
Spring Batch ItemReader 정하기
spring batch에는 여러가지 Reader 구현 방식들이 있습니다.
이 중에 저는 프로젝트에 적용할 방식으로 JpaRepositoy 방식으로 채택했습니다. 이 방식을 선택한 이유들은 spring batch의 ItemReader의 구현체들이 어떻게 되어있는지와 함께 설명해 보겠습니다.
spring batch에서 쓰이는 itemReader로서 가장 대표적인 구현체인 JdbcPagingItemReader가 있습니다.
해당 클래스의 계층 구조를 살펴보면 아래와 같습니다.
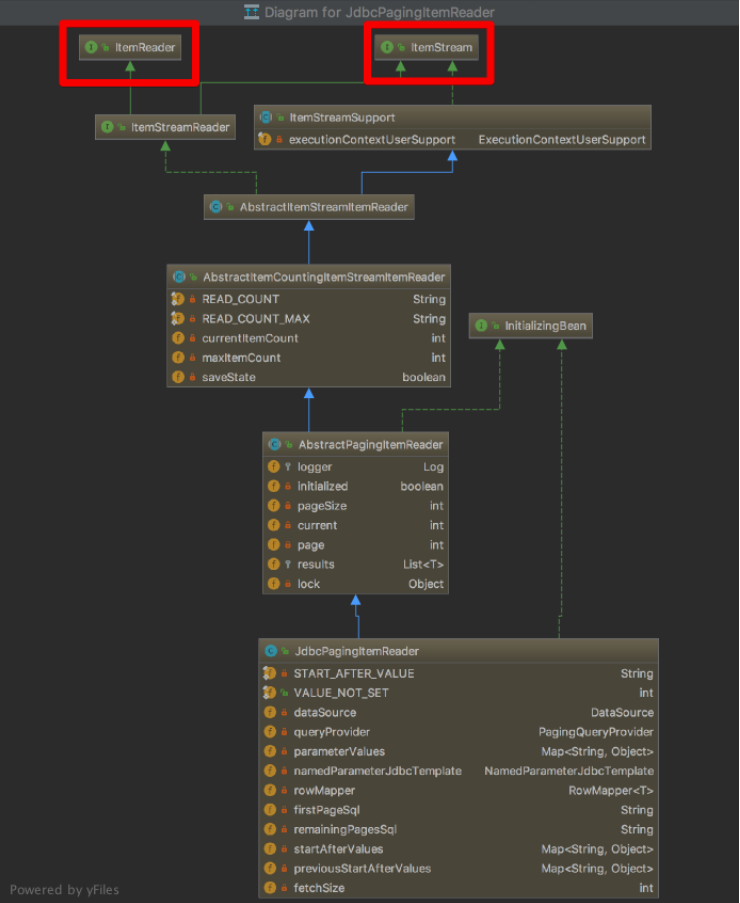
출처 : https://jojoldu.tistory.com/336
보통 개발자가 ItemReader와 ItemStream 인터페이스를 직접 구현해서 원하는 형태의 ItemReader를 만드는 일은 거의 없습니다. 대부분의 데이터 형태는 ItemReader로 이미 제공하고 있기 때문입니다.
단, 조회 프레임워크가 Querydsl, Jooq라면 직접 구현해야할 수도 있습니다.
웬만하면 JdbcItemReader로 해결되지만, JPA의 영속성 컨텍스트가 지원이 안되서 HibernateItemReader를 이용하여 Reader 구현체를 직접 구현해야 합니다.
JPA의 영속성 컨텍스트가 지원이 안되서 HibernateItemReader를 이용하여 Reader 구현체를 직접 구현해야 하는 것이죠.
저는 개인적으로 프로젝트에서 JPA를 쓰기 때문에 JPA 관련 itemReader를 쓰게 되었습니다.
Spring Batch의 대표적 Reader들
Spring Batch는 대표적으로 2개의 Reader 타입을 지원합니다.
Cursor와 Paging인데요.

이 2개의 Reader 타입을 알아보고 결론적으로 제가 Paging을 사용한 이유를 설명드리겠습니다.
Cursor는 실제로 JDBC ResultSet의 기본 기능입니다.
ResultSet이 open 될 때마다 Database의 데이터가 return 됩니다.
Database와 커넥션을 맺은 후 데이터를 Streaming해서 보냅니다. 그리고 Cursor를 한칸씩 옮기면서 데이터를 가져옵니다.
반면 Paging은 좀 더 많은 작업을 필요로 합니다.
Paging 개념은 페이지라는 Chunk로 Database에서 데이터를 검색한다는 것입니다.
Chunk라는 개념이 중요한데요. 즉, 페이지 단위(pageSize=chunkSize)로 한번에 데이터를 조회해오는 방식입니다.
2개 방식의 구현체는 다음과 같습니다.
1) Cursor 기반 ItemReader 구현체
JdbcCursorItemReaderHibernateCursorItemReaderStoredProcedureItemReader
2) Paging 기반 ItemReader 구현체
JdbcPagingItemReaderHibernatePagingItemReaderJpaPagingItemReader
다시 정리하면, Paging방식은 Database Cursor와 달리
여러 쿼리를 실행하여 각 쿼리가 지정한 한번에 pageSize만큼 가져 오는 방법입니다.
게시판의 페이징을 구현해보면 알겠지만 페이징을 한다는 것은 각 쿼리에 시작 행 번호 (offset) 와 페이지에서 반환 할 행 수 (limit)를 지정해야한다는 것을 의미합니다.
spring Batch에서는 offset과 limit을 PageSize에 맞게 자동으로 생성해 줍니다.
다만 각 쿼리는 개별적으로 실행한다는 점을 유의해야합니다.
각 페이지마다 새로운 쿼리를 실행하므로 페이징시 결과를 정렬하는 것이 중요합니다.
데이터 결과의 순서가 보장될 수 있도록 order by가 권장됩니다.
그리고 스프링 배치는 Chunk 지향 처리입니다. Chunk 단위로 트랜잭션을 다룹니다. 트랜잭션처럼 롤백도 됩니다.
읽어야 할 또는, 처리할 아이템이 굉장히 많을때 트랜잭션을 한번에
이어가는 것 보다 일정 주기로 여러번 실행하는 것이 안정적이기 때문입니다.
반면, Cursor는 하나의 Connection으로 Batch가 끝날때까지 사용되기 때문에 Batch가 끝나기전에 Database와 어플리케이션의 Connection이 먼저 끊어질수 있어서 위험합니다.
✨ 안정적인 면에서도 Cursor보단 Paging방식이 더 나은 선택인 것입니다.
JdbcPagingItemRedaer
JdbcPagingItemRedaer는 JdbcCursorItemReader와 같은 JdbcTemplate 인터페이스를 이용한 PagingItemReader입니다.
기본적인 코드는 아래와 같습니다.
// Cursor 기반 ItemReader 구현체
@Bean
public JdbcCursorItemReader<Schedule> allReadReader() {
return new JdbcCursorItemReaderBuilder<Schedule>()
.verifyCursorPosition(false)
.fetchSize(FETCH_SIZE)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Schedule.class))
.sql("select * from schedules order by id")
.name("jdbcCursorItemReader")
.build();
}
// Paging 기반 ItemReader 구현체
@Bean
public JdbcPagingItemReader<Schedule> allReadPagingReader(
PagingQueryProvider queryProvider) {
return new JdbcPagingItemReaderBuilder<Schedule>()
.pageSize(CHUNK_SIZE)
.fetchSize(FETCH_SIZE)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Schedule.class))
.queryProvider(queryProvider)
.name("jdbcCursorItemReader")
.build();
}
@Bean
public PagingQueryProvider queryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProvider = new SqlPagingQueryProviderFactoryBean();
queryProvider.setDataSource(dataSource);
queryProvider.setSelectClause("*");
queryProvider.setFromClause("from schedules");
Map<String, Order> sortKeys = new HashMap<>(1);
sortKeys.put("id", Order.ASCENDING);
queryProvider.setSortKeys(sortKeys);
return queryProvider.getObject();
}코드를 보시면 JdbcCursorItemReader와 설정이 크게 다른것이 하나 있는데요.
바로 쿼리 queryProvider()입니다.
JdbcCursorItemReader를 사용할 때는 단순히 String 타입으로 쿼리를 생성했지만, PagingItemReader에서는 PagingQueryProvider를 통해 쿼리를 생성합니다.
이렇게 하는데는 큰 이유가 있습니다.
각 Database에는 Paging을 지원하는 자체적인 전략들이 있습니다.
때문에 Spring Batch에는 각 Database의 Paging 전략에 맞춰 구현되어야만 합니다.
그래서 아래와 같이 각 Database에 맞는 Provider들이 존재합니다.
각 Database의 Paging 전략에 맞춘 Provider
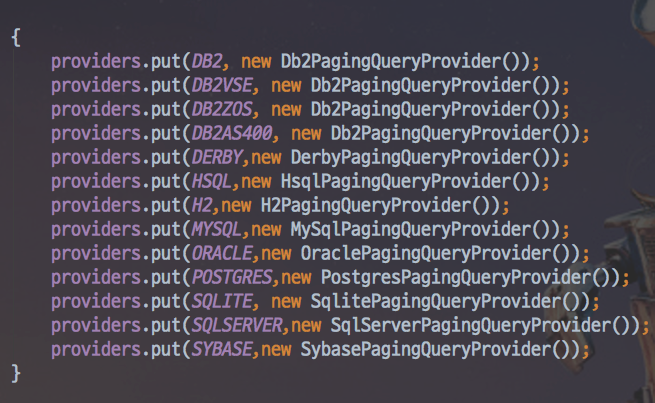
하지만 이렇게 되면 Database마다 Provider 코드를 바꿔야하니 불편함이 많습니다.
(로컬은 H2로 사용하면서 개발/운영은 MySQL을 사용하면 Provider를 하나로 고정시킬수가 없을 겁니다.)
그래서 Spring Batch에서는 SqlPagingQueryProviderFactoryBean을 통해 Datasource 설정값을 보고 위 이미지에서 작성된 Provider중 하나를 자동으로 선택하도록 합니다.
이렇게 하면 코드 변경 사항이 적어서 Spring Batch에서 공식 지원하는 방법입니다.
이외 다른 설정들의 값은 JdbcCursorItemReader와 크게 다르지 않습니다.
또 쿼리에 대한 매개 변수 값의 Map을 지정합니다.
queryProvider.setWhereClause 을 보시면 어떻게 변수를 사용하는지 자세히 알 수 있습니다.
where 절에서 선언된 파라미터 변수명과 parameterValues에서 선언된 파라미터 변수명이 일치해야만 합니다.
JpaPagingItemReader
점점 JPA를 사용하고 추세에 맞게
Spring Batch도 JPA를 지원하기 위해 JPA에 맞게 itemReader를 지원합니다.
그게 JpaPagingItemReader입니다.
단, Querydsl, Jooq 등을 통한 ItemReader 구현체는 공식 지원하지 않습니다.
CustomItemReader 구현체를 만들어야만 했습니다.
저 역시 DB 접근 구현체로 JPA를 사용했기에 Page를 구현하는 거와 함께 JpaPagingItemReader를 사용했습니다.
저는 그중에서도 JPA Repository를 사용할 수 있는 RepositoryItemReader를 사용했습니다.
RepositoryItemReader 프로젝트의 적용
프로젝트에는 Batch 작업으로 ward-study user에게 등록한 study-group이 있을시 예약시간을 30분 주기로 이메일로 알림을 주는 방식을 채택했습니다. 그 때 페이징할 대상으로 user를 선택했습니다.
왜 paging할 대상은 USER ?
Notification할 message들은 reservation이 더 많습니다. 페이징할 대상으로 reservation을 선택하는 게 더 나을지도 몰르겠지만 애초에 보낼 대상을 산정하면 이미 매핑될 테이블로 reservation을 batch processor에서 로직을 만들어 찾을 수 있기에 페이징할 대상은 user가 더 적합하다고 생각했습니다.
repository도 userrepository로 합니다.
@StepScope
@Bean
public RepositoryItemReader<User> notificationAlarmReader() {
return new RepositoryItemReaderBuilder<User>()
.name("notificationAlarmReader")
.repository(userRepository)
.methodName("findBy")
.pageSize(CHUNK_SIZE)
.arguments(List.of())
.sorts(Collections.singletonMap("id", Sort.Direction.ASC))
.build();
}다음 메서드가 중요하다, CHUNK_SIZE 기입을 해주면서 페이징(Chunk) 기반 ItemReader를 사용하는 것이다.
pageSize(CHUNK_SIZE)JpaRepository 주의 사항
단, 이 PagingItemReader로 JpaRepository를 사용할 시 주의 사항이 있습니다. 크게 두가지입니다.
1) 정렬 (Order)이 무조건 포함되어 있어야 합니다.
관련해서는 이전에 자세하게 정리한 포스팅이 있으니 참고하시면 좋습니다.
2) Hibernate, JPA 등 영속성 컨텍스트가 필요한 Reader 사용시 chunk와 pageSize 갯수를 똑같이 맞춰주는 것입니다. (기본 페이지 수(pageSize)가 10 으로 잡혀있습니다.)
참고
출처 : https://github.com/f-lab-edu/ward-study-reservation
