학습동기
N+1 문제를 해결하기 위해서 fetchJoin을 자주 사용한다. 하지만 @OneToMany의 경우 카테시안 곱 문제나 여러개의 fetchJoin을 사용할 경우 발생하는 MultipleBagFetchException을 고려해줘야한다. 이것 말고도 fetchJoin을 사용하면서 주의해야할 점에 대해서 정리해보려고 한다.
Fetch Join
Fetch Join은 SQL에서 제공하는 Inner,Outer 같은 Join문과는 다르다. JPQL에서 성능을 최적화하기 위해 제공하는 기능이다.
@Test
void fetchJoin() {
String jpql = "select m from Member m join fetch m.team";
List<Member> members = em.createQuery(jpql, Member.class)
.getResultList();
for (Member member : members) {
System.out.println(
"member.getName() = " + member.getName() + ", " + "teamName = " + member.getTeam().getName());
}
}
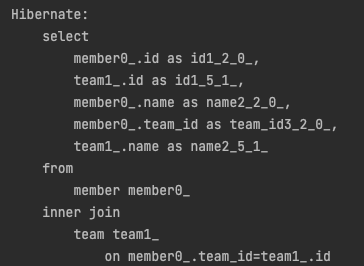
한번의 쿼리로 Member를 조회할 때 속해있는 Team까지 한번에 조회할 수 있다.
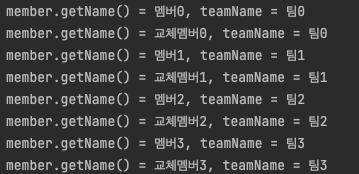
fetchType이 Lazy로 설정되어있어도 fetchJoin이 우선순위를 가지기 때문에 한번의 조회로 연관된 엔티티를 같이 조회한다.
예시처럼 다대일 관계에서는 fetchJoin을 쓰면 N+1 문제를 해결할 수 있다. 하지만 일대다 관계에서는 고려해야할 사항들이 있다.
@OneToMany에서 고려할 사항
가장 먼저 문제가 되는 상황은 데이터가 카테시안 곱만큼 늘어나서 조회된다는 것이다.
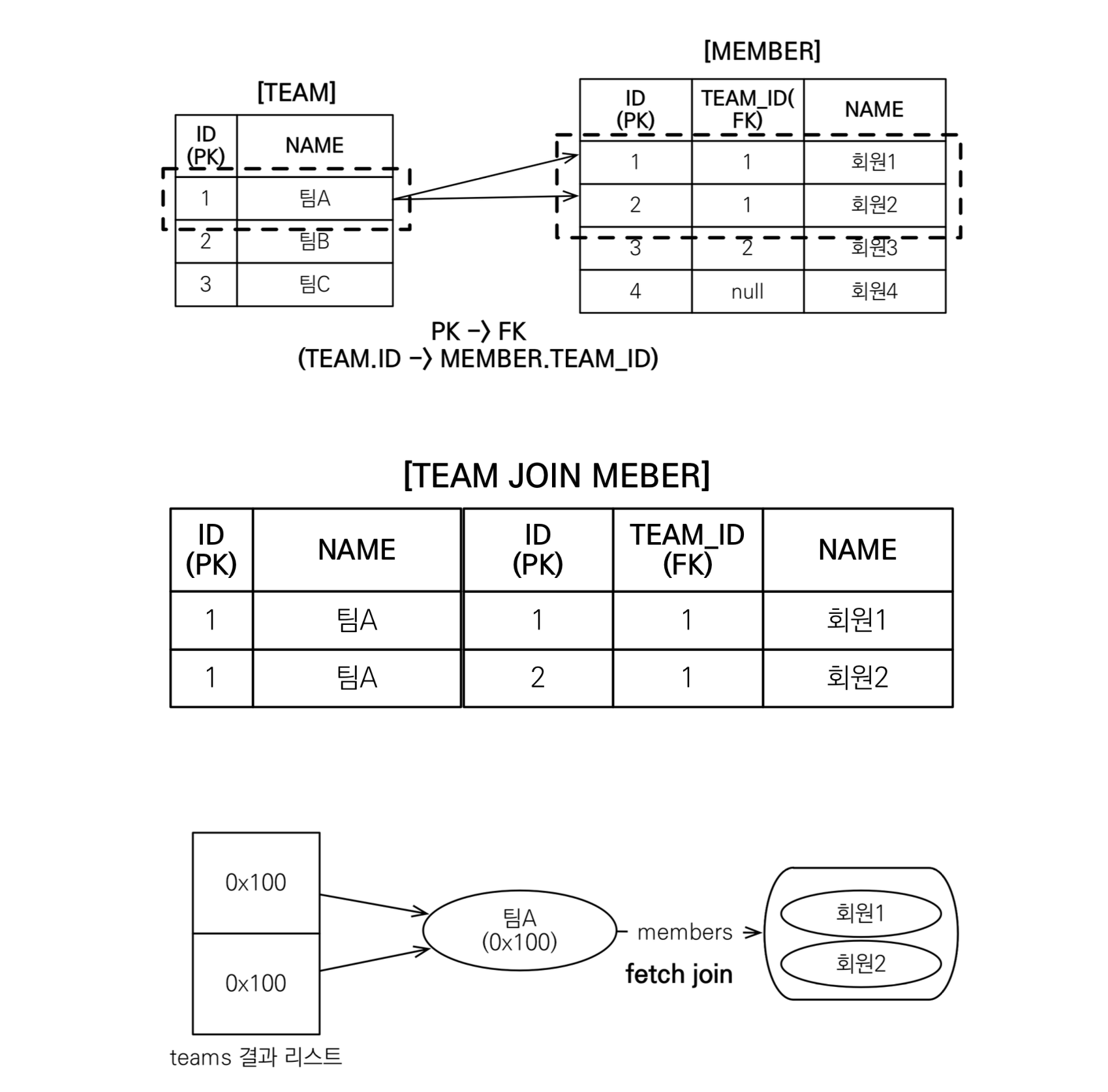
그림에서 보이는 것 처럼 TeamA에 Member가 2명 존재하는 경우 fetchJoin으로 TeamA와 Member를 조회하는 경우 Team이 Member의 수만큼 곱해져 TeamA가 2개로 조회되는 문제가 발생한다.
이 문제를 해결하기 위해서는 Distinct를 사용하면 된다.
select distinct t from Team t join fetch t.members
where t.name = '팀A'해당 distinct는 jpql에서 지원하는 distinct로 sql distinct의 기능에 추가로 애플리케이션에서 엔티티 중복을 제거한다.
sql의 distinct를 사용할 경우 join 하는 member의 데이터가 다르므로 중복제거에 실패한다.
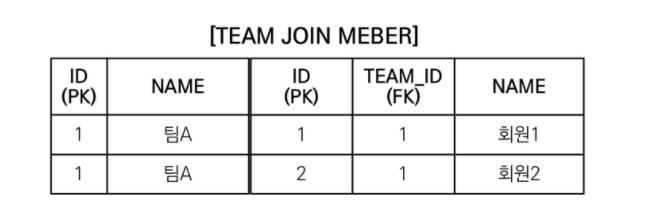
jpql에서의 distinct는 추가로 애플리케이션에서 중복을 제거하기 때문에 팀A의 중복을 제거할 수 있다.
FetchJoin과 일반 조인의 차이
일반 조인으로 실행하면 연관된 엔티티를 조회하지 않는다.
inner 조인으로 실행시켰을 때는 아래와 같은 결과를 반환한다.
String jpql = "select m from Member m inner join m.team";
List<Member> members = em.createQuery(jpql, Member.class)
.getResultList();
for (Member member : members) {
System.out.println(
"member.getName() = " + member.getName() + ", " + "teamName = " + member.getTeam().getName());
}
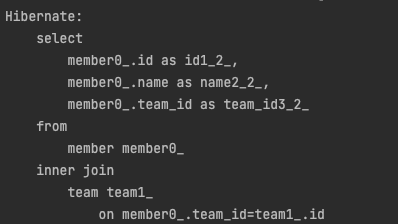
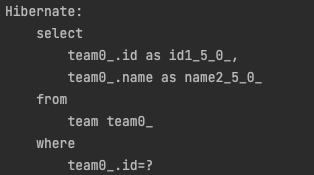
team을 select하는 쿼리는 n번 발생해서 N+1 문제가 발생한다.
join fetch를 하는 경우에는 아래와 같이 쿼리가 나간다.
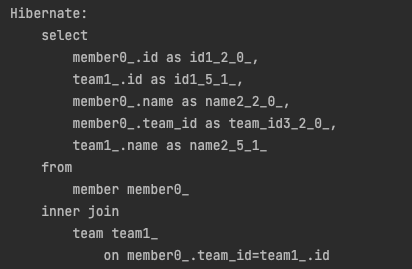
연관관계에 필요한 값까지 모두 가져오는 것을 확인할 수 있다.
fetchJoin을 사용하면 연관된 엔티티도 함께 조회한다.
FetchJoin의 특징과 한계
1. 별칭을 줄 수 없다.
select m from Member m join fetch m.team tteam에 t처럼 값을 부여할 수 없다. 하이버네이트에서는 사용 가능하지만 가급적 사용하지 말자. 엔티티 그래프를 훼손시킬 수 있다.
fetch Join을 할 때는 일부만 가져오는 것이 아니라 전체 값을 받아와야 한다.
2. 둘 이상의 컬렉션은 Fetch Join 할 수 없다.
이전글 에서 확인한 것 처럼 하나의 엔티티에 @OneToMany 가 두개 이상 존재하면 MultipleBagFetchException이 발생한다.
여러 엔티티를 fetch하게되면 bag이라는 구조에 담기게 되는데, bag은 순서가 없기 때문에 두개 이상의 엔티티를 받아오게 되면 카테시안 곱으로 늘어나게 된다. 그래서 OneToMany로의 fetchJoin은 하나로 제한된다.
3. 컬렉션을 Fetch Join하면 페이징을 사용할 수 없다.
~ToOne 은 페이징이 가능하다.
일대다 관계의 엔티티를 페이징하게 되면 데이터를 전부 가져오고나서 메모리에서 페이징을 한다. 쿼리로 살펴보자.
@Test
void fetchJoin() {
String jpql = "select t from Team t join fetch t.members";
List<Team> teams = em.createQuery(jpql, Team.class)
.setFirstResult(0)
.setMaxResults(2)
.getResultList();
for (Team team : teams) {
System.out.println("member.getName() = " + team.getName());
for (Member member : team.getMembers()) {
System.out.println("-> member = " + member.getName());
}
}
}해당 쿼리를 실행하면 페이지네이션이 적용되어 2개의 값만 반환된다.
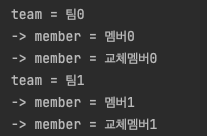
하지만 실행된 쿼리에는 limit이 걸려있지 않다.
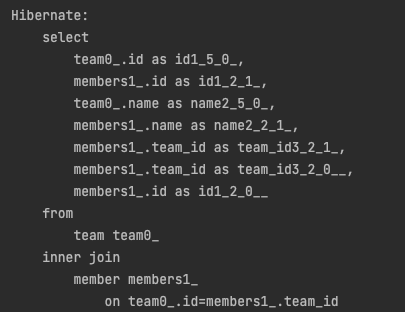
member를 대상으로 페이지네이션을 걸게되면 아래와 같이 limit이 걸린다.
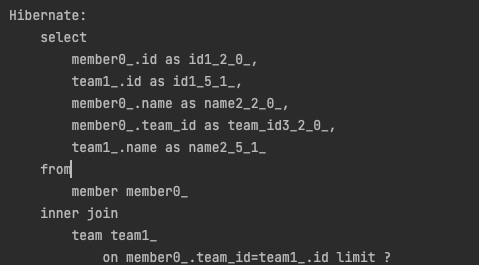
이는 로그를 통해서 확인할 수 있는데,
WARN 27013 --- [main] o.h.h.internal.ast.QueryTranslatorImpl : HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!페이지네이션이 이뤄진 데이터를 받은 것이 아니라 모든 데이터를 받아와서 메모리에서 페이지네이션을 적용해서 값을 주는 것이다.
따라서 @OneToMany 의 경우 fetch join을 하게 되면 페이지네이션 API를 활용할 수 없다는 단점이 있다.
실무에서는 batchSize를 통해서 해결한다고 한다.
정리
-
연관된 엔티티들을 SQL 한번으로 조회해서 성능을 최적화한다.
-
엔티티에 직접 적용하는 로딩 전략보다 우선한다.
-
실무에서 모든 글로벌 로딩 전략은 지연 로딩으로 설정하고, FetchJoin으로 최적화한다.
-
모든 것을 fetchJoin으로 해결할 수 없다. 객체 그래프를 유지할 때 사용하자
Reference
자바 ORM 표준 JPA 프로그래밍 - 김영한 지음
https://www.baeldung.com/java-hibernate-multiplebagfetchexception
