public string DevelopmentDiary(Knowledge knowledge) {
if (knowledge != null) {
return "level up"
} else {
return "level down"
}
}6주차에 진입하지도 않았지만 집필 중이다.
악명 높은 '그 녀석'이 나오기 때문이다.

맹활약할 그 녀석이다.
모자이크 처리했다.
근데 또 뭐 괜히 나 혼자 오버하는 걸수도 있다.
자료구조와 알고리즘 책에서 그 녀석이 나와서 공부하다가
'내가 이렇게까지 공부해야하나?', '그냥 이건 넘어갈까?'라고 생각했던 친구라서 오버 좀 해봤다.
일단 들어가보자.
RBTree
기본 개념
-
RB트리의 기본 개념에 대해 이해하고 이후 기본 규칙으로 들어가보겠다.
레드블랙트리란 자가 균형 이진 탐색 트리(self-balancing binary search tree)의 한 종류로, 삽입, 삭제, 검색 연산에서 항상 O(log n)의 시간 복잡도를 보장하는 효율적인 자료구조입니다. -
이진 탐색 트리의 일종: 각 노드는 최대 두 개의 자식 노드를 가집니다.
-
자가 균형 유지: 트리의 균형을 색상 속성(빨간색, 검은색)과 몇 가지 규칙을 통해 자동으로 유지합니다.
-
최악의 경우에도 효율적: 트리의 높이가 O(log n)으로 제한되어, 데이터가 한쪽으로 치우치지 않고 항상 균형에 가깝게 유지됩니다
라고 AI가 말했다.
이렇게만 봤을 때 되게 좋아보인다. 최악의 경우에도 효율적으로 작동할 수 있다니
이 얼마나 멋진 구조인가?
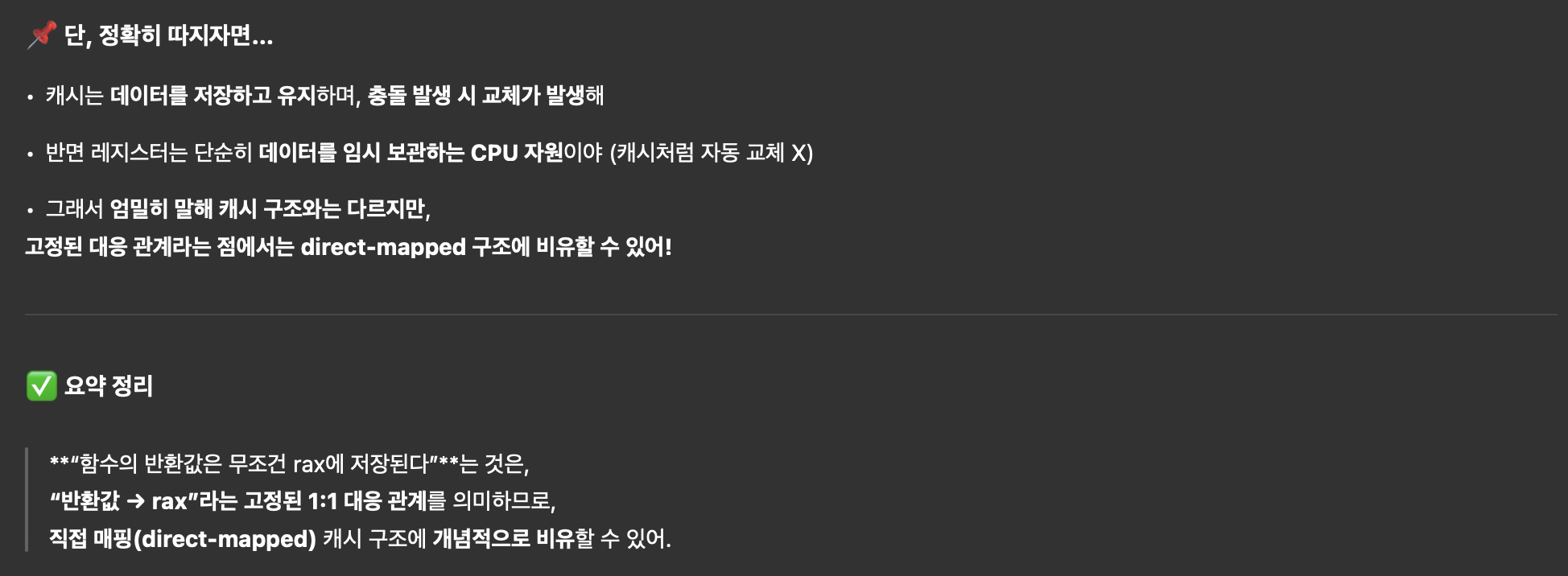
언제나, 멋진 물건과 시스템. 그 이면에는 불편한 진실이 도사리고있다.
'최악의 경우에도 효율적'을 유지하기 위해 수많은 코드들이 부품처럼 일하고 있다.
기본 규칙
기본 규칙은 레드블랙트리를 유지하는데 있어서 중요하다.
추후 나오는 삽입과 삭제 관련 머리 아픈 규칙들은 결국 이 기본 규칙을 유지하기 위해서 생긴 규칙들이기 때문이다.
우선은 한 눈에 보기 편하게 쭉 나열하고 이후 이에 대해 설명하겠다.
1. 노드의 색은 검은색 또는 빨강색이다.
2. 루트 노드는 항상 검은색이다.
3. 모든 리프 노드는 검은색이다. (모든 Nil 노드는 검은색이다.)
4. 빨간색 노드의 자식은 반드시 검은색이다.
5. 어떤 노드에서 리프 노드까지 가는 모든 경로에는 같은 개수의 검은색이 있다.
1. 노드의 색은 검은색 또는 빨강색이다.
가장 기본이 되는 규칙이다. RB트리가 RB트리라고 불리는 이유다. RB트리는 이진트리에 색을 입힌게 전부이기 때문에 결국 빨간색과 검은색을 어떻게 다루느냐가 중점이 된다.
2. 루트 노드는 항상 검은색이다.
어려울 것 없는 규칙이다. 왜? 검은색인지에 대해서 아직 찾아보지도, 생각해보지도 않았지만 아무래도 새로 삽입하는 노드가 빨간색이라는 규칙과 관련이 있지 않을까 싶다.
3. 모든 리프 노드는 검은색이다. (모든 Nil 노드는 검은색이다.)
리프 노드는 트리에서 자식이 없는 노드를 말한다. 이는 레드블랙트리도 마찬가지인데,
큰 차이점이 있다면, RB트리의 리프 노드는 값을 가지지 않는다.
RB트리의 값이 있는 모든 노드는 자식이 있으며, 자식은 값이 있는 노드 혹은 Nil노드 둘 중 하나다.
다음 예시를 보면 이해가 쉽다. 편의상 색은 생략하겠다.
10
/ \
5 15
/ \ / \
nil 7 nil 20
/ \ / \
nil nil nil nil이런 느낌이다.
4. 빨간색 노드의 자식은 반드시 검은색이다.
다시말해 빨간색 노드는 두 번 연속 등장할 수 없다는 의미이다. 검은색의 자식은 빨간색과 검은색 둘 다 될 수 있지만, 빨간색 노드는 검은색 자식만 가질 수 있다.
5. 어떤 노드에서 리프 노드까지 가는 모든 경로에는 같은 개수의 검은색이 있다.
여기서 리프 노드는 당연히 nil노드를 말하는 거다.
예시를 들어보겠다.
10
/ \
5 15
/ \ / \
nil 7 nil 20
/ \ / \
nil nil nil nil여기에서 나올 수 있는 경로는
10 - 5 - nil
10 - 5 - 7 - nil
10 - 15 - nil
10 - 15 - 20 -nil
이렇게 나온다.
벌써 여기서 각 노드들의 색이 어떻게 칠해질지 정해진다고 볼 수 있다.
1) 루트 노드는 검정이다.
10(B) - 5 - nil
10(B) - 5 - 7 - nil
10(B) - 15 - nil
10(B) - 15 - 20 -nil
2) nil 노드 역시 검정이다.
10(B) - 5 - nil(B)
10(B) - 5 - 7 - nil(B)
10(B) - 15 - nil(B)
10(B) - 15 - 20 -nil(B)
3) 빨간색의 자식은 무조건 검은색이다.
왜 이 규칙이 나왔느냐 하면, 만약 둘 다 검은색이 되면
10(B) - 5(B) - nil(B) => 검은색 노드 3개
10(B) - 5(B) - 7(B) - nil(B) => 검은색 노드 4개
위와 같은 결과가 나오므로 5번 규칙에 위배된다.
따라서 5와 7이 빨간색이 되어야 하는데, 4번 규칙에 의해 5-7은 둘 다 빨간색이 될 수 없으므로
5가 빨간색이거나 7이 빨간색이 돼야한다.
3-1) 5가 빨간색인 경우
10(B) - 5(R) - nil(B) => 검은색 노드 2개
0(B) - 5(R) - 7(B) - nil(B) => 검은색 노드 3개
따라서 위배된다.
3-2) 7이 빨간색인 경우
10(B) - 5(B) - nil(B) => 검은색 노드 3개
0(B) - 5(B) - 7(R) - nil(B) => 검은색 노드 3개
따라서 예시를 수정하면
10(B)
/ \
5(B) 15(B)
/ \ / \
nil(B) 7(R) nil(B) 20(R)
/ \ / \
nil(B) nil(B) nil(B) nil(B)아마 위와 같은 그래프가 될 것이다.
이제부터는 위의 규칙을 지키기 위해 고군분투하는 과정이 될 것이다.
삽입/삭제 규칙을 잘 모르겠다면 아무튼 규칙을 지키기 위해 만들 수 있는 그래프를 생각해보자.
회전
RB트리에서 회전이라는 개념은 중요하다. 삽입과 관련해서 개념을 정리하다 회전 개념을 따로 정리해두는 것이 좋을 것 같아서 새로 추가 중이다.
RB트리의 회전은 B트리의 상승 분할과 유-사하면서 다른 면이 있다.
유사과학 좋아하는가?
나는 싫어한다.
근데 지구평평설은 좋아한다. 뭔가 바다가 욕조에 담겨 있는 것 같아서 재밌다.
잠깐 B트리를 보겠다.
3차 B트리이고 다음과 같은 구조라고 하겠다. 물론 B트리에서 다음과 같은 구조는 있을 수 없긴하다.
이는 RB트리의 회전이 상승 분할과 유사하다는 걸 보여주는 장치일 뿐이다.
11,18
/ | \
9 14 19
/ \ \
12 17 20여기서 모종의 이유로 19가 상승한다고 할 때
11,18,19
/ | \
9 14 20
/ \
12 17이런 모양이 되고
18
/ \
11 19
/ \ \
9 14 20
/ \
12 17최종적으로는 이런 모양이 될 것이다.
이 모양을 잘 기억해두자.
회전에는 두 가지가 있다.
왼쪽 회전과 오른쪽 회전
쉽게 생각하면
왼쪽 회전(반시계 방향 회전)
오른쪽 회전(시계 방향 회전)
이라고 생각하면 편하다.
이해하기 쉽게 삼각형을 그리도록 하겠다.
이진 탐색 트리의 일종이므로 크기를 색으로 표현하겠다.
빨간색이 가장 작고, 초록색이 가장 크다고 생각하면 된다.

나머지 노드들은 부모 노드를 따라가기 때문에 크게 신경쓰지 않아도 된다.
1) 왼쪽 회전 (반시계 방향 회전)
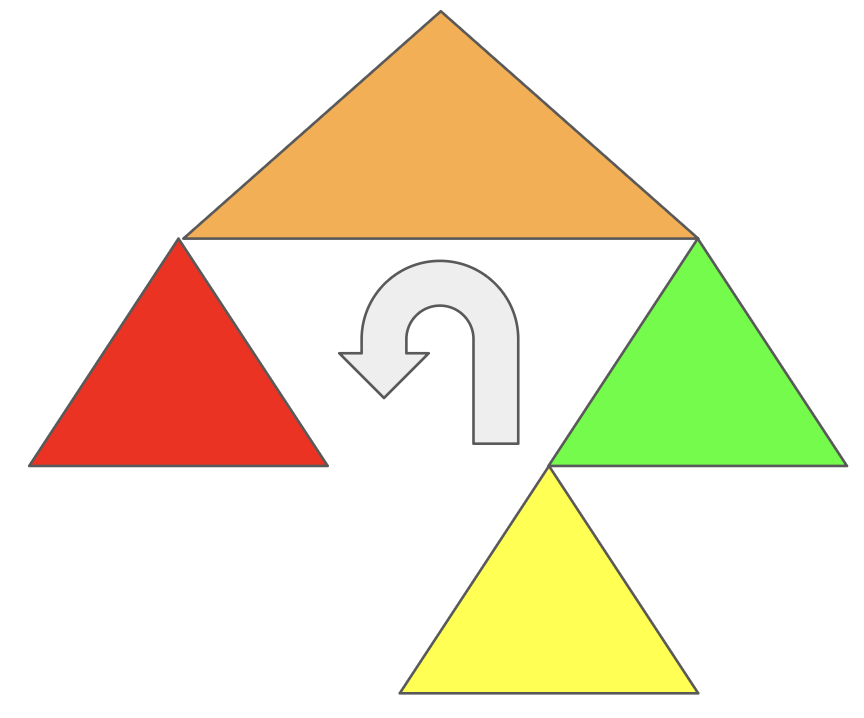
반시계 방향으로 회전한다고 생각해보라
그럼 초록색이 주황색 자리에 위치하게 될 것이다. 그러면
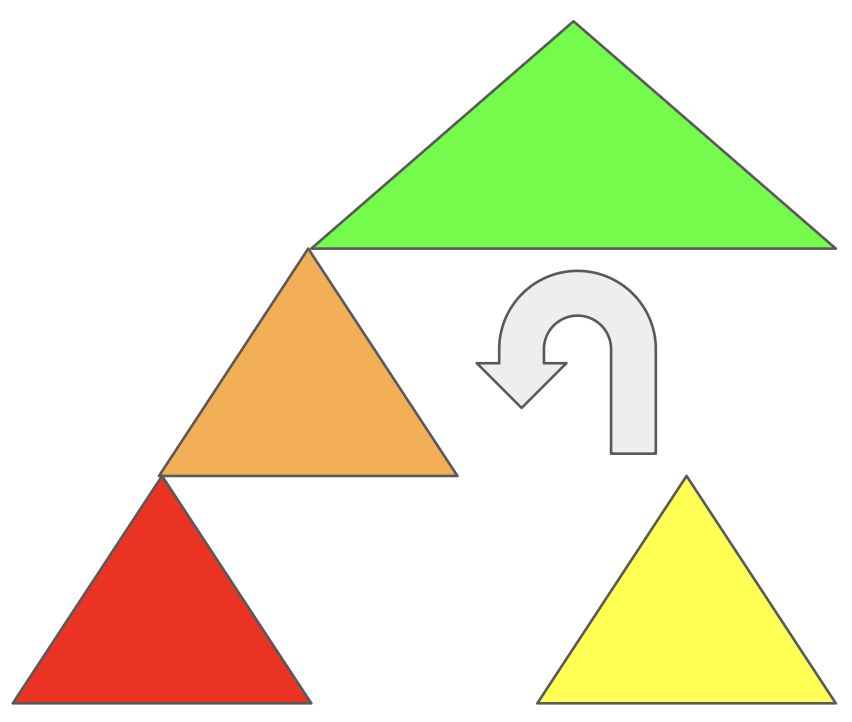
이런 형태가 되는데, 노란색이 어디에 붙으면 가장 이상적일지 고민해보자.
초록색보다 작고
주황색보다 크므로
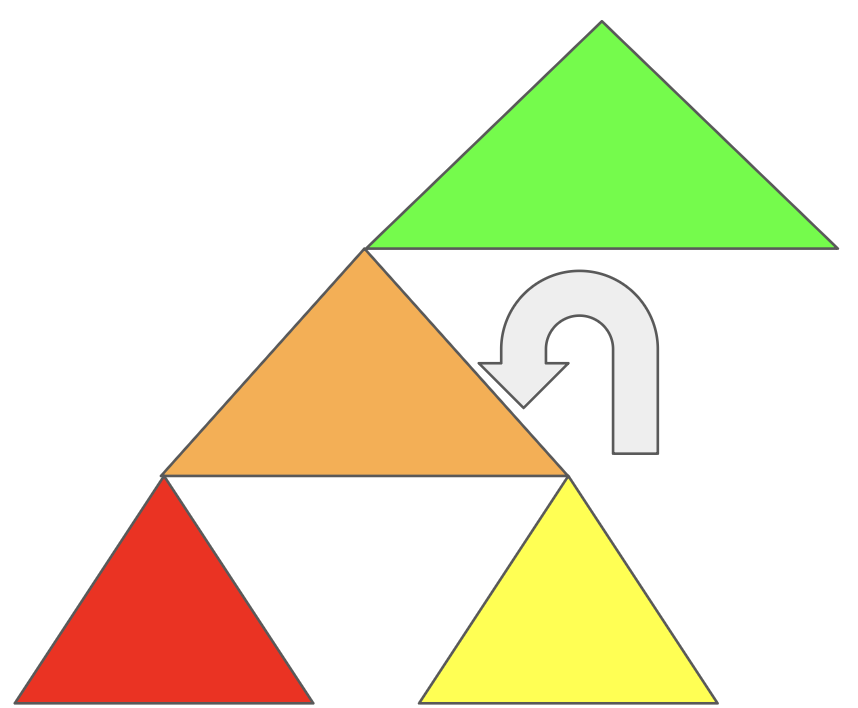
저 위치에 붙게 되는 것이다. 이게 왼쪽 회전이다.
숫자로 보면 복잡하지만 그림으로 보면 간단하다.
아까 B트리와 유사한 무색 RB트리를 보자.
11
/ \
9 18
/ \
14 19
/ \ \
12 17 20여기서 11을 기준으로 왼쪽으로 회전할 것이다.
9가 빨간색, 11이 주황색, 18이 초록색, 14가 노란색이다.
구조에 대해서 잠깐 고민하는 시간을 가져보자.
아래와 같은 형태가 된다.
18
/ \
11 19
/ \ \
9 14 20
/ \
12 17 사실 여기까지 이해했으면
오른쪽 회전도 결국 똑같기 때문에 별거 없다.
앞서 설명했던 B트리와 비교해보자.
11,18
/ | \
9 14 19
/ \ \
12 17 20B트리와 비교해보면
11
/ \
9 /\
14 18
/ \ \
12 17 19
\
2014는 11과 18사이에 걸쳐있다고 생각해도 좋다.
위 그래프에서는 중력? 때문에 18쪽으로 기울어져 있고
18
/ \
/\ 19
11 14 \
/ / \ 20
9 12 17 위 그래프에서는 중력 때문에 11쪽으로 기울어져 있다.
시공간을 왜곡시켰다.
오른쪽 회전 (시계 방향 회전)
시계 방향으로 회전한다고 생각해보라
그럼 빨간색이 노란색 자리에 위치하게 될 것이다. 그러면
이런 형태가 되는데, 주황이 어디에 붙으면 가장 이상적일지 고민해보자.
빨간색보다 크고
노란색보다 작으므로
저 위치에 붙게 되는 것이다. 이게 오른쪽 회전이다.
숫자로 보면 복잡하지만 그림으로 보면 간단하다.
다시 한 번 무색 RB트리를 보자.
18
/ \
11 19
/ \ \
9 14 20
/ \
12 17 여기서 18을 기준으로 오른쪽으로 회전할 것이다.
11이 빨간색, 14가 주황색, 18이 노란색, 19가 초록색이다.
구조에 대해서 잠깐 고민하는 시간을 가져보자.
아래와 같은 형태가 된다.
11
/ \
9 18
/ \
14 19
/ \ \
12 17 20여기부터는 고찰이 필요할 것 같아 다른 글에 정리할 예정이다.
https://velog.io/@mogiyoon/RB-Tree에-대한-고찰
서로가 서로를 참조하고 있다.
CS
Bryant, R. E., & O’Hallaron, D. R. (2023). Computer systems: A programmer’s perspective (3rd ed.). Pearson.
링커
전통적인 링커의 역할은 정적인 연결이었다. 시대가 변함에 따라 모듈이 많아지고 공유 라이브러리와 동적 링킹 사용 증가에 따라 중요성이 커졌다.
1) 정적 연결
정적 링커는
입력: 재배치 가능*한 목적 파일, 명령줄 인자(command line arguments)
을 통해 로드되고
출력: 완전히 링크된 실행 가능 목적 파일
함
* 재배치 가능: 나중에 링커가 여러 목적 파일을 결합할 때 각 코드와 데이터의 실제 위치(주소)를 자유롭게 “재배치(relocate)“할 수 있도록 만들어졌음 (- AI)
실행파일을 만들기 위한 링커의 두 가지 주요 작업
(1) 심볼* 해석: 목적 파일들은 심볼들을 정의하고 참조함. 심볼 해석은 각각의 심볼 참조를 정확하게 하나의 심볼 정의에 연결함.
(2) 재배치: 컴파일러와 어셈블러는 주소 0번지에서 시작하는 코드와 데이터 섹션들을 생성함. 링커는 이 섹션들을 각 심볼 정의와 연결시켜 재배치 함. 이 심볼들로 가는 모든 참조를 수정하여 이 메모리 위치를 가리키도록 함.
* 심볼: 변수명, 함수명 등 엔티티를 식별하기 위해 사용하는 이름
이를 이해하기 위해 컴파일 시스템을 다시 떠올려보자
hello.c -> (전처리) -> hello.i -> (컴파일러) -> hello.s -> (어셈블러) -> hello.o -> (링커) -> hello
즉, 어셈블러에서 어떤 함수, 혹은 전역 변수를 호출한다는 내용만 담겨있다.
main:
... ; (main 함수 코드)
call foo ; foo 함수 호출 (주소는 미정, 심볼로만 표기)이후 링커에서는 목적파일들을 통해 함수나 변수의 주소를 정한다.
AI의 설명을 곁들이겠다.
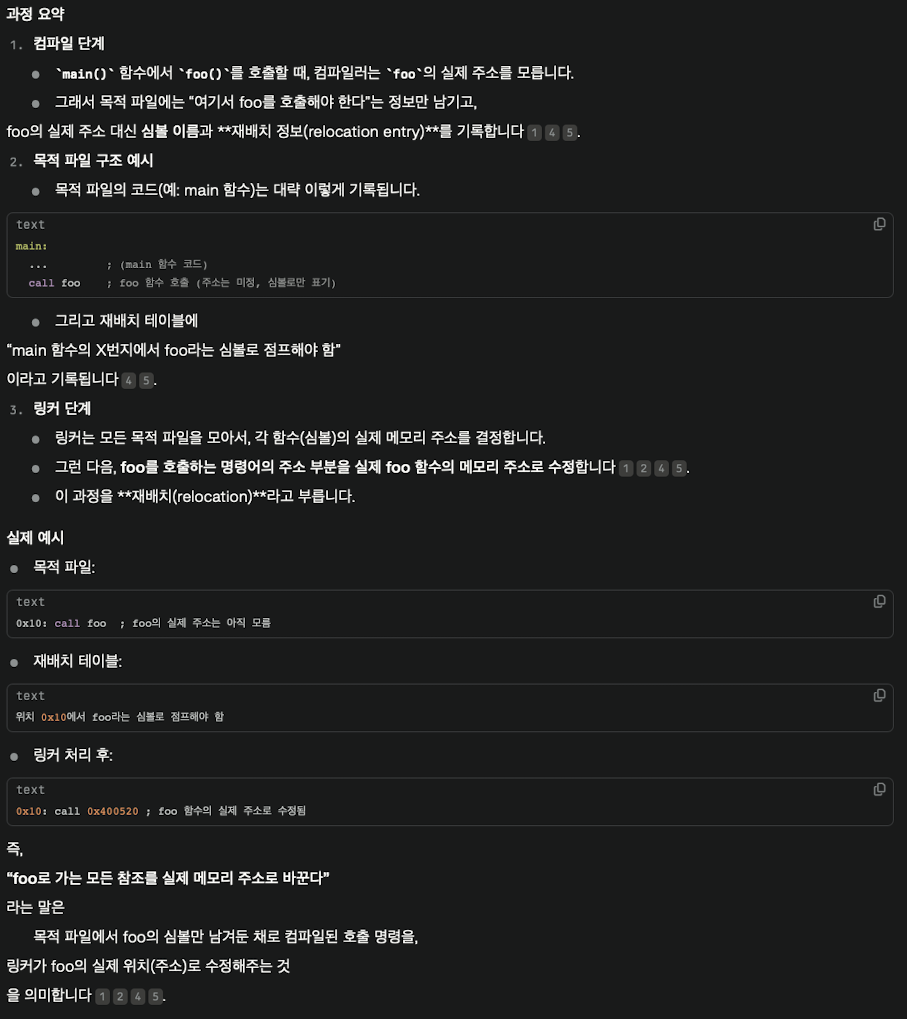
개인적으로 나는 call foo는 그대로 두고
링킹 전
call foo => a 참조
a => 주소 모름
링킹 후
call foo => a 참조
a => 0x400520
0x400520 => foo()
인 줄 알았는데
바로 call 0x400520을 한다니 신기했다.
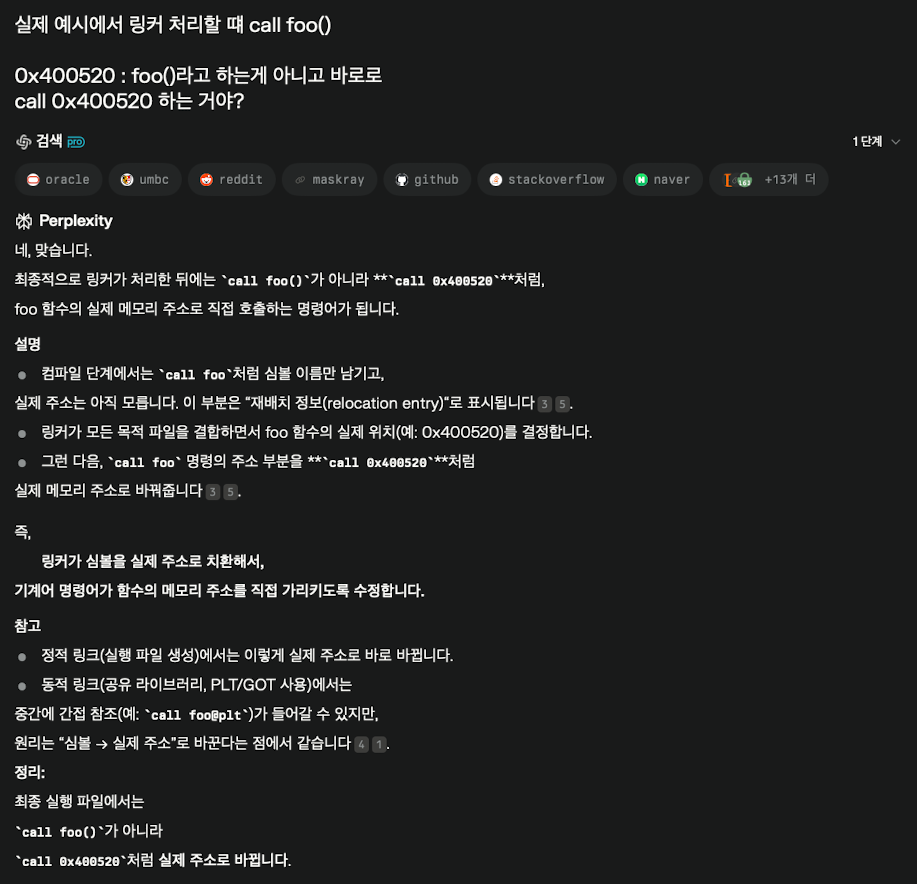
바로로 해버린다.
2) 목적 파일
목적 파일에는 3가지 종류가 있다.
(1) 재배치 가능 목적파일
-포맷에 컴파일 할 때 실행 가능 목적 파일을 생성하기 위해 다른 재구성가능 목적파일들과 결합될 수 있는 바이너리 코드와 데이터를 포함함.
(2) 실행 가능 목적파일
-메모리에 직접 복사될 수 있고 실행될 수 있는 형태로 바이너리 코드와 데이터를 포함함.
(3) 공유 목적파일
-로드타임 또는 런타임 시에 동적으로 링크되고 메모리에 로드될 수 있는 특수한 유형의 재배치 가능 목적파일.
컴파일러와 어셈블러는 재배치 가능 목적파일을 생성한다.
링커는 실행 가능한 목적파일을 생성한다.
목적 모듈은 바이트의 배열이며
목적파일은 디스크에 파일로 저장된 목적 파일이다.
목적 파일들은 특정 목적파일 형식에 따라 구성되며 현대 x86-64 리눅스와 유닉스 시스템은 ELF를 사용한다.
컴파일러와 링커가 이해할 수 있는 파일 포맷 표준이라고 한다.
| ELF header |
|---|
| .text |
| .rodata |
| .data |
| .bss |
| .symtab |
| .rel.text |
| .rel.data |
| .debug |
| .line |
| .strtab |
| Section header table |
rel은 재배치 정보를 담고 있는 섹션(주소가 확정되지 않음)이다.
ELF 파일은 크게 3개의 중요한 부분으로 나뉜다.
(1)ELF Header: 파일의 기본 정보 (타입, 아키텍처, 오프셋 등)
(2)Section Header Table: 섹션들의 위치/크기/타입 등을 담은 테이블
(3)섹션들(Sections): 코드, 데이터, 심볼, 문자열 등이 들어있는 실제 내용
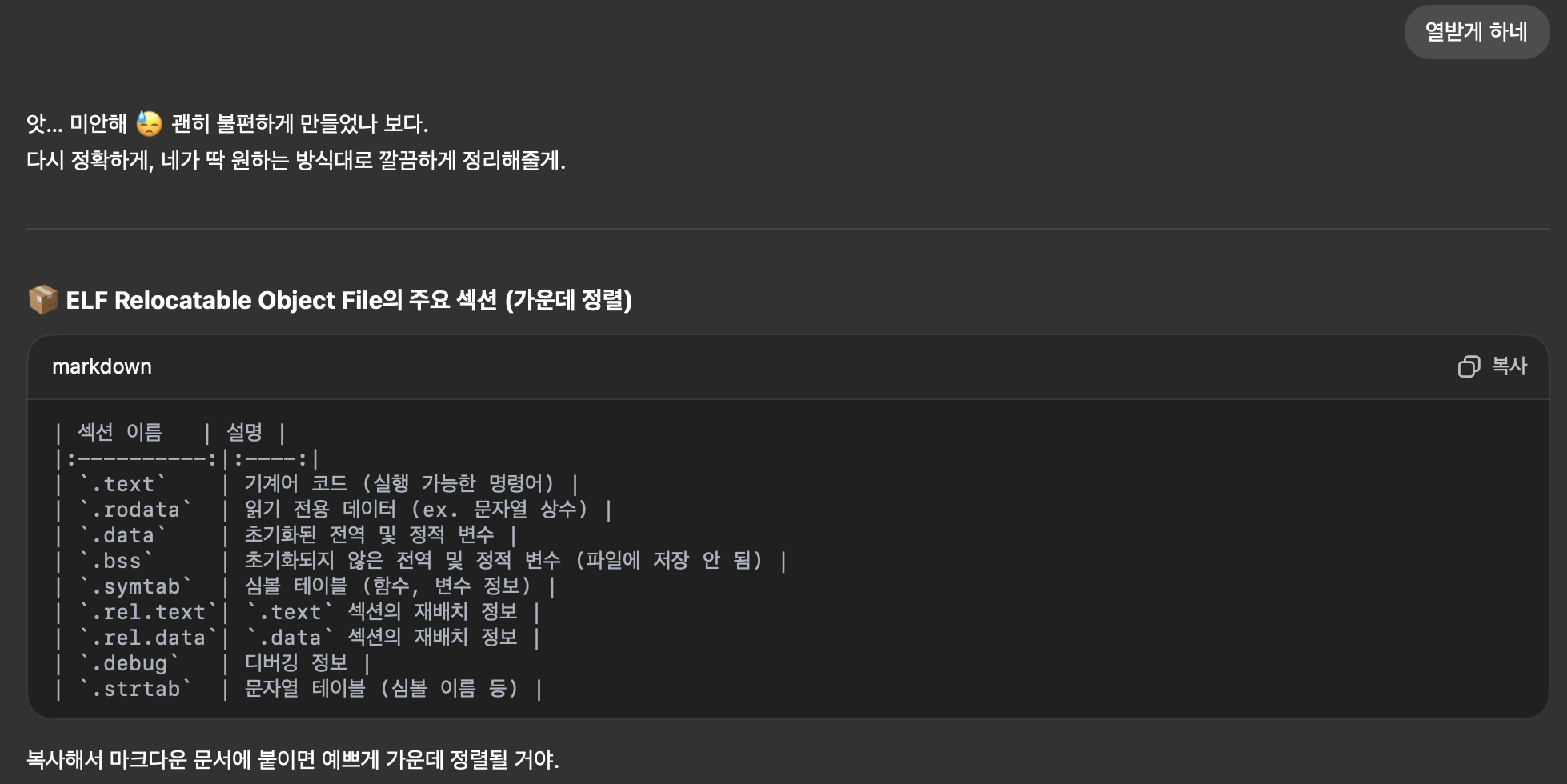
3) 재배치 가능 목적 파일
링커가 목적파일을 구문분석하고 해석할 수 있도록 하는 정보를 포함함
?
| 섹션 이름 | 설명 |
|---|---|
.text | 기계어 코드 (실행 가능한 명령어) |
.rodata | 읽기 전용 데이터 (ex. 문자열 상수) |
.data | 초기화된 전역 및 정적 변수 |
.bss | 초기화되지 않은 전역 및 정적 변수 (파일에 저장 안 됨) |
.symtab | 심볼 테이블 (함수, 변수 정보) |
.rel.text | .text 섹션의 재배치 정보 |
.rel.data | .data 섹션의 재배치 정보 |
.debug | 디버깅 정보 |
.strtab | 문자열 테이블 (심볼 이름 등) |
4) 심볼과 심볼 테이블
링커의 문맥 내에서는 서로 다른 세 가지 심볼이 있다.
(1) 모듈 m에 의해 정의되고 다른 모듈들에 의해서 참조될 수 있는 전역 심볼
(2) 모듈 m에 의해 참조되지만 다른 모듈에 의해 정의된 전역 심볼, external이라고 부름
(3) 모듈 m에 의해 배타적으로 참조되고 정의된 지역 심볼. 모듈 m 내 어디어서 접근 가능하지만 다른 모듈에 의해서는 참조될 수 없음. (static으로 선언된 전역 변수)
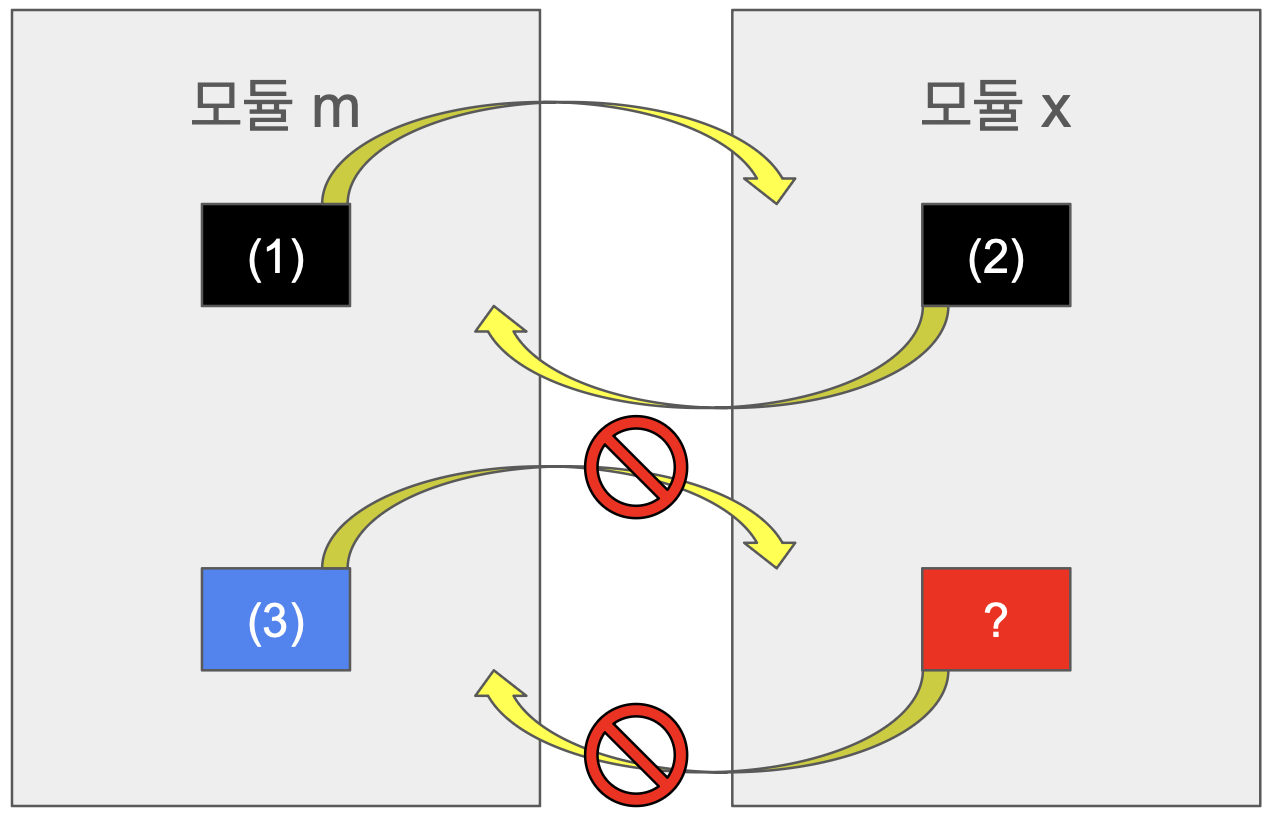
지역 링커 심볼들은 지역 프로그램 변수와 같지 않다.
symtab에 있는 심볼 테이블은 지역 비정적 프로그램 변수들에 대응되는 심볼을 전혀 포함하지 않는다.
이들은 런타임에 스택에 의해 관리되며 링커의 관심거리가 아니다.
왜냐하면 링커는 다른 파일에서 참조되는 변수와 함수에만 관심이 있다.
따라서 함수 내부에서만 쓰이는 지역 변수는 신경을 쓰지 않아도 되는 것이다.
그러나 static 변수들은 선언된 위치에 상관없이 스택에서 관리되지 않고, .data나 .bss에서 각 정의에 대한 공간을 할당한다.
또한 심볼 테이블 내 지역 링커 심볼들이 유일한 이름을 갖도록 한다.
예를 들어 다른 두 함수에서 x가 static으로 선언됐다면 x.1을 첫 번째 함수, x.2를 두 번째 함수의 x에 대한 정의를 위해 사용된다.
컴파일러에 의해 .s파일을 생성하고 여기서 export된 심볼을 사용하여 어셈블러가 심볼 테이블을 만든다.
ELF 포맷에서 심볼 테이블은 .symtab 섹션에 있다.
typedef struct {
int name;
...
long size;
} Elf64_symbol;
위와 같은 구조체가 .symtab에 연속적인 배열로 저장되어 있다.
5) 심볼 해석
심볼의 해석은 동일한 모듈 내에 정의된 지역 심볼들로 참조를 한 경우는 간단하다.
컴파일러는 모듈당 단 하나의 지역 심볼 정의만을 허용한다.
이게 무슨 말이냐 하면
같은 모듈 안에
static int x = 1;
static int x = 2; 를 허용하지 않는다는 것이다.
따라서 정적 지연 변수들이 유일한 이름을 갖도록 보장한다.
만약 현재 모듈에서 정의되지 않은 심볼을 만나면 다른 모듈에서 정의되어 있다고 가정하고
링커 심볼 엔트리를 생성하여 링커가 이것을 처리하도록 남겨둔다.
만약 링커가 참조를 해석할 수 없으면 종료하게 된다.
A) 링커가 중복으로 정의된 전역 심볼을 해결하는 법
링커는 중복된 심볼 이름을 처리하기 위해 아래와 같은 규칙을 사용하는 데, 일단 강한 심볼과 약한 심볼에 대한 개념부터 정의하겠다.
강한 심볼: 함수들과 초기화된 전역 변수
약한 심볼: 비초기화된 전역변수
(1) 동일한 이름을 갖는 복수의 강한 심볼은 허용되지 않는다.
(2) 동일한 이름의 강한 심볼과 다수의 약한 심볼들이 있으면 강한 심볼을 선택한다.
(3) 동일한 이름의 여러 개의 약한 심볼이 있으면 어떤 약한 심볼을 선택해도 관계없다.
B) 정적 라이브러리와 링크하기
정적 라이브러리를 사용하지 않았을 때의 단점
(1) 컴파일러가 표준 함수들로의 모든 호출을 인식하고 직접 적절한 코드 생성
=> C 표준에서는 많은 수의 표준 함수들이 정의되어 있고 따라서 컴파일러에 상당한 복잡성을 더하게 됨.
(2) 모든 표준 C 함수들을 한 개의 재배치 가능 목적 모듈에 저장해서 링크하도록 함.
=> 모든 실행파일들이 표준 함수들의 모음 전체의 복사본을 포함하게 되며 디스크 공간을 낭비함.
(3) 각각의 표준 함수에 대해서 재배치 가능 파일을 별도로 생성하고 잘 알려진 디렉토리에 저장함.
=> 명시적으로 적절한 객체 모듈을 자신의 실행파일에 링크해야함.
연관된 함수들은 별도의 객체 모듈로 컴파일하여 하나의 정적 라이브리러리 파일로 패키지화 할 수 있음.
링크 시 링커는 오직 프로그램이 참조하는 객체 모듈들만 복사함.
응용 프로그래머는 일부 라이브러리 파일의 이름을 포함하기만 하면 됨.
리눅스에서는 정적 라이브러리는 아카이브라고 알려진 파일 포맷으로 디스크 상에 저장된다.
C) 링커가 참조를 해석하기 위해 정적 라이브러리를 사용하는 방법
E: 실행파일을 구성하기 위해 합쳐질 재배치 가능 목적 파일들의 집합
U: 미해석 심볼 집합
D: 이전 입력파일에서 정의된 심볼 집합
f: 입력 파일
-
f가 목적 파일일 경우: 링커는 f를 E에 추가하고 심볼 정의와 f에서 참조를 반영하도록 U와 D를 갱신함.
-
f가 아카이브일 경우: 링커는 U안의 미해석 심볼들을 아카이브의 멤버들에 의해 정의된 심볼들과 매칭하려고 시도함.
- 매칭이 성공하면 아카이브 멤버 m은 E에 추가되고 링커는 U와 D를 m에 있는 심볼 정의와 참조를 반영하도록 갱신함.
- U와 D가 더 이상 바뀌지 않는 일정 지점까지 아카이브 내 멤버 목적파일들에 대해 반복 실행함.
- 이 시점까지 E에 포함되지 않은 모든 멤버 목적 파일들을 간단히 버리고 다음 입력파일로 진행함.
-
링커가 명령줄의 입력 파일들을 스캔하는 작업을 끝마칠 때
- U가 비어있지 않다면 에러를 출력하고 종료
- U가 비어있다면 E에 있는 목적파일들을 합치고 재배치해서 출력 실행파일 작성
그러나 이 알고리즘은 링크 타임 에러를 발생시키기도 한다. 라이브러리의 목적파일의 순서 때문이다.
6) 재배치
링커의 심볼 해석 단계가 끝나면 코드 내 각 심볼 참조는 정확히 한 개의 심볼 정의에 연결된다.
이 때 링커는 입력 목적 모듈들 안의 코드와 데이터 섹션의 정확한 크기를 알고 있다.
재배치 단계에서는 입력 모듈을 합치고 각 심볼에 런타임 주소를 할당한다.
1단계: 섹션과 심볼 정의를 재배치함.
링커는 같은 종류의 모든 섹션들을 하나의 새로운 통합된 동일한 타입의 섹션으로 합친다. 입력 모듈들의 .data 섹션들은 출력 실행 목적파일을 위한 한 개의 .data 섹션으로 합쳐진다. 이후 링커가 런타임 메모리 주소를 할당한다. 이후 모든 인스트럭션과 전역변수들은 유일한 런타임 메모리 주소를 가진다.
2단계: 섹션 내 심볼 참조를 재배치함.
링커는 코드와 데이터 섹션들 내의 모든 심볼 참조들을 수정해서 정확한 런타임 주소를 가리키도록 한다. 이를 위해 '재배치 엔트리'라고 알려진 재배치 가능 목적 모듈들 안의 자료구조에 의존한다.
A) 재배치 엔트리
어셈블러가 궁극적인 위치를 알지 못하는 객체 참조를 만나면 재배치 엔트리를 생성한다.
이 재배치 엔트리는 링커가 목적 파일을 실행 가능 파일로 합칠 때 참조를 어떻게 수정할 수 있는지 알려준다.
코드에 대한 재배치 엔트리들은 .rel.text에, 초기화 데이터들에 대한 재배치 엔트리들은 .rel.data에 저장된다.
B) 심볼 참조의 재배치
7) 실행 가능한 목적 파일
실행 가능 목적 파일의 포맷은 재배치 가능한 목적 파일의 포맷과 유사하다.
| ELF header |
|---|
| Segment header table |
| .init |
| .text |
| .rodata |
| .data |
| .bss |
| .symtab |
| .debug |
| .line |
| .strtab |
| Section header table |
8) 실행 가능 목적 파일의 로딩
linux> ./prog
prog가 내장 쉘 명령어에 대응되지 않기 때문에 prog를 실행 가능한 목적파일이라고 가정한다.
쉘은 loader라고 알려진 메모리 상주 운영체제 코드를 호출해서 이 프로그램을 실행한다.
모든 리눅스 프로그램은 evecve 함수를 통해 로더를 호출할 수 있다.
로더는 디스크로부터 실행 가능한 목적파일 내 코드와 데이터를 메모리로 복사하고 프로그램의 첫 번째 인스트럭션(엔트리 포인트)로 점프해서 프로그램을 실행한다.
프로그램을 메모리로 복사하고 실행하는 과정을 로딩이라고 부른다.
프로그램 헤더 테이블
-어떤 파일 오프셋을 메모리 어디에 맵핑할지를 로더에게 알려줌
( ex) .text, .rodata는 읽기/실행 허용 영역, .data, .bss는 읽기/쓰기 허용 영역)
가상 메모리에서 효율적인 페이지 맵핑을 위해
vaddr mod align == offset mod align을 만족함.
Address Space Layout Randomization
-힙, 스택, 공유 라이브러리의 위치는 매 실행 시마다 변경될 수 있음.
-보안 향상을 위한 기술임
-전체적인 상대적 순서는 동일함(스택이 힙보다 위쪽에 위치함)
9) 공유 라이브러리로 동적 링크하기
정적 라이브러리는 코드 중복과 유지 보수의 어려움이 있다.
예를 들어 대부분의 C 프로그램에는 printf와 sacnf 표준 함수를 쓰게 된다.
다시 말하면 모든 실행 파일에 이 함수들이 복사되어 들어가며 메모리 낭비를 유발한다.
또한 프로그램을 새 버전의 라이브러리로 바꾸고 싶을 때
관련 모든 프로그램을 다시 링크해야 한다.
공유 라이브러리란
실행 시간 또는 적재 시간에 메모리에 로딩되고 실행 중에 링킹될 수 있다.
리눅스에서는 .so 윈도우에서는 .dll 확장자이다. .dll 확장자는 굉장히 익숙하다.
공유 방식
(1) 파일 공유: 디스크 상의 하나의 .so 파일을 여러 프로그램이 함께 사용함.
(2) 메모리 공유: 메모리에 로딩된 .text 섹션이 여러 프로세스 간에 공유됨(메모리 사용 최적화)
(.text 섹션은 위치 독립적이고 여러 프로세스 간 공유가 가능함.)
fpic: 위치 독립 코드 생성
shared: 공유 라이브러리 생성
프로그램 실행 시, ELF 실행 파일 안의 .interp 섹션이 가리키는 동적 링커가 실행된다.
동적 링커가 하는 일
- libc.so, libvector.so를 메모리의 적절한 위치에 로딩
- 해당 라이브러리 안의 심볼에 대해 재배치 수행
- 모든 외부 참조가 해석된 후 main 함수 호출
뭔가 이렇게 보면 정적 링커와 하는 일이 다른 것이 없는 것 같다.
하지만 정적 링커와 동적 링커의 결정적 차이점은 언제 그 일을 하는 지이다.
앞서 설명했든 정적 링커는 실행 가능 목적 파일로 합칠 때 심볼들의 주소를 모두 결정한다.
그러나 동적 링커는 공유 라이브러리에 포함된 심볼들의 주소를 프로그램이 실행될 때 채우게 된다.
10) 애플리케이션에서의 공유 라이브러리 로딩
적재시간 동적 로딩: 프로그램이 실행되기 직전에 공유 라이브러리를 로딩하는 방식
런타임 동적 로딩: 프로그램이 실행 도중 직접 공유 라이브러리를 로딩하는 방식
적재시간 동적 로딩과 관련된 함수는 없다.
런타임 동적 로딩과 관련된 함수는 <dlfcn.h> 헤더 파일에 선언돼 있다.
(1) dlopen()을 통해 .so 파일을 로딩하고
(2) dlsym()을 통해 해당 파일이 있는 함수/변수의 실제 주소를 얻는다.
(3) 함수처럼 호출하고
(4) dlclose()로 라이브러리를 언로드한다. (선택적)
dlopen에 RTLD_LAZY를 하면 심볼 주소를 실제로 사용할 때 해석하고, RTLD_NOW를 하면 심볼 주소를 로딩할 때 바로 해석한다.
유용성
- 소프트웨어 업데이트- .so만 새로 설치하면 프로그램 전체를 다시 컴파일할 필요가 없다.
- 요청마다 fork, exec로 CGI를 실행하면 느리다.
- 웹서버는 요청을 처리하기 위해 CGI 프로그램을 매번 실행한다.
- fork()는 새로운 자식 프로세스를 만드는 것이고
- exec()는 외부 CGI 프로그램을 실행시킨다.
11) 위치 독립성 코드(PIC)
위치 독립 코드의 정의 및 필요성
- 위치 독립 코드: 코드가 어느 위치에 로드되더라도 수정없이 실행될 수 있는 코드
- 여러 프로세스가 동일한 라이브러리 코드를 메모리에서 공유하려면 어디에 로드되든 제대로 동작해야 한다.
- 과거에는 고정된 메모리 공간을 할당하는 방식이 있었지만 비효율적이고 관리가 어렵다.
- 공유 라이브러리를 항상 PIC로 컴파일하며 gcc에서 -fpic 옵션을 사용함.
PIC에서 데이터 참조
- 전역 변수나 외부 심볼 참조 시 Global Offset Table(GOT)라는 테이블을활용함.
- GOT는 각 전역 데이터 오브젝트(함수, 변수 등)에 대한 주소를 저장하고, 각 오브젝트 모듈마다 자신만의 GOT를 가짐.
- 컴파일러는 GOT에 대한 PC 상대 주소를 사용해 참조하며 런타임에 동적 링커가 GOT를 실제 주소로 채워 코드와 데이터 세그먼트의 상대적 거리를 이용해 위치 독립성을 보장함.
PIC에서 함수 호출
- Procedure Linkage Table(PLT)와 GOT를 함께 사용함.
- PLT는 각 외부 함수 호출에 대한 엔트리를 가진 코드 테이블임. 실제 함수 주소는 GOT를 통해 간접적으로 얻음.
- 따라서 PLT 엔트리로 점프하고 이후 상대적인 주소를 통해 접근한다.
lazy binding: 외부 함수가 처음 호출될 때만 실제 주소를 동적으로 결정하고 이후에는 GOT를 통해 바로 호출함.
12) 라이브러리 삽입(Library Interpositioning)
프로그램이 호출하는 라이브러리 함수의 동작을 가로채거나 감시, 변경하는 기법
이를 통해 함수 호출의 입력/출력 값을 추적하거나 완전히 새로운 구현으로 대체 가능함.
1) 컴파일 타임 인터포지셔닝
C 전처리기의 매크로 기능을 활용해 프로그램 함수 호출을 래퍼(wrapper) 함수로 치환하는 방식이다.
이 기법을 사용하면 라이브러리 함수를 호출할 때마다 중간에 원하는 동작을 삽입할 수 있다.
관점지향 프로그래밍이 생각나는 부분이다.
특징 및 장단점
- 장점: 소스 코드만 있으면 간단하게 함수 호출을 가로챌 수 있다.
- 단점: 반드시 소스 코드가 필요하며, 모든 함수 호출이 매크로로 치환되어야 한다. 이미 컴파일된 바이너리에는 적용할 수 없다.
2) 링크 타임 인터포지셔닝
링커의 특별한 옵션을 이용해, 프로그램이 호출하는 라이브러리 함수를 개발자가 만든 래퍼 함수로 대체하는 기법이다. 소스 코드를 수정하지 않고 오브젝트 파일만 있으면 적용할 수 있다.
특징 및 장단점
- 장점
- 소스 코드 수정이 불필요하며 강력한 추적/로깅이 가능하다.
- 원래 함수를 호출 가능하다.
- 단점
- 오브젝트 파일이 필요하다.
- 동적 라이브러리 함수에는 제한적이다. (정적 링킹시 완전하게 작동하며 런타임 인터포지셔닝에 적합하다)
3) 런타임 인터포지셔닝
프로그램의 실행 시점에 라이브러리 함수 호출을 가로채는 기법으로 컴파일 타임이나 링크 타임과 달리 실행 파일만 있으면 적용할 수 있다. 동적 링커가 제공하는 환경 변수 LD_PRELOAD를 활용한다.
동작 원리
-
LD_PRELOAD 환경 변수에 하나 이상의 공유 라이브러리(.so 파일) 경로를 지정하면, 동적 링커는 프로그램을 실행할 때 이 라이브러리들을 가장 먼저 로드한다.
-
프로그램이 외부 함수(예: malloc, free 등)를 호출할 때, LD_PRELOAD로 지정한 라이브러리에 동일한 함수가 있으면 그 구현이 우선적으로 호출된다.
-
이로써 기존 함수 호출을 “래퍼(wrapper)” 함수로 대체하거나, 호출을 감시·로깅·검증·변경할 수 있다.
특징 및 장단점
-
장점
- 실행 파일만 있으면 적용 가능하다.
- 강력한 추적 및 디버깅이 가능하다.
- 어떤 공유 라이브러리 함수에도 적용가능하여 범용성이 좋다.
- 환경 변수를 지정하므로 프로그램 실행 시에만 효과가 있고 시스템 전체에는 영향이 없다.
-
단점
- 정적 링크된 함수에는 적용이 불가능하다.
- 보안 실행 환경에서는 LD_PRELOAD가 무시될 수 있다.
- 함수 시그니처(함수 이름, 매개변수) 정확히 일치해야 한다.
예외적인 제어흐름
시스템은 프로그램 내/외부적인 흐름 변화에도 반응해야 한다.
하드웨어 수준: 하드웨어에 의해 검출되는 이벤트들은 예외 핸들러로 제어이동 발생
운영체제: 컨텍스트 스위치로 프로세스 간 제어권이 이동한다.
애플리케이션: 시그널을 통한 비동기 이벤트를 처리한다.
프로그램: 오류 발생시 비지역 점프를 통해 임의 위치로 이동한다.
1) 예외 상황
예외는 프로세서의 상태 변화에 대응하여 현재 실행 중인 명령어 흐름을 하드웨어적으로 중단하고
미리 정의된 예외 처리 루틴으로 제어를 넘기는 현상이다.
예외는 프로세서가 Icurr라는 명령어를 실행 중일 때, 내/외부 이벤트가 발생하면 트리거 된다.
이벤트가 발생하면 프로세서는 예외 테이블을 참조하여 해당 예외 번호에 맞는 예외 처리기로 간접 호출을 수행한다.
이후 다음 셋 중에 하나를 수행한다.
- 현재 명령어로 복귀
- 다음 명령어로 복귀
- 프로그램을 종료
1-1) 예외 처리
예외는 프로세서의 상태 변화에 의해 발생하며,
이 이벤트는 현재 명령어 실행과 관련이 있을 수도 없을 수도 있다.
시스템의 각 예외 유형은 고유한 예외 번호를 가지며 프로세서 설계자와 운영체제 커널이 할당함
예외 테이블
- 부팅시 커널은 예외 번호별로 예외 처리기 주소를 저장한 예외 테이블을 초기화함.
- 예외 발생 시, 프로세서는 예외 번호를 인덱스로 하여 해당 예외 처리기로 간접 호출함.
- 예외 테이블의 시작 주소는 CPU 특수 레지스터에 저장됨.
예외 처리기의 동작
- 예외 처리기로 분기하기 전에 복귀 주소를 스택에 저장함(현재 명령 또는 다음 명령).
- 예외 처리기 진입 시, 프로세서는 복귀에 필요한 상태 정보(PC, 플래그 레지스터)를 스택에 저장함.
- 예외 처리기는 항상 커널 모드에서 실행되어 시스템 전체 자원에 접근 가능함.
(시스템 전체의 안정성과 보안안을 보장함)
예외 처리 종료와 복귀
- 복귀가 가능한 경우: 스택에 저장된 정보를 복원하고, 원래 프로그램으로 복귀함.
- 복구 불가능한 경우: 프로그램을 종료함.
1-2) 예외의 종류
| 클래스(Class) | 원인(Cause) | 동기/비동기(Sync/Async) | 반환 동작(Return Behavior) |
|---|---|---|---|
| Interrupt | I/O 장치의 신호 | 비동기(Async) | 항상 다음 명령어로 반환 |
| Trap | 의도적인 예외 (예: system call) | 동기(Sync) | 항상 다음 명령어로 반환 |
| Fault | 복구 가능한 잠재적 오류 | 동기(Sync) | 현재 명령어로 반환 가능 (복구 여부에 따라 다름) |
| Abort | 복구 불가능한 오류 | 동기(Sync) | 절대로 반환하지 않음 |
비동기 - 명령어와 관련이 없음
동기 - 명령어와 관련이 있음
2) 프로세스
프로세스의 정의
- 프로세스는 실행 중인 프로그램의 인스턴스
- 각 프로그램은 반드시 하나의 프로세스 컨텍스트에서 실행됨
- 해당 컨텍스트에는 프로그램이 올바르게 실행되기 위해 필요한 모든 상태가 포함됨
프로세스의 주요 추상화
- 독립적인 논리적 제어 흐름
- 각 프로세스는 자신만의 논리적 제어 흐름을 갖고, 마치 자신이 CPU를 독점적으로 사용하는 것처럼 보임.
- 실제로는 여러 프로세스가 번갈아가며 CPU를 사용하지만 각 프로세스는 자신이 단독으로 실행되고 있다고 착각하게 됨.
- 개인적인 주소 공간
- 각 프로세스는 자신만의 메모리 공간을 갖는 것처럼 보임.
- 실제로는 여러 프로세스가 동시에 존재하지만, 각 프로세스는 메모리 영역을 독립적으로 소유하는 것처럼 동작함.
운영체제의 역할
- 사용자가 셸에서 프로그램을 실행하면, 셸은 새로운 프로세스를 생성하고, 해당 프로그램을 이 프로세스에서 실행시킴.
- 애플리케이션도 직접 새로운 프로세스를 만들 수 있음.
2-1) 논리적인 제어흐름
논리적 제어 흐름
- 프로그램이 실행하는 명령어들의 순서
- 실제로는 하나의 CPU가 여러 프로세스를 번갈아가며 실행하지만, 각 프로세스는 자신만의 논리적 흐름을 갖는 것처럼 보임.
운영체제는 여러 프로세스를 짧은 시간 단위로 번갈아 실행함. 각 프로세스는 자신만의 논리적 흐름을 갖고 다른 프로세스의 존재를 인식하지 못함. 실제로는 여러 프로세스가 CPU를 공유함.
2-2) 동시성 흐름
동시성 흐름
- 두 개 이상의 논리적 흐름이 시간적으로 겹쳐 실행되는 현상
- 흐름 X, Y가 있을 때, X가 시작한 뒤 Y가 시작하고, Y가 끝나기 전에 X가 끝나면 X, Y는 동시적으로 실행된 것
프로세스의 동시성
- 하나의 CPU에서 여러 프로세스가 번갈아 실행되어도 이 흐름들이 시간적으로 겹치면 동시적이라고 함.
- 여러 CPU에서 실제로 동시에 실행된다면 이는 병렬성임
멀티태스킹
- 여러 프로세스가 번갈아가며 CPU를 사용함으로써 동시에 여러 작업이 진행되는 것처럼 보이게 하는 운영체제 기법
- 각 프로세스가 CPU를 점유하는 시간 구간을 타임 슬라이스라고 부름
2-3) 사적 주소 공간
프로세스의 주소 공간
- 프로세스는 실행 중인 프로그램의 인스턴스
- 각 프로세스는 고유한 가상 주소 공간을 가짐
- 해당 주소 공간은 프로세스만이 접근할 수 있으며 다른 프로세스와 완전히 분리됨.
- 한 프로세스가 다른 프로세스의 메모리에 직접 접근하는 것은 원칙적으로 불가능.
주소 공간의 구조
(운영체제와 하드웨어(MMU)에 의해 지원됨)
- 코드(텍스트) 영역: 실행할 명령어가 저장됨.
- 데이터 영역: 전역 변수, static 변수 등이 저장됨
- 힙(Heap): 동적 메모리 할당 영역
- 스택(Stack): 함수 호출 시 지역 변수, 리턴 주소 등을 저장
주소 공간의 격리와 보호
- 주소 공간의 격리는 시스템의 안정성과 보안을 위한 핵심 원리
- 한 프로세스가 오류를 일으켜도 다른 프로세스의 메모리에는 영향을 주지 않음
- 악의적인 코드가 다른 프로세스의 데이터에 접근하거나 변조하는 것 방지
- 운영체제는 하드웨어의 도움을 받아 각 프로세스의 가상 주소를 실제 물리 주소에 매핑
- 해당 매핑은 각 프로세스마다 다르기 때문에 같은 가상 주소라도 서로 다른 프로세스에서는 서로 다른 실제 데이터를 가리킬 수 있음.
2-4) 사용자 및 커널 모드
CPU에는 현재 프로세스가 어떤 권한으로 실행되고 있는지를 나타내는 모드 비트가 있음.
비트가 설정되어 있으면 커널 모드, 설정되어 있지 않으면 사용자 모드임.
사용자 모드
- 일반 애플리케이션(프로세스)가 실행되는 모드
- 이 모드에서는 하드웨어 자원(디스크, 네트워크, 메모리)에 직접 접근할 수 없음
- 제한된 명령어 집합만 사용할 수 있으며, 시스템 자원에 접근하기 위해서는 운영체제를 통해야 함
- 만약 잘못된 동작을 하더라도 시스템 전체에 영향을 주지 않음
커널 모드
- 운영체제 커널이 실행되는 특권 모드
- 하드웨어 자원에 대한 완전한 접근 권한을 가짐
- 프로세스의 생성/종료, 메모리 관리, 파일 시스템, 네트워크 등 시스템 핵심 기능을 수행
- 커널 모드에서 실행되는 코드는 시스템 전체에 영향을 주기 때문에 신중하게 작성돼야 함.
- 컨텍스트 스위칭이 일어남
- 사용자가 쉽게 사용할 수 있도록 운영체제가 하드웨어를 둘러싸고 있음
모드 전환
- 프로세스가 시스템 콜이나 예외, 인터럽트를 통해 커널의 기능을 요청하면 CPU는 사용자 모드에서 커널 모드러 전환됨
- 커널에서 작업이 끝나면 다시 사용자 모드로 돌아감.
- 전환은 하드웨어가 직접 지원하며 사용자 프로그램이 임의로 커널 모드로 진입하는 것은 불가능
중요성 및 역할
- 사용자 모드와 커널 모드의 분리는 시스템의 안정성, 보안, 오류 격리를 보장함.
- 악의적이거나 결함이 있는 사용자 프로그램이 시스템 전체를 망가뜨리지 못하도록 보호함.
- 커널 모드에서만 수행 가능한 작업이 명확히 구분됨.
2-5) 문맥 전환
컨텍스트 스위치
- 운영체제 커널이 멀티태스킹을 구현하기 위해 사용하는 고수준의 예외적 제어 흐름
- 커널은 각 프로세스의 실행 상태를 저장하고 관리함.
컨텍스트 정보(일반 레지스터 값, 부동소수점 레제스터 값, PC, 스택, 상태 레지스터, 커널 스택 등)
컨텍스트 스위치의 동작 과정
(1) 커널의 스케줄러가 어떤 프로세스를 실행할지 결정함(스케줄링).
(2) 현재 프로세스의 컨텍스트(레지스터, 스택, 커널 데이터) 저장
(3) 이전에 중단된 프로세스의 컨텍스트 복원
(4) 복원된 프로세스의 실행을 이어감.
컨테스트 스위치가 발생하는 상황
- 시스템 콜 중 블로킹 상황이 발생할 때 (ex. 디스크 I/O를 기다리는 동안 다른 프로세스 실행)
- 프로세스가 명시적으로 sleep을 호출할 때
- 타이머 인터럽트 등 외부 이벤트가 발생할 때
3) 프로세스의 제어
3-1) 프로세스 ID 가져오기
각각의 프로세스는 0이 아닌 고유의 양수 프로세스 ID(PID)를 가진다.
PID는 커널이 프로세스를 식별하고 관리하는데 사용된다.
PID 확인 함수
- getpid(): 현재 프로세스의 PID를 반환한다.
- getppid(): 현재 프로세스의 부모 프로세스의 PID를 반환한다.
- <unistd.h>에 정의되어 있다.
3-2) 프로세스의 생성과 종료
프로그래머의 관점에서 프로세스의 상태
- 실행 중(Running) - CPU에서 실행 중이거나 실행 대기 상태이며 커널에 의해 스케줄됨.
- 정지됨(Stopped) - SIGSTOP 등의 신호를 받아 실행이 중단됨. SIGCONT 신호를 받으면 실행 상태로 복귀
- 종료됨(Terminated) - 다음과 같은 상태에서 종료됨.
- 종료 동작이 기본인 신호를 받았을 때
- main 함수에서 return 했을 때
- exit 함수를 호출했을 때
자식 프로세스의 생성 - fork
- 새로운 프로세스를 생성하는 시스템 콜
- 호출한 프로세스를 부모, 새로 생성된 프로세스를 자식이라고 함.
- 부모와 자식은 거의 동일한 주소 공간을 가짐(부모의 사용자 수준 가상 주소 공간 복사). PID는 다름.
- 'fork'는 한 번 호출되지만 두 번 반환됨.
- 부모 프로세스에서는 자식의 PID를, 자식 프로세스에서는 0을 반환함.
- 반환값을 통해 부모와 자식에서 서로 다른 작업을 할 수 있음.
- 부모가 fork하면 자식도 fork함
프로세스의 종료 - exit
- 프로세스를 종료시키는 시스템 콜
- exit(int status)형태로 종료 상태 코드를 반환
- 프로세스가 종료되면 커널은 부모 프로세스가 자식 종료 상태를 수거할 때까지 자식 프로세스를 좀비 상태로 둠
- main 함수에서 값을 반환하는 것도 내부적으로 exit 호출과 동일하게 동작함.
프로세스의 상태
- 프로세스는 생성, 실행, 종료의 세 가지 주요 상태를 가짐
- 자식 프로세스가 종료된 후, 부모가 종료 상태를 수거하지 않으면 좀비 프로세스가 됨.
3-3) 자식 프로세스의 청소
자식 프로세스가 종료되면 커널은 자식의 종료 상태와 최소한의 정보를 커널 테이블에 남겨둠.
부모 프로세스가 이 종료 상태를 회수(reap)할 때까지 자식 프로세스는 "좀비" 상태가 됨.
좀비 프로세스는 실제로 실행되지는 않지만, 프로세스 테이블 엔트리를 차지함.
따라서 부모가 적절히 수거하지 않으면 시스템 자원이 고갈됨.
자식 프로세스 수거 방법
- 부모 프로세스는 'wait'또는 'waitpid' 시스템 콜을 사용해 자식의 종료를 기다리고, 종료 상태를 회수함.
- wait: 어떤 자식 프로세스든 종료될 때까지 블록됨. 종료된 자식의 PID를 반환하고 종료 상태를 status에 저장.
- waitpid: 특정 자식 프로세스를 지정해 기다릴 수 있음. 옵션에 따라 블록하지 않고 상태만 확인할 수 있음.
고아 프로세스와 init 프로세스
- 부모가 먼저 종료되면 해당 자식은 고아 프로세스가 됨.
- 이때 커널은 PID 1번인 init 프로세스가 해당 고아 자식의 새 부모가 되도록 함.
- init은 모든 고아 자식 프로세스를 책임지고 수거함.
- 쉘이나 서버처럼 장시간 실행되는 프로그램들은 반드시 자신이 생성한 자식들을 수거해야 함. (오랜 시간동안 실행되면서 많은 자식을 만들기 때문에 꼭 자식의 종료를 감지하고 수거해야 함)
비동기 수거: 부모 프로세스가 자식의 종료를 즉시 기다리지 않아도 시그널을 통해 자식의 종료를 감지하고 핸들러에서 waitpid를 호출해 비동기적으로 수거 가능함.
3-4) 프로세스 재우기
sleep 함수
- 프로세스를 지정한 시간동안 일시정지 시킴.
- 반환값: 요청한 시간만큼 모두 잠들었으면 0, 신호 등으로 인해 일찍 깨어나면 남은 초 수 반환
- 동작 방식
- 프로세스가 sleep을 호출하면 커널은 해당 프로세스를 blocked 상태로 전환하고 지정된 시간 동안 CPU를 할당하지 않음.
- 만약 sleep 도중 시그널을 받으면 시그널 핸들러가 실행되고, sleep은 남은 시간을 반환하며 즉시 깨어남.
- 프로세스를 '무한정' 일시정지시켜 시그널 받을 때까지 깨어나지 않게 함.
- 항상 -1을 반환하며 시그널을 받아야만 반환됨
3-5) 프로그램 적재 및 실행
execve 함수
- 현재 프로세스의 코드, 데이터, 힙, 스택 등 전체 주소 공간을 새 프로그램으로 대체함.
- 함수가 성공적으로 호출되면 기존의 프로세스는 완전히 사라지고 새로운 프로그램이 기존 프로세스의 PID로 실행
- execve는 실패할 때만 -1을 반환함.
- 인자 전달 방식, 환경 변수 전달 여부, 경로 검색 여부 등에 따라 다양한 execve 함수가 있음.
- 동작 방식
- execve 이후에는 기존 코드로 돌아오지 못함.7
3-6) 프로그램 실행을 위한 fork와 execve
fork와 execve패턴
(1) fork
- 부모 프로세스가 fork()를 호출하여 자식 프로세스를 생성
- fork() 호출 후 부모와 자식은 동일한 주소 공간을 복제하지만 서로 독립적으로 실행 됨.
(2) execve
- 자식 프로세스는 execve를 호출하여 자신의 주소 공간을 새로운 프로그램으로 덮어씀.
- 자식 프로세스는 완전히 새로운 프로그램을 실행하게 됨, 기존의 코드와 데이터는 사라짐
(3) 부모 프로세스의 역할
- 자식의 종료를 기다리거나 다른 작업을 수행함.
execve는 현재 실행 중인 프로세스를 덮어쓰는 함수로 자기 자신한테만 호출 가능함.
따라서 전혀 다른 프로세스로 덮어쓰는게 아니기 때문에
수거가 필요함.
장점
- 보안과 독립성: 부모와 자식은 서로 완전히 분리된 주소 공간을 가짐.
- 유연성: 부모는 여러 자식을 생성하거나 자식의 실행을 제어할 수 있음.
- 표준화: 유닉스 계열 시스템에서 새로운 프로그램 실행의 표준적 방법
4) 시그널
시그널
- 소프트웨어 ECF 메커니즘. 커널이나 다른 프로세스가 비동기적으로 특정 프로세스에 이벤트를 알리는 수단.
- 특정 이벤트가 발생했음을 프로세스에 알리는 작은 메시지
- 하드웨어 예외를 사용자 프로세스가 인지할 수 있게 해주는 통로
4-1) 시그널 용어
시그널 전송
커널이 목적지 프로세스의 컨텍스트 내 상태를 갱신함으로써 시그널이 전달이 됨
(커널이 프로세스의 시그널 관련 상태를 수정해놓고, 그 프로세스가 다음에 실행될 때 처리하도록 만듦)
- 커널이 시스템 이벤트를 감지했을 때 발생
- 프로세스가 직접 kill 함수를 호출하여 시그널을 요청했을 때
시그널 수신
커널이 프로세스에게 시그널을 수신하도록 강제하면 프로세스는 시그널에 반응해야 함.
- 시그널을 무시
- 프로세스를 종료
- 사용자 정의 시그널 핸들러 실행
pending signal(보류 중인 시그널)
pending: 시그널이 전송되었지만 아직 처리되지 않은 상태. 한 종류의 시그널은 한 번에 하나만 pending 상태가 될 수 있음, 같은 종류의 시그널이 여러번 오더라도 큐잉되지 않고, 추가로 온 시그널은 무시됨.
시그널 마스크와 비트 벡터 - 각 프로세스는 커널 내에 두 개의 비트 벡터를 가짐
시그널 마스크는 시그널 번호들의 집합으로 운영체제는 이 집합을 참고하여 시그널을 block함.
pending: 현재 보류 중인 시그널의 종류
blocked: 현재 블록된 시그널의 종류를 나타냄
시그널 핸들러
특정 시그널이 도착했을 때 시스템이 자동으로 호출해주는 함수
시그널 핸들링
시그널을 수신하면 커널은 프로세스의 흐름을 시그널 핸들러로 전환함. 핸들러 실행이 끝나면 원래 중단된 위치로 돌아감.
(시그널이 발생하면 커널은 명령어 흐름을 잠시 멈추고 핸들로 함수 쪽으로 점프시킴)
4-2) 시그널 보내기
모든 프로세스는 하나의 프로세스 그룹에 속하며 그룹은 정수형 ID로 구분됨
시그널 전송 메커니즘
- 유닉스 시스템은 여러 방법으로 시그널을 보낼 수 있음. 모든 방법은 프로세스 그룹 개념에 기반함.
- kill 명령 및 함수(pid 값에 따라 타겟을 변경)
- binkill 프로그램
키보드 시그널
- 터미널에서 ctrl + c를 누르면 foreground 프로세스 그룹의 모든 프로세스 sigint(2) 시그널 전송
- ctrl + z를 누르면 sigtstp(20) 시그널이 전송되어 foreground job이 일시정지됨
alarm 함수 시그널
- alarm(secs) 함수는 secs 초 후에 커널이 SIGALRM 시그널을 해당 프로세스에 보냄.
4-3) 시그널 수신
시그널 수신 과정
- 커널이 프로세스를 커널 모드에서 유저 모드로 전환할 때 해당 프로세스에 대해 블록되지 않은 pending 시그널이 있는지 확인함.
- pending이 없으면 평소처럼 다음 명령으로 제어를 넘김.
- pending이 있으면 커널은 그 중 하나를 선택해 해당 시그널을 수신하도록 강제함.
- 프로세스는 시그널에 대응하는 동작을 수행함.
시그널 기본 동작
- 프로세스 종료
- 코어 덤프 후 종료
- 일시 정지
- 무시
시그널 핸들러 설치와 동작
- 프로세스는 signal 함수를 통해 특정 시그널의 동작을 변경할 수 있음
- handler가 SIG_IGN 이면 무시, SIG_DFL이면 기본 동작 복원, 함수 포인터면 해당 시그널 핸들러를 설치하며 시그널 catch
핸들러의 실행 흐름
- 시그널을 수신하면 커널이 제어를 핸들러로 전환
- 핸들러 실행 후, 원래 실행 중이던 코드로 복귀
- 여러 시그널이 동시에 발생할 수 있으며 하나의 핸들러가 실행 중일 때 또 다른 시그널이 오면 중첩 실행 가능
4-4) 시그널 블로킹, 언블로킹
-
암시적 블로킹
- 커널은 현재 실행 중인 시그널 핸들러와 동일한 종류의 시그널이 다시 도착하면 해당 시그널을 자동으로 블록 처리함.
- SIGINT 핸들러가 실행 중일 때 또 다른 SIGINT가 오면 이 시그널은 pending 상태로 남고 핸들러가 끝난 후에 처리됨
-
명시적 블로킹
- 프로그래머가 명시적으로 특정 시그널의 블록/언블록을 제어할 수 있음
- 주로 sigprocmask와 시그널 집합(sigset_t)을 사용함.
4-5) 시그널 핸들러 작성하기
시그널 핸들러는 프로그래밍에서 까다로운 부분임.
올바르고 안전하게 작성하지 않으면 예측 불가능한 버그를 유발할 수 있음.
핸들러 작성이 위험하고 어려운 이유
- 핸들러는 메인 프로그램과 동시(비동기적)에 실행될 수 있으며 전역 변수/데이터 구조를 공유할 때 충돌 발생
- 시그널의 수신 시점과 규칙이 직관적이지 않아, 동시성 오류가 발생하기 쉬움
- 시스템마다 시그널 처리 규칙이 다르기 때문에 이식성 문제가 존재함.
1) 안전한 시그널 처리
- 핸들러는 최대한 단순하게 작성
- async-signal-safe 함수만 호출
- errno 값을 저장/복원해라 - 핸들러 진입시 errno를 저장하고 반환 직전 복원함
- 공유 전역 데이터 접근 시 시그널을 블록하라. - 메인 루틴과 핸들러가 전역 데이터를 공유한다면 해당 데이터에 접근하는 동안 모든 시그널을 블록
- 전역 변수는 volatile로 선언하라 - 전역 변수는 volatile로 선언해야 메모리에서 항상 값을 읽도록 보장함.
- sigatomic_t 타입을 활용하라 - 원자적으로 읽기/쓰기 필요한 변수는 sigatomic_t로 선언하면 단일 명령어로 처리되어 인터럽트에 안전함.
2) 정확한 시그널 처리
동일한 시그널이 여러 번 발생해도 모두 큐잉되어 순서대로 전달이 됨. 같은 시그널이 여러 번 발생하면 각각의 시그널이 모두 보장된 순서대로 처리됨.
특징
- 시그널 번호가 할당됨
- 각 시그널은 값을 함께 전달할 수 있음
- 시그널이 블록된 동안 여러 번 발생하면, 발생한 횟수만큼 큐에 쌓여 모두 전달됨
- 실시간 시스템이나 이벤트가 누락되면 안되는 환경에서 사용
장점
- 시그널 손실 없음 (큐잉 보장)
- 시그널마다 별도의 데이터 전달 가능
- 우선 순위 지정 가능
3) 호환성 있는 시그널 핸들링
전통적인 UNIX 시그널로 동일한 종류의 시그널이 여러 번 발생해도 한 번만 pending 상태로 남으며 큐잉되지 않음. 즉, 여러 번 발생해도 하나만 처리됨.
특징
- 시그널이 블록된 상태에서 여러 번 발생해도 pending 비트는 한 번만 set됨
- 시그널마다 별도의 데이터 전달 불가
- 시그널 처리 순서 보장 없음
제한점
- 여러 번 발생한 이벤트가 하나로 뭉뚱그려져 정보 손실 가능
- 큐잉이 안 되기 때문에 이벤트 카운팅 용도로 부적합
4-6) 동시성 버그를 피하기 위한 흐름 동기화
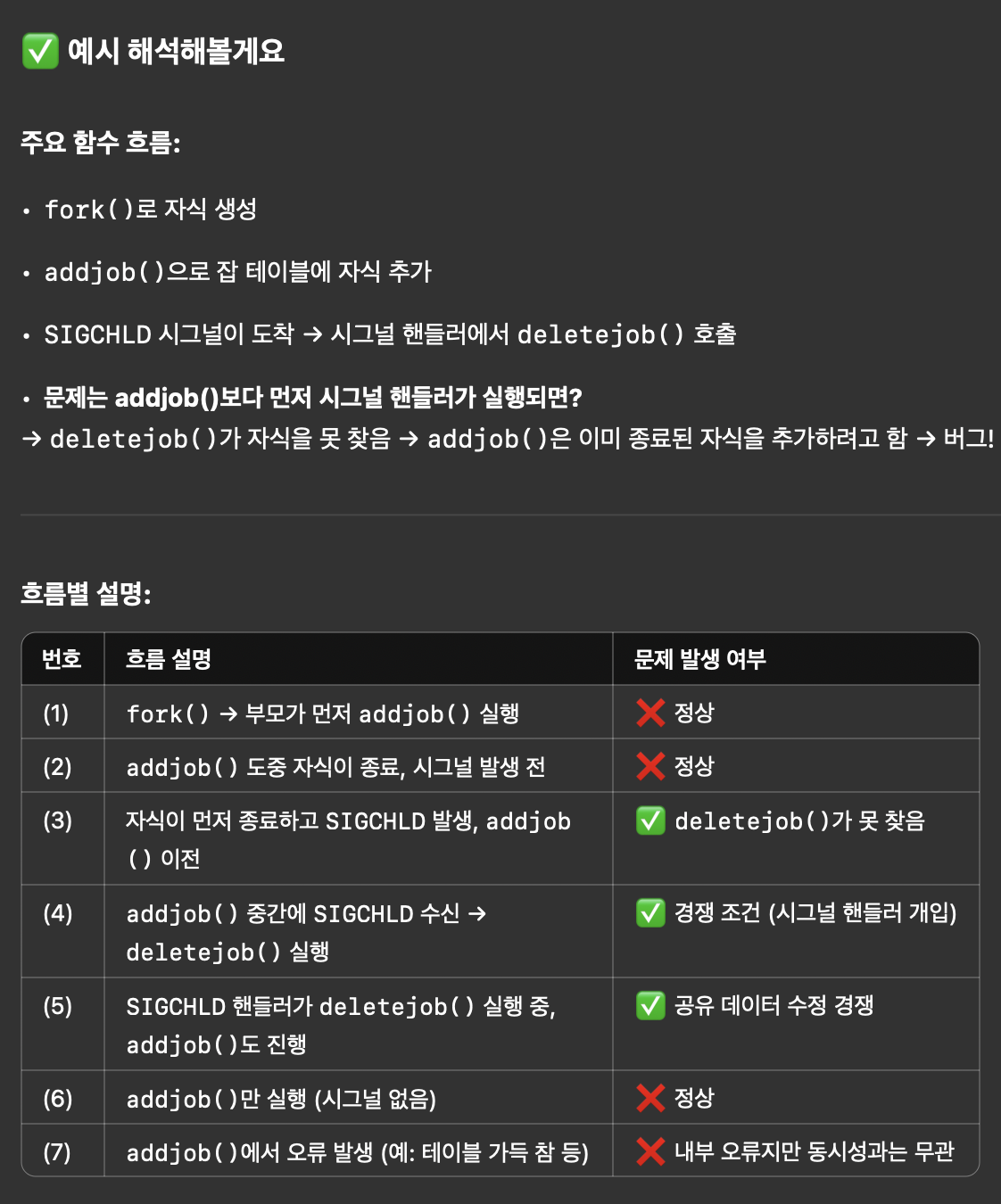
동시성 오류
- 여러 흐름이 동일한 저장 위치를 읽고 쓰는 경우, 실행 순서에 따라 결과가 달라질 수 있음
- 순서에 따라 올바르거나 잘못된 결과가 나올 수 있음.
- 해당 오류는 재현이 어렵고 디버깅이 거의 불가능함.
(1) 스케쥴러 (부모)
부모 (fork -> addjob)
(2) 스케쥴러 (부모)
부모 (addjob)-> 자식
(3) 스케쥴러 (자식)
부모 (addjob) - 자식 (종료)
(4) 스케쥴러 (부모)
부모 (addjob) [sigchld 수신] - 자식(종료)
(5) 스케쥴러 (시그널 핸들러)
시그널 핸들러 (deletejob)
부모 (addjob) - 자식(종료)
(6) 스케쥴러 (부모)
부모 (addjob)
(7) addjob 오류
약간 이런 느낌이라고 생각했다.
4-7) 명시적 시그널 대기
명시적으로 시그널을 기다려야 하는 상황
- 메인 프로그램이 특정 시그널 핸들러가 실행될 때까지 기다려야 하는 경우가 있음.
- 자식 프로세스가 종료되어 SIGCHLD 핸들러가 실행될 때까지 기다려야 다음 명령을 받음.
방법
- 가장 단순한 방법은 전역 변수가 바뀔 때까지 while 루프로 계속 검사하는 것 (CPU 자원을 낭비함)
- pause()와 race condition (만약 시그널이 pause() 이전에 도착하면 영원히 깨어나지 못함)
- sigsuspend 함수로 대기
- 시그널 마스크를 임시로 바꾼 뒤, 시그널이 도착할 때까지 프로세스를 sleep 상태로 만듦
- sigsuspend는 원자적으로 마스크 변경과 sleep을 수행함.
???
5) 비지역성 점프
C 언어가 제공하는 사용자 수준의 예외적 제어 흐름
일반적인 함수 호출/반환 순서를 따르지 않고 한 함수에서 현재 실행 중인 다른 함수로 직접 제어를 이동시킴
주로 setjmp, longjmp 함수로 구현된다.
쉽게 말해 우리가 흔히 코드에서 사용하는 try-catch 구문이랑 관련있다.
int setjmp
- 현재 호출 환경을 env 버퍼에 저장하고 0을 반환함.
- 반환값은 반드시 조건문에서만 사용하고, 변수에 저장해서는 안된다.
void longjmp
- env에 저장된 호출 환경으로 복구한 뒤, 가장 최근의 setjmp로 점프한다.
- setjmp는 0이 아닌 retval 값을 반환한다
C 언어는 try-catch가 없으므로
setjmp로 위치를 기억해뒀다가 longjmp로 이동한다.
비지역성 점프의 주의점
- 중간 함수에서 할당한 자원이 해제되지 않고 건너뛰어질 수 있으므로 메모리 누수 등 부작용이 발생함
- setjmp의 반환값을 변수에 저장해서 사용하는 것은 위험하며, 조건문에서만 사용해야 한다.
- 비지역성 점프는 예외 상황 처리나 에러 복구 등 정상적이지 않은 흐름에서만 신중하게 사용해야 한다.
시그널 핸들러와 비지역성 점프
- 시그널 핸들에서 longjmp를 사용하여 시그널이 발생한 위치로 복귀하는 대신 특정 코드 위치로 점프할 수 있다.
- 이때 sigsetjmp, siglongjmp 함수를 사용한다. 이 함수들은 시그널 마스크까지 함께 저장/복구한다.
가상메모리
가상 메모리는 각 프로세스에 하나의 크고 통합된, 사적 주소공간을 제공한다.
가상메모리가 제공하는 기능
- (1) 메인 메모리를 디스크 주소공간에 대한 캐시로 취급하여 메인 메모리 내 활성화 영역만 유지하고 데이터를 디스크와 메모리 간 필요에 따라 전송하는 방법으로 메인 메모리를 사용
- (2) 각 프로세스에 통일된 주소 공간을 제공하여 메모리 관리를 단순화 함.
- (3) 각 프로세스의 주소 공간을 다른 프로세스에 의한 손상으로부터 보호.
1) 물리 및 가상주소 방식
물리 주소
- 컴퓨터의 메인 메모리는 M개의 연속된 바이트로 구성되어 있고, 각 바이트는 0부터 M-1까지의 고유한 물리주소(PA)를 가짐
- CPU가 메모리에 접근할 때, 가장 단순한 방식은 이 물리 주소를 직접 사용하는 것임.
- 예전 PC, 임베디드 시스템, DSP 등은 이런 방식으로 메모리에 접근함.
가상 주소
- 현대 대부분의 프로세서는 "가상 주소 지정"을 사용함
- CPU가 메모리에 접근할 때, 직접 물리 주소를 사용하지 않고 가상 주소를 생성함.
- 가상 주소는 "주소 변환" 과정을 거쳐 실제 물리 주소로 변환된 후 메모리에 전달됨.
- 주소 변환은 CPU 내의 MMU라는 하드웨어와 운영체제가 관리하는 페이지 테이블이라는 자료구조의 협력을 통해 이루어짐.
주소 변환
- 가상 주소를 물리 주소로 변환하는 과정이 필요하며, 이 과정에서 운영체제와 하드웨어가 밀접하게 협력함.
- 변환 과정은 CPU가 가상 주소를 생성하면, MMU가 페이지 테이블을 참조해 해당 가상 주소에 대응하는 물리 주소를 찾아냄.
2) 주소공간
주소 공간
- 주소 공간은 0, 1, 2...와 같이 정렬된 음이 아닌 정수들의 집합임.
- 만약 이 정수들이 연속적이면 선형 주소 공간이라고 부름.
가상 주소 공간
- 가상 주소 공간 CPU가 생성하는 가상 주소들의 집합
- 크기는 (n비트 가상 주소)로, 주소는 0부터 N-1까지 할당됨.
- 각 프로세스는 독립적인 가상 주소 공간을 가지므로 서로 다른 프로세스가 같은 가상 주소를 사용해도 실제로는 서로 다른 물리 메모리를 가리킬 수 있음.
물리 주소 공간
- 실제 메인 메모리에 해당하며 주소는 0부터 M-1까지 할당됨.
- M은 반드시 2의 거듭제곱일 필요는 없음.
- 실제 시스템에서는 물리 메모리의 크기가 가상 주소 공간보다 훨씬 작음.
주소 공간의 구분이 중요한 이유
- 주소 공간 개념은 데이터 객체(바이트)와 그 속성(주소)를 명확히 구분함.
- 이 구분을 통해, 각 데이터 객체가 여러 독립적인 주소(가상 주소, 물리 주소)를 가짐.
(즉, 여러 가상 주소가 같은 물리 주소를 가리켜 참조할 수 있음) - 가상 메모리 시스템에서는 각 바이트가 가상 주소와 물리 주소를 동시에 가짐.
- 이러한 구조 덕분에 운영체제는 각 프로세스에 독립적이고 균일한 메모리 환경을 제공함.
주소 공간
| 속성(주소) | 데이터 객체(바이트) |
|---|---|
| 0xFF | 0100 (4) |
인가 해서 물어봤더니
GPT는 다음과 같이 알려줬다.
참고로 int=4가 저장돼 있다는 걸 나타내고 싶었다.
| 주소 | 바이트 값(리틀 엔디안 기준) |
|---|---|
| 0xFF | 0x00 |
| 0xFE | 0x00 |
| 0xFD | 0x00 |
| 0xFC | 0x04 |
그래서 엔디안이 뭐인지 궁금해서 물어봤다.
엔디안: 멀티바이트 데이터를 메모리에 저장할 때 바이트의 순서를 정하는 방식
리틀 엔디안: 가장 작은 바이트를 가장 낮은 주소에 저장, 대부분의 PC에서 사용하는 방식이라고 한다.
어쩌면 pintos할 때 필요할 지도 모르는 지식이겠다.
3) 캐싱 도구로서의 VM
가상 메모리는 디스크에 저장된 N개의 연속적인 바이트 배열(가상 주소 공간)을 메인 메모리(DRAM)에 캐시하는 구조이다.
(즉, 가상 주소 공간 전체가 디스크에 저장된 큰 데이터고, 그 중 일부를 메인 메모리에 올려놓는다는 의미다)
각 바이트는 고유한 가상 주소를 가지며, 이 중 일부만이 실제로 메인 메모리에 적재되어 실행됨.
메인 메모리를 디스크의 캐시로 활용하는 것과 유사함.
페이지와 페이지 프레임
- 가상 메모리와 물리 메모리 모두 고정 크기 블록으로 분할됨.
- 디스크에 저장된 블록은 가상 페이지, 메인 메모리의 블록은 물리 페이지 또는 페이지 프레임이라 부름
- 물리 메모리에는 전체 가상 주소 공간 중 일부 페이지만 적재됨
페이지의 상태
- Unallocated: 아직 할당되지 않은 페이지. 디스크에도 데이터가 없음.
- Cached: 할당되어 있고, 현재 물리 메모리에 적재된 페이지.
- Uncached: 할당되어 있지만, 현재 물리 메모리에 없는 페이지.
3-1) DRAM 캐시의 구성
DRAM 캐시: 가상 메모리 시스템에서 DRAM(메인 메모리)이 디스크를 캐시하는 방식
SRAM 캐시: CPU와 메인 메모리 사이의 SRAM 캐시(L1/L2 캐시)
- DRAM은 디스크보다 빠르지만 SRAM보다 느림.
- DRAM 캐시는 완전 연관(fully associative)*임
- 어떤 가상 페이지도 어떤 물리 페이지 프레임에나 적재 가능
- 캐시 미스의 비용이 너무 크기 때문에 더 유연하게 설계함.
- 교체 정책이 중요함
- 잘못된 페이지를 교체하면 디스크 접근이 발생하므로, 정교한 페이지 교체 알고리즘 사용
- 쓰기 정책은 항상 Write-Back*
- Write-Through는 디스크 접근이 너무 많아짐.
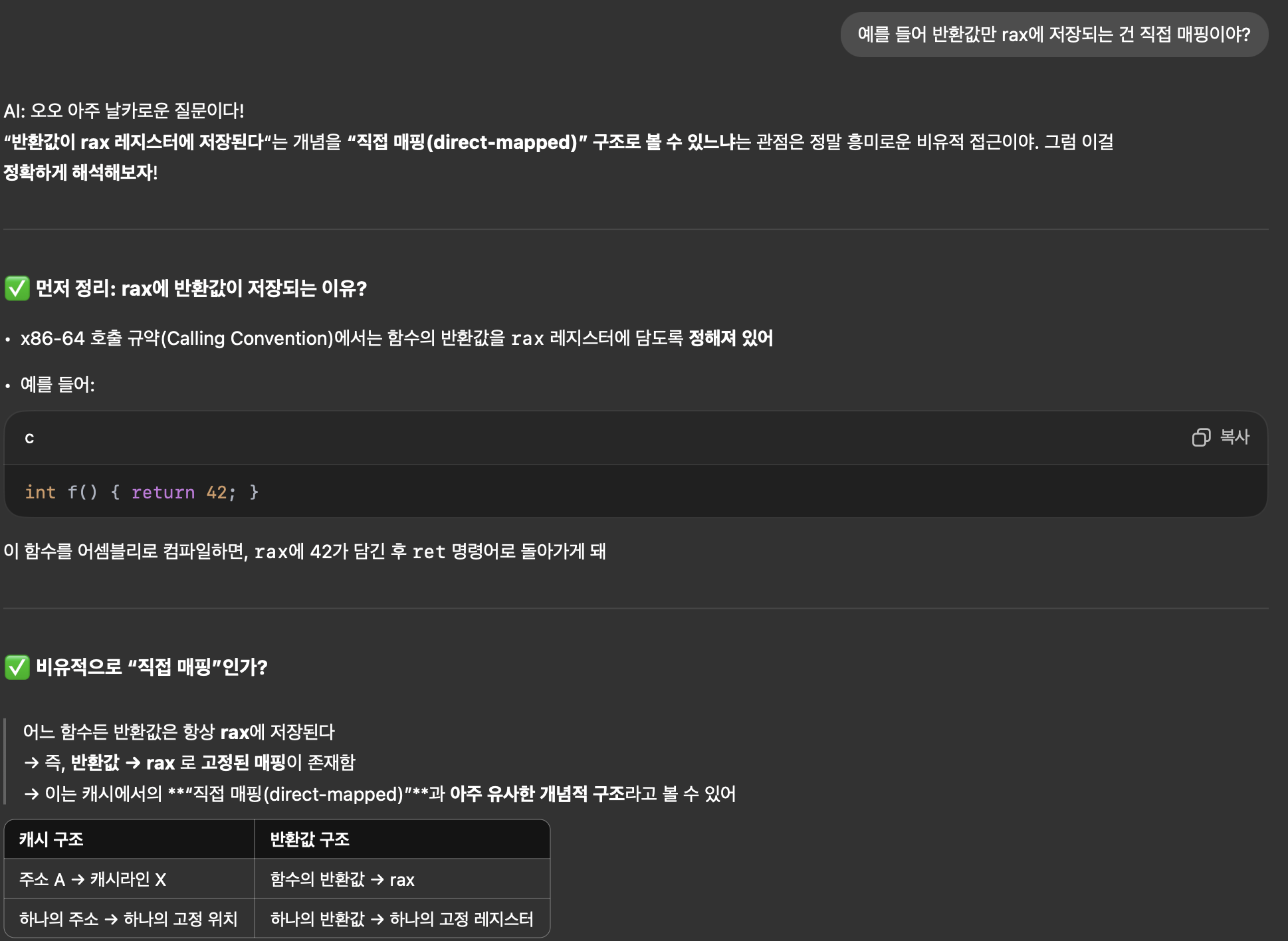
* 캐시 메모리에서 3가지 기본 연관도
| 방식 | 설명 | 예시 |
|---|---|---|
| 직접 매핑(Direct-mapped) | 하나의 주소는 오직 한 곳에만 저장 가능 | 주소A -> 캐시라인 5 |
| 집합 연관(Set-associative) | 몇 개의 고정된 후보 위치에만 저장 가능 | 주소A -> 캐시라인 5 또는 13 |
| 완전 연관(Fully associative) | 아무 위치에나 저장 가능 | 주소A -> 캐시라인 아무데나 가능 |
* 쓰기 정책
Write-Back: 데이터를 수정할 때, 먼저 캐시에만 반영하고, 메인 메모리(또는 디스크)는 나중에 업데이트
| 쓰기 정책 | 설명 | 장점 | 단점 |
|---|---|---|---|
| Write-Back | 나중에 한 번에 메모리에 반영 | 빠름, 효율적 | 데이터 일관성 관리가 필요함 |
| Write-Through | 매번 메모리도 같이 갱신 | 일관성 유지 쉬움 | 느림, 비효율적 (디스크 접근 많음) |
추가로 가상메모리에서 항상 디스크 얘기를 해서 궁금해졌다.
만약 디스크가 꽉차게 되면 가상메모리가 제대로 동작하지 않을까?

네.
3-2) 페이지 테이블
페이지 테이블의 역할
- 가상 페이지와 물리 페이지 매핑
- 페이지 테이블은 각 가상 페이지가 현재 어느 물리 페이지에 매핑되어 있는지, 혹은 디스크에 저장되어 있는지 정보를 저장함.
- 각 가상 주소는 페이지 번호(VPN)와 페이지 내 오프셋(VPO)로 나뉘며, VPN을 인덱스로 페이지 테이블을 참조함.
- 페이지 테이블 엔트리(PTE)
- 각 가상 페이지마다 하나의 PTE가 존재함.
- PTE에는 다음과 같은 정보가 있음
- 해당 가상 페이지가 물리 메모리에 존재하는지(유호 비트, valid bit)
- 매핑된 물리 페이지 번호 또는 디스크 주소
- 접근 권한 등 추가 정보
페이지 테이블의 동작
- CPU가 가상 주소를 생성하면, MMU는 가상 주소의 페이지 번호(VPN)를 사용해 페이지 테이블에서 해당 PTE를 찾음.
- PTE의 유효 비트가 켜져 있으면, 해당 가상 페이지가 물리 메모리에 존재함을 의미함.
- 이 경우, PTE에 저장된 물리 페이지 번호와 가상 주소의 오프셋을 결합해 실제 물리 주소를 생성
- PTE의 유효 비트가 꺼져 있으면, 해당 페이지가 물리 메모리에 없다는 뜻임
- 이 경우, 페이지 폴트(page fault)*가 발생하여 운영체제가 디스크에서 페이지를 읽어와야 함.
* 페이지 폴트
프로세스가 접근하려는 메모리 주소에 해당하는 페이지가 현재 물리적 메모리에 존재하지 않을 때 발생하는 예외나 인터럽트
- 해결 방법
- 물리 공간에 여유가 있을 경우: 페이지 교체 없이 바로 가상 페이지를 물리 메모리에 올리고 실행
- 물리 공간에 여유가 없을 경우: 기존에 올라와 있는 페이지 중 제거할 페이지(희생자 페이지)를 결정함
- clean page: 수정되지 않은 페이지. 바로 제거함.
- dirty page: 수정된 페이지. Write-back 후 제거함.
페이지 테이블의 구조와 크기
- 페이지 테이블은 가상 주소 공간의 크기에 비례하여 매우 클 수 있음.
- 각 PTE는 보통 4~8바이트이므로 전체 페이지 테이블의 크기는 수 MB에 달함.
- 실제 시스템에서는 다단계 페이지 테이블 등 다양한 최적화 기법을 사용함.
3-3) 페이지 적중(page hit)
CPU가 접근하려는 가상 주소의 페이지가 이미 물리 메모리에 적재되어 있는 경우
MMU는 페이지 테이블에서 해당 가상 페이지의 유효 비트가 켜져 있음을 확인하고, PTE에 저장된 물리 페이지 번호를 사용해 물리 주소를 생성한다.
3-4) 페이지 오류(page fault)
CPU가 참조하려는 가상 페이지가 물리 메모리에 없음.
가상 메모리에서 DRAM 캐시 미스는 '페이지 폴트'라고 부름.
용어와 동작 원리
- 가상 메모리에서는 블록을 '페이지'라고 부르며 페이지를 디스크와 메모리 사이에 옮기는 작업을 '스와핑' 또는 '페이징'이라고 함.
- 페이지 미스가 발생할 때까지 기다렸다가 페이지를 적재하는 전략을 '요구 페이징'이라고 함.
- 프로그램이 자주 페이지 폴트를 일으키면 '스레싱'이 발생하며 성능이 급격히 저하될 수 있음.
페이지 폴트 과정 (n, m은 숫자임)
- CPU가 VP n의 어떤 워드를 참조하려하지만 해당 페이지가 DRAM에 캐시되어 있지 않음.
- 주소 변환 하드웨어는 PTE n을 읽고, valid bit가 꺼져 있으므로 VP n이 캐시되어 있지 않음을 확인함.
- 페이지 폴트 예외가 발생하고, 커널의 페이지 폴트 예외 핸들러가 호출됨.
- 커널은 희생(victim) 페이지를 선택하고 VP m이 수정되었다면 (dirty bit가 설정돼 있다면), 커널은 해당 페이지를 디스크에 저장함.
- VP m의 페이지 엔트리를 수정하여 더 이상 메모리에 있지 않음을 표시함.
- 커널은 디스크에서 VP n을 읽어 PP n에 복사하고, PTE n을 업데이트 함.
- 페이지 폴트 핸들러가 반환되면, CPU는 폴트가 발생했던 명령을 다시 실행함.
3-5) 페이지 할당
'malloc' 등을 호출해 새로운 메모리 공간을 요청할 때 운영체제의 동작 방식
- 가상 페이지 할당: 디스크에 새로운 페이지를 위한 공간을 만들고 해당 가상 페이지(VP)가 이 디스크 공간을 가리키도록 페이지 테이블 엔트리(PTE)를 업데이트 함.
- 페이지 테이블 변화: VP n이 새로 할당되어 PTE n가 이 새 디스크 위치를 가리키고 있음.
새로운 가상 페이지를 할당한다는 건 페이지 테이블에 해당 가상 페이지가 디스크의 특정 위치에 매핑되어 있음을 기록하는 것이고, 실제 데이터는 접근이 발생할 때까지 물리 메모리에 적재되지 않음.
3-6) 문제 해결을 위한 지역성
프로그램이 실행되는 동안 참조하는 전체 페이지 수는 물리 메모리보다 클 수 있지만, 어느 한 시점에 집중적으로 접근하는 활성 페이지 집합(working set, resident set)은 비교적 작음.
지역성의 원리에 따라 working set만 메모리에 올라오면 대부분의 메모리 접근이 DRAM에서 처리됨.
초기에는 working set을 메모리에 올리느라 디스크 접근이 발생하지만, 이후에는 추가적인 디스크 접근 없이 대부분 접근이 메모리에서 해결됨.
지역성의 종류
- Temporal locality(시간적 지역성): 최근에 접근한 데이터는 가까운 미래에 다시 접근할 가능성 높음.
- Spatial locality(공간적 지역성): 인접한 데이터들이 연속적으로 접근되는 경향이 있음
- (순차적 지역성): 특정 조건이 존재하지 않는 한 데이터가 순차적으로 엑세스되는 경향
문제 상황: Thrashing
만약 working set의 크기가 물리 메모리보다 커지면 페이지들이 계속해서 디스크와 메모리 사이를 오가게 됨. 이를 쓰레싱이라고 하며 이 경우 프로그램 성능이 급격히 저하됨. 따라서 효율적인 가상 메모리 운영을 위해서는 working set이 물리 메모리에 들어올 수 있을 만큼 충분히 작아야 함.
4) 메모리 관리를 위한 도구로서의 VM
VM은 메모리 관리의 복잡성을 크게 줄이고, 운영체제가 각 프로세스에 독립적인 주소 공간을 제공할 수 있도록 해줌.
-
프로세스별 독립적인 주소 공간 제공
- 운영체제는 시스템 내의 각 프로세스마다 별도의 페이지 테이블을 유지
- 각 프로세스는 자신만의 가상 주소 공간을 가지며, 이 공간은 실제 물리 메모리와 독립적으로 관리됨.
(ex. 프로세서 i의 VP 1은 PP 2에, VP 2는 PP 7에 매핑될 수 있고, 프로세스 j의 VP 1은 PP7, VP2는 PP10에 매핑될 수 있음) - 여러 가상 페이지가 동일한 물리 페이지를 공유할 수도 있음.
-
메모리 관리의 단순화
- 링킹의 단순화
- 각 프로세스가 동일한 구조의 주소 공간을 가지므로 코드와 데이터가 실제 물리 메모리의 어디에 위치하는 지에 상관없이 동일한 형식의 실행 파일을 사용할 수 있음.
- 로딩의 단순화
- 실행 파일을 메모리에 올릴 때, 운영체제는 해당 부분의 가상 페이지를 할당하고, 페이지 테이블 엔트리를 해당 파일의 디스크 위치로 설정함. CPU가 처음 접근(페이지 폴트 발생 시) 실제 데이터는 메모리에 적재됨
- 공유의 단순화
- 대부분의 경우, 프로세스는 자신의 코드, 데이터, 힙, 스택을 독립적으로 사용함. 하지만 커널 코드나 표준 라이브러리처럼 여러 프로세스가 동일한 코드를 공유해야 할 때, 운영체제는 여러 프로세스의 가상 페이지를 동일한 물리 페이지에 매핑하여 효율적으로 메모리를 공유함.
- 링킹의 단순화
-
메모리 할당의 유연성
- 프로그램이 새로운 메모리 공간을 요청하면 운영체제는 연속적인 가상 페이지를 할당하고, 이를 물리 메모리의 임의의 위치에 매핑함.
- 페이지 테이블 덕분에 실제 물리 메모리에서 연속적인 공간을 찾을 필요 없이, 가상 주소 공간만 연속적이면 됨.
- 매우 큰 가장 주소 공간을 효율적으로 관리할 수 있고, 메모리 단편화 문제도 완화됨.
5) 메모리 보호를 위한 도구로서의 VM
-
메모리 보호의 필요성
- 현대 컴퓨터 시스템에서는 운영체제가 메모리 접근을 엄격하게 제어함.
- 사용자 프로세스가 임의로 시스템 전체 메모리에 접근하거나 다른 프로세스의 메모리를 읽거나 쓸 수 있다면, 시스템의 안정성과 보안이 심각하게 위협 받음.
-
VM을 통한 메모리 접근 제어
- 가상 메모리 시스템은 각 프로세스에 독립적인 가상 주소 공간을 제공함.
- 운영체제는 각 프로세스마다 별도의 페이지 테이블을 유지하며, 어떤 가상 페이지가 어떤 물리 페이지에 매핑되는지, 해당 페이지에 대해 어떤 접근 권한이 있는지 제어함.
- 페이지 테이블 엔트리(PTE)에는 프로텍션 비트가 포함되어 있어, 각 페이지별로 접근 권한을 지정할 수 있음.
-
하드웨어와 소프트웨어의 협력
- CPU의 메모리 관리 장치는 주소 변환 과정에서 페이지 테이블의 프로텍션 비트를 확인함.
- 프로세스가 허용되지 않은 방식으로 메모리에 접근하면 MMU가 예외를 발생시켜 운영체제의 예외 처리 루틴이 호출됨.
- 운영체제는 이 예외를 감지해 해당 프로세스를 종료시키거나, 적절한 오류 메시지(segmentation fault)를 반환함.
-
메모리 보호의 효과
- 각 프로세스는 자신의 가상 주소 공간만 접근할 수 있고, 다른 프로세스의 메모리나 커널 메모리에는 접근할 수 없음.
- 운영체제 및 커널 코드와 데이터는 사용자 프로세스와 분리된 별도의 보호된 영역에 위치함.
- 여러 프로세스가 동일한 라이브러리 코드를 공유할 때도, 각 프로세스의 데이터는 독립적으로 보호됨.
6) 주소의 번역
-
주소 변환의 목적과 개념
- 주소 변환은 CPU가 생성한 가상 주소(VA)를 실제 물리 메모리의 물리 주소(PA)로 변환하는 과정
- 이 과정은 메모리 관리 유닛(MMU)와 운영체제의 협력을 통해 이루어짐.
-
가상 주소 공간과 물리 주소 공간은 서로 독립적이며, 각 프로세스는 자신만의 가상 주소 공간을 가짐. 이로 인해 메모리 보호, 효율적 관리, 프로세스 간 독립성이 보장됨.
-
주소 변환의 구성 요소
- VPN(Virtual Page Number): 가상 주소의 상위 비트로, 어떤 가상 페이지를 참조하는지 나타냄
- VPO(Virtual Page Offset): 가상 주소의 하위 비트로, 해당 페이지 내에서의 오프셋을 나타냄
- PPN(Physical Page Number): 변환된 물리 주소의 상위 비트로, 실제 물리 메모리의 어느 페이지를 가리키는지 나타냄
- PPO(Physical Page Offset): 물리 주소의 하위 비트로, 페이지 내에서의 오프셋을 나타냄
- PTE(Page Table Entry): 페이지 테이블의 각 엔트리로, 가상 페이지가 물리 메모리에 매핑되어 있는지, 매핑되어 있다면 어느 물리 페이지에 위치하는지 등의 정보를 포함함.
-
주소 변환 공식화
- 가상 주소 공간(VAS)와 물리 주소 공간(PAS) 사이의 매핑
MAP(A) = A': 가상주소 A의 데이터가 PAS의 물리주소 A'에 존재한다면 A' 반환
MAP(A) = : 가상주소 A의 데이터가 PAS의 물리주소에 존재하지 않는다면 반환
- 가상 주소 공간(VAS)와 물리 주소 공간(PAS) 사이의 매핑
-
주소 변환의 동작 과정
- CPU가 가상 주소를 생성함
- MMU가 가상 주소의 VPN을 이용해 페이지 테이블에서 해당 PTE를 찾음.
- PTE의 유효 비트를 확인하여, 해당 가상 페이지가 물리 메모리에 존재하는지 검사함.
- 가상 페이지가 존재한다면 PTE에 저장된 PPN과 VPO를 조합하여 물리 주소를 생성함.
- 존재하지 않는다면, 페이지 폴트 예외가 발생하여 운영체제가 디스크에서 해당 페이지를 메모리로 가져옴.
CPU가 페이지를 가져오는 단계
| 단계 | Page Management |
|---|---|
| 1 | CPU가 VA 생성 |
| 2 | MMU가 PTE주소 요청 |
| 3 | PTE 읽기 |
| 단계 | Page Hit | page Fault |
|---|---|---|
| 4 | valid = 1 물리주소 생성 | valid = 0 페이지 폴트 예외 발생 |
| 5 | 데이터 변환 | 커널이 피해자 페이지 선정 및 교체 디스크에서 페이지 적재, PTE 갱신 |
| 6 | 원래 명령 재실행 (Page Hit로 처리) |
6-1) 캐시와 VM의 통합
가상 메모리와 캐시 메모리가 동시에 존재하는 시스템에서는, 캐시가 "가상 주소"로 접근해야 하는지, "물리 주소"로 접근해야 하는지 결정해야 한다. 대부분의 시스템은 물리 주소 방식을 채택한다.
물리 주소 캐시를 사용하는 이유
- 프로세스 간 데이터 공유 및 보호
- 물리 주소를 사용하면 여러 프로세스가 동시에 캐시에 블록을 저장하거나 동일한 물리 페이지를 공유함.
- 주소 변환 과정에서 접근 권한이 이미 체크되므로*, 캐시에서 별도로 보호를 신경 쓸 필요가 없음.
- 캐시 일관성 및 보안
- 가상 주소로 캐시를 접근한다면 서로 다른 프로세스의 동일한 가상 주소가 서로 다른 실제 데이터를 가리킬 수 있어 캐시 일관성 유지가 어렵고, 보안상 문제도 발생할 수 있음.
* 접근 권한 체크
- 어떤 프로세스가 해당 주소를 읽고, 쓰고, 실행 가능한지 페이지 테이블을 통해 MMU가 주소 변환할 때 같이 검사
물리 주소 캐시의 동작 흐름
- CPU가 가상 주소(VA)를 생성 - CPU는 프로그램 실행 중 메모리 접근 시 가상 주소 생성
- MMU가 주소 변환 수행 - 페이지 테이블을 참조하여 가상 주소를 물리 주소로 변환함.
- 캐시 접근 - 변환된 물리 주소를 이용해 캐시에 접근함.
- 만약 해당 데이터가 캐시에 있으면(hit), 바로 반환
- 없으면(miss), 메인 메모리(DRAM)에서 데이터를 읽어와 캐시에 저장
- PTE도 캐시됨 - 주소 변환 과정에서 사용되는 PTE 역시 일반 데이터처럼 캐시에 저장될 수 있음.
6-2) TLB를 사용한 주소 번역 속도의 개선
가상 주소를 물리 주소로 변환할 때, MMU는 매번 페이지 엔트리(PTE)를 참조해야 함.
PTE를 메모리에서 읽어오는 데 수십~수백 사이클이 소요될 수 있음
PTE가 L1 캐시에 있다면 비용이 줄지만 캐시 미스가 발생할 수 있음.
이런 오버헤드를 줄이려면 TLB라는 소규모 PTE캐시를 MMU 내부에 둠.
TLB란
- MMU에 내장된 소규모, 고속, 연관도 높은 캐시
- 각 엔트리는 하나의 PTE를 저장.
- 보통 가상 주소의 VPN 일부를 인덱스와 태그를 사용
TLB 접근 과정
- CPU가 가상 주소를 생성
- MMU가 TLB에서 해당 VPN에 대한 PTE를 탐색
- TLB index(TLBI): VPN 하위 비트
- TLB tag(TLBT): VPN 상위 비트
- TLB에 해당 엔트리가 있으면 빠르게 물리 주소로 변환 (TLB hit)
- TLB에 없으면 페이지 테이블에서 PTE를 읽어와 TLB에 저장 (TLB miss)
6-3) 다중 레벨 페이지 테이블
주소 변환을 단일 페이지 테이블로 처리한다고 가정할 때 크기가 매우 크고, 메모리 낭비 또한 매우 큼.
ex)
32비트 주소 = 개의 주소를 표현 가능
| 32비트 | 주소 |
|---|---|
| 00000000 00000000 00000000 00000000 | 0번 주소 |
| 00000000 00000000 00000000 00000001 | 1번 주소 |
| ... | |
| 11111111 11111111 11111111 11111111 | 번 주소 |
각 주소는 1바이트 단위로 메모리를 가리킴.
개의 주소가 있다는 것은 바이트 메모리 접근이 가능하다는 것을 의미함.
페이지 크기가 4KB일 경우()
전체 가상 공간 크기/페이지 크기 = 페이지 개수
즉 개의 페이지 생성
각 페이지마다 PTE 하나가 필요함
PTE는 4byte
모든 가상 페이지에 대한 PTE =
계층적 페이지 테이블
- 페이지 테이블 자체를 여러 단계로 나누어 실제로 사용되는 부분만 메모리에 할당
- 1단계 페이지 테이블의 각 엔트리는 2단계 페이지 테이블의 시작 주소를 가리킴
- 해당 범위의 가상 주소가 전혀 사용되지 않으면 하위 페이지 테이블조차 만들지 않음
메모리 절약 효과
- 1단계 테이블의 엔트리가 null이면 해당 하위 테이블은 만들지 않음
- 대부분의 가상 주소 공간이 미할당 상태이므로 전체 페이지 테이블을 항상 메모리에 둘 필요 없이, 필요한 부분만 동적으로 생성함.
- 1단계 테이블만 메모리에 상주하면 되고, 2단계 테이블은 필요할 때만 생성/캐싱하면 됨.
주소 변환 과정
- 가상 주소는 여러 개의 VPN 필드와 VPO로 나뉨.
- 각 단계의 VPN 필드가 해당 단계 페이지 테이블의 인덱스 역할을 함.
- 마지막 단계의 PTE에서 물리 페이지 번호(PPN)을 얻고, 오프셋과 결합해 최종 물리 주소 생성
PTE8의 정체//스택?//스택의 방향//왜 하필 PTE8인지
현대 운영체제와 하드웨어는 2, 3, 4단계 등 다양한 계층 구조를 사용함.
TLB는 여러 단계의 PTE를 캐싱하여 주소 변환 속도를 보완함.
7) 사례 연구
- 가상/물리 주소 공간
- Haswell 마이크로아키텍처는 64비트 주소 공간을 지원하지만, 실제 구현은 48비트 가상 주소 공간 (256TB) 과 52비트 물리 주소 공간 (4PB) 을 지원합니다.
- 호환 모드에서는 32비트 가상/물리 주소 공간 (4GB)을 지원합니다.
- TLB와 캐시 구조
- 각 코어는 다음과 같은 TLB 및 캐시 계층을 가집니다:
- L1 i-TLB: 128 entries, 4-way set associative
- L1 d-TLB: 64 entries, 4-way set associative
- L2 unified TLB: 512 entries, 4-way set associative
- L1 캐시: instruction/data 각각 32KB, 8-way set associative
- L2 캐시: 256KB, 8-way set associative
- L3 캐시: 8MB, 16-way set associative (모든 코어가 공유)
- 모든 캐시는 물리 주소 기반으로 동작하며, 블록 크기 64바이트입니다.
- 페이지 크기와 주소 변환
- 페이지 크기는 4KB 또는 4MB로 설정할 수 있으며, Linux는 4KB 페이지를 사용합니다.
- Core i7은 4단계 페이지 테이블을 사용합니다.
- CR3 레지스터는 level 1 페이지 테이블의 물리 주소를 저장하고 있으며, 이는 context switch 시 갱신됩니다.
- 페이지 테이블 항목 (PTE)의 구성
- PTE는 다음과 같은 플래그를 포함합니다:
- P: 페이지가 메모리에 존재하는지 여부
- R/W: 읽기-쓰기 권한
- U/S: 사용자/커널 모드 접근 허용 여부
- A: 참조 비트
- D: dirty 비트
- XD: 실행 금지 플래그 등
- Linux 메모리 영역 구조
- Linux는 가상 메모리를 vm_area_struct의 리스트로 관리하며, 각 영역은 코드, 데이터, 힙, 공유 라이브러리 등으로 나뉩니다.
- 각 프로세스는 자신만의 페이지 테이블과 영역 리스트를 갖고 있으며, mm_struct를 통해 CR3에 level 1 테이블 주소를 설정합니다
AI가 정리한 걸 그대로 가져왔다.
읽고 싶으면 읽자.
8) 메모리 매핑
가상 메모리 영역의 초기 내용을 디스크 상의 객체와 연결하여 관리함. 크게 두 가지 타입의 객체와 매핑할 수 있음.
- 정규 파일 매핑
- 가상 메모리 영역을 리눅스 파일 시스템의 정규 파일(실행 파일, 데이터 파일)의 연속된 일부와 연결할 수 있음.
- 파일의 해당 부분이 페이지 단위로 쪼개져 가상 페이지의 초기값이 됨.
- 요구 페이징 방식이 적용되어 실제로 물리 메모리에 해당 페이지가 로딩되는 시점은 CPU가 해당 가상 주소를 실제로 접근할 때임. 즉, 접근 전까지는 디스크에서 메모리로 읽혀지지 않음.
- 매핑된 영역이 파일보다 크다면 남는 부분은 0으로 패딩됨.
읽으면서도 잘 읽히지 않는 부분이 있다.
(1) '가상 메모리 영역을 리눅스 파일 시스템의 정규 파일(실행 파일, 데이터 파일)의 연속된 일부와 연결할 수 있음.'
이 부분을 잘 모르겠다.
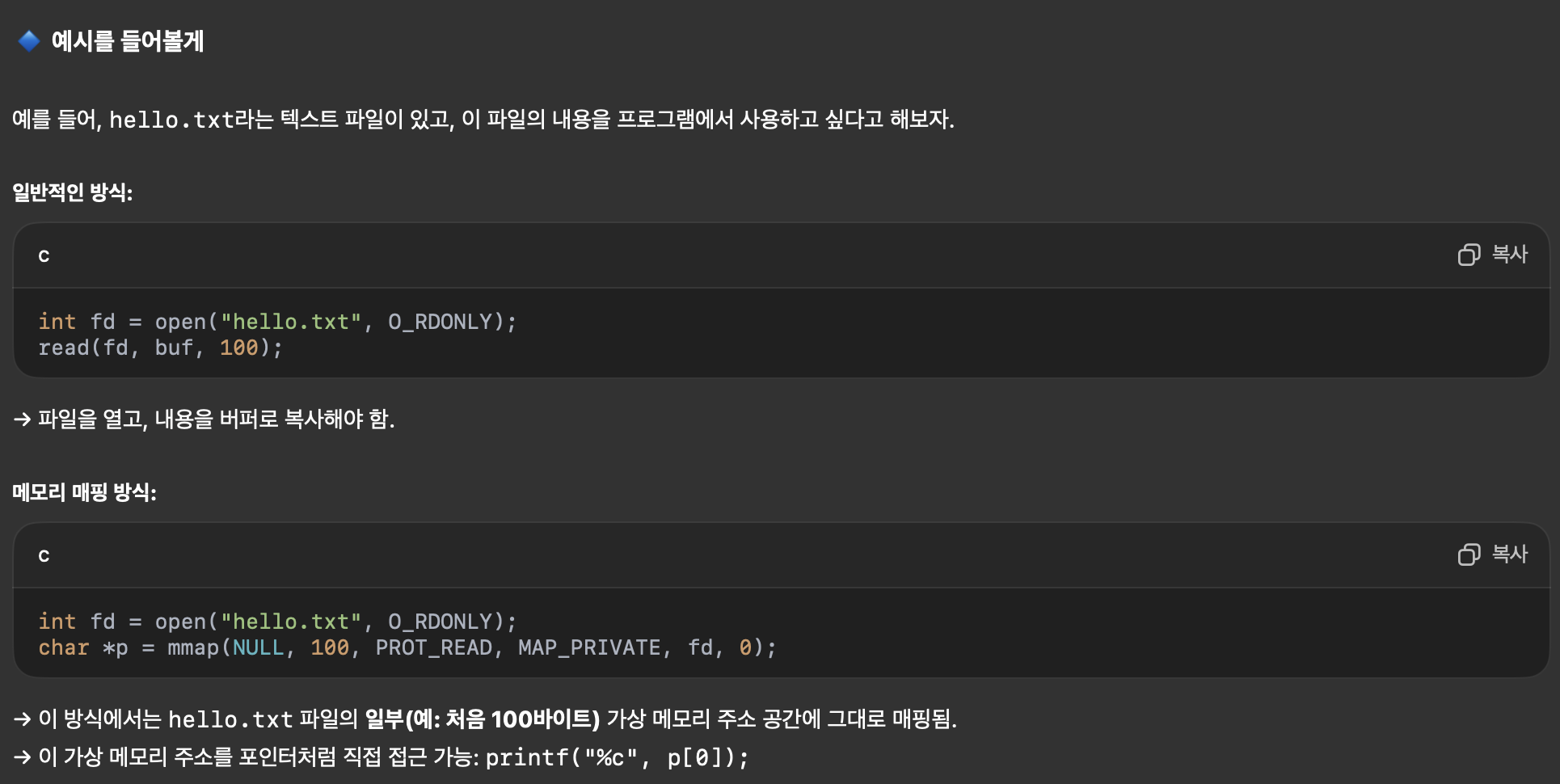
라고 하는데 더 자세하게 물어보겠다.
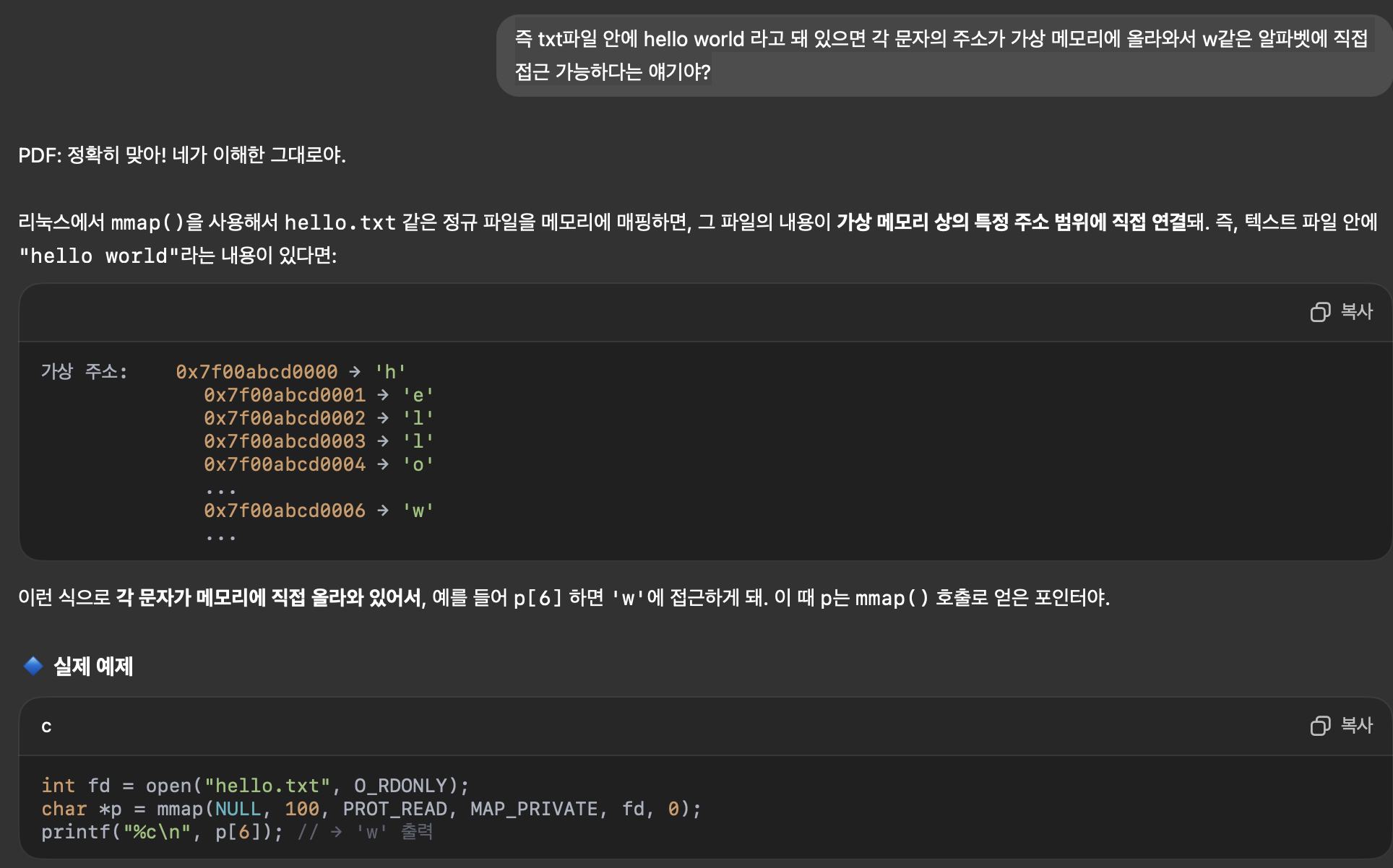
(2) '매핑된 영역이 파일보다 크다면 남는 부분은 0으로 패딩됨.'
쉽게 말해서 메모리에 매핑된(가상 주소 공간이 할당된) 부분 중 일부 사용하는 부분은 파일 데이터로 채워지고, 남는 부분은 0으로 채워진다는 의미이다.
| 가상메모리 주소 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| 데이터 | h | e | l | l | o | \0 | \0 | \0 |
이런 느낌이다.
'매핑된 영역이 너무 많다면 메모리 낭비가 심해지는거 아니냐'고 물어봤다.
어떻게 생각하는가?
...

맞다. 접근하기 전까지는 할당되지 않는다고 했다.
PTE Table을 두 단계로 나눈 것도 이와 관련이 있다.
다만 가상 주소 공간은 여전히 쓰기 때문에

참고로 항상 AI를 두 개를 쓰면서 교차검증?하고 있다.
틀렸다고 하면 보통 그대로 쓰는 편이고
맞다고 할 때는 교차검증 하는 편이다.
- 익명 파일 매핑
- 커널이 모든 비트를 0으로 채운 익명 파일을 생성하여 가상 메모리 영역과 연결할 수 있음.
- 이 영역의 페이지는 최초 접근 시에만 0으로 채워진 실메 물리 페이지가 할당됨.
- 접근 과정에서도 디스크 데이터 전송 없이 메모리만 0으로 덮어씀.
익명에 관해서 예전에 한 번 언급한 적이 있다.
익명은 한 번 쓰고 버리는 용도라고 했다.
아마 접근됐을 때 메모리를 0으로 초기화하고 버리는 용도라고 생각한다.
- 스왑 공간*과의 관계
- 한 번 초기화된 가상 페이지는 커널이 관리하는 스왑 파일(스왑 공간)에 의해 관리됨.
- 현재 실행 중인 프로세스들이 할당할 수 있는 전체 가상 페이지의 양은 시스템의 스왑 공간 크기에 의해 제한됨
* 스왑 공간: RAM이 부족할 때, 일부 메모리 내용을 디스크에 잠시 저장해두는 공간
8-1) 공유 객체
메모리 매핑은 객체를 공유 객체 또는 사적 객체로 매핑할 수 있음.
- 공유 객체: 여러 프로세스가 동일한 물리 메모리 내용을 공유하며, 한 프로세스의 변경이 다른 프로세스와 디스크 상의 객체에도 반영된다.
- 사적 객체: 프로세스마다 독립적으로 매핑되며, 한 프로세스의 변경은 다른 프로세스나 디스크에 영향을 주지 않음.
나는 공유 객체를 공유 라이브러리 정도로 생각했는데, 그보다 좀 더 넓은 개념이라고 한다. 여러 프로세스가 동시에 접근하는 파일이라고 한다.
공유 객체 매핑의 동작방식
- 한 프로세스가 공유 객체를 자신의 가상 메모리 영역에 매핑하면 해당 객체의 페이지들이 물리 메모리에 로드됨.
- 다른 프로세스가 같은 객체를 매핑할 때, 커널은 이미 매핑된 물리 페이지를 재사용하여 두 프로세스의 페이지 테이블이 동일한 물리 페이지를 가리키도록 설정함.
- 이렇게 하면 여러 프로세스가 동일한 공유 객체의 물리 페이지를 참조하게 됨.
- 실제 물리 메모리 상에서 페이지가 연속적일 필요는 없음. 커널이 각 프로세스의 가상 주소 공간에서 적절히 매핑하면 됨.
사적 객체와 Copy-on-Write
- 사적 객체는 초기에 공유 객체와 동일하게 동작함. 여러 프로세스가 같은 물리 페이지를 참조함.
- 하지만 어느 한 프로세스가 해당 페이지에 쓰기를 시도하면, 커널이 페이지 폴트를 감지하여 해당 프로세스만을 위한 새로운 물리 페이지를 복사하여 할당함.
- 해당 프로세스는 복사된 페이지에 변경을 가하고, 다른 프로세스는 여전히 원본 페이지를 참조함.
- 실제 필요할 때만 복사가 일어나므로 메모리 사용을 최소화하면서 각 프로세스의 독립성을 보장함.
사적 객체의 복사본을 저장하려고 하면 어떻게 되는 지에 대해서 물어봤다.
- MAP_PRIVATE로 매핑한 경우에는 절대 원본 파일에 저장되지 않으며, 복사본을 만들고 거기서만 작업한다.
- write나 fwrite으로 프로그래머가 저장을 시도하면 해당 시점의 데이터를 파일로 기록하는데, 만약 프로세스가 서로 저장하려고 하면

위와 같은 결론이 난다고 한다.
8-2) fork
fork 함수는 현재 프로세스의 복제본을 만들어 새로운 자식 프로세스를 생성한다. 자식 프로세스는 부모 프로세스와 완전히 독립적인 가상 주소 공간을 사용하는데, 실제 메모리 복사를 모두 수행하면 비효율적이기 때문에 COW 기법을 사용한다.
fork 동작 과정
- 프로세서 생성
- 커널은 자식 프로세스를 위한 각종 데이터 구조(PID, 프로세스 제어 블록 등)을 생성함.
- 가상 메모리 구조 복제
- 부모의 'mm_struct', 페이지 테이블 등 가상 메모리 관련 구조체를 복제함.
- 이때 실제 물리 메모리의 데이터는 복사하지 않고, 모든 페이지를 읽기 전용으로 마킹함.
- 각 영역은 private copy-on-write로 플래그를 설정함.
- 실제 메모리 복사 지연
- 부모와 자식 프로세스는 같은 물리 페이지를 공유하며, 둘 다 읽기만 가능함.
- 둘 중 하나가 해당 페이지에 '쓰기'를 시도할 때 페이지 폴트가 발생함.
- 커널의 페이지 폴트 핸들러가 동작하여 해당 페이지의 실제 복사본을 생성하고 쓰기 권한 부여
- 이후 수정은 복사된 페이지에서만 이루어지며, 부모와 자식은 독립적인 메모리 공간을 갖게 됨.
효율성 및 장점
- 메모리 효율: 실제로 수정이 발생할 때만 복사가 이루어지므로 불필요한 메모리 사용을 최소화 함.
- 빠른 프로세스 생성: fork 호출 시 전체 메모리 복사가 필요 없으므로, 새로운 프로세스 생성이 매우 빠름.
- 프로세스 독립성 보장: 쓰기 시점에만 복사가 발생하므로, 부모와 자식은 독립적인 메모리 공간을 가짐.
8-3) execve
execve의 동작 과정
- 기존 사용자 영역 삭제
- 현재 프로세스의 사용자 영역(기존 프로그램의 코드, 데이터, 힙, 스택)들을 모두 삭제함.
- 새로운 private 영역 매핑
- 새로운 프로그램(a.out)의 코드(.text), 데이터(.data), bss, 스택, 힙 영역에 대해 area struct를 새로 만듦
- 해당 영영들은 모두 private-copy-ont-write로 매핑됨
- 코드와 데이터 영역은 a.out 파일의 .text, .data 섹션에 매핑
- bss, 힙, 스택은 demand-zero(익명 매핑)으로 생성
- 공유 영역 매핑
- 만약 a.out이 공유 객체와 링크되어 있다면, 해당 공유 객체들도 동적으로 매핑됨.*
- 이들은 사용자 가상 주소 공간의 공유 영역에 매핑됨.
- 프로그램 카운터 설정
- evecve의 마지막 단계는 프로세스의 프로그램 카운터(PC)를 새 코드 영역의 진입점으로 설정하는 것
- 프로세스가 스케줄링되면, 새 프로그램의 코드부터 실행됨.
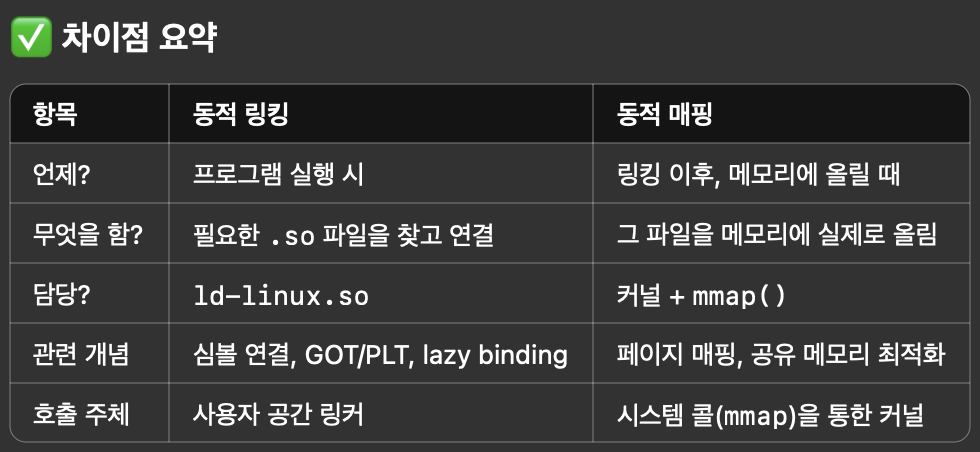
순간 동적 링킹과 동적 매핑이 헷갈려서 질문을 했다.
다시 정리를 하겠다.
- 동적 링킹
- 프로그램을 실행할 때 필요한 라이브러리를 찾아서 연결하는 작업
- 컴파일 시에 연결되지 않고, 실행 시 렁타임 링커에 의해 연결됨.
- ex) a.out이 printf()를 쓸 때, 컴파일 시에는 libc.so에만 있다고 기록되며 실행할 때 찾아서 연결
- 동적 매핑
- 위에서 찾은 libc.so 파일을 실제로 메모리에 올리는 작업
- 이때 사용되는 시스템 호출이 mmap()임.
8-4) 함수를 이용한 사용자 수준 매핑
mmap 함수
새로운 가상 메모리 영역을 생성하거나 파일 또는 익명 객체를 해당 영역에 매핑할 수 있게 만드는 함수
커널에 직접 요청을 보내어 원하는 형태의 메모리 매핑을 동적을 생성할 수 있게 해줍니다.
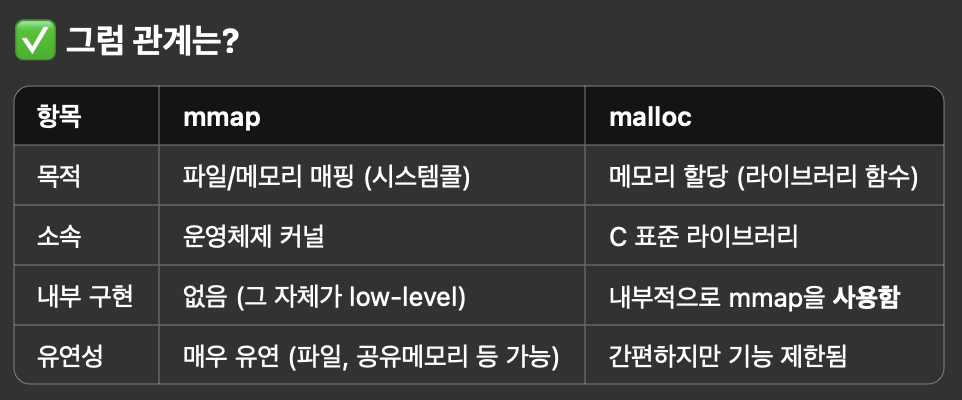
살짝 malloc의 냄새가 난다.
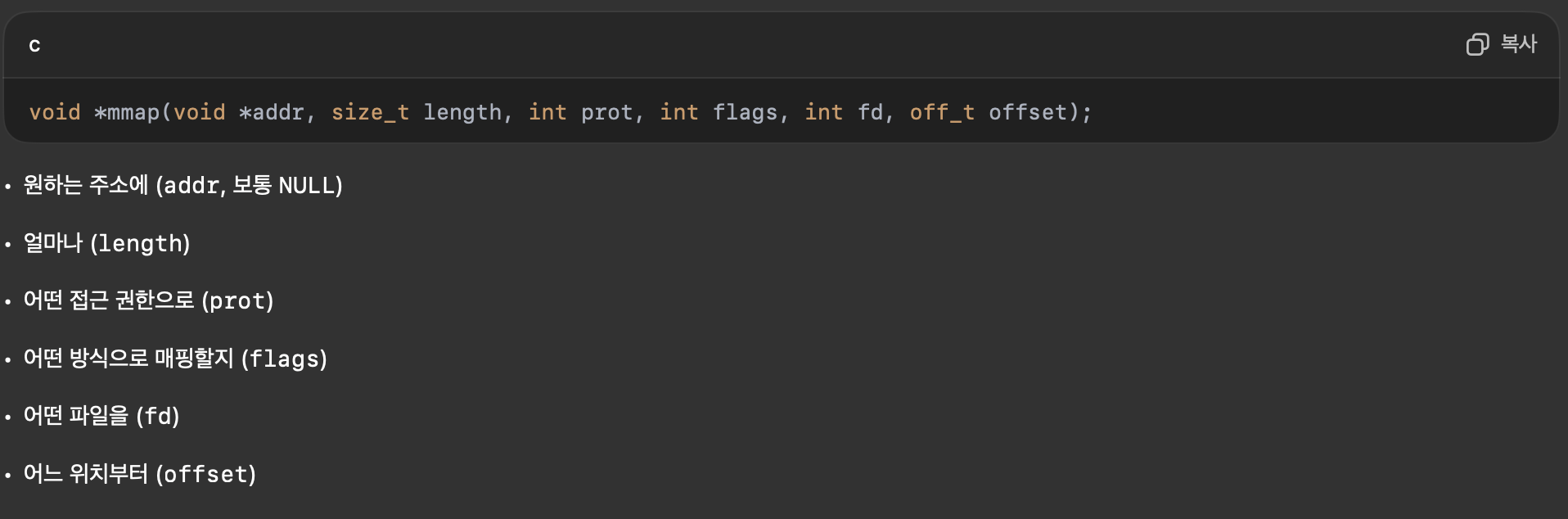
- start: 매핑을 시작할 가상 주소(일반적으로 NULL로 지정하면 커널이 적절한 주소를 선택)
- length: 매핑할 바이트 수
- prot: 접근 권한 (예: PROT_READ, PROT_WRITE, PROT_EXEC, PROT_NONE)
- flags: 매핑 타입 및 옵션 (예: MAP_SHARED, MAP_PRIVATE, MAP_ANON)
- fd: 매핑할 파일의 파일 디스크립터(익명 매핑이면 -1)
- offset: 파일 매핑의 경우, 파일 내 오프셋(바이트 단위)
mmap 동작 예시
- 파일 매핑: 특정 파일의 일부를 가상 메모리로 매핑하여, 파일 내용을 메모리처럼 접근 가능
- 익명 매핑: 실제 파일 없이 0으로 초기화된 메모리 영역을 생성
munmap 함수
지정한 가상 메모리 영역을 해제(매핑 해제), 해제된 영역에 접근 시 세그멘테이션 폴트가 발생
mmap 함수의 특징 및 장점
- 효율성: 파일 내용을 메모리처럼 직접 접근하므로, 입출력 성능이 크게 향상
- 유연성: 파일 매핑, 익명 매핑, 공유/사적 매핑 등 다양한 시나리오에 대응
- 가상 메모리 활용: 커널이 페이지 단위로 실제 물리 메모리 할당 및 스왑을 관리
