쿠버네티스 인 액션 '4장.레플리케이션과 그 밖의 컨트롤러: 관리되는 파드 배포'을 읽고 정리한 내용이다.
여기서 다루는 내용은 아래와 같다
- 파드의 안정적 유지
- 동일 파드의 여러 인스턴스 실행
- 노드 장애시 자동 파드 재 스케줄링
- 파드의 수평 스케줄링
- 각 클러스터의 노드에서 시스템 수준의 파드 실행
- 배치 잡 실행
- 잡을 주기적 또는 한번만 실행하도록 스케줄링
파드를 안정적으로 유지하기
우리는 k8s를 사용하면서, 파드를 수동적으로 개입하지 않아도 안정적인 상태를 스스로 유지하길 원한다.
-> 레플리케이션컨트롤러, 디플로이먼트가 이런 것들을 해준다.
사실 k8s 스스로도 기본적으로 해주는 것들이 있다...
컨테이너의 주 프로세스에 크래시가 발생하면 kubelet이 컨테이너를 다시 시작한다.
예를 들어, 만약 어플리케이션 버그로 인해 크래시 발생 시, k8s가 어플리케이션을 자동으로 재시작한다.
하지만 어플리케이션이 무한 루프나 교착 상태에 빠져 응답하지 않는 상황이라면?
-> 이 경우에는 어플리케이션을 자동으로 재시작하지 않는다
즉, 어플리케이션 내부 기능에 의존하지 말고 외부에서 상태를 체크해야한다. 외부에서 어플리케이션의 상태를 체크하고 있다가, 문제가 발생함을 인지하고 조치를 취해야 한다.
라이브니스 프로브
이 것을 통해 컨테이너가 살아있는지 확인할 수 있다.
파드의 specification에 각 컨테이너 마다 라이브니스 프로브를 지정할 수 있다.
k8s는 주기적으로 프로브를 실행 -> 문제있을 시 해당 프로브가 지정된 컨테이너 재시작
프로브 실행 메커니즘
HTTP GET 프로브
- IP 주소, 포트, 경로 지정하며 HTTP GET 요청 수행
- HTTP 에러코드 리턴 or 무응답 시 재시작
TCP 소켓 프로브
- 지정된 포트에 TCP 연결 시도
- 연결 실패하면 재시작
Exec 프로브
- 컨테이너 내의 임의의 명령 실행
- 명령의 종료 상태 코드 확인 : 0 외의 값은 실패 -> 재시작
apiVersion: v1
kind: pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe:
httpGet:
path: /
port: 8080
여기서 정의한 라이브니스 프로브는 컨테이너가 문제가 있다고 판단하면 재시작 시킨다.
kubectl describe po kubia-liveness 명령을 내렸을 때 볼 것
Last State: Terminated
Exit Code: 137 이면 128+x (x: 9 == SIGKILL)
Liveness: .....
- delay : 컨테이너 시작 후 얼마나 지나서 프로브 시작할 것인지
- timeout : 얼마의 시간 안에 컨테이너가 응답해야하는지
- period : 프로브 실행 주기
- failure : 연속 실패 횟수 제한
라이브니스 프로브의 속성 지정하기
...
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 15 # 컨테이너 뜨고나서 첫 프로브까지 대기 시간
효과적인 라이브니스 프로브 생성
운영환경에서 실행 중인 파드는 반드시 라이브니스 프로브를 정의해야 한다.
정의하지 않으면 쿠버네티스가 어플리케이션이 살아 있는지를 알 수 있는 방법이 없다.
프로세스가 실행되는 한 쿠버네티스는 컨테이너가 정상적이라고 간주할 것이다.
더 나은 라이브니스 프로브를 위해 특정 URL 경로 (ex, /health)에 요청하도록 프로브를 구성해 어플리케이션 내에서 실행중인 모든 주요 구성요소가 살아 있는지 또는 응답이 없는지 확인하도록 구성할 수 있다.
웹서버의 경우, 웹서버 컨테이너를 재시작해서 해결할 수 있는 문제일때만 라이브니스 프로브가 실패하도록 해야한다.
예를 들어, DB 서버의 문제가 있다고 해서 웹서버 컨테이너의 프로브가 실패하게 구현하면 안된다.
또한 너무 많은 리소스를 사용하지 않고 1초내에 응답해야한다.
요약
컨테이너에 크래시가 발생하거나 라이브니스 프로브가 실패한 경우,
K8S는 컨테이너를 재시작 한다.
이 작업은 kubelet이 한다.
하지만 노드 자체에 크래시가 발생한 경우, 중단된 모든 파드의 대체 파드를 생성하는 것은 컨트롤 플레인이 한다.
레플리케이션 컨트롤러
k8s 리소스 중 하나로 파드가 항상 실행되도록 보장한다.
파드가 하나 사라지면? 사라진 파드를 감지해 교체 파드를 생성한다.
지정한 숫자의 파드가 항상 클러스터 내에 동작하는 상태로 존재하도록 유지한다!
만약 노드가 고장나더라도 해당 노드안에 있던 관리되는 pod들은 레플리케이션 컨트롤러에 의해 다른 노드에 자동으로 생성된다.
일반적으로 파드의 여러 복제본을 관리하기 때문에 이런 이름을 가졌다.
질문) 한 파드가 여러 레이블을 가지고 있고, 동시에 2개 이상이 rc에서 관리받는다면 두 rc 각각의 스케일링에 따라 어떻게 동작하나?
동작
실행중인 파드 목록 지속적으로 모니터링 -> 의도하는 수와 일치하는지 확인
- desired count 보다 크면 제거, 작으면 생성
레플리케이션 컨트롤러는 레이블 셀렉터 당 desired count 를 관리한다.
역할은 항상 정확한 수의 파드가 레이블 셀렉터의 desired count와 일치하는지를 확인하고 조치하는 것이다.
요소
- 레이블 셀렉터
레플리케이션 컨트롤러의 범위에 있는 파드를 결정 - 레플리카 수
실행할 파드의 desired count 지정 - 파드 템플릿
새로운 파드를 만들기 위해 사용
사용시 이점
기존 파드가 사라지면 새파드를 시작해 항상 실행되도록 한다
노드에 장애 발생시, 노드에 속해있던 파드들 교체 복제본 생성
수동 또는 자동으로 파드를 쉽게 수평 확장할 수 있음
생성
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 3
selector:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- image: luksa/kubia
name: kubia
ports:
- containerPort: 8080
템플릿의 파드 레이블과 컨트롤러의 레이블 셀렉터는 완전히 일치해야 함.
그렇지 않으면 무한정 생산할 수 있음.
k8s API 서버가 이를 검증해주지만, 셀렉터를 지정하지 않는 것도 방법이다.
그러면 자동으로 템플릿의 레이블로 설정된다.
위 컨트롤러를 통해 생성된 파드 3개중, 하나를 제거하면 새로운 파드를 즉시 기동해 3개로 숫자를 맞춰준다.
레플리케이션 컨트롤러의 상태를 확인해보면 (kubectl describe rc kubia)
desired , current, ready 수를 확인할 수 있다.
ready 상태에 대해서는 추후 스 프로브에서 공부할 예정이다.
기존 파드를 삭제한 그 자체에 대한 대응으로 신규 파드를 만든게 아니다. 결과적인 상태(부족한 파드 수)에 대응하는 것이다.
노드 장애 예시
한 노드의 네트워크 인터페이스를 종료시켜 노드 장애 시물레이션을 해본다.
1. 네트워크 인터페이스 종료
2. 노드의 상태가 NotReady 상태로 변경
이때 파드의 상태는???
k8s가 파드를 재 스케줄링 하기 전 대기하는 기간 : 일시적인 네트워크 결함이나 kubelet 재시작 등의 이유로 노드에 일시적으로 도달할 수 없는 경우를 위해
3. 몇 분 동안 노드의 상태가 NotReady 상태로 유지되면 파드의 상태를 Unknown 상태로 변경.
이때 레플리케이션 컨트롤러는 즉시 새 파드를 기동한다.
즉 위 과정을 거쳐, 노드에 장애가 발생한 경우 인간의 개입없이 시스템이 자동으로 자가치유를 진행한다.
만약 이 상태에서 노드를 되살리면, Ready 상태로 돌아온다.
레플리케이션 컨트롤러의 범위
레플리케이션 컨트롤러와 그가 생성한 파드는 독립적이다.
레플리케이션 컨트롤러는 레이블 셀렉터와 일치하는 파드만을 관리한다.
파드의 레이블을 변경하면 기존 컨트롤러의 범위에서 제거되거나 추거될 수 있다.
다른 컨트롤러의 관리 범위로 이동할 수 있다(이동할 컨트롤러의 레이블 셀렉터와 일치하도록 레이블을 변경하면!)
아무 컨트롤러도 레이블 셀렉터로 지정하지 않은 레이블로 수정을 한다면, no-managed 파드가 된다. 그럼 당연히 자동 스케줄링 혜택도 못받아요..ㅠ
특정 파드에 어떤 작업을 하려는 경우 해당 파드를 컨트롤러의 범위에서 제거하면 작업이 수월하다.
ex) 문제가 있는 파드를 컨트롤러 관리범위에서 빼내어 컨트롤러가 대체 파드를 생성하도록 한후 원인분석을 하면 좋다
질문) 레플리케이션 컨트롤러의 레이블 셀렉터를 수정하면 어떻게 되나?
기존에 셀렉터가 가리키던 레이블의 파드들은 그대로 있되 관리되지 않는 상태로 가고,
새 레이블에 속한 파드들을 새로 생성한다.
파드 템플릿 변경
파드 템플릿 변경은 이미 생성이 되어있는 파드들에는 아무런 영향을 주지 않는다.
기존 파드 수정시 해당 파드를 삭제하고 컨트롤러가 새 템플릿을 기반으로 새 파드를 생성하도록 해야한다.
수평 파드 스케일링
원하는 파드 복제본 수를 변경하여 '수평 스케일링'을 할 수 있다.
- rc 리소스의 replicas 필드값을 변경하면 된다.
- 우리는 선언적으로 몇개의 복제본을 가져야하는지를 명시할 뿐이며, rc가 알아서 파드가 desired count 보다 많으면 일부를 삭제하고 적으면 추가로 생성한다.
- 'N개를 더 만들어줘' or 'M개를 삭제해줘' 같은 명령은 혼란의 여지가 있고 오류 발생 가능성이 높다.
- 이 책의 15장에서는 수평 파드 '오토'스케일링에 대해 배울 예정이다.
rc 리소스의 replicas 필드값 변경하는 방법 (2가지)
- kubectl scale rc 명령
$ kubectl scale rc kubia --replicas=10- rc의 정의 문서에 있는 spec.replicas 필드 값 편집하기
$ kubectl edit rc kubiaapiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
# 이 값을 10으로 수정후 편집기를 닫으면 rc가 업데이트 되고 즉시 파드 수가 10개로 확장된다
replicas: 3
selector:
app: kubia
template:
metadata:
labels:
app: kubia
spec:
containers:
- image: luksa/kubia
name: kubia
ports:
- containerPort: 8080
레플리케이션 컨트롤러 삭제
rc 를 삭제하면 그 rc가 관리하던 파드들은 어떻게 될까? 같이 삭제되나? 아니면 그냥 Not Managed 상태로 될까?
-> 이를 결정할 수 있는 옵션이 'cascade'
$ kubectl delete rc kubia --cascade=true
$ kubectl delete rc kubia --cascade=false레플리케이션 컨트롤러 대신 레플리카 셋 사용하기
레플리카 셋 이란 무엇인가
- 차세대 레플리케이션 컨트롤러
- 완전히 대체 가능
- 거의 동일하게 사용
- 일반적으로 레플리카 셋은 직접 생성 X
- 상위수준 리소스인 '디플로이먼트' 를 생성할 때 자동으로 생성된다.
차이점은?
더 풍부한 표현식을 사용하는 파드 셀렉터를 갖고 있음
레플리카 셋의 레이블 셀렉터
- 특정 레이블이 없는 파드 매칭
- 레이블 값과 상관없이 키를 갖는 파드 매칭
- env=production, part=common 이렇게 2개의 파드 세트를 모두 매칭시켜 하나의 그룹으로 취급할 수 있음
- rc는 동시 2개 파드 세트 매칭 못함 -> only 하나
레플리카 셋 (rs) 정의하기
# API group 'apps', 버전 'v1beta2' 에 속한다.
# rs는 v1 API의 일부가 아니다
apiVersion: apps/v1beta2
kind: ReplicaSet
metadata:
name: kubia
spec:
replicas: 3
# rs의 가장 간단한 셀렉터
selector:
matchLabels:
app: kubia
# 템플릿은 rc와 동일
template:
metadata:
labels:
app: kubia
spec:
containers:
- image: luksa/kubia
name: kubia
ports:
- containerPort: 8080
위 YAML 파일을 kubectl create 명령과 함께 사용하여 rs을 생성한다.
# rs 정보 확인 : rc와 동일한 정보를 관리하며 이를 보여줌
$ kubectl get rs
$ kubectl describe rs레플리카셋의 더욱 표현적인 레이블 셀렉터 사용하기
앞서 사용한 matchLabels 는 가장 단순한 레이블 셀렉터
'matchExpressions' 레이블 셀렉터 표현방법을 알아야 한다.
apiVersion: apps/v1beta2
kind: ReplicaSet
spec:
replicas: 3
selector:
matchExpressions:
- key: app
operator: In
values:
- kubia
template:
...
matchExpressions을 사용하면, 위와 같이 셀렉터에 표현식을 추가할 수 있다.
각 표현식은 키, 연산자, 가능한 값이 포함되어야 한다.
- In : 레이블의 값이 지정된 값 중 하나와 일치해야함
- NotIn : 레이블의 값이 지정된 값과 일치하지 않아야함
- Exists : 파드는 지정된 키를 가진 레이블이 포함돼야 한다 (값은 안중요)
- 이때 'values' 지정 안해야 함 - DoesNotExist : 파드에 지정된 키를 가진 레이블이 포함되어 있지 않아야 함 (값은 안중요)
- 이때 'values' 지정 안해야 함
여러 표현식을 지정하는 경우, 셀렉터가 파드와 매칭되기 위해서는, 모든 표현식이 true 여야함.
matchLabels 와 matchExpressions 를 모두 지정하면, 셀렉터가 파드를 매칭하려면 1.모든 레이블이 일치 2.모든 표현식이 true로 평가 되어야함.
레플리카 셋 정리
$ kubectl delete rs kubia레플리카 셋을 삭제하면 모든 파드가 삭제된다.
질문) cascade 옵션 없음???
데몬셋을 사용해 각 노드에서 정확히 한 개의 파드 실행하기
클러스터의 특정 레이블을 가진 노드들에 노드당 하나의 파드만 생성하도록 지정한다.
대상 노드들에 정확히 하나의 파드가 생성되며, 생성되지 않는 노드가 없도록 한다.
즉 노드 수 만큼 파드를 만들어 각 노드에 배치한다.
데몬셋은 타겟 노드들에 해당 파드가 실행되고 있는지를 모니터링 하며, 만약 실행되지 않고 있으면 새로 파드를 생성해서 실행시킨다.
마찬가지로 데몬셋에 지정된 파드 템플릿으로 새 파드 생성한다.
node-Selector 지정안하면 클러스터의 모든 노드 대상으로 파드를 배치한다.
rc, rs 에서 nodeSelector 를 사용하는 것과 차이점은?
- 특정 레이블을 가진 노드들에 pod를 desired count 만큼 배치한다. 이때 한 노드에 여러 동일 타입 pod 들이 들어갈 수 있으며, 특정 레이블을 가진 노드여도 pod 가 하나도 배치되지 않을 수 있다.
- 데몬 셋에서는 desire count 라는 개념이 없다
- rc, rs 에서는 '쿠버네티스 스케줄러'가 스케일링 및 배치 담당. 데몬셋은 그렇지 않음.
보통 시스템 수준의 작업을 수행하는 인프라 관련 파드가 데몬 셋을 이용하여 배치된다.
- 대상 노드들에서 로그 수집기로 동작하는 파드
- 대상 노드들에서 리소스 모니터링하는 파드로 동작
- k8s의 kube-proxy 프로세스 : 서비스를 작동시키기 위해 동작
k8s 미사용 환경에서는 일반적으로 노드 부팅시 '시스템 초기화 스크립트' 또는 'systemd' 데몬이 동작하며 노드가 시작된다. k8s 사용 환경에서도 그렇게 할 수 있지만, 그러면 k8s가 제공하는 모든 기능을 최대한 활용할 수 없다. (?)
데몬셋으로 노드에 파드 실행하기
노드 다운시 -> 해당 파드 새로 생성안함
새노드 추가시 -> 새 파드 인스턴스를 새 노드에 배포
대상 노드 하나에 실수로 누가 대상 파드를 삭제 -> 새 파드 인스턴스를 배포
예제
SSD를 갖는 모든 노드에서 실행되어야하는 ssd-monitor 데몬을 데몬 셋을 이용해 배치해보자.
apiVersion: apps/v1beta2
kind: DemonSet
metadata:
name: ssd-monitor
spec:
selector:
matchLabels:
app: ssd-monitor
template:
metadata:
labels:
app: ssd-monitor
spec:
nodeSelector:
disk: ssd
containers:
- image: luksa/ssd-monitor
name: kubia데몬셋의 파드 템플릿에서 파드의 label을 'app: ssd-monitor' 로 지정. 이 파드들은 'disk: ssd' 라는 label을 가진 node 들에만 배포됨.
데몬셋의 selector.matchLabels 설정을 통해 자신이 관리할 파드의 label을 'ssd-monitor' 로 지정.
$ kubectl create -f ssd-monitor-daemonset.yaml
$ kubectl get ds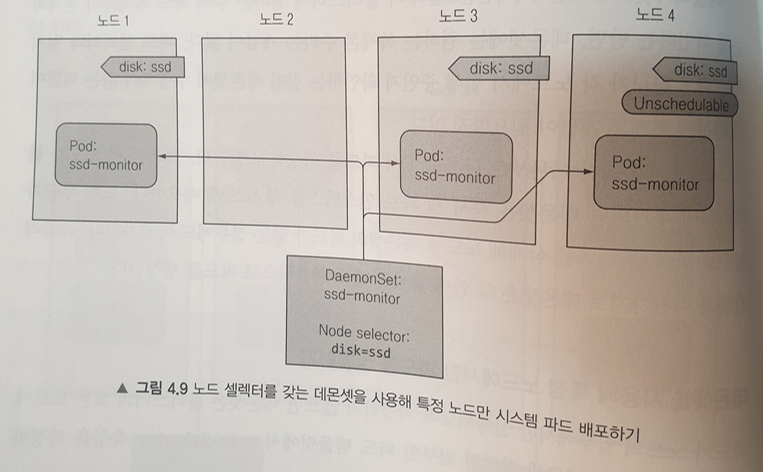
만약 위 예제에서, 갑자기 파드의 label 을 다른 것으로 변경하면 어떻게 되나?
label 변경된 파드가 종료된다.
또한, 만약 ssd-monitor 데몬셋을 삭제하면 실행중인 데몬 파드도 삭제된다.
(--cascade 옵션 없나?*)
완료가능한 단일 태스트를 수행하는 파드 실행
작업완료 후 종료되는 태스크만 실행하려는 경우가 있다.
- rc,rs,ds 은 완료됐다고 간주되지 않는 지속적인 태스크 실행
- 프로세스 종료시 자동으로 재시작 (무한)
완료 가능한 태스크 (completable task)에서는 프로세스가 종료되어도 자동으로 다시 시작되지 않는다.
잡 리소스
Job 이라는 리소스가 이런 기능을 지원한다.
파드의 컨테이너 내부에서 실행중인 프로세스가 성공적으로 완료되면 컨테이너를 다시 시작하지 않는다. 파드는 완료된 것으로 간주된다.
Job이 실행되고 있던 노드에 장애가 발생한 경우, 잡이 관리하는 파드는 다른 노드로 다시 스케줄링된다. 실행이 완료될 때 까지는 스케줄링 일어남.
프로세스 자체에 장애가 발생한 경우에는 Job 설정에서 컨테이너를 다시 시작할지 여부를 설정할 수 있다.
Job은 작업이 제대로 완료되는 것이 중요한 임시 작업에 유용하다.
예를 들어 ETL 작업같은 배치성 작업에 유용하다.
배치 프로세스를 실행시키는데, 노드에 문제발생 or 노드에서 해당 파드 제거됨 or 프로세스에서 장애발생 등의 상황에 자동으로 대처해준다.
잡 리소스 정의
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
metadata:
labels:
app: batch-job # 파드셀렉터 지정안하고 템플릿에 있는 label을 쓴다
spec:
restartPolicy: OnFailure # Job의 템플릿으로 사용되는 파드의 restartPolicy 는 기본 값(Always)을 사용할 수 없다
containers:
- image: luksa/batch-job
name: mainJob으로 관리되는 pod는 실행이 완료되어도 삭제되지 않는다.
kubectl logs 로 로그를 확인할 수 있다.
삭제하는 방법
- 파드 직접 삭제
- 파드를 생성한 잡을 삭제
Job에서 여러 파드 인스턴스 실행하기
Job은 2개 이상의 파드 인스턴스를 생성해 병렬 또는 순차적으로 실행하도록 구성할 수 있다.
정의 파일의 spec 하위에 지정할 수 있는 속성을 가진다.
- completions 속성 : 잡을 두 번 이상 실행해야하는 경우, 잡의 파드를 몇 번 실행할지 지정.
- parallelism 속성 : Job이 여러 파드를 병렬로 실행할 수 있게 함. 몇개 까지 병렬로 실행할지 지정.
kind: Job
..
spec:
completions: 5
parallelism: 2
template:
..이 Job은 5개 파드를 성공적으로 완료해야 하며, 2개 까지 병렬로 실행할 수 있다.
Job 파드가 완료되는데 까지 걸리는 시간 제한하기
잡은 파드가 완료될 때 까지 얼마나 기다려야 하나?
파드 스펙에 activeDeadlineSeconds 속성 설정.
- 파드가 이보다 오래 실행되면 시스템이 종료를 시도하고 잡은 실패한 것으로 표시됨.
Job을 주기적으로 또는 한 번 실행되도록 스케줄링하기
Job이 미래 특정시간 또는 지정된 간격으로 반복 실행하고 싶을 때 'CronJob' 리소스 사용.
잡 리소스는 예정된 시간에 크론잡 리소스에서 생성된다. 그러면 잡은 파드를 생성한다.
잡이나 파드가 상대적으로 늦게 생성되고 실행될 수 있다. 예정된 시간을 너무 초과해 시작되면 안되는 경우도 있다. 이런 경우에는 크론잡 스펙의 startingDeadlineSeconds 필드를 지정해 데드라인을 실행할 수 있다.
ex) startingDeadlineSeconds: 15 -> 파드는 예정된 시간에서 늦어도 15초내에 시작해야함.
일반적인 상황에서 크론잡은 각 실행에 항상 하나의 잡만 생성하지만, 2개 이상의 잡이 동시 생성되거나 전혀 생성되지 않을 수 있다.
그렇기 때문에 잡은 멱등성을 가져야하며 다음 번 잡 실행이 이전의 누락된 실행에서 완료했어야 하는 작업을 수행하는지 확인해야 한다.
