
동시성 이슈란?
스레드는 cpu 작업의 한단위이다.
여기서 멀티스레드 방식은 멀티태스킹을 하는 방식 중, 한 코어에서 여러 스레드를 이용해서 번갈아 작업을 처리하는 방식이다.
멀티 스레드를 이용하면 공유하는 영역이 많아 프로세스방식보다 context switcing(작업전환) 오버헤드가 작아, 메모리 리소스가 상대적으로 적다는 장점이 있다.
하지만 자원을 공유해서 단점도 존재한다.
그게 바로, 동시성(concurrency) 이슈이다.
여러 스레드가 동시에 하나의 자원을 공유하고 있기 때문에 같은 자원을 두고 경쟁상태(raceCondition) 같은 문제가 발생하는 것이다.
❗ 여기서 동시성 과 병렬성도 비교해보면 좋을 것이다.
동시성 vs 병렬성
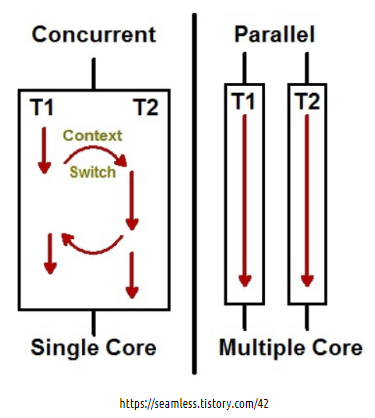
동시성
-
동시에 실행되는 것처럼 보이는 것 -
싱글 코어에서 멀티 스레드를 동작시키기 위한 방식으로, 멀티 태스킹을 위해
여러 개의 스레드가 번갈아가면서 실행되는 성질을 말한다. -
멀티 스레드로 동시성을 만족시킬 수 있는 것이지 동시성과 멀티 스레드는 연관이 없다. 반례로 코틀린은 싱글스레드에서
코루틴을 이용하여 동시성을 만족할 수 있다. -
코루틴(Coroutine):싱글 스레드에서도 루틴(routine) 이라는 단위(맥락상 함수와 동일)로루틴간 협력이 가능하며, 동시성 프로그래밍을 지원하고 비동기 처리를 쉽게 도와주는 개념을 말한다. -
싱글 코어에서 멀티 스레드를 이용해 동시성을 구현하는 일부 케이스에 대한 내용이다. 멀티 코어에서 멀티 스레드를 이용하여 동시성을 만족할 경우에는 실제 물리적 시간으로 동시에 실행된다.
병렬성
-
실제로 동시에 실행되는 것 -
멀티 코어에서 멀티 스레드를 동작시키는 방식으로, 한 개 이상의 스레드를 포함하는 각 코어들이 동시에 실행되는 성질을 말한다.
-
부분적으로만 맞는 내용이다. 병렬성의 핵심은 물리적인 시간에 동시에 수행되는 것이지 멀티 코어에 포커스가 맞춰져서는 안된다. 그 예로 네트워크 상의 여러 컴퓨터에게 분산작업을 요청하는 분산 컴퓨팅이 있다.
출처 : https://vagabond95.me/posts/concurrency_vs_parallelism/
스레드 안전성(Thread safe) 이란?
여러 스레드가 작동하는 환경에서도 문제 없이 동작하는 것을 스레드 안전하다고 말한다.
즉, 동시성 이슈를 해결하고 일어나지 않는다면 Thread safe하다고 하는 것이다.
동시성을 제어하는 방법
1) 암시적 Lock (synchronized)
동시성을 해결하는 데 가장 간단하면서 쉬운 방법은 Lock을 걸어 버리는 것이다.
즉, 문제가 된 메서드, 변수에 각각 synchronized라는 키워드를 넣는 것이다.
class Count {
private int count;
public synchronized int view() {return count++;}
}
class Count {
private Integer count = 0;
public int view() {
synchronized (this.count) {
return count++;
}
}
}2) 명시적 Lock
synchronized 키워드 없이 명시적으로 ReentrantLock을 사용하는 방법이다.
해당 Lock의 범위를 메서드 내부에서 한정하기 어렵거나, 동시에 여러 Lock을 사용하고 싶을 때 사용한다. 직접적으로 Lock 객체를 생성하여 사용한다.
public class CountingTest {
public static void main(String[] args) {
Count count = new Count();
for (int i = 0; i < 100; i++) {
new Thread(){
public void run(){
for (int j = 0; j < 1000; j++) {
count.getLock().lock();
System.out.println(count.view());
count.getLock().unlock();
}
}
}.start();
}
}
}
class Count {
private int count = 0;
private Lock lock = new ReentrantLock();
public int view() {
return count++;
}
public Lock getLock(){
return lock;
};
}3) 스레드 안전한 객체 사용
이외에도 concurrent 패키지는 각종 스레드 안전한 컬랙션을 제공한다. ConcurrentHashMap과 같은 컬랙션은 스레드 안전하게 사용할 수 있다.
- Concurrent 패키지
concurrent패키지에 존재하는 컬랙션들은 락을 사용할 때 발생하는 성능 저하를 최소한으로 만든다. 락을 여러 개로 분할하여 사용하는 Lock Striping 기법을 사용하여 동시에 여러 스레드가 하나의 자원에 접근하더라도 동시성 이슈가 발생하지 않도록 도와주는 것이다.
class Count {
private AtomicInteger count = new AtomicInteger(0);
public int view() {
return count.getAndIncrement();
}
}- ConcurrentHashMap
ConcurrentHashMap은 내부적으로 여러개의 락을 가지고 해시값을 이용해 이러한 락을 분할하여 사용한다. 분할 락을 사용하여 병렬성과 성능이라는 두 마리의 토끼를 모두 잡은 컬랙션인 것이다. 내부적으로 여러 락을 사용, 일반적인 map을 사용할 때처럼 구현하면 내부적으로 알아서 락을 자동으로 사용해 줄 테니 편리하게 사용할 수 있다.
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {3) 불변 객체 (Immutable Instance)
스레드 안전한 프로그래밍을 하는 방법중 효과적인 방법은 불변 객체를 만드는 것이다. 불변객체의 대표적인 예가 String이다. 불변 객체는 락을 걸 필요가 없다. 내부적인 상태가 변하지 않으니 여러 스레드에서 동시에 참조해도 동시성 이슈가 발생하지 않는 것아다. 즉, 불변 객체는 언제나 스레드 안전(Thread-safe)하다.
불변 객체는 생성자로 모든 상태 값을 생성할 때 세팅하고, 객체의 상태를 변화시킬 수 있는 부분을 모두 제거해야 한다.
가장 간단한 방법은 세터(setter)를 만들지 않는 것이다.
그래서 내부 상태가 변하지 않도록 모든 변수를 final로 선언하는 것도 있다.
final 키워드를 쓰면 무조건 초기화를 해야 한다.
또 데이터 자체를 Stream()안에서 캡슐화해서 결과를 도출하는 것도 불변화 시키는 방법이다. 함수형 프로그래밍을 사용하는 이유이기도 하다.
관련 블로그: https://velog.io/@mooh2jj/왜-함수형-프로그래밍인가
참고
- <자바 병렬 프로그래밍>, 브라이언 게츠 등 저
- https://beststar-1.tistory.com/24
