
I/O 작업
I/O 작업은 유저 프로세스가 커널에 데이터 처리를 요청하고 응답을 받는 작업이다.
작업의 성향에 따라 다음 4가지로 분류된다.
- Sync(Synchronous)
- Async(Asynchronous)
- Blocking
- Non-Blocking
이 4가지 작업에 대한 명확한 구분을 이해하기 어렵다.
다른 개발자들도 각기 저마다 다르게 해석 하는것 같다.
따라서 내 나름대로 한번 정리를 해보고자 한다.
혼란의 원인은 Blocking - Sync의 설명이 비슷하고 Non-Blocking - Async 설명이 비슷하다는 것이다.
우선 Sync/Async(Synchronous/Asynchronous) 와 Blocking/Non-Blocking은 서로 성향이 다르다.
이 성향의 차이란 단순히 I/O API 호출 동작 방식이나 결과값을 받아오는 타이밍 방식으로 해석하면 모호해진다.
이 차이는 숲과 나무와 같은 개념의 레벨 차이로 해석하는 것이 더 명확하다.
Sync/Async가 숲이라면 Blocking/Non-Blocking은 나무이다. Sync/Async가 좀더 크고 포괄적인 개념이다.
- 의존성 있는 작업들을 Sync하게 처리하기 위해 I/O API들을 Blocking 하게 사용할 것인가 ? Non-Blocking하게 사용할 것인가 ?
- 의존성 없는 작업들을 Async하게 처리하기 위해 I/O API들을 Blocking 하게 사용할 것인가 ? Non-Blocking하게 사용할 것인가 ?
다른 사람들은 이런 그림으로 개념을 나타내는데 개인적으로는
이 그림이 더 적절한 표현인것 같다
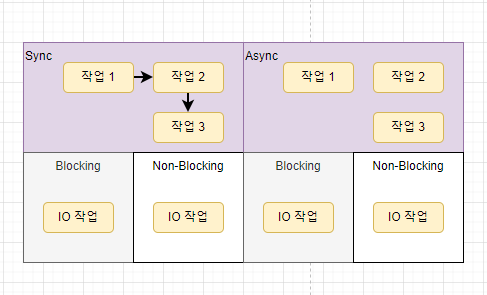
예를 들어 Sync한 작업들은 의존성 있는 작업들을 순차적으로 처리한다.
Sync한 작업들을 처리하기 위해 Blocking한 방식을 사용할 수 있고 Non-Blocking한 방식을 사용할 수 있다.
주의할 것은 작업 1, 작업 2... 등은 반드시 I/O 작업이 아니고 I/O 작업까지 포함하는 추상적인 작업이다.
Blocking/Non-Blocking는 Sync/Async 처리 방식을 구현하기 위한 도구일 뿐이다.
Sync/Async
작업 여러개를 어떻게 처리할지 결정하는 방식이다.
작업 시간(시작, 끝)이 있는 여러 작업들이 정렬되어 순서대로 처리되면 Sync이다. 그러나 순서대로 처리되지 않으면 Aync다.
Sync
Sync로 처리해야 하는 작업들은 작업들끼리 서로 의존성이 있어 어떤 작업이 처리가 되어야 그 결과를 바탕으로 다음 작업을 처리할 수 있다.
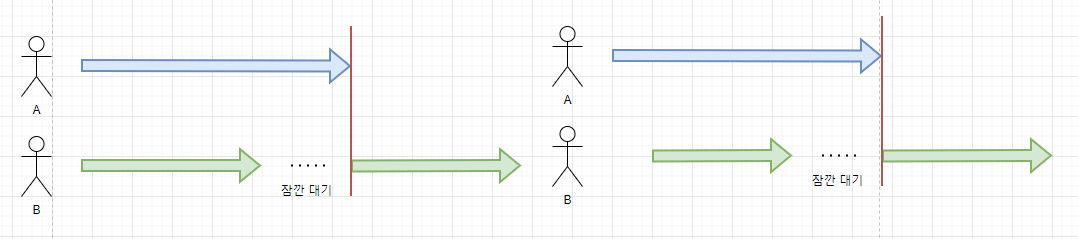
이 그림을 보면 작업자 A, B가 작업 Blue, Green을 맡아서 처리하고 있다.
작업 Blue, Green을 실행하는 시점은 같거나 다를 수 있다.
그러나 Green 작업은 중간에 절대 Blue 작업이 완료될때까지 대기하고 그 결과를 바탕으로 다음 작업을 진행해야 한다. Green 작업은 Blue 작업에 의존한다.
Async
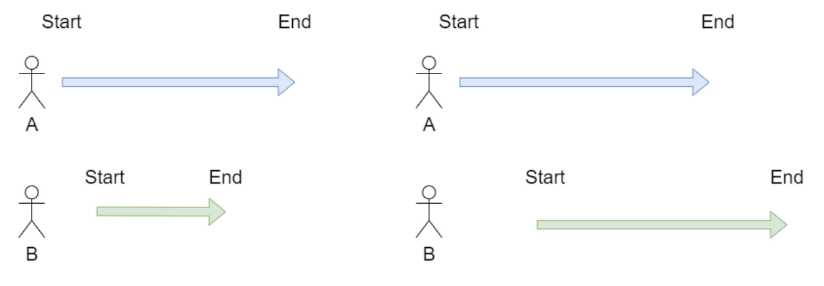
반면 Aync는 작업간 의존성이 없어 다른 작업이 완료 될때까지 대기할 필요가 없다.
Blocking/Non-Blocking
이 관점은 하나의 작업자가 I/O 작업 하나에 대해서 어떻게 처리할지 결정하는 것이다.
Blocking
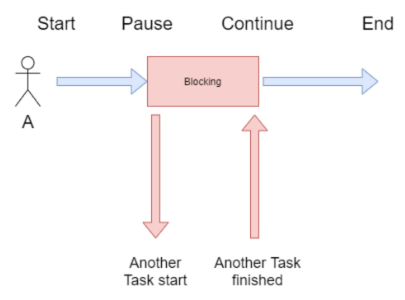
단순 read/write I/O 함수 호출이 여기에 해당된다.
한 스레드에서 I/O 작업을 요청하고 완료되어 커널로 부터 결과를 받을때까지 대기(Blocking)한다.
API 호출 후 결과를 받을때까지 return 되지 않는다.
Non-Blocking
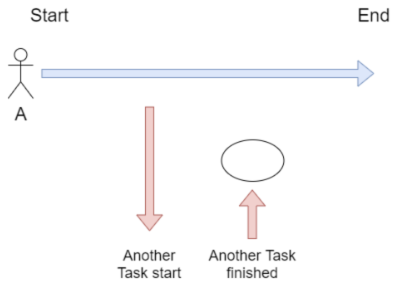
read/write I/O 함수에 NON-BLOCK 옵션 설정한 함수 호출이 여기에 해당된다.
한 스레드에서 I/O 작업을 요청하고 완료되지 않아도 대기하지 않고(Non-Blocking) 해당 스레드는 다음 처리를 수행한다.
API 호출 후 결과를 받든 안받은 상관없이 바로 return 되면 Non-Blocking이다.
조합 사례
다은과 같은 조합이 있을 수 있다.
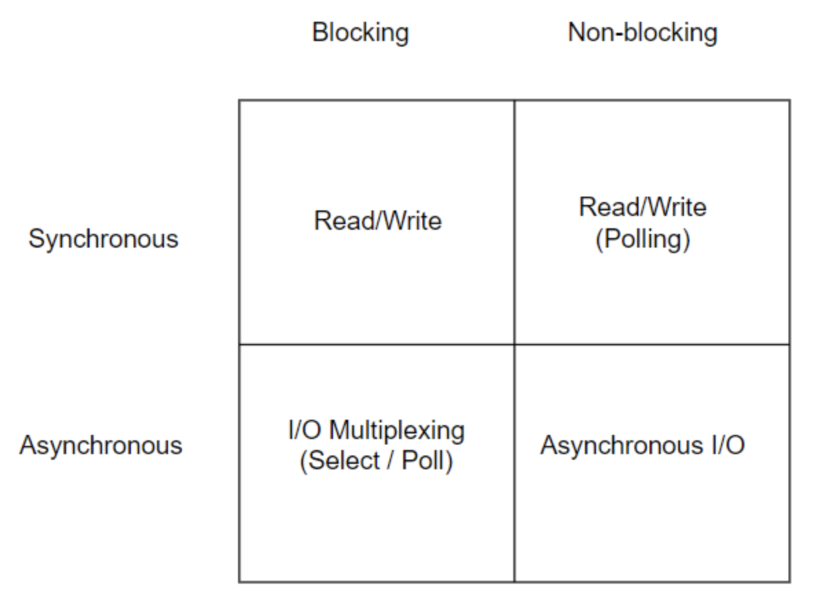
위에서 말한 Sync/Async와 Blocking/Non-Blocking간의 관계를 생각 하며 이 그림을 해석해야 한다.
다음은 조합의 사례들이다.
Synchronous + blocking I/O
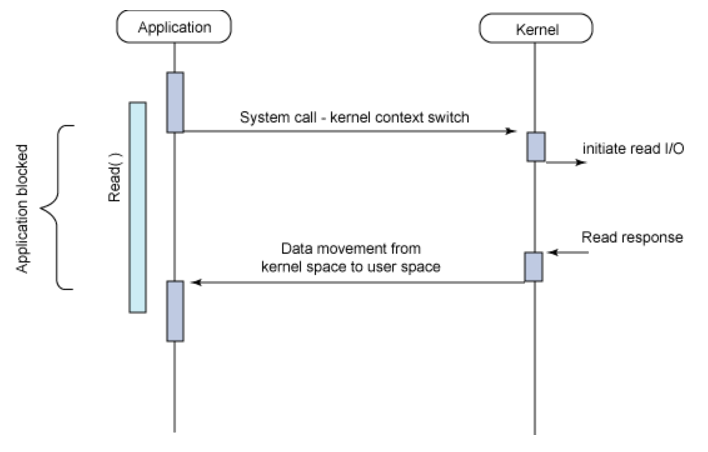
Application이 Read(blocking I/O) 함수를 호출하여 값을 가져오고 있다.
Read()가 완료되기 전까지는 다음 작업을 수행하지 않고 대기하며 작업이 완료되고 나서야 다음 작업(Synchronous)을 수행한다. 대기를 할때는 CUP를 점유하지 kernel의 응답만 기다린다.
CPU 리소스 사용률이 높아야하는 작업에는 적합하지 않은 모델이다.
Synchronous + non-blocking I/O
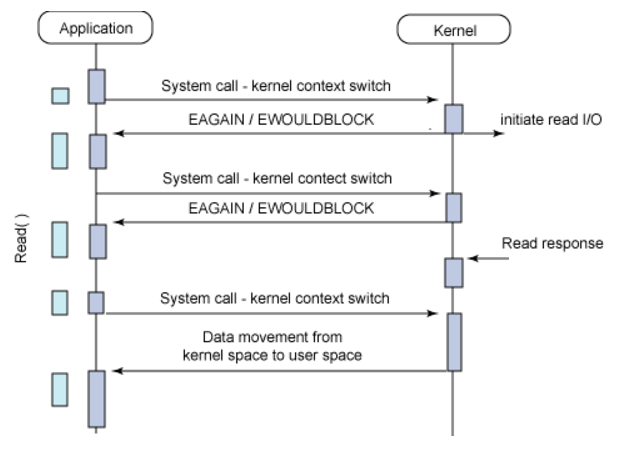
위 그림은 Polling 방식의 예다. Polling이란 다른 주체가 수행하는 작업의 결과를 얻을때 주기적으로 신호를 보내거나 API를 호출하여 확인하는 방식이다. 작업이 완료 되었다면 결과를 얻는 것이며 작업이 완료되지 않으면 결과를 받는 대신 바로 미완료라는 응답을 받는다.
Application이 Read(non-blocking I/O) 함수를 호출하여 값을 가져오고 있다. non-blocking이라서 작업이 완료되지 않을때마다 실패(EAGAIN/EWOULDBLOCK) 응답을 받지만 결국 마지막에는 Kernel이 작업을 완료하여 Kernel로부터 결과를 받는다 이후 다음 작업(Synchronous)을 수행한다.
non-blocking한 socket을 생성하려면 O_NONBLOCK 옵션을 사용해야 한다.
이 방식은 너무 자주 호출하면 의미 없는 CPU 사용률이 높아진다는 점이다. 그렇다고 자주 호출하지 작업은 완료 되었지만 바로 확인이 안되어 반응이 느리다.
Asynchronous + Non-Blocking I/O (AIO)
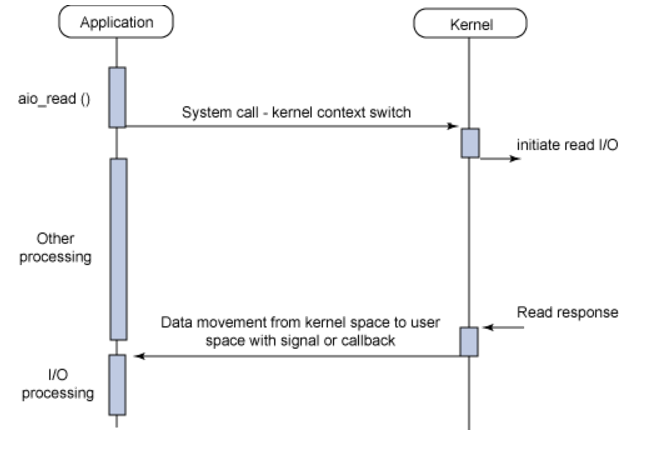
Application이 aio_read(Non-Blocking) 함수를 호출한다. 그리고 나서 Application은 다음 작업을 수행한다. aio_read만 보면 사용 방식이 polling 방식과 비슷해서 Synchronous + non-blocking I/O과 혼동될 수 있는데 중요한 차이점은 aio_read 호출 후 다른 작업을 수행 한다는 것이다. Synchronous + non-blocking I/O는 결과를 받기 전에는 다음 작업을 수행하지 않았다.
Asynchronous + Blocking I/O (I/O Multiplexing)
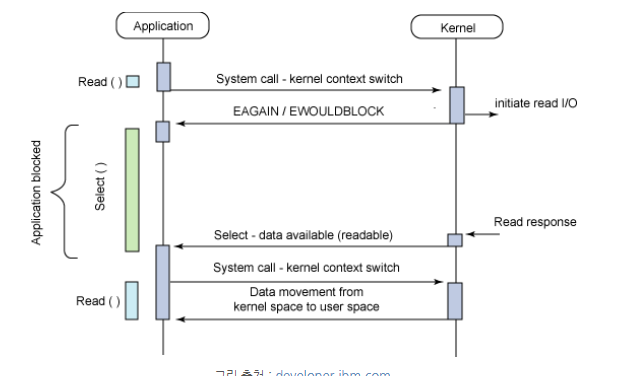
select(blocking) 호출시 select에서 관리하는 여러 I/O중에서 데이터 준비된 I/O가 있을때까지 대기한다.
데이터 준비된 I/O가 생기면 다른 I/O작업이 완료 여부와는 상관 없이(Asynchronous) Read()를 호출하여 작업을 완료한다.
위 그림에서는 첫 Read 요청에서 Non-blocking 호출이 있는데 이는 select의 결과에 따라 Read를 수행하게끔 구현하면 socket을 Non-blocking 모드로 생성하지 않아도 되며 첫번재 Non-blocking Read 호출을 제거할 수 있다.
그럼에도 socket은 Non-blocking으로 생성하는 것을 권고한다. 데이터가 checksum 실패로 폐기되는 등의 일부 상황에선 select가 어떤 FD에 데이터 있으니 읽으라고 알려와서 읽었다가 socket이 Block 되는 상황이 발생. 이런 상황에서 socket이 Non-blocking이 아니라면 무한 대기가 된다
데이터를 받는 socket을 Non-Blocking으로 구성하여 EWOULDBLOCK error만 return 하고 넘어가게끔 설계하여 안전성을 높일 수 있다. Read가 실패하여 blocking이 되는 상황도 고려해야 한다.
I/O Multiplexing에 대한 해석은 논란이 있다.
select는 blocking이고 Read도 blocking으로 사용할 수 있지만 안정성을 위해 Non-blocking으로 사용한다. 각 Read한 후 처리하는 작업들이 서로 의존성이 없으면 Asynchronous하게 처리 가능 하지만 만약 의존성이 있다면 뮤텍스, 세마포어를 이용하여 Synchronous 하게 처리해야 한다.
또한 I/O Multiplexing 기법(epoll, iocp, select, ...)에 따라 알림 방식과 로직이 달라질 수 있다.
I/O Multiplexing을 Asynchronous + Blocking I/O 모델로 분류하기 보다는 I/O Multiplexing이라는 개념에 집중하는 것이 좋을것 같다.
I/O Multiplexing은 중첩 I/O라고도 불린다. I/O들을 겹쳐서 select, epoll과 같은 함수들로 랩핑한 후 여러 I/O 이벤트를 한번에 감지할 수 있는것이다. 이벤트가 발생하면 해당 I/O를 가져와 처리한다.
