
Linux 파일 I/O는 크게 두가지로 분류 된다.
- Low-Level File I/O
- High-Level File I/O
Low-Level File I/O(System call)
system call을 이용해서 파일 입출력을 수행한다.
#include <unistd.h>
File descriptor 사용
Byte 단위로 디스크에 입출력
특수 파일에 대한 입출력 가능하다.
High-Level File I/O(Buffered I/O)
C Standard lib 사용해서 파일 입출력 수행
#include <stdio.h>
File pointer 사용하지만 File descriptor도 지원한다.- FILE* fp
버퍼(block) 단위로 디스크에 입출력을 지원하며 그 외 여러 형식의 입출력을 지원한다
IO 스트림 플러쉬 결정을 Application에서 결정할 수 있다.
Page cache
Disk 접근 시간 절약을 위해 kernel 내부적 기법.
디스크 접근 속도가 느리니 디스크에 저장하는 메모리 단위인 페이지 크기의 임의 메모리(캐시)에 데이터를 기록하여 모은 다음 한번에 가급적이면 최소한으로 디스크에 접근하여 저장 하는 방식
Page write-back
Page cache에 변경 된 내용을 disk에 반영하는 것. 반영 시기는 kernel이 결정
Low-Level IO에서는 Page write-back 수행. fsync system call 호출하여 Page write-back 강제로 수행하는 것은 가능 하지만 Application에서 필요한 경우에만 Page write-back을 할 수는 없어 자율성이 떨어진다.(High level I/O에서도 flush 기능을 제공)
만약 Application에서 자유롭게 Page write-back을 하고 싶다면 직접 Application에서 Buffer를 생성하여 관리하면 된다. 하지만 이럴 필요 없이 High-Level File IO에서 Buffered IO 기증을 지원 하므로 직접 구현할 필요가 없다.
Disk address
Physicla disk address
옛날 HDD 기준 Sector(물리적 데이터 전송 단위)를 지정
- A사 HDD => Sylinder Number | Surface Number | sector Number
- B사 HDD => Surface Number | Sylinder Number | sector Number
- C사 SDD => 그들 만의 물리 주소 방식
개발자가 각 디스크의 메모리 접근 방식을 모두 알고 있어야 할까 ? --> No. 현실적으로 불가능
그래서 Linux OS에서는 Logical disk address 사용
Logical disk address: relative address
Disk system의 데이터 전체를 block들의 나열로 취급한다.
Block에 번호를 부여하고 Block 번호를 통해 임의의 block에 접근 가능하다.
Linux 시스템은 논리적인 disk address 주소 체계를 구축하고
각 HW 회사에서는 자신들의 디스크 장비를 Linux 시스템에서 동작 시키기 위해 논리적 disk address를 지원하는 디바이스 드라이버를 개별적으로 만든다.
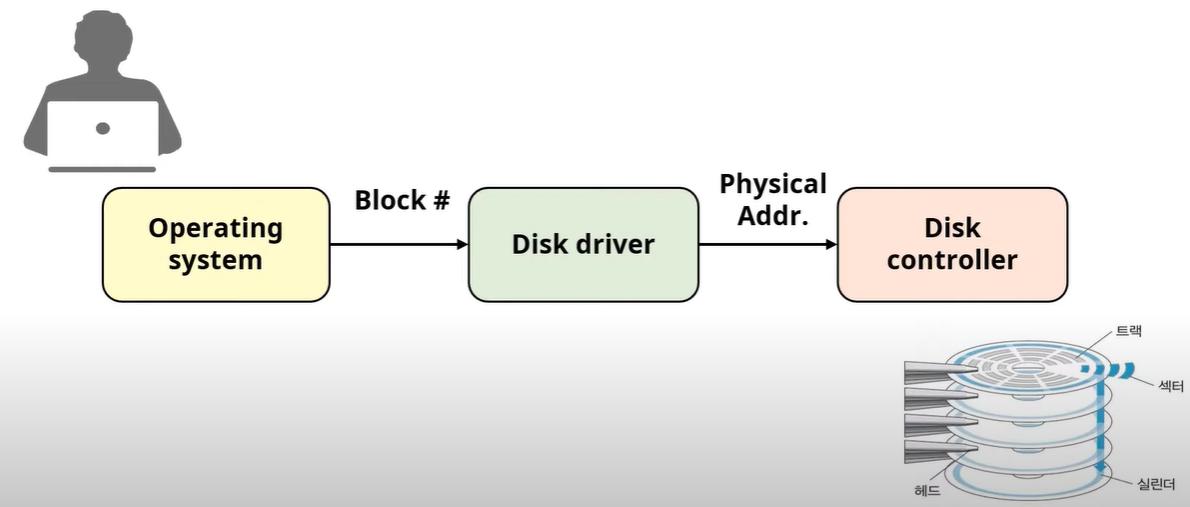
Block 번호 -> physical address 모듈 필요(disk driver)
Block
OS(ex: linux) 입장에서 파일 시스템은 block들의 나열이다. Block을 통해 파일 시스템을 추사오하 하였다.
512 ~ 8192 bytes(2 ^ n)
Block size는 Page size보다 작다
Disk(or block device) 접근의 최소 단위이다.
Kernel buffer(page cache, Low-level I/O)
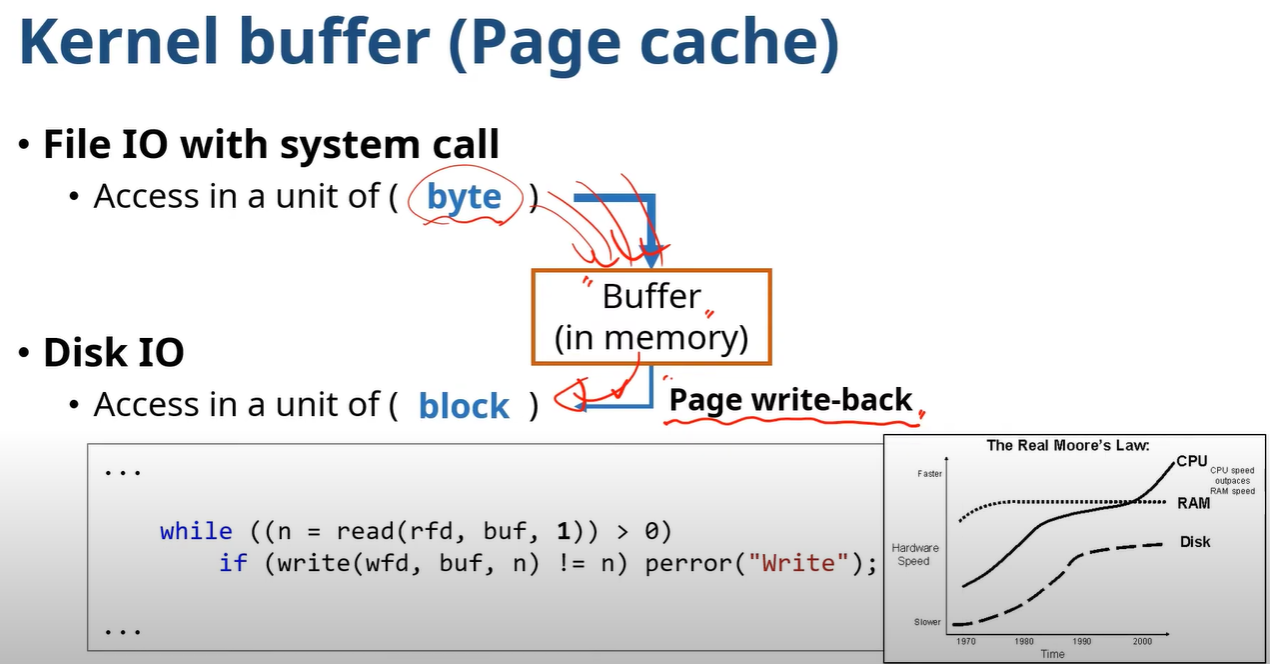
위 그림은 Low Level I/O가 동작하는 방식이다.
byte를 write 할때는 1 byte여도 Disk I/O는 Block 단위로 발생한다.
만약 매번 디스크에 저장하면 속도가 굉장히 느리다.(또한 User mode에서 Kernel mode로 접근할때 context switching도 성능 저하의 요인)
따라서 커널은 임의 Buffer를 메모리에 만들어 데이터를 모은 다음 Block 단위로 디스크에 접근하여 한번에 저장(Page write-back)함으로서 성능을 높인다.
Buffering mode 지원
stdio는 3가지 buffering mode를 지원한다. 이 mode는 setvbuf 함수를 사용하여 변경 가능 하다.
int setvbuf(FILE* stream, char* buf, int mode, size_t size);Unbuffered(_IONBF)
버퍼링 하지 않음
Line-buffered(_IOLBF)
\n 문자를 기준으로 버퍼링을 수행한다.
터미널에 연결된 기본 스트림(표준 출력 - stdout, 표준 입력 - stdin)들은 이 모드가 기본이다.
Block-buffered(_IOFBF)
블록 단위로 버퍼링이 이루어진다.
파일과 연결된 스트림은 이 모드가 기본이다.
