공개된 무료 버전과 클라우드에서 바로 사용할 수 있는 SaaS, 라이선스를 구매해 설치할 수 있는 엔터프라이 버전, 총 3가지 유형을 제공
- 무료 버전은 프로메테우스와 유사하지만 인플럭스DB가 쓰기 성능이 더 뛰어나 대량의 이벤트를 모니터링하는 데는 좀 더 적합
- 엔터프라이즈 버전은 프로메테유스에서 부족한 부분인 고가용성을 위한 분산 저장을 좀 더 쉽게 구성할 수 있는 기능 제공
- 프로메테우스와 더불어 오픈 소스로 모니터링 플랫폼을 구축하기 위한 최선의 도구이고, 유료 서비스도 있어 선택의 폭이 좀 더 넓음
- 하지만 간단한 구성으로 데이터를 받아오는 프로메테우스보다 상대적으로 구성이 어렵다는 단점이 존재
메트릭이란?
메트릭(Metric)은 간단히 말해 현재 시스템의 상태를 알 수 있는 측정값입니다.
컨테이너 인프라 환경에서는 크게 2가지 상태로 메트릭을 구분합니다.
파드 같은 오브젝트에서 측정되는 CPU와 메모리 사용량을 나타내는 시스템 메트릭(System Metric),
HTTP 상태 코드 같은 서비스 상태를 나타내는 지표인 서비스 메트릭(Service Metric) 입니다.
시계열 데이터베이스란?
시계열 DB는 시간을 축(키)으로 시간의 흐름에 따라 발생하는 데이터를 저장하는 데 최적화된 데이터베이스입니다.
예를 들어 네트워크 흐름을 알 수 있는 패킷과 각종 기기로부터 전달받는 IoT 센서 값, 이벤트 로그 등이 있습니다.
이 책에서는 프로메테우스의 시계열 DB에 쿠버네티스와 노드에서 공개하는 메트릭을 저장하고,
이를 효과적으로 조합해 사용자가 원하는 모니터링을 구성합니다.
데이터 수집과 통합 도구의 기능을 간단히 정리하면 다음과 같습니다.
| 구분 | 프로메테우스 | 데이터독 | 뉴 렐릭 | 인플럭스DB |
|---|---|---|---|---|
| 가격 | 무료 | 유료 | 유료 | 유/무료 |
| 형태 | 설치형 | 서비스형 | 서비스형 | 서비스형/설치형 |
| 참고 자료 | 매무 많음 | 많음 | 많음 | 많음 |
| 기능 확장성 | 매우 좋음 | 좋음 | 좋음 | 좋음 |
데이터 시각화 도구
프로메테우스와 인플럭스DB가 제공하는 대시보드는
서비스형으로 사용하는 데이터톡과 뉴 렐릭보다 시각화 부분이 다소 약합니다.
그래서 부족한 시각화 기능을 보강하는 다음과 같은 도구를 사용합니다.
-
그라파나(Grafana)
- 그라파나 랩스(Grafana Labs)에서 개발했으며, 특정 소프트웨어에 종속되지 않은 독립적인 시각화 도구
- 30가지 이상의 다양한 수집 도구 및 DB들과 연계를 지원
- 주로 시계열 데이터 시각화에 많이 쓰임, 관계형 데이터베이스 데이터를 표 형태로 시각화해 사용할 수도 있음
- 기능을 확장하는 플러그인과 개별 사용자들이 만들어 둔 대시보드의 공유가 매우 활발
- 오픈 소스라서 사용자의 요구 사항에 맞게 수정 가능, 필요에 따라 설치형과 서비스형 모두 선택 가능
-
키바나(Kibana)
- 엘라스틱서치(ElasticSearch)를 개발한 엘라스틱에서 만든 시각화 도구
- 엘리스틱서치에 적재된 데이터를 시각화하거나 검색하는 데 사용, 이러한 데이터를 분석할 때도 사용
- 엘라스틱서치의 데이터만을 시각화할 수 있기 때문에 프로메테우스의 시계열 데이터를 메트릭비트(Metricbeat)라는 도구로 엘라스틱서치에 전달해야 하는 불편함 존재
- 시각화 기능이 매우 강력해서 시각화를 중점적으로 다루는 경우에는 고려해볼만 함 -
크로노그래프(Chronograf)
- 인플럭스DB를 개발한 인플럭스데이터에서 만든 시각화 도구
- 오픈소스로 제공돼 사용자 편의에 맞게 수정 가능
- 설치형과 서비스형 모두 제공
- 키바나와 마찬가지로 자사 제품인 인플럭스DB만 시각화할 수 있으므로 다양한 대상을 시각화할 수 없음
| 구분 | 그라파나 | 키바나 | 크로노그래프 |
|---|---|---|---|
| 가격 | 유/무료 | 유/무료 | 유/무료 |
| 형태 | 서비스/설치형 | 서비스/설치형 | 서비스/설치형 |
| 시각화 대상 | 다양한 대상 시각화 가능 | 엘라스틱서치 | 인플럭스DB |
| 정보량 | 많음 | 많음 | 적음 |
| 기능 확장성 | 좋음 | 좋음 | 적음 |
엘라스틱 제품들을 설치형으로 구성하면 무료로 사용할 수 있지만, 엘라스틱서치로 저장해야 해서 필요한 도구가 늘어납니다.
우리는 자유도가 높은 오픈 소스를 활용해 컨테이너 인프라 환경을 구현하고 실습하는 것이 목적이므로
기능이 부족하지 않고, 확장성도 뛰어난 프로메테우스와 그라파나의 조합으로 모니터링 시스템을 구축하겠습니다.
쿠버네티스 환경에 적합한 모니터링 데이터 수집 방법
쿠버네티스 인프라에 대한 모니터링은 이전 포스팅에서 HPA를 동작시키려고 메트릭 서버를 구성하면서 이미 진행한 적이 있습니다.
앞서 해봤던 모니터링 구조에서 컨테이너 메트릭을 수집하고 이를 메트릭 서버에 저장해 활용하는 부분을 다시 한 번 살펴봅시다!
쿠버네티스 노드는 kubelet을 통해 파드를 관리하며,
파드의 CPU나 메모리 같은 메트릭 정보를 수집하기 위해 kubelet에 내장된 cAdvisor를 사용합니다.
cAdvisor는 구글이 만든 컨테이너 메트릭 수집 도구로, 쿠버네티스 클러스터 위에 배포된
여러 컨테이너가 사용하는 메트릭 정보를 수집한 후 이를 가공해서 kubelet에 전달하는 역할을 합니다.
하지만 cAdvisor로 수집되고 kubelet으로 공개되는 데이터가 있어도 외부에서 이를 모아서 표현해주는 도구가 없다면 의미가 없습니다.
그래서 메트릭 데이터를 수집하는 목적으로 메티륵 서버를 설치해 HPA와 같은 기능을 구현하고
쿠버네티스 대시보드를 설치해 현재 상태를 확인할 수도 있습니다.
쿠버네티스 대시보드에 관한 내용은 추후 포스팅 하겠습니다.
이렇게 메트릭 서버에서 수집한 데이터로 여러 기능을 수행하도록 구성한 것을
리소스 메트릭 파이프라인(Resource Metric Pipeline) 이라고 합니다.
하지만 메트릭 서버는 집계한 데이터를 메모리에만 저장하므로 데이터를 영구적으로 보존하기 어렵고 현재 시점의 데이터만 출력됩니다.
그래서 메트릭 데이터를 저장 공간에 따로 저장하는 완전한 모니터링 파이프라인(Full Monitoring Pipeline) 으로 구축하기를 권장합니다.
이 설계 방식을 반영한 도구가 프로메테우스입니다.
완전한 모니터링 파이프라인으로 구성한 프로메테우스는 여러 수집 대상이 공개하는 메트릭 데이터를 모아 시계열 데이터베이스에 저장합니다.
저장된 데이터는 시간이 지나도 확인할 수 있는 영속적인 데이터입니다.
누적된 메트릭 데이터로는 쿠버네티스 인프라의 상태 변화를 파악할 수 있고, 적절한 위험 감지 및 조치를 취할 수 있습니다.
그러면 프로메테우스로 모니터리 시스템을 구축해봅시다!
프로메테우스로 모니터링 데이터 수집과 통합하기
프로메테우스는 많은 종류의 오브젝트를 설치합니다.
다음과 같은 오브젝트를 설치하며, 오브젝트를 통해 설치된 요소로 모니터링에 필요한 데이터를 수집하고 저장합니다.
프로메테우스 서버(prometheus-server)
프로메테우스의 주요 기능을 수행하는 요소로 3가지 역할을 맡습니다.
노드 익스포터 외 여러 대상에서 공개된 메트릭을 수집해오는 수집기,
수집한 시계열 메트릭 데이터를 저장하는 시계열 데이터베이스,
저장된 데이터를 질의하거나 수집 대상의 상태를 확인할 수 있는 웹 UI입니다.
프로메테우스를 사용하려면 웹 UI를 가장 먼저 알아야합니다.
프로메테우스의 수집기는 매우 독특한 방법으로 수집 대상을 찾습니다.
서비스 디스커버리(Service Discovery) 라는 방법입니다.
노드 익스포터(node-exporter)
노드의 시스템 메트릭 정보를 HTTP로 공개하는 역할을 합니다.
설치된 노드에서 특정 파일들을 읽고, 이를 프로메테우스 서버가 수집할 수 있는 메트릭 데이터로 변환한 후에
노드 익스포터에서 HTTP 서버로 공개합니다.
공개된 내용을 프로메테우스 서버에서 수집해 가게 됩니다.
쿠버 스테이트 메트릭(kube-state-metrics)
API 서버로 쿠버네티스 클러스터의 여러 메트릭 데이터를 수집한 후,
이를 프로메테우스 서버가 수집할 수 있는 메트릭 데이터로 변환해 공개하는 역할을 합니다.
프로메테우스가 쿠버네티스 클러스터의 여러 정보를 손쉽게 획득할 수 있는 것이 이 쿠버 스테이트 메트릭 덕분입니다.
얼럿매니저(alertmanager)
얼럿매니저는 프로메테우스에 경보(alert) 규칙을 설정하고, 경보 이벤트가 발생하면 설정된 경보 메세지를 대상에서 전달하는 기능을 제공합니다.
프로메테우스에 설치하면 프로메테우스 서버에서 주기적으로 경보를 보낼 대상을 감시해 시스템을 안정적으로 운영할 수 있게 합니다.
푸시게이트웨이(pushgateway)
배치와 스케줄 작업 시 수행되는 일회성 작업들의 상태를 저장하고 모아서 프로메테우스가 주기적으로 가져갈 수 있도록 공개합니다.
일반적으로 짧은 시간 동안 실행되고 종료되는 배치성 프로그램의 메트릭을 저장하거나
외부망에서 접근할 수 없는 내부 시스템의 메트릭을 프록시 형태로 제공하는 용도로 사용합니다.
푸시게이트웨이는 필요에 따라 구성하기 때문에 이번 포스팅에선 다루지 않겠습니다.
그럼 프로메테우스의 구성 요소를 설치해 보면서 각각의 의미와 기능을 알아보겠습니다.
헬름으로 프로메테우스 설치하기
프로메테우스는 젠킨스처럼 헬름으로 쉽게 설치할 수 있습니다.
다만 젠킨스 설치 때와 마찬가지로 NFS 디렉터리(/nfs_shared/prometheus)를 만들고,
만든 NFS 디렉터리를 쿠버네티스 환경에서 사용할 수 있도록 PV와 PVC로 구성해야 합니다.
접근 ID(사용자, 그룹ID)는 1000번으로 설정합니다.
이 과정은 헬름으로 젠킨스 설치하기와 동일하므로 사전에 구성된 스크립트를 실행해 프로메테우스를 설치하겠습니다.
-
먼저 쿠버네티스에 프로메테우스를 설치하는 데 필요한 사전 구성을 진행합니다.
-
준비된 스크립트를 실행합니다.
-
~/_Book_k8sInfra/ch6/6.2.1/prometheus-server-preconfig.sh
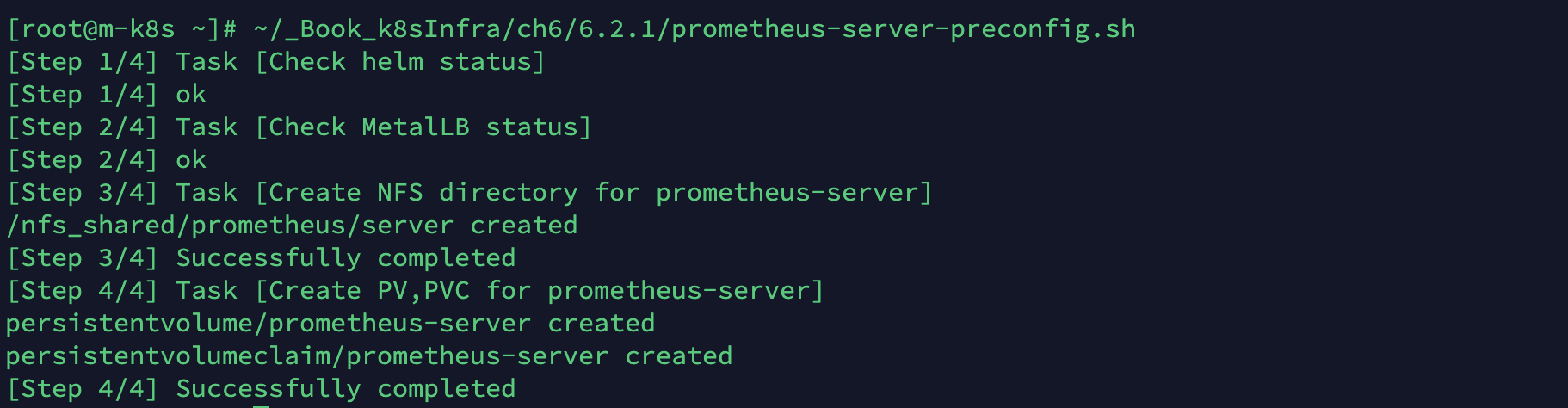
#!/usr/bin/env bash # check helm command echo "[Step 1/4] Task [Check helm status]" if [ ! -e "/usr/local/bin/helm" ]; then echo "[Step 1/4] helm not found" exit 1 fi echo "[Step 1/4] ok" # check metallb echo "[Step 2/4] Task [Check MetalLB status]" namespace=$(kubectl get namespace metallb-system -o jsonpath={.metadata.name} 2> /dev/null) if [ "$namespace" == "" ]; then echo "[Step 2/4] metallb not found" exit 1 fi echo "[Step 2/4] ok" # create nfs directory & change owner nfsdir=/nfs_shared/prometheus/server echo "[Step 3/4] Task [Create NFS directory for prometheus-server]" if [ ! -e "$nfsdir" ]; then ~/_Book_k8sInfra/ch6/6.2.1/nfs-exporter.sh prometheus/server chown 1000:1000 $nfsdir echo "$nfsdir created" echo "[Step 3/4] Successfully completed" else echo "[Step 3/4] failed: $nfsdir already exists" exit 1 fi # create pv,pvc echo "[Step 4/4] Task [Create PV,PVC for prometheus-server]" pvc=$(kubectl get pvc prometheus-server -o jsonpath={.metadata.name} 2> /dev/null) if [ "$pvc" == "" ]; then kubectl apply -f ~/_Book_k8sInfra/ch6/6.2.1/prometheus-server-volume.yaml echo "[Step 4/4] Successfully completed" else echo "[Step 4/4] failed: prometheus-server pv,pvc already exist" fi
-
-
프로메테우스 차트를 설치하려고 준비해 둔 prometheus-install.sh를 실행해 모니터링에 필요한 3가지 프로메테우스 오브젝트(프로메테우스 서버, 노드 익스포터, 쿠버 스테이트 메트릭)를 설치합니다.
-
~/_Book_k8sInfra/ch6/6.2.1/prometheus-install.sh
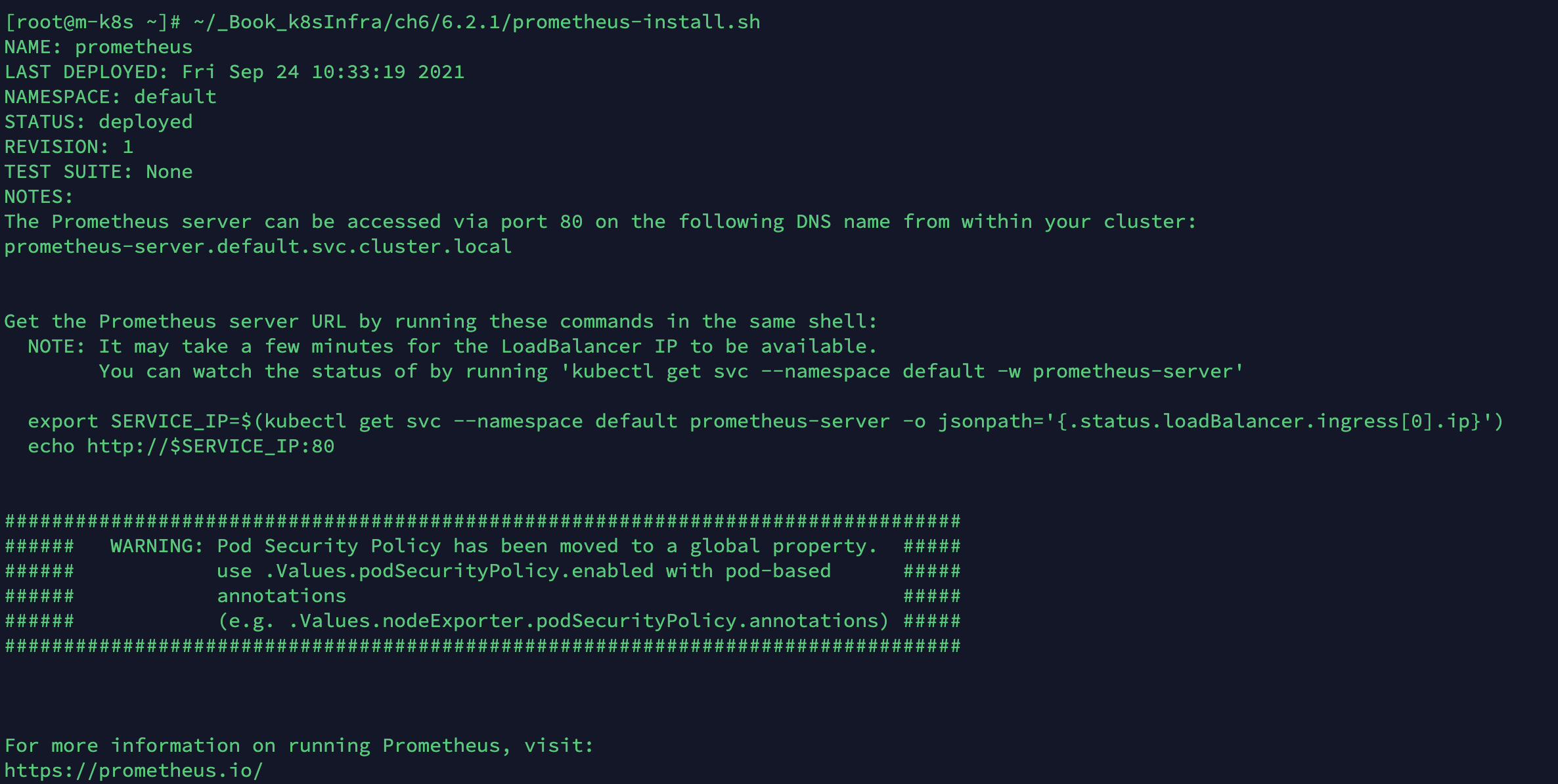
-
설치하면 위와 같은 프로메테우스 릴르스 정보가 나타납니다.
-
NAME : prometheus - 설치된 프로메테우스 요소들의 릴리스 이름입니다. 프로메테우스 서버, 노드 익스포터, 쿠버 스테이트 메트릭과 관련된 조회, 삭제, 변경 등을 수행할 떄 이 이름을 사용합니다.
-
NAMESPACE : default - 프로메테우스가 배포된 네임스페이스가 default임을 나타냅니다.
-
NOTES : 설치와 관련된 안내 사항을 표시합니다. 프로메테우스 차트가 설치된 후 출력되는 값으로, prometheus-server.default.svc.cluster.local과 같은 도메인 이름이 표시됩니다. 쿠버네티스 클러스터에서 서비스를 생성하는 클러스터 내부에서 서비스에 접속할 수 있는 도메인 이름을 발급하는데, 도메인 이름은 파드에서 다른 서비스를 검색(discovery)할 때와 그라파나에서 프로메테우스 서버의 주소를 등록할 때 사용합니다.
-
WARNING : Pod Security Policy - 헬름으로 설치한 파드마다 보안 정책을 다르게 할 수 있다는 정보성 메세지입니다. 프로메테우스 요소별로 접근할 수 있는 디렉터리를 정하거나 컨테이너 자체의 프로세스 권한을 개별적으로 제어할 수 있습니다.
-
프로메테우스 차트를 설치하는 스크립트의 내용은 다음과 같습니다.
#!/usr/bin/env bash # edu 차트 저장소의 prometheus 파트를 사용해 프로메테우스 릴리스를 설치합니다. helm install prometheus edu/prometheus \ # 푸시게이트웨이를 사용하지 않도록 설정합니다. 프로게이트 웨이는 짧은 작업의 메트릭을 적재하거나 보안상 내부 접근을 제어하는 폐쇄망 등에서 프로메테우스로 데이터를 보내는데 사용합니다. --set pushgateway.enabled=false \ # 얼럿매니저를 사용하지 않도록 설정합니다. 얼럿매니저는 이전 포스팅에서 다룬 슬랙으로 알림받는 것과 유사한 기능을 제공합니다. --set alertmanager.enabled=false \ # 테인트가 설정된 노드의 설정을 무시하는 톨러레이션을 설정합니다. 톨러레이션을 설정하면 마스터 노드에도 노드 익스포터를 배포할 수 있고, 프로메테우스가 마스터 노드의 메트릭 데이터를 수집할 수 있습니다. --set nodeExporter.tolerations[0].key=node-role.kubernetes.io/master \ --set nodeExporter.tolerations[0].effect=NoSchedule \ --set nodeExporter.tolerations[0].operator=Exists \ # PVC 동적 프로비저닝을 사용할 수 없는 가상 머신 환경이기 때문에 이미 만들어 놓은 prometheus-server라는 이름의 PVC를 사용하게 합니다. --set server.persistentVolume.existingClaim="prometheus-server" \ # 프로메테우스 서버 구성 시 컨테이너에 할당할 사용자 ID와 그룹 ID를 설정합니다. --set server.securityContext.runAsGroup=1000 \ --set server.securityContext.runAsUser=1000 \ # MetalLB로부터 외부 IP를 할당받기 위해 타입을 로드밸런서로 설정합니다. --set server.service.type="LoadBalancer" \ # 프로메테우스 설정을 변경할 때 lockfile(잠긴 파일)이 있으면 변경 작업을 실패할 수 있습니다. 특히 얼럿매니저를 나중에 설치할 때 관련 문제가 발생할 수 있으므로 lockfile이 생성되지 않게 설저압니다. --set server.extraFlags[0]="storage.tsdb.no-lockfile"
-
-
프로메테우스 차트를 설치하고 나면 구성 요소인 프로메테우스 서버, 노드 익스포터, 쿠버 스테이트 메트릭이 설치됐는지 확인합니다.
- 이때 노드 익스포터가 여러 개인 이유는 노드마다 메트릭을 수집하기 위해 데몬셋으로 설치했기 때문입니다.
kubectl get pods --selector=app=prometheus

-
프로메테우스 서버에서 제공하는 웹 UI로 접속하기 위한 프로메테우스 서비스의 IP주소가 192.168.1.12인지 확인합니다.
kubectl get service prometheus-server

-
웹 브라우저에서 192.168.1.12로 접속해 프로메테우스 웹 UI가 정상적으로 작동하는지 확인합니다.
웹 UI 설치가 끝났으니 설치된 웹 UI의 기능을 하나씩 살펴봅시다!
프로메테우스의 웹 UI 다루기
프로메테우스는 서버의 API에서도 필요한 메트릭을 확인할 수 있지만, 일반적으로 웹 UI에서 확인합니다.
따라서 웹 UI를 이해하면 프로메테우스의 동작 원리를 파악할 수 있습니다.
Graph
프로메테우스에 접속하면 가장 먼저 Graph 메뉴를 만나게 됩니다.
그래프는 프로메테우스의 웹 UI에서 제공하는 가장 중요한 내용을 처리하는 페이지입니다!
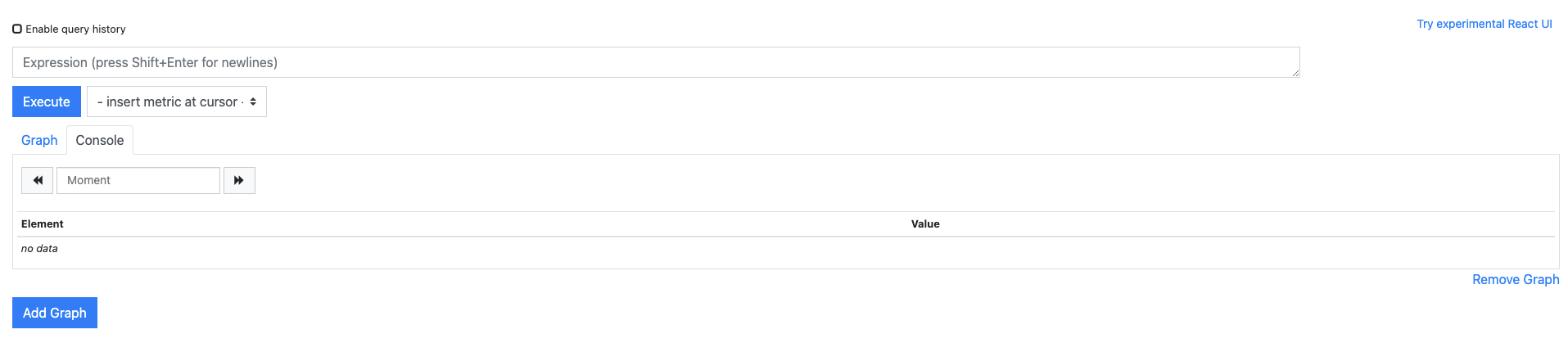
Graph 메뉴에서는 다음과 같은 내용을 처리합니다.
-
쿼리 입력기
- 프로메테우스가 적재한 메트릭 데이터를 조회할 수 있는 표현식(Expression)을 입력하는 곳
- 이때 사용하는 표현식은 PromQL(Prometheus Query Language)이라는 프로메테우스에서 제공하는 쿼리 언어
- 프로메테우스는 시계열 DB를 사용하므로 다른 RDBMS처럼 쿼리문을 작성해 효과적으로 필요한 메트릭을 추출
- PromQL 문법에 맞는 표현식을 쿼리 입력기에 입력한 후 Enter를 누르거나 Execute 버튼을 눌러 필요한 메트릭 값을 가지고 옴
- PromQL는 수집한 메트릭을 표현하는 가장 중요한 문법이라서 잠시후 자세히 다뤄봅니다.
-
Execute
- PromQL을 실행하는 버튼
- 누르면 표현식에 맞는 메트릭 데이터를 화면에 표시
-
Graph
- PromQL로 프로메테우스가 적재한 메트릭 데이터를 확인할 때 시각적으로 표현해주는 옵션
- Graph 탭을 누르면 데이터를 시각화한 영역형 또는 막대형 차트를 표시
-
Console
- PromQL로 추출된 메트릭 데이터를 보여주는 기본 옵션
- 추출된 데이터는 표 형식으로 나오기 때문에 개별 데이터를 파악하기에 용이
-
Add Graph
- 그래프 추가처럼 보이나 실제로는 쿼리 입력기를 하나 더 추가해 또 다른 메트릭을 확인하는 버튼
-
Remove Graph
- 현재 쿼리 입력기를 제거하는 버튼
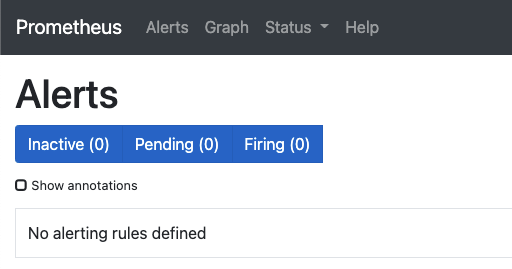
Alert
Alert은 상단 왼쪽에 있습니다.
경보 화면에서는 현재 프로메테우스 서버에 등록된 경보 규칙과 경보 발생 여부를 확인할 수 있습니다.
Status
Status(상태)를 클릭하면 하위 메뉴가 보입니다.
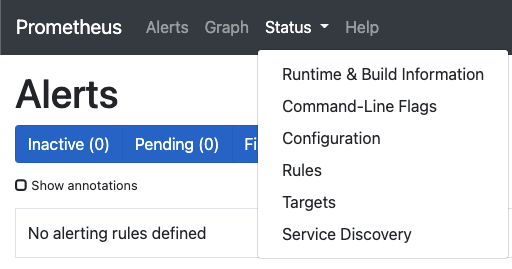
각 하위 메뉴는 다음과 같은 내용을 제공합니다.
-
Runtume & Build Information
- 프로메테우스 서버의 업타임 같은 런타임 관련 정보, 버전을 나타내는 빌드 정보 등의 정보 확인
-
Command-Line Flags
- 프로메테우스 서버가 실행될 때 인자로 입력받았던 값을 보여줌
-
Configurtion
- 프로메테우스 서버가 구동될 때 설정된 값 표시
-
Rules
- 프로메테우스 서버에 등록된 다양한 규칙 확인
-
Targets
- 프로메테우스 서버가 수집해오는 대상의 상태 확인
-
Service Discovery
- 프로메테우스 서버가 서비스 디스커버리 방식으로 수집한 대상들에 대한 정보 요약
수집 대상의 상태를 한 번 확인해 봅시다. Status > Targets 메뉴를 선택합니다.
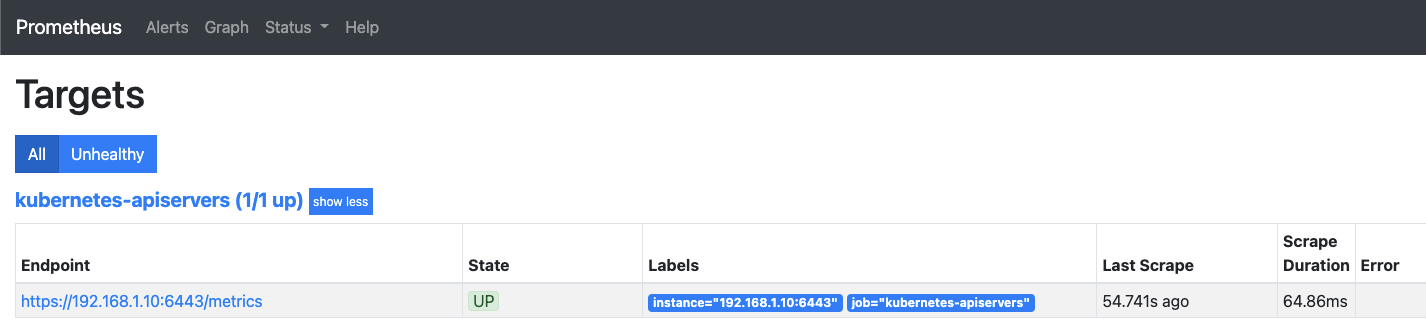




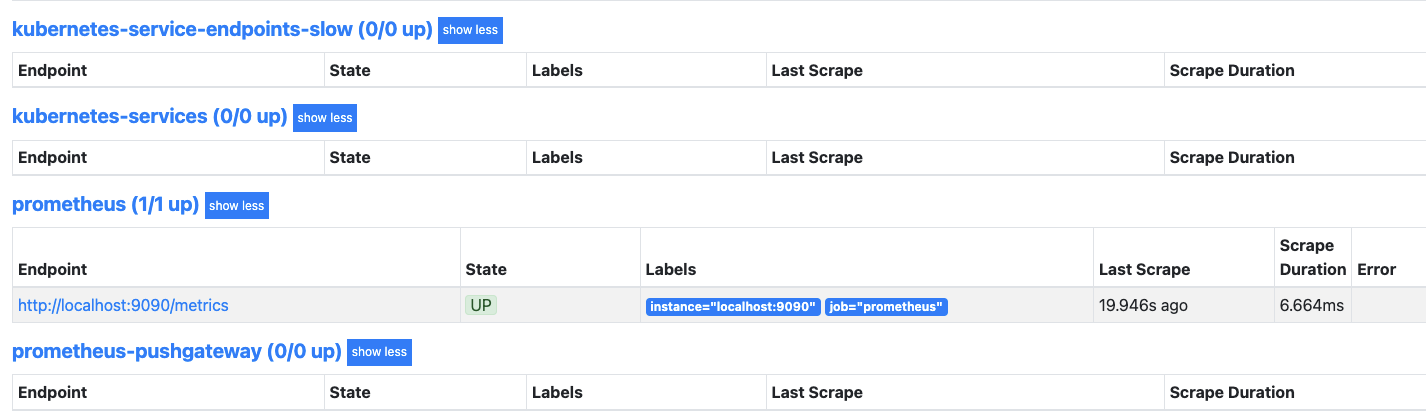
프로메테우스가 메트릭 데이터를 수집하는 대상과 메트릭 데이터를 공개하는 대상의 상태가 표시됩니다.
그림을 보면 프로메테우스 서버가 쿠버네티스 API 서버, 노드, cAdvisor, 파드, 자기 자신이 공개하는 메트릭 데이터를 /metrics 로 수집하고 있습니다.
이떄 cAdvisor의 메트릭은 공개하는 경로가 /metrics/cadvisor로 조금 다른데,
이는 메트릭을 공개하는 대상에 따라 메트릭을 공개하는 경로를 다르게 설정할 수 있기 때문입니다.
그런데 수집 대상은 어떻게 가지고 온 걸까요??
프레메테우스의 수집 대상을 모든 환경에 맞게 입력해야 할까요?
그렇지 않습니다. 프로메테우스에는 수집 대상을 확인하는 특별한 방법이 있습니다!
서비스 디스커버리로 수집 대상 가져오기
프로메테우스는 수집 대상을 자동으로 인식하고 필요한 정보를 수집합니다.
정보를 수집하려면 일반적으로 에이전트를 설정해야 하지만,
쿠버네티스는 사용자가 에이전트에 추가로 입력할 필요 없이 자동으로 메트릭을 수집할 수 있습니다.
이는 프로메테우스 서버가 수집 대상을 가져오는 방법인 서비스 디스커버리 덕분입니다.
서비스 디스커버리는 다음 순서로 동작합니다.
-
프로메테우스 서버는 컨피그맵에 기록된 내용을 바탕으로 대상을 읽어옵니다.
-
읽어온 대상에 대한 메트릭을 가져오기 위해 API 서버에 정보를 요청합니다.
-
요청을 통해 알아온 경로로 메트릭 데이터를 수집합니다.
이와 같은 순서로 프로메테우스 서버와 API 서버가 주기적으로 데이터를 주고받아 수집 대상을 업데이트하고,
수집 대상에서 공개되는 메트릭을 자동으로 수집합니다!
서비스 디스커버리 방법은 대상에 따라 크게 2가지 경로로 나뉩니다.
쿠버네티스 API 서버에 직접 연결돼 메트릭을 수집하는 cAdvisor와
API 서버가 경로를 알려 주어 메트릭을 수집할 수 있는 에이전트 입니다.
프로메테우스에서 에이전트는 보통 익스포터라 하므로 이후에는 익스포터로 부르겠습니다.
그러면 2가지 경로에 대해서 실습을 통해 살펴봅시다!
cAdvisor
cAdvisor의 메트릭이 API 서버를 통해 노출되면 프로메테우스 서버가 쉽게 수집하도록 변환하는 과정을 거칩니다.
직접 새로운 오브젝트를 배포하고 프로메테우스에 수집되는 메트릭을 관찰해서 cAdvisor의 작동 원리와 수집과정을 알아봅시다.
cAdvisor로 메트릭 수집하고 확인하기
-
프로메테우스의 웹 UI로 갑니다.
- cAdvisor로 수집된 메트릭은 container라는 이름으로 시작하므로 Graph 메뉴의 쿼리 입력기에
container_memory_usage_bytes를 입력하고 Execute 버튼을 누릅니다. - 쿼리 입력기에 일부만 입력해도 나머지는 자동완성되니 나타나는 쿼리 중에 선택해도 됩니다.
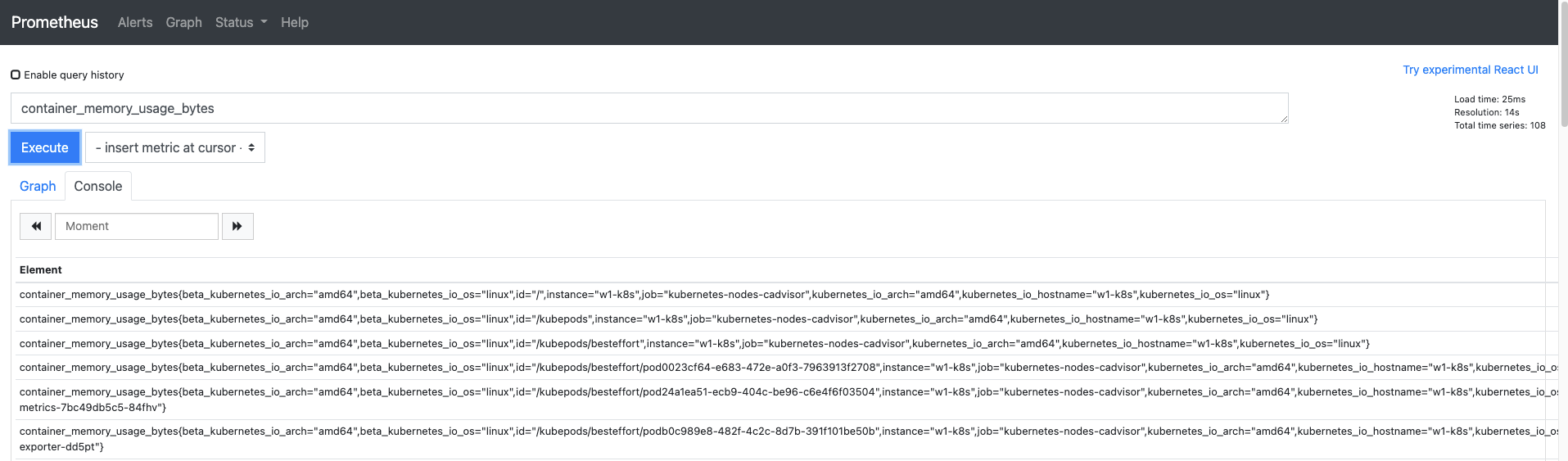
- 출력된 결과 중 오른쪽 상단에 나온 3개의 내용은 다음과 같습니다.
- Load time : PromQL이 동작하는 데 걸린 시간입니다. 단위는 ms입니다.- Resolution : 수집된 데이터로 지정된 초 단위의 그래프를 그립니다.
- Total time series : PromQL로 수집괸 결과의 개수입니다.
- cAdvisor로 수집된 메트릭은 container라는 이름으로 시작하므로 Graph 메뉴의 쿼리 입력기에
-
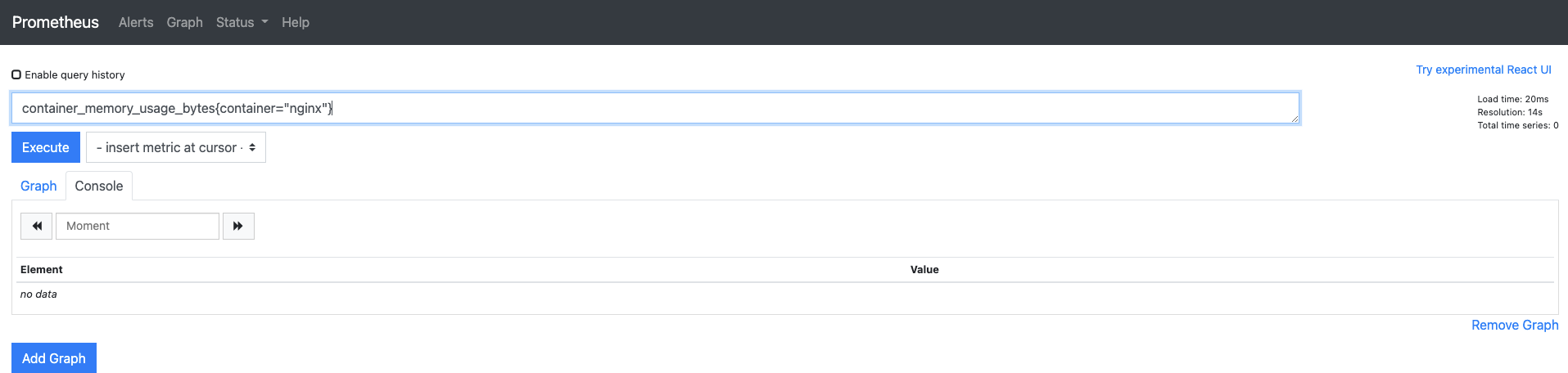
새로 디플로이먼트를 추가하면 자동으로 메트릭을 수집하는지 확인해 봅시다.
- PromQL문에 추가할 파드의 이름으로 검색하도록 {container="nginx"}를 추가하고 다시 Execute 버튼을 누릅니다.
- 이런 구문을 레이블이라고 하는데, PromQL에서 필요한 내용을 추출할 떄 사용합니다.
- 현재 nginx 디플로이먼트가 설치돼 있지 않은 상태이기 때문에 추가 구문을 입력하면 아무것도 검색되지 않습니다.
-
Terminus에서 nginx 디플로이먼트를 배포하고 1~2분 정도 기다립니다.
kubectl create deployment nginx --image=nginx

-
웹 UI에서 Execute 버튼을 다시 눌러 배포한 nginx 디플로이먼트에 대한 메트릭이 자동으로 수집되는지 확인합니다.
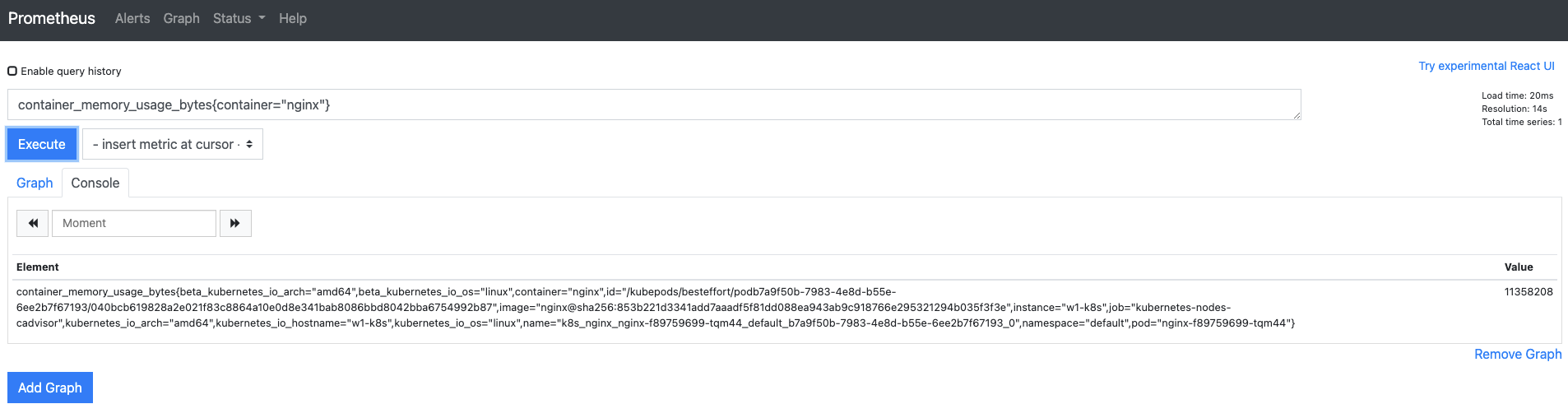
- 메트릭이 자동으로 수집되는 것은 컨피그맵에 수집 대상이 지정됐기 때문입니다. 앞에서 수집된 내용은 다음 명령을 실행해 나온 내용 중에 56~68번줄에 정의돼 있습니다.
kubectl get configmap prometheus-server -o yaml | nl
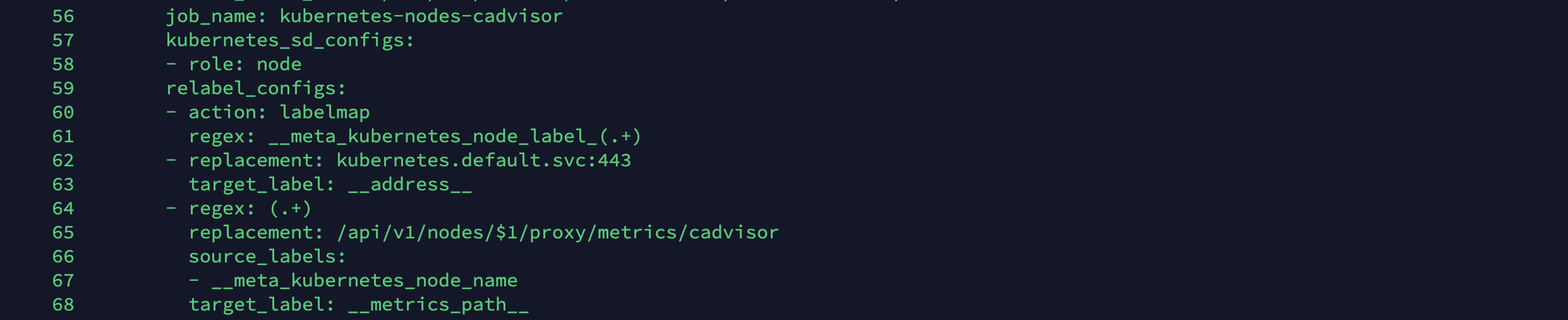
56 job_name: kubernetes-nodes-cadvisor 57 kubernetes_sd_configs: # 쿠버네티스 서비스 디스커버리 구성 구문 시작 58 - role: node 59 relabel_configs: # 프로메테우스의 레이블 다시 정의 60 - action: labelmap # 레이블 변환하는 방식을 지정 61 regex: __meta_kubernetes_node_label_(.+) # 레이블 변환 부분을 탐색하는 조건식 62 - replacement: kubernetes.default.svc:443 # 설정된 레이블에 교체할 값 63 target_label: __address__ # 값을 교체할 레이블에 설정 64 - regex: (.+) # 원본 레이블에서 추출할 값을 지정하는 조건식 65 replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor # 원본 레이블에서 추출한 값을 변수에 넣어 대상 레이블에 들어갈 값을 설정 66 source_labels: # 교체 대상이 되는 값이 있는 원본 레이블 지정 67 - __meta_kubernetes_node_name # 지정된 레이블을 교체 대상으로 설정 68 target_label: __metrics_path__ # 값을 교체할 레이블에 설정 -
이번에는 디플로이먼트를 삭제하면 더 이상 메트릭이 수집되지 않음도 확인해 봅시다.
- 배포된 nginx 디플로이먼트를 삭제하고 5~10분 정도를 기다립니다.
kubectl delete deployment nginx

- 현재 PromQL 설정으로 검색하면 5분 전 메트릭까지 검색해 결과로 보여줍니다. 따라서 더 이상 메트릭이 검색되지 않은 것을 확인하려면 생성할 때보다 더 오래 기다려야 합니다.
- 이때 메트릭 자제가 지워진 것이 아니라 웹 UI에서 쿼리로 검색되지 않을 뿐입니다.(이전 메트릭은 저장되어 있음)
이처럼 cAdvisor는 각 노드에 컨테이너 시스템 정보를 담고 있는 특정 파일들을 읽어 들여 메트릭을 수집합니다.
그리고 프로메테우스가 수집할 수 있도록 컨테이너 메트릭을 프로메테우스의 메트릭으로 변환해 공개합니다.
익스포터로 메트릭 수집하고 확인하기
서비스 디스커버리에서 수집은 자동으로 이뤄지지만, 사실 익스포터는 사전 준비 작업 2가지를 해야합니다.
첫 번쨰로 API 서버에 등록돼 경로를 알 수 있게 해야 하고,
두 번째로 익스포터가 데이터를 프로메테우스 타입으로 노출해야 합니다.
익스포터에 필요한 사전 준비 작업을 진행하고, 노출된 메트릭을 확인해 보겠습니다.
-
API 서버에 등록될 구성이 포함된 nginx-status-annot.yaml을 배포합니다.
kubectl apply -f ~/_Book_k8sInfra/ch6/6.2.3/nginx-status-annot.yaml

-
프로메테우스 서버가 배포된 애플리케이션을 API 서버에서 찾아 메트릭을 수집하려면 애너테이션 설정(annotation)이 가장 중요한데, 이는 매니페스트에 적용돼 있습니다.
cat ~/_Book_k8sInfra/ch6/6.2.3/nginx-status-annot.yaml | nl
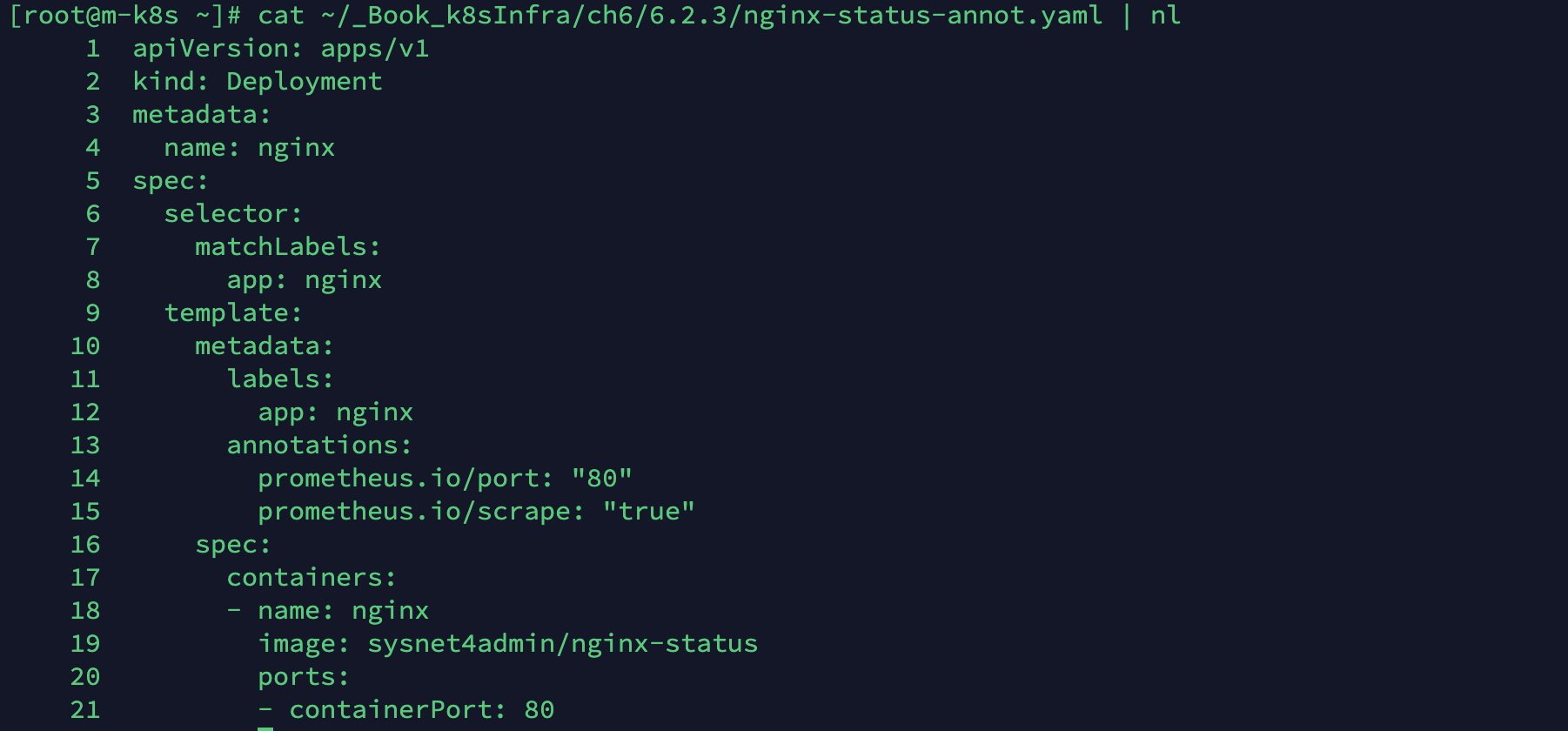
애너테이션으로 매트릭 수집하기
annotation은 일반적으로 소스 코드에 주석으로 추가되는 메타데이터입니다.
따라서 여러 애플리케이션이나 다른 도구에 정보를 전달하는 역할을 합니다.
프로메테우는 애너테이션을 이용해 수집 대상을 판별하고 경로를 재조합합니다.
애너테이션으로 경로를 노출하고 메트릭을 수집하려면 다음과 같이 합니다.
1. 프로메테우스에 메트릭을 공개하려는 애플리케이션은 애너테이션이 매니페스트에 추가돼 있어야 합니다. 이때 애너테이션에 추가되는 구문은 prometheus.io/로 수집합니다.
2. 작성된 매니페스트를 쿠버네티스 클러스터에 배포해 애너테이션을 포함한 정보를 API 서버에 등록합니다.
3. 프로메테우스 서버가 prometheus.io/로 시작하는 애너테이션 정보를 기준으로 대상의 주소를 만듭니다.
4. 프로메테우스 서버가 애너테이션을 기준으로 만든 대상의 주소로 요청을 보내 메트릭 데이터를 수집합니다.
-
API 서버를 통해 배포된 nginx 디플로이먼트 정보가 프로메테우스 서버에 등록됐는지 확인합니다.
- 웹 UI에서 Status > Targets을 선택합니다. 배포된 nginx 디플로이먼트의 메트릭이 수집되는지 확인합니다.
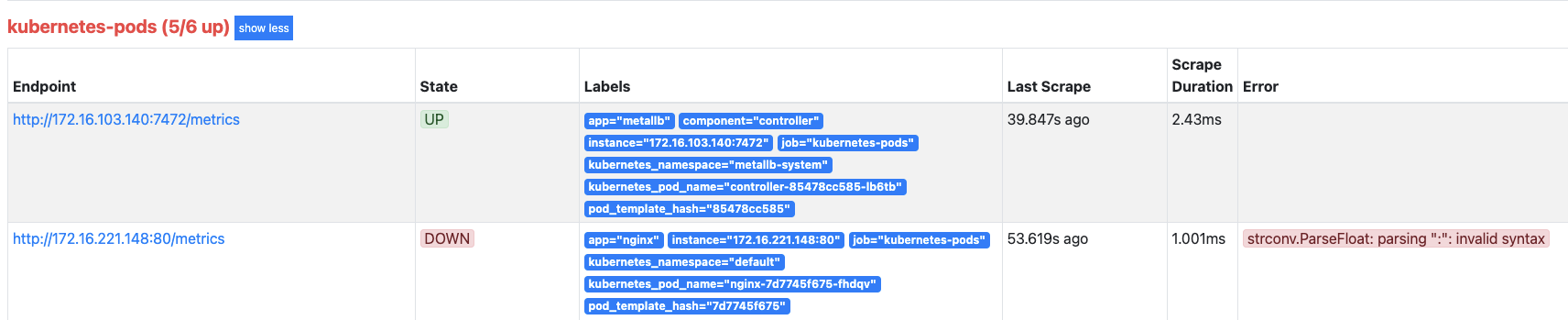
- nginx 디플로이먼트는 등록됐지만, 메트릭이 수집되지 않습니다.
- 메트릭이 수집되지 않은 것은 메트릭이 공개되지 않았기 때문입니다. 프로메테우스에서는 크게 두 가지 방법으로 메트릭을 공개할 수 있습니다.
- 첫 번째는 Go, Rust, C#, Python, java와 같은 프로그래밍 언어의 프러메테우스 SDK를 사용해 직접 메트릭을 공개하도록 작성하는 방법입니다.
- 두 번째는 이미 만들어 둔 익스포터를 사용해 메트릭을 공개하는 방법입니다. 이번 실습에서는 이미 만들어진 익스포터로 메트릭을 공개하겠습니다.
- 웹 UI에서 Status > Targets을 선택합니다. 배포된 nginx 디플로이먼트의 메트릭이 수집되는지 확인합니다.
-
실습에서는 NGINX를 기준으로 설치했기 때문에 NGINX에서 제공하는
nginx-prometheus-exporter를 추가로 구성한 nginx-status-metrics.yaml을 배포합니다.kubectl apply -f ~/_Book_k8sInfra/ch6/6.2.3/nginx-status-metrics.yaml

- nginx-prometheus-exporter는 멀티 컨테이너 패턴 중에 하나인 사이드카(Sidecar) 패턴으로 작성돼 있습니다.
- 사이드카 외에 여러 가지 패턴으로 파드의 멀티 컨테이너를 구성할 수 있는데, 이는 뒤에 나오는 멀티 컨테이너 패턴을 참고해 주세요.
멀티 컨테이너 패턴
파드 내부에 컨테이너를 여러 개 구성하는 방법은 몇 가지 있습니다.
- 사이드카(Sidecar) : 메인 컨테이너의 기능을 확장하거나 기능을 향상하고자 할 때 추가하는 패턴입니다.
- 앰버서더(Ambassador) : 사용자가 외부에서 접근할 때 앰배서더 컨테이너를 통해 통신이 이루어지는 형태로, 세부적인 외부 접근 대상이나 방법은 앰배서더 컨테이너에 위임합니다. 주로 프록시 컨테이너를 구성해 외부의 접근을 제어하고 내부 자원을 보호하는 구성이 앰배서더 패턴에 속합니다.
- 어댑터(Adapter) : 메인 컨테이너의 정보를 외부에서 사용할 수 있는 형식으로 변환하는 컨테이너가 추가된 형태입니다. 데이터 형태를 변환하므로 앞에서 다룬 NGINX의 익스포터는 어댑터 패턴이라고 할 수 있습니다.
이렇게 멀티 컨테이너 패턴은 한 가지 형태로 고정된 것이 아니라 형태를 해석하는 방식에 따라 한 가지 이상으로 부를 수 있습니다!
-
다시 프로메테우스 웹 UI로 가서 nginx 디플로이먼트에 대한 메트릭이 수집되고 있는지 확인합니다.
- 수집되고 있지 않다면 새로고침하거나 좀 더 기다렸다가 확인합니다.
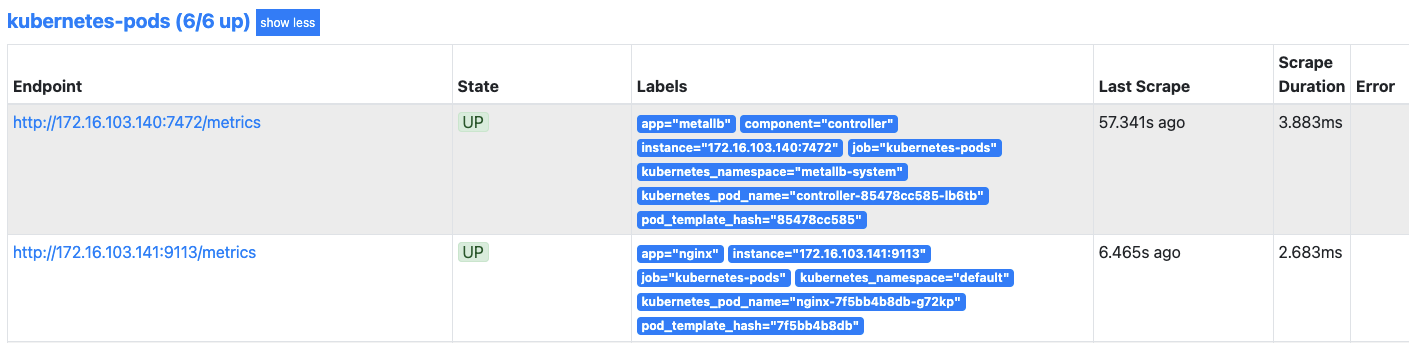
- 수집되고 있지 않다면 새로고침하거나 좀 더 기다렸다가 확인합니다.
-
다음 실습을 위해 디플로이먼트를 삭제합니다.
kubectl delete -f ~/_Book_k8sInfra/ch6/6.2.3/nginx-status-metrics.yaml

다양한 종류의 프로메테우스 익스포터
프로메테우스는 대상을 모니터링하기 위해 다양한 형태의 익스포터를 사용합니다.
프로메테우스 공식 홈페이지에서 소개하는 익스포터의 종류는 10가지 이상이며,
사용자가 직접 익스포터를 제작할 수도 있어서 앞으로도 계속 늘어날 것입니다.
사용하려는 도구들을 모니터링해야 한다면 프로메테우스 생태계와 각 업체에서 제공하는 익스포터를 사용해
메트릭 데이터를 수집하면 됩니다.
프로메테우스 익스포터를 종류별로 정리하면 다음과 같습니다.
| 분야 | DB | 메시징 시스템 | 스토리지 | 외부 모니터링 시스템 |
|---|---|---|---|---|
| 주요 관심사 | 안정성 지표, 내부 구조 | 처리량, 전달 성공율 | 사용량 | 외부 시스템 통합 |
| 대표적 수집 대상 | ElasticSearch, MongoDB, MySQL, Oracle, PostgreSQL | Kafka, NATS, MQTT, RabbitMQ | Ceph, Gluster, GPFS, NetApp E-Series | AWS CloudWatch, Google Stackdriver(Operation Suite), Azure Monitor, JMX |
여러 익스포터 중 쿠버네티스에서 가장 많이 씨이는 노드 익스포터와 쿠버 스테이트 메트릭을 살펴보겠습니다.
노드 익스포터로 쿠버네티스 노드 메트릭 수집하기
노드 익스포터는 익스포터 중에서도 쿠버네티스 노드의 상태 값을 메트릭으로 추출하는 데 특화돼 있습니다.
노드 익스포터는 노드의 /proc과 /sys에 있는 값을 메트릭으로 노출하도록 구현돼 있습니다.
그리고 노드 익스포터를 실행하기 위해서 쿠버네티스 노드마다 1개씩 배포할 수 있는 데몬셋으로 구현돼 배포됩니다.
노드 익스포터가 배포하는 핵심 메트릭인 /proc과 /sys에는 다음 정보들이 저장돼 있습니다.
-
/proc
- 리눅스 운영 체제에서 구동 중인 프로세스들의 정보를 파일 시스템 형태로 연결한 디렉터리입니다.
- 디렉터리 안에는 현재 구동 중인 프로세스들의 PID가 디렉터리 형태로 나타나며, 각 디렉터리 내부에 해당 프로세스에 대한 상태나 실행 환경에 대한 정보가 들어있습니다.
- 모니터링 도구는 이 디렉터리를 통해 시스템에서 구동 중인 프로세스의 정보나 상태, 자원 사용량 등을 알 수 있습니다.
-
sys
- 저장 장치, 네트워크 장치, 입출력 장치 같은 각종 장치를 운영 체제에서 사용할 수 있도록 파일 시스템 형태로 연결한 디렉터리입니다.
- 기존에 /proc에 연결돼 있던 커널 장치 드라이버 등이 /proc에서 /sys로 분리됐습니다.
- 이 디렉터리 내부에 있는 파일들을 분석하면 전체 장치의 상태를 알 수 있기 떄문에 모니터링 도구는 이 디텍터리를 시스템 장치의 상태 저보를 수집하는 데 사용합니다.
노드 익스포터는 각 쿠버네티스 노드의 /proc, /sys에 있는 파일들으 ㄹ읽어서 프로메테우스가 받아들일 수 있는 메트릭 형태로 변환합니다.
그리고 변환한 메트릭을 HTTP 서버를 통해 /metrics 주소로 공개합니다.
그럼 실제로 노드 익스포터를 통해 수집된 메트릭 값을 확인해 보겠습니다.
참고로, cAdvisor의 메트릭이 container로 시작하는 것처럼 노드 익스포터의 메트릭은 node로 시작합니다.
노드 익스포터로 수집된 메트릭 확인하기
-
프로메테우스 웹 UI에서 Graph 메뉴로 이동합니다.
- 쿼리 입력기에
node_cpu_seconds_total을 입력하고 엔터나 execute 버튼을 누릅니다. - 해당 쿼리는 노드의 CPU 상태별로 사용된 시간을 합해서 보여줍니다.
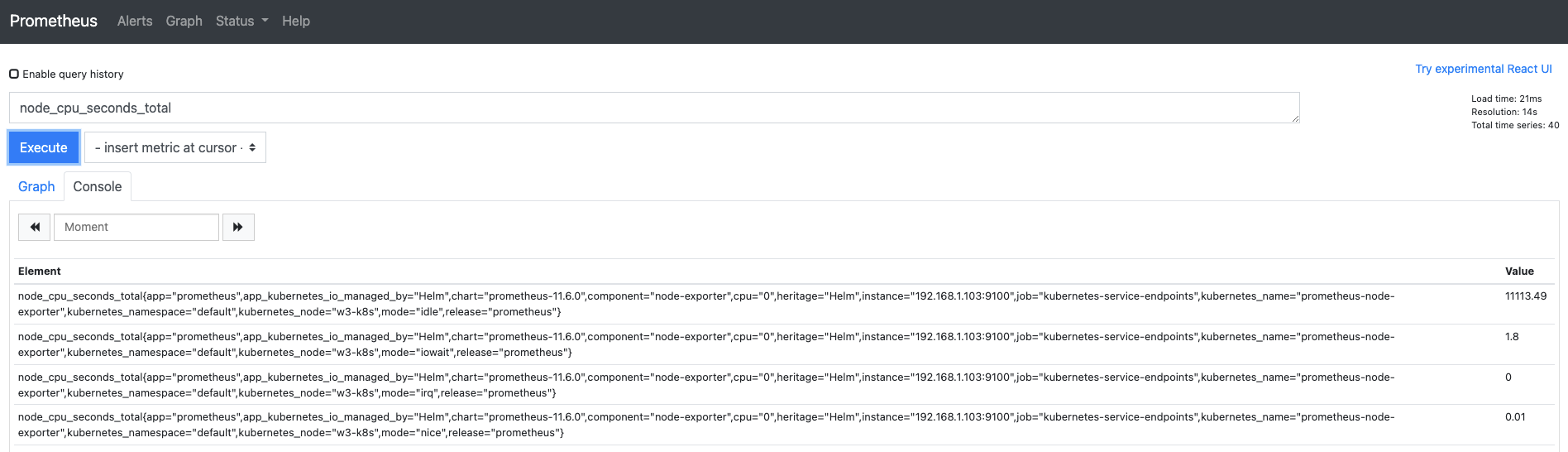
- 쿼리 입력기에
-
누적된 CPU 상태 값을 봤으니 현재 상태에서 주비된 메트릭을 확인해 보겠습니다.
- 쿼리 입력기에
node_memory_MemAvailable_bytes을 입력하고 Execute를 누릅니다. - 해당 쿼리는 노드별로 현재 사용 가능한 메모리의 용량을 표시하는데, 이때 단위는 바이트(Bytes)입니다.
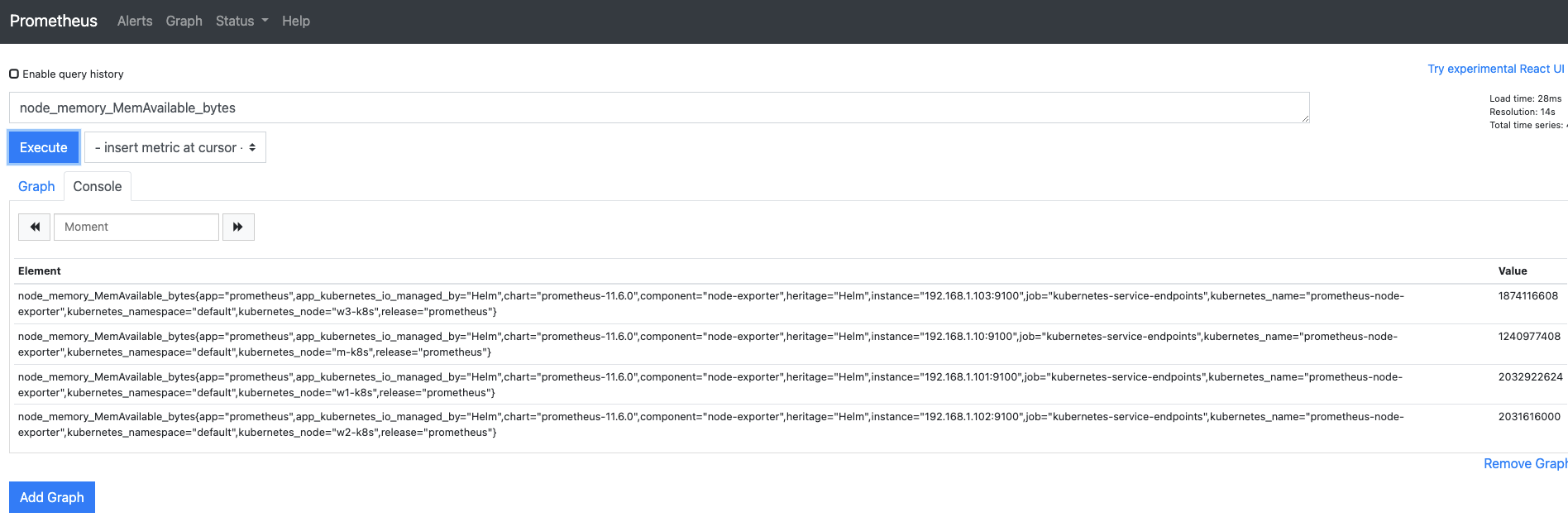
- 쿼리 입력기에
노드 익스포터를 통해 메트릭이 정상적으로 수집되는 것을 확인했습니다.
다음으로 쿠버네티스의 자체 메트릭을 수집하는 쿠버 스테이트 메트릭을 살펴보겠습니다.
쿠버 스테이트 메트릭으로 쿠버네티스 클러스터 메트릭 수집하기
쿠버 스테이트 메트릭은 이름에서 알 수 있듯이 쿠버네티스 상태를 보여주는 메트릭입니다.
쿠버네티스 상태에 관한 정보를 가지고 와서 프로메테우스가 받아들일 수 있는 메트릭 형태로 변환하고
변환한 메트릭을 HTTP 서버를 통해 /metrics 주소로 공개하는 부분은 노드 익스포터와 동일합니다.
그러나 각 노드의 특정 디렉터리를 마운트해서 사용하지 않고 이미 API 서버에 모인 값들을 수집한다는 점이 다릅니다.
쿠버 스테이트 메트릭을 통해 수집된 메트릭 값을 직접 확인해 보겠습니다.
쿠버 스테이트 메트릭도 kube라는 고유의 문자열로 시작합니다.
-
프로메테우스 쿼리 입력기에
kube_pod_container_status_restarts_total을 입력하고 Execute를 누릅니다.- 해당 쿼리는 쿠버네티스에 배포된 파드가 다시 시작하는 경우 이를 누적해 기록한 메트릭 데이터입니다.
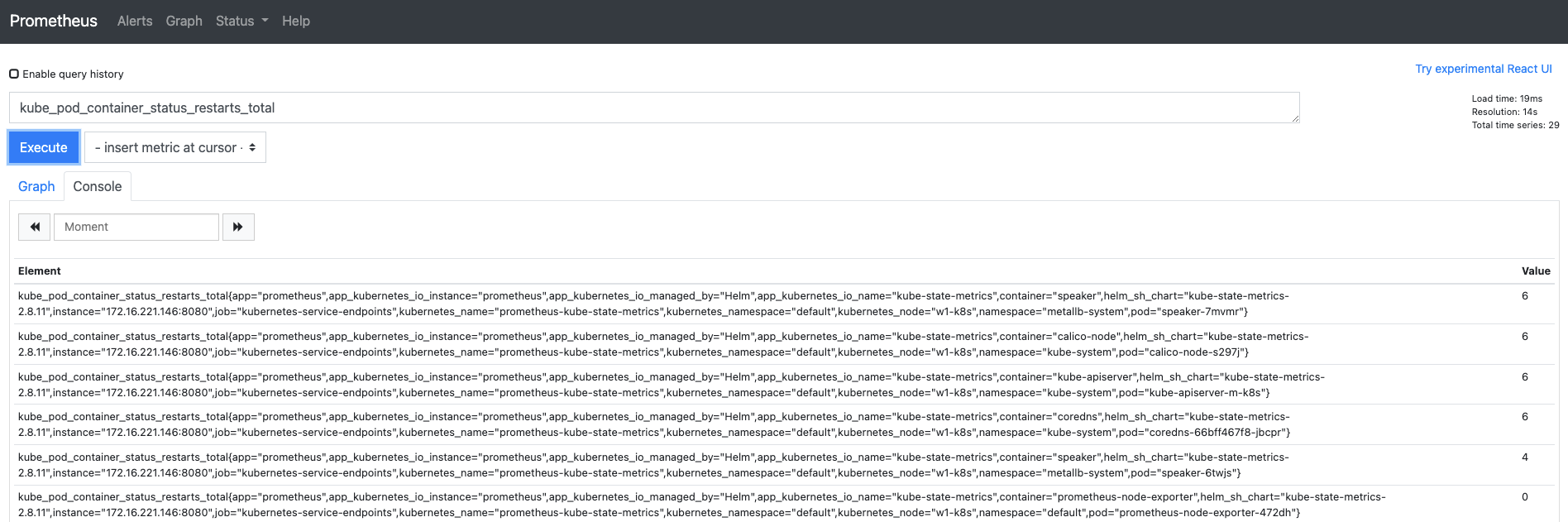
- 해당 쿼리는 쿠버네티스에 배포된 파드가 다시 시작하는 경우 이를 누적해 기록한 메트릭 데이터입니다.
-
이번엔 쿠버네티스 현재 상태를 알아보는 메트릭을 검색해 보겠습니다.
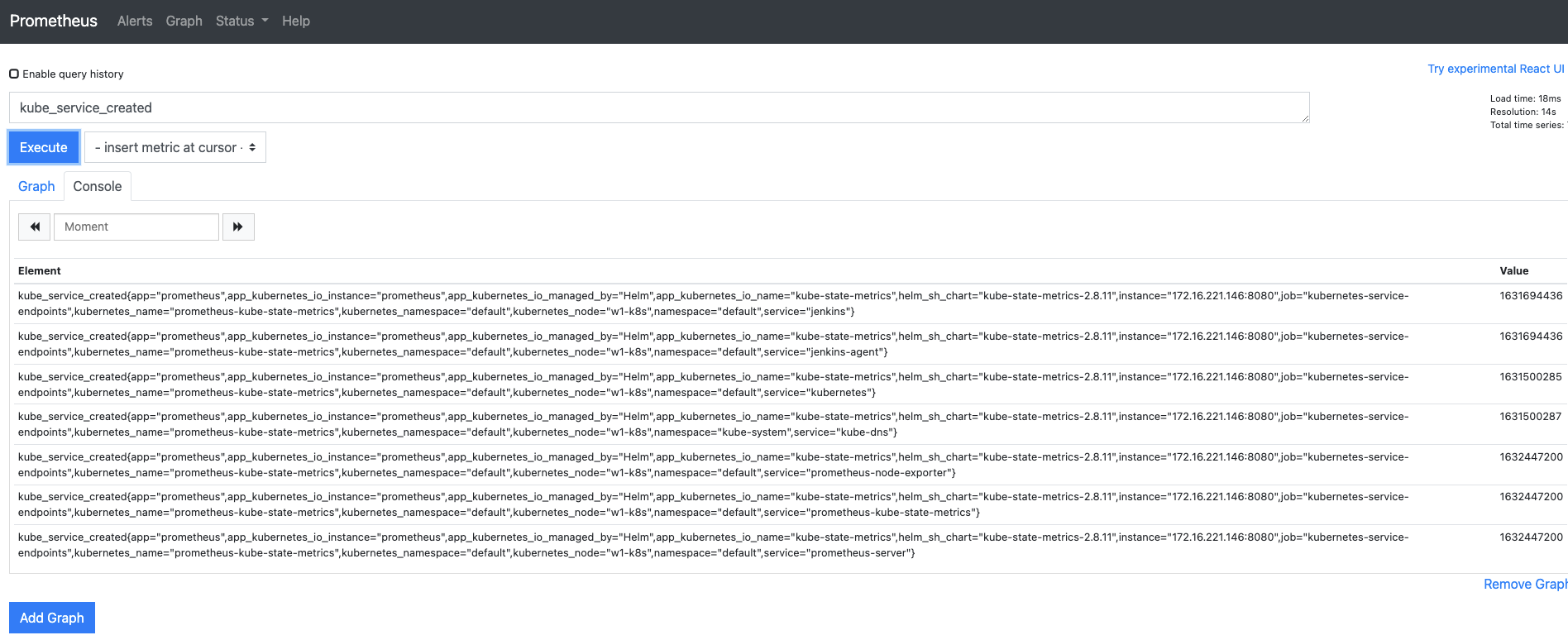
- 쿼리 입력기에
kube_service_created를 입력하고 Execute를 누릅니다. - 다음과 같이 쿠버네티스에 존재하는 서비스들이 생성된 시간을 보여줍니다.
- 이때 출력되는 시간은 유닉스 시간으로, 1970년 1월 1일 00:00:00 협정 세계시(UTC)부터의 경과 시간을 초로 환산해 정수로 나타낸 것입니다.
- 쿼리 입력기에
프로메테우스가 익스포터를 통해 다양한 메트릭 데이터를 자동으로 수집하는 것을 확인했습니다.
쿼리 입력기에 지금까지 소개한 PromQL만 입력하고 결과를 확인해도 충분히 훌륭한 결괏값을 얻을 수 있지만,
사용자가 원하는 형태가 아닐 수도 있습니다.
예를 들어 5분 또는 10분 간의 평균 CPU 사용량과 같은 메트릭을 알고 싶은 경우입니다.
기존 쿼리에 약간의 구문을 추가하면 원하는 결괏값을 얻어낼 수 있습니다.
그러면 원하는 값들을 검색할 수 있는 방법을 배워봅시다!
PromQL로 메트릭 데이터 추출하기
현업에서는 수집된 메트릭 데이터를 그대로 사용하기보다는 필요한 메트릭 데이터를 다시 한 번 가공해서 추출하는 경우가 더 많습니다.
필요한 메트릭 데이터를 정확하게 추출하려면 PromQL을 알아야 합니다.
이 절에서는 PromQL의 표현식과 이를 활용해 필요한 데이터를 추출하는 방법을 알아보겠습니다.
메트릭 데이터 구조
메트릭 데이터를 추출하려면 메트릭 데이터의 구조를 알아야 하빈다.
간단한 예제로 메트릭 데이터의 구조를 살펴봅시다.
웹 UI에서 쿼리 입력기에 up{job="prometheus"}를 입력합니다.
이때 up은 수집 대상이 작동하고 있는지 알려줍니다.
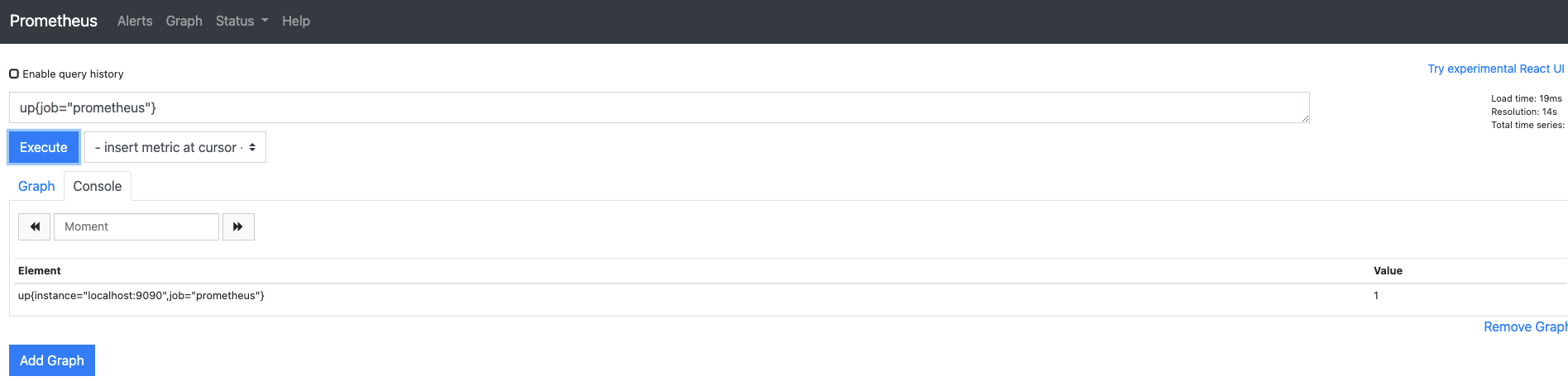
결과로 나온 메트릭 데이터를 보면 up이라는 메트릭 이름을 가지는 대상을 검색하고, 그 중에 job="prometheus"라는 레이블 이름을 검색 조건에 추가합니다.
이를 일반적으로 필터링이라고 하고, 검색 조건에 맞는 메트릭 데이터가 존재하고 추출에 성공하면 1이라는 값으로 표현합니다.
추출된 내용을 보면서 전체적인 메트릭 데이터를 이해해보겠습니다.
메트릭 값의 종류
익스포터에서 이미 두 가지 타입의 메트릭 값을 경험했습니다.
node_cpu_seconds_total과 kube_pod_container_status_restarts_total은 누적되는 메트릭 데이터 값으로,
카운터(Counter) 타입이라고 합니다.
node_memoey_MemAvailable_bytes와 kube_service_created는 특정 시점의 메트릭 데이터 값으로,
게이지(Gauge) 타입이라고 합니다.
바로 앞에서 실행한 up{job="prometheus"}는 지금이라는 시점에 해당하는 메트릭 데이터를 보여주므로 게이지 타입입니다.
이 두 가지 타입 외에서 히스토그램과 서머리 타입이 있습니다.
- 카운터(Counter)
- 누적된 값을 표현하는데 사용하는 메트릭 타입
- 카운터에 누적된 값으로 구간별로 변화율을 파악해 해당 값이 어느 정도 추세로 증가하는지 알 수 있음
- 그래서 이벤트나 오류 등이 급증하는 구간을 파악하는 데 적합
- 값이 누적되기 때문에 특정 순간의 데이터를 표현하는 데는 적합하지 않음
- 카운터는 값을 중점적으로 보기보다 값이 얼마만큼 변했는지 변화율을 주로 확인
- 게이지(Gauge)
- 특정 시점의 값을 표현하는 데 사용하는 메트릭 타입
- 카운터가 누적된 값을 표현해 증가만을 고려하는 것과 달리 게이지는 시점별로 증가나 감소를 모두 표현할 수 있음
- CPU 온도나 메모리 사용량 등은 누적된 값이 필요하지 않고 조회하는 순간의 값이 중요하므로 게이지 타입을 사용
- 히스토그램(Histogram)
- 사전에 미리 정의한 구간 안에 있는 메트릭 값의 빈도를 측정
- 이때 익스포터를 구현한 단계에서 정의한 구간을 버킷(Bucket) 이라고 함
- 예를 들어 히스토그램을 사용해, 클라이언트가 서버로 HTTP 요청을 한 경우 응답시간과 맞는 버킷에 값을 추가하고 이벤트 횟수를 저장해 표시할 수 있음
- 서머리(Summary)
- 히스토그램과 비슷하게 구간 내에 있는 메트릭 값의 빈도를 측정
- 예를 들어 클라이언트 요청에 따른 응답 시간을 관측하고 저장할 때 사용할 수 있음
- 하지만 히스토그램과 달리 구간이 지정되는 것이 아니라 프로메테우스 자체적으로 0~1 사이로 구간을 미리 정해 놓음
일반적으로 메트릭 이름이 어떤 단어로 끝나느냐에 따라 메트릭 값의 타입을 추정할 수 있습니다.
total로 끝나면 누적한 값이므로 카운터 타입이고,
bytes 또는 created라는 단어로 끝나면 해당 시점의 용량 또는 생성됨을 의미하므로 게이지 타입입니다.
좀 더 정확한 메트릭 값의 타입은 각 익스포터에서 공개되는 메트릭 정보를 curl로 조회해 다음과 같이 메트릭 위에 주석으로 확인할 수 있습니다.
curl -s 192.168.1.10:9100/metrics | nl | grep node_memory_MemAvailable_bytes

메트릭 레이블
모든 메트릭 데이터는 하나 이상의 레이블을 가집니다.
프로메테우스의 레이블은 일반적인 주석이 아니라 메트릭 데이터의 다양한 내용을 표현하는 유일한 방법입니다.
따라서 단순히 1~2개의 레이블이 아니라 제공하고 싶은 다수의 내용을 key-value 형태로 넣습니다.
이렇게 제공되는 다수의 레이블로 관리자는 원하는 레이블을 검색하고 선택적으로 추출할 수 있습니다.
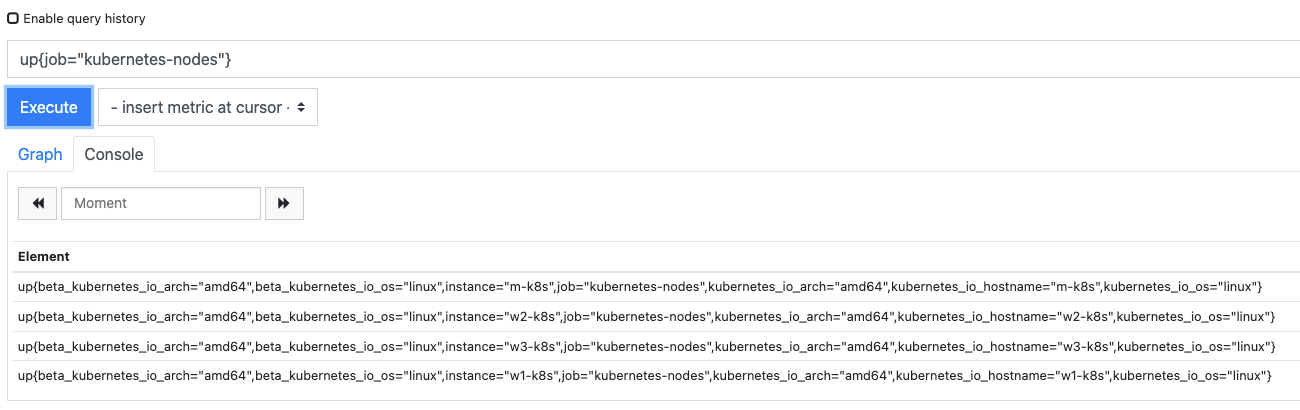
이전에 검색한 up{job="prometheus"}의 메트릭 데이터에는 instance="localhost:9090과 job="prometheus"라는 2개의 레이블만 있지만, up{job="kubernetes-nodes"}로 검색하면 7개의 레이블을 확인할 수 있습니다.
그럼 검색할 수 있는 레이블에는 제한이 있을까요? 아닙니다.
검색된 어떤 메트릭 레이블도 쿼리에 포함할 수 있습니다.
검색 대상을 job에서 instance로 바꿔 up{instance="m-k8s"}를 확인해 봅시다.
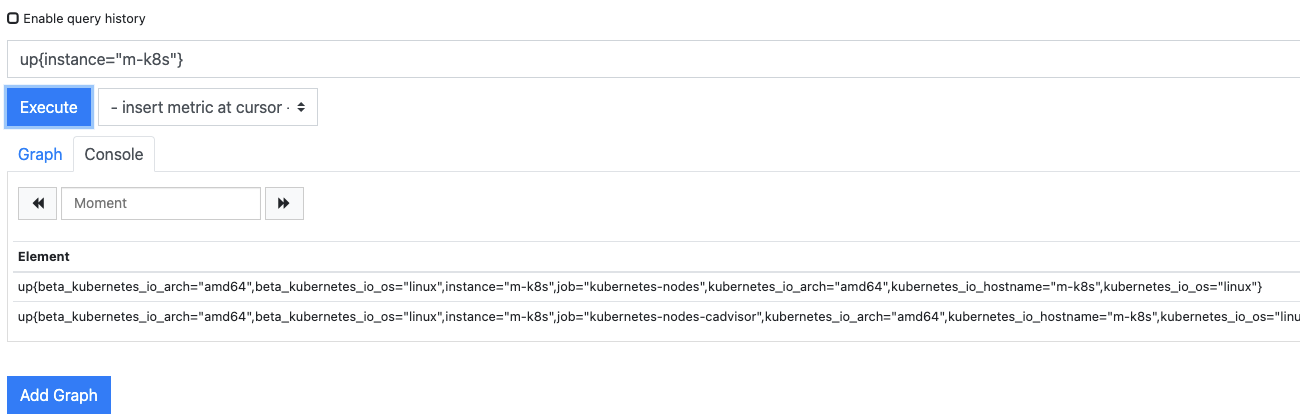
이처럼 메트릭 데이터에 포함되는 레이블로 원하는 값을 쉽게 검색할 수 있습니다.
그런데 instance에서 m-k8s를 제외한 나머지를 확인하거나 특정 문자열만 가진 대상만 검색하고 싶다면 어떻게 할까요?
이번에는 다양한 조건을 줘서 검색하는 방법을 알아보겠습니다.
메트릭 레이블 매처
메트릭 레이블에 조건을 줘서 검색하는 방법을 레이블 매처(Label Matchers) 라고 합니다.
레이블 매처는 레이블이 존재하면 그에 해당하는 메트릭 데이터를 추출합니다.
레이블 매처에는 앞에서 사용한 =을 포함 해 총 4가지 조건 기호가 있습니다.
-
=- 조건에 넣은 값과 레이블 값이 같은 메트릭을 보여줍니다.
- 예를 들어 {instance="m-k8s"}는 instance 레이블 값이 m-k8s인 메트릭을 찾아 출력합니다.
-
!=- 조건에 넣은 값과 레이블 값이 다른 메트릭을 보여줍니다.
- 예를 들어 {instance!="m-k8s"}는 instance 레이블 값이 m-k8s가 아닌 메트릭을 찾아 출력합니다.
-
=~- 조건에 넣은 정규 표현식에 해당하는 메트릭을 보여줍니다.
- 예를 들어 {instance=~"w.+"}는 instance 레이블 값이 w로 시작하는 메트릭을 찾아 출력합니다.
-
!~- 조건에 넣은 정규 표현식에 해당하지 않는 메트릭을 보여줍니다.
- 예를 들어 {instance!~"w.+"}는 instance 레이블 값이 w로 싣작하지 않는 모든 메트릭을 찾아 출력합니다.
레이블 매처를 사용해 다른 조건이 어떻게 검색되는지 확인해 보겠습니다.
레이블 매처로 조건 지정해 필터링하기
-
쿠버네티스는 마스터 노드와 워커 노드로 구성되는데, 일반적으로 마스터 노드에는 중요한 파드들이 이미 스케줄링돼 있습니다.
- 따라서 쿠버네티스 클러스터를 안정적으로 운영하려면 일반 애플리케이션 파드는 워커 노드에만 스케줄링합니다.
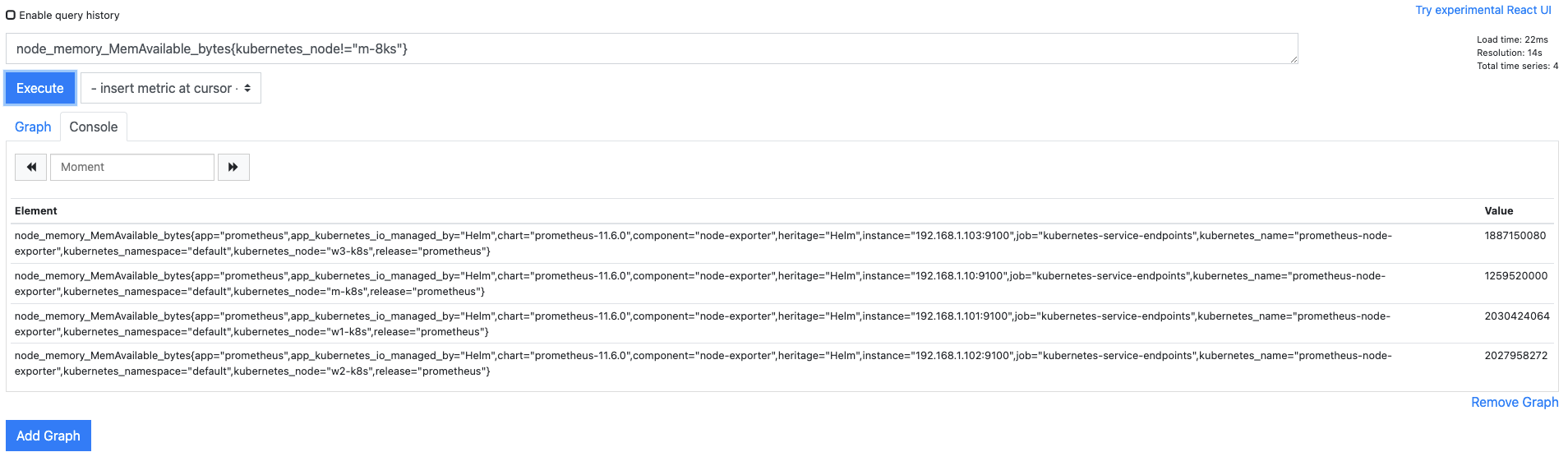
- 그런데 워커 노드의 리소스를 관리하지 않으면 가용할 리소스가 없어서 파드가 배포되지 않을 수 있으므로 워커 노드에 대한 가용 메모리를 모니터링해야 합니다.
!=를 사용한node_memory_MemAvailable_bytes{kubernetes_node!="m-8ks"}는 마스터 노드를 제외한 나머지 워커 노드의 가용 메모리를 검색합니다.
-
단순히 레이블만 이용해서는 충분한 검색 조건을 만들기가 어렵습니다.
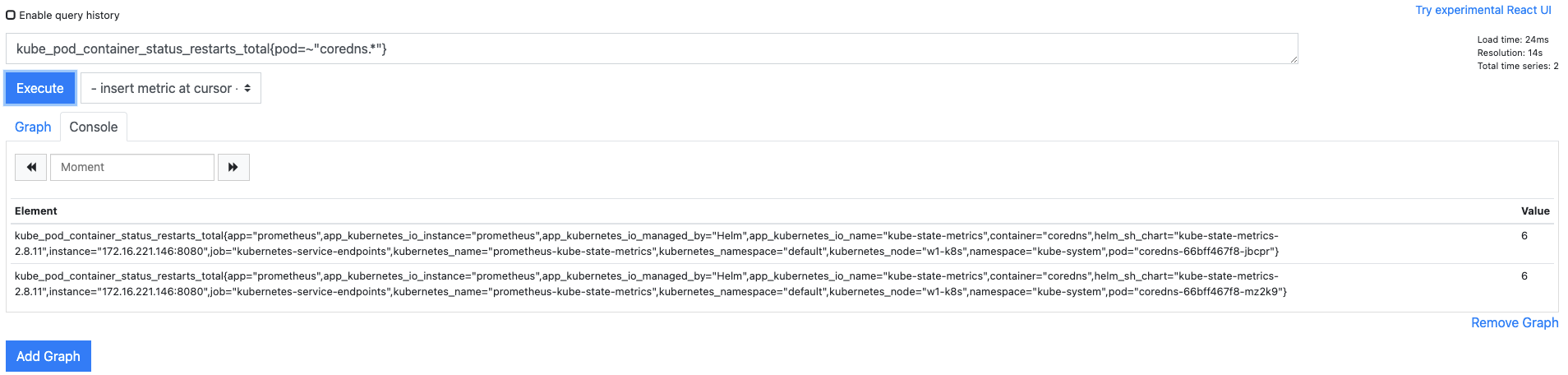
- 예를 들어 Deployment에 속한 파드 이름은 해시 문자가 추가되기 때문에 정확한 전체 이름은 예측할 수 없습니다.
- 이런 경우 정규 표현식을 이용해 변하지 않는 이름은 지정해 놓고 변화하는 해시 문자는
*(애스터리스크)로 표시하면 모든 경우의 수를 포함해 검색할 수 있습니다. ~=를 사용한kube_pod_container_status_restarts_total{pod=~"coredns.*"}는 coredns로 시작하는 디플로이먼트에서만 다시 시작한 횟수를 검색합니다.
-
검색 결과에 따라 필요 없는 정보가 너무 많은 경우가 있습니다.
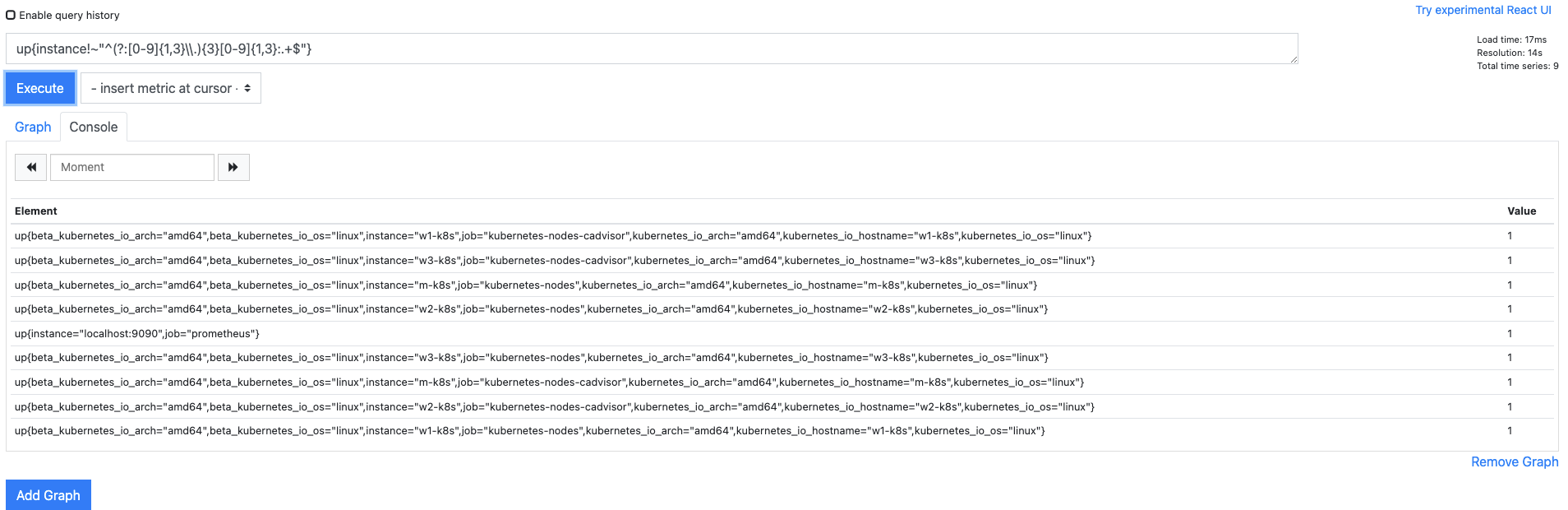
- instance 레이블에 호스트 이름이 아닌 IP 주소가 적힌 것은 필요하지 않다고 가정하고 해당 내용을 제거해 봅시다.
- IP 주소 검색을 위한 정규 표현식을 PromQL로 작성하면
up{instance!~"^(?:[0-9]{1,3}\\.){3}[0-9]{1,3}:.+$"}입니다. !~는 정규 표현식에 해당하지 않는 레이블을 검색하므로 이를 실행하면 instance 레이블에 호스트 이름만 있는 메트릭 데이터가 검색됩니다.
PromQL 정규 표현식
특정한 문자열의 집합을 표현하는 패턴을 정규 표현식 이라고 하며, 복잡한 규칙성이 있는 문자열을 검사하는 데 사용합니다.
정규 표현식의 문법은 매우 복잡하기 때문에 짧게 설명하기는 어렵습니다.
앞에 작성한 예시로 정규 표현식의 구조만 간단히 살펴보겠습니다.
IP 주소가 주어졌을 때 IP 주소의 형태가 맞는지 아닌지를 판단하기 어렵습니다.
그러므로 앞에서처럼up{instance!~"^(?:[0-9]{1,3}\\.){3}[0-9]{1,3}:.+$"}같은 정규 표현식을 작성해
0~255 사이의 숫자가 점(.)으로 4개 연결되는 조건과 같은 패턴이 있는지 판단하고 이를 검색할 수 있습니다.
정규 표현식은 IP 주소 외에도 규칙성이 있는 전화번호, 이메일 주소, 비밀번호 검사 등에 사용됩니다.
프로메테우스의 레이블 매처로 검색된 메트릭 데이터를 그대로 사용하기도 하지만,
좀 더 알아보기 쉽게 만들어야 할 때가 이씃ㅂ니다.
PromQL에서는 미리 정의해 둔 연산자라는 표현식이 있는데,
이를 활용해 지금까지 봤던 메트릭 값을 효과적으로 나타내거나 레이블이 아닌 메트릭 값을 이용한 검색도 할 수 있습니다.
그러면 PromQL 연산자로 메트릭 값을 활용해 보겠습니다.
PromQL 연산자
PromQL 연산자(Operator)는 메트릭 값을 이용한 여러 가지 활용 방법을 제공합니다.
활용법에 따라 크게 4가지로 구분됩니다.
- 비교 연산자 : 레이블 매처와 유사한 형태이나 비교 대상이 숫자이므로 크기를 구분하는 조건들이 있습니다. 사용되는 연산자는
==, !=, >, <, >=, <=입니다. - 논리 연산자 : 수집된 메트릭에서 보고 싶은 범위를 지정하는 and(교집합), or(합집합), unless(차집합) 연산자가 있습니다.
- 산술 연산자 : 사칙연산(
+, -, *, /), 나머지(%), 지수(^) 같은 연산자로 메트릭의 값을 사용자가 원하는 값으로 변환합니다. - 집계 연산자 : 평균(avg), 합계(sum), 계수(count)왁 ㅏㅌ이 수집된 메트릭을 종합하고 분석하는 연산자로 메트릭의 값을 좀 더 의미 있는 데이터로 정리합니다.
비교 연산자
비교 연산자는 메트릭 값을 비교해 조건에 해당하는 값을 가진 대상을 검색합니다.
따라서 주로 수집 대상의 상태를 파악하는 데 사용합니다.
예를 들어 kube_pod_container_status_restarts_total>0을 사용하면 다시 시작한 적이 있는 파드만 검색할 수 있습니다.

논리 연산자
논리 연산자는 연산자 앞뒤로 입력되는 PromQL 표현식 레이블의 키와 값을 기준으로 조건 연산을 수행해 값을 반환합니다.
and 연산자는 양쪽 표현식의 레이블 값이 서로 일치하는 경우 왼쪽 값을 반환하고,
OR 연산자는 왼쪽 표현식으로 출력되는 값이 없는 경우 오픈쪽 값을 반환합니다.
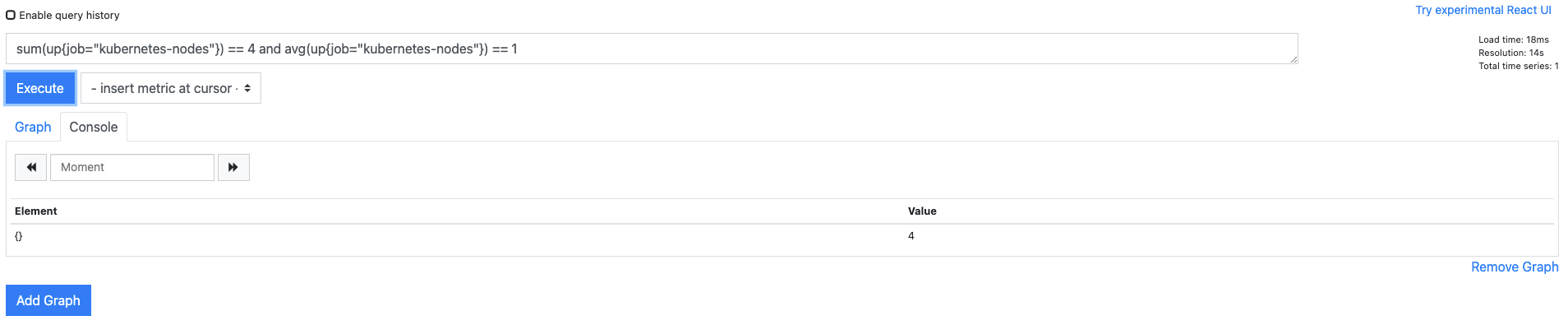
unless 연산자는 조금 독특한데, 양쪽 표현식을 비교해서 오른쪽 표현식의 출력 값에서 왼쪽 표현식에 나온 값들을 모두 제외하고 반환합니다.
sum(up{job="kubernetes-nodes"}) == 4 and avg(up{job="kubernetes-nodes"}) == 1은 왼쪽 표현식의 결과가 참이고, 오른쪽 표현식의 결과 또한 참인 경우를 논리 연산자 and로 비교해 오른쪽 결과가 4인 경우만을 반환합니다.
양쪽 모두 쿠버네티스 노드가 정상적으로 살아 있는지 파악하려는 목적이므로
표현식을 중복해서 사용합니다.
실제로 논리 연산자는 검색 대상이 잘못됐을 때 이를 수정하거나 검출할 때 사용하지만, 사용할 때 매우 복잡합니다.
산술 연산자
산술 연산자는 검색된 메트릭의 값을 사용자가 원하는 형태로 바꿔 줍니다.
주로 수치 단위를 변경하는 데 사용합니다.
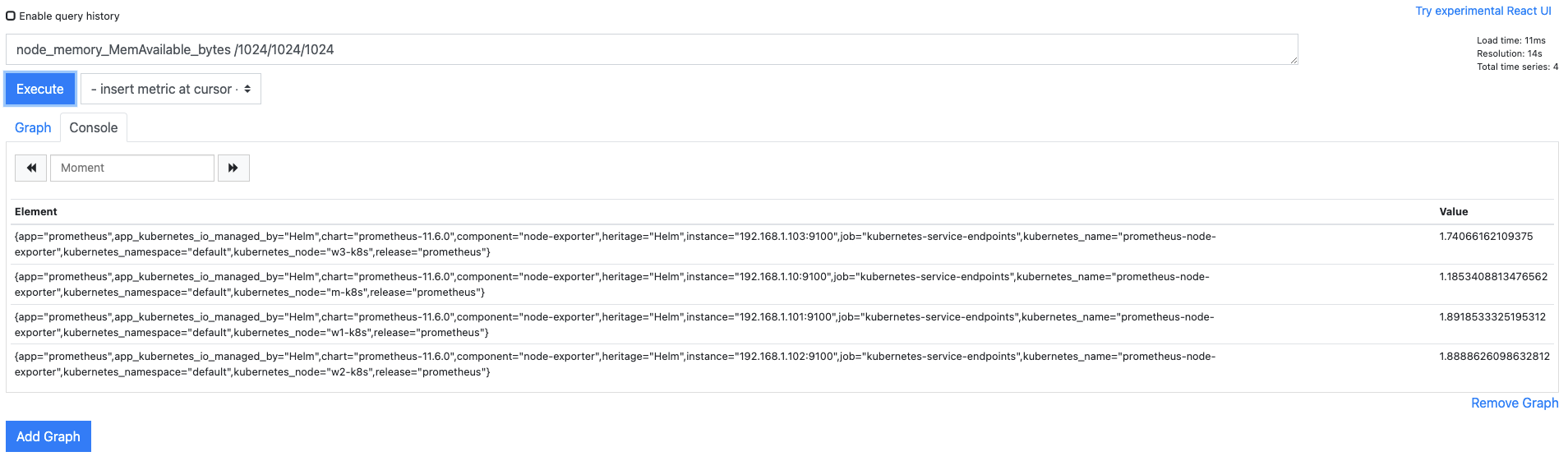
노드가 사용 가능한 메모리 크리를 반환받고 검색된 결과에서 1024(2^10)을 3차례 사용해 (/1024/1024/1024) Byte단위를 Kib, Mib, Gib 순으로 변경해봅시다.
node_memoey_MemAvailable_bytes /1024/1024/1024
집계 연산자
집계 연산자는 검색된 메트릭 값을 종합해 유용한 형태로 변환합니다.
따라서 수집된 값에서 총합, 평균, 계측된 수 등을 바로 파악할 때 사용합니다.
또한, 다른 연산자에 존재하지 않는 분류와 관련된 by(그룹화), without(제외) 등의 추가 옵션을 제공합니다.
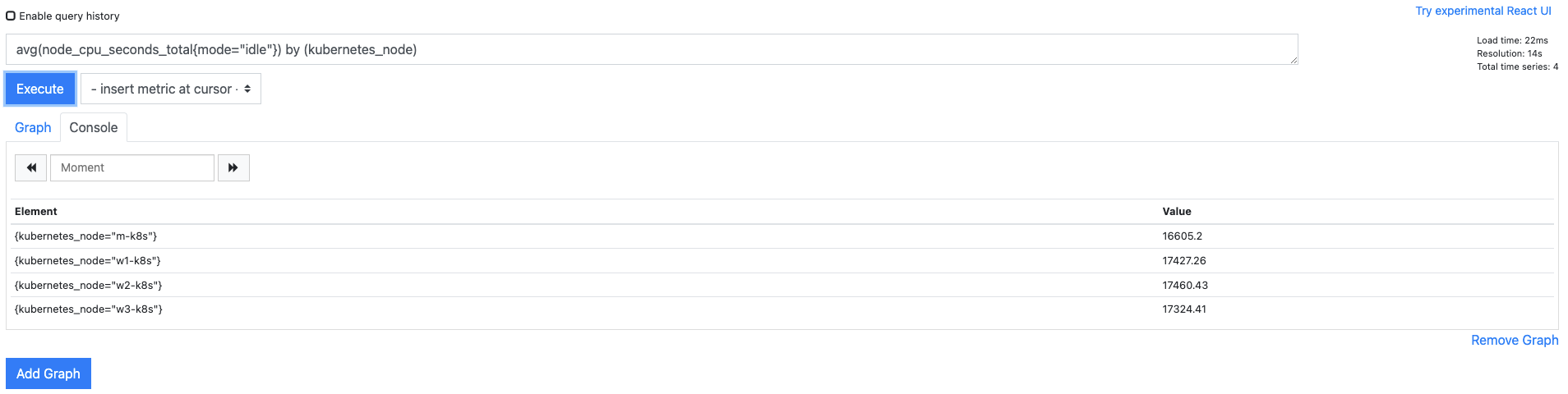
avg(node_cpu_seconds_total{mode="idle"}) by (kubernetes-node)를 실행하면 노드별로 CPU를 사용하지 않는 시간의 평균을 구합니다.
특히 마스터 노드는 CPU가 2개이므로 평균값을 보는 것이 더 정확합니다.
프로메테우스의 메트릭 데이터는 매우 간결하며 명확하게 구조화돼 있을 뿐만 아니라,
레이블과 메트릭 값을 이용해 다양한 방법으로 검색하고 가공할 수 있습니다.
PromQL 데이터 타입
메트릭 데이터에서 아직 다루지 않은 부분이 있습니다.
처음에 프로메테우스 데이터베이스를 시계열 데이터베이스라고 소개했습니다.
그렇다면 메트릭 데이터에도 시간 정보가 있을텐데 왜 메트릭 데이터에는 보이지 않을까요?
이번에는 시계열 정보가 담겨 있는 메트릭 데이터에 관해 알아봅시다!
쿼리 입력기에 node_cpu_seconds_total 처럼 PromQL 표현에 맞는 쿼리를 입력해도 시간 정보는 나오지 않습니다.
메트릭 이름, 레이블, 메트릭 값만 표시될 뿐입니다.
사실 메트릭 데이터는 현재 시간을 내포하기 때문에 시간에 대한 정보가 결과에 표현되지 않을 뿐입니다.
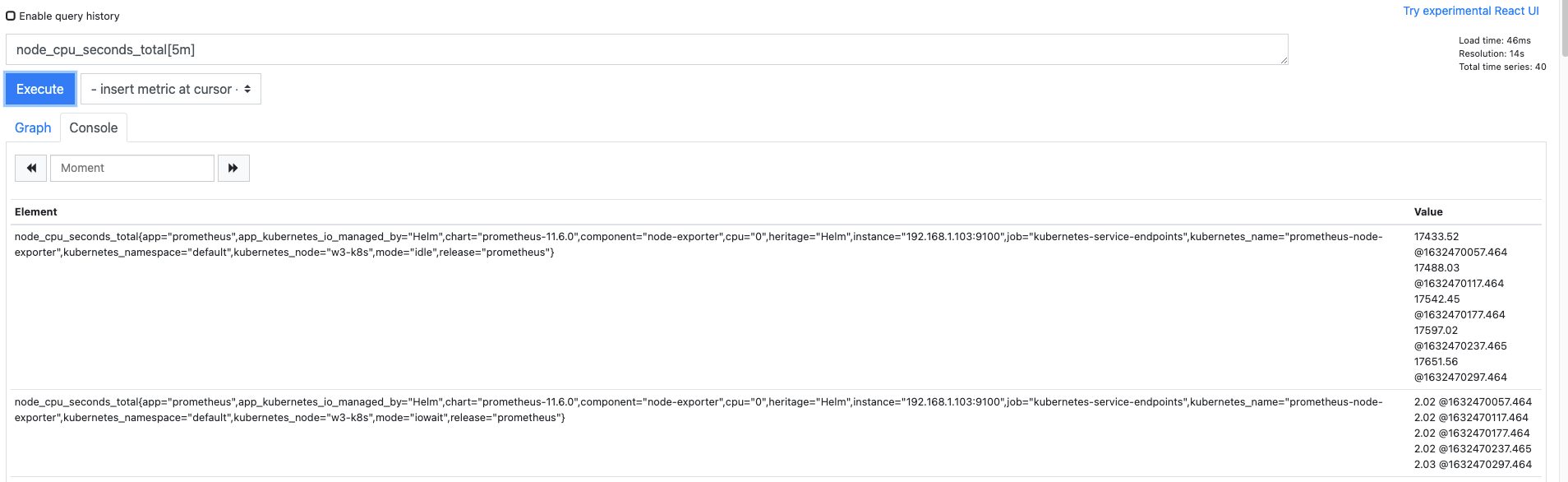
시간을 포함한 메트릭 데이터를 확인하려면 쿼리를 입력할 때 [구간 값] 을 입력해야 합니다.
메트릭 데이터를 받아오는 구간을 프로메테우스에서는 레인지 셀렉터(Range Selector) 라고 합니다.
레인지 셀렉터를 설정하면 메트릭 값과 함꼐 시간 정보가 나타나 각 메트릭 값을 구분할 수 있습니다.
앞에서 작성한 쿼리에 [5m]을 추가해 5분 동안 발생된 메트릭 값을 요청합니다.
레인지 셀렉터의 단위로는 ms(밀리초), s(초), m(분), h(시간), d(일), w(주), y(년)을 사용할 수 있습니다.
이렇게 구간이 있는 PromQL 데이터 타입을
레인지 벡터(Range vector) 라고 하고,
특정(일반적으로 현재 시점을 의미함) 시점에 대한 메트릭 값만을 가지는 PromQL 데이터 타입을
인스턴트 벡터(Instant vertor) 라고 합니다.
두 가지 타입 외에도 실수 값을 표현하는 스칼라 타입(Scalar type) 과 문자열을 표현하는 스트링 타입(String type) 이 있습니다.
스칼라 타입은 주로 인스턴트 벡터 값을 변경하는 용도로 사용되고 단독으로 사용하지는 않습니다.
스트링 타입은 프로메테우스 2.0부터는 사용하지 않습니다.
레인지 벡터와 인스턴트 벡터 비교하기
레인지 벡터와 인스턴트 벡터의 차이를 개념 설명만으로 이해하기가 쉽지 않습니다.
두 벡터를 비교하는 실습을 해봅시다!
-
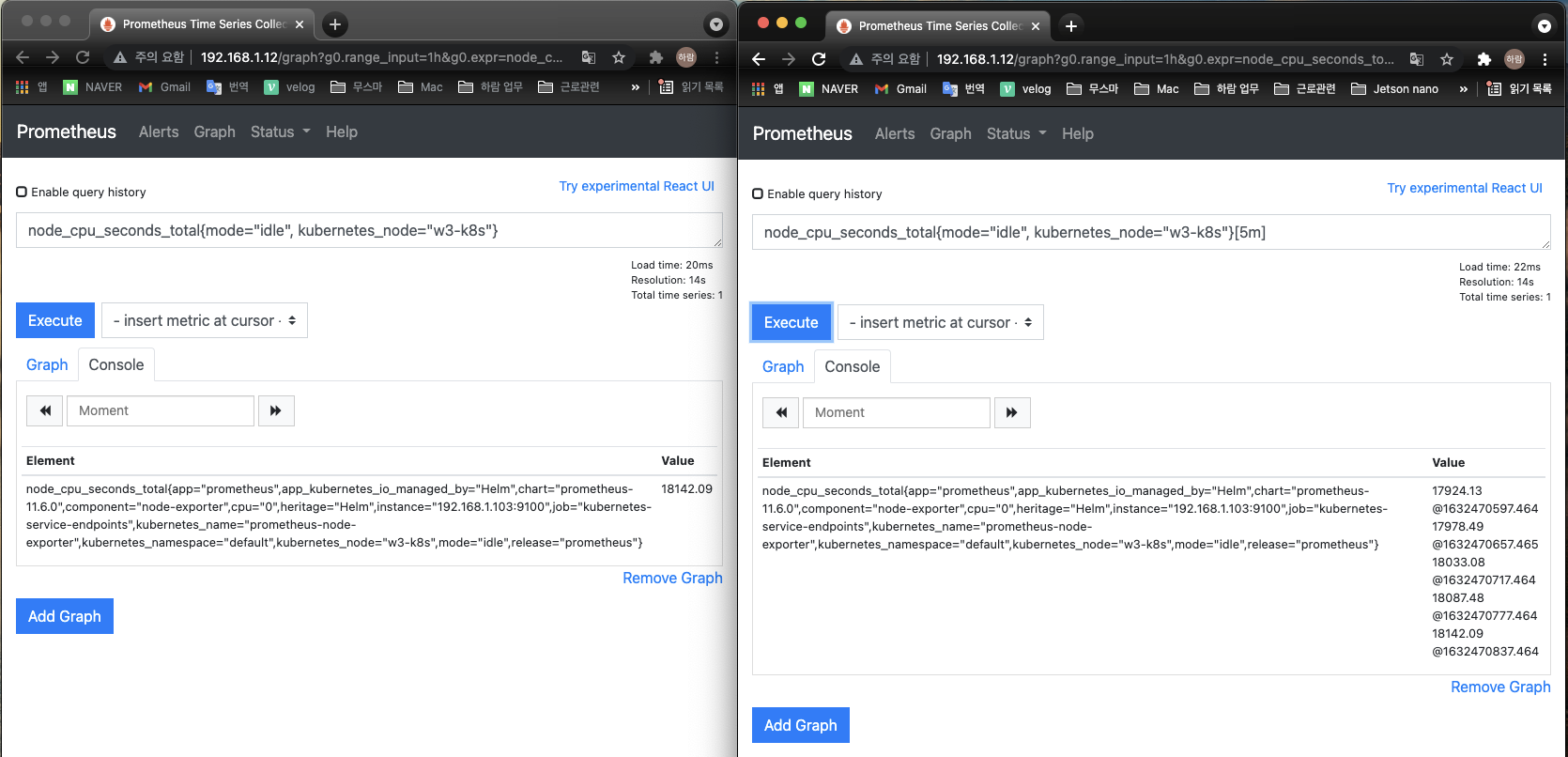
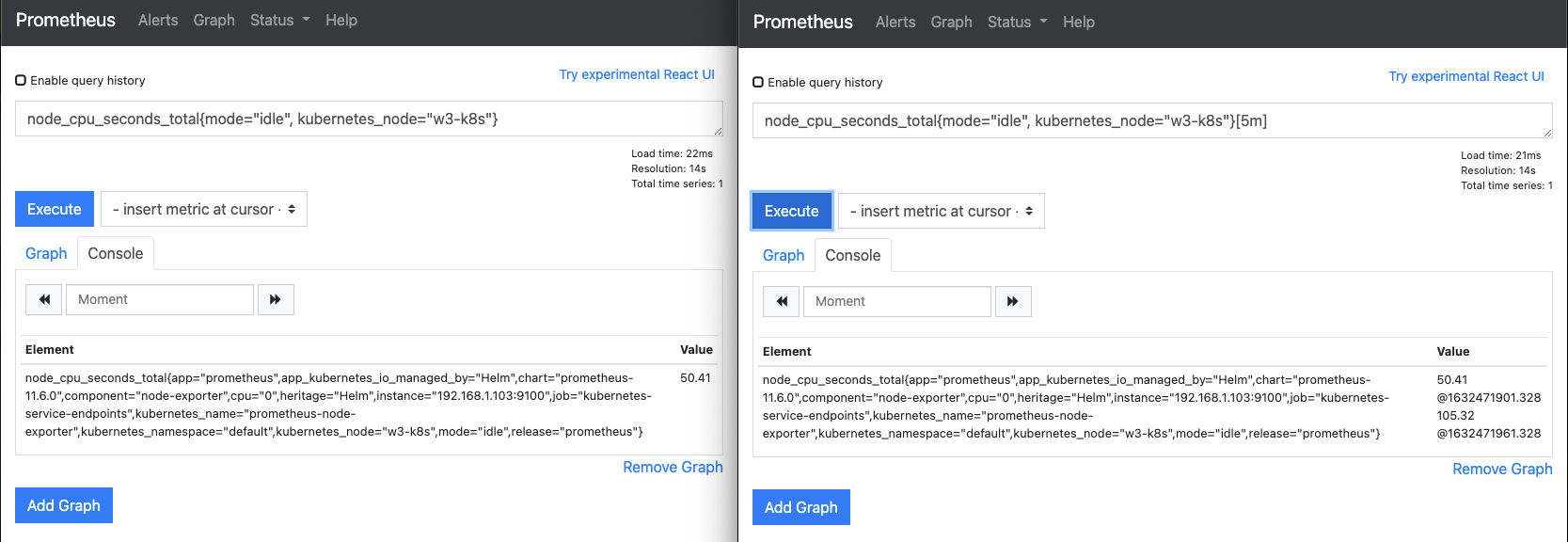
웹 브라우저에 프로메테우스 웹 UI를 2개 띄워둡니다.
- 왼쪽에는
node_cpu_seconds_total{mode="idle", kubernetes_node="w3-k8s"}를 - 오른쪽에는
node_cpu_seconds_total{mode="idle", kubernetes_node="w3-k8s"}[5m]을 입력합니다. - mode와 kubernetes_node 레이블을 선택한 이유는 node_cpu_seconds_total이 보내는 다양한 메트릭 값 중에 1개만 보기 위해서 입니다.
- 왼쪽에는
-
메트릭 데이터가 수집되지 않도록 버추얼박스에서 w3-k8s의 전원을 끄고, 10분 정도 기다립니다.
-
10분 후에 2개의 웹 UI를 새로고침해서 아무것도 검색되지 않는지 확인합니다.
-
버추얼박스에서 w3-k8s를 다시 시작합니다. 시작 > 헤드리스 시작을 선택하면 됩니다. 헤드리스 시작을 선택하면 접속 창이 뜨지 않고 실행됩니다.
-
웹 UI를 30초 정도 후에 다시 새로고침해 메트릭 데이터를 받아오는지 확인합니다.
- 첫 번째 메트릭 데이터가 수집되면 다음과 같이 표시됩니다. 이때 @뒤에 표시되는 숫자는 유닉스 시간입니다.
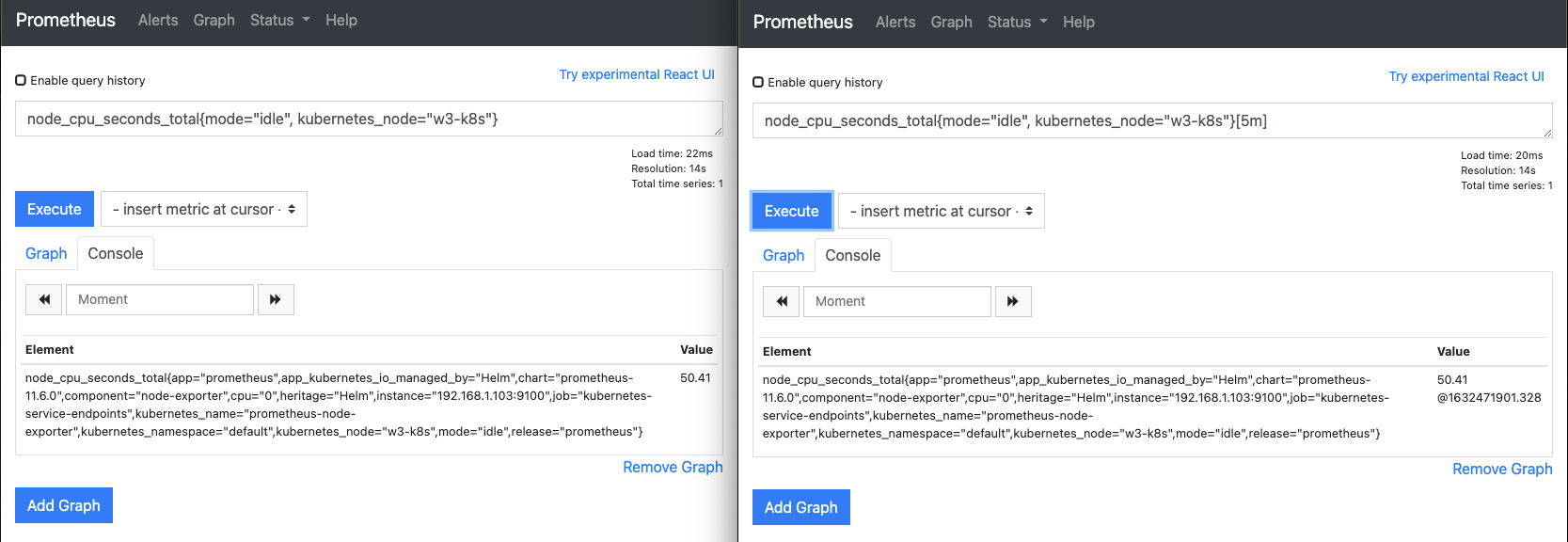
- 첫 번째 메트릭 데이터가 수집되면 다음과 같이 표시됩니다. 이때 @뒤에 표시되는 숫자는 유닉스 시간입니다.
-
30초 후에 다시 웹 UI를 새로고침해 두 번쨰 메트릭 데이터가 수집되는지 확인합니다.
- 두 번째로 수집된 메트릭이 오른쪽 웹 UI에 누적되는지, 시간이 60초 차이(1632471961.328 - 1632471901.328 = 60)가 나는지 확인합니다.
- 60초 차이가 나는 것은 프로메테우스의 기본 수집 주기가 60초이기 때문입니다.
-
주기적으로 메트릭이 수집되고 시간 데이터가 누적되는 것을 확인합니다.
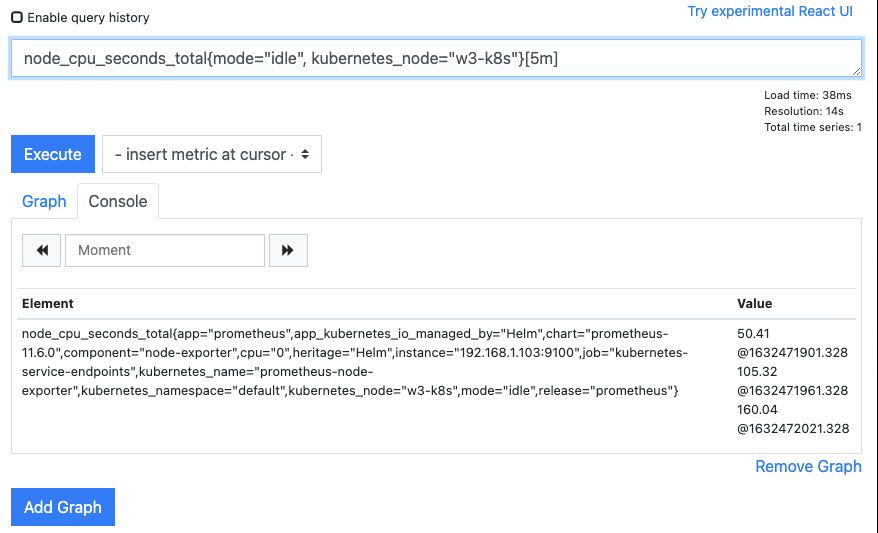
-
여섯 번째 메트릭이 수집되면 첫 번째로 수집된 메트릭이 보이지 않고, 두 번째부터 여섯 번째 메트릭까지 확인됩니다.
- 이는 레인지 셀럭터를 5m으로 지정해 지금부터 4분 전(총 5분)까지의 메트릭만을 검색해 보여주기 때문입니다.
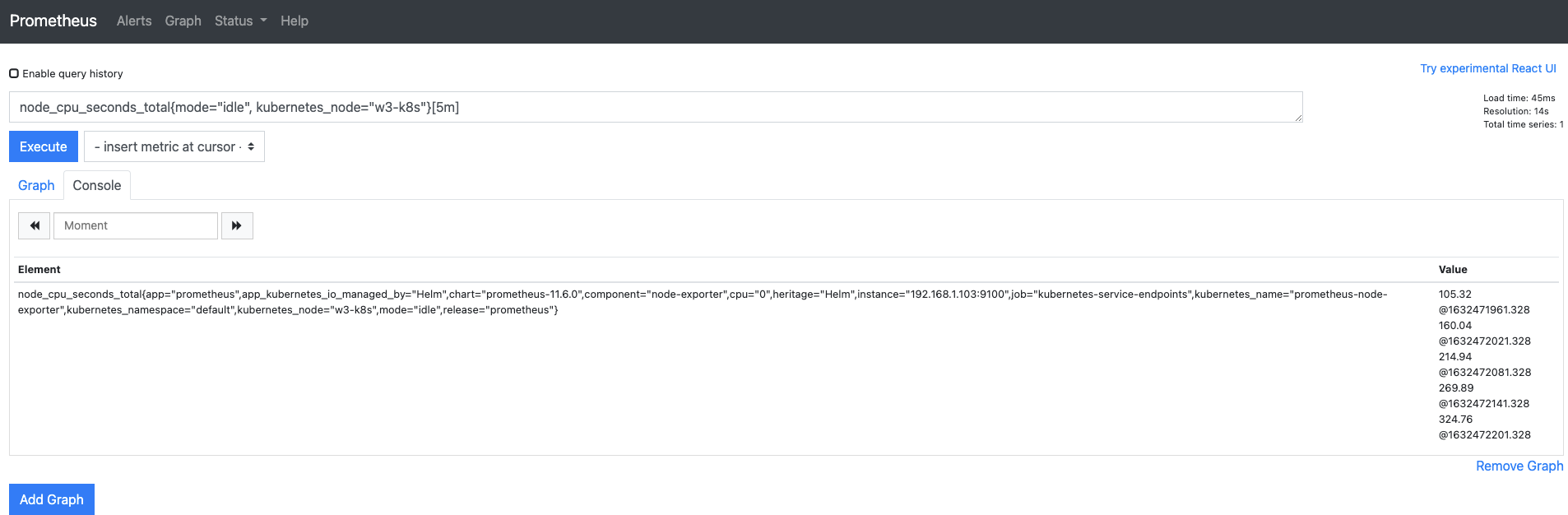
- 이는 레인지 셀럭터를 5m으로 지정해 지금부터 4분 전(총 5분)까지의 메트릭만을 검색해 보여주기 때문입니다.
이제 레인지 벡터와 인스턴트 벡터가 어떻게 다른지 이해했을 테니, 왜 2가지 타입으로 나뉘어 존재하는지 확인해 봅시다.
시계열 메트릭 데이터로 그래프 그리기
레인지 벡터와 인스턴트 벡터의 사용법을 알려면 메트릭 타입을 이해해야 합니다.
게이지 타입으로 수집된 가용 메모리의 메트릭 데이터를 그래프로 그리면 한눈에 상태 변화를 확인 할 수 있습니다.
하지만 카운터 타입은 항상 증가하는 값이기 때문에 그래프로 그리면 계속 증가하는 형태로만 보입니다. 따라서 어떠한 의미도 알아낼 수 없습니다.
의미 있는 메트릭 데이터의 흐름을 보려면 게이지 타입의 메트릭을 사용해야 하는데,
메트릭 값에 따라 카운터 타입만을 제공하는 경우가 있습니다.
대표적인 예가 노드의 총 CPU 사용 시간을 파악할 수 있는 node_cpu_seconds_total입니다.
그래서 이런 경우에는 카운터 타입으로 구성된 레인지 벡터를 이용해 유의미한 결과를 만들어야 합니다.
즉, 레인지 벡터로 구성된 값들의 변화를 계산해 변화율을 그래프 형태로 그리는 것입니다.
이렇게 레인지 벡터의 변화율을 계산하려면 또 다른 연산 방법이 필요합니다.
레인지 벡터를 위해 제공되는 프로메테우스의 내장 함수로, 주어진 메트릭 데이터를 분석하고, 의미 있는 데이터로 변환하는 방법을 알아봅시다.
PromQL 함수
프로메테우스는 PromQL에서 인스턴트 벡터로 추출한 메트릭을 그대로 사용하는 경우도 많지만,
앞에서 살펴본 것처럼 구간의 의미를 알려면 함수(Function)의 도움을 받아야 합니다.
프로메테우스에서 주로 사용하는 함수는 다음과 같습니다.
| 종류 | 용도 | 함수 |
|---|---|---|
| 연산 함수 | 수학 연산에 사용 | abs(절댓값), ceil(올림), floor(내림), round(반올림), predict_linear(예측값) 등 |
| 변환 함수 | 데이터 타입 간 변환에 사용 | scalar(스칼라로 변환), vertor(벡터로 변환), rate(변화율), irate(순간 변화율) 등 |
| 집계 함수 | 수집된 레인지 벡터의 데이터 집계를 위해 사용 | avg_over_time(평균), sum_over_time(합계), count_over_time(계수) 등 |
여러 함수 중에서 가장 많이 쓰이는 함수 세 가지를 사용해 수집된 메트릭 데이터를 가공해 의미 있는 메트릭 값을 산출하는 방법을 알아봅시다.
변화율을 나타내는 rate
rate는 수집한 값들의 변화율을 구할 때 사용합니다.
주로 값이 증가하는 카운터 형식의 메트릭에 사용되며, 지정한 구간이 얼마나 빠르게 변화했는지 알기 위한 지표로 사용됩니다.
rate 함수로 변화율 확인하기
-
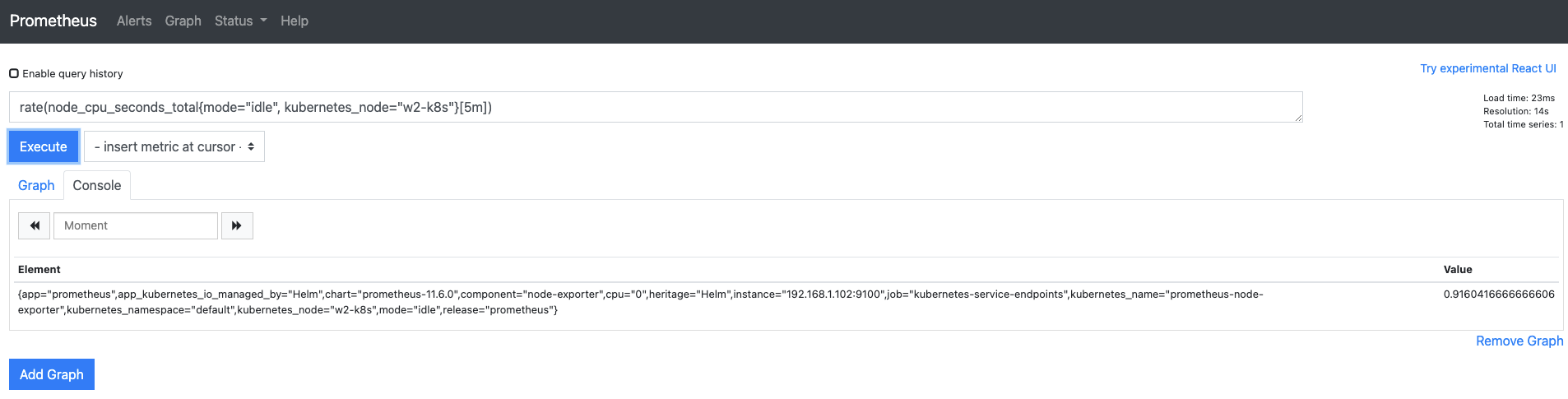
웹 UI 쿼리 입력기에
rate(node_cpu_seconds_total{mode="idle", kubernetes_node="w2-k8s"}[5m])을 입력하고 다음과 같이 1보다 작은 값이 나오는지 확인합니다.
-
쿼리 결과를 그래프로 확인합시다.
- Graph 탭으로 가서 기본값을 1시간(1h)에서 5m으로 변경합니다. 다음과 같이 추이를 확인할 수 있는 그래프가 그려집니다.
- 저는 Try Experimental React UI를 누르고, Use Local Time을 체크하여 아래와 같은 화면이 나옵니다. 내용은 똑같으니 모습이 다르다고 당황하지 마세요!
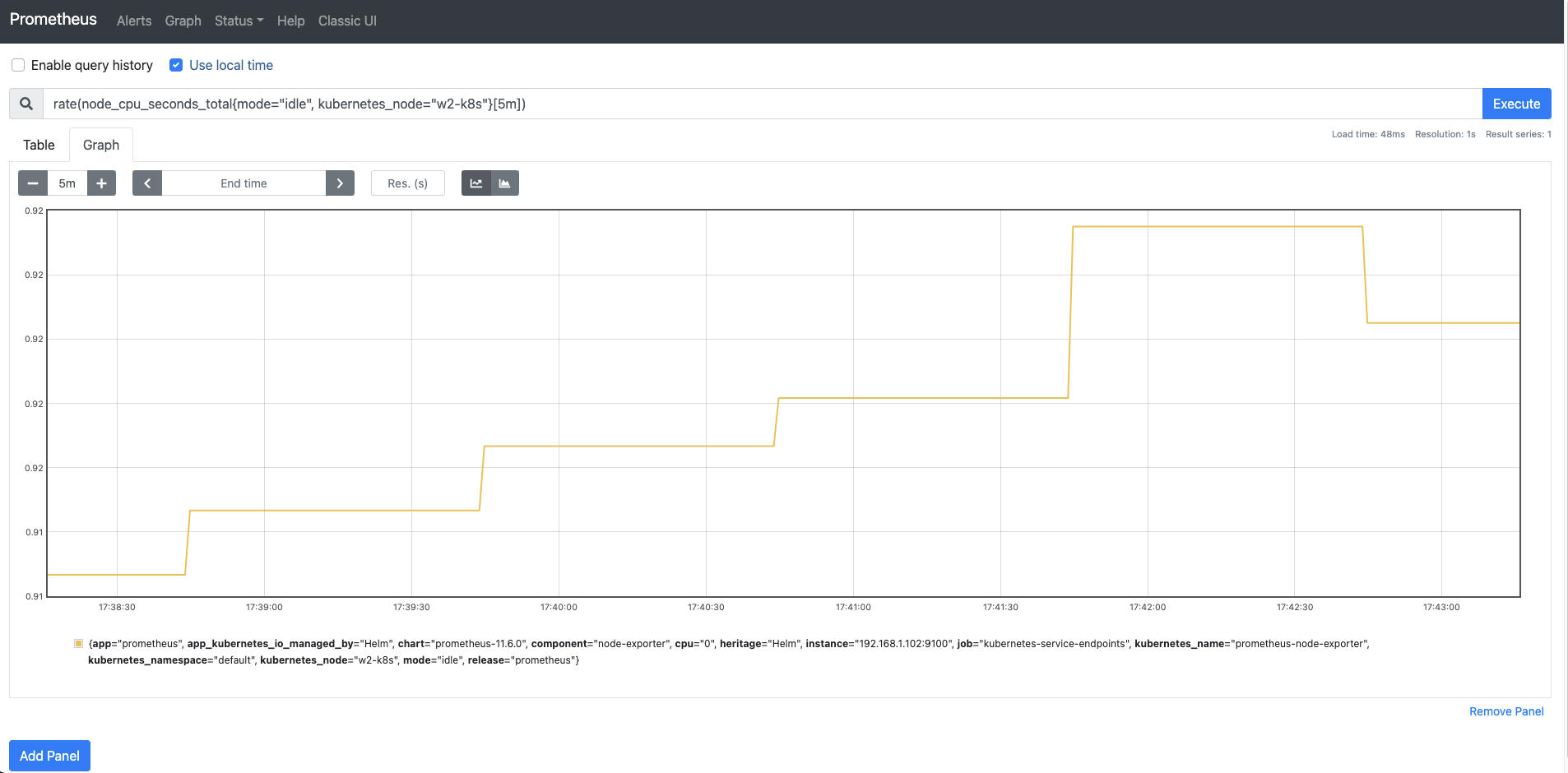
- rate 함수로 그리는 변화율 그래프는 다음 공식에 따라 생성됩니다.
- 최종 수집 - 최초 수집 -> 4분 간 편차 값(5m일 때) / 수집 시간 -> 결과 - 앞에서 보듯이 프로메테우스에서 제공하는 그래프는 몇 가지 단점이 있습니다.
- 변화율 값을 정확하게 표시하지 못합니다.
- 제한이 많은 꺽은선 그래프로 표시돼 추이 변화를 파악하기 어렵습니다.
- 하나의 패널로 구성돼 여러 가지의 PromQL 쿼리를 비교할 수 없습니다. - 따라서 프로메테우스에서 제공하는 그래프는 변화율을 보기에 적합하지 않습니다. 추후에 그라파나를 사용해 메트릭 데이터를 그래프 형태로 표현하는 방법을 자세히 알아보겠습니다.
순간변화율을 나타내는 irate
두 번쨰 함수 irate는 rate와 변화율을 구하는 부분은 같습니다.
그러나 rate는 구간 시작 값과 구간 종료 값의 차이에 대한 변화율을 다루고,
irate는 구간 종료 바로 전 값과 구간 종료 값의 차이에 대한 변화율을 나타내는 점이 다릅니다.
따라서 구간이 매우 길면 irate의 변화율은 큰 의미가 없기 때문에 rate 함수를 사용하는 것이 낫습니다.
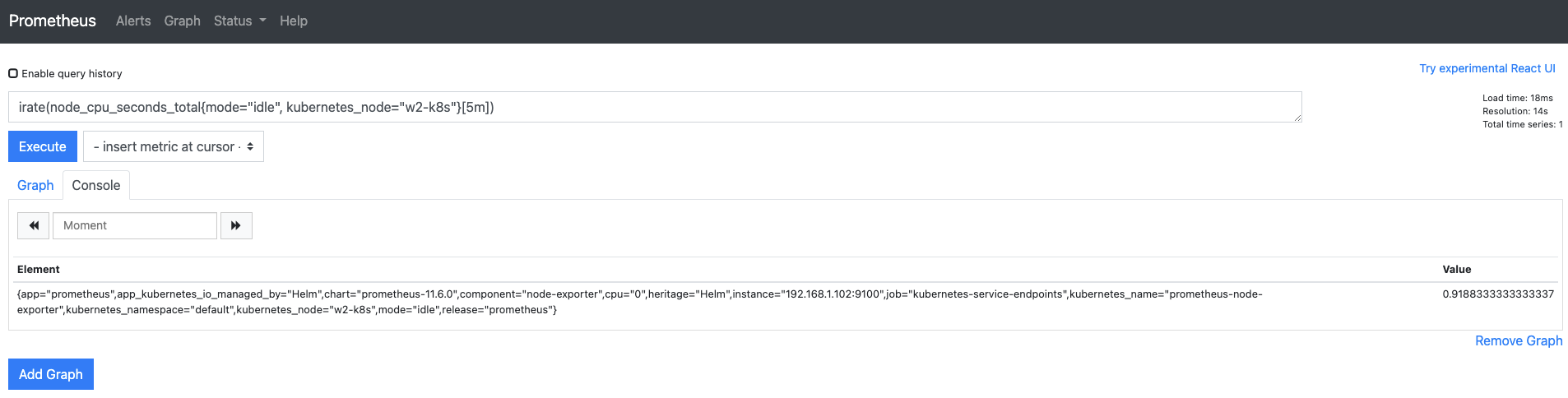
프로메테우스의 웹 UI의 쿼리 입력기에
irate(node_cpu_seconds_total{mode="idle", kubernetes_node="w2-k8s"}[5m])
을 입력해 irate의 결과가 rate와 비슷하게 나오는지 확인합니다.
다음과 같이 1보다 작은 값이 나옵니다.
추세를 보여주는 predict_linear
세 번째 함수인 predict_linear는 레인지 벡터로 수집된 과거 메트릭 데이터를 기반으로
앞으로 생성될 메트릭 값을 예측합니다.
predict_linear 함수로 메트릭 값 예측하기
-
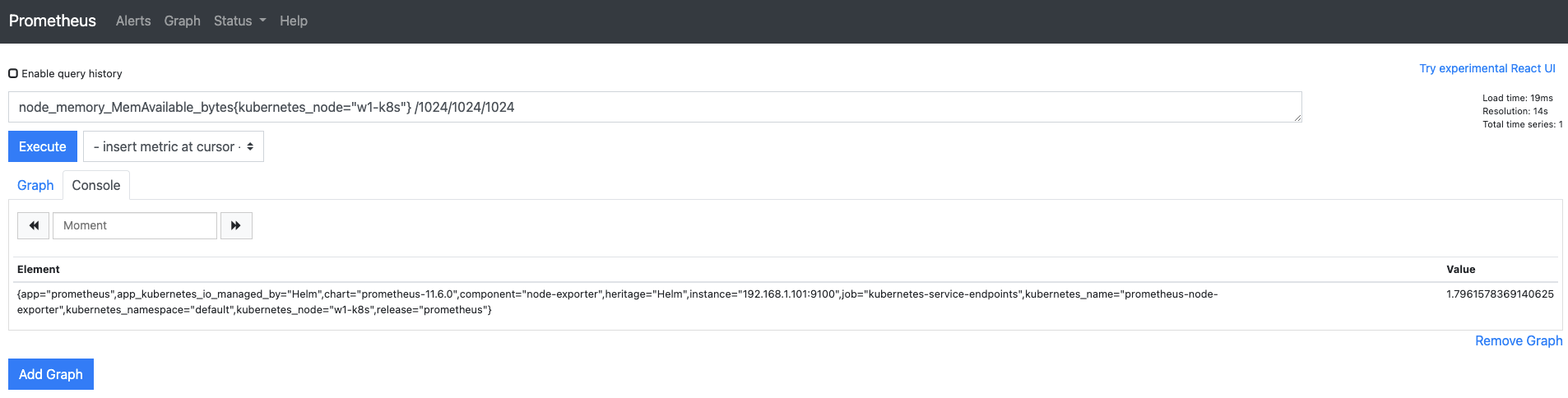
웹 UI의 쿼리 입력기에
node_memory_MemAvailable_bytes{kubernetes_node="w1-k8s"}를 입력해 현재 사용 가능한 메모리 용량을 확인합니다.
-
1시간 후에 사용 가능한 메모리 용량을 예측해 봅시다.
- 쿼리 입력기에
predict_linear(node_memory_MemAvailable_bytes{kubernetes_node="w1-k8s"}[5m], 60*60*1)을 입력합니다.(1911865344)
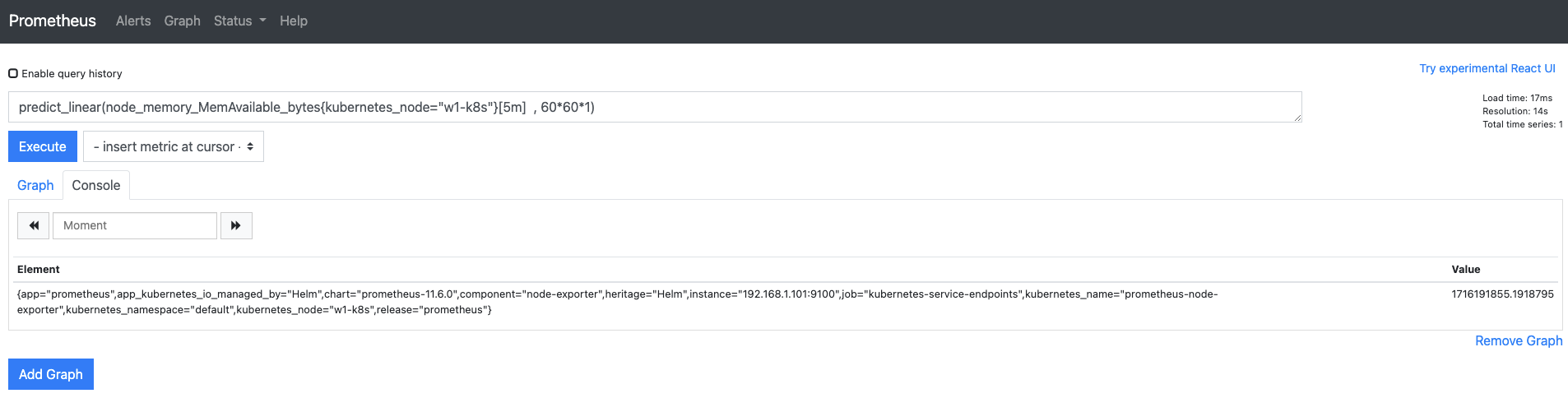
- [5m]은 예측에 기초가 되는 자료의 범위를 의미하고, 60601은 1시간(3,600초) 후의 값을 예측한다는 의미입니다.
- 앞의 질의 결과와 차이가 크지 않다면 5분 간 사용한 메모리 용량의 변화가 크지 않다는 의미이므로 메모리 사용량을 늘리거나, 5분보다 큰 주기를 설정해서 테스트해봐도 좋겠습니다.(1728226051.17559480)
- PromQL 함수 쿼리에서 용량 변환인 1024/1024/1024를 어떻게 사용하는지는 아직 모르겠군요. 앞의 쿼리에 1024/1024/1024를 붙이면 인자가 잘못됐다며 오류가 발생합니다. 나중에 해결방법을 알게되면 포스트 수정하겠습니다.
- 쿼리 입력기에
-
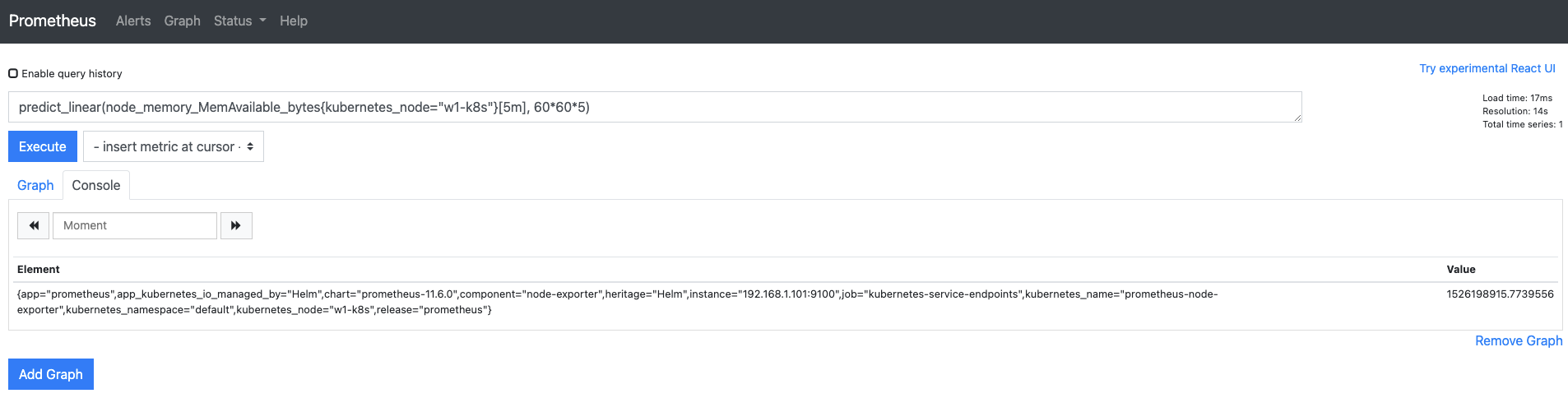
이번에는 5시간 후에 사용 가능한 메모리 용량이 얼마인지 예측해봅시다. 이 정도 쿼리는 쉽게 만들 수 있겠죠? 직접 작성해볼까요? (1526198915.7739556)
predict_linear(node_memory_MemAvailable_bytes{kubernetes_node="w1-k8s"}[5m], 60*60*5)
서머리와 히스토그램
앞에서 메트릭 값의 종류 중에서 간단히 다루고 넘어갔던 서머리와 히스토그램에 대해 살펴보겠습니다.
서머리와 히스토그램을 뒤로 미룬 이유는 둘을 이해하려면 레이블과 함수를 모두 알아야하기 때문입니다.
두 메트릭 값은 구간 내에 특정 메트릭 값이 나타나는 빈도를 알려줍니다.
하지만 약간의 차이가 있습니다.
구조적으로 서머리는 익스포터에서 이미 만들어진 값을 보여주고,
히스토그램은 요청을 받으면 이를 계산해서 보여 줍니다.
서머리
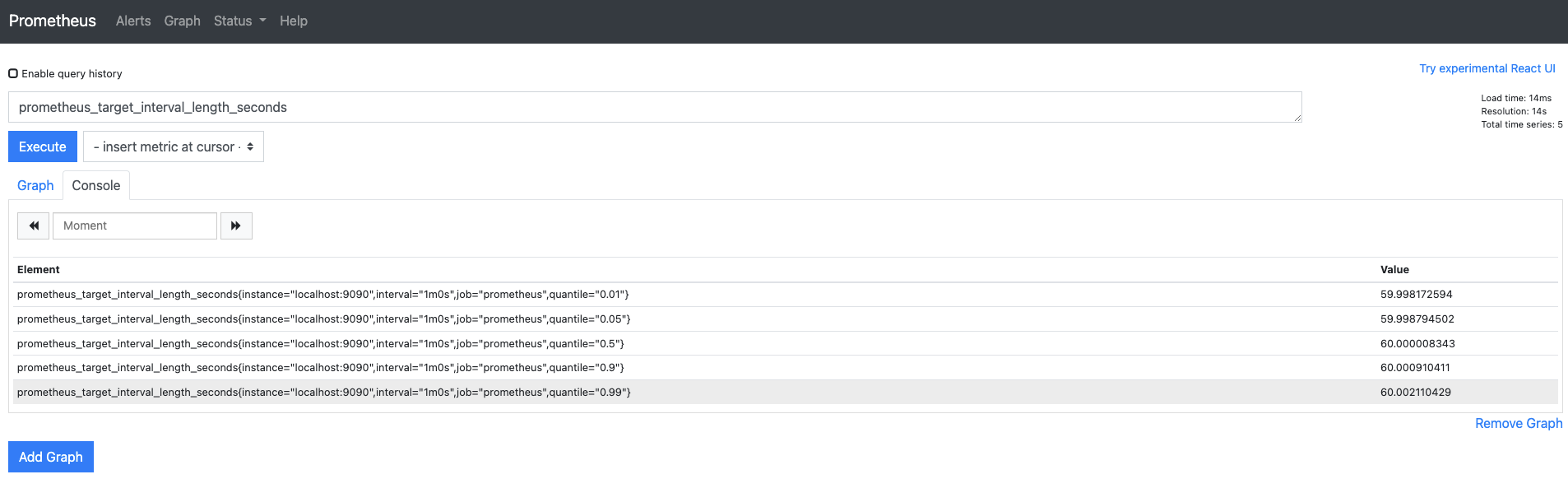
서머리는 이미 공개된 메트릭 값을 조회하면 바로 확인할 수 있습니다.
쿼리 입렵기에
prometheus_target_interval_length_seconds를 입력합니다.
결과에서 quantile(분위수) 의 값에 매핑되는 메트릭 값을 확인합니다.
프로메테우스 서버가 수집 대상으로부터 60.002110429초로 응답받았다면
이는 전체 100개 중에서 99번째(quantile="0.99") 응답 시간을 의미합니다.
이와 같은 100개 중 99번째 수를 99백분위수라고 합니다.
히스토그램
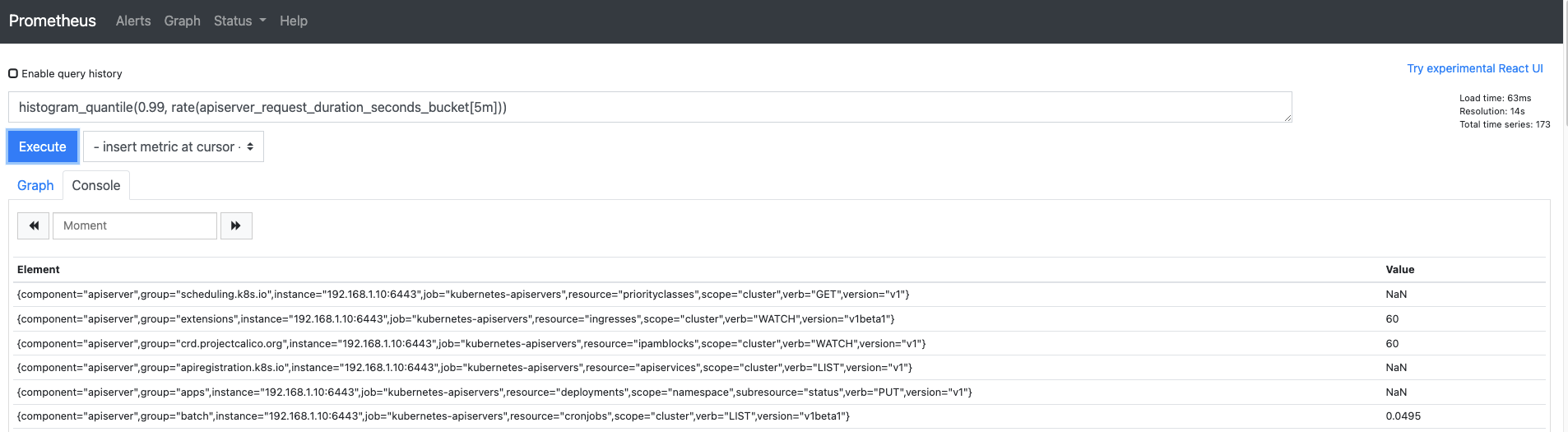
히스토그램은 쿼리 입력기에 쿼리를 보내면 그때서야 내부 계산식을 통해 히스토그램 메트릭을 생성합니다.
histogram_quantile(0.99, rate(apiserver_request_duration_seconds_bucket[5m]))을 입력합니다.
apiserver_request_duration_seconds_bucket은 API 서버의 응답 시간이고,
메트릭 값의 타입은 카운터입니다.
여기서 rate 함수를 사용한 이유는 메트릭 값을 변화율로 바꾸려는 것이 아니라
히스토그램에서 관측하는 범위를 지정하기 위해서입니다.
그리고 0.99는 API 서버의 응답 시간이 99백분위수인 값을 찾습니다.
참고로 검색된 값 중에 NaN(Not a Number)은 버킷(개발자가 지정해 둔 측정 범위)으로 검출된 값이 없을 때 표시되는 값입니다.
히스토그램에 연산자 추가하기
히스토그램에 연산자를 추가하면 함수를 추가할 때보다 더 유용한 정보를 검출할 수도 있습니다.
sum 연산자를 추가해서 API 서버로부터 가장 느리게 응답받은 시간을 출력해 보겠습니다.
histogram_quantile(0.99, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le))를 입력합니다.
API 서버로부터 가장 느리게 응답받은 시간이 60초라고 나옵니다.
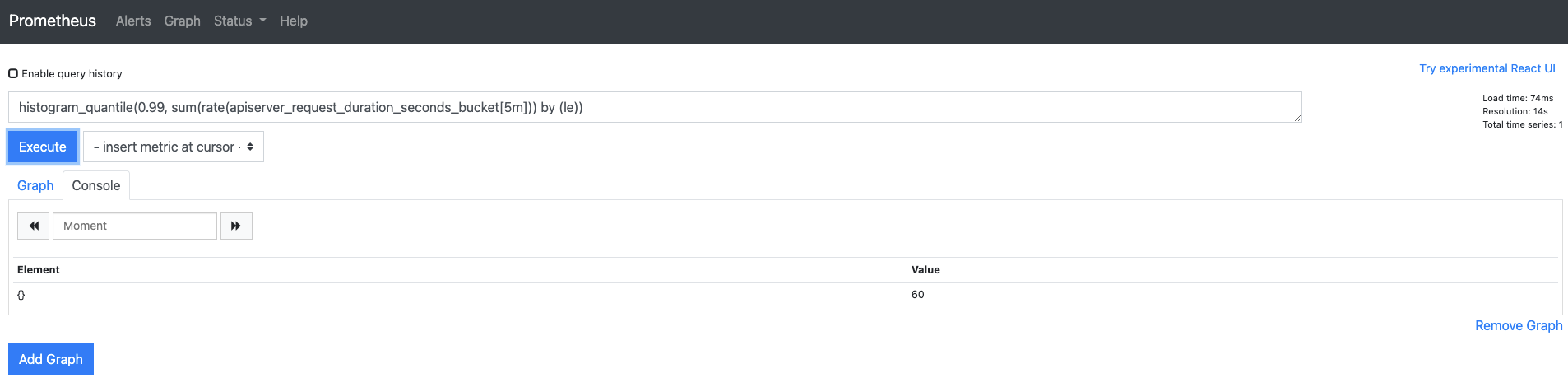
sum 연산자 외에 by (le)를 사용했는데,
le(Less Than Or Equal To) 레이블로 구분하지 않으면 sum 연산자 때문에 검색되는 모든 값이 합쳐져
histogram_quantile 함수에서 백분위수로 값을 산정할 수 없습니다.
여기서 le는 개발자가 미리 정해 둔 버킷의 기준값입니다.
히스토그램을 제외하고 le 레이블로 구분한 결과도 확인해볼까요?
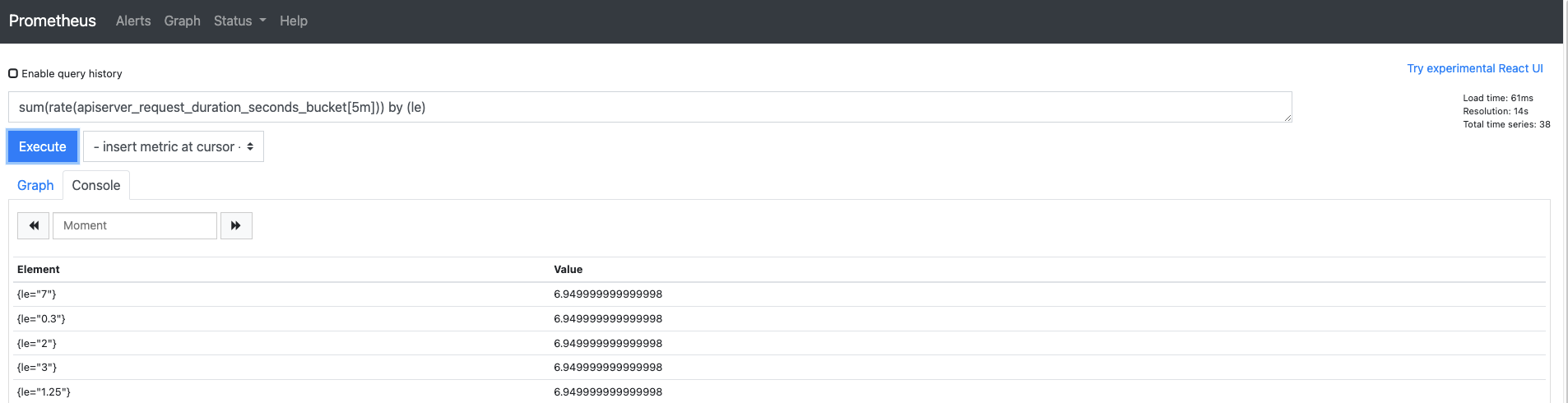
지금까지 프로메테우스의 웹 UI로 메트릭 데이터를 확인했습니다.
메트릭 데이터를 수집하는 가장 중요한 목적은 모니터링인데,
1개의 지표만을 보고 단순히 파악하는 것은 의미가 없습니다.
따라서 다수의 지표가 1개의 대시보드에서 모두 표현되는 형태가 필요합니다.
프로메테우스는 그래프 기능이 매우 제한적이므로
이를 가장 효과적으로 보완할 수 있는 그라파나에 대해 알아봅시다!
그라파나로 모니터링 데이터 시각화하기
메트릭 데이터를 시각화할 떄 가장 많이 언급되는 도구가 그라파나(Grafana) 입니다.
그라파나는 프로메테우스뿐만 아니라 엘리스틱서치, 인플럭스DB 등 여러 종류의 데이터 소스를 시각화할 수 있고,
높은 범용성을 가진 오픈 소스 도구입니다.
이번엔 그라파나를 설치한 후 프로메테우스의 메트릭을 가져오도록 구성하고,
메트릭 시각화를 실제로 구현해 봅시다.
프로메테우스와 다르게 그라파나는 매우 복잡한 구성이나 설정이 없으니 편한 마음으로 따라오세요!
헬름으로 그라파나 설치하기
그라파나 역시 헬름으로 설치할 수 있습니다.
젠킨스와 프로메테우스에서 진행했던 설정과 모두 동일하므로 스크립트로 처리해 진행하겠습니다.
-
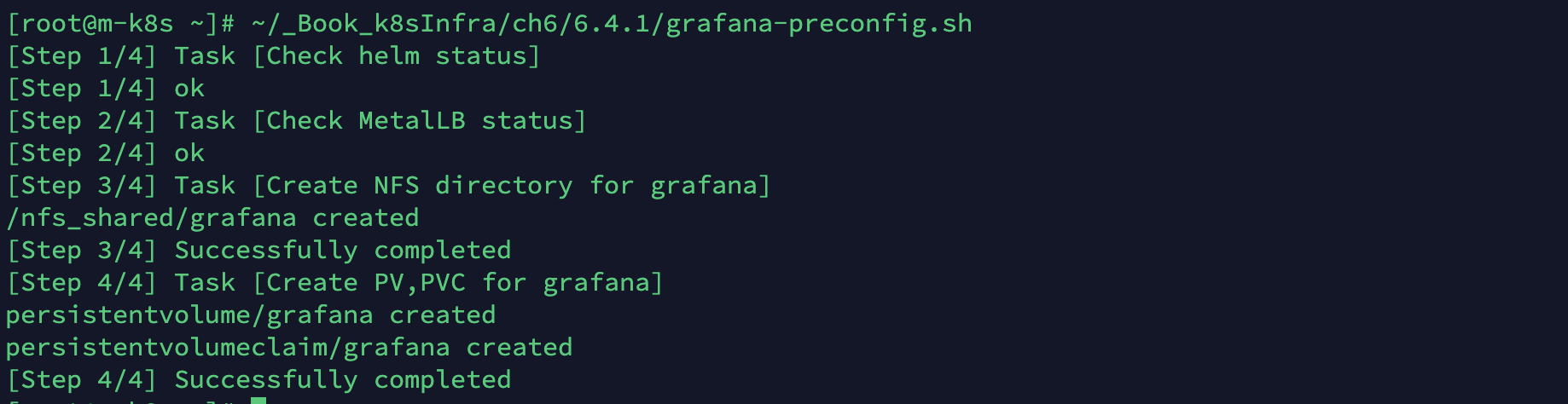
미리 준비된 스크립트를 실행해 쿠버네티스에 그라파나 설치를 위한 사전 구성을 진행합니다.
- 헬름과 MetalLB가 구성돼 있지않다면 앞선 포스팅에서 해당 부분을 먼저 구성한 후 진행해야 합니다.
- 또한 프로메테우스에서 수집된 메트릭이 필요하므로 위의 내용들도 먼저 진행해야 합니다.
~/_Book_k8sInfra/ch6/6.4.1/grafana-preconfig.sh
-
미리 구성된 스크립트로 그라파나 차트를 배포합니다.
~/_Book_k8sInfra/ch6/6.4.1/grafana-install.sh
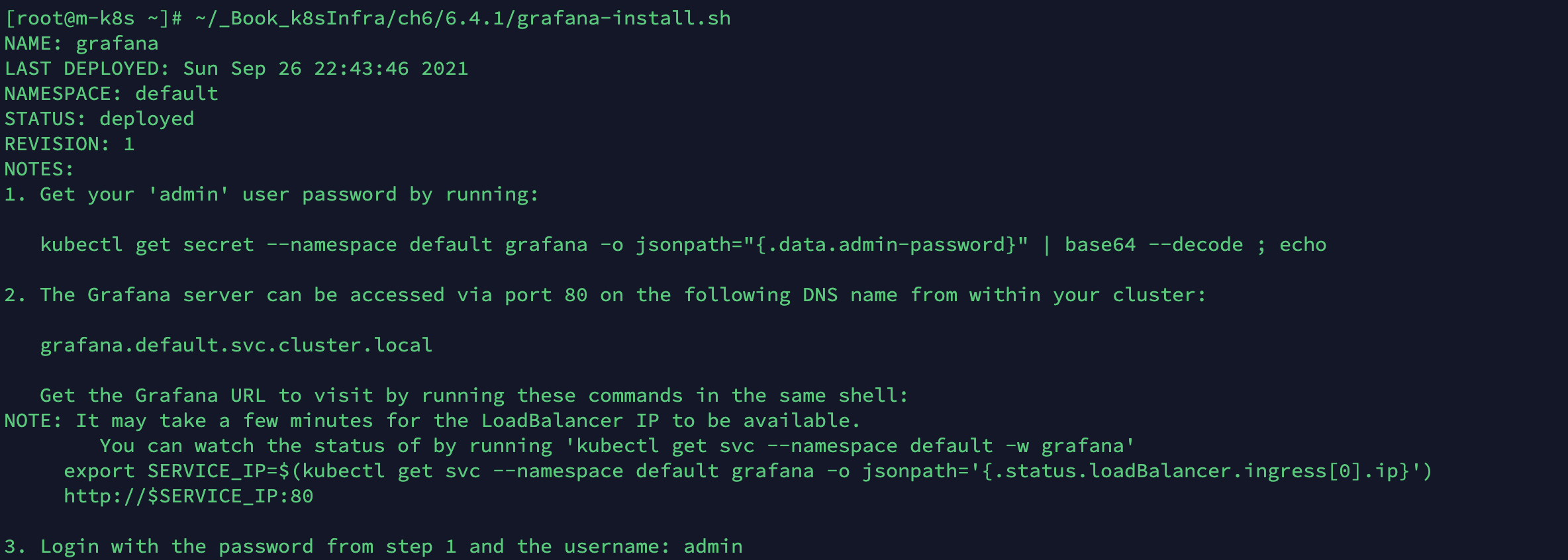
- 그라파나 차트를 설치한 스크립트에서 각 코드의 역할은 다음과 같습니다.
#!/usr/bin/env bash # ede 차트 저장소의 grafana 차트로 쿠버네티스 클러스터 위에 grafana 릴리스를 설치합니다. helm install grafana edu/grafana \ # 그라파나 디플로이먼트가 삭제되더라도 대시보드 데이터를 유지하기 위해 PVC를 통해 영구적으로 데이터를 저장할 수 있게 설정합니다. --set persistence.enabled=true \ # 퍼블릭 클라우드의 PVC 동적 생성을 사용할 수 없는 가상 머신 환경이기 때문에 앞에서 이미 만들어 놓은 grafana라는 이름의 PVC를 사용하도록 설정합니다. --set persistence.existingClaim=grafana \ # 차트 설치 시 생성될 서비스 타입을 로드밸런서로 설정해 MetalLB로부터 외부 IP 주소를 할당받게 합니다. --set service.type=LoadBalancer \ # 그라파나가 사용할 사용자 ID와 그룹 ID를 설정합니다. --set securityContext.runAsUser=1000 \ --set securityContext.runAsGroup=1000 \ # 그라파나 초기 비밀번호를 admin으로 설정합니다. --set adminPassword="admin"
-
그라파나 차트가 정상적으로 쿠버네티스 클러스터에 설치됐는지 확인합니다.
kubectl get deployment grafana

-
그라파나의 서비스 IP를 조회합니다.
kubectl get service grafana

-
웹 브라우저에서 192.168.1.13을 입력해 그라파나의 웹 UI에 접속합니다.
- 로그인 화면이 나오면 username과 password 모두 admin을 입력하고 Log in 버튼을 누릅니다.
- 로그인 화면이 나오면 username과 password 모두 admin을 입력하고 Log in 버튼을 누릅니다.
-
처음 접속하면 보안을 위해 새로운 비밀번호를 지정하는 페이지로 이동됩니다.
- 반드시 변경해야 하는 것은 아니지만, 변경하지 않으면 로그인할 때마다 변경하도록 요청하니까 비밀번호를 변경합니다.(개인 비밀번호 사용하면 됩니다.)
-
로그인한 후에 다음처럼 그라파나 홈 화면이 출력됩니다.
프로메테우스를 데이터 소스로 구성하기
그라파나는 프로메테우스 외에도 다양한 종류의 메트릭 데이터를 시각화할 수 있어서 기각화 기능 위주로 매우 간결하게 구현돼 있습니다.
그라파나의 메뉴를 살펴봅시다.
그라파나 홈 화면 왼쪽에는 그라파나에서 제공하는 다양한 기능들을 바로 사용하거나 설정할 수 있는 7가지 메뉴가 있습니다.
-
돋보기 메뉴(검색)
- 사용자가 만든 대시보드를 대시보드의 태그 또는 이름으로 검색할 수 있습니다.
-
플러스 메뉴(추가, 폴더 설정)
- 가장 중요하고 많이 사용합니다.
- 새로운 대시보드를 구성할 수 있고 다른 사람이 만든 대시보드를 추가할 수도 있습니다.
- 대시보드를 분류해 관리하는 폴더도 여기서 설정합니다.
-
창문 메뉴(추가, 슬라이드 쇼, 스냅샷)
- 플러스 메뉴와 기본 기능은 같습니다.
- 추가로 이미 만들어진 여러 대시보드를 연결해 한 화면에서 파워포인트의 슬라이드 쇼처럼 확인할 수 있는 플레이리스트와 특정 시간의 대시보드 화면을 캡쳐해서 공유할 수 있는 스냅샷이 있습니다.
-
나침반 메뉴(표현식 탐색, 테스트)
- 데이터 소스를 선택해 여러 표현식을 확인하는 탐색(Explore) UI를 사용할 수 있습니다.
- PromQL 표현식을 테스트할 수 있습니다.
-
종 메뉴(경보)
- 그라파나에서 경보를 보내기 위한 채널과 경보 규칙을 설정하는 메뉴입니다.
-
톱니바퀴 메뉴(다양한 그라파나 설정)
- 대시보드 구성을 설정하는 하위 메뉴들이 들어 있습니다.
- 주로 사용하는 메뉴는 데이터 소스(Data Sources) 입니다.
- 대시보드의 기능을 강화하는 플러그인과 조직을 구성할 수 있는 팀/사용자 등 그라파나 UI의 다양한 설정을 모두 여기서 할 수 있습니다.
-
방패 메뉴(관리자 메뉴)
- 그라나파에 새로운 사용자를 추가하거나 애플리케이션의 상태와 설정값을 확인하는 메뉴로, 주로 그라파나 관리자가 사용합니다.
그라나나 홈 화면의 오른쪽 상단에는 현재 화면에 보이는 대시보드에 대한 설정을 할 수 있는 2가지 메뉴가 더 있습니다.
여기서 설정하면 바로 현재 대시보드에 적용됩니다.
-
대시보드 설정 메뉴
- 그라파나의 처음 접속 페이지인 대시보드(Home)를 설정할 수 있는 메뉴입니다.
- 현재는 처음에는 홈 화면을 설정하지만, 대시보드가 추가되면 추가된 대시보드를 설정해 메인 화면을 바꿀 수 있습니다.
-
보기 모드 변경 메뉴
- 대시보드에 표시된 내용만 집중해서 볼 수 있는 모드로 변경하는 메뉴입니다.
- 한 번 누르면 왼쪽에 메뉴가 사라지는 TV 모드로 변환되고 한 번 더 누르면 위쪽 메뉴가 사라지는 가판대(kiosk) 모드로 바뀝니다.
- 변환된 모드에서 ESC를 누르면 다시 기본 모드로 돌아옵니다.
메뉴를 확인했으니 프로메테우스로 수집된 메트릭 데이터를 그라파나에서 시각화할 수 있는 데이터 소스로 구성해봅시다!
프로메테우스 메트릭 데이터를 그라파나의 소스 데이터로 구성하기
-
왼쪽 메뉴에서 톱니바퀴 모양의 아이콘을 누른 후 Data Sources를 선택합니다.
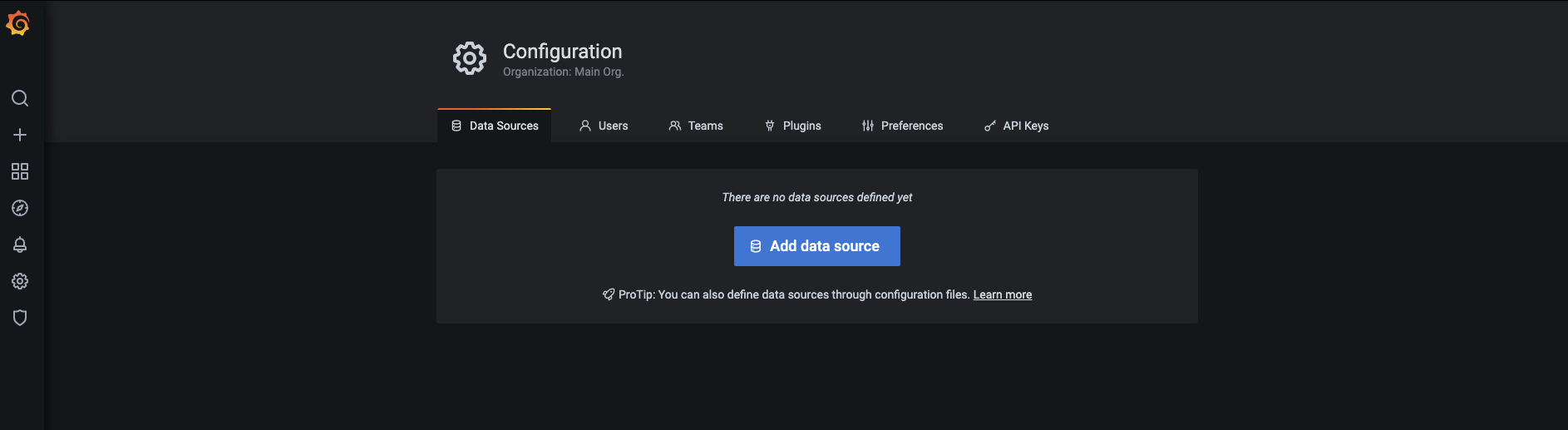
-
다음 화면이 보이면 Add data source 버튼을 누릅니다.
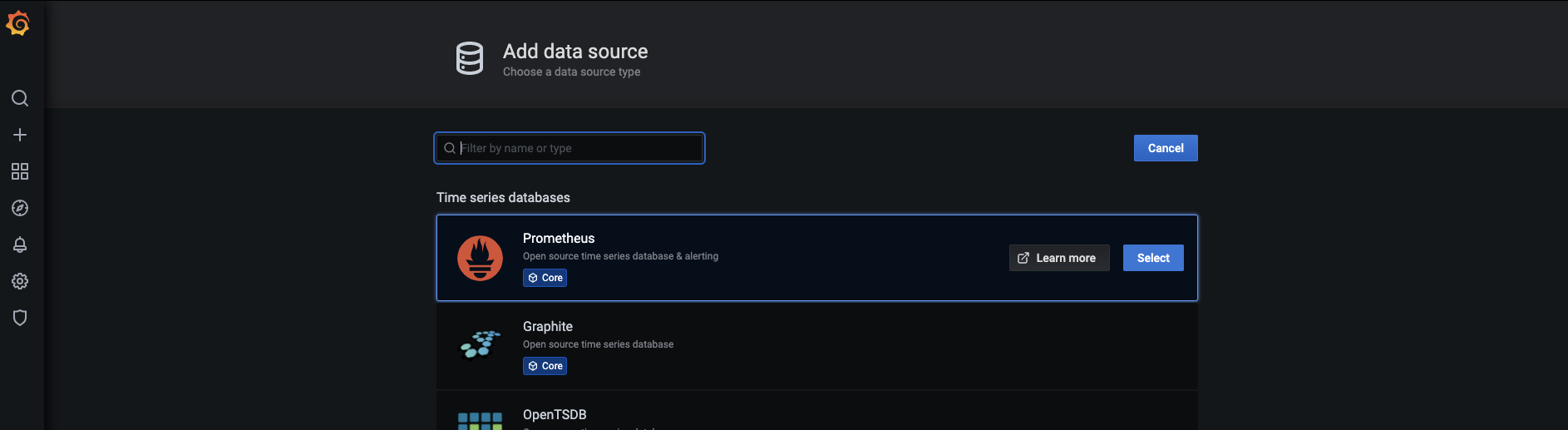
-
화면에 표시되는 다양한 소스 중에서 프로메테우스 아이템 위에 마우스를 올리고 Select 버튼을 눌러 프로메테우스 데이터를 데이터 소스로 선택합니다.
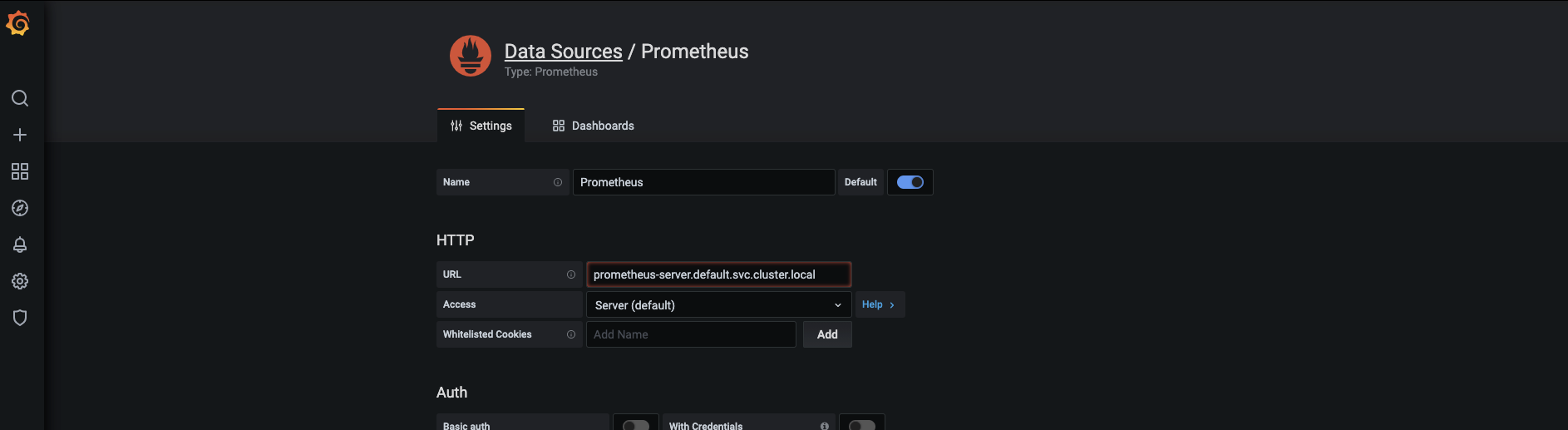
-
값을 설정하는 부분이 나옵니다.
- 프로메테우스가 소스이기 때문에 이름(Name)은 기본값인 Prometheus를 그대로 사용합니다.
- 접속주소(URL)는 프로메테우스의 서버 IP를 직접 입력해도 되지만, 일반적으로 내부의 연결 경로는 CoreDNS로 제공되므로 도메인 이름(prometheus-server.default.svc.cluster.local)으로 적습니다.
- 도메인 이름은 프로메테우스를 설치할 때 표시됩니다(설치할 때 얘기했죠?). 설치한 후에는 IP 정보를 기반으로 확인할 수 있습니다.
쿠버네티스 내에서 도메인 이름을 제공하는 CoreDNS
현재 구성된 쿠버네티스에는 CoreDNS라고 하는 DNS(Domain Name System) 서비스를 제공하는 디플로이먼트가 포함돼 있습니다.
CoreDNS는 파드와 서비스가 배포될 때 IP 주소 정보와 도메인 이름을 자동으로 등록해 도메인 이름으로 연결할 수 있게 합니다.
1. Grafana에서 prometheus-server.default.svc.cluster.local 도메인을 CoreDNS에 질의
2. CoreDNS에서 프로메테우스에 대한 IP 주소를 Granfana로 보내줌
3. Grafana에서 메트릭 데이터를 가져오기 위해 받아온 IP 주소로 프로메테우스 서버에 접속
따라서 실무 환경에서 IP로 직접 연결하기보다는 도메인 이름으로 구성해 파드와 서비스 IP가 변경됐을 때 유연하게 대응할 수 있습니다!
실습 환경에서 프로메테우스의 도메인 이름을 CoreDNS에 IP 주수로 질의하면 다음과 같이 나옵니다.
kubectl run net --image=sysnet4admin/net-tools --restart=Never --rm -it -- nslookup 192.168.1.12
쿠버네티스에서 배포된 오브젝트들은 IP가 변경돼도 도메인 이름으로 통신해 서로 연결할 수 있습니다.

- 두 가지를 입력하고 나면 화면을 아래로 스크롤해 Save & Test 버튼을 누르면 설정을 테스트하고 저장하게 됩니다.
- 모든 것이 정상적으로 처리됐는지 확인하고 왼쪽 상단의 그라파나 로고를 클릭해 그라파나 홈 화면으로 이동합니다.
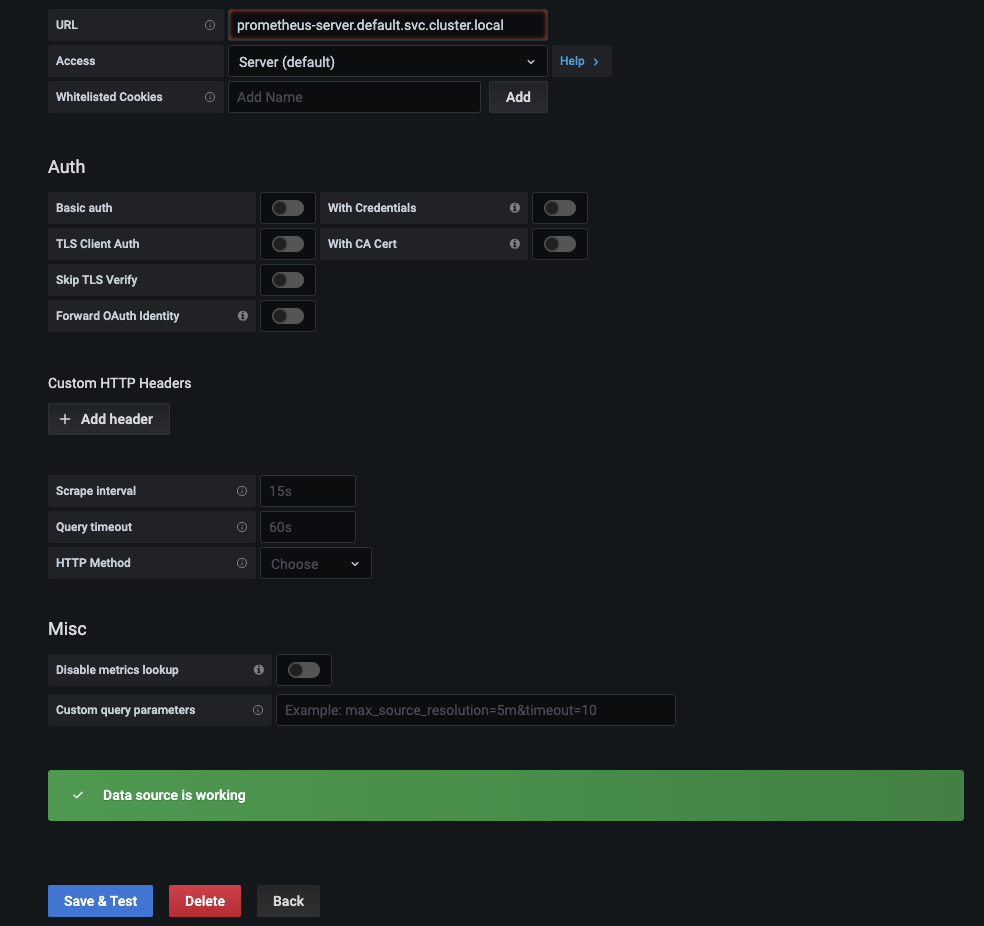
- 모든 것이 정상적으로 처리됐는지 확인하고 왼쪽 상단의 그라파나 로고를 클릭해 그라파나 홈 화면으로 이동합니다.
프로메테우스의 메트릭 데이터를 데이터 소스로 사용하기 위한 설정이 끝났습니다.
설정도 쉽지만 그라파나에서 데이터를 시각화하는 과정도 쉽고 재미있습니다.
우번 쿠버네티스의 밑바탕이 되는 노드에 대한 메트릭 데이터를 시각화해 보겠습니다!
노드 메트릭 데이터 시각화하기
메뉴를 설명할 때 첫 접속페이지를 대시보드라고 했습니다.
그라파나는 이러한 대시보드를 만들고 그 안에 패널(Panel)이라는 구성 요소를 추가하는 방식으로 메트릭 데이터를 추가합니다.
그라파나 대시보드의 PromQL 표현식은 조금 어렵지만,
그라파나의 기능을 사용하는 것은 매우 쉽습니다.
앞에서 PromQL을 충분히 학습했으므로 진행에 어려움은 없을 겁니다.
시작해봅시다!
-
바탕이 되는 대시보드를 설정합니다. 왼쪽에서
+ > Dashboard를 선택합니다.
-
대시보드를 생성하는 화면에서
+ Add new panel버튼을 눌러 패널을 추가합니다.
-
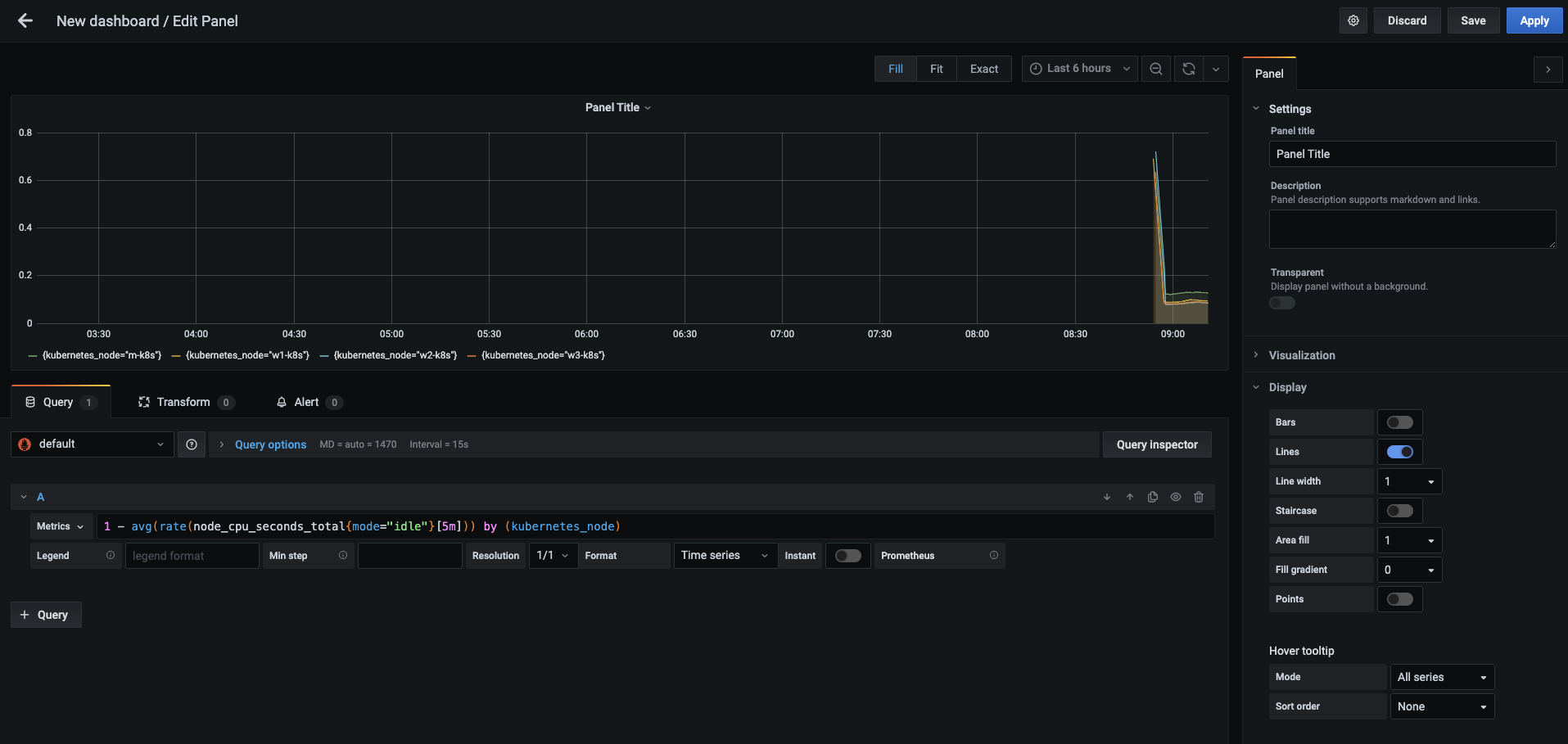
패널이 추가되면 가운데 보이는 메트릭(Metrics) 부분에
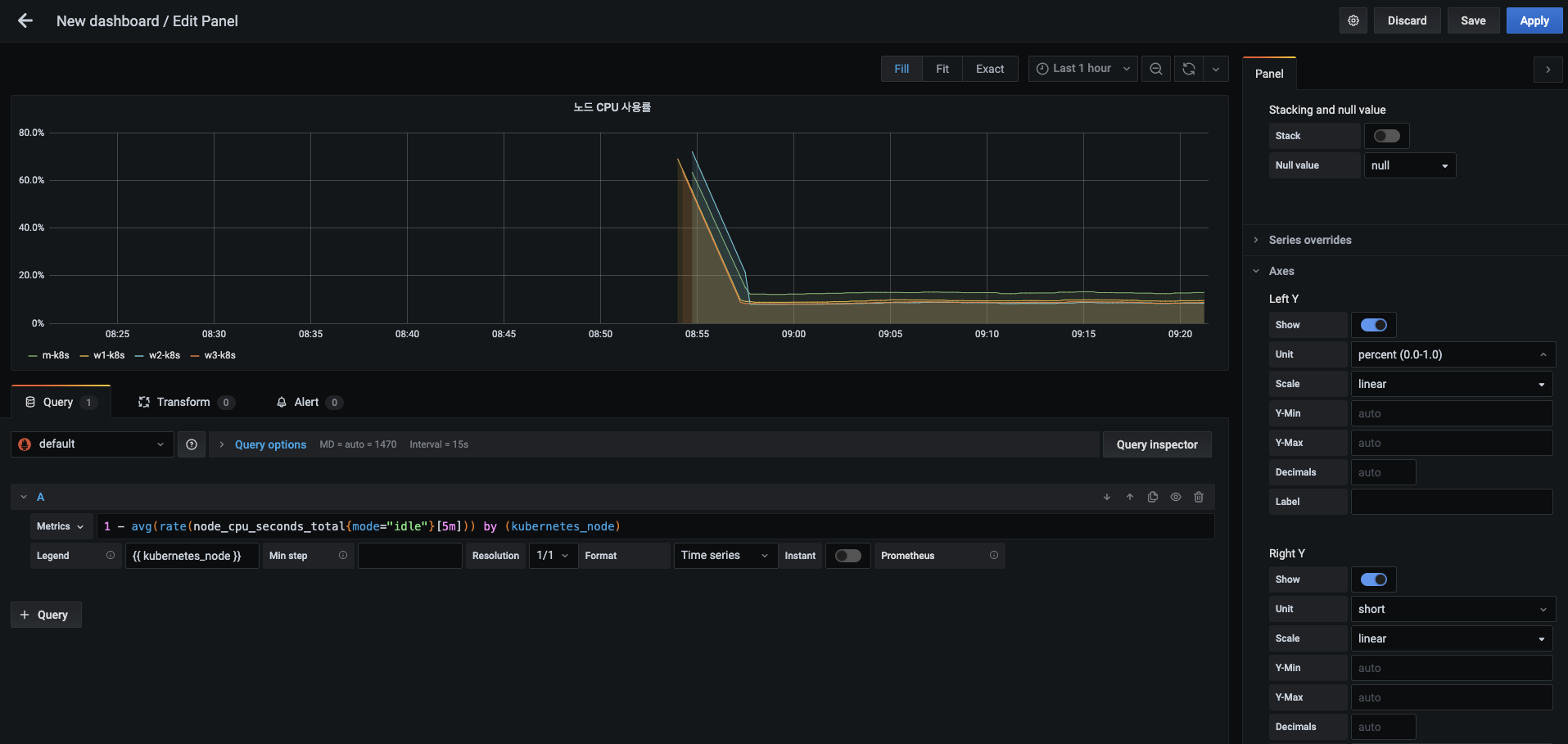
1 - avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) by (kubernetes_node)를 입력합니다.- 이때 1에서 메트릭 값을 빼는 이유는 유휴(idle) 상태 외에는 모두 사용하는 상태이므로, 이를 제외한 총 CPU 사용률을 구하기 위해서입니다.(사용중인 CPU 총 사용률)
- 마스터 노드는 CPU가 2개이므로 avg로 평균을 구해 좀 더 정확한 CPU 사용률을 나타냅니다.
- 입력 후에 Shift+Enter 또는 메트릭 표현식을 입력하는 부분 밖에서 마우스를 클릭해 프로메테우스(현재 기본값)로부터 입력 값을 읽어 들여 다음과 같이 그래프가 표현되는지 확인합니다.
-
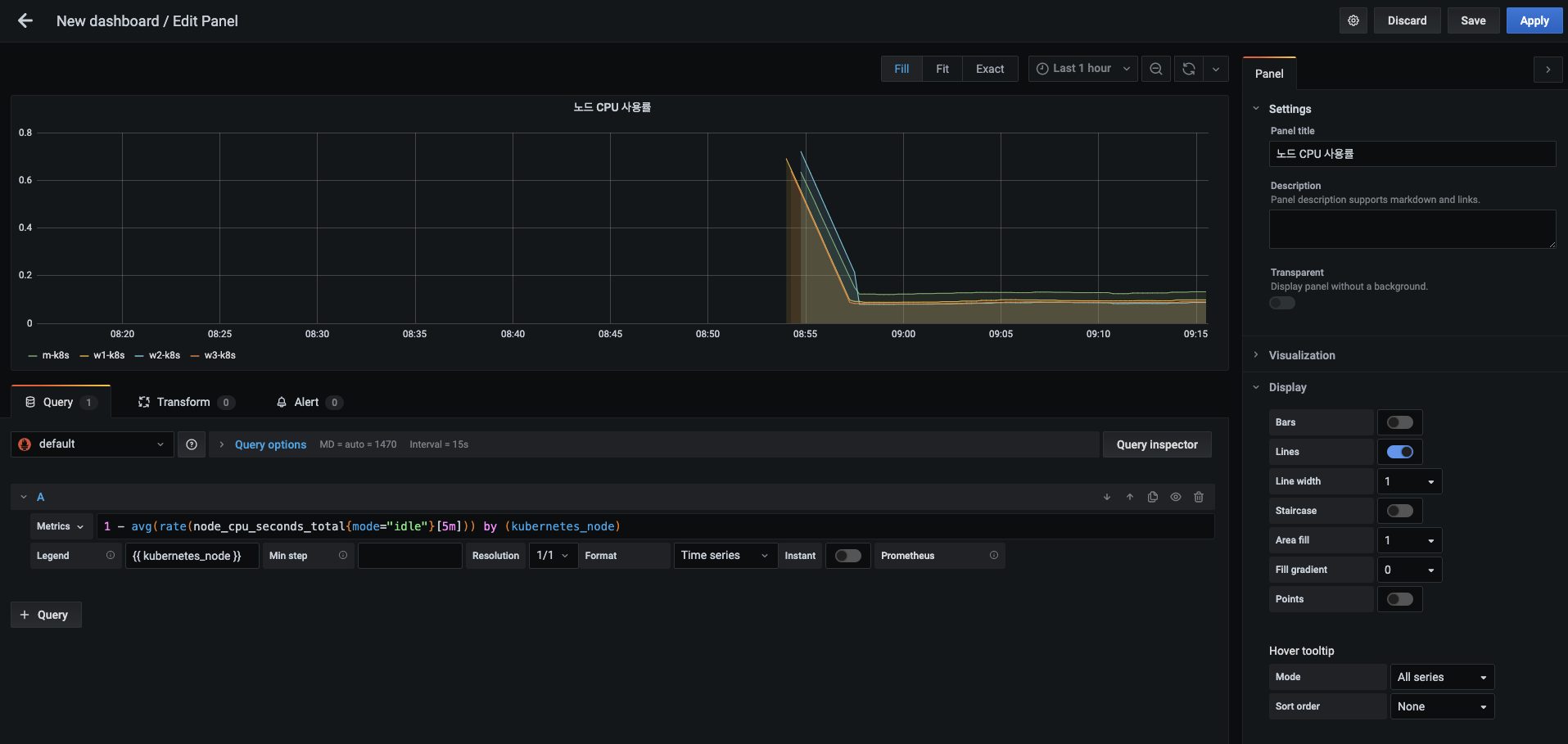
오른쪽 패널 탭의 패널 제목(Panel title)은 노드 CPU 사용률 로 변경하고, 메트릭아래 있는 범례(Legend)에는 {{ kubernetes_node }} 를 입력합니다.
- 범례는 메트릭 레이블의 값을 사용해 시각화 대상을 쉽게 인지할 수 있게 합니다.
- 오른쪽 상단에 메트릭 수집 구간 선택 상자에서 현재 설정인 Last 6 hours(6시간 동안)를 Last 1 hour(지난 1시간 동안)로 변경합니다. 좀 더 짧은 구간의 변화 값을 확인할 수 있습니다.
-
오른쪽 패널 탭을 아래로 스크롤하면 Axes(축) 항목이 보입니다.
- 여기서 Y축(Left Y)의 단위(Unit)를 Misc > percent(0.0-1.0) 으로 선택합니다.
- 그러면 시각화 패널에서 Y축의 CPU 사용률이 백분율로 표시됩니다.
- 그림은 Y축 단위를 변경하는 중간 단계를 보여주며, 적용하고 나면 백분율로 표시됩니다.
- 설정을 적용하기 위해 오른쪽 상단의 Apply 버튼을 누릅니다.
-
대시보드에 노드 CPU 사용률 패널이 생성되고 나면 오른쪽 상단 메뉴에서 Add panel 버튼을 눌러 패널을 추가합니다.
-
화면에 보이는
+ Add new panel버튼을 누릅니다.
-
새로 열린 패널에 다음 내용을 입력합니다.
- 패널 제목 : 노드 메모리 사용량
- 메트릭 :
node_memory_Active_bytes - 범레 : {{ kubernetes_node }}
- Y축 단위 : Data (Metric) -> bytes(Metric)
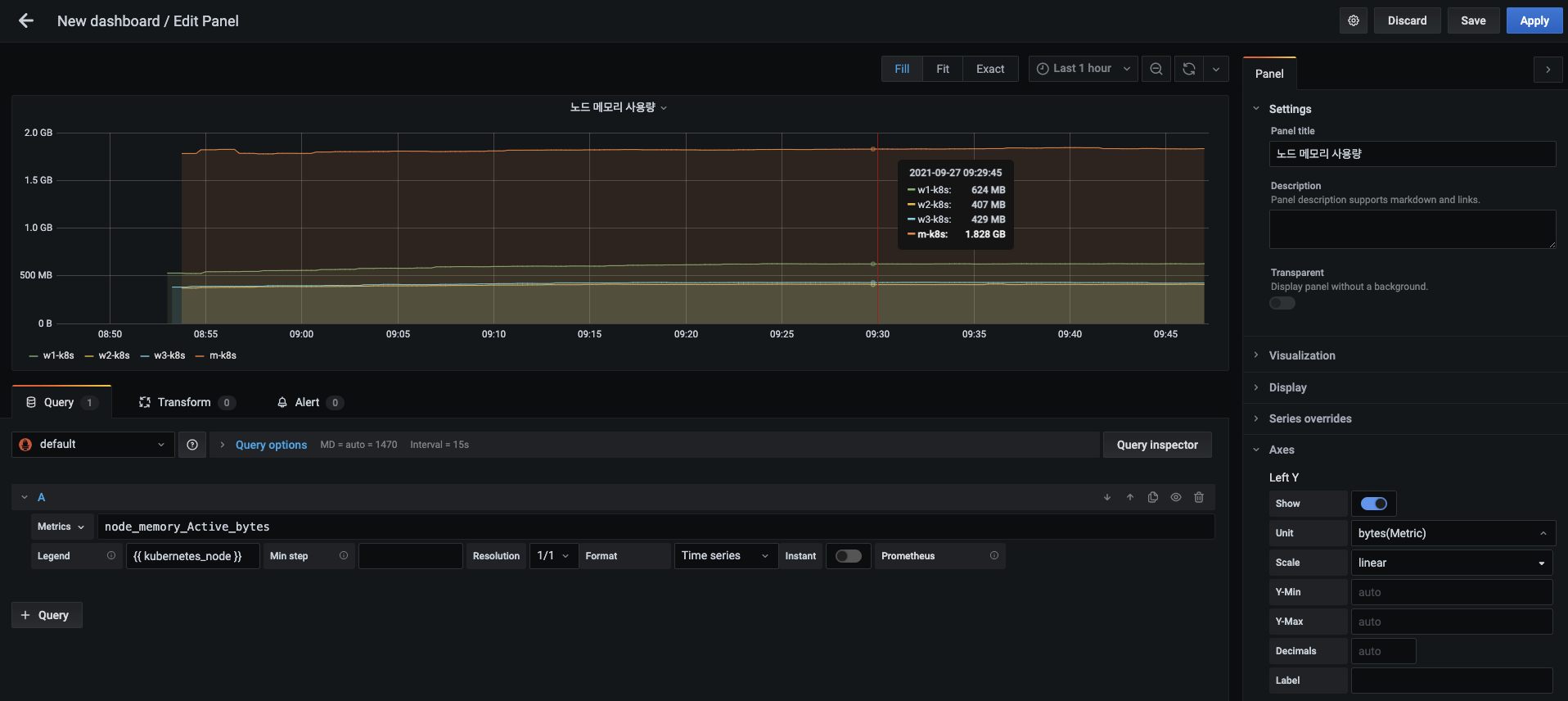
-
입력을 마치면 Apply 버튼을 눌러 적용합니다.
-
대시보드에 추가된 노드 메모리 사용량 패널을 확인합니다. 이번에도 Add panel > Add new panel 버튼을 눌러 패널을 추가합니다.
-
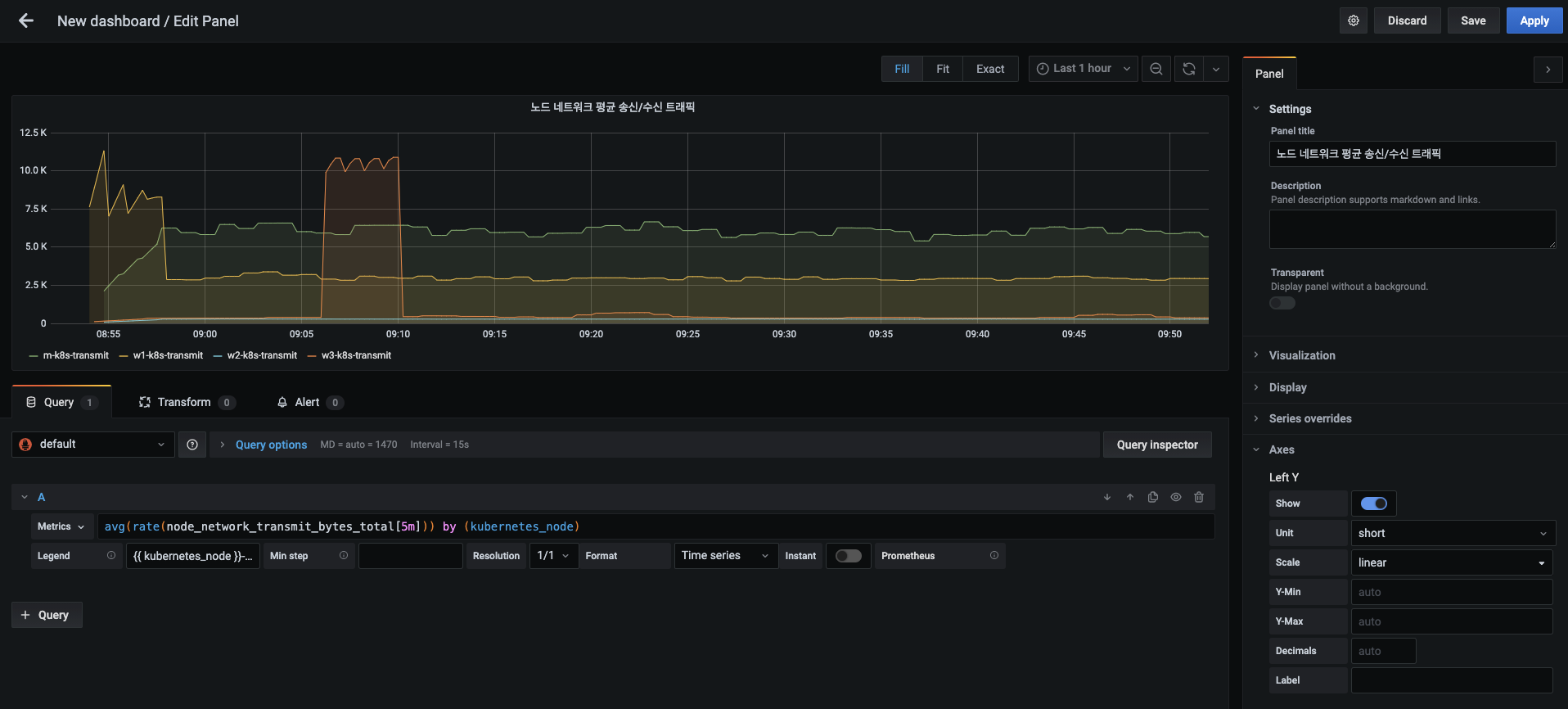
노드 네트워크 평균 송신/수신 트래픽 패널에서 송신 부분으로 다음 내용을 입력합니다.
- 패널 제목 : 노드 네트워크 평균 송신/수신 트래픽
- 메트릭 :
avg(rate(node_network_transmit_bytes_total[5m])) by (kubernetes_node) - 범레 : {{ kubernetes_node }}-transmit
-
송신 부분을 설정하고 나면 왼쪽 하단에 + Query 버튼을 누릅니다.

-
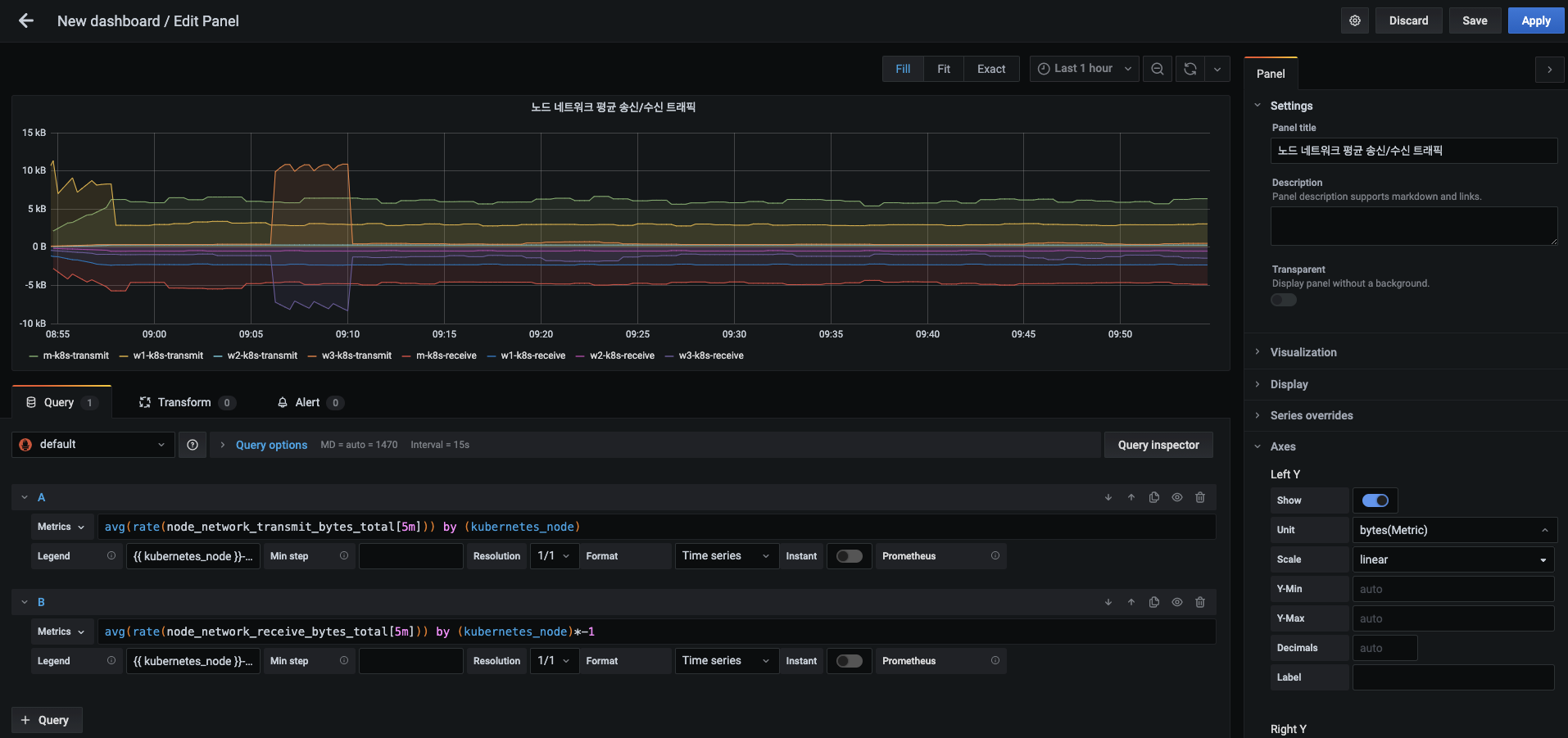
노드 네트워크 평균 송신/수신 트래픽 패널의 수신 부분으로 다음 내용을 입력합니다.
- 이때 송신과 수신이 같은 단위로 표시되면 구분하기 어려우니 메트릭에 -1을 곱해 위상을 전환합니다.
- 메트릭 :
avg(rate(node_network_receive_bytes_total[5m])) by (kubernetes_node)*-1 - 범레 : {{ kubernetes_node }}-receive
- Y축 단위 : Data (Metric) -> bytes(Metric)
-
설정을 마치면 Apply 버튼을 눌러 적용합니다.
-
대시보드에서 노드 네트워크 평균 송신/수신 트래픽 패널을 확인하고, 마지막 패널을 추가합니다.
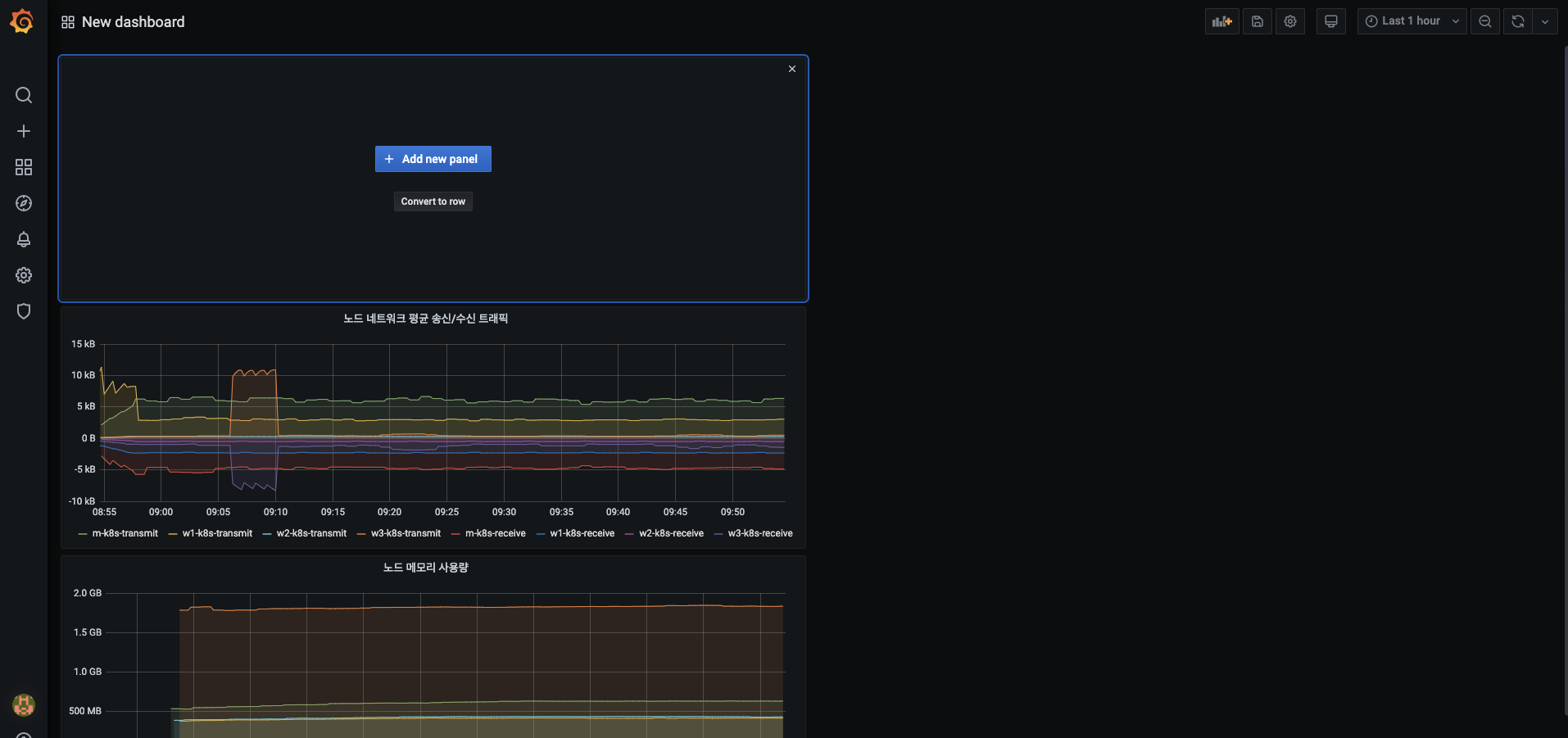
-
새로운 패널에 다음 내용을 입력합니다.
- 패널 제목 : 노드 상태
- 메트릭 :
up{job="kubernetes-nodes"} - 범레 : {{ instance }}
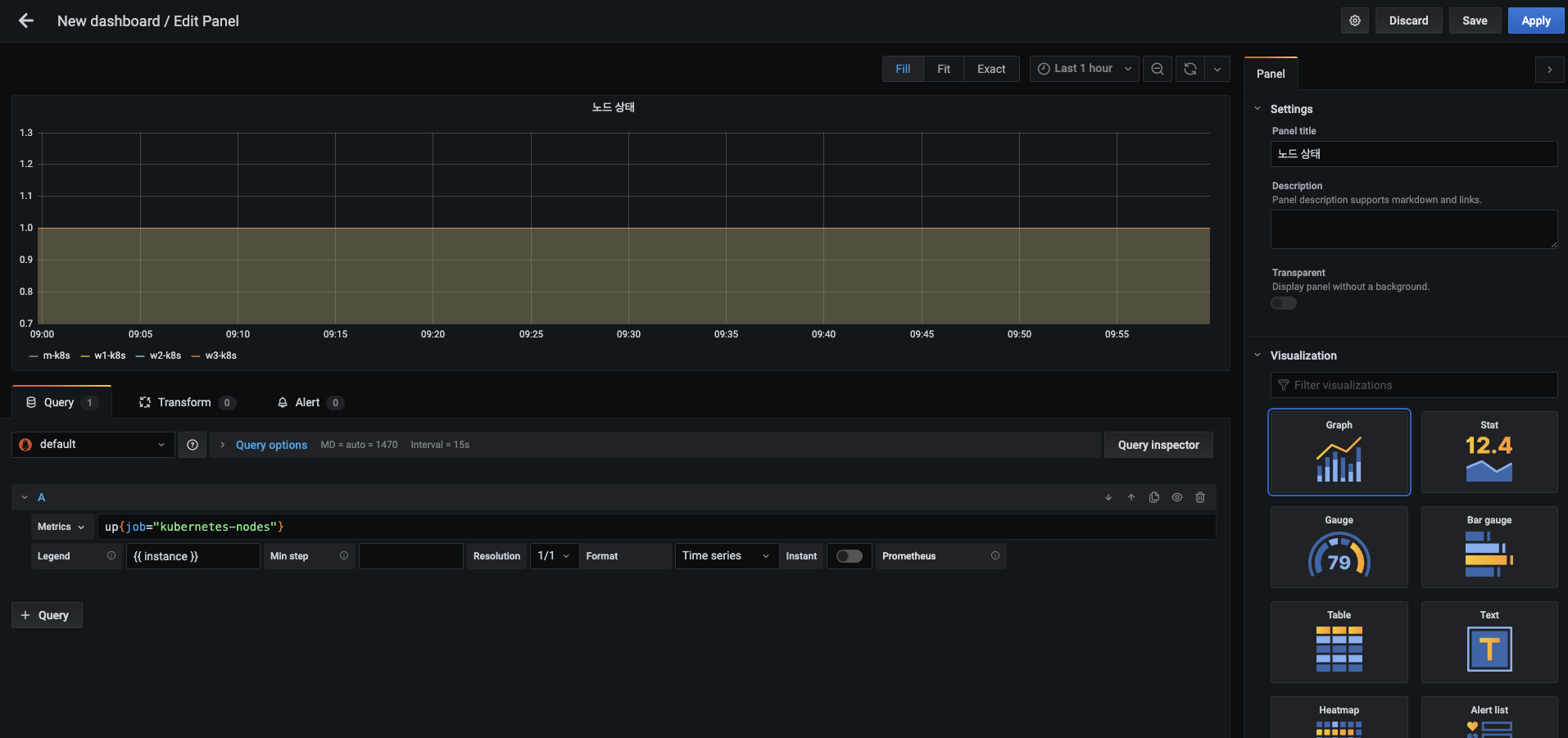
-
모든 노드가 동작 중인 상태라는 1의 값을 가지기 때문에 구분할 수 없습니다.
- 오른쪽 패널 탭의 시각화(Visualization) 항목의 옵션을 그래프(Graph)에서 상태 값(Stat)으로 변경합니다.
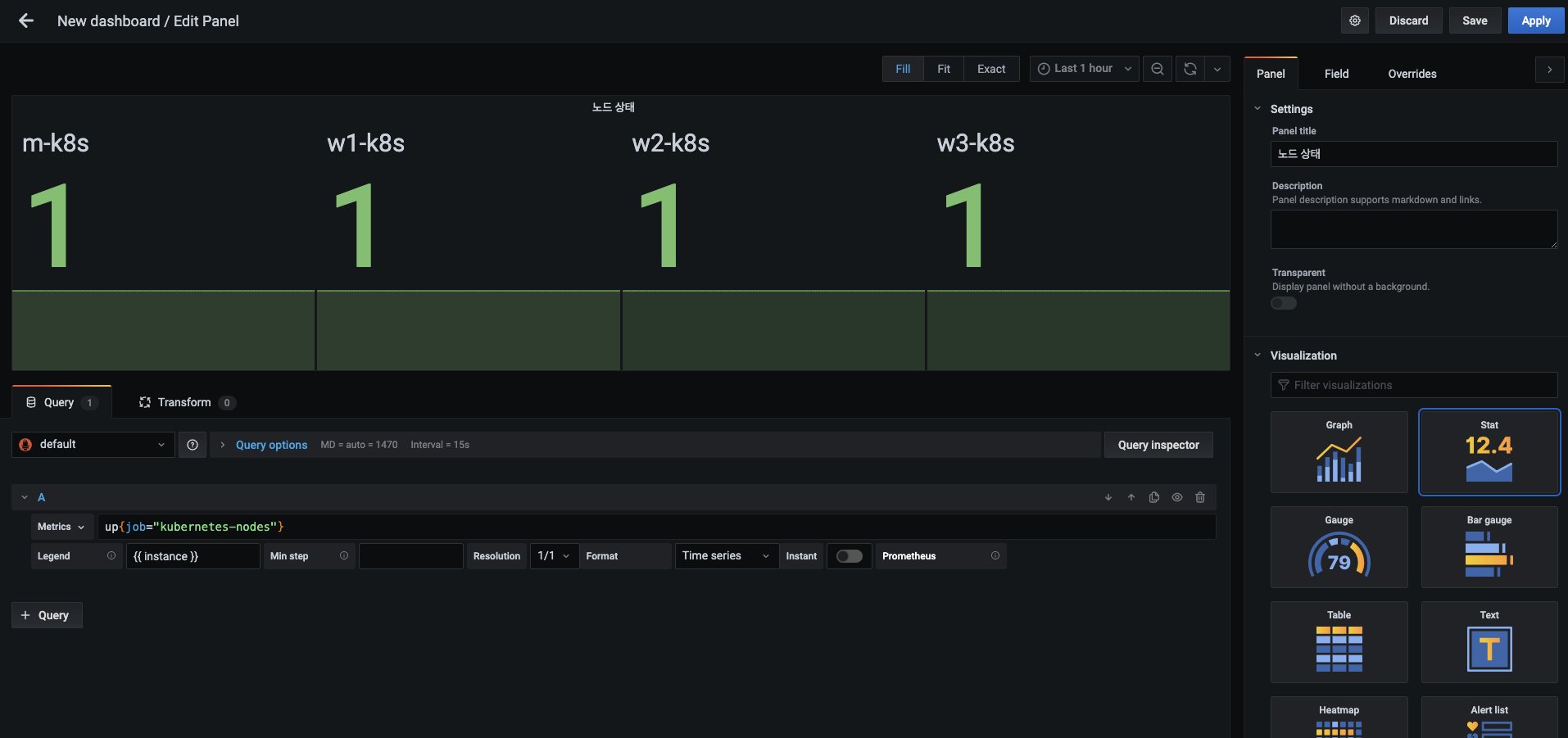
- 오른쪽 패널 탭의 시각화(Visualization) 항목의 옵션을 그래프(Graph)에서 상태 값(Stat)으로 변경합니다.
그라파나 패널 시각화(Viusalization) 옵션
1. 그래프(Graph)
- 그라파나에서 가장 많이 사용되는 기본 옵션
- 선 또는 막대로 데이터를 시각화
- 대부분의 시계열 데이터를 사용자가 원하는 형태로 표시
2. 상태 값(Stat)
- 특정 값과 함꼐 추이를 꺽은선 그래프로 표시
- 텍스트 모드를 적용해 그래프 없이 값만 볼 수도 있음
- 주로 여러 대상이나 단일 대상의 상태를 나타내는 데 사용
3. 게이지(Gauge)
- 차량의 계기판과 같이 값의 범위가 있는 데이터를 표현할 때 유용
- 주로 백분율처럼 사용량의 시작과 끝이 있을 때 사용
4. 바 게이지(Bar gauge)
- 게이지처럼 값의 범위가 있는 데이터를 표현할 때 유용
- 게이지와 다르게 모양이 원형이 아닌 막대형으로 표현
- 게이지보다는 범위가 더 넓어 한계를 모르는 경우에 사용
5. 테이블(Table)
- 수집된 메트릭 데이터를 그대로 표현할 수 있어 주로 실제 값을 대시보드에서 확인하는 목적으로 사용
6. 텍스트(Text)
- 제작자가 알리고 싶은 정보를 대시보드에 표현할 때 사용
- 주로 대시보드의 목적과 사용법 등의 정보를 전달하는 데 사용
7. 히트맵(Heatmap)
- 패널을 다수 구역으로 나누어 해당 구역에 속하는 값이 많을수록 구역 색상을 점점 연하게 표현해 한눈에 값의 분포를 확인 가능
- 주로 히스토그램과 함께 빈도를 나타내는 용도로 사용
8. 경보 목록(Alert list)
- 수집 대상의 문제를 빠르게 확인하기 위한 정보를 표시
- 가장 최근에 발생한 경보부터 확인 가능
9. 대시보드 목록(Dashboard list)
- 최근에 확인한 대시보드와 사용자가 즐겨찾기한 대시보드 등을 만드는 데 사용
10. 뉴스(News)
- RSS 피드와 같은 정보를 표시
- 기본적으로 그라파나 공식 블로그의 게시글 정보를 표시
11. 로그(Logs)
- 외부 로그 데이터를 표시
- 주로 엘라스틱서치, 로키(Loki), 인플럭스DB, 같은 데이터 소스에서 받아온 로그 데이터를 시각화하는 데 사용
- 추가로 로그 수준(Level)에 따라 패널에 색상 변화 추가 가능
12. 플러그인 목록(Plugin list)
- 현재 설치된 플러그인 확인
- 그라파나에서 기본적으로 제공하는 패널만으로는 부족한 기능을 외부에서 제공하는 플러그인 방식의 패널로 추가하는데, 이렇게 추가된 패널들을 대시보드에서 확인하게 함
- 패널 외에도 플러그인을 사용하면 기존에 그라파나에서 제공하지 않던 다양한 기능 추가 가능
-
시각화 목적에 맞게 상태 값 형태를 좀 더 바꾸겠습니다.
- 패널 탭을 아래로 내리면 디스플레이 항목이 보입니다. 이 부분을 다음과 같이 바꿔 노드별 상태 값을 숫자로만 표현합니다.
- Value : Last (not null)
- Orientation : Horizontal
- Graph mode : None
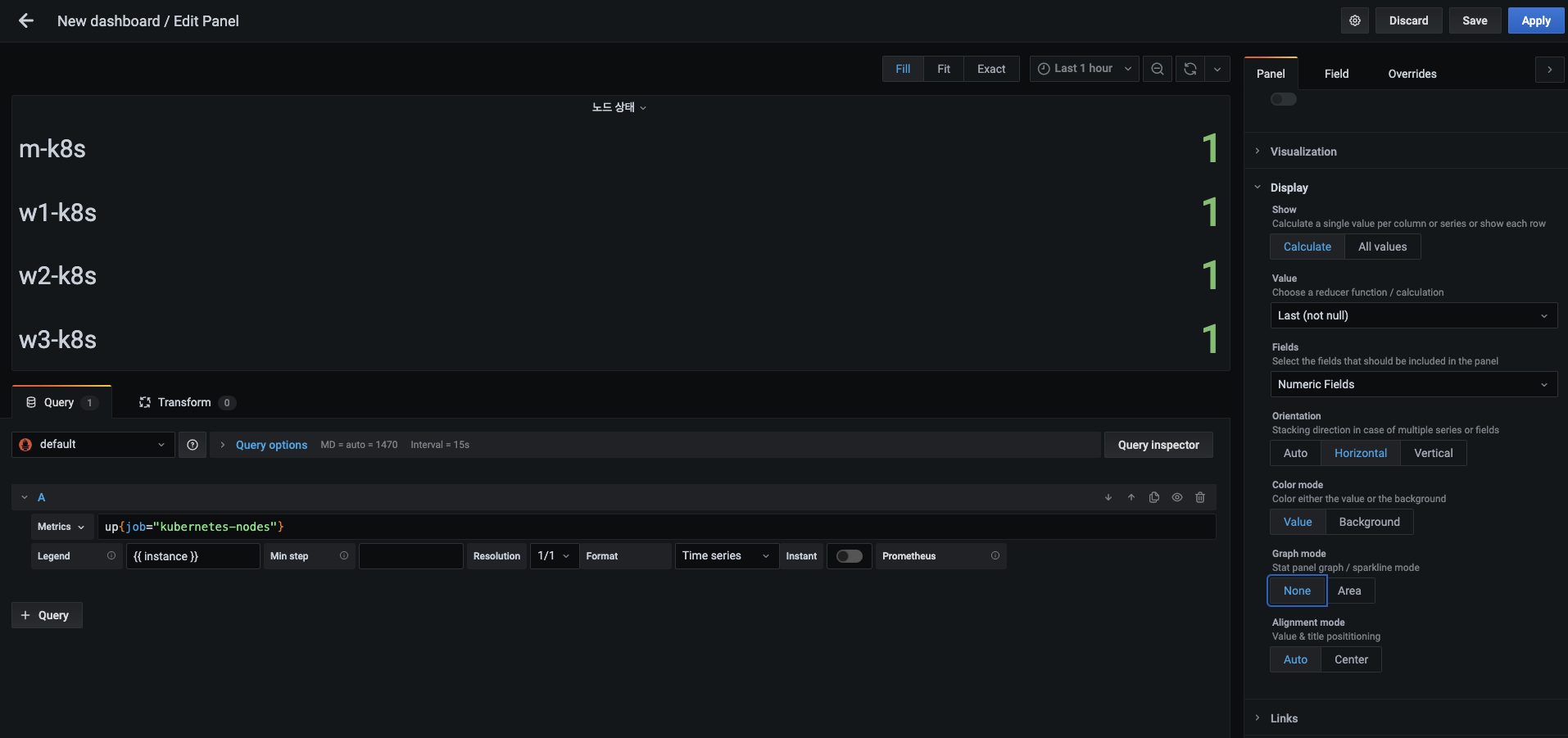
-
숫자로 표현한 노드 값을 사람이 인식하기 쉬운 문자열로 변경해 봅시다.
- 패널 탭 옆의 필드(Field) 탭에서 Value mappings라는 항목을 찾습니다.
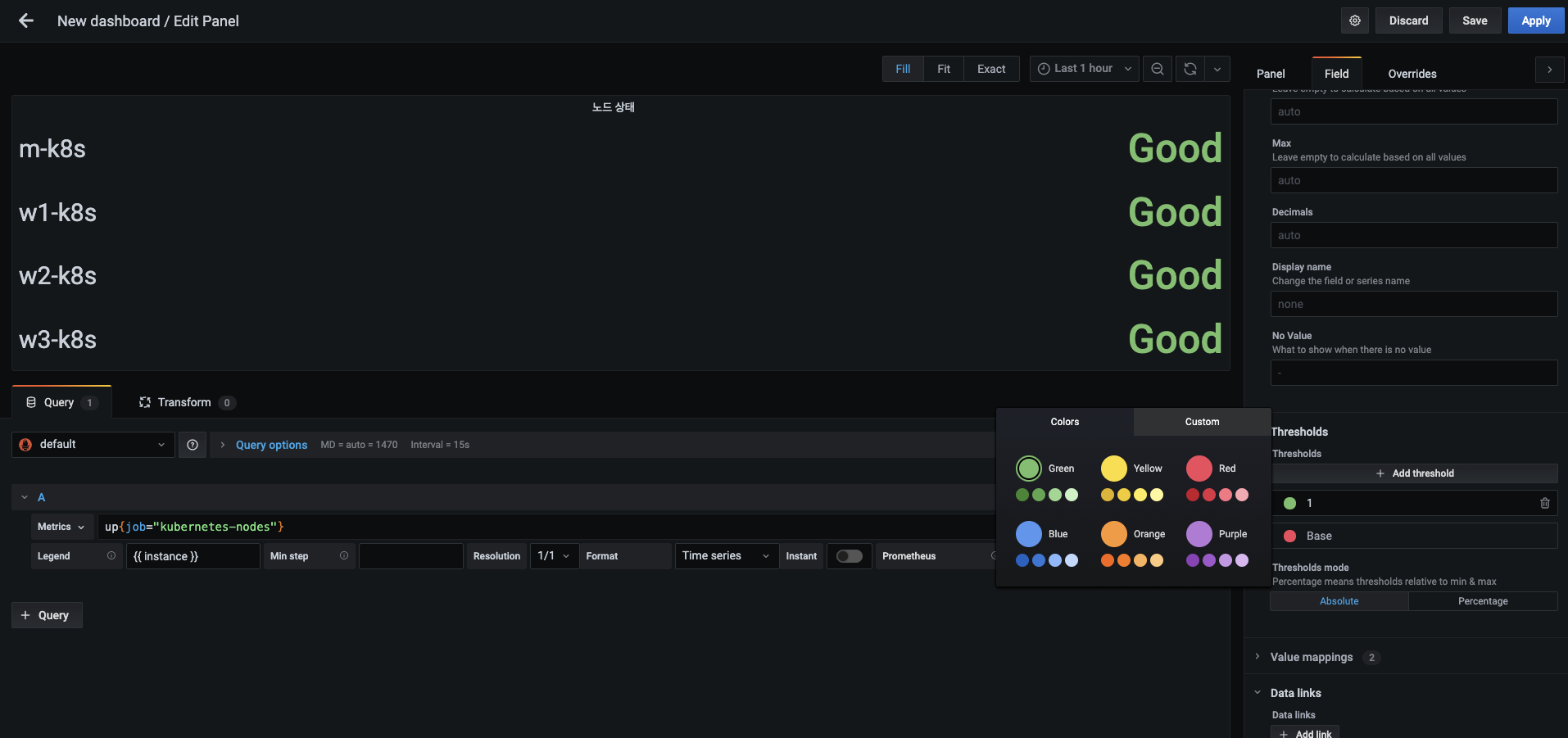
- 그리고 Add value mapping 버튼을 눌러 1에 대응하는 Good이라는 문자열을 입력하고, 0에 대응하면 Bad라는 문자열을 입력합니다.
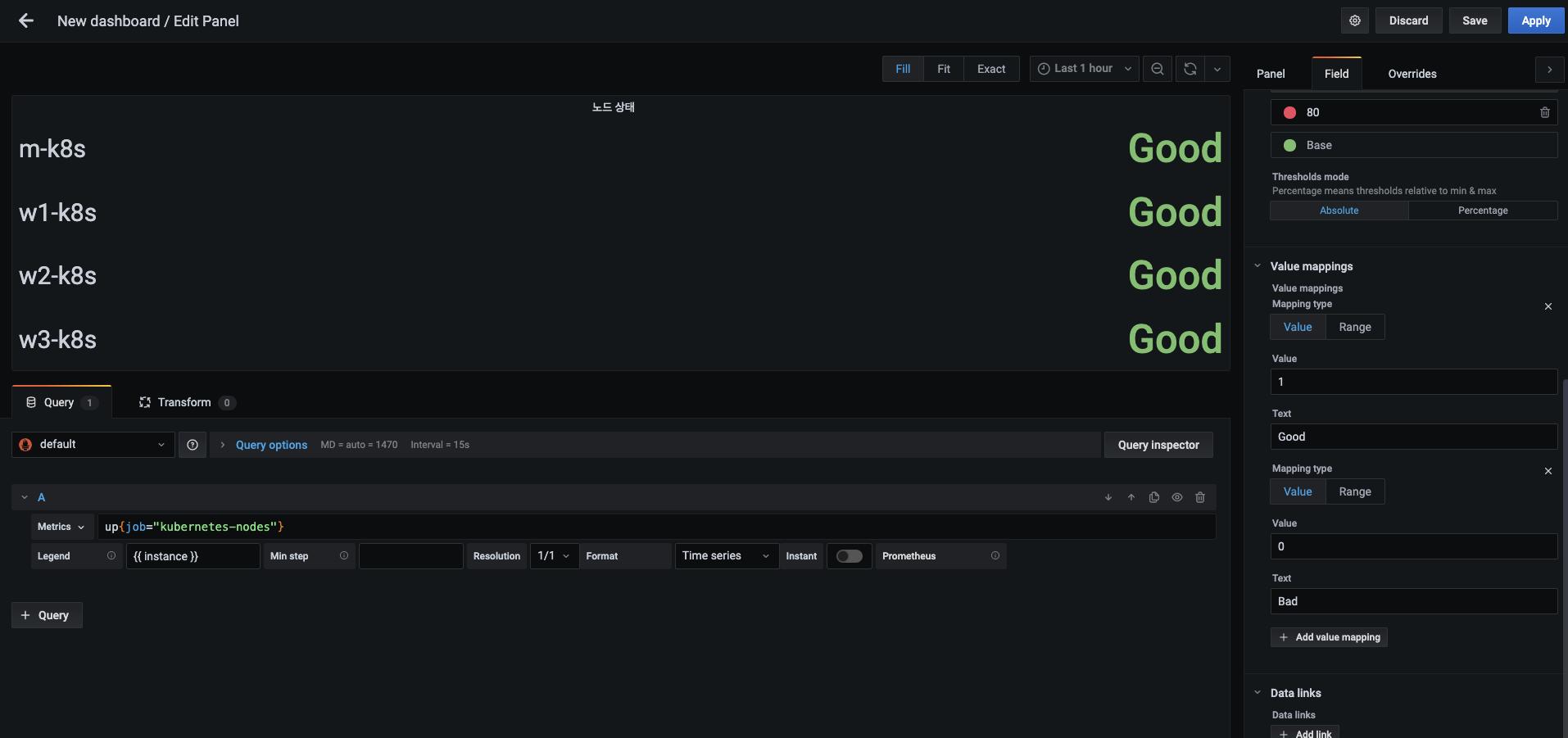
-
1 외의 상태에서는 빨간색으로 표시해 문제가 발생했음을 확실하게 표시하겠습니다.
- Value mappings 위에 있는 Thresholds에서 다음 순서로 설정합니다.
- 위에 임계값을 80에서 1로 바꾸고 옆의 원을 눌러 색상을 초록색으로 바꿉니다.
- 아래 임계값은 Base(기본)로 두고 옆의 원을 빨간색으로 바꿉니다. 설정을 바꾸고 나면 Apply 버튼을 눌러 적용합니다.
-
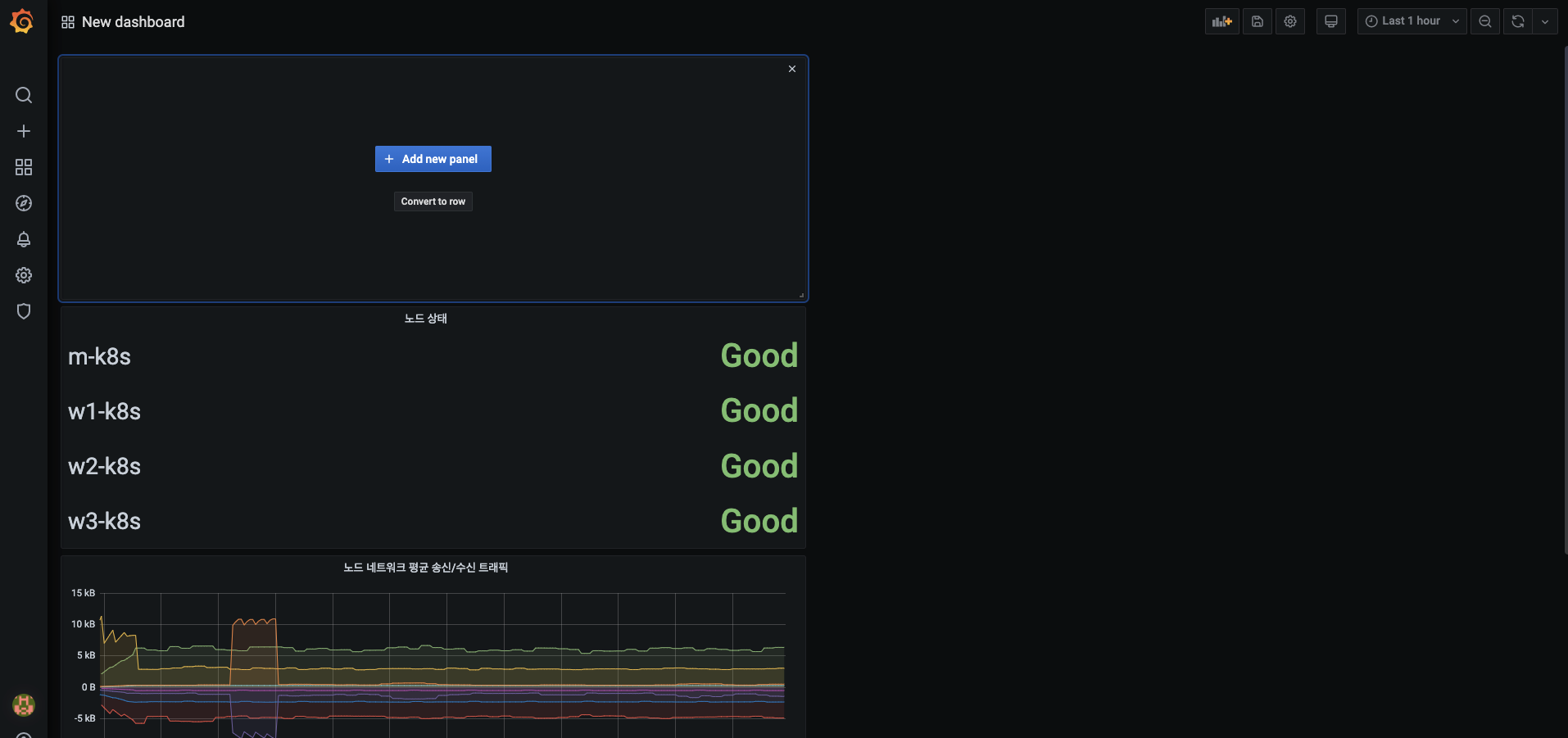
대시보드에 노드 상태 패널이 생성됐는지 확인하고, 오른쪽 상단에 Add panel 버튼을 누릅니다.
- 이번에는 Convert to row 버튼을 누르는데, 이 버튼은 현재 생성된 패널들을 모아서 접고 펼 수 있는 아코디언(Accordion) 형태의 메뉴를 생성합니다.
- 아코디언 메뉴는 행(row)를 기준으로 정렬합니다.
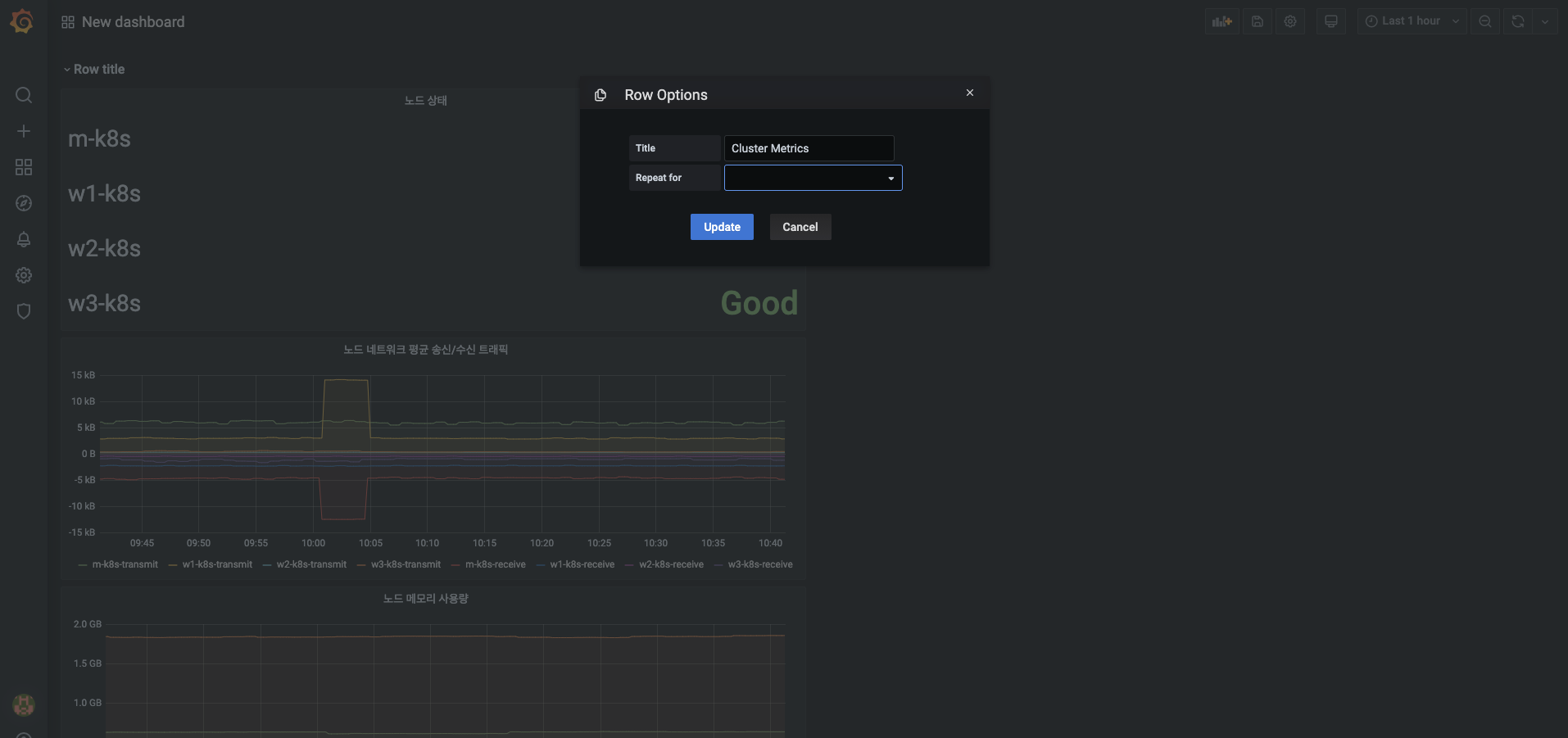
-
생성된 아코디언 메뉴인 Row Title에 마우스를 올리면 제목을 바꿀 수 있는 톱니바퀴 메뉴가 나옵니다.
- 메뉴를 눌러서 제목을 Cluster Metrics로 변경하고 Updata 버튼을 누릅니다.
- 메뉴를 눌러서 제목을 Cluster Metrics로 변경하고 Updata 버튼을 누릅니다.
-
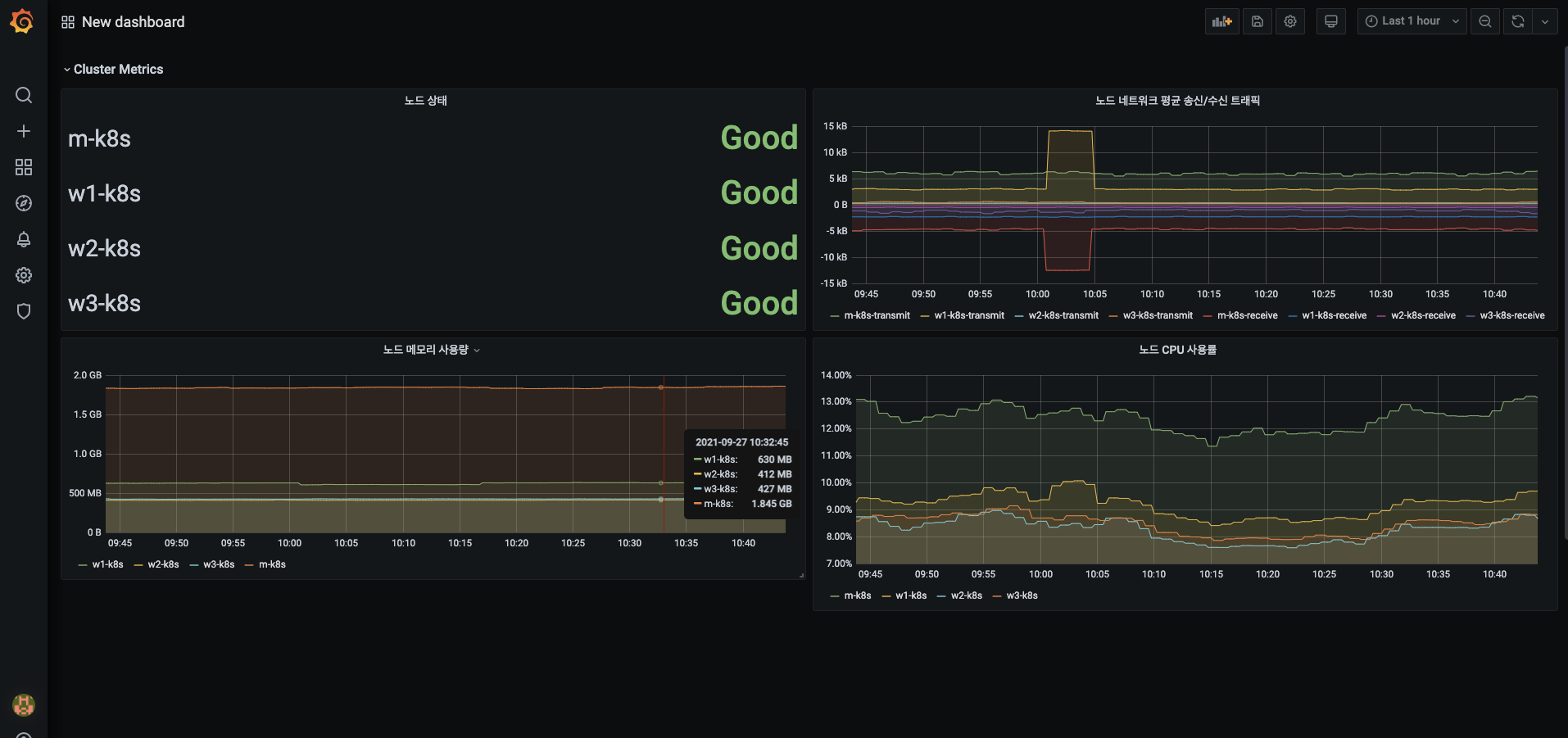
아코디언 메뉴의 제목이 변경됐는지 확인하고, 다음 방법으로 지금까지 생성한 4개의 패널을 Cluster Metrics 메뉴 아래로 옮깁니다.
- 패널 이동 : 패널의 제목 부분에 마우스를 올리면 마우스의 커서가 Move 형태로 바뀝니다. 왼쪽 마우스 버튼을 누른 상태로 끌어서 Cluster Metrics 메뉴로 옮깁니다.
- 채널 확대/축소 : 생성된 패널의 오른쪽 하단부에 마우스를 올리면 커서의 형태가 Resize로 바뀝니다. 왼쪽 마우스 버튼을 누른 상태로 끌어서 패널 크기를 조정합니다.
-
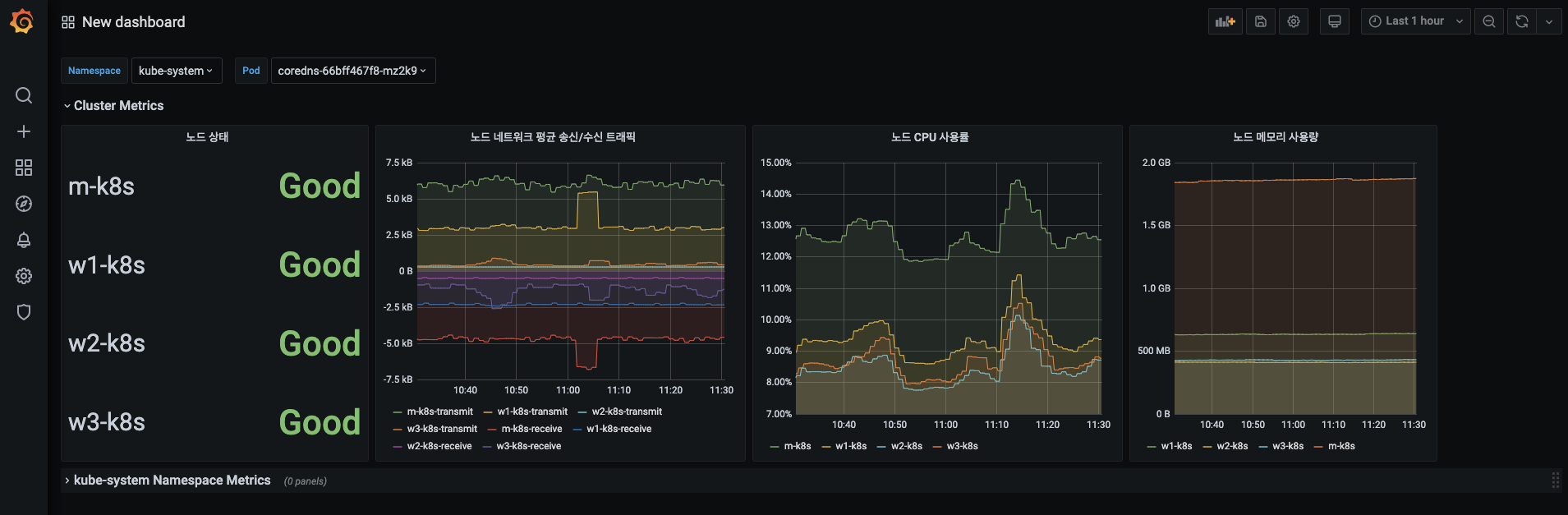
Cluster Metrics 메뉴 아래로 정렬한 4개의 패널이 다음 형태인지 확인합니다.
- 채널 확대/축소를 활용해보세요.
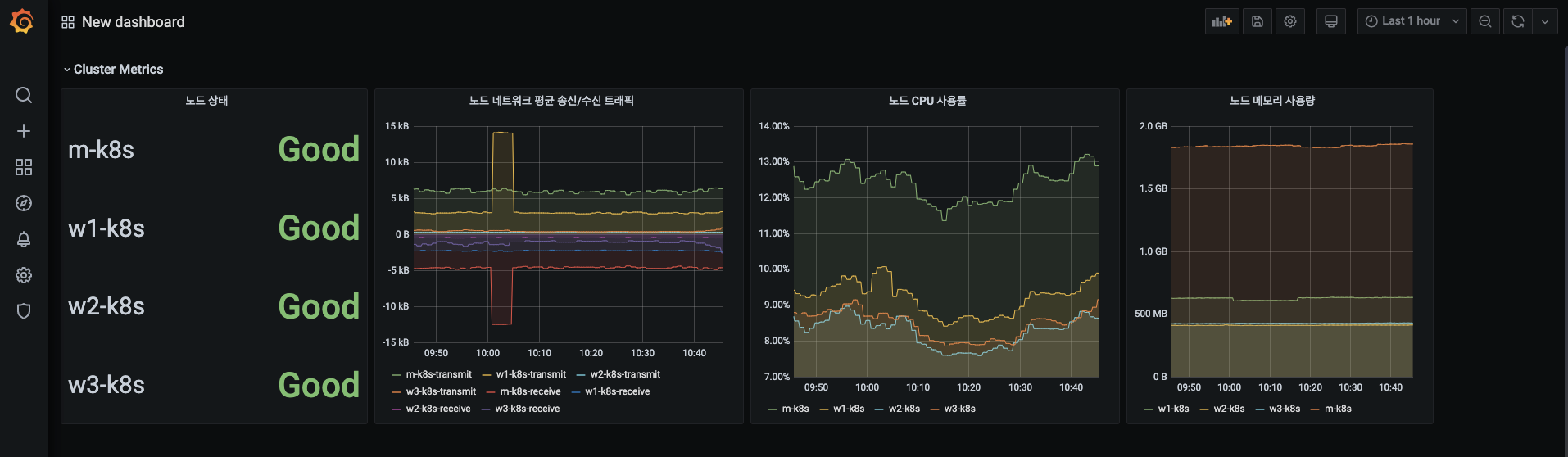
- 채널 확대/축소를 활용해보세요.
-
설정한 아코디언 메뉴가 정상 동작하는지 확인합니다. Cluster Metrics 메뉴를 눌러 정렬한 4개의 패널을 화면에서 숨겨봅시다.

-
Cluster Metrics가 다시 화면에 나타나게 해봅시다.
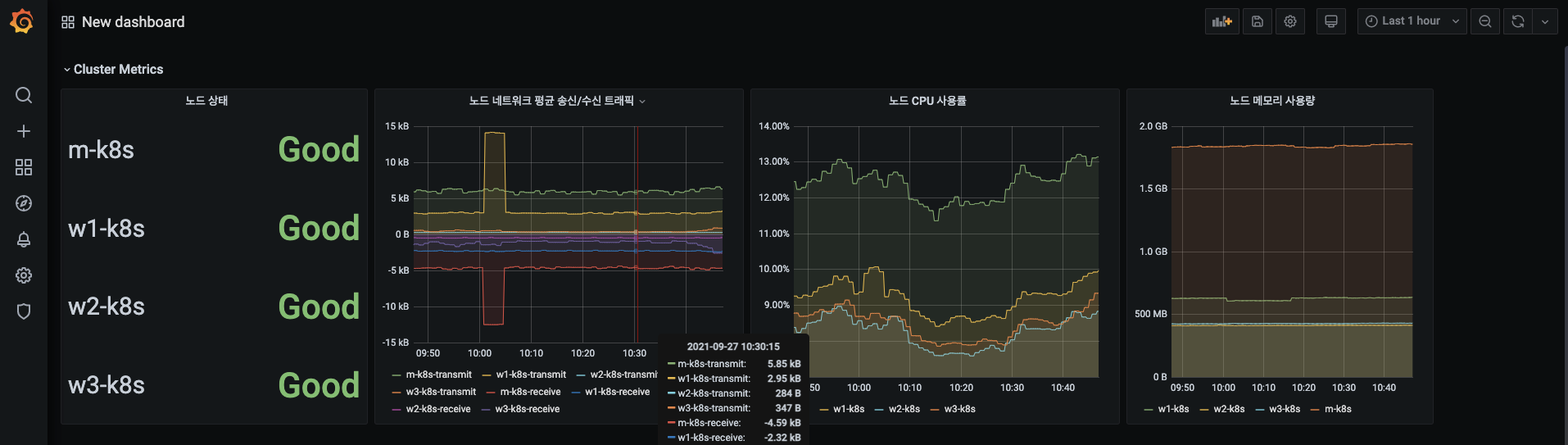
쿠버네티스 노드에 대한 메트릭을 시각화하는 방법을 살펴봤습니다.
다음으로 쿠버네티스 노드에서 동작하는 파드에 대한 시각화를 진행해볼까요~?
파드 메트릭 데이터 시각화하기
파드 메트릭의 시각화 방법은 노드 메트릭의 시각화와 동일합니다.
그런데 파드는 여러 개의 네임 스페이스에 존재하므로 사용자가 원하는 네임스페이스에 속한 파드만 확인할 수 있다면 편리하겠죠?
그라파나에서는 변수를 선언하고, 선언한 변수로 사용자가 원하는 내용만을 선별해 대스보드에서 확인할 수 있습니다.
헬름 차트처럼 사용자의 목적에 맞게 사용할 수 있는 대시보드를 구성해 보겠습니다.
조건별 파드 메트릭 데이터 시각화하기
-
화면 오른쪽 상단에서 톱니바퀴 모양의 Dashboard settings(대시보드 설정) 메뉴를 누릅니다.
-
대시보드 설정 화면이 나오면 Variables(변수) 메뉴를 누릅니다.
- Add variable 버튼을 눌러 변수를 추가합니다.
- Add variable 버튼을 눌러 변수를 추가합니다.
-
변수에 필요한 세부 설정을 합니다.
- Name : 대시보드에서 사용하는 변수 이름으로 여기서는 Namespace를 입력합니다. 대시보드에서
$Namespace로 변수를 사용할 수 있습니다. - Label : 대시보드에서 변수 선택 시 변수를 지칭하는 레이블입니다. 변수 이름과 같게 Namespace로 설정합니다.
- Data Source : 쿼리가 실행될 때 값을 받아오는 소스를 설정합니다. 노드 메트릭을 가지고 오는 곳과 동일하게 Prometheus를 선택합니다.
- Refresh : 변수를 읽어 들이는 방법을 설정합니다. 대시보드가 로드될 때마다 새로 읽어 들이도록 On Dashboard Load를 선택합니다.
- Query : 쿼리를 입력해 결과를 그라파나 변수로 사용하도록 추가합니다. 입력한 label_values(kube_pod_info, namespace) 에서 lable_values는 프로메테우스 플러그인에서 제공하는 함수로, 메트릭에 있는 특정 레이블의 값을 반환받을 수 있습니다. 현재 쿼리는 kube_pod_info의 namespace 값을 그라파나의
Namespace변수의 값으로 치환합니다. - Include All option : 모든 네임스페이스를 선택할 수 있는 옵션을 적용할지 말지 결정합니다. 스위치를 활성화하면 네임스페이스를 모두 선택할 수 있는 All 선택 옵션이 추가됩니다.
- Custom all value : Include All option에서 스위치를 활성화했을 때 추가되는 옵션으로, All 선택 옵션의 범위를 사용자가 지정할 수 있습니다.
.+를 설정하면 하나 이상의 값을 가진 것들을 선택할 수 있습니다.
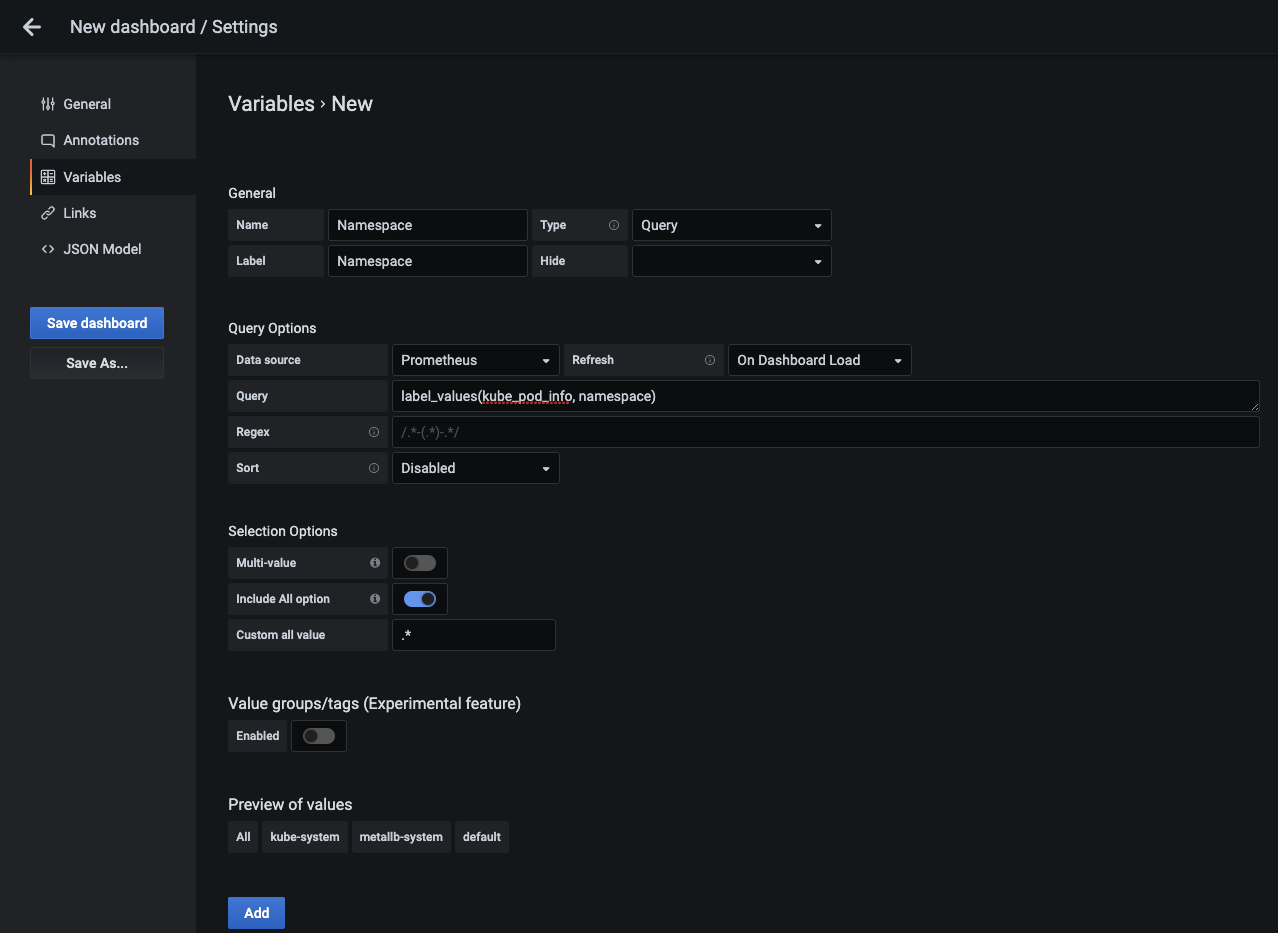
- 설정 항목을 모두 작성하면 변수로 사용할 수 있는 값이 Preview of values 항목 밑에 모두 표시됩니다. 이를 확인하고 Add 버튼을 눌러 변수 설정을 완료합니다.
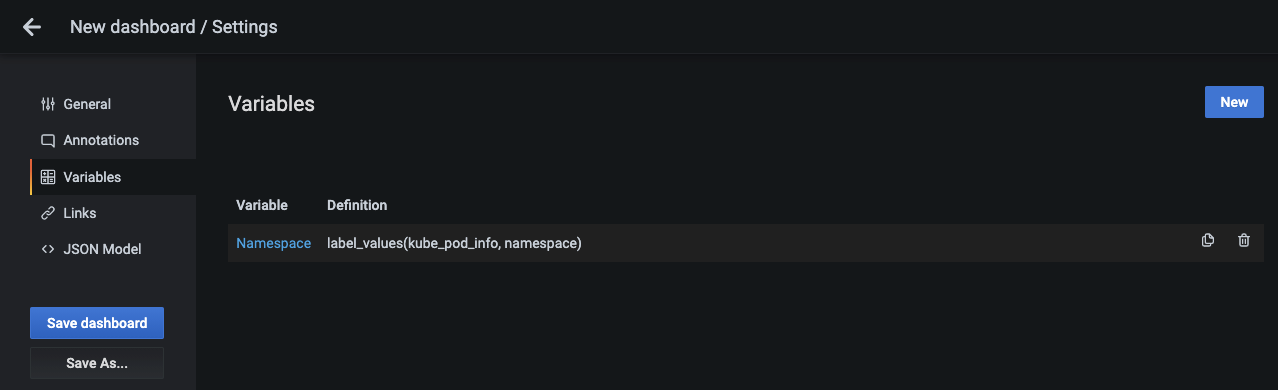
- Name : 대시보드에서 사용하는 변수 이름으로 여기서는 Namespace를 입력합니다. 대시보드에서
-
Namespace 변수가 추가됐으면 오른쪽 위에 있는 New 버튼을 눌러 네임스페이스 하위에 속한 파드를 변수로 추가합니다.
-
파드 변수를 추가하는 데 필요한 설정은 아래처럼 설정하고, 설정 항목은 Namespace 변수와 동일합니다.
- Name : Pod
- Label : Pod
- Data Source : Prometheus
- Refresh : On Dashboard Load
- Query : 대시보드에 설정돼 있는 Namespace 변수를 쿼리문에 포함하도록
label_values(kube_pod_info{namespace=~"$Namespace"}, pod)로 작성합니다. 이렇게 하면 네임스페이스에 속한 파드만 검색할 수 있습니다. - Include All option : 파드 변수도 스위치를 활성화합니다.
- Custom all value :
.+를 설정하면 하나 이상의 값을 가진 것들을 선택할 수 있습니다.
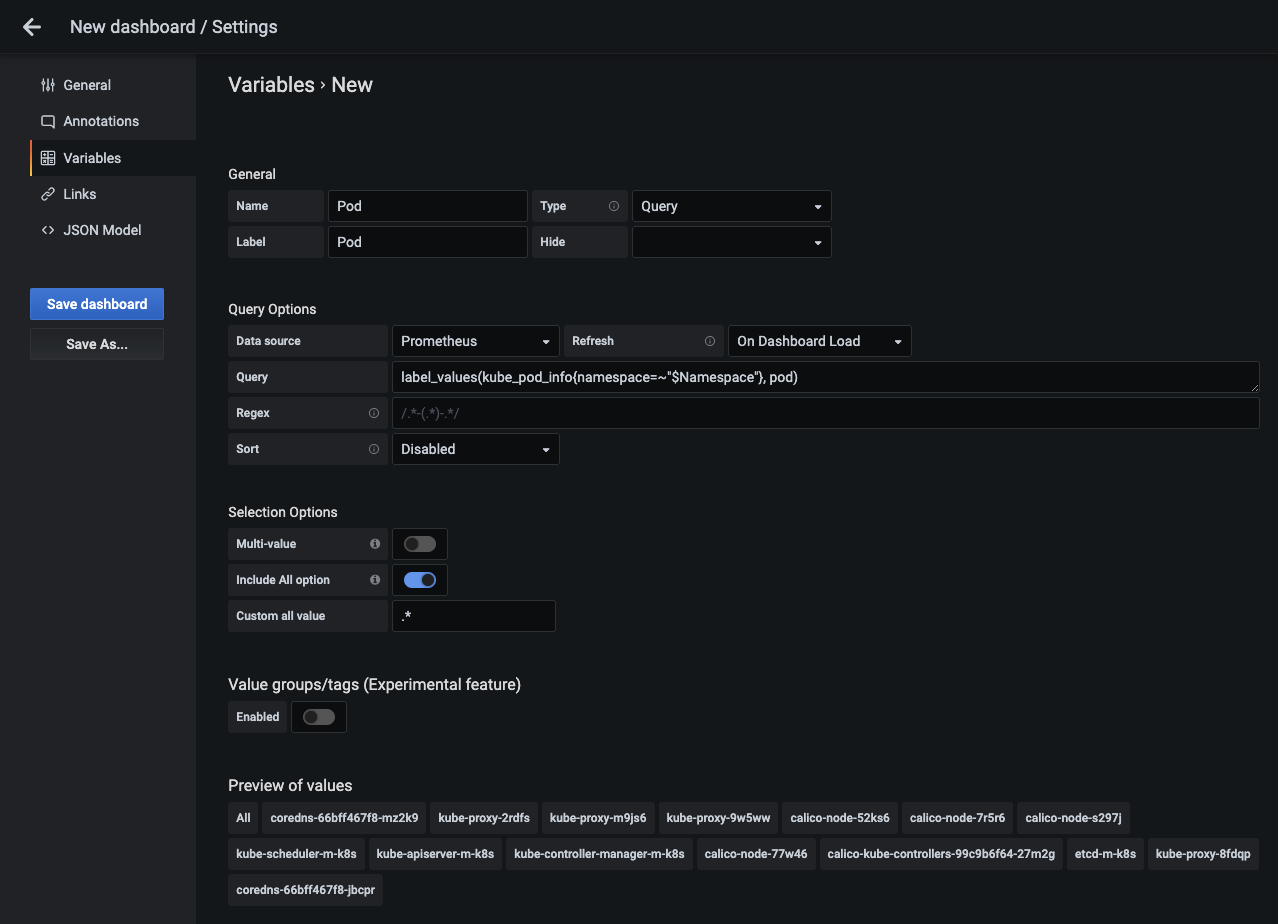
- 설정 항목을 모두 작성하면 변수로 사용할 수 있는 값이 Preview of values 항목 밑에 모두 표시됩니다. 이를 확인하고 Add 버튼을 눌러 변수 설정을 완료합니다.
-
파드 변수가 추가됐음을 확인한 후에 키보드의 ESC 키 또는 왼쪽 상단의 Go back 버튼을 눌러 대시보드 화면으로 이동합니다.
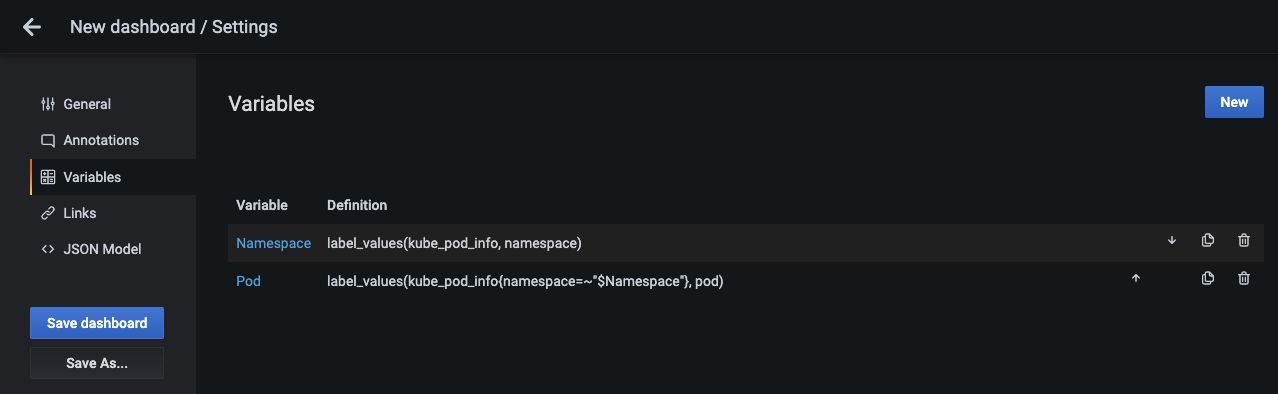
-
대시보드로 돌아가면 추가한 2개의 변수(Namespace, Pod)로 이루어진 선택 상자가 상단에 보입니다. 이제 사용자가 특정 네임스페이스와 파드를 선택할 수 있습니다.

-
이번에는 패널들을 행으로 정렬하는 아코디언 메뉴를 먼저 만들겠습니다.
- 아코디언 메뉴에 추가한 변수로 현재 확인하려는 내용을 선택하고 패널을 구현하겠습니다.
- Add panel > Conver to row 순서로 버튼을 누릅니다.
-
생성한 아코디언 메뉴의 제목을 $Namespace Namespace Metrics로 입력해 사용자가 선택한 네임스페이스 이름을 표시합니다.
-
kube-system Namespace Metrics(kube-system은 선택된 네임스페이스 이름)로 변경된 아코디언 메뉴 타이틀을 확인하고, 아코디언 메뉴를 아래로 내립니다.
- 제목의 오른쪽 끝에 있는 점자를 마우스 왼쪽 버튼을 누른 상태로 끌어내리면 됩니다.
- 제목의 오른쪽 끝에 있는 점자를 마우스 왼쪽 버튼을 누른 상태로 끌어내리면 됩니다.
-
파드 메트릭을 시각화하기 위한 패널을 추가하겠습니다. Add panel > + Add new panel 버튼을 누릅니다.
-
추가한 패널에 대시보드에 선언한
$Namespace변수와$Pod변수를 포함해 다음과 같이 입력합니다.- 패널 제목 : $Pod Pod CPU 사용률
- 메트릭 :
sum(rate(container_cpu_usage_seconds_total{namespace=~"$Namespace", pod=~"$Pod", container!=""}[5m])) by (pod) - 범례 : {{ pod }}
- Y축 단위 : Misc > percent(0.0-1.0)
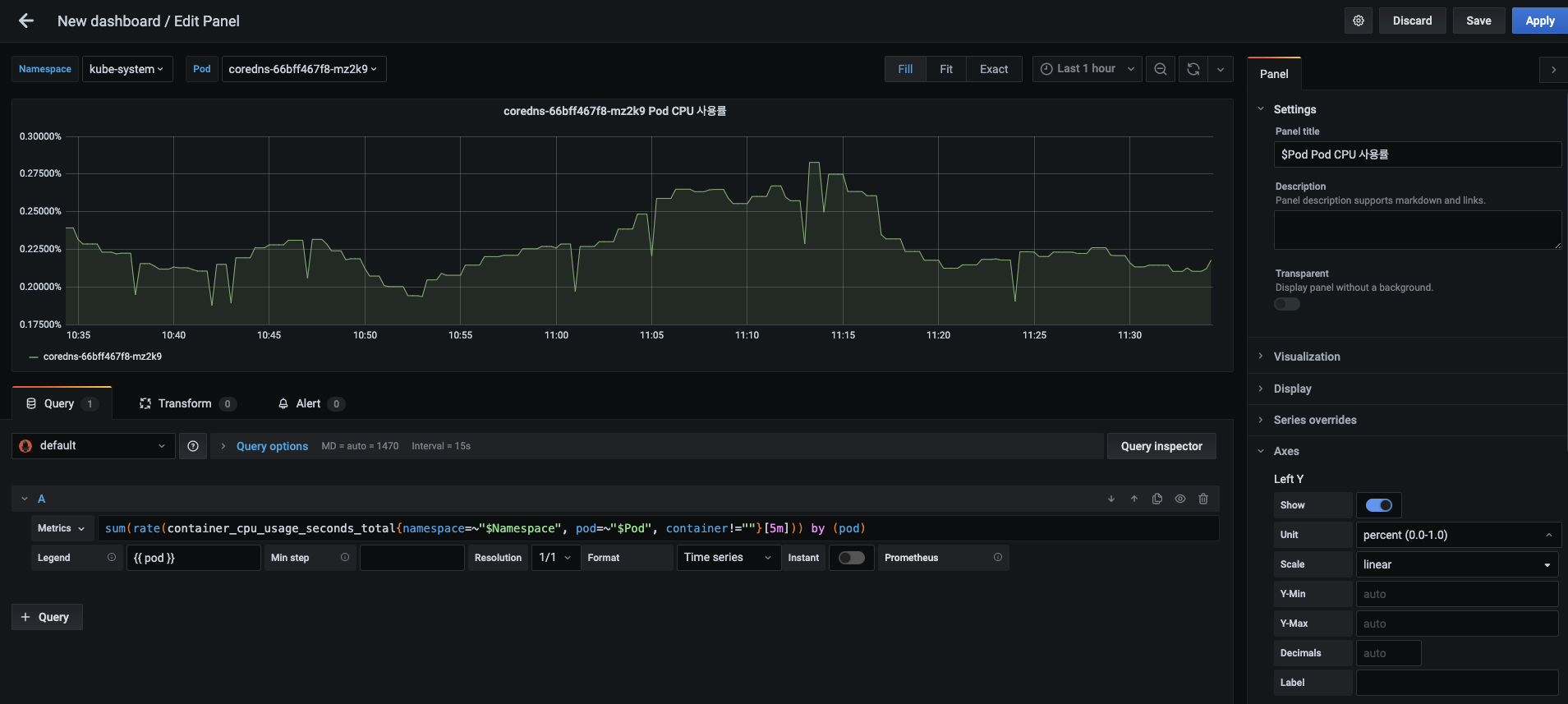
- 파드 메트릭을 수집하기 위한 PromQL은 다소 복잡해 보이지만 실제로 그리 어렵지 않습니다. 네임스페이스와 파드에 All이라는 변수가 선택되면
.+정규 표현식이 값으로 들어가므로=~를 사용해 이를 인식하게 합니다. 그리고 container 레이블이 없는 메트릭은, 파드 내에 있는 (모든)컨테이너의 총 CPU 사용 시간을 나타냅니다. 따라서 이를 포함하면 2배의 CPU 사용률이 계산되므로!=를 사용해 제외합니다. - 설정이 끝나면 오른쪽 상단에 있는 Apply 버튼을 눌러 적용합니다. 대시보드에 생성된 Pod CPU 사용률 패널을 확인합니다.
-
Add panel > + Add new panel 버튼을 누릅니다. Pod 메모리 사용량 패널을 설정하기 위해 다음의 내용을 입력합니다. 설정이 끝나면 Apply로 적용합니다.
- 패널 제목 : $Pod Pod 메모리 사용량
- 메트릭 :
sum(container_memory_usage_bytes{namespace=~"$Namespace", pod=~"$Pod", container!=""}) by (pod) - 범례 : {{ pod }}
- Y축 단위 : Data (Metric) > bytes(Metric)
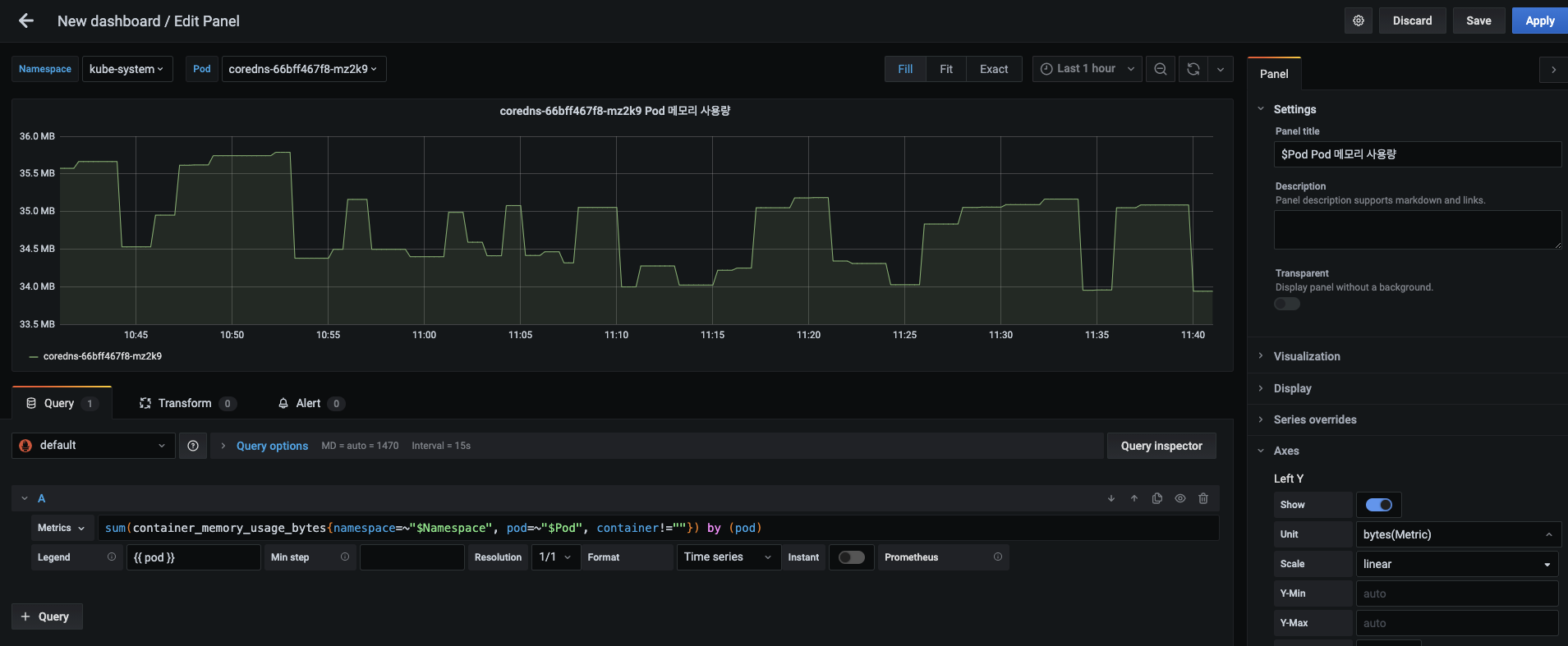
-
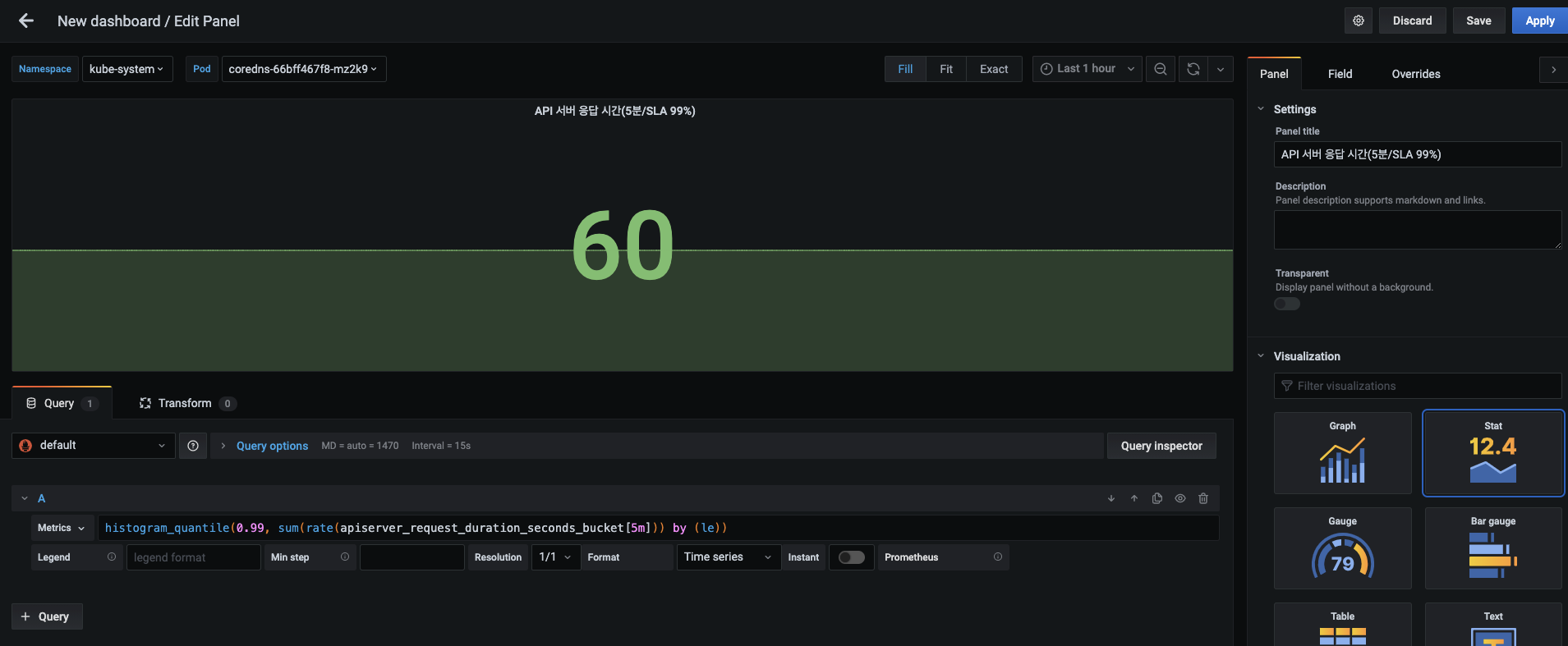
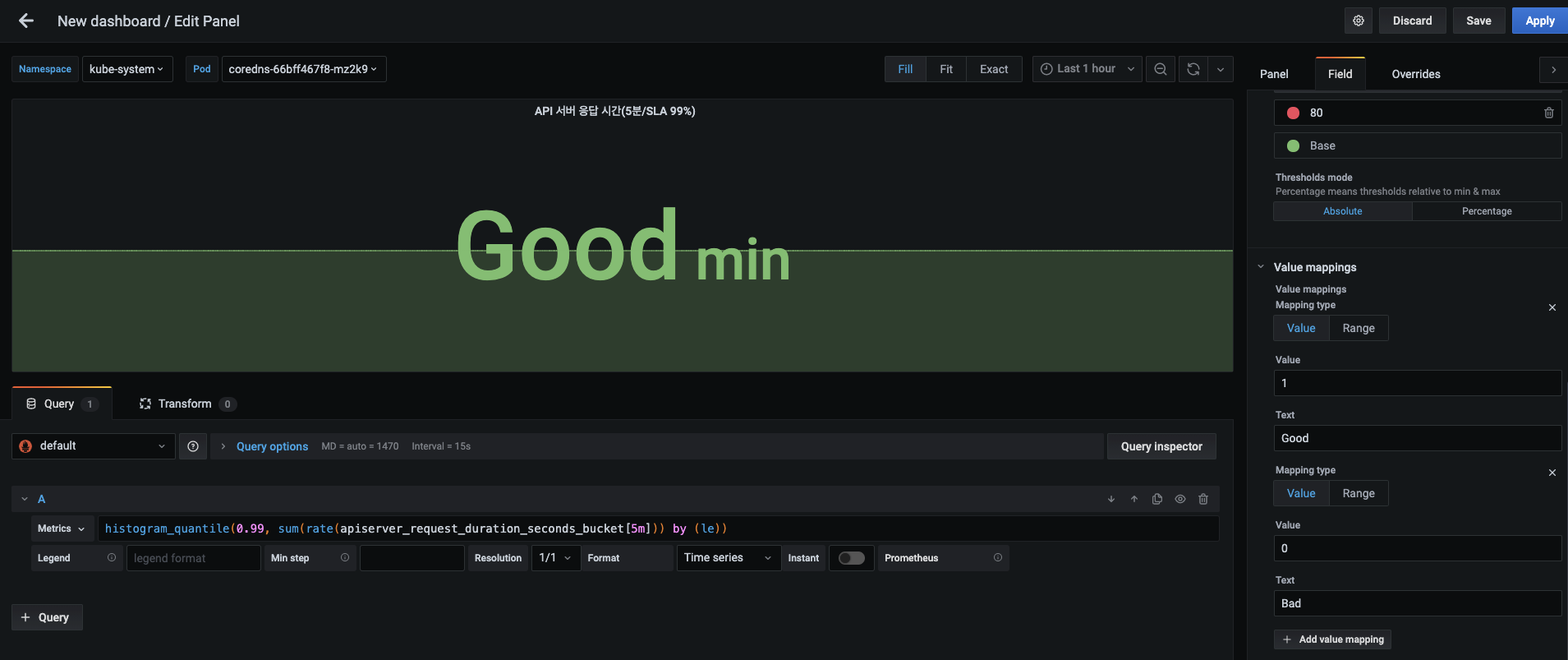
다음으로 API 서버 응답 시간을 측정하기 위한 패널을 추가합니다. 패널에 다음 내용을 설정합니다.
- 패널 제목 : API 서버 응답 시간(5분/SLA 99%)
- 메트릭 :
histogram_quantile(0.99, sum(rate(apiserver_request_duration_seconds_bucket[5m])) by (le)) - 시각화 : Stat
- 설정이 끝나면 패널에 60이라는 숫자가 표시됩니다.
SLI, SLO, SLA
사이트 신뢰성 엔지니어링(SRE, Site Reliability Engineering) 영역에서는 서비스 수준 지표(SLI, Service Level Indicator)를 기준으로 서비스 수준 목표(SLO, Service Level Objective)를 산정할 수 있습니다.
예를 들어 API 서버에 대한 요청으로부터 응답 시간(SLI)이 2분 이내여야 한다는 목표(SLO)가 있다면 응답 시간 5분 지연 시 월 서비스 사용료에서 2%를 할인한다는 서비스 수준 계약(SLA, Service Level Agreement)를 체결할 수 있습니다.
SLA를 적용함으로써 서비스 제공자는 서비스의 범위를 정할 수 있고, 사용자는 SLA를 기준으로 서비스 품질을 정량적으로 측정할 수 있습니다.
-
60이 초를 나타냄을 알 수 있게 단위를 넣습니다.
- 패널 탭 오른쪽의 필드 탭에서 Standard options 항목의 Unit을 Time > seconds(s)로 설정합니다. 해당 값이 60초 이상일 때 그라파나에서 자동으로 계산해 분(minutes)으로 변경합니다.
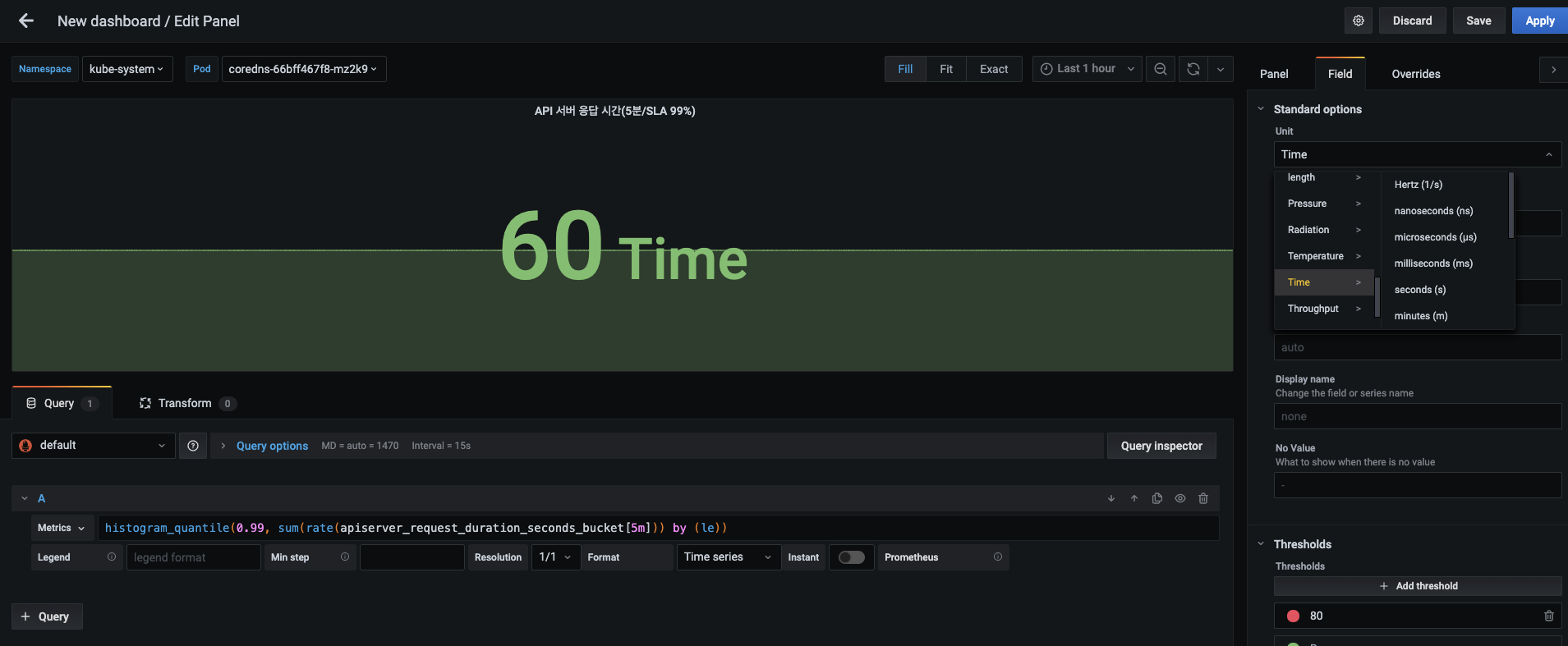
- 패널 탭 오른쪽의 필드 탭에서 Standard options 항목의 Unit을 Time > seconds(s)로 설정합니다. 해당 값이 60초 이상일 때 그라파나에서 자동으로 계산해 분(minutes)으로 변경합니다.
-
측정 단위로 분으로 자동 변경되면 그라파나에서는 현재 표시되는 값을 1에 매핑돼 있는 Good 문자열로 변경합니다.
- 따라서 정확한 표현을 위해 그림처럼 매핑돼 있는 1과 0에 대한 설정을 모두 삭제합니다.
- 현재 매핑돼 있는 값인 1과 0은 기본으로 제공되는 값이 아니라 노드 상태에서의 설정한 상태 값을 기억하고 있어서 생기는 문제입니다.
- 2개의 값을 삭제하고나면 Apply 버튼을 눌러 현재의 설정을 적용합니다.
-
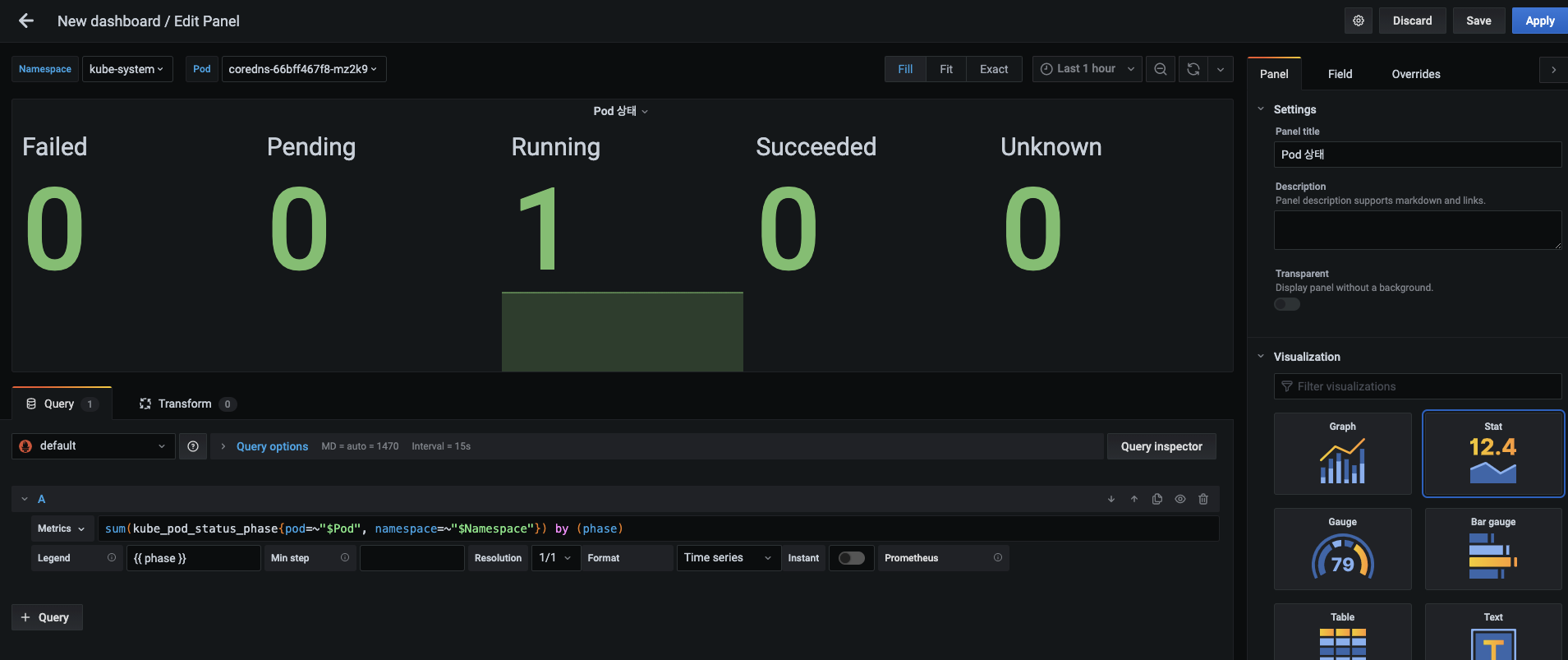
생성된 API 서버 응답 시간 패널을 확인하고, 마지막 패널인 Pod 상태 확인 패널을 추가합니다.
- Pod 상태 패널을 다음과 같이 설정합니다.
- 패널 제목 : Pod 상태
- 메트릭 :
sum(kube_pod_status_phase{pod=~"$Pod", namespace=~"$Namespace"}) by (phase) - 범례 : {{ phase }}
- 시각화 : Stat
-
현재도 파드 상태를 확인할 수 있지만, 대시보드의 공간을 적게 소모하기 위해 표시되는 상태 값을 수평으로 나열하겠습니다.
- Panel 탭의 Display 항목에서 Orientation을 Horizontal로 선택하고, Apply 버튼으로 적용합니다.
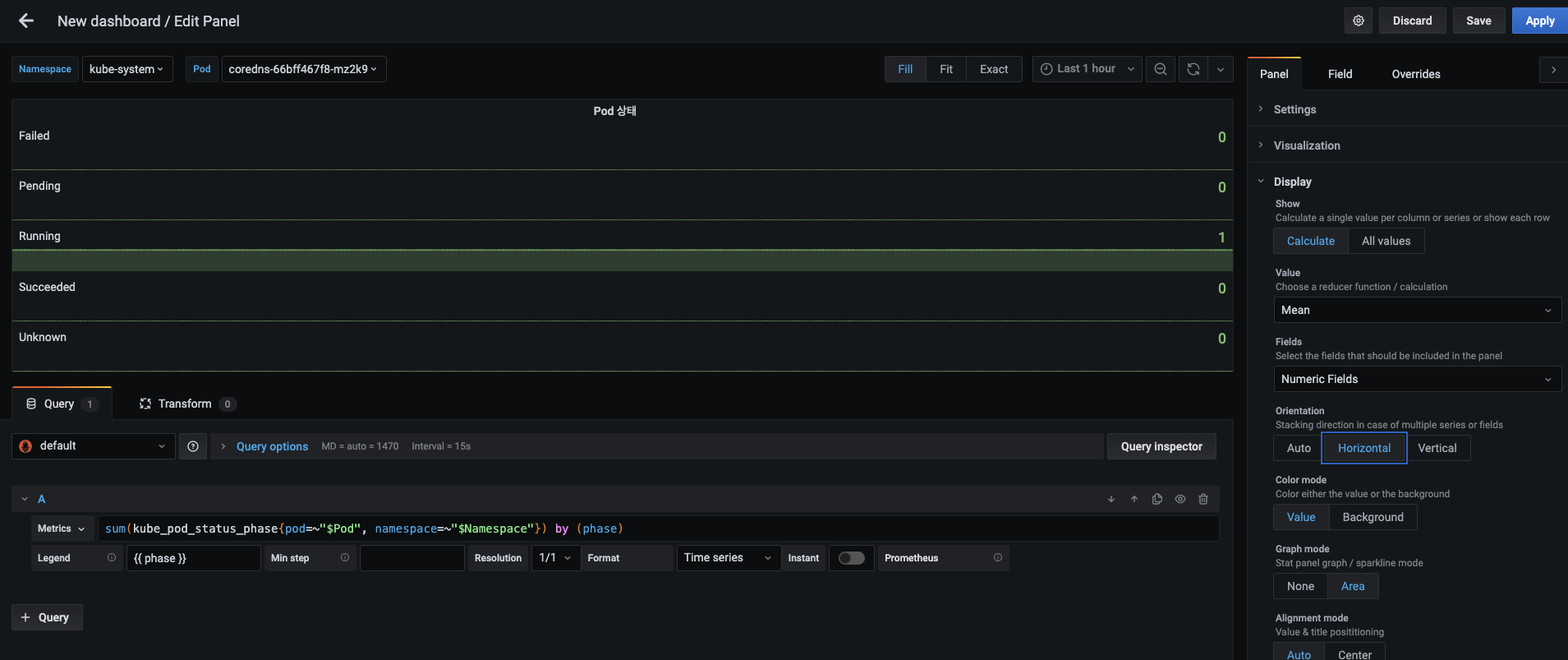
- Panel 탭의 Display 항목에서 Orientation을 Horizontal로 선택하고, Apply 버튼으로 적용합니다.
-
대시보드에서 추가된 Pod 상태 패널을 확인합니다.
-
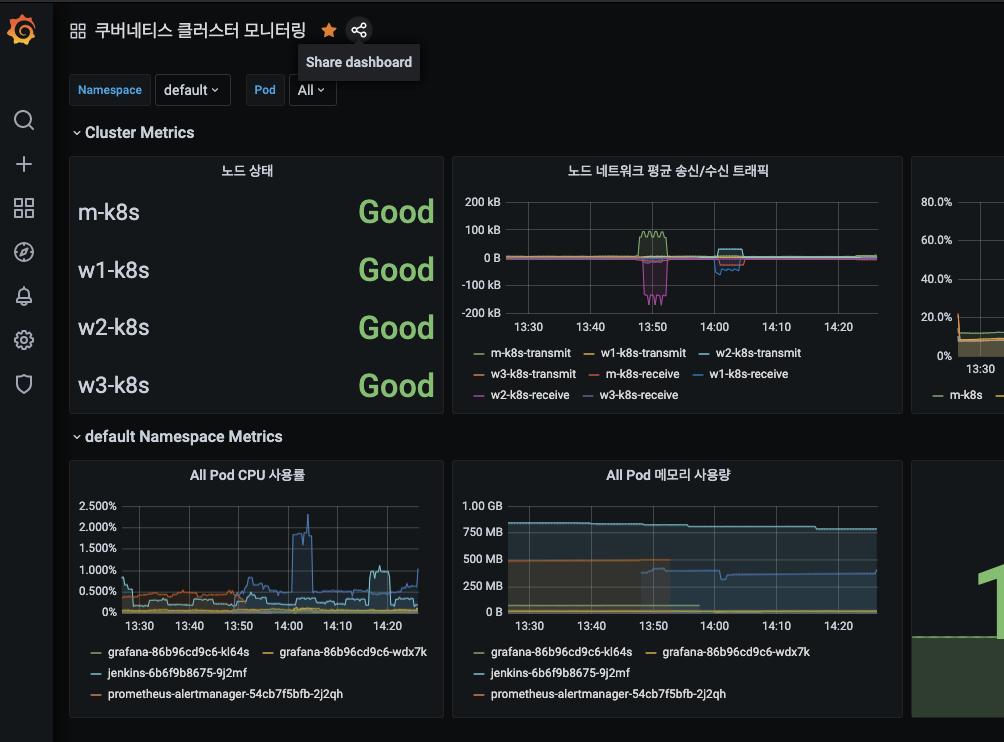
지금까지 만든 4개 패널(Pod CPU 사용률, Pod 메모리 사용량, API 서버 응답 시간, Pod 상태)을 패널 이동과 확대/축소를 사용해 다음과 같은 형태로 구성한 후 Namespace Metrics 아코디언 메뉴 아래로 옮깁니다.
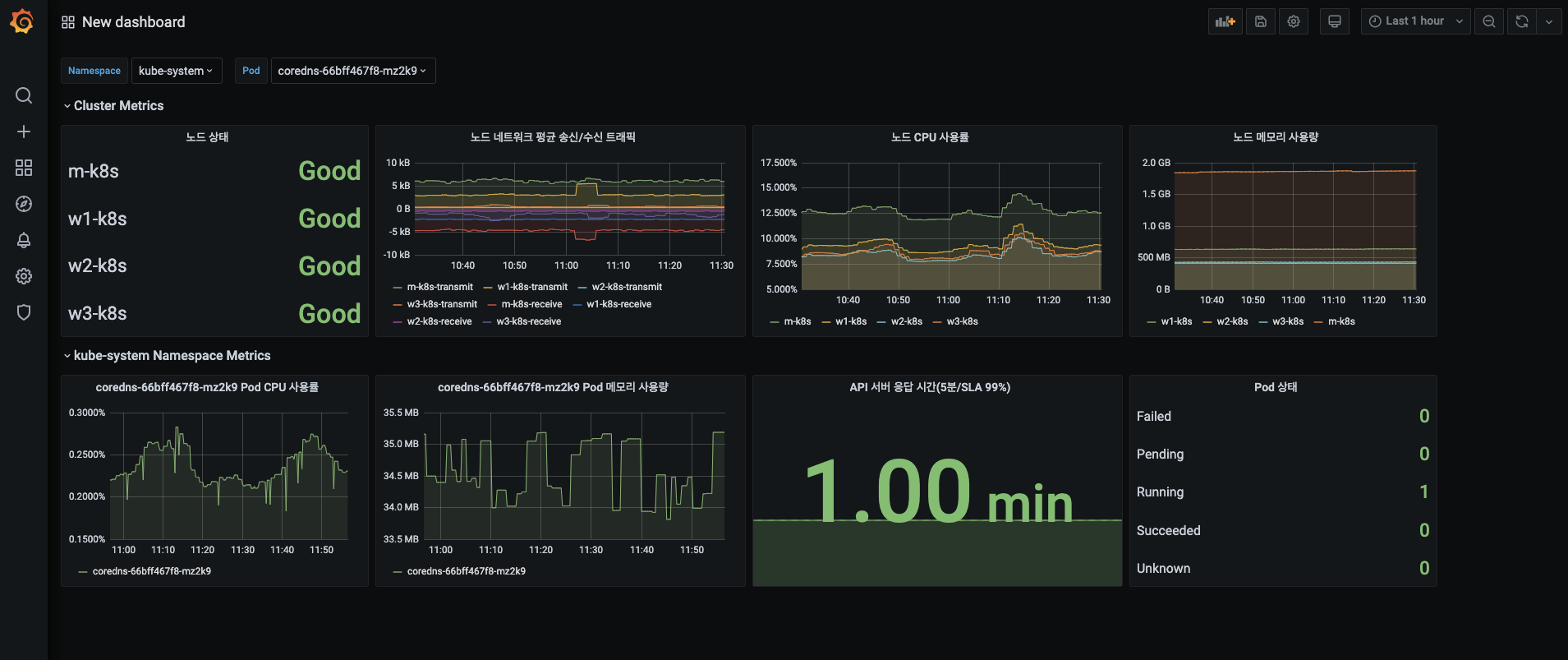
-
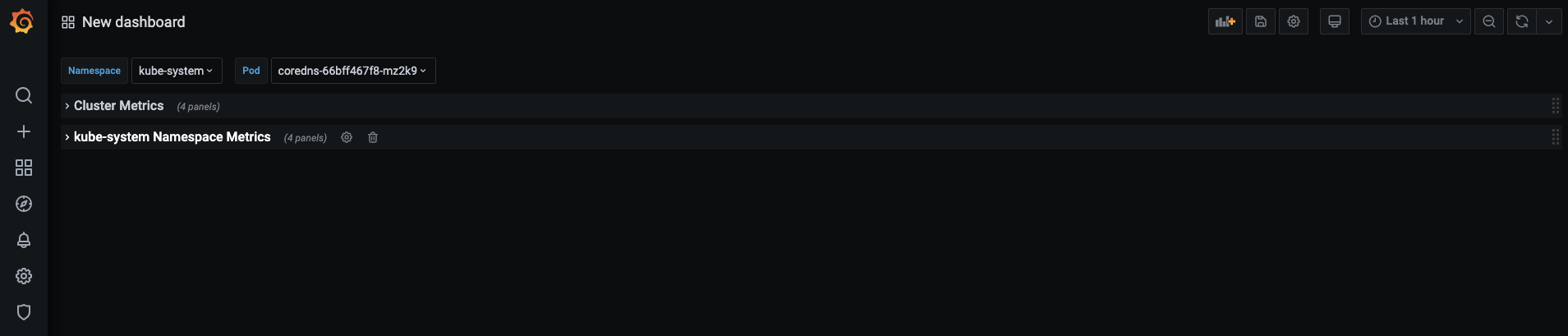
아코디언 메뉴가 제대로 동작하는지 확인합니다. 아코디언 메뉴를 접은 후에 제목 옆에 4 panels라는 문구가 보이면 다시 아코디언 메뉴를 클릭해 패널들을 볼 수 있습니다.
-
변수가 정상적으로 선택되고 동작되는지도 확인합니다.
- 변수 선택 상자에서 Namespace는 default를, 파드는 All을 고르고, 이에 해당하는 파드들이 시각화되는지 확인합니다.
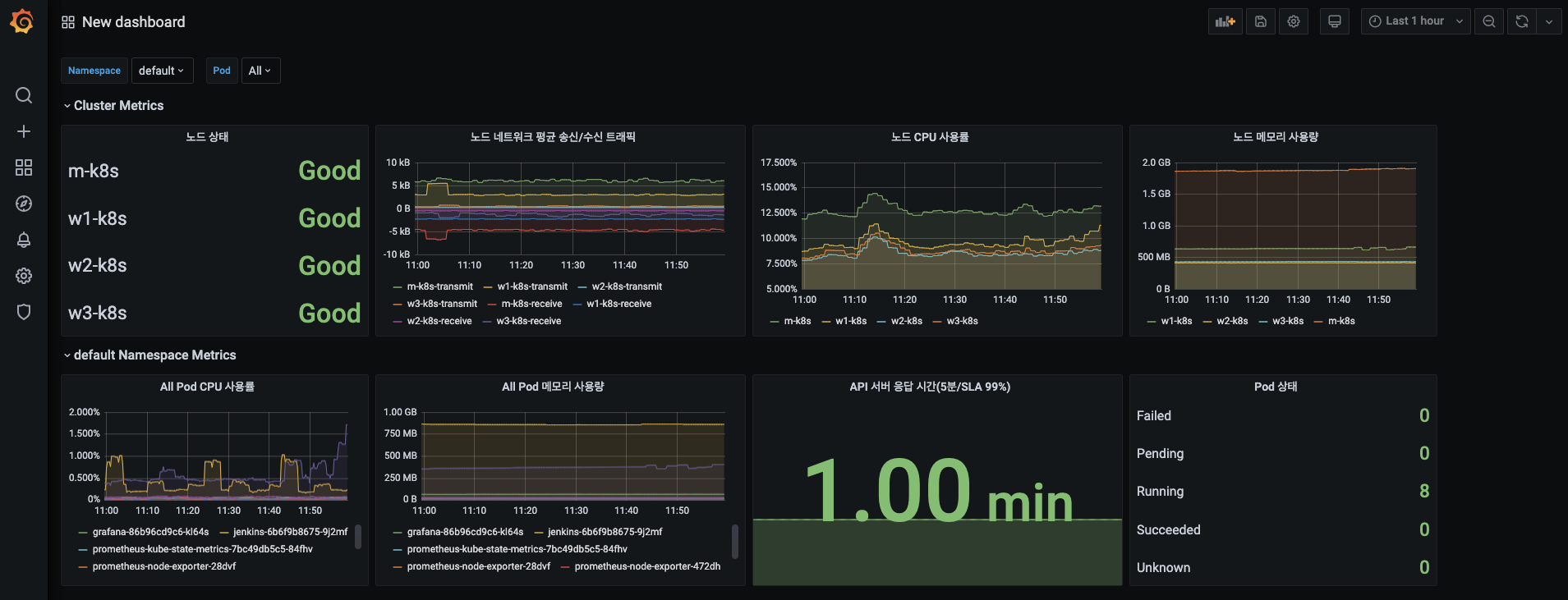
- 변수 선택 상자에서 Namespace는 default를, 파드는 All을 고르고, 이에 해당하는 파드들이 시각화되는지 확인합니다.
-
오른쪽 상단에 있는 Save dashboard(대시보드 저장) 버튼을 누릅니다.
- 대시보드 이름을 쿠버네티스 클러스터 모니터링으로 입력하고 Save 버튼을 눌러 현재 대시보드 설정을 저장합니다.
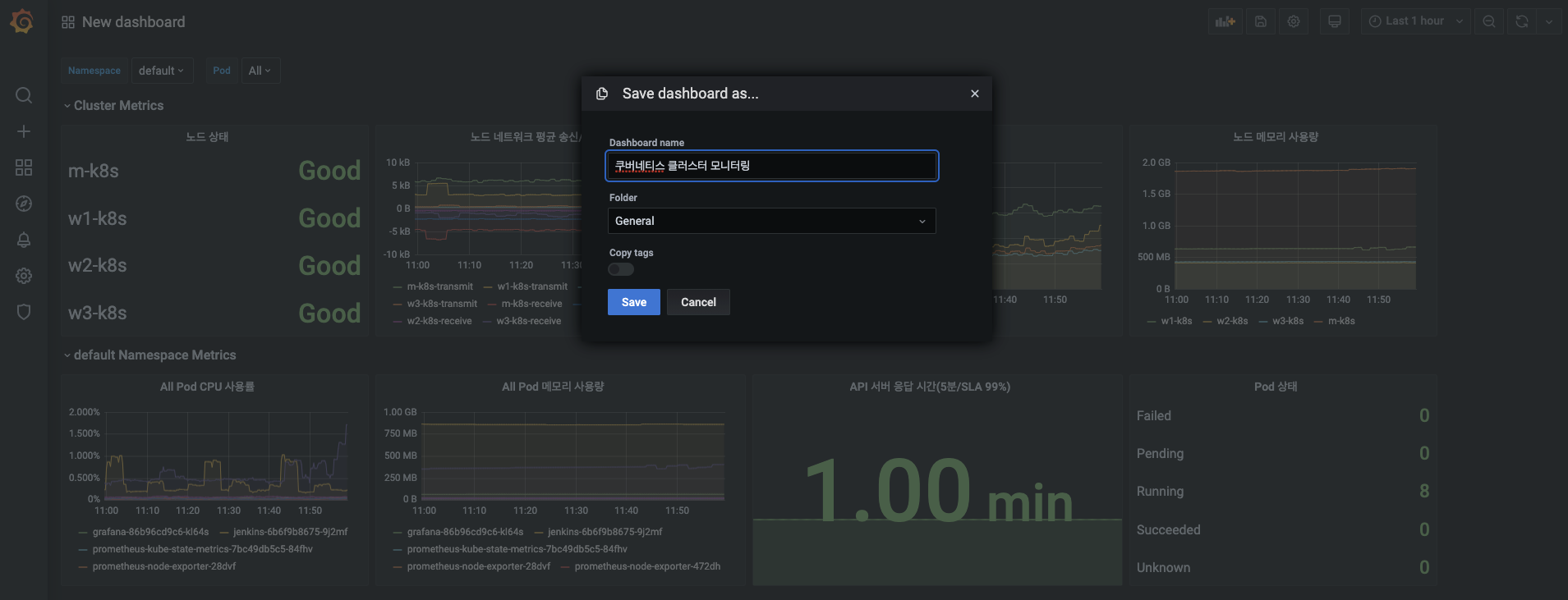
- 대시보드 이름을 쿠버네티스 클러스터 모니터링으로 입력하고 Save 버튼을 눌러 현재 대시보드 설정을 저장합니다.
-
대시보드가 저장됐다는 메세지를 확인하면 왼쪽 상단에 그라파나 로고를 클릭해 그라파나 홈 화면으로 돌아갑니다.
-
그라파나 홈 화면에서 쿠버네티스 클러스터 모니터링 대시보드를 확인하고, 제목을 눌러 다시 대시보드에 진입합니다.
-
대시보드에 진입하면 해당 시점에 메트릭 데이터들을 시각화하는지 화면에 표시되는 수집 시간을 확인합니다.
- 현재 12:02분인데 12:01분 시점의 메트릭이 시각화 되어있는 것이 보이는군요!
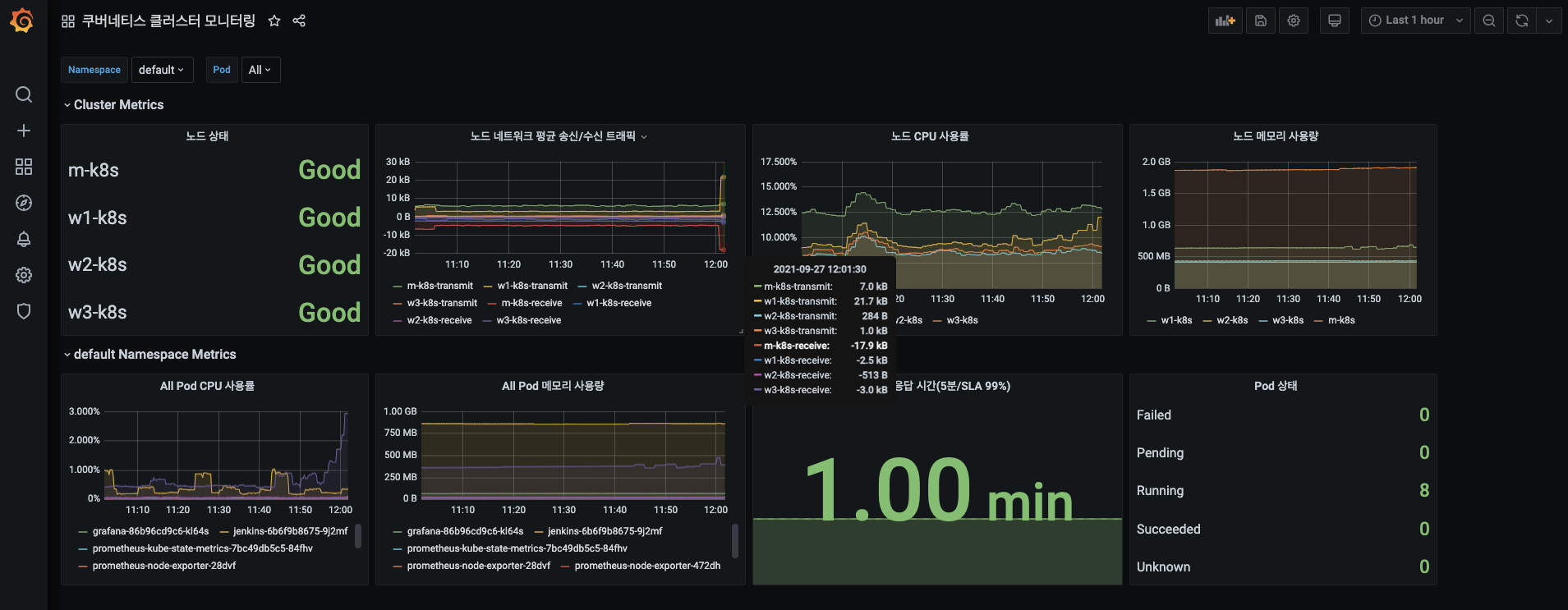
- 현재 12:02분인데 12:01분 시점의 메트릭이 시각화 되어있는 것이 보이는군요!
-
현재의 대시보드는 메트릭 데이터를 주기적으로 수집하지 않습니다.
- 따라서 주기적으로 수집되는 메트릭 데이터를 보고 싶다면 오른쪽 상단에 있는 Refresh dashboard(대시보드 새로고침) 버튼 옆의 드랍다운 메뉴를 눌러 수집 주기를 선택합니다.
- 한 번만 수집하고 싶다면 Refresh dashboard 버튼을 누르면 됩니다.
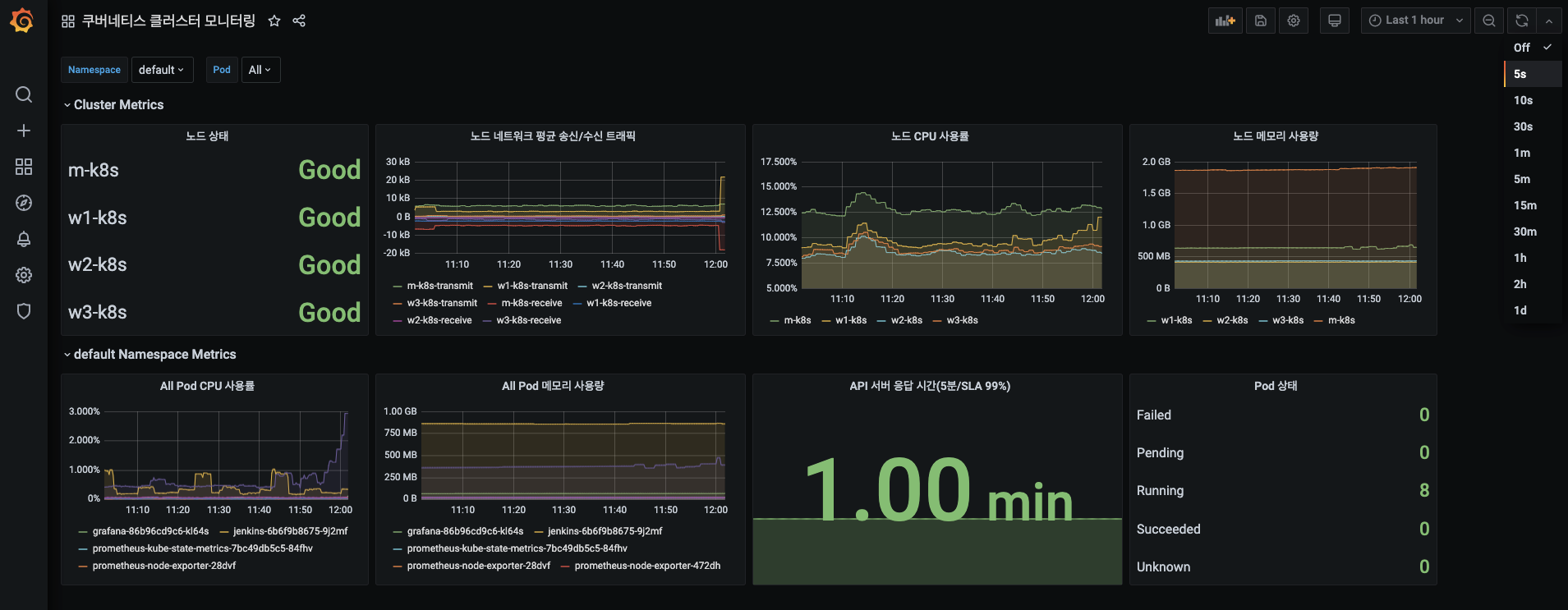
-
수집 주기가 변경됐는지 확인하고 다음 진행을 위해 그라파나 홈 화면으로 돌아갑니다.
- 5초 간격으로 그래프가 갱신되는군요! 실시간으로 관찰하기 아주 좋습니다.
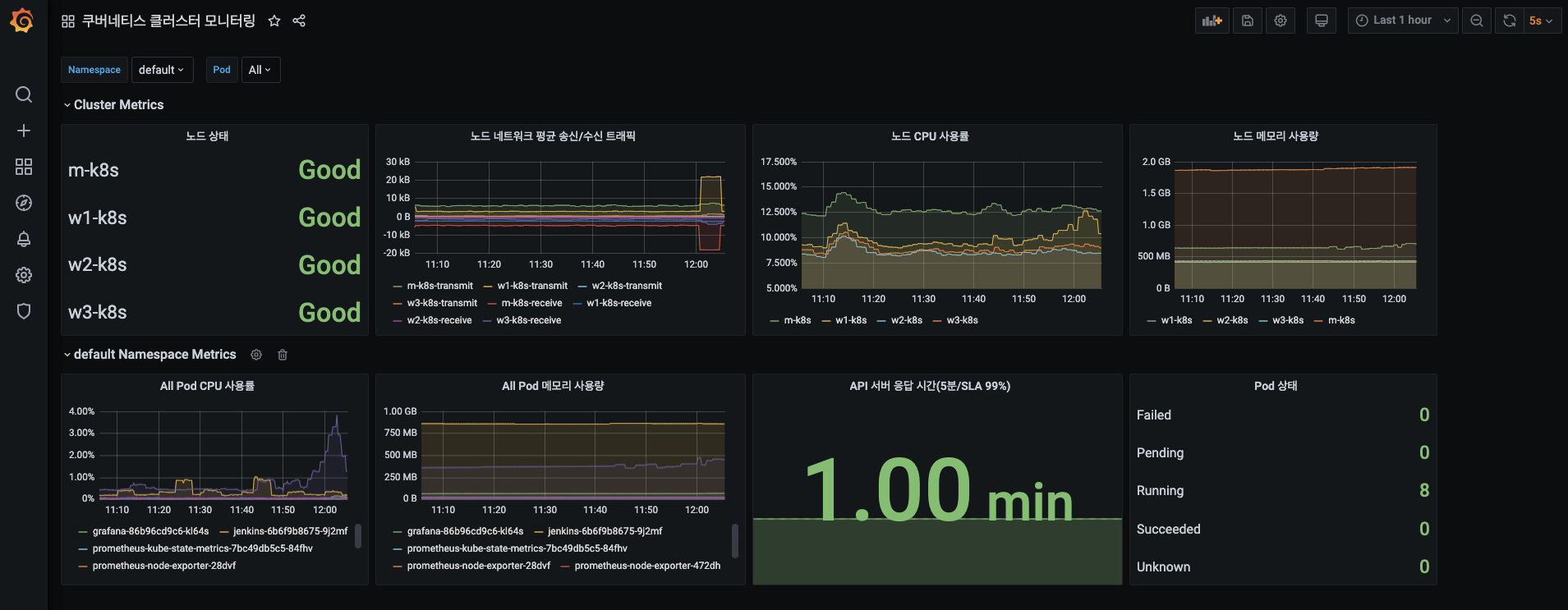
- 5초 간격으로 그래프가 갱신되는군요! 실시간으로 관찰하기 아주 좋습니다.
그라파나를 설치하고 그라파나 대시보드를 구성해 봤습니다.
대시보드는 일반적으로 큰 화면에 띄우고 모니터링하지만, 사람이 항상 지켜볼 순 없습니다.
경보 시스템이 있어서 이상 징후를 감지하고 알려줄 수 있다면 매우 유용하겠죠?
다음 절에서는 마지막으로 경보 시스템을 추가해 봅시다!
좀 더 견고한 모니터링 환경 만들기
프로메테우스와 그라파나로 쿠버네티스 시스템을 모니터링하는 방법은 간편하고 효과적입니다.
그라파나 대시보드를 사람이 항상 관찰할 수 없으니 시스템에서 이상 신호를 감지하고 메세지를 받게 하겠습니다.
또한 대시보드를 다른 사용자에게 전달해 그라파나 대시보드와 패널을 작성하는 방법을 알지 못해도 보드 사용할 수 있게 합니다.
또한 이미 만들어진 대시보드를 추가해 바로 사용할 수 있는 방법을 알아보겠습니다.
얼럿매니저로 이상 신호 감지하고 알려주기
대시보드는 설정된 모든 상태를 확인할 때는 효율적인 도구이지만,
특정 내용을 감지해서 따로 알려주지 않기 때문에 직접 확인해야 하는 비효율적인 면이 있습니다.
현재 시스템에서 사용자가 이상 신호가 담긴 경보 메세지를 받으려면
그라파나의 얼럿 메뉴 또는 프로메테우스의 얼럿매니저로 수신해야 합니다.
그라파나 얼럿 메뉴는 오직 시각화 그래프에만 존재하기 때문에 제한적으로 사용해야 하고,
메세지를 다양한 형태로 보낼 수 없다는 단점이 있습니다.
따라서 이 포스팅에선 프로메테우스의 얼럿매니저로 경보 메세지를 받겠습니다.
경보 메세지를 받을 슬랙 앱 설정하기
프로메테우스의 경보 메세지를 받으려면 메세지를 받아줄 메신저 앱이 필요합니다.
이전 포스팅에서 구성한 슬랙으로 프로메테우스의 경보 메세지를 받게 구성하는데,
이번에는 슬랙 앱을 설정하면서 동시에 슬랙 채널도 만들겠습니다.
-
프로메테우스 경보 메세지를 받기 위한 구성을 시작합니다.
- 슬랙을 열고 상단의 워크스페이스 설정 메뉴를 누릅니다.
- 설정 및 관리 > 앱 관리 메뉴를 선택합니다.
-
슬랙 앱의 검색 창에 webhook을 입력합니다.
- 웹훅(슬랙에서는 웹후크라고 통칭)은 경보 또는 CI 시작과 같은 특정 이벤트가 발생할 떄 발생한 이벤트를 지정한 대상에 전달하는 앱입니다.
- 웹훅(슬랙에서는 웹후크라고 통칭)은 경보 또는 CI 시작과 같은 특정 이벤트가 발생할 떄 발생한 이벤트를 지정한 대상에 전달하는 앱입니다.
-
검색된 슬랙 앱 중에서 수신 웹후크를 선택합니다.
- Slack에 추가 버튼을 눌러 수신 웹후크를 슬랙에 추가합니다.
- Slack에 추가 버튼을 눌러 수신 웹후크를 슬랙에 추가합니다.
-
화면 중간쯤에 작게 보이는 새 채널 생성을 눌러 수신 웹후크 앱이 보내주는 경보 메세지를 받을 채널을 생성합니다.
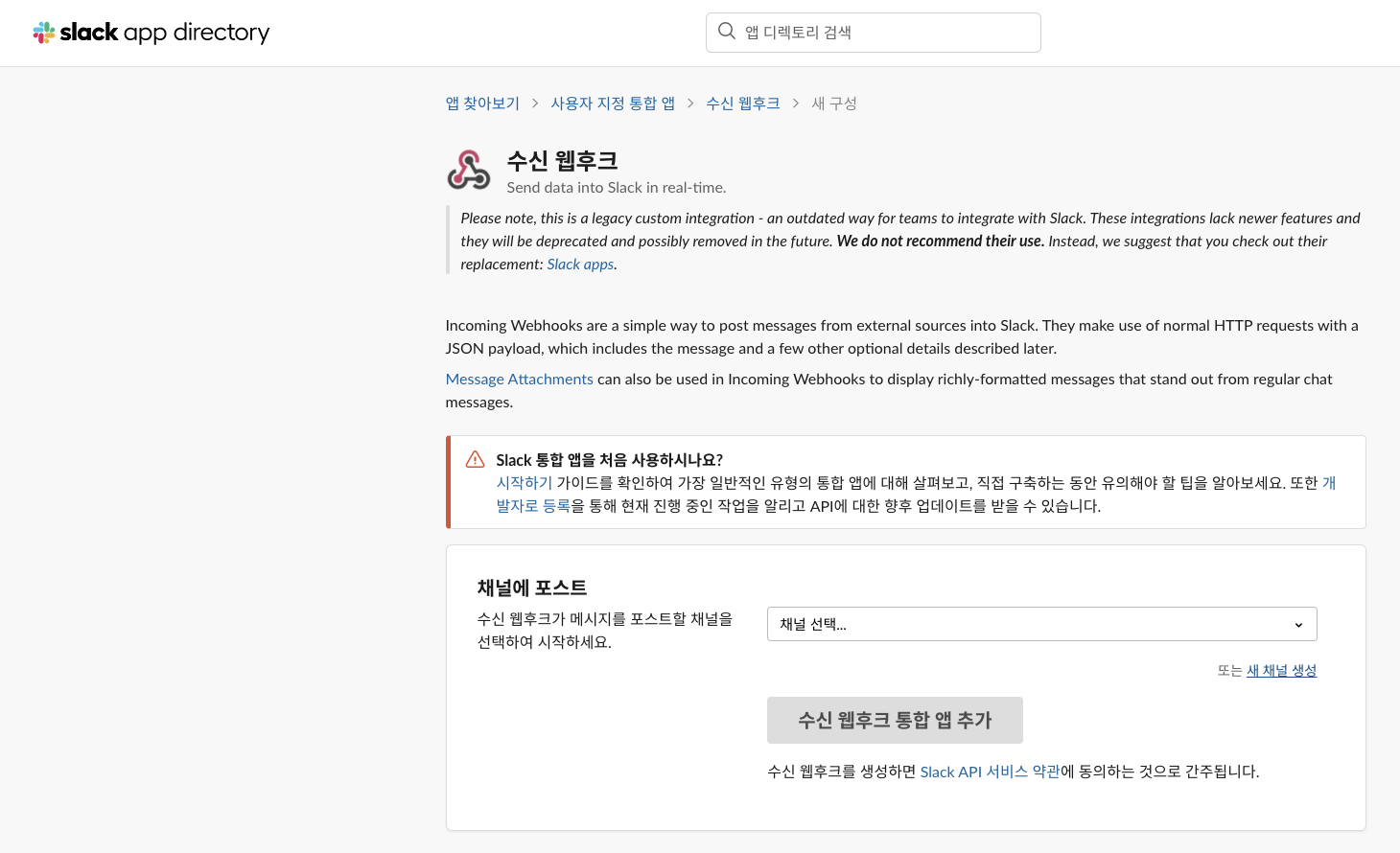
-
채널 생성에 필요한 정보를 입력하는 대화 상자가 나타납니다.
- 이름에는
k8s-node-notice를 작성합니다. - 설명에는 쿠버네티스 노드의 이상 신호를 알려줍니다. 를 입력합니다.
- 입력이 끝나면 생성 버튼을 누릅니다.
- 이름에는
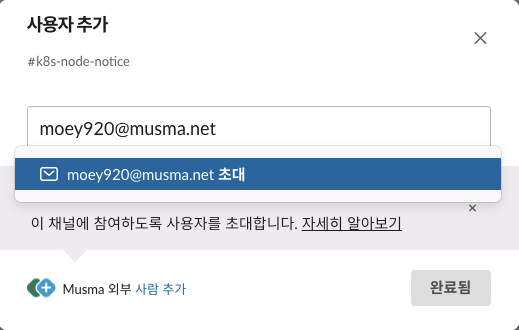
-
사용자를 추가하고 완료됨 버튼을 누릅니다.
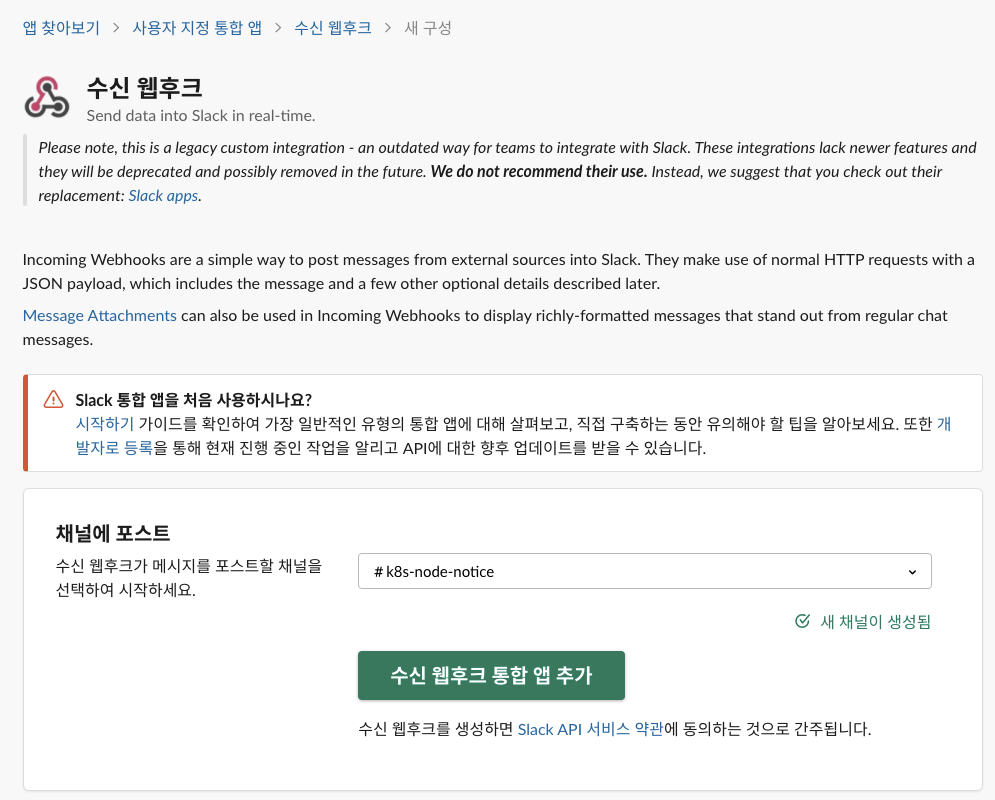
-
'새 채널이 생성됨' 메시지와 추가된 k8s-node-notice 슬랙 채널을 확인합니다. 수신 웹후크 통합 앱 추가 버튼을 눌러 슬랙 앱을 현재 설정한 슬랙 채널인 k8s-node-notice와 연결합니다.
-
수신 웹후크에 설정된 고유한 웹후크 URL을 확인합니다. 웹후크 URL은 사용자 채널마다 모두 다르게 생성됩니다.
- 얼럿매니저 설정에서 웹후크 URL을 사용하니 메모해 두세요.
https://hooks.slack.com/services/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- 프로메테우스의 얼럿매니저에서 고유의 웹후크 URL로 경보 메세자를 보내면 수신 웹후크에서 해당 경보 메세지를 슬랙 채널로 보내는 구조입니다.
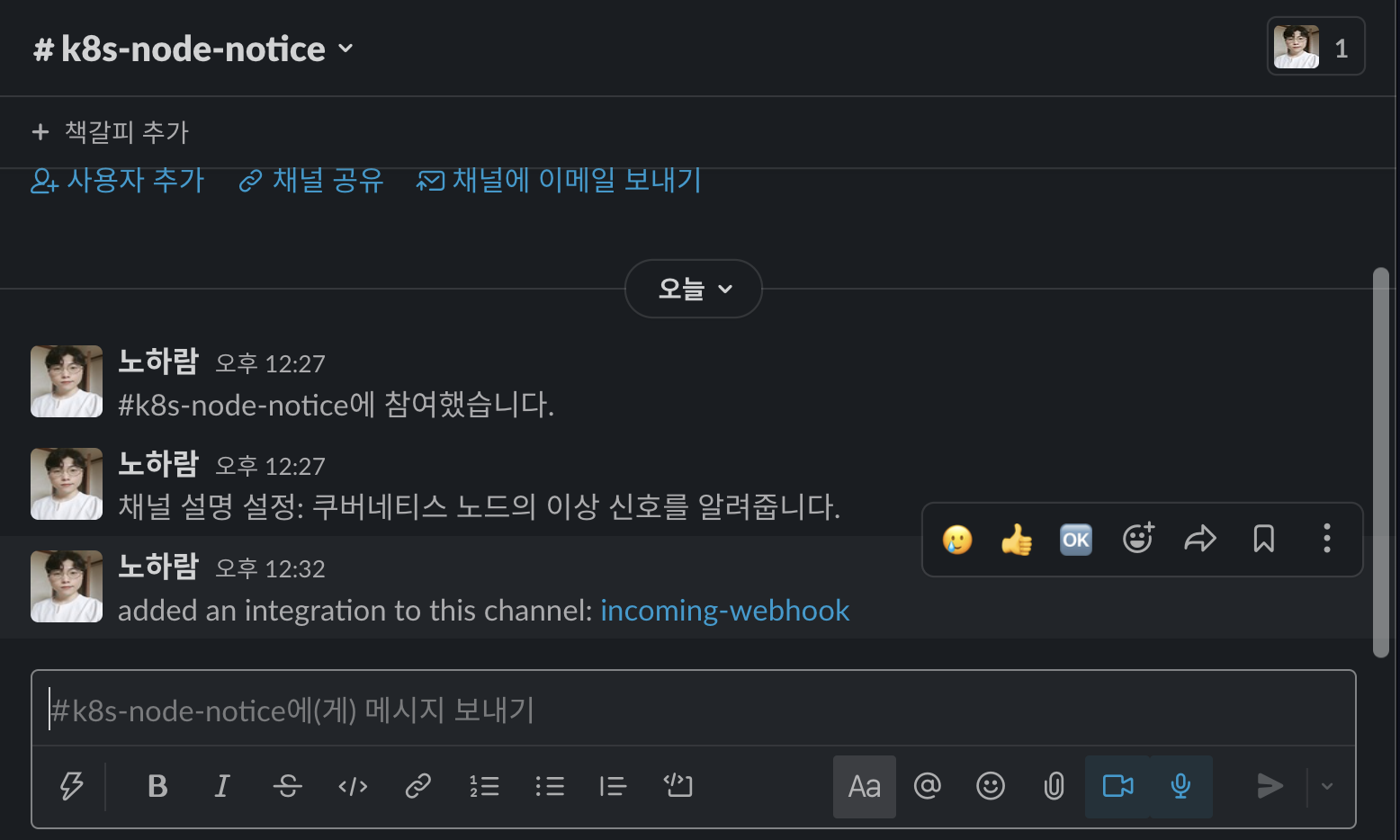
-
슬랙 앱에서 실제로 경보를 받을 슬랙 채널인 k8s-node-notice가 생성됐는지, 수신 웹후크(incoming-webhook)가 설정됐는지 확인합니다.
얼럿매니저 구성하기
다음으로 프로메테우스의 얼럿매니저를 설치하고 구성합니다.
-
얼럿매니저의 설정은 컨피그맵에서 가져오는데, alert-notifier.yaml이라는 이름으로 구성돼 있습니다.
- 일부 수정할 부분이 있으므로 홈디렉터리 밑에 webhook라는 디렉터리를 새로 만들고, 이곳에 해당 파일을 복사합니다.
mkdir ~/webhookcp ~/_Book_k8sInfra/ch6/6.5.1/alert-notifier.yaml ~/webhook/
-
복사한 파일에 각자의 고유 웹후크 주소를 넣어야 합니다.
- sed 명령으로 Slack-URL을 슬랙 웹후크 주소로 변경합니다.(각자 앞에서 메모해 둔 주소를 입력합니다.)
sed -i 's,Slack-URL,https://hooks.slack.com/services/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,g' ~/webhook/alert-notifier.yaml- configmap은 다음과 같습니다.
apiVersion: v1 kind: ConfigMap metadata: annotations: meta.helm.sh/release-name: prometheus meta.helm.sh/release-namespace: default labels: app: prometheus app.kubernetes.io/managed-by: Helm chart: prometheus-11.6.0 component: alertmanager heritage: Helm release: prometheus name: prometheus-notifier-config namespace: default data: alertmanager.yml: | global: slack_api_url: Slack-URL receivers: - name: slack-notifier slack_configs: - channel: #monitoring send_resolved: true title: '[{{.Status | toUpper}}] {{ .CommonLabels.alertname }}' text: >- *Description:* {{ .CommonAnnotations.description }} route: group_wait: 10s group_interval: 1m repeat_interval: 5m receiver: slack-notifier
-
얼럿매니저 설정에 필요한 컨피그맵이 준비됐습니다. 슬랙 웹후크 주소를 변경한 파일을 실행해 컨피그맵을 만들고 확인합니다.
kubectl apply -f ~/webhook/alert-notifier.yamlkubectl get configmap prometheus-notifier-config

-
얼럿매니저는 프로메테우스와 그라파나처럼 독립적인 설치 공간이 필요합니다.(NFS, PV, PVC)
-
설정값을 작성해둔 prometheus-alertmanager-preconfig.sh를 실행합니다.
-
~/_Book_k8sInfra/ch6/6.5.1/prometheus-alertmanager-preconfig.sh

-
배시 파일의 내용은 다음과 같습니다.
#!/usr/bin/env bash nfsdir=/nfs_shared/prometheus/alertmanager # check helm command echo "[Step 1/4] Task [Check helm status]" if [ ! -e "/usr/local/bin/helm" ]; then echo "[Step 1/4] helm not found" exit 1 fi echo "[Step 1/4] ok" # check metallb echo "[Step 2/4] Task [Check MetalLB status]" namespace=$(kubectl get namespace metallb-system -o jsonpath={.metadata.name} 2> /dev/null) if [ "$namespace" == "" ]; then echo "[Step 2/4] metallb not found" exit 1 fi echo "[Step 2/4] ok" # create nfs directory & change owner echo "[Step 3/4] Task [Create NFS directory for alertmanager]" if [ ! -e "$nfsdir" ]; then ~/_Book_k8sInfra/ch6/6.5.1/nfs-exporter.sh prometheus/alertmanager chown 1000:1000 $nfsdir echo "[Step 3/4] Successfully completed" else echo "[Step 3/4] failed: $nfsdir already exists" exit 1 fi # create pv,pvc echo "[Step 4/4] Task [Create PV,PVC for alertmanager]" pvc=$(kubectl get pvc prometheus-alertmanager -o jsonpath={.metadata.name} 2> /dev/null) if [ "$pvc" == "" ]; then kubectl apply -f ~/_Book_k8sInfra/ch6/6.5.1/prometheus-alertmanager-volume.yaml echo "[Step 4/4] Successfully completed" else echo "[Step 4/4] failed: prometheus-alertmanager pv,pvc already exist" fi
-
독립적인 설치 공간이 필요한 젠킨스, 프로메테우스, 그라파나, 얼럿매니저
네 기능모두 NFS(Network File System)안에 존재합니다.
그리고 각자의 PV와 PVC를 가지고 있습니다.
젠킨스 : /nfs_shared/jenkins
프로메테우스-서버 : /nfs_shared/prometheus/server
프로메테우스-얼럿매니저 : /nfs_shared/prometheus/alertmanager
그라파나 : /nfs_shared/grafana
-
얼럿매니저를 설치하는 데 필요한 구성이 끝나면 헬름 차트로 얼럿매니저를 설치합니다.
- 설치할 떄 upgraded라고 뜨는 부분은 프로메테우스 헬름 차트 방면에서 보면 프로메테우스가 얼럿매니저에 경보 메세지를 보내기 위한 규칙을 설정(업그레이드)하는 과정이고, 프로메테우스에 독립적인 도구인 얼럿매니저 방면에서 보면 실제로는 설치되는 것입니다.
~/_Book_k8sInfra/ch6/6.5.1/prometheus-alertmanager-install.sh
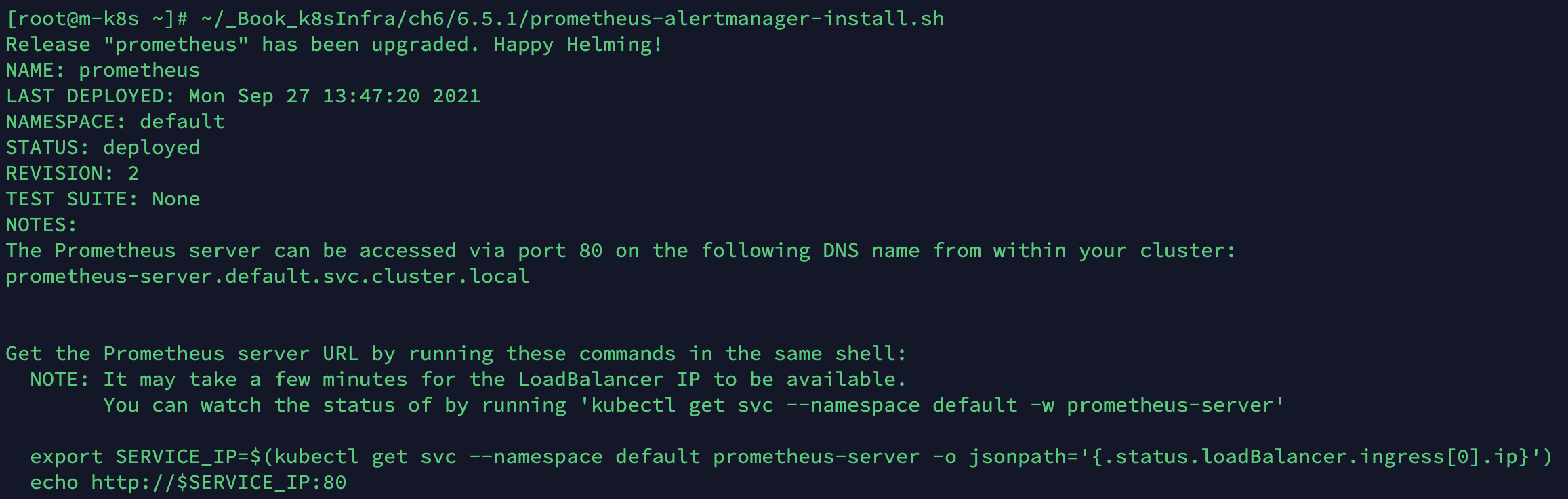
#!/usr/bin/env bash helm upgrade prometheus edu/prometheus \ --set pushgateway.enabled=false \ --set nodeExporter.tolerations[0].key=node-role.kubernetes.io/master \ --set nodeExporter.tolerations[0].effect=NoSchedule \ --set nodeExporter.tolerations[0].operator=Exists \ --set alertmanager.persistentVolume.existingClaim="prometheus-alertmanager" \ --set server.persistentVolume.existingClaim="prometheus-server" \ --set server.securityContext.runAsGroup=1000 \ --set server.securityContext.runAsUser=1000 \ --set server.service.type="LoadBalancer" \ --set server.baseURL="http://192.168.1.12" \ --set server.service.loadBalancerIP="192.168.1.12" \ --set server.extraFlags[0]="storage.tsdb.no-lockfile" \ --set alertmanager.configMapOverrideName=notifier-config \ --set alertmanager.securityContext.runAsGroup=1000 \ --set alertmanager.securityContext.runAsUser=1000 \ --set alertmanager.service.type="LoadBalancer" \ --set alertmanager.service.loadBalancerIP="192.168.1.14" \ --set alertmanager.baseURL="http://192.168.1.14" \ -f ~/_Book_k8sInfra/ch6/6.5.1/values.yaml
-
프로메테우스 서버에 설정된 경보 메세지 전송 규칙을 확인해 보겠습니다.
- 웹 브라우저에 192.168.1.12를 입력해서 프로메테우스 홈 으로 이동합니다.
- Alerts 탭으로 이동해 화면에 보이는 NodeDown 글자를 눌러 사진처럼 경보 메세지 전송 규칙이 입력돼 있는지 확인합니다.
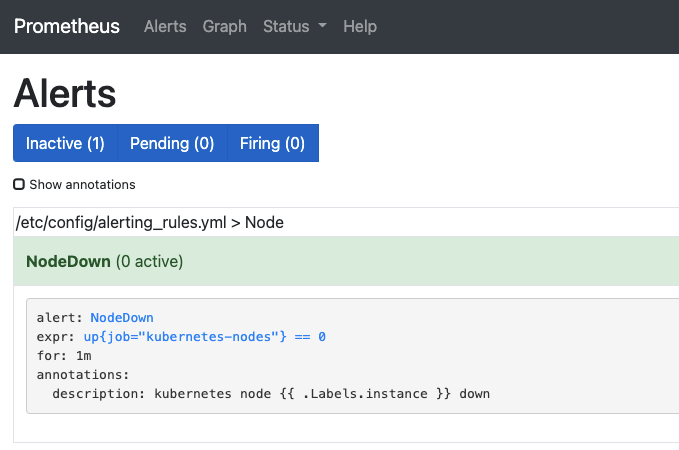
- 경보 규칙의 각 항목은 다음과 같습니다.
- alert : 경보 메세지를 대표하는 이름
- expr : PromQL 표현식으로 경보 규칙을 설정해 참인 경우 경보 발생
- for : 문제 지속 시간
- annotations : 하위 항목에 필요한 전달 메세지를 주석으로 기록
- description : 사용자 임의 지정 변수로 필요한 경보 내용을 작성할 수 있음
-
얼럿매니저가 정상적으로 설치됐는지 확인합니다. 먼저 얼럿매니저의 서비스 IP를 확인합니다.
kubectl get service prometheus-alertmanager

-
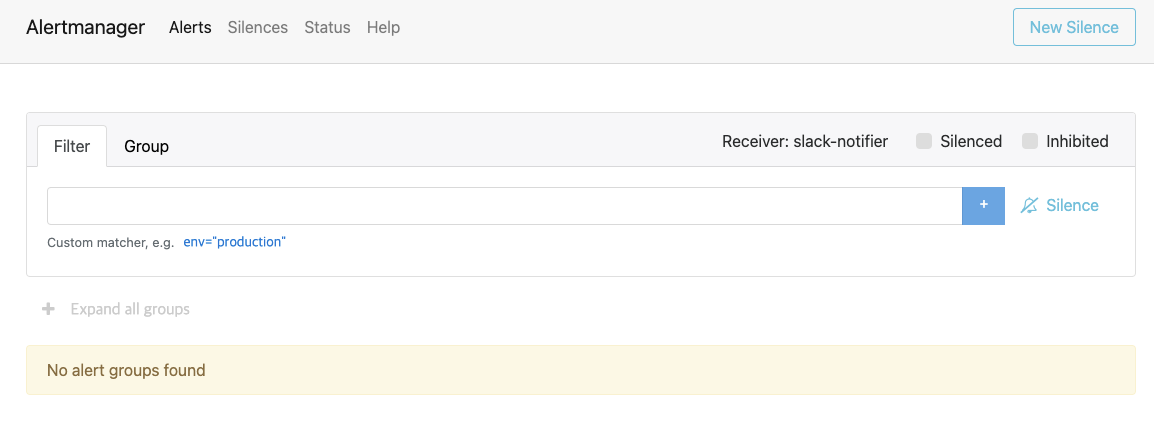
웹 브라우저에서 서비스 IP(192.168.1.14)를 입력합니다.
- 얼럿매니저의 웹 UI가 보이면 경보 메세지를 받지 않은 상태(No alert groups found)인지 확인합니다.
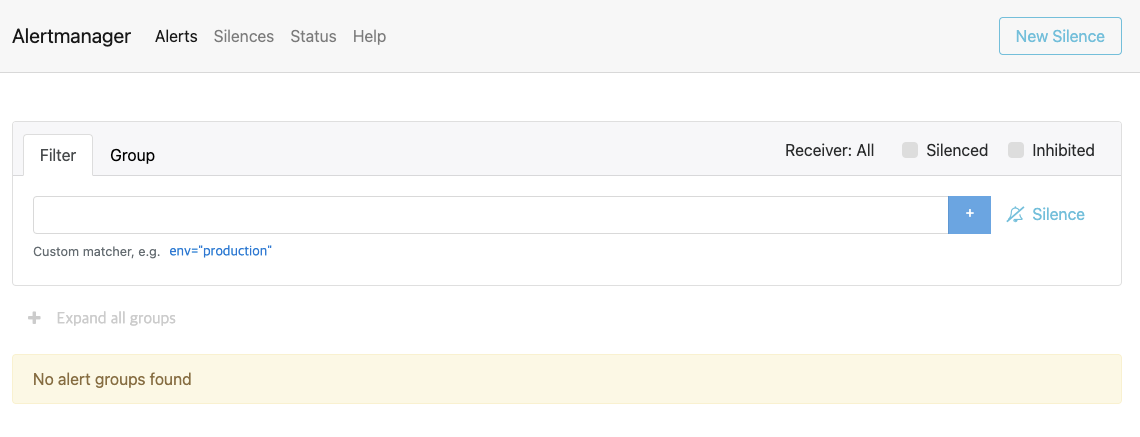
- 얼럿매니저의 웹 UI가 보이면 경보 메세지를 받지 않은 상태(No alert groups found)인지 확인합니다.
-
경보 메세지를 받도록 쿠버네티스 노드 중에 하나인 w3-k8s의 전원을 끕니다.
-
프로메테우스 서버가 쿠버네티스 노드가 종료된 것을 감지해 경보 메세지를 얼럿매니저에 보냅니다.
- 얼럿매니저가 경보 메세지를 슬랙 웹후크 URL로 보내면 사용자는 슬랙 서버를 통해 슬랙 앱에서 해당 경보 메세지를 확인합니다.
- 따라서 경보 메세지가 실제로 출력될 k8s-node-notice 채널로 이동해, 노드의 전원이 꺼졌음을 확인하고 경보 메세지를 보내오는지 확인합니다.
- 아까 1분 간격으로 노드의 이상을 감지하고 알람을 보내게 설정해놨죠?(경보 메세지 전송 규칙) 근데 왜 노드가 종료된지 1분이 지나도 알람이 오지 않을까요? 아래에서 알아봅시다.
경보 메세지의 출력은 왜 느린가요?
노드가 갑자기 종료되면 쿠버네티스는 노드가 정상적으로 돌아올 때까지 5분 정도 기다리고,
노드가 복구되지 않으면 노드에 존재하던 파드를 종료(Terminating)하고 다시 사용 가능한 노드에 배포합니다.
쿠버네티스 노드를 강제 종료하면 노드 위에 있던 파드들이 정상적으로 동작할 수 없습니다.
종료된 노드에 얼럿매니저나 프로메테우스 서버가 존재한다면 경보 메세지를 받거나 전달하기는 불가능합니다.
따라서 프로메테우스 서버나 얼럿매니저가, 종료된 노드에 있다면 파드가 다시 배포될 떄까지 기다려야 합니다.
거의 10분 이상 소요되므로 오래 걸린다고 느낄 수밖에 없습니다.
-
일정 시간이 지난 후에 쿠버네티스 노드가 중단(Kubernetes node w3-k8s down) 됐다는 경보 메세지가 나오는지 확인합니다.
- 메세지 중간에 있는 [FIRING] NodeDown을 눌러 경보 메세지를 보낸 대상을 확인합니다.
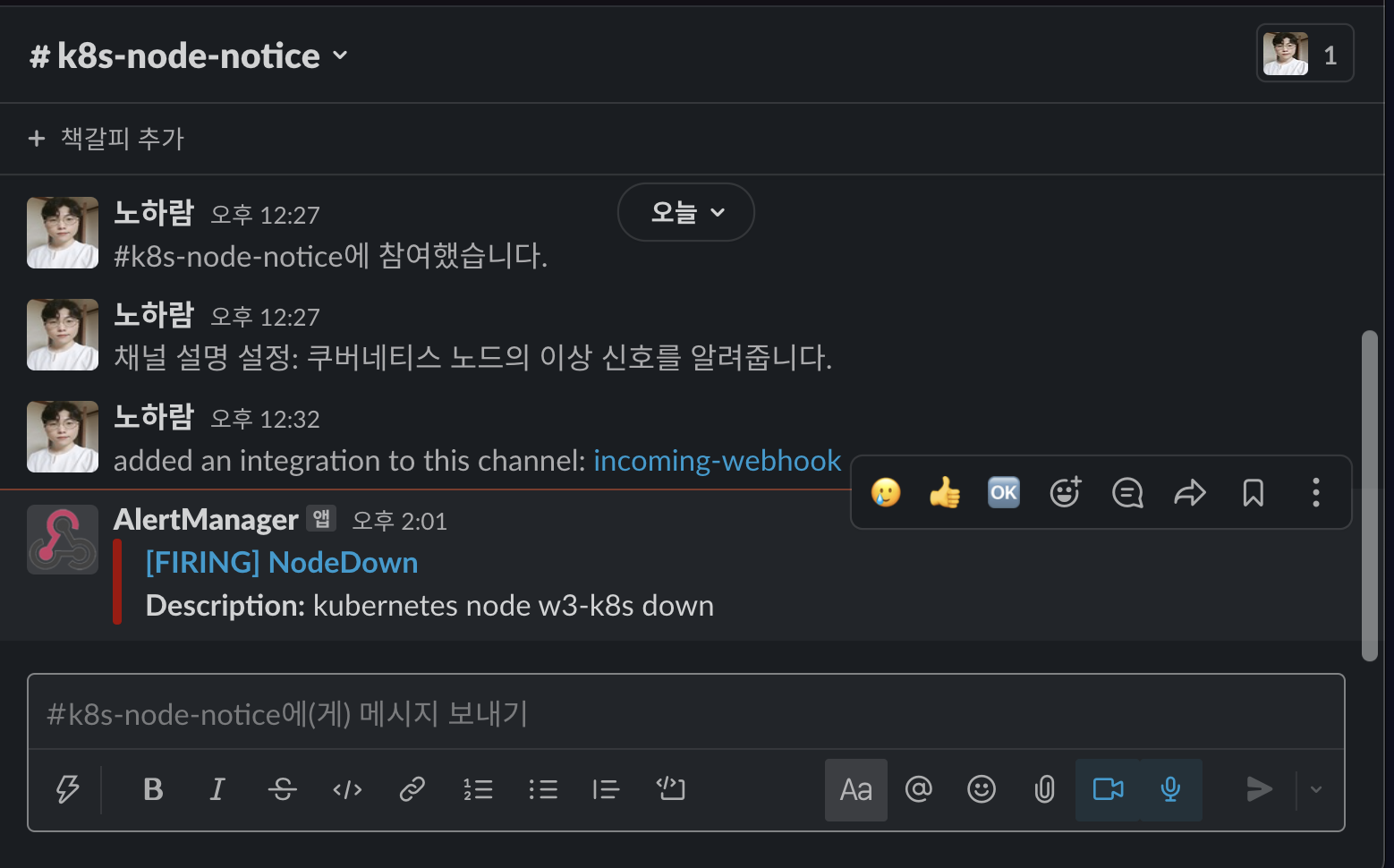
- 메세지 중간에 있는 [FIRING] NodeDown을 눌러 경보 메세지를 보낸 대상을 확인합니다.
-
[FIRING] NodeDown 메세지를 누르면 얼럿매니저에 접속됩니다.
- 이는 해당 메세지를 보낸 주체가 얼럿매니저임을 의미합니다.
- 얼럿매니저 메뉴 중에서 info 버튼을 누르면 슬랙에 전송된 메세지와 동일한 내용을 확인할 수 있습니다.
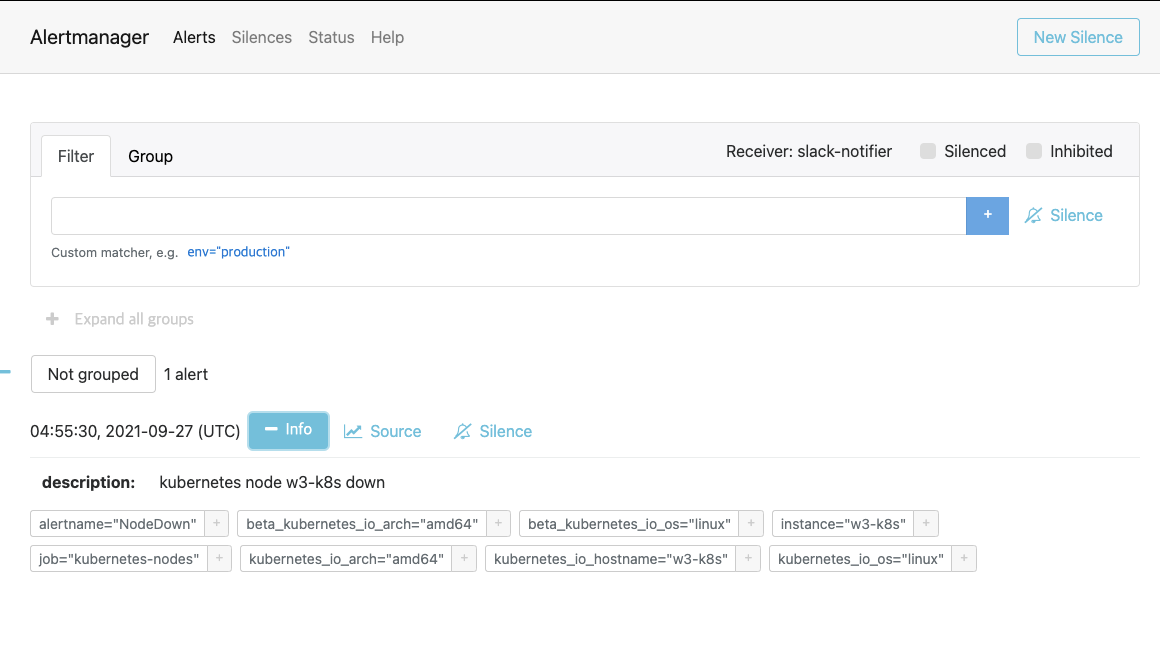
-
프로메테우스 서버(192.168.1.12)에 접속해 얼럿매니저에 경보 메세지를 보낸 프로메테우스 서버의 상태를 확인합니다.
- 그리고 Alerts 탭을 누르면 빨간 색의 NodeDown 경보 메세지가 보입니다.
- Nodedown 글자를 누르고, Show annotations를 체크하면 다음과 같이 발생한 경보 메세지에 대한 세부 정보를 확인할 수 있습니다.
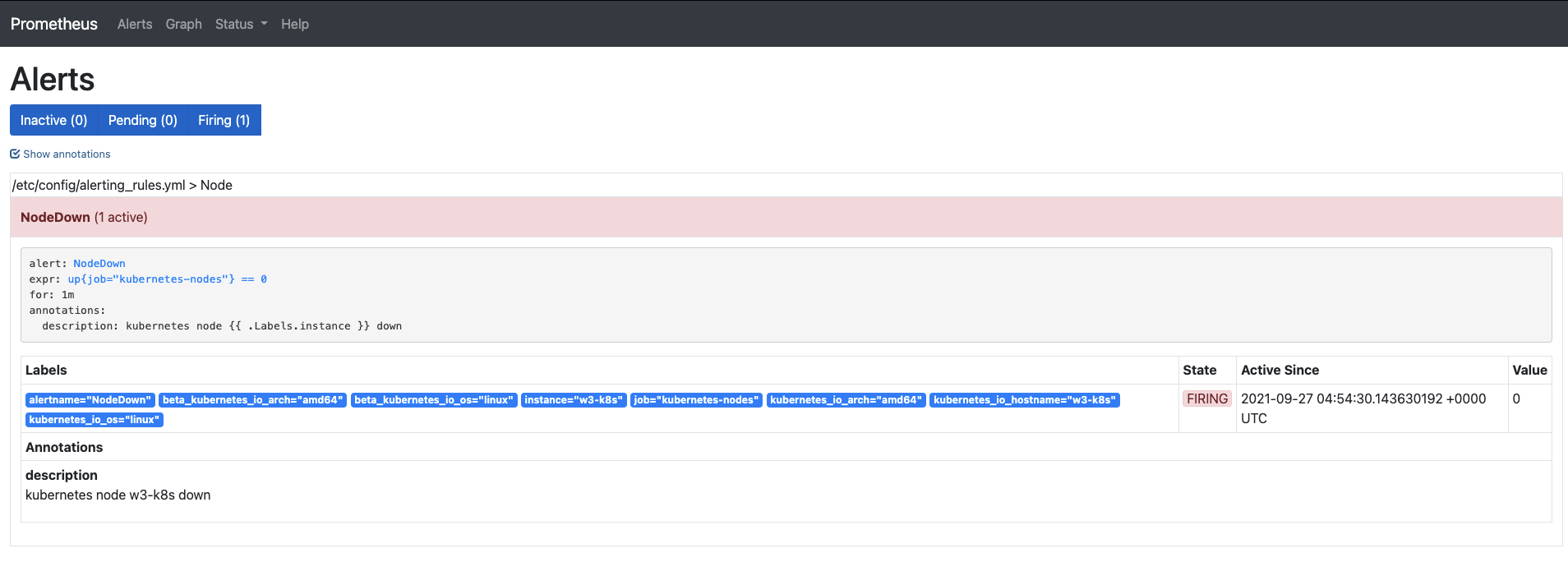
-
슬랙에 경보 메세지가 주기적으로 오는지 확인합니다.
- 쿠버네티스 노드가 계속 중단된 상태이므로 프로메테우스 서버에서 이를 인식하고 경보 메세지를 계속 보냅니다.
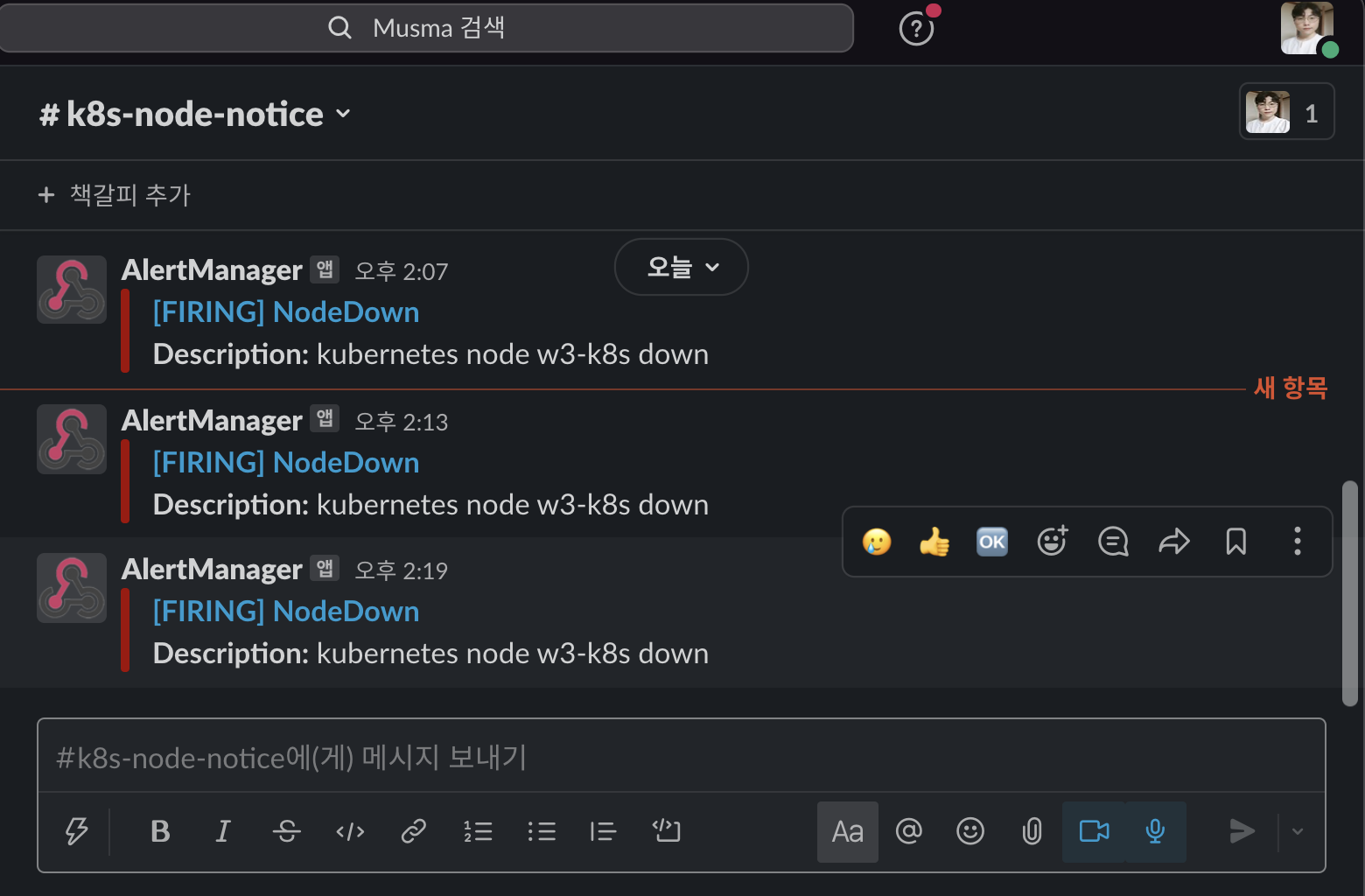
- 쿠버네티스 노드가 계속 중단된 상태이므로 프로메테우스 서버에서 이를 인식하고 경보 메세지를 계속 보냅니다.
-
경보 메세지를 더 이상 받지 않으려면 종료했던 w3-k8s 노드를 헤드리스로 다시 시작합니다.
-
w3-k8s 노드를 다시 시작한 후에 슬랙에 노드 중단 해결([RESOLVED] Nodedown) 메세지가 출력되는지 확인합니다.
- 추가로 얼럿매니저의 상태를 확인하기 위해 출력된 메세지를 클릭합니다.

- 추가로 얼럿매니저의 상태를 확인하기 위해 출력된 메세지를 클릭합니다.
-
슬랙 메세지로 얼럿매니저의 상태를 확인하러 들어가면 아무런 경보 메세지도 없습니다. 즉, 문제가 해결됐습니다.
-
경보 메세지가 더이상 발생하지 않는지 일정 시간 동안 슬랙 채널을 모니터링합니다.
이처럼 얼럿매니저를 통해 이상 신호를 받아 조치할 수 있음을 확인했습니다.
내가 만든 대시보드 공유하기
이번에는 지금까지 만든 대시보드를 다른 사용자에게 전달하는 방법을 알아보겠습니다.
그라파나는 자신이 만든 대시보드를 공유하는 기능을 제공합니다.
앞서 만든 대시보드를 내보내고 다시 가져와서 이 기능을 확인해 보겠습니다.
-
대시보드를 내보내는 대상으로 위에서 만든 쿠버네티스 클러스터 모니터링 대시보드를 사용하겠습니다.
- 그라파나 홈 화면에 가서 최근에 확인한 대시보드에 나타난 쿠버네티스 클러스터 모니터링 대시보드를 누릅니다.
- 그라파나 홈 화면에 가서 최근에 확인한 대시보드에 나타난 쿠버네티스 클러스터 모니터링 대시보드를 누릅니다.
-
대시보드로 이동해서 화면 왼쪽 상단에 있는 Share dashboard(대시보드 공유하기) 메뉴를 누릅니다.
-
Export 탭에서 Save to file 버튼을 눌러 대시보드의 JSON 파일을 내려받습니다.
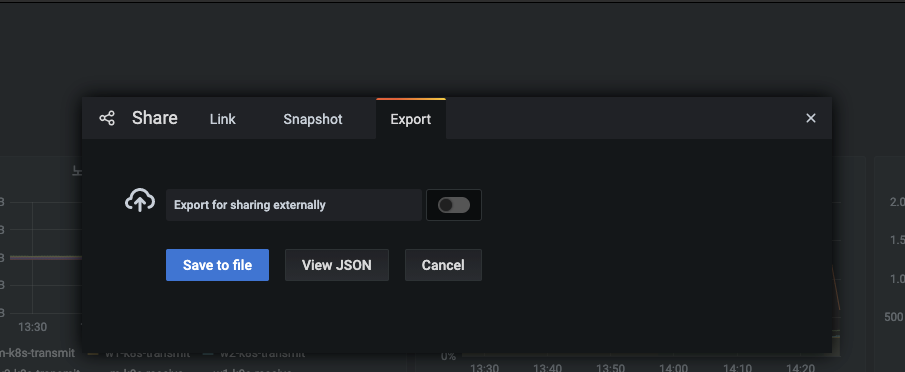
- Share dashboard 메뉴에는 3가지 탭이 있는데, 각 탭은 다음 역할을 담당합니다.
- Link : 다른 사용자가 대시보드에 접속할 수 있는 링크 주소와 옵션이 있습니다.
- Snapshot : 대시보드의 현재 상태를 저장해 대시보드에 접근할 수 없는 곳에서 확인할 수 있습니다.
- Export : 대시보드를 JSON 파일로 내보냅니다. 내보낸 JSON 파일은 그라파나 대시보드 저장소에 올리거나 다른 사용자에게 JSON 파일 형태로 전달할 수 있습니다. 이떄 Export for sharing externally 스위치를 활성화하면 다른 사람이 만든 대시보드를 가져올 때 데이터 소스를 선택할 수 있습니다. 현재 데이터 소스는 프로메테우스로 고정돼 있기 때문에 활성화하지 않았습니다.
-
내려받은 JSON 파일을 확인하고 다른 사용자에게 전달합니다.
- 현재 다른 사용자가 존재하지 않으므로 현재의 대시보드를 지우고 다시 불러와 다른 사용자의 대시보드 설정을 그대로 가져올 수 있는지 확인해 보겠습니다.
- 화면 오른쪽 상단에 톱니바퀴 모양의 Bashboard settings(대시보드 설정) 메뉴를 누릅니다.
-
대시보드 설정 창에서 Delete Dashboard > Delete 버튼을 눌러 대시보드를 삭제합니다.
- 삭제하면 대시보드를 복구할 수 없으니 앞에서 JSON 파일을 제대로 내려받았는지 꼭 확인하고 진행하세요!!
- 삭제하면 대시보드를 복구할 수 없으니 앞에서 JSON 파일을 제대로 내려받았는지 꼭 확인하고 진행하세요!!
-
대시보드가 삭제되면 오른쪽 상단에 삭제 완료 안내 메세지가 출력되고 홈 화면으로 이동됩니다.
- 홈 화면 왼쪽에 있는 메뉴 중에서 + > Import를 선택합니다.
- 홈 화면 왼쪽에 있는 메뉴 중에서 + > Import를 선택합니다.
-
Import 메뉴에서 Upload .json file 버튼을 누릅니다. 내려받은 JSON 파일을 선택하고 열기 버튼을 누릅니다.
-
JSON 파일로 입력된 대시보드의 이름이 내려받은 대시보드 이름(쿠버네티스 클러스터 모니터링)과 같은지 확인하고 Import 버튼을 눌러 대시보드를 불러옵니다.
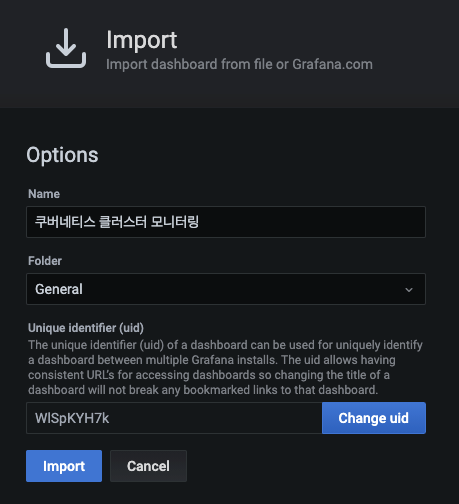
-
JSON 파일로 생성된 대시보드 패널들이 정상 동작하는지, 현재 시각으로 메트릭을 수집해 오는지 확인합니다.
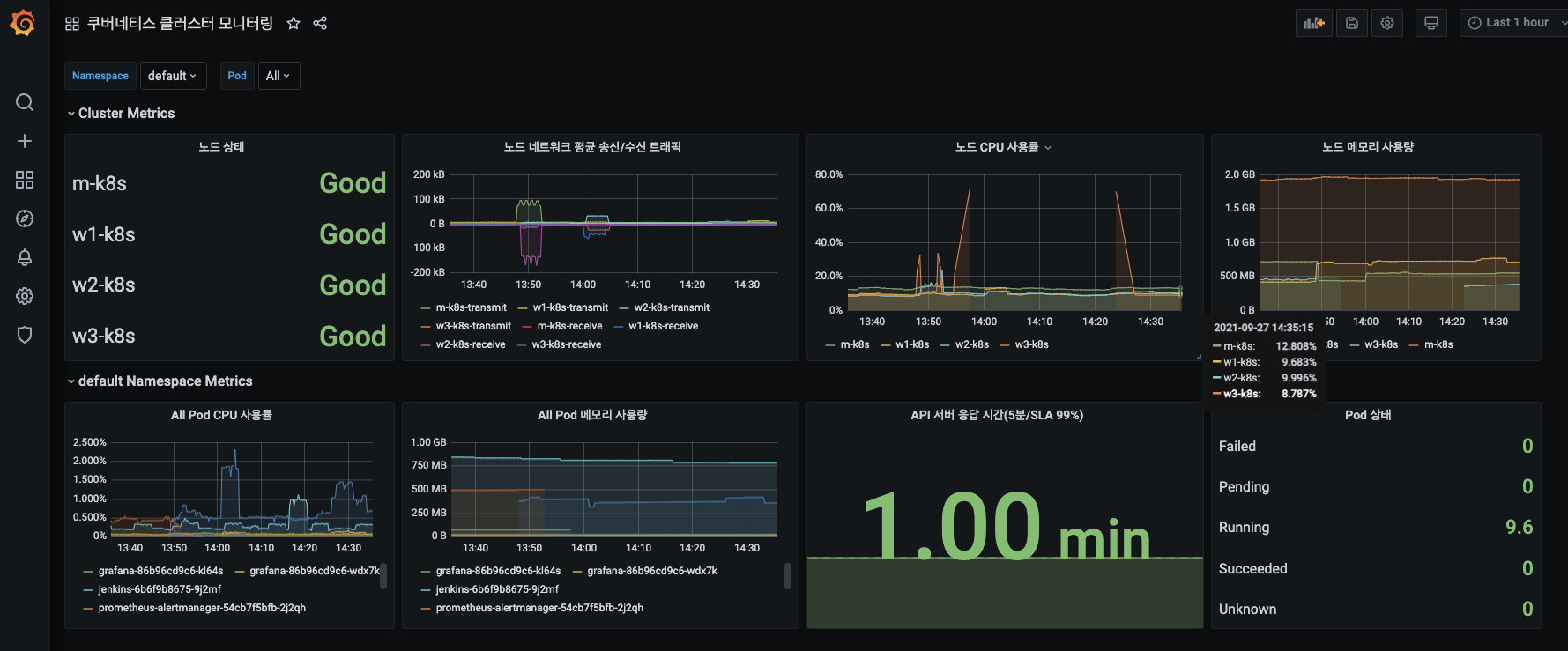
직접 만든 대시보드를 공유하는 것도 좋지만, 다른 사람이 이미 만들어 놓은 대시보드가 있다면 이를 활용하는 것이 더 좋은 방법일 수도 있습니다. 이어서 확인해 봅시다.
다른 사람이 만든 대시보드 가져오기
그라파나를 만든 그라파나 랩스에는 사용자가 만든 대시보드를 공유하는 기능이 있어서 다른 사용자가 만든 대시보드를 자신의 그라파나에 추가할 수 있습니다. 이 기능을 사용해 봅시다.
-
웹 브라우저에서 그라파나 랩스 홈페이지에 접속합니다.
- Grafana 탭에 있는 Dashboards 메뉴를 누릅니다.

- Grafana 탭에 있는 Dashboards 메뉴를 누릅니다.
-
그라파나의 공식 대시보드와 커뮤니티(사용자 포함) 대시보드가 공유되는 페이지로 이동합니다.
-
대시보드 공유 페이지에서 화면을 내리면 다음과 같이 사용자가 원하는 대시보드를 필터링(검색)할 수 있는 메뉴가 보입니다.
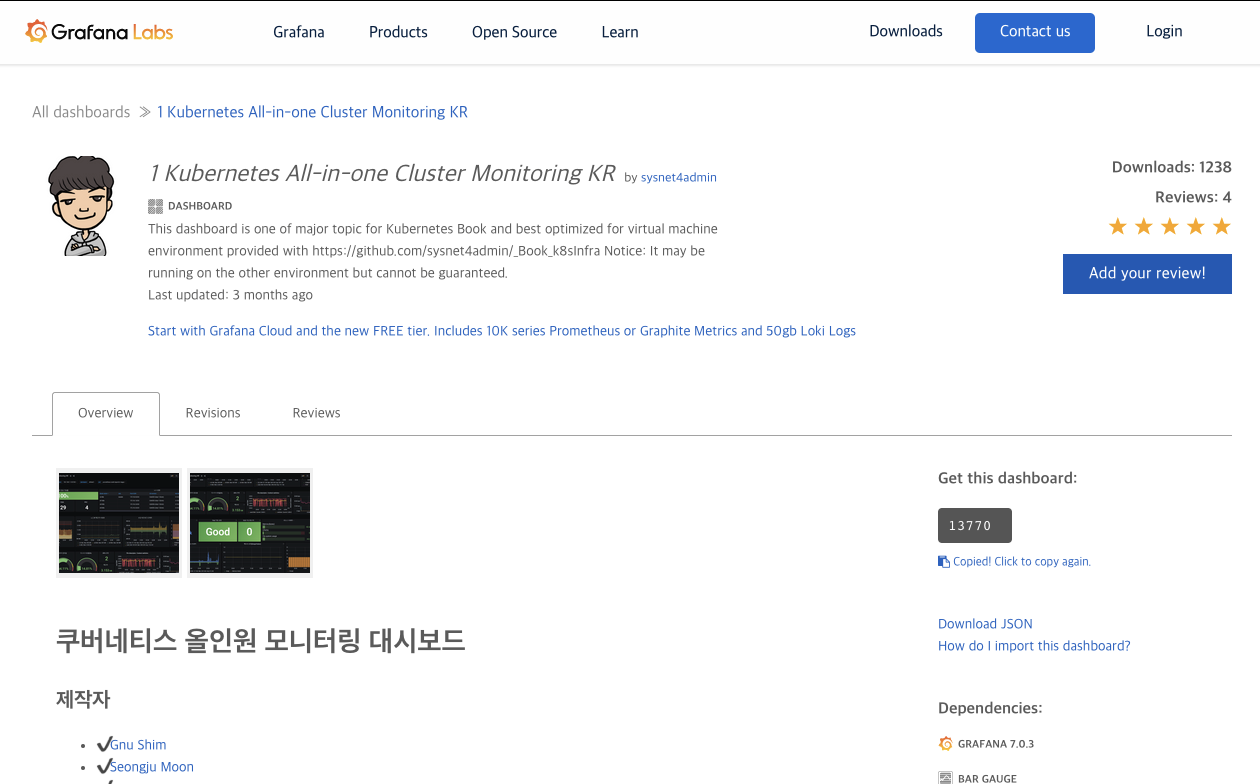
- Name / Description에 all-in을 입력하고 검색된 결과 중에 1 Kubernetes All-in-one Cluster Monitoring KR을 선택합니다.
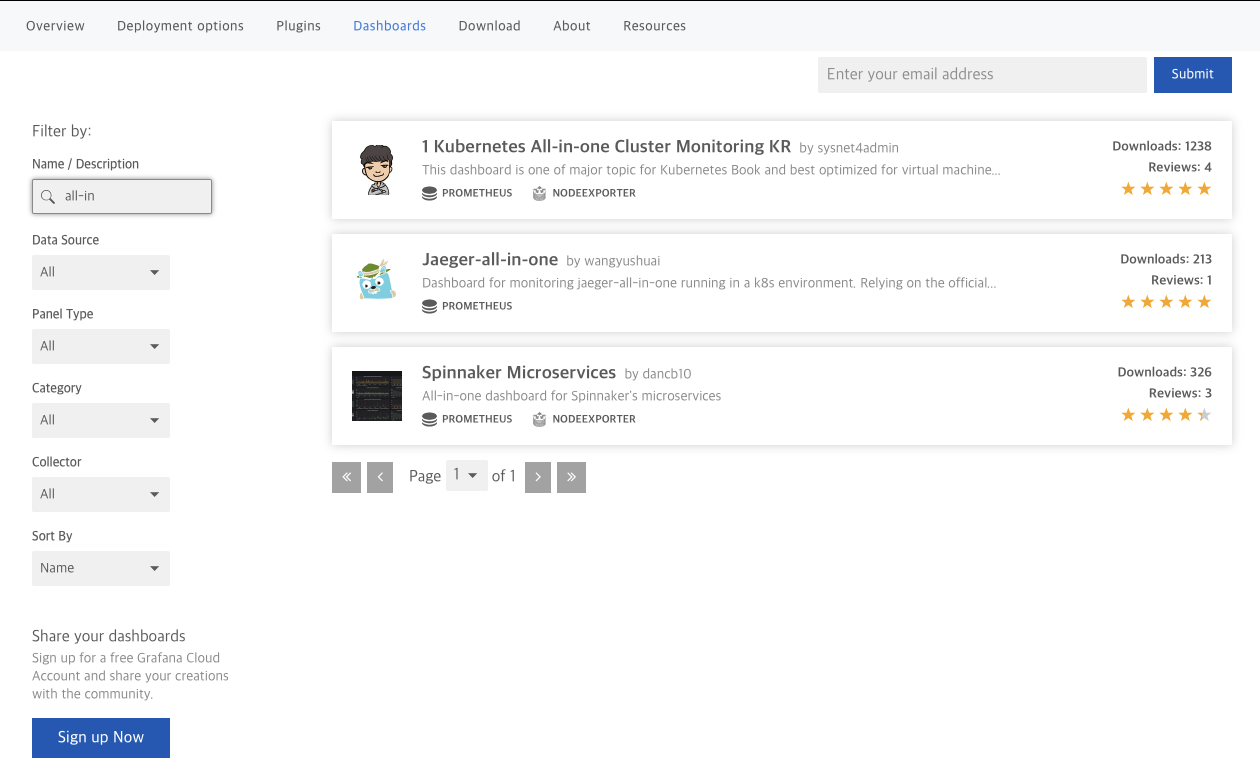
- Name / Description에 all-in을 입력하고 검색된 결과 중에 1 Kubernetes All-in-one Cluster Monitoring KR을 선택합니다.
-
각 대시보드는 고유의 식별자를 가지고 있는데, 현재 대시보드의 식별자는 13770입니다. 이 번호를 Copy ID to Clipboard 버튼을 눌러 복사하거나 기억합니다.
-
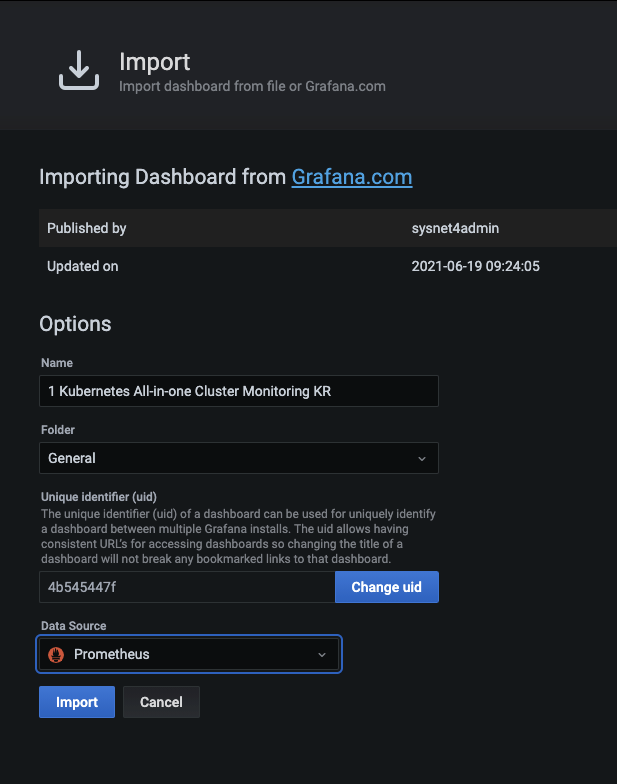
작성되어 있는 대시보드를 가져오기 위한 과정은 아까와 비슷합니다.
- 그라파나 홈 화면 왼쪽 메뉴 중 + > Import를 선택합니다.
- ID 입력칸 부분에 고유 식별자 번호인 13770을 입력하고 Load 버튼을 누릅니다.
- 불러올 대시보드의 이름이 1 Kubernetes All-in-one Cluster Monitoring KR인지 확인합니다.
- 데이터 소스는 Prometheus로 변경하고 Import 버튼을 누릅니다.
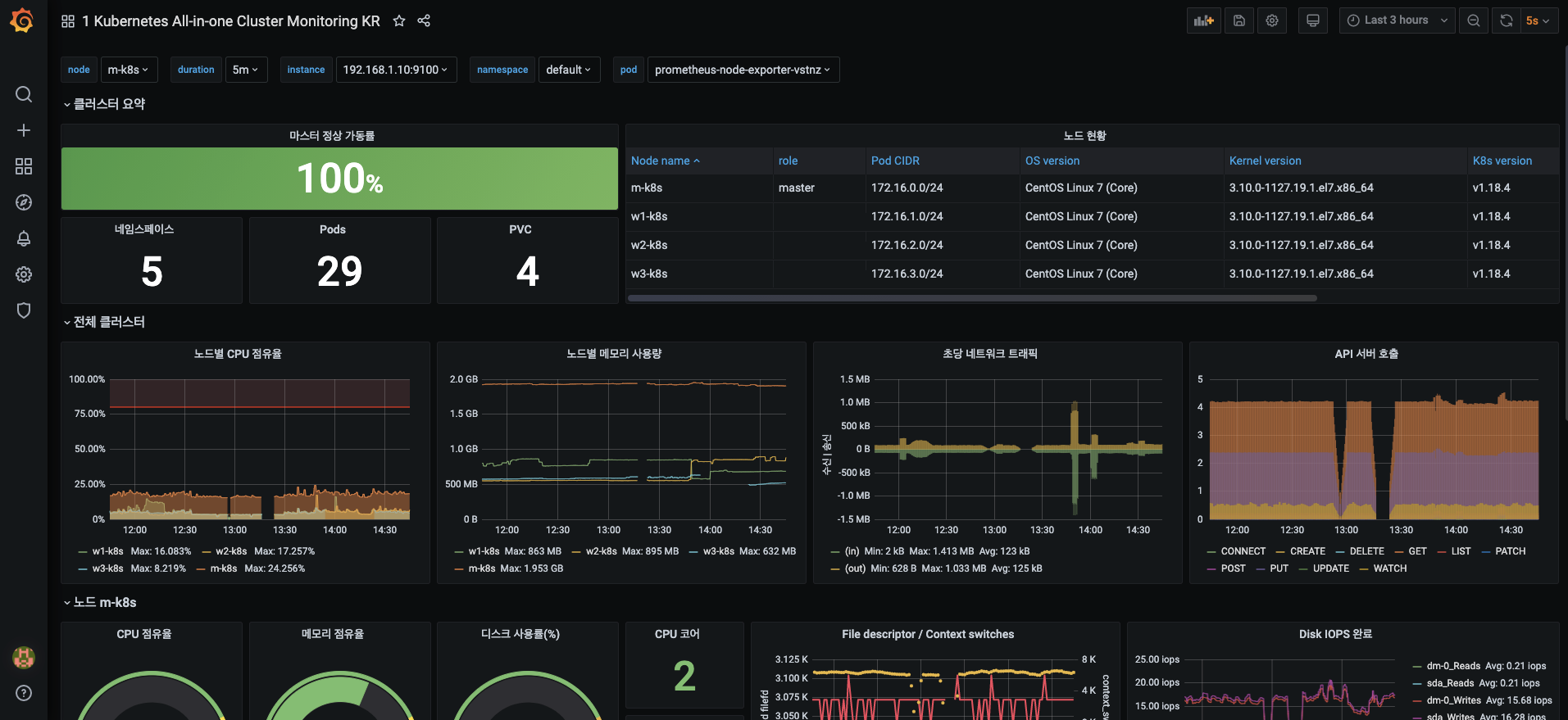
6.대시보드를 추가하면 다음과 같이 쿠버네티스 노드에 대한 다양한 메트릭을 수집해 올 수 있습니다.
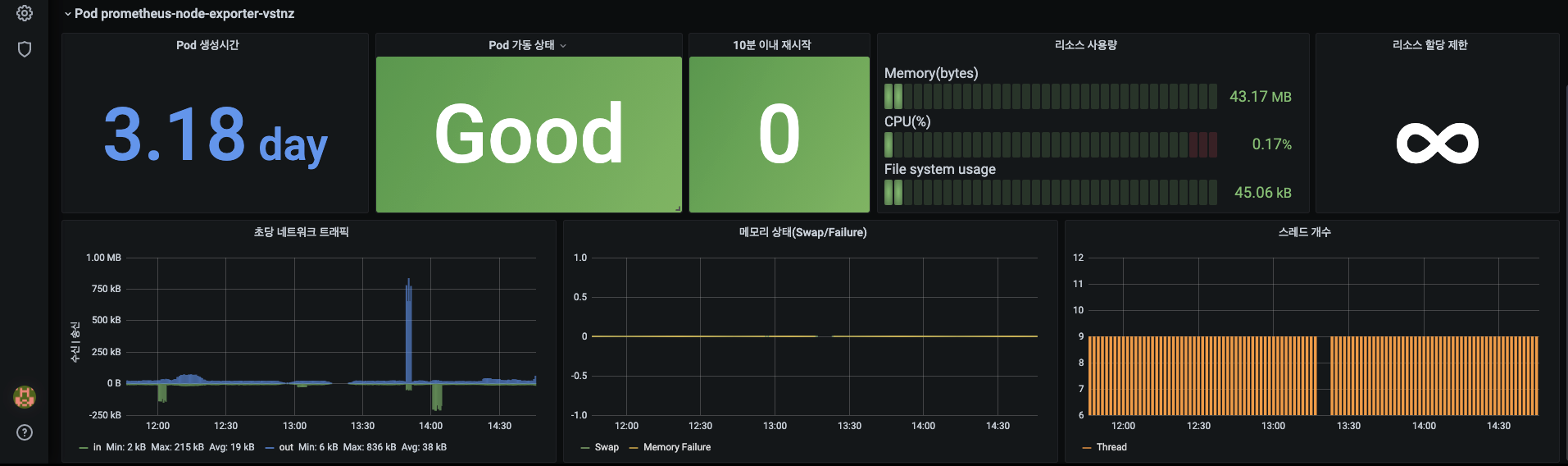
- 화면을 내려 파드에 대한 다양한 메트릭도 시각화 되는지 확인합니다.
이번 포스팅에서는 구축된 컨테이너 인프라 환경을 안정적으로 유지하고 관리할 수 있도록
프로메테우스와 그라파나로 모니터링 하는 방법을 알아봤습니다.
프로메테우스는 쿠버네티스에 포함된 요소들의 정보가 담긴 메트릭을 매우 손쉽게 추출하고,
그라파나는 이를 효과적으로 시각화할 수 있습니다.
지금까지 배운 쿠버네티스에 관한 많은 내용과 지식이 한 번에 모두 습득되지 않을 수 있습니다.
여러 번 실습해 보면 전반적인 쿠버네티스 환경과 그 안에서 실행되는 애플리케이션들을 이해할 수 있을 겁니다.
지금까지 함께 실습한 내용을 바탕으로 쿠버네티스의 자유로운 생태계에 대한 이해를 더 확장할 수 있기를 바랍니다.
훌륭한 책을 서술하신 저자에게 깊은 감사의 말씀을 전합니다.
본 게시물은 "컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커 - 조훈,심근우,문성주 지음(2021)" 기반으로 작성되었습니다.
