tanstack-query를 사용하며 겪은 Suspense 내의 API 병목현상 해결기를 담은 글입니다.
자바스크립트의 비동기 동작
자바스크립트는 싱글스레드다.
자바스크립트의 메인 스레드인 이벤트 루프는 싱글스레드이므로 하나의 작업을 순차적으로 실행한다.
따라서 이전 작업이 끝날 때까지 다음 작업은 blocking 된다.
그렇다면 타이머 작업은 어떻게 동작하는 것일까?
예를 들어, 1초후 A 동작을 실행하도록 하는 타이머 함수가 있다고 해보자.
만약 동기적으로 동작한다면 브라우저에서 일어나는 클릭, 스크롤 같은 이벤트부터 네트워크 요청까지 모든 작업이 끝난 이후에 1초를 세고 A 동작이 실행될 것이다.
우리의 예상은 1초후이지만 블로킹 현상으로 n초후에 작업이 실행될 것이다.
또한 정말 브라우저에서 모든 네트워크 요청이나 파일 다운로드를 순차적으로 처리한다면 우리는 한가지를 처리할 때마다 모든 동작이 멈추는 블로킹 현상으로 엄청난 불편함을 겪을 것이다.
자바스크립트는 런타임 환경에서는 멀티스레드다.
자바스크립트의 메인 스레드인 Event Loop는 싱글 스레드다.
하지만 런타임 환경에서는 웹 브라우저의 Web API 나 NodeJS 같은 멀티 스레드 환경에서 실행된다.
비동기 함수 실행 방식을 간단히 짚고 넘어가자.
- 자바스크립트는 실행 컨텍스트 스택(Call Stack)에 실행해야할 함수들을 쌓는다.
- 시간이 오래걸리는 비동기 작업들(DOM, ajax, 타이머 함수, 이벤트)은 브라우저의 Web API 멀티 스레드로 이동한다.
- Web API에서 처리가 완료(fullfilled)된 비동기 작업들은 이벤트 콜백 함수를 Task Queue(Callback Queue)에 넣는다.
- Event Loop는 전역 실행컨텍스트까지 실행 컨텍스트 스택(Call Stack)이 비면 Queue에 대기중인 콜백 함수들을 pop하여 넣는다.
- 실행 컨텍스트 스택(Call Stack)에 있는 함수는 실행된다.
이처럼 자바스크립트는 비동기 로직을 이벤트 루프와 Node.js의 백그라운드 도움을 받아 병렬적으로 처리할 수 있다.
비동기 병렬 처리로 병목 현상 해결하기
우리는 자바스크립트가 런타임 환경에서 브라우저 Web API를 이용해 멀티 스레드처럼 동작한다는 것을 알았다.
이를 통해 ajax를 병렬 처리할 수 있다는 것도 알 수 있다.
상관 관계가 전혀 없는 데이터를 API 호출하는 경우에는 병렬처리하여 더욱 효율적인 네트워크 요청을 할 수 있다.
Promise.all & Promise.allSettled & Promise.race
Promise.all: 모든 프로미스가 성공적으로 완료될 때까지 기다린 후 결과 배열을 반환한다. 하나라도 rejected 하면 전체 프로미스가 실패한다.Promise.allSettled: 각 프로미스가 성공 또는 실패한 후에 결과를 반환한다. 각각의 프로미스 결과를 추적할 수 있다.Promise.race: 가장 먼저 fulfilled 상태가 된 프로미스 처리 결과를 resolve 한다. 하나라도 rejected 이면 에러를 reject 한다.
| Promise.all | Promise.alSettled | Promise.race | |
|---|---|---|---|
| 결과 반환 | 모든 프로미스가 성공할 때 | 모든 프로미스가 성공 또는 실패할 때 | 가장 먼저 성공한 프로미스 |
| 최대 소요시간 | 처리 시간이 가장 긴 프로미스 | 처리 시간이 가장 긴 프로미스 | 처리 시간이 가장 짧은 프로미스 |
지금까지 자바스크립트에서의 비동기 작업 처리과정과 비동기 작업을 병렬 처리하는 방법을 간단히 알아보았다.
이제 Suspense 내에서 왜 API 병목현상이 발생했고, 어떻게 tanstack query에서 병렬 처리할지 알아보자.
Suspense
React 공식문서에 따르면 <Suspense>란 하위 컴포넌트가 API 호출로 데이터를 응답받는 동안, 즉 로딩하는 동안 fallback 화면을 보여주는 것이다.
-
Render-as-you-fetch 방식은 비동기 작업과 렌더링을 동시에 시작하는 것으로, Suspense의 동작 방식이다. 초기 상태를 렌더링하고(loading fallback), 비동기 작업이 완료되면 응답받은 값으로 렌더링한다(children).
-
Fetch-on-render 방식은 컴포넌트 렌더링을 먼저 하고 그 후 비동기 작업을 하는 것으로, useEffect 문에서 데이터 페칭을 하는 방법이다.
<Suspense fallback={<Loading />}>
<SomeComponent />
</Suspense>이처럼 Suspense는 선언적으로 로딩 화면을 구현할 수 있다.
Suspenses는 하위 컴포넌트들 중 하나라도 로딩중이면 fallback 화면을 보여준다.
예를 들어, 아래 코드처럼 하위 컴포넌트들이 각각 API 요청을 여러개 한다면 총 로딩 시간은 모든 API 요청이 응답을 받는 시간이 된다.
export default function ArtistPage({ artist }) {
return (
<>
<h1>{artist.name}</h1>
<Suspense fallback={<Loading />}>
<Biography artistId={artist.id} />
<Panel>
<Albums artistId={artist.id} />
</Panel>
</Suspense>
</>
);
}Suspense 동작 방식
Suspense는 Promise를 캐치한다.
이는 ErrorBoundary가 error를 캐치하는 것과 비슷하다.
API 호출의 Promise를 throw하면 Suspense는 이를 catch해서 pending 상태이면 LoadingFallback을 return 하고, settled(fulfilled, rejected)이면 children을 리턴한다.
Suspense의 부작용
Suspense는 Promise를 캐치하여 pending이면 LoadingFallback을, settled이면 children을 리턴한다.
따라서, 하나의 API 요청으로 인한 Promise가 throw 되면 pending 상태일 때는 children 컴포넌트가 언마운트되고 Loading 컴포넌트가 마운트된다. settled 상태가 되었을 때 children 컴포넌트가 마운트된다.
즉 children 컴포넌트는 Promise가 throw 될 때마다 언마운트되므로 2개 이상의 요청이 순차적으로 호출되는 병목 현상이 발생하게 되는 것이다.
따라서 Suspense를 무지성으로 로딩 컴포넌트가 필요한 곳에 모두 씌워버리면 안된다.
모든 API 호출에서 병목 현상이 발생해 로딩 시간이 저하될 수 있다.
다음 사진은 이슈 트래커 프로젝트의 이슈 상세페이지다.
이슈 상세페이지에서는 최초 렌더링시 두 번의 fetch가 발생한다.
- 이슈 상세 정보 조회 API 호출
- 리액션 조회 API 호출
아래처럼 네트워크 탭에서 waterfall 현상을 확인할 수 있었다.
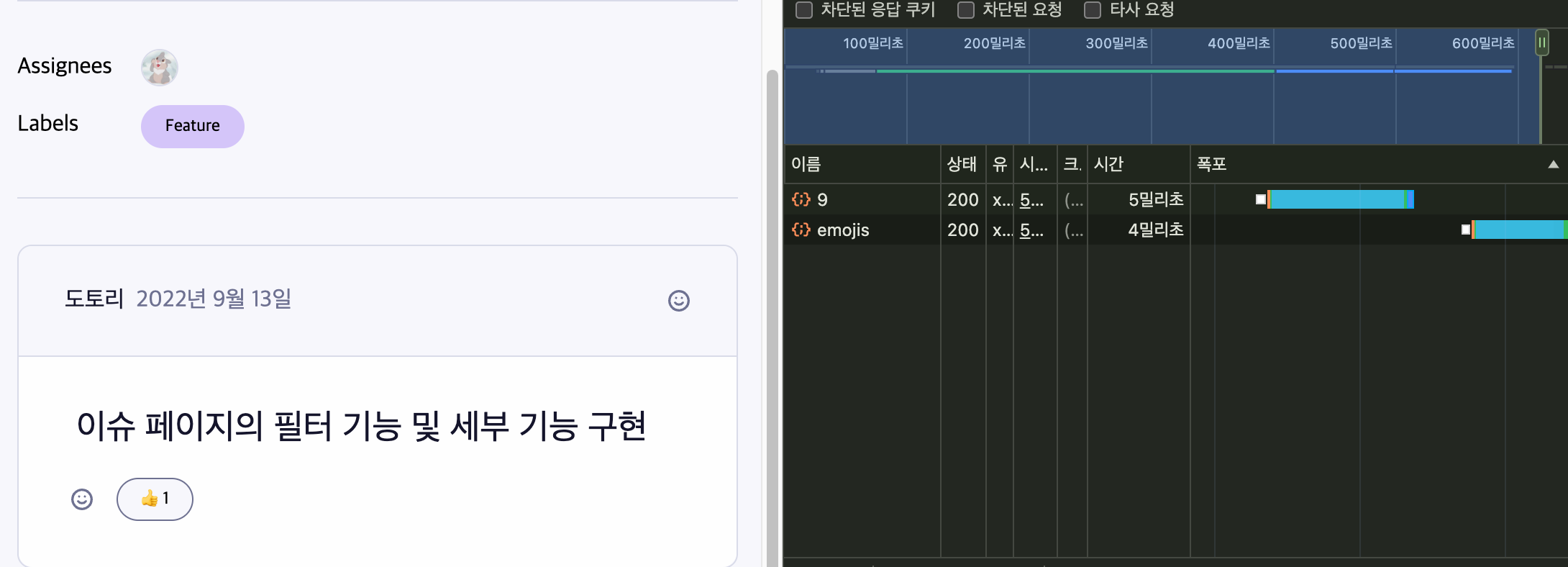
이 두가지 API는 서로 상관관계가 없으므로 병렬적으로 호출하여 전체적인 로딩 시간을 줄이는 것이 성능상 유리하다.
tanstack query
tantsck query는 기본적으로 parallel queries를 지원한다.
따라서 useQuery와 useQueries 는 병렬적으로 실행되어야 하지만 Suspense의 동작원리에 따른 문제점으로 Suspense 내에서는 적용되지 않는 이슈가 발생했다.
(👏 useQueries 이슈는 tanstack/query v4.5.0에서 해결되었다!)
Suspense + useSuspenseQueries ( ⭕️ )
tanstack/query v.4.5.0 이상이라면 useQueries 를 사용해 병렬 처리를 할 수 있다.
v5부터는 문법이 useSuspenseQueries로 변경되었다.
아직 프로젝트 작업 단계가 초기 상황이어서 버전에 대한 의존성 충돌 문제와 문법을 수정해야할 코드의 양이 적다면 버전업이 빠른 해결방법일 수 있다.
하지만 나는 마무리된 프로젝트를 고도화하는 작업에 있으므로 다른 해결방법을 찾아보았다.
Suspense + useQuery ( ❌ )
문제의 useQuery를 살펴보자.
이슈 상세페이지의 코드는 다음과 같이 useQuery를 나란히 사용하고 있다.
const { data: issue } = useIssueData(Number(issueId));
const { data: reactions } = useReactionData();원래대로라면 useQuery 자체는 Parallel query를 지원한다.
하지만 Suspense의 동작자체가 Promise가 throw 될 때마다 children 컴포넌트가 언마운트되어 네트워크 병목현상이 발생하고 있다.
Suspense + useQuery + prefetch ( ⭕️ )
Tanstack-query 공식문서는 waterfall 현상들에 대해 소개하고 여러 해결방법들을 제안한다.
나는 그 중 Prefetching 방법을 선택했다.
Prefetching 방식은 애플리케이션이나 API 구조를 재구성할 필요가 없고 server rendering 방식이 아니었기 때문이다.
공식문서의 Prefetching을 간단히 요약해보자.
필요한 데이터를 prefetching을 이용해 미리 캐시하면 더 빠른 사용자 경험성을 제공할 수 있다.
prefetching은 네트워크 요청 waterfall 을 방지할 수 있다.
몇가지 prefetch 패턴이 있다.
- 이벤트 핸들러에서
- 컴포넌트에서
- 라우터 통합을 통해
- 서버 렌더링 중 (라우터 통합의 또 다른 형태)
여기에서 우리는 2번과 3번을 자세히 살펴보도록 하자.
컴포넌트 렌더링시 발생하는 API 호출해 대한 것이므로 1번은 패스,
4번은 서버 렌더링 측면에서 설명되어있다.
컴포넌트에서 - 쿼리 함수 내부에서 prefetch
prefetch는 컴포넌트 렌더링을 차단하므로, useSuspenseQueries 를 사용하여 prefetch할 수 없다. (병렬 호출은 가능하나 prefetch가 불가능하다.)
useQuery 역시 Suspense 내에서는 순차적으로 처리된다.
useQuery 쿼리 함수 내부에서 prefetch 하기
article을 가져올 때 comment도 필요할 가능성이 높다는 점을 알고 있다면 prefetching 할 수 있다.
article을 페칭하는 useQuery의 queryFn에 comment의 prefetchQuery를 전달하면 API가 병렬 호출된다.
즉, 쿼리 함수 내부에 prefetch를 함으로써 병렬 호출이 가능해진다.
const queryClient = useQueryClient()
const { data: articleData, isPending } = useQuery({
queryKey: ['article', id],
queryFn: (...args) => {
queryClient.prefetchQuery({
queryKey: ['article-comments', id],
queryFn: getArticleCommentsById,
})
return getArticleById(...args)
},
})
라우터 통합 - 경로 단위로 미리 fetch를 명시하기
컴포넌트 트리 구조 자체가 water fall 요청이 쉽게 발생할 수 있고, 이에 대한 수정 사항은 번거로울 수 있다.
따라서 프리페치를 라우터 수준에서 통합하는 방식을 제안한다.
각 경로에 대해 해당 컴포넌트에 필요한 데이터를 미리 명시적으로 선언하는 건이다.
라우터 수준에서 모든 데이터가 응답받을 때까지 해당 경로의 렌더링을 차단하거나, 프레피체를 시작하지만 결과를 기다리지 않도록 선택할 수 있다.
이 두 가지 방식을 혼합하여 일부 중요한 데이터를 기다릴 수도 있지만 모든 보조 데이터 로드가 완료되기 전에 렌더링을 시작할 수도 있다.
다음 예제는 /article 경로에서 article 데이터 로드가 완료될 때까지 렌더링하지 않도록 하며, 가능한 빨리 comment 프리페치를 시작하지만 아직 로드되지 않았더라도 경로 렌더링을 차단하지 않는다.
const queryClient = new QueryClient()
const routerContext = new RouterContext()
const rootRoute = routerContext.createRootRoute({
component: () => { ... }
})
// '/article` 경로의 라우터를 작성한다.
const articleRoute = new Route({
getParentRoute: () => rootRoute,
path: 'article',
// 로드 전에 실행될 쿼리 옵션
beforeLoad: () => {
return {
articleQueryOptions: { queryKey: ['article'], queryFn: fetchArticle },
commentsQueryOptions: { queryKey: ['comments'], queryFn: fetchComments },
}
},
loader: async ({
context: { queryClient },
routeContext: { articleQueryOptions, commentsQueryOptions },
}) => {
// comment 쿼리를 prefetch 한다. 하지만 블로킹하지 않고 렌더링한다.
queryClient.prefetchQuery(commentsQueryOptions)
// article 쿼리가 fetch 될 때까지 라우트는 전혀 렌더링되지 않는다.
await queryClient.prefetchQuery(articleQueryOptions)
},
component: ({ useRouteContext }) => {
const { articleQueryOptions, commentsQueryOptions } = useRouteContext()
const articleQuery = useQuery(articleQueryOptions)
const commentsQuery = useQuery(commentsQueryOptions)
return (
...
)
},
errorComponent: () => 'Oh crap!',
})
결론
Suspense 내부에서 API 호출을 병렬 처리하는 방법은 다음 세가지다.
- useSuspenseQueries (tanstack-query v.4.5.0 이상)
- 단 쿼리 호출을 최상단 컴포넌트로 끌어올려야 한다.
- props로 데이터를 내려주는 과정이 번거로울 수 있다.
- useQuery 쿼리 함수 내부에서 prefetch 하기
- A 데이터를 사용할 때 B 데이터가 필수적으로 사용되리라는 것이 예상될 때 적합하다.
- Router의 loader 사용하기 (react-router-dom v6 이상)
- 쿼리 호출 레벨이 달라 최상단으로 끌어올리는 구조 변경이 어려운 경우 적합하다.
- 추후 경로 내부에서 Suspense가 더 많이 분리될 수 있는 경우 확장성이 좋다.
나는 2번 쿼리 함수 내부에서 prefetch하는 방식을 선택했다.
우선 프로젝트에서 사용하고 있는 react-router-dom의 방식은 다음과 같이 선언적으로 구성되어있다.
<BroswerRouter>
<Routes>
<Route/>
<Route/>
<Route/>
</Routes>
</BroswerRouter>prefetch를 지원하는 loader를 사용하기 위해서는 createBrowserRouter와 RouterProvider 컴포넌트를 사용하여 라우팅하는 로직으로 마이그레이션해야 한다.
우선 해당 프로젝트에서는 API 호출을 병렬 처리해야하는 이슈가 많지 않아서 마이그레이션보다는 간단히 적용할 수 있는 방식을 택하게 되었다.
또한 이슈에 대해 reaction을 남기는 기능으로 인해 reaction 데이터가 필수적으로 사용되리라 예상가능했고 prefetch 하기에 적합했다.
| 적용 전 | 적용 후 |
|---|---|
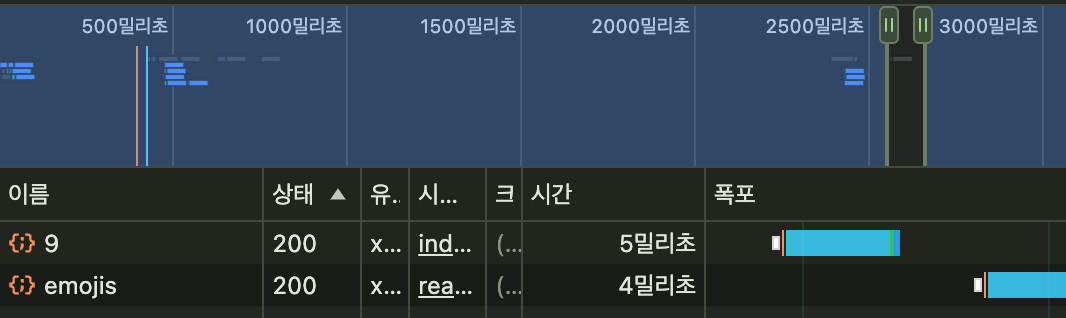 | 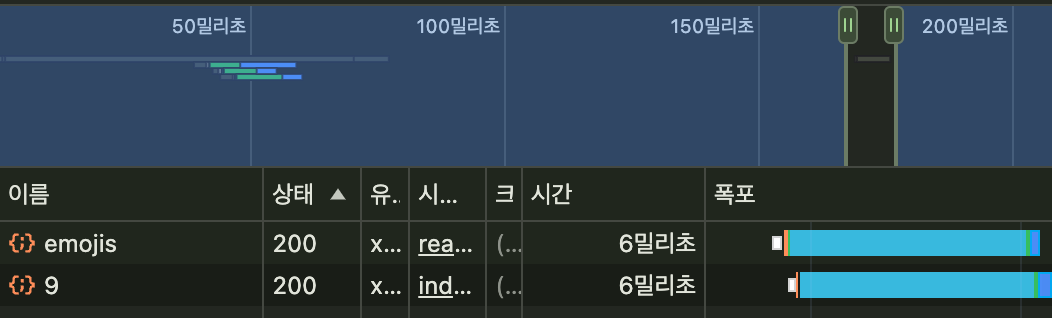 |
| 소요시간: 9ms | 소요시간: 6ms |
프로젝트에서는 tanstack-query의 enabled 속성으로 선택적 호출을 사용하여
불필요한 API 호출을 최소화므로 전체적으로 유의미한 개선을 보이진 않았다.
하지만 앞으로 Suspense 내에서 동시에 여러 API 를 호출해야 하는 경우
이 점을 고려하여 API 호출을 최적화 할 수 있을 것이다.
