
4부. 엔터티, 인코딩, 국제화
14장. 보안 HTTP 환일님 블로그
15장. 엔터티와 인코딩 준수님 노션
16장. 국제화
인터넷 상의 다양한 언어와 문자로 된 국제 문서들의 처리 및 지원과 관련하여, 국제화 주요 이슈인 문자집합 인코딩과 언어 태그에 대해 알아본다. HTTP 애플리케이션은 여러 언어의 문자로 텍스트를 보여주고 요청하기 위해 문자집합 인코딩을 사용한다. 그리고 사용자가 이해할 수 있는 언어로 콘텐츠를 서술하기 위해 언어 태그를 사용한다.
이 장의 전체 내용은 아래와 같다.
- HTTP가 어떻게 여러 언어 문자들의 체계 및 표준과 상호작용하는지 설명한다.
- HTTP 프로그래머의 업무 수행에 도움이 될 수 있는 전문용어, 기술, 표준의 개요에 대해 알아본다.
- 언어를 위한 표준 명명 체계와, 어떻게 표준화된 언어 태그가 콘텐츠를 서술하는지에 대해 설명한다.
- 국제화된 URI 규칙과 주의사항에 대해 알아본다.
- 날짜와 그 외 다른 국제화 이슈에 대해 논의한다.
16.1 국제적인 콘텐츠를 다루기 위해 필요한 HTTP 지원
HTTP 엔터티 본문은 비트로 가득 찬 상자에 불과하며, 어떠한 언어도 전송할 수 있다. 다만, 서버가 클라이언트에게 각 문서의 문자와 언어를 알려주어야 한다. 클라이언트가 올바르게 비트들을 문자로 풀어내고, 처리하여 콘텐츠를 제공받아야 하기 때문이다. 서버는 HTTP Content-Type charset 매개 변수와 Content-Language 헤더를 통해 문서의 문자와 언어를 알려준다.
동시에 클라이언트는 서버에게 어떤 언어를 이해할 수 있고, 어떤 알파벳의 코딩 알고리즘이 브라우저에 설치되어 있는지 말해줄 필요가 있다. 이를 위해 Accept-Charset 과 Accept-Language 헤더를 보낸다.
Accept-Language: fr, en;q=0.8
Accept-Charset: iso-8859-1, utf-8위의 예시를 보면 모국어가 프랑스어이면서, 부득이한 경우에는 영어를 사용하는 것을 알 수 있다. 브라우저는 iso-8859 서유럽어 차셋 인코딩과 UTF-8 유니코드 차셋 인코딩을 지원한다.
매개변수 q=0.8 의 q는 품질 인자(quality factor)라고 하며, 0~1 사이의 값을 갖는다. 사용자의 선호도라고 볼 수 있다. 위에서는 프랑스어를 1이라고 했을 때, 영어가 0.8의 선호도를 갖는 것을 뜻한다.
16.2 문자집합과 HTTP
국제 알파벳 스크립트와 문자집합 인코딩에 대해 알아본다.
16.2.1 차셋(Charset)은 글자를 비트로 변환하는 인코딩이다
HTTP 차셋 값은 어떻게 엔터티 콘텐츠 비트들을 특정 문자 체계의 글자들로 바꾸는지를 말해준다. 각 차셋 태그는 비트와 문자사이의 변환 알고리즘을 지칭한다.
Content-Type: text/html; charset=iso-8859-6위의 헤더는 콘텐츠가 html 파일이면서, 비트를 글자로 디코딩하기 위해 아랍 문자집합(iso-8859-6) 디코딩 기법을 사용하라고 말해준다.
UTF-8과 iso-2022-jp 같은 몇몇 문자 인코딩은 글자 당 비트 수가 일정하지 않아 복잡한 가변길이 코드다. 이러한 코딩은 중국어와 같이 글자 수가 많은 문자체계를 지원하기 위해 추가적인 비트를 사용할 수 있게 해준다.
16.2.2 문자집합과 인코딩은 어떻게 동작하는가
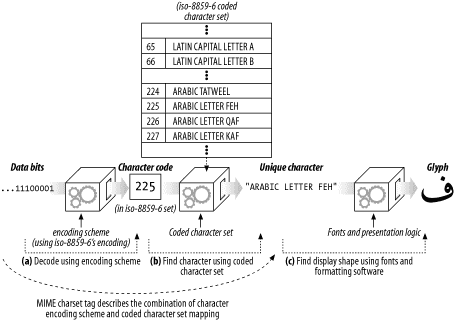
- iso-8859 코딩을 사용할 때, 최초 데이터 비트들은 코딩된 문자집합에서 매칭되는 문자 코드로 변환된다. 문자 코드를 통해 문자집합 내의 글자를 찾고, 사용자의 그래픽 디스플레이 소프트웨어(브라우저, 운영체제, 글꼴)가 최종 모양을 결정한다.
16.2.3 잘못된 차셋은 잘못된 글자를 낳는다.
인코딩 알고리즘에 따라서 서로 다른 문자집합을 가지므로, 잘못된 차셋 매개 변수를 사용할 경우에 다른 글자가 출력될 수 있다.
16.2.4 표준화된 MIME 차셋 값
특정 문자 인코딩과 특정 코딩된 문자집합의 결합을 MIME 차셋이라고 한다. HTTP 는 표준화된 MIME 차셋 태그를 Content-Type 과 Accept-Charset 헤더에 사용한다. (432p 표 16-1 참조)
예시)
- iso-8859-1 : 서유럽 언어 지원
- iso-8859-2 : 체코어, 폴란드어 등 중부 유럽 혹은 동유럽 언어 지원
- iso-8859-7 : 현대 그리스어
16.2.5 Content-Type charset 헤더와 META 태그
웹 서버가 클라이언트에게 Content-type 헤더를 통해서 charset 매개 변수를 받지 못하는 경우에는 html 문서 안의 META 태그를 통해서 알 수 있다. 이 마저도 없는 경우에는 소프트웨어가 텍스트를 스캐닝하여 문자 인코딩을 추측한다.
<head>
<meta HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=iso-2022-jp">
<meta LANG="jp">
</head>16.2.6 Accept-Charset 헤더
앞서 설명한 바와 같이 클라이언트가 서버에게 어떤 문자 체계를 지원하는 지를 Accept-Charset 헤더를 통해 알려준다.
16.3 다중언어 문자 인코딩에 대한 지침
코딩된 문자집합(Coded Character Set)
- US-ASCII : 아스키는 '정보교환을 위한 미국 표준 코드'이다. 표준화된 가장 유명한 코딩된 문자집합이다.
- iso-8859 : ASCII 확장으로 지역에 따라 커스터마이징된 문자집합을 제공한다.
- UCS : 국제 문자 세트(Universal Character Set)는 전 세계 모든 글자를 하나의 코딩된 문자집합으로 통합하려는 세계적인 표준이다. 유니코드는 UCS 를 따르는 상업적 컨소시엄이다.
문자 인코딩 구조
문자 인코딩 구조들은 숫자로 된 문자 코드를 콘텐츠 비트로 변환하고 다른 쪽에서는 다시 문자 코드로 환원한다.
- UTF-8 : UCS를 위해 설계된 문자 인코딩 구조이다.
- euc-kr : 한글 인터넷 문서를 위해 널리 사용되는 인코딩이다.
16.4 언어 태그와 HTTP
언어 태그는 언어에 이름을 붙이기 위한 짧고 표준화된 문자열이다. 예를 들어 프랑스어를 표현할 때, 사람들마다 표현 방식이 모두 다를 수 있다. French, Francais, France, Fra, F 등 각자의 방식으로 다양하게 표현하려하기 때문에 이를 표준화할 필요가 있다.
16.4.1 Content-Language 헤더
Content-Language 헤더 필드는 엔터티가 어떤 언어 사용자를 대상으로 하는지 서술한다.
Content-Language: fr, en16.4.2 Accept-Language 헤더
클라이언트는 자신이 이해할 수 있는 콘텐츠를 요청하기 위해 Accept-Language 헤더를 사용한다.
16.4.3 언어 태그의 종류
언어 태그가 표현하는 언어의 종류는 다양하다.
- 일반적인 언어의 종류(스페인어, 프랑스어 등)
- 특정 국가의 언어(영국식 영어)
- 방언
- 지방어
- 다른 언어의 변형이 아닌 표준 언어(i-navajo: 아메리카 원주민 나바호족 언어)
- 비표준 언어(x-snowboarder-slang)
16.4.4 서브태그
언어 태그는 하이픈(-) 으로 분리된 하나 이상의 서브태그로 이루어져 있다.
- 첫 번째 서브태그 : 주 서브태그이며 표준화되어 있음
- 두 번째 서브태그 : 선택적이고 자신만의 이름 태그를 따름
- 세 번째부터의 서브태그는 등록되어 있지 않다.
예시) 마서스 비니어드 섬의 수화 : sgn-US-MA
- sgn : 수화를 뜻함
- US : 미국
- MA : 메사추세츠 지역 변종
16.4.5 대소문자의 구분 및 표현
모든 태그는 대소문자 구분이 없다. 그러나 관용적으로 소문자를 사용한다. 국가는 대문자로 표현한다.
16.4.6 IANA 언어 태그 등록
IANA 라는 단체에서 첫 번째와 두 번째 서브태그 값에 대한 여러 표준 문서를 관리한다. 언어 태그가 오직 국가와 해당 국가의 언어 조합이라면 굳이 관리할 필요가 없다. 그렇지 않은 언어 태그들이 관리 대상이다.
16.4.7 첫 번째 서브태그: 이름공간
첫 번째 서브태그는 ISO 639 표준 언어 집합에서 선택된 표준화된 언어 토큰이다. ISO 639는 각 언어별 언어코드이며, 앞서 얘기한 프랑스어(fr), 터키어(tr), 한국어(ko) 등이다. 여기에 속하지 않는 언어 태그들이 IANA 에 등록되어 관리되고 있는 태그들이다. 위의 수화(sgn)가 그 예로 볼 수 있다.
16.4.8 두 번째 서브태그: 이름공간
두 번째 서브태그는 ISO 3166 국가 코드와 지역 표준 집합에서 선택된 표준화된 국가 토큰이다. 반드시 두 글자이상이며, 3~8 글자라면 IANA에 등록된 것이다. 독일(DE), 미국(US) 등이 있다.
16.4.9 나머지 서브태그 : 이름공간
세 번째와 그 이후의 서브태그는 8자 이하의 알파벳과 숫자로 이루어져야 한다는 것을 제외한 다른 규칙은 없다.
16.4.10 선호 언어 설정하기
웹 브라우저 프로필에서 선호 언어를 설정할 수 있다.
예로 크롬은 설정 > 고급 설정 표시 > 언어 및 입력 설정 에서 가능하다.
16.5 국제화된 URI
오늘날의 URI 는 국제화를 그다지 지원하지 않는다.
16.5.1 국제적 가독성 vs 의미 있는 문자들
전 세계 모두가 URI 를 공유할 수 있게 되는 것과 사용하고 기억하기 쉬운 URI 를 만드는 것은 서로 충돌하는 목표이다. URI 는 조작 및 공유가 쉽게끔 아주 제한된 문자집합(알파벳, 숫자, 일부 특수문자)으로 구성됐다. URI를 만든 사람들은 리소스 식별자의 가독성과 공유 가능성의 보장이 더 중요하다고 여겼다.
16.5.2 URI에서 사용될 수 있는 문자들
URI 에서 사용할 수 있는 문자들은 US-ASCII 문자들은 예약된 문자들, 예약되지 않은 문자들, 이스케이프 문자들로 나뉜다.
- 예약되지 않음 :
A-Za-z0-9"-""_"".""!""~""*""'""("")" - 예약됨 :
";""/""?"":""@""&""=""+""$""," - 이스케이프 :
"%"
16.5.3 이스케이핑과 역이스케이핑(unescaping)
URI 이스케이프는 예약된 문자나 다른 지원하지 않는 글자들을 안전하게 URI에 삽입할 수 있도록 한다. 이스케이프는 퍼센트 글자(%) 하나와 뒤이은 16진수 글자 둘로 이루어진 세 글자 문자열이다.
예를 들어, URI 에 스페이스(아스키 32)를 삽입하고 싶다면, %20 을 사용할 수 있다. 32의 16진수 표현이 20이기 때문이다.
내부적으로 HTTP 애플리케이션은 데이터가 필요할 때만 URI 를 unescaping 해야 한다. 또한 절대로 두 번 unescaping 해서는 안된다. URI를 잘못 해석하여 데이터 손실을 유발할 수도 있기 때문이다.
16.6 기타 고려사항
- HTTP 헤더는 반드시 US-ASCII 문자집합의 글자들로만 이루어져야 한다.
- 오늘날 대부분의 브라우저는 퓨니코드(유니코드 문자열을 호스트 이름에서 허용된 문자만으로 인코딩하는 방법)를 이용해 국제화 도메인 이름을 지원한다. 예를 들어
한글.com은 퓨니코드를 통해xn--bj0bj06e.com으로 변환한다.
