
인덱스를 만드는 키 종류
- 기본키(PK) - 중복x, null허용 x 하는 키, 클러스터링 인덱스 - 한 테이블의 1개만 배정 가능.
- 유일키(Unique key) - 중복x, null허용하는 키, 보조키
- 외래키(FK) - 참조키, 보조키
인덱스의 자료구조
인덱스 -> B-tree 인덱스 생성
즉, 또 하나의 매핑 테이블이 생성되는 것이다!
매핑 테이블 구조는 pointer 주소값을 가지고 있는 것처럼 해당 테이블 블럭의 주소를 가지는 구조이며,
search시, 그 테이블로 매핑된 곳을 가서 나머지 데이터들을 꺼내오는 방식이다.
- Block(블럭): 데이터가 저장되는 최소 단위(데이터들이 로우 단위로 저장됨)
인덱스 탐색은
Root -> Branch -> Leaf -> 디스크 저장소 순으로 진행된다.
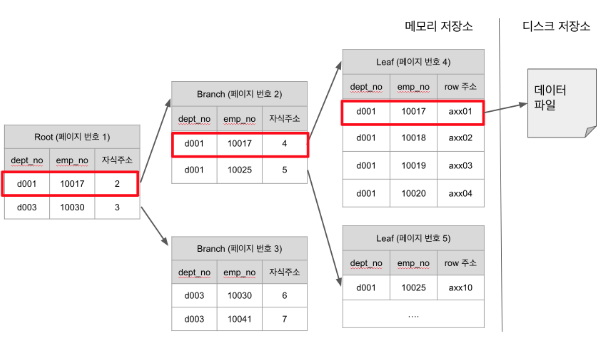
- InnoDB (MySQL)은 디스크에 데이터를 저장하는 가장 기본 단위를 페이지라고 하며, 인덱스 역시
페이지 단위로 관리됨.
속도는 그럼 왜, 어떻게 빨라지는 걸까?
컬럼을 기준으로 소팅(정렬)되어 저장돼어 search가 더 빨라지는 것이다.
즉 테이블 풀 스캔 x => 인덱스 스캔
여기서 특정 데이터 검색시 시작점 지정하게 되고(ex. where조건절) 인덱스 스캔이 되는 것이다!
효율적인 인덱스 배치(3가지 기준)
자주 등장하는 컬럼을, 그리고 분별력이 있는 컬럼을 먼저 배치하면 더 효율적으로 search가 된다.
where
order by 내에서.
그러기 위해 필드에 index를 설정할 시,
고려할 요소로 3가지 기준들이 있다.
1) 카디널리티 (Cardinality)
중복이 없는 정도를 나타내는 값인데, 높을수록 한 컬럼이 갖고있는 데이터에 중복이 없다는 뜻이다.
ex. 주민등록번호, 계좌번호 > 성별, 학년
=> 1개의 컬럼만 인덱스를 걸어야 한다면, 해당 컬럼은 카디널리(Cardinality)가 가장 높은 것을 잡아야 한다.
2) 선택도 (Selectivity)
특정값을 얼마나 잘 골라낼 수 있는지에 대한 지표로,
선택도 = (카디널리티 / 총 레코드수) * 100 전체 레코드와 조건절에 의해 선택될 예상 레코드 수의 비율이다. 5~10% 비율이 적당하다고 한다.
3) 활용도
카디널리티나 선택도가 별로 좋지 않더라도, 데이터가 빈번하게 호출되고 인덱스를 써서 조금이라도 개선됨이 보이면 쓰는거다.
여러컬럼을 조합을 하는
복합 인덱스같은 경우,
빨라지긴 하는데 마구잡이 인덱스 설정하면 lock 남발 => 데드락 발생할 가능성 있어 주의해서 써야 한다.
인덱스의 손익분기점
select 외 insert, update, delete(특히, insert) 어디에 저장할 지 찾아야 되서 더 비효율인 작업이 되어진다!
인덱스 손익 분기점은 전체 데이터의 10~15% 부터다. 이 때부터는 search도 느려지게 된다!
커버링 인덱스
인덱스로 설정한 컬럼만 읽어 쿼리를 모두 처리할 수 있는 인덱스.
불필요한 디스크 I/O 를 줄여 조회 시간을 단축할 수 있다.
select * from product ;
->
select id, name, price from product;
참고
< Real Mysql 8.0 > 1권
