
EagerLoading과 LazyLoading
1) EagerLoading : 특정 엔티티를 조회할 때 연관된 모든 엔티티를 같이 로딩, 즉시 로딩이라고 합니다.
즉시 로딩은 연관된 엔티티를 모두 가져온다는 장점이 있지만,
실무에서 엔티티간의 관계가 복잡해질수록 조인으로 인한 성능 저하를 피할 수 없게 됩니다.
JPA에서 연관관계의 데이터를 어떻게 가져올 것인가를 fetch(패치)라고 하는데,
연관관계의 어노테이션 속성으로 fetch모드를 지정합니다.
EagerLoading(즉시 로딩)은 불필요한 조인까지 포함해서 처리하는 경우가 많기 때문에 LazyLoading(지연 로딩)의 사용을 권장하고 있습니다.
2) LazyLoading: 가능한 객체의 초기화를 지연시켜 로딩하는 방법입니다.
즉, 실제 객체 대신 프록시 객체를 로딩해두고 해당 객체를 실제 사용할 때만(ex. getter 메서드를 사용할 때) 영속성 컨텍스트를 통해 실체 객체를 호출하는 로딩입니다.
@XToOne(OneToOne, ManyToOne) 관계는 기본이 EagerLoading(즉시 로딩)이므로 직접 지연로딩(fetch = FetchType.LAZY)으로 설정해야 합니다.
- 예시
@Entity
@Getter
@ToString(exclude = "member")
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class Board extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long bno;
@Column
private String title;
@Column
private String content;
// Lazy loading
@ManyToOne(fetch = FetchType.LAZY)
private Member member;
}- console 조회 표시
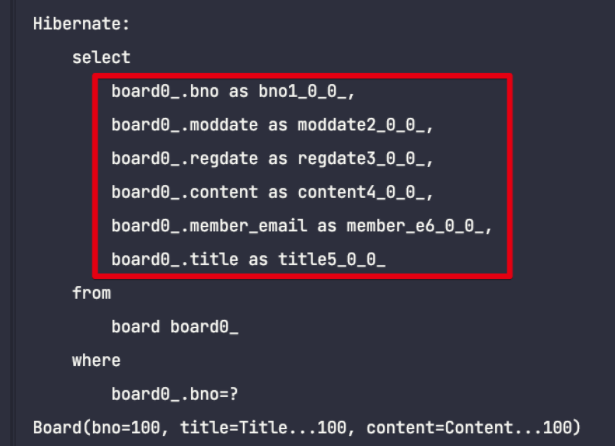
Board 엔티티에 LazyLoading(지연 로딩)을 적용한 후 SQL 쿼리문을 확인해보면, 이전과는 다르게 Board 테이블만 조회가 됩니다.
그리고 지연로딩은 proxy 객체를 사용하는 것으로, HiberateProxy$XXXXX 표시가 나온다.
N+1 문제 발생
하지만 지연로딩으로 sql을 가져와도 계속 생기는 문제가 있습니다. 바로 N+1 문제입니다. 이는 EgaerLoading에서 일어나는 문제이지만 Lazy Loading에서도 일어나는 성능 최적화 문제입니다.
💥
연관관계 매핑이 양방향(N:N)인 엔티티를 조회하면무한참조가 일어납니다!
예를 들어 이런 상황입니다.
SQL 1번으로 N명의 Member를 조회하였는데, 한번 SQL을 실행해서 조회된 결과 수만큼 N번 Member 엔티티 안에 연관관계로 있는 Order 엔티티까지 추가로 조회 SQL을 실행하는 것입니다.
Member 조회 -> Member 안의 Order 엔티티까지 조회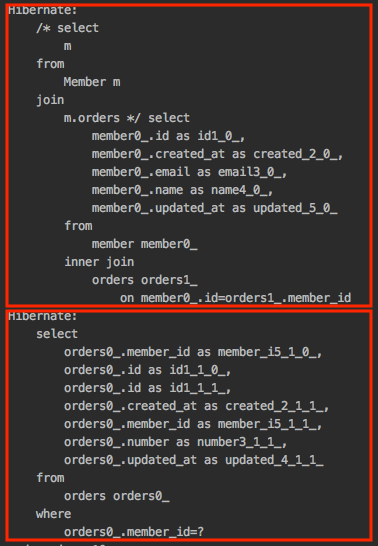
이런 N+1 해결하는 방법이 대표적으로
fetchJoin, @EntityGraph 방법이 있습니다.
fetchJoin 으로 해결하기
N+1 자체의 문제는 한쪽 테이블 조회하고 싶은데 연결된 다른 테이블까지 따로 조회되는 것입니다.
미리 두 테이블을 JOIN 하여 한 번에 모든 데이터를 가져올 수 있다면 애초에 N+1 문제가 발생하지 않을 것입니다. 이런방식을 fetchJoin 이라고 부릅니다.
✅fetchJoin : 연관된 엔티티나 컬렉션을 한 번에 같이 조회할 수 있습니다. fetchJoin을 사용하게 되면 연관된 엔티티는 프록시가 아닌 실제 엔티티를 조회하게 되므로 연관관계 객체까지 한번의 쿼리로 가져올 수 있습니다.
ex.
@Query("select DISTINCT o from Owner o join fetch o.pets")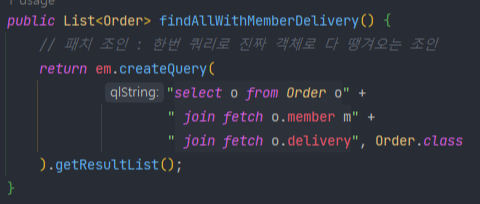
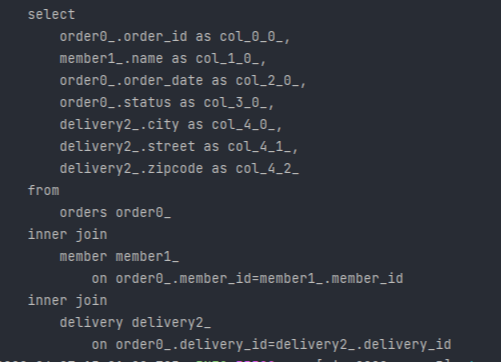
결과를 보면 쿼리가 1번만 발생하고 미리 데이터를 조인(Inner Join)해서 가져오는 것을 볼 수 있습니다.
Fetch Join(패치 조인)의 단점
- 쿼리 한번에 모든 데이터를 가져오기 때문에 JPA가 제공하는 Paging API 사용 불가능(Pageable 사용 불가)
- 1:N 관계가 두 개 이상인 경우 사용 불가
- 패치 조인 대상에게 별칭(as) 부여 불가능
- 번거롭게 쿼리문을 작성해야 함
@EntityGraph
@EntityGraph 의 attributePaths는 같이 조회할 연관 엔티티명을 적으면 됩니다. ,(콤마)를 통해 여러 개를 줄 수도 있습니다.
Fetch join과 동일하게 JPQL을 사용해 Query문을 작성하고 필요한 연관관계를 EntityGraph에 설정해야 합니다.
ex.
@EntityGraph(attributePaths = {"pets"})
@Query("select DISTINCT o from Owner o")EntityGraph는 미리 데이터를 조인(outerJoin)해서 가져옵니다.
Fetch Join vs EntityGraph
Fetch Join과 @EntityGraph의 출력되는 쿼리를 보면 알다시피,
Fetch join의 경우 inner join을 하는 반면에 EntityGraph는 outer join을 기본으로 합니다.
(기본적으로 outer join 보다 inner join이 성능 최적화에 더 유리하다.)
보통 그래서 Fetch Join이 더 많이 사용됩니다.
JPQL을 사용할 경우 그냥 쿼리 뒤에 join fetch 만 붙여주면 되는데 번거롭게 어노테이션과 그 속성을 추가할 필요가 없기 때문인 것도 있는 것 같습니다.
Fetch Join과 EntityGraph 사용시 주의할 점
FetchJoin과 EntityGraph는 공통적으로 카테시안 곱(Cartesian Product)이 발생 하여 중복이 생길 수 있습니다.
※ 카테시안 곱 : 두 테이블 사이에 유효 join 조건을 적지 않았을 때 해당 테이블에 대한 모든 데이터를 전부 결합하여 테이블에 존재하는 행 갯수를 곱한만큼의 결과 값이 반환되는 것
-
카테시안 곱(Cartesian Product)을 일이키는
Cross Join
카테시안 곱이 일어나는 Cross Join은 JPA 기능 때문이 아니라, 쿼리의 표현에서 발생하는 문제이다. -
Cross Join이 일어나는 조건
Join 명령을 했을 때 명확한 Join 규칙이 주어지지 않았을 때,
join 이후 on 절이 없을 때, db는 두 테이블의 결합한 결과는 내보내야겠고, 조건이 없으니 M * N으로 모든 경우의 수를 출력하는 것이다.
JPA는 사용자가 보내준 코드를 해석해서 최적의 sql 문장을 조립하는데,
이 때 코드가 얼마나 연관관계를 명확히 드러냈냐에 따라 발생 할 수도 안 할 수도 있다.
Fetch Join과 @EntityGraph의 기능은 'Cross Join을 만들어라' 나 'Inner Join을 만들어라' 가 아니고,
'연관관계 데이터를 미리(EAGER) 함께 가져와라' 인 만큼 중복을 제거해야 합니다.
=> 이런 중복 발생 문제를 해결하기 위해서 DISTINCT 또는 Set 자료구조를 사용하면 됩니다.
1. JPQL에 DISTINCT 를 추가하여 중복 제거
@Query("select DISTINCT o from Owner o join fetch o.pets")
List<Owner> findAllJoinFetch();@EntityGraph(attributePaths = {"pets"})
@Query("select DISTINCT o from Owner o")
List<Owner> findAllEntityGraph();2. OneToMany 필드 타입을 Set으로 선언하여 중복 제거
@OneToMany(mappedBy = "owner", fetch = FetchType.EAGER)
private Set<Pet> pets = new LinkedHashSet<>();(Set은 순서가 보장되지 않는 특징이 있지만, 순서 보장이 필요한 경우 LinkedHashSet을 사용하자.)
💥 Fetch Join의 한계: 컬렉션을 페치 조인하면 페이징이 불가능! => Batch_size로 해결!
위방식으로 처리를 해보았지만,
중복 Distinct 처리는 SQL 쿼리 성능에 좋지 못합니다.
그리고 Collections 타입의 OneToMany 연관관계의 타입들은 Paging을 사용시 💥paging out of memory warning 오류가 뜹니다!
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!✅ hibernate는 DB레벨에서 페이징 하지 못하고 우선 데이터를 모두 가져온 다음 애플리케이션 메모리에서 페이징을 하기 때문입니다!
즉, Collection 타입의 필드들을 조회시, fetch join을 할 때 페이징은 불가능합니다!
이를 해결하는 방법으로는 in 쿼리를 사용해서 컬렉션 필드를 제한해서 조회하는 Batch_size 를 사용하는 겁니다!
이 방법 설명은 다음 블로그를 참고해주세요!
https://velog.io/@mooh2jj/JPA-페이징-컬렉션-N1-문제-브릿지-뻥튀기-문제-해결-정리
그외 JPA 쓰면서 고려해야 할 점들
참고: https://velog.io/@johnsuhr4542/JPA-를-사용하면서-고려해야-했던-점
참고
