Next에서 SEO 개선을 위해 리치 스니펫을 적용하는 과정을 작성한 글입니다.
리치 스니펫 - 구조화된 데이터
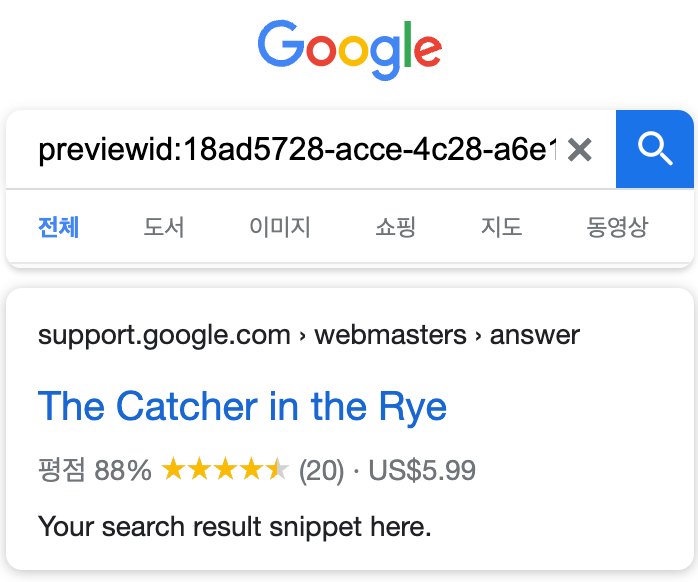
기본 스니펫 노출 정보 이외 평점, 사진 등 추가 정보를 제공할 수 있다.
리뷰 스니펫을 추가하면 별점과 리뷰 개수를 검색 결과로 확인할 수 있게 된다.
| 구글 | 네이버 |
|---|---|
  |   |
작성 방법
- 네이버 구조화 데이터 가이드, 구글 구조화 데이터 가이드를 따라 작성한다.
- schema.org 를 따라서 JSON-LD 데이터로 구조화 문서 작성
- type은 위치기반 서비스로 Locale Business를 선택했다.
- schema validator에서 구조화 데이터를 테스트할 수 있다.
작성한 구조화 데이터는 다음과 같다.
const reviewSnippet = reviewsData.map((e) => ({
'@type': 'Review',
reviewBody: e.content,
reviewRating: {
'@type': 'Rating',
ratingValue: e.rating,
},
author: {
'@type': 'Person',
name: e.user.username,
},
}))
const richSnippet = {
'@context': 'https://schema.org',
'@type': 'LocalBusiness',
name: agency.name,
telephone: tel,
address: {
'@type': 'PostalAddress',
streetAddress: agency.address_detail,
addressCountry: 'KR',
},
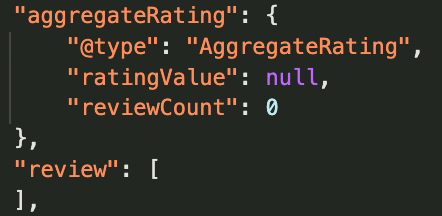
aggregateRating: {
'@type': 'AggregateRating',
ratingValue: average_rating,
reviewCount: reviewsData.length,
},
review: reviewSnippet,
geo: {
'@type': 'GeoCoordinates',
latitude: agency.address_point.lat,
longitude: agency.address_point.lon,
},
}Script
위에서 생성한 구조화 데이터를 script 에 넣는다.
next에서 script 파일을 생성하는 방법은 다음 세가지다.
1. _document.tsx 파일에서 next/document의 Head 컴포넌트내에 <script> 태그 추가
next/document 의 Head 컴포넌트 내에 <script> 태그를 추가하면 서버에서만 렌더되며 <head> 태그 내에 생성된다.
2. _document.tsx 파일 외부에서 next/head의 Head 컴포넌트 내에 <script> 태그 추가
next/head의 Head 컴포넌트 내에 <script> 태그를 추가하면 <body> 태그 내에 <script> 태그가 생성된다.
3. _document.tsx 파일 외부에서 next/script의 Script 컴포넌트 추가
starategy 중 beforeInterative, afterInteractive에 대해 더 자세히 알아보자.
- beforeInteractive
- 페이지 상호작용전 로드
- 서버에서 초기 HTML을 보낼 때 주입되고 번들이 된 자바스크립트가 실행하기 전에 먼저 실행된다.
_document파일 내에서만 실행할 수 있게 디자인 되었다. 순서를 보장할 수 없기 때문
- afterInteractive
- 페이지 상호작용이 가능한 직후 즉시 로드, 기본값
- 페이지에 hydration 되고나서 클라이언트 사이드에 주입하기 때문에 그만큼 초기 페이지 로딩 시간을 단축할 수 있다.
Script 적용 상황
- 페이지가 상호작용하기 전 로드해야 하는 경우 (head에 추가)
_document.tsx파일에서next/document의Head컴포넌트내에<script>태그 추가- ex) kakao map sdk
- 페이지가 상호작용 가능하고나서부터 로드해도 되는 경우
_document.tsx파일 외부에서next/head의Head컴포넌트 내에<script>태그 추가_document.tsx파일 외부에서next/script의Script컴포넌트 추가 (body)- ex) 해당 페이지에서만 필요한 스크립트 파일
구조화데이터는 script를 어디에 넣어야할까?
우선 리뷰는 상세페이지에 존재하므로, _document.tsx 외부 파일이다.
구조화 데이터는 SEO를 개선하기 위해 HTML 파일에 제공되는 데이터이므로 헤더에 추가하고, 비동기적으로 파일을 불러오기 위해 defer를 사용했다.
const Detail = () => {
(...)
return (
<>
<Head>
<script
type="application/ld+json"
defer
dangerouslySetInnerHTML={{ __html: JSON.stringify(richSnippet) }}
/>
</Head>
</>
)
}테스트
구글 리치 검색 결과 테스트 사이트에서 링크 혹은 소스코드를 입력하면 구조화 결과를 미리볼 수 있다.
- 예시 결과: 별별 부동산 구글 리치 검색 결과 테스트
Trouble Shooting
server 렌더링 단계에서 만들어지므로 클라이언트 단계에서 fetch하는 review 데이터가 제대로 렌더되지 않았다.
특히 리뷰데이터는 tanstack-query의 useInfiniteQuery를 이용해 무한스크롤 기능을 적용했다.
따라서 SSR + useInifiniteQuery를 적용시켜 첫페이지의 리뷰데이터를 서버에서 미리 fetch하고 얻은 값으로 구조화데이터에 반영되도록 해야한다.
다음으로 클라이언트에서는 무한스크롤도 동작하도록 리팩토링해야한다.
prefetch
Tanstack-query는 서버에서 prefetch한 데이터를 클라이언트에서 사용하는 두가지 방법이 있다.
- prefetch한 데이터를
initialData로 설정- 설정이 최소화되어 빠른 솔루션이 될 수 있다.
- 필요한 컴포넌트마다
initialData를 전달해야하는데 depth가 깊은 쿼리의 경우 복잡도가 높아짐 initialData는 업데이트되지 않는다.- 한 페이지를 여러번 앞뒤로 탐색하면
getServerSideProps가 매번 호출되어 서버에서 prefetch를 통해 새 데이터를 가져오지만,initialData옵션을 사용하므로 클라이언트 캐시와 데이터가 업데이트되지 않는다.
- 한 페이지를 여러번 앞뒤로 탐색하면
export async function getServerSideProps() {
const posts = await getPosts()
return { props: { posts } }
}
function Posts(props) {
const { data } = useQuery({
queryKey: ['posts'],
queryFn: getPosts,
initialData: props.posts,
})
// ...
}- 서버에서 query를 prefetch하고 dehydrate를 통해 클라이언트에서 hydration하여 사용
- 적용 방법이 복잡하다.
- 컴포넌트 depth에 상관없이 prefetch한 데이터를 캐시하고 가져올 수 있다.
Hydration 사용하기
- hydration을 사용하고자 하는 컴포넌트의 서버렌더링에서
const queryClient = new QueryClient를 생성한다.
2.getServerSideProps에서await queryClient.prefetchQuery(...)를 수행한다. dehydratedState(queryClient)를 반환한다.- 컴포넌트 상위에
<HydrationBoundary state={dehydratedState}>트리를 래핑한다. (보일러 플레이트를 없애기 위해 app 상단에서 래핑했다) - 클라이언트 측에서는 서버에서 prefetch 한 데이터를 쿼리 캐시에 적용하여 네트워크 요청없이 데이터를 사용할 수 있다.
다음은 Next 공식문서 예제이다.
// _app.tsx
import {
HydrationBoundary,
QueryClient,
QueryClientProvider,
} from '@tanstack/react-query'
export default function MyApp({ Component, pageProps }) {
const [queryClient] = React.useState(() => new QueryClient())
return (
<QueryClientProvider client={queryClient}>
<HydrationBoundary state={pageProps.dehydratedState}>
<Component {...pageProps} />
</HydrationBoundary>
</QueryClientProvider>
)
}// pages/posts.jsx
import {
dehydrate,
HydrationBoundary,
QueryClient,
useQuery,
} from '@tanstack/react-query'
// This could also be getServerSideProps
export async function getStaticProps() {
const queryClient = new QueryClient()
await queryClient.prefetchQuery({
queryKey: ['posts'],
queryFn: getPosts,
})
return {
props: {
dehydratedState: dehydrate(queryClient),
},
}
}
function Posts() {
// This useQuery could just as well happen in some deeper child to
// the <PostsRoute>, data will be available immediately either way
const { data } = useQuery({ queryKey: ['posts'], queryFn: getPosts })
// This query was not prefetched on the server and will not start
// fetching until on the client, both patterns are fine to mix
const { data: commentsData } = useQuery({
queryKey: ['posts-comments'],
queryFn: getComments,
})
// ...
}SSR + useInfiniteQuery 를 사용한 무한스크롤
Hydration은 초기설정이 복잡하지만 depth에 관계없이 prefetch한 데이터를 캐싱해서 클라이언트 측에서 사용할 수 있는 것이 이점이다.
확장성을 생각하여 Hydration을 이용해 리뷰의 첫 페이지를 prefetch하고 useInfiniteQuery 를 사용해 무한 스크롤을 구현해보기로 했다.
방법은 Next 공식문서와 아주 유사하다.
prefetchQuery 대신 prefetchInfiniteQuery를 사용하고, useQuery 대신 useInfiniteQuery를 사용한다.
이때 서버에서 사용되는 fetch가 2개 이상이라면Promise.all(...) 을 통해 병렬처리하여 fetching 시간을 줄일 수 있다.
export const getServerSideProps: GetServerSideProps<{
agency: RealEstateResponse
dehydratedState: DehydratedState
}> = async (context) => {
const queryClient = new QueryClient()
const id = Number(context?.params?.id?.[0])
const getAgencyData = () => getRealEstateData(id)
const prefetchReviewData = async () => {
await queryClient.prefetchInfiniteQuery({
queryKey: QueryKeys.reviewsAboutAgency(id),
initialPageParam: { page: 1, page_size: 10 },
queryFn: ({ pageParam }) => getAgencyReivewsData({ agency_id: id, pageParams: pageParam }),
})
}
const [agencyData] = await Promise.all([getAgencyData(), prefetchReviewData()])
return {
props: {
agency: agencyData,
dehydratedState: dehydrate(queryClient),
},
}
}| 직렬 | 병렬 |
|---|---|
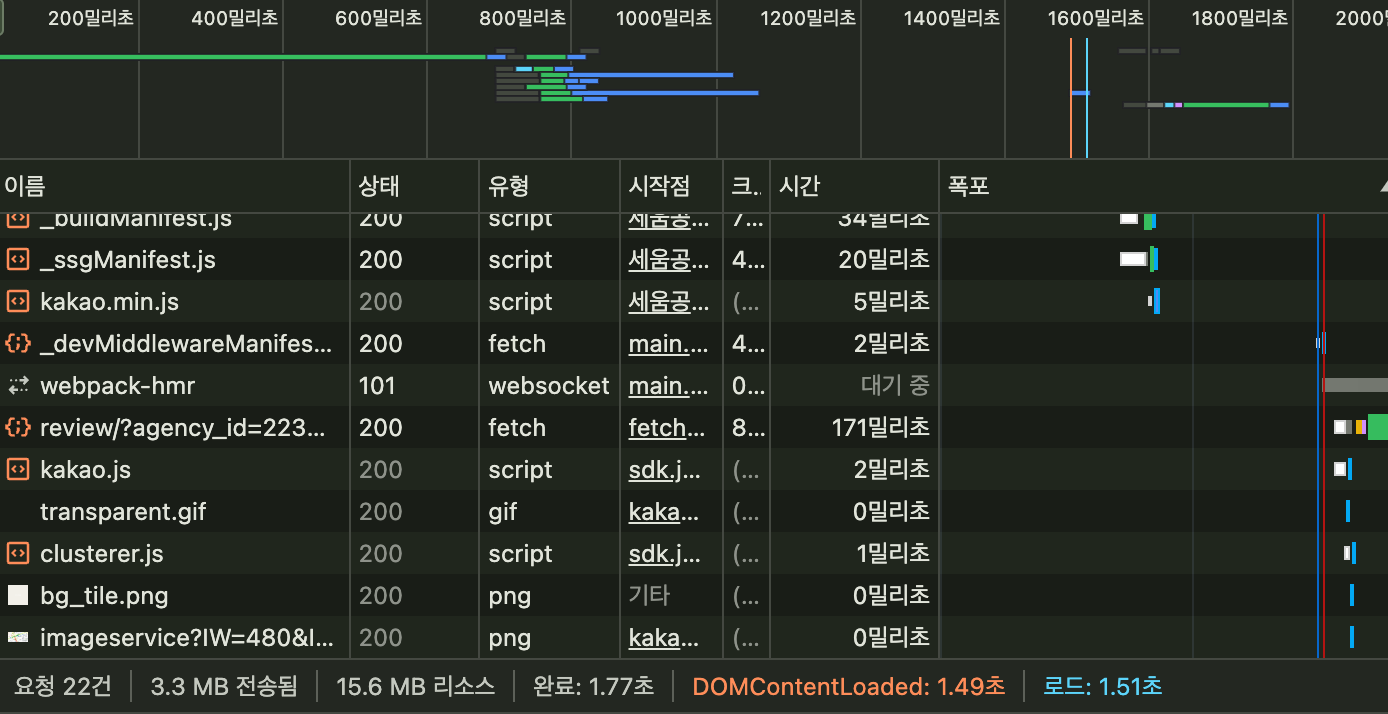 | 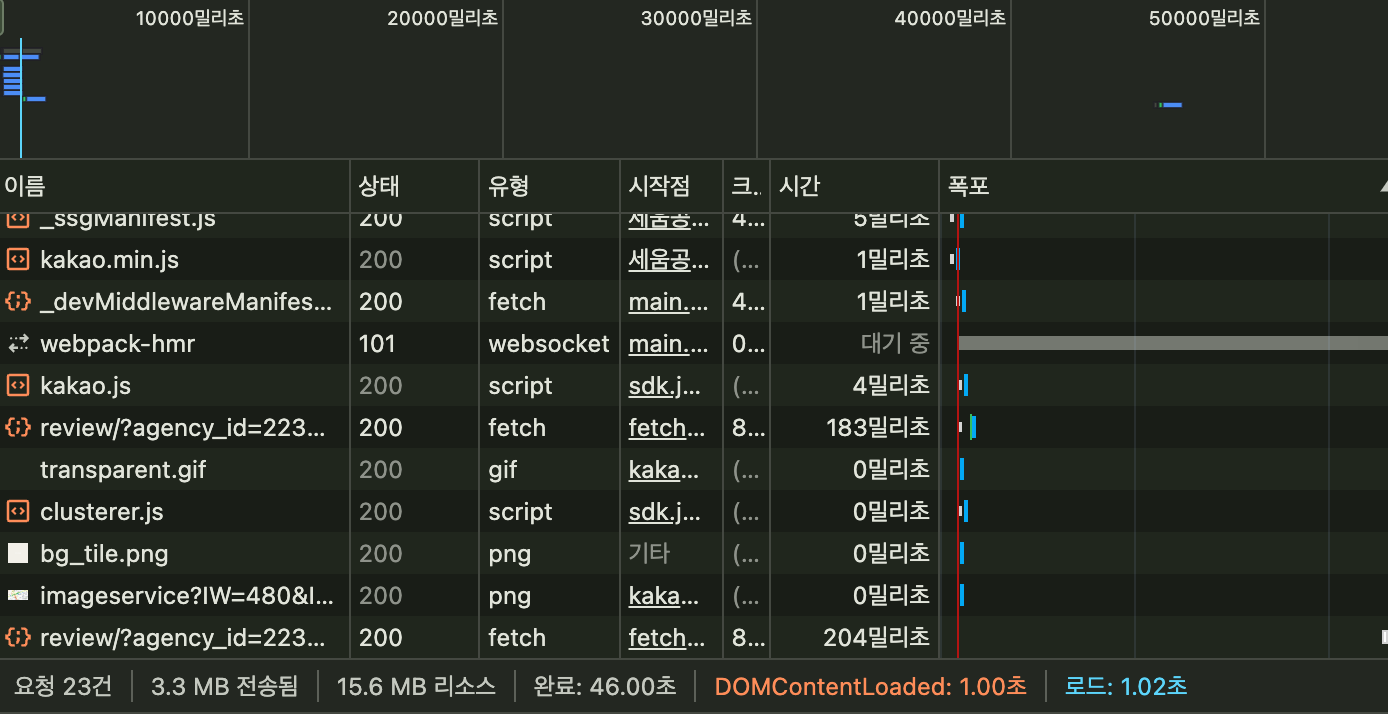 |
| 1.51초 | 1.02초 |
export default function Detail({ agency }: InferGetServerSidePropsType<typeof getServerSideProps>) {
(...)
const { data: reviewsResult, fetchNextPage: fetchMoreReviews } = useInfiniteQuery({
queryKey: QueryKeys.reviewsAboutAgency(id),
queryFn: ({ pageParam }) => getAgencyReivewsData({ agency_id: id, pageParams: pageParam }),
initialPageParam: { page: 1, page_size: 10 },
getNextPageParam: (lastPage) => ({ page: lastPage.page + 1, page_size: 10 }),
})
(...)
}리치스니펫을 만들다가 Hydration까지 넘어오게되었는데 모든 개념은 이어져 있는 것 같다.
이번 블로깅을 통해 SSR이 제공하는 이점을 직접 구현하고 경험해볼 수 있었다.
Ref
