들어가며
전통적인 비잔틴 장애 허용 메커니즘을 실용적으로 사용되도록 만든 것을 Practical BFT라고 한다.
오늘은 분산형 네트워크의 핵심인 합의 알고리즘 중에서 PBFT에 대해 알아보도록 할 것이다.
이러한 pBFT는 비동기적 시스템(요청에 대한 응답을 언제 받을지에 대한 상한없음)에서 효과적으로 작동한다.
what is BFT?
Byzantine Fault Tolerance는 분산 네트워크의 어떤 노드들이 응답에 실패하거나 올바르지 못한 정보를 응답할 때조차도, 합의에 이르게 해주는 분산 네트워크의 특징이다.
BFT 메커니즘의 목표는 결함이 있는 노드의 영향을 줄이는 것을 목표로 하는 집단 의사 결정을 채택하여 시스템 장애로부터 보호하는 것이다.
이 BFT는 Byzantine General’s Problem으로부터 나왔다.
Byzantine General’s Problem
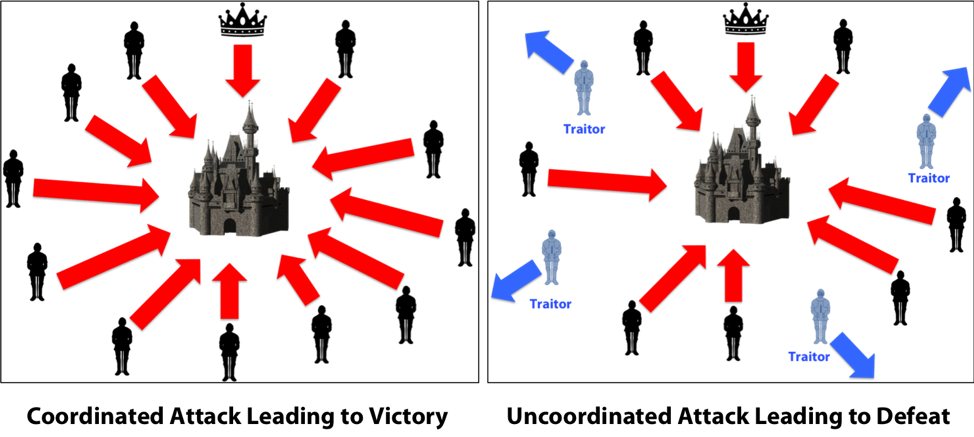
비잔틴 제국의 장군들은 서로 흩어져 있다. 이때, 다른 제국을 정복하려고 하는데 배신자들이 제국에 대한 공격 정보를 조작하여서 성공적인 공격이 되지 못하게 하려고 한다. 이러한 상황 속에서 공격을 어떻게 성공적으로 합의하여 실행할 수 있을지에 대한 문제가 비잔틴 장군 문제이다.
가정) 모든 메세지가 올바르게 전달되고, 믿을만한 채널을 사용하며, 모든 메세지가 동기적으로 전달.
레슬리 램포트는 이 문제에 대한 해답으로, m명의 배신자가 존재한다고 할때 총 노드의 수는 3m+1이 되어야 한다는 것을 이끌어 냈다.
즉, 결함이 있는 노드가 전체 노드의 1/3 미만이어야 한다는 것이다.
How PBFT works?
PBFT의 노드들은 연속적으로 나열되어 있으며, 이러한 노드들의 기능은 모두 동일한 replicas이다. 가장 첫번째 노드를 primary node(or leader node)라고 부르며, 나머지 뒤에 따라오는 노드들을 secondary nodes(or backup nodes)라고 부른다. primary node가 fail일 경우, 그 다음 노드가 primary node가 된다.
악의적인 노드가 최대일 경우, 즉 악의적인 노드가 전체 노드의 1/3 미만일때에도 작동한다. 일반적으로 노드의 수가 많아질수록, 시스템의 보안은 더 좋아진다고 볼 수 있다.(그러나 이것엔 치명적인 결함이 있다. 뒤에서 더 다루겠다.)
PBFT 합의 라운드는 크게 네 개의 페이즈로 구성된다.
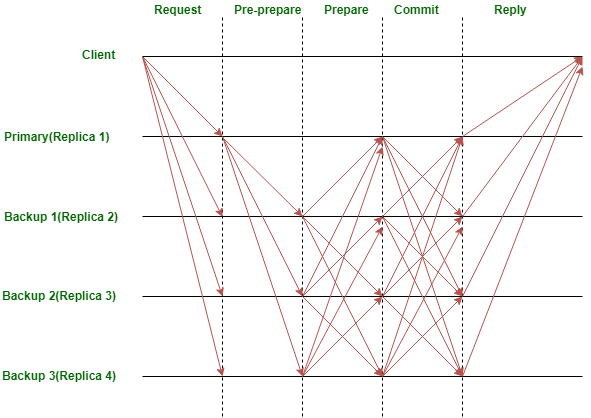
- client가 primary node에게 request를 보내는 페이즈(Request phase)
- primary node가 request를 모든 secondary nodes에게 보내는 페이즈(pre-prepare,prepare, commit phase)
- 노드들이 요청된 서비스를 시행하고, client에게 응답을 보내는 페이즈(Reply phase)
- client가 서로 다른 노드로부터 m+1개의 같은 응답을 받으면 요청에 대한 성공적인 응답이라고 판단하는 페이즈(이때, 최대 m개의 결함있는 노드가 존재한다.)
Types of Byzantine Failures
비잔틴 장애로 인해 합의에 방해를 하는 노드들이 존재할 수 있는데, 이러한 비잔틴 장애의 종류는 크게 두가지로 볼 수 있다. 하나는 fali-stop이고, 다른 하나는 arbitrary-node failure이다.
fail-stop은 말 그대로 노드가 검증에 실패해서 작업을 중단하는 비잔틴 장애이고, arbitrary-node failure의 종류는 다음과 같다.
- 요청에 대한 결과 반환에 실패
- 부정확한 결과를 응답
- 의도적으로 잘못된 정보를 응답
- 시스템의 다른 부분에 대한 다른 응답 제출(이게 뭘 의미하는진 잘 모르겠다.)
이러한 byzantine failure는 전체 노드의 1/3미만으로 허용된다.
다음으로 일반적인 케이스의 practical 비잔틴 장애 허용 알고리즘을 살펴보겠다.
Normal-case operation
client가 primary에게 트랜잭션 처리를 요청하면(Request), primary는 proposal을 만들어서 backup들에게 전달한다(Pre-prepare). backup들은 이렇게 받은 프로포절을 검증하고, 검증에 성공했다면 다른 replicas들에게 prepare 메세지를 전달하고, 실패했다면, 아무것도 하지 않는다(Prepare). 이것이 바로 첫번째 voting 라운드이다. 2/3를 초과한 backup들로부터 prepare 메세지를 수신하면, replicas들은 commit 메세지를 다음 라운드로 보낸다(Commit). 이것은 두번째 voting 라운드이다. 마지막으로 client는 합의의 결과를 reply하여 확인할 수 있다(Reply).
이러한 pbft 알고리즘에서 요구되는 것은 primary가 특정 시간 내에 새로운 트랜잭션을 생성하는 것이다. 만약, 이러한 primary가 fail이라면 어떻게 될 것인가?
View change protocol
primary가 악의적으로 트랜잭션을 조작하거나, 네트워크 연결이 해제되는 등의 failure가 발생한다면, client는 누구에게 request를 해야 하는 것인가?
이 해답은 view change protocol로 해결된다.
replicas들은 타이머가 만료된 후에도 아무런 작업이 진행되지 않는다면, view change vote를 실시한다. 2m개의 메세지를 받은 후에, replica는 다음 primary가 되고, new-view 메세지를 노드들에게 전파한 후에 pre-prepare단계를 실시한다.(좀 더 자세하게..비둘기의집 원리?)
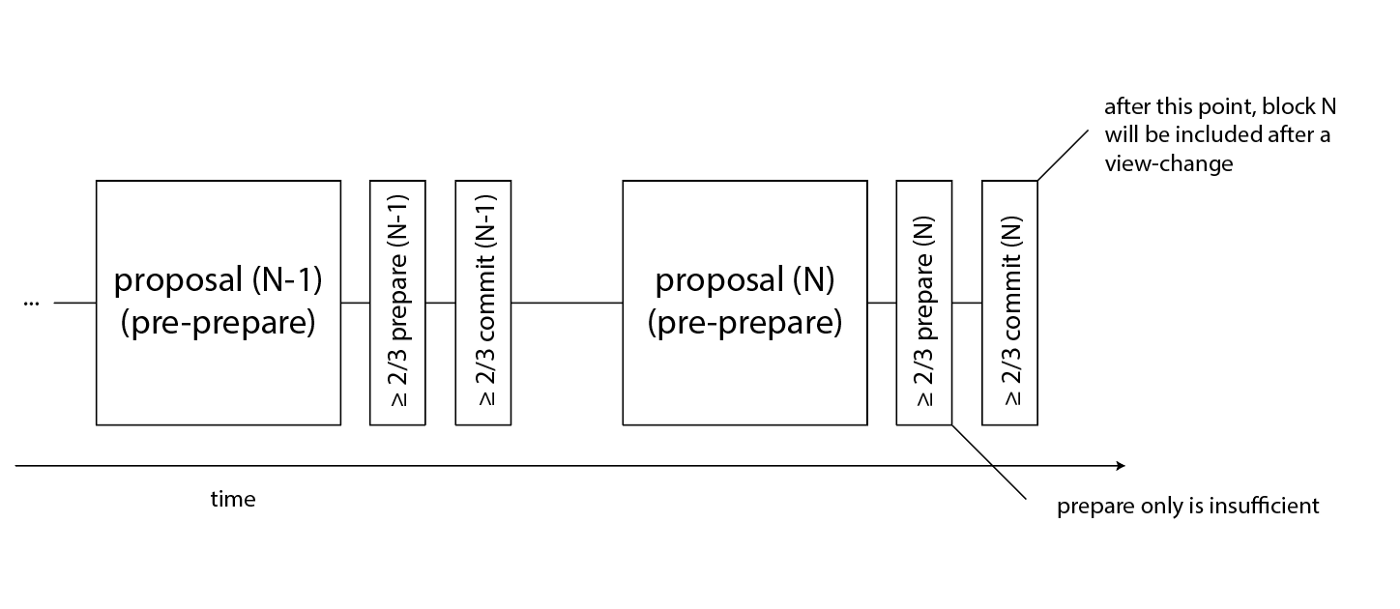
2개의 voting round가 view-chage에 대한 안정성을 제공해주고, 이러한 view-chage는 모든 정통적인 합의 알고리즘의 기반이 된다.
Advantages of PBFT
PBFT 알고리즘은 다음과 같은 장점들을 가진다.
- Energy Efficiency
합의 과정에서 복잡한 수학 계산과 같은 연산이 필요없기 때문에, 에너지 측면에서 효율적이다. 질리카는 PBFT 방식과 PoW 방식을 같이 사용하는데, 100개의 블록마다 PoW를 이용해서 합의를 시도하기 때문에, 비트코인이나 이더리움보다 에너지 측면에서 효율적이다고 볼 수 있다.
그러나, 이러한 측면은 보안면에서 단점이 되기도 한다. - Transaction Finality
트랜잭션이 확정되고 합의된 후에는 다중으로 확인할 필요가 없다. 그에 반해, 비트코인의 PoW같은 경우에는 새로운 블록에 트랜잭션을 추가하기 위해선 모든 노드들이 모든 트랜잭션을 검증한 후에 새로운 블록 생성이 가능하다. 따라서, 검증하는 노드의 수에 따라 검증에 많은 시간이 걸릴 수도 있다. - Low reward variance
네트워크의 모든 노드는 client의 요청에 응답을 해주기 때문에, 의사결정에 도움을 준 모든 노드에게 보상이 돌아간다. 이러한 보상 시스템 덕분에 보상의 변동량이 낮아지게(분산이 작다) 된다.
Limitations of PBFT
PBFT의 특성으로 인한 한계점도 존재한다.
우선, PBFT는 높은 communication을 요구하므로 노드가 많아지면 네트워크가 정상적으로 작동하기 힘들다. 시간 복잡도가 노드의 수에 따라서 기하급수적으로 증가하기 때문이다.
- Sybil attacks
한 사람이 수많은 노드로 합의 알고리즘에 참여할 수도 있기 때문에, sybil attacks에 취약한 편이다. 노드가 많아질수록 보안이 강화되지만, 확장성 문제 때문에 이는 실질적으로 쉽지 않다. 따라서 다른 메커니즘과 PBFT가 함께 쓰이기도 한다.(ex.질리카) - Scaling
노드들이 라운드마다 메세지로 통신을 하기 때문에, 합의에 필요한 메세지의 수는 O(n^k)(n은 노드 수, k는 배신자 수)에 비례해서 증가한다.
따라서 다음과 같은 블록체인 네트워크들은 PBFT와 다른 알고리즘을 섞어서 사용한다.
Platform using pBFT variants
- Zilliqa – pBFT in combination with PoW consensus
- Hyperledger Fabric – permissioned version of pBFT
- Tendermint – pBFT + DPoS(Delegated Proof-of-Stake)
마치며
전통적인 합의 알고리즘 중 하나인 PBFT에 대해 알아보았다.
분산형 네트워크의 핵심이 분산된 노드 간의 합의 알고리즘이기 때문에, 정말 기본적이지만 그만큼 중요한 분야라고 생각한다. PBFT보다 성능이 좋은 합의 알고리즘도 많이 개발되었지만, 우선 이것부터 공부해보았다. 다음으로는 비트코인의 합의 알고리즘으로 유명한 PoW, 이더리움의 2.0 알고리즘인 PoS를 더 알아보도록 하겠다.
참고
Your Journey To Consensus (Part 3) - Byzantine Fault Tolerance and PBFT
Practical Byzantine Fault Tolerance
Consensus Series: PBFT
