인덱스를 이용하는데 성능이 더 느린 이유
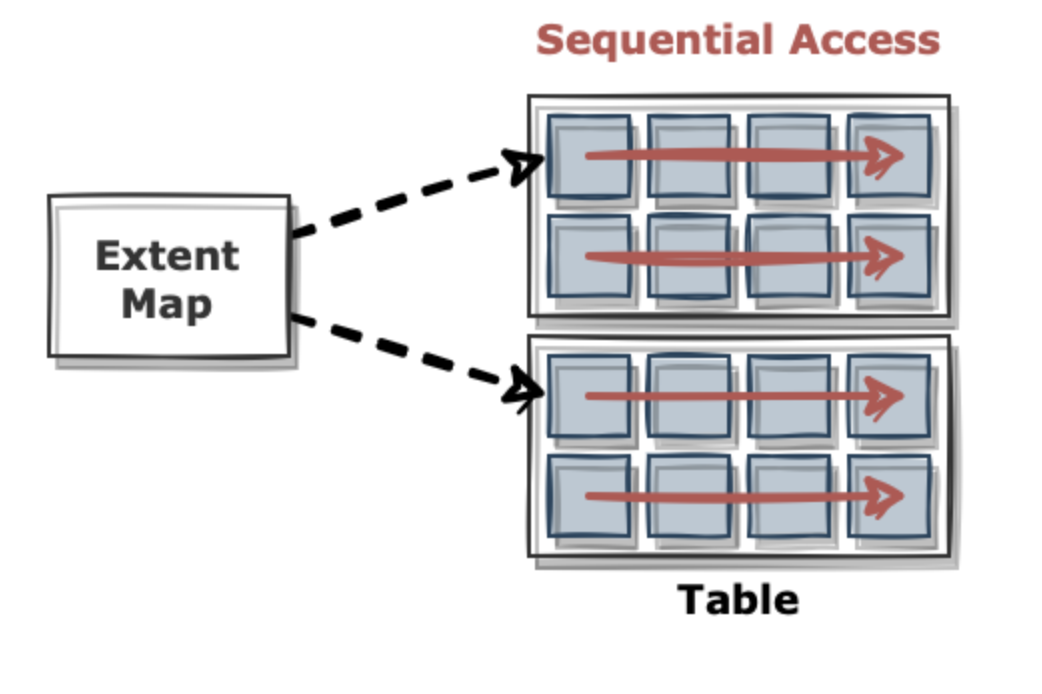
- Table Full Scan의 경우 시퀀셜 액세스와 Multiblock I/O 방식으로 디스크 블록을 읽는다. 이때 한번의 접근으로 수십~수백 개 블록을 가져올 수 있다.
- 수십~수백 건의 소량 데이터를 찾을 때 수백만~ 수천만 건 데이터를 스캔하는 건 비효율 적 따라서 큰 테이블에서 소량 데이터를 검색할 때는 반드시 인덱스 사용
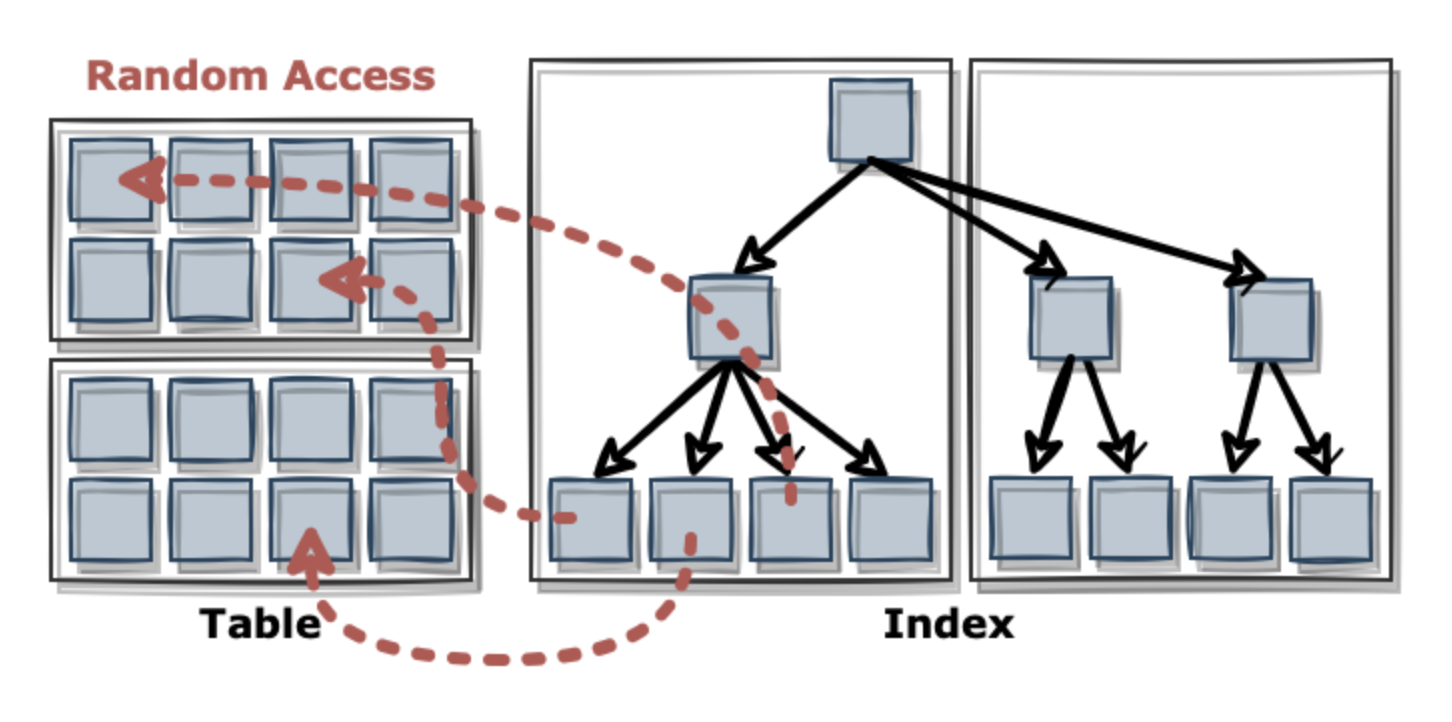
- Index Range Scan을 통한 테이블 액세스는 랜덤 액세스(비 순차적 액세스)와 Single Block I/O 방식으로 디스크 블록을 읽음
- 즉 하나의 데이터를 찾기 위해 I/O를 각각 요청해야 한다.
- 만약 한블록에 평균 500개의 레코드가 있다면, 같은 블록을 최대 500번 읽을 수 있다. 만약 인덱스를 이용해 '전체레코드'를 액세스 한다면, 모든 블록을 평균 500번씩 읽게 된다. 즉 각 블록을 단 한 번 읽는 Table Full Scan 보다 훨씬 불리
table full scan
index range scan
의문점
index range scan은 multiblock I/O가 안되는가?
이 의문점에 대한 답은 인덱스의 구조와 관련 있다고 생각한다. 애초에 인덱스를 저장할때 순차적이지 않기 때문에 말이 되지 않는 질문이다.

엄마나는커서개발자가될래요!!!