
JPA를 사용하는 이유
JPA는 ORM기술 중 하나,
-
ORM =
객체+RDB두 기둥위에 있는 기술 -
SQL의 문제점
1) 같은 코드의 무한 반복 -> sql 코드, 기본 CRUD의 반복
2) 패러다임으로는 구식 -> 객체와 RDB의 구조적 차이 -> 객체를 DB table과 불일치.
다시말하면, 객체는 추상화, 상속, 다형성(클래스, 메서드) 의 특징을 가지고 있고, RDB는 데이터 중심으로 이루어져, RDB에 객체를 저장하는 데 불일치가 생길 수 밖에 없다.
- 연관관계 차이점
객체는 참조를 사용해서 연관된 객체를 조회하는 데, 테이블은 외래키로 연관관계를 설정하고 조인으로 연관 테이블을 조회함
객체 그래프 탐색:객체는 자유롭게 객체 그래프를 탐색할 수 있어야 한다!그런데 sql은 그게 안된다!
ex)
EntityManager.find()
객체 그래프 탐색 -> a.getB().getC()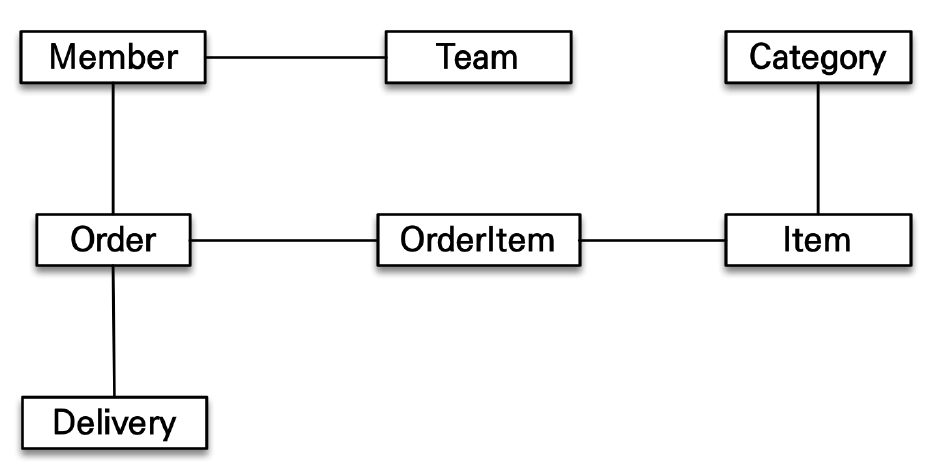
객체 그래프가 어디까지 탐색할 수 있는 지를 SQL에서 사용해보아야 한다.(지연로딩을 사용하는 이유!)
→ JPA는 실제 객체를 사용하는 시점까지 DB조회를 미룬다(지연로딩). 따라서 연관된 객체를 신뢰하고 조회할 수 있다!
- 비교
DB는 PK(기본 키)로 각 로우를 구분하는 반면, 객체는 동일성/동등성 비교를 한다.
JPA에서는 DB의 같은 로우를 조회할 경우, 1차 캐시로 동일성 을 보장해준다! (단, 같은 트랜잭션 범위내에서!)
- 동일성(==)로 하는 성질,
주소값까지 같은걸로 보장한다는 것! - 동등성(equals)로 하는 성질
- 성능
1) 1차 캐시와 동일성(identity) 보장
- 같은 트랜잭션 안에서 같은 엔티티 조회시 엔티티 동일성 보장! - 약간의 조회 성능 향상
- DB Isolation Level이 Read Commit이어도 애플리케이션에서 Repeatable Read 보장
2) 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
- 트랜잭션을 커밋할 때까지 INSERT, UPDATE, DELETE SQL을 모아서 보냄
- JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송
3) 지연 로딩(Lazy Loading)
- 즉시로딩 - 정적로딩
- 지연로딩 - 동적로딩
JPA로 조회설계시 순서는
즉시로딩 -> 지연로딩(최적화시) 으로 진행하는 것이다. - 김영한
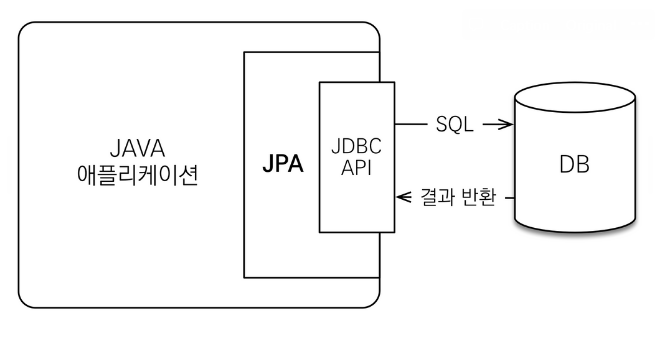
JPA란?
자바의 ORM 기술 표준
: Java Persistence API, 자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스
-
여기서
ORM이란?
: 객체 - RDB 매핑해주는 기술 -
객체는 객체대로 / RDB는 RDB대로 설계후
그 차이(패러다임의 차이)는 ORM이 SQL을 자동 생성하여 해결해줌 -
그럼
Hibernate는 뭐지?
-JPA 구현체의 한 종류로, (DataNucleus, EclipseLink등 다른 구현체도 존재)
- JPA가 DB와 자바 객체(Entity)를 매핑하기 위한 인터페이스이고 Hibernate는 이를 구현한 라이브러리이다 (마치 인터페이스-클래스의 관계) -
그럼
Spring Data JPA는?
- JPA를 편하게 쓰기 위한 모듈
- EntityManager가 아닌, Repository를 정의하여 사용하는 더 쉬운 방법
(Repository 내부적으로는 EntityManager을 사용) -
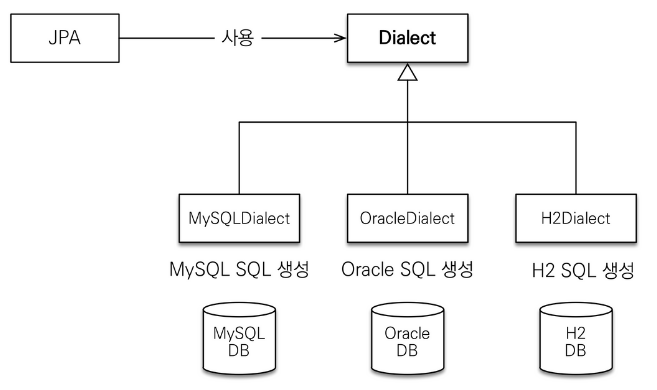
데이터베이스 방언(Dialect)이란?
- DB마다 제공하는 SQL 문법이 다른데, 이처럼 SQL 표준이 아닌 기능을 의미함
- JPA가 참고해서 번역해서 사용, JPA는 특정DB에 종속X
JPA 작동 방식
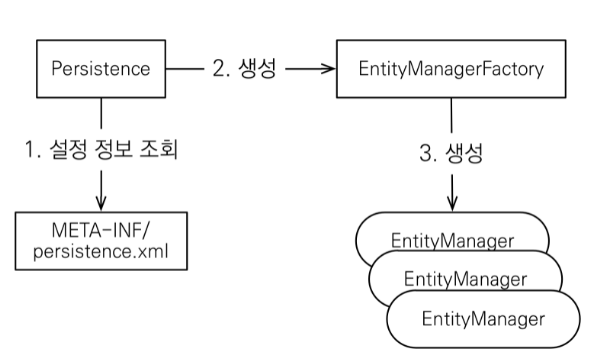
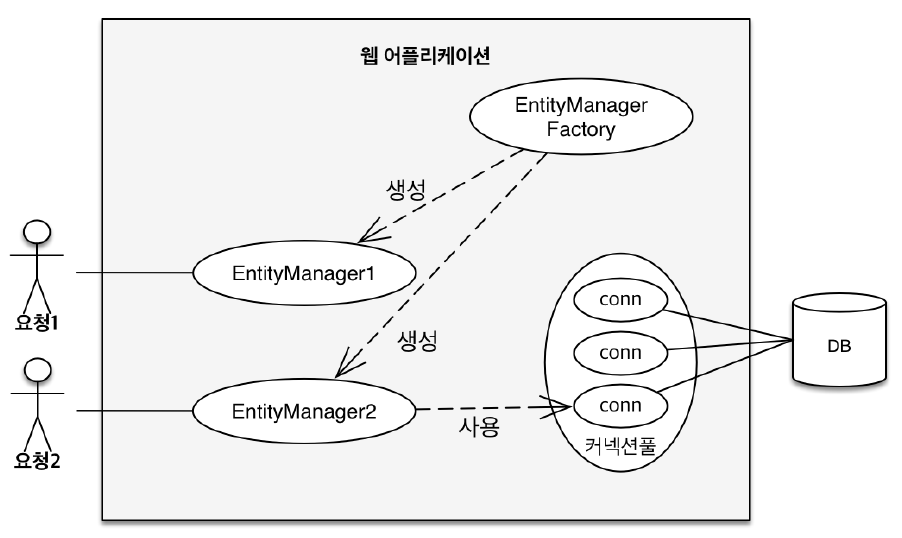
EMF(EntityManagerFactory)에서 EM(EntityManager)을 생성함
- EMF : EM을 관리하는 주체. 어플리케이션에서 DB당
하나만 생성 - EM : 영속성 컨테스트에 접근하는 주체. 엔테티에 대한 DB 작업을 해주는 것이 EM이다. 매번 요청이 올때 마다 사용, 버림 (단, 쓰레드 간 공유X)
모든 작업은 트랜잭션 안에서 실행됨
✅ 트랜잭션이란?
- DB의 상태가 변화하는 작업 단위로, 그 작업 단위는 개발자가 정할수 있음.
- 사용자가 DBMS에게 요청하는 일련의 작업들
💥주의사항
- EM은 하나만 생성해서 애플리케이션 전체에서 공유한다!
- EM는 쓰레드간에 공유X (사용하고 버려야 한다)
- JPA의 모든 데이터 변경은 트랜잭션 안에서 실행된다는 걸 잊지말자.
지연 로딩과 즉시 로딩
- 지연 로딩(LazyLoading):
객체가 실제 사용될 때 로딩 - 즉시 로딩(EagerLoading):
JOIN SQL로 한번에 연관된 객체까지 미리 조회

JPQL이란?
-
JPA를 사용하면
엔티티 객체를 중심으로 개발
• 문제는 검색 쿼리!
• 검색을 할 때도 테이블이 아닌엔티티 객체를 대상으로 검색
• 모든 DB 데이터를 객체로 변환해서 검색하는 것은 불가능
• 애플리케이션이 필요한 데이터만 DB에서 불러오려면 결국 검색 조건이 포함된 SQL이 필요 -
JPQL는 JPA가 제공하는 SQL을 추상화한
객체 지향 쿼리 언어
• SQL과 문법 유사, SELECT, FROM, WHERE, GROUP BY, HAVING, JOIN 지원
• JPQL은엔티티 객체를 대상으로 쿼리
• SQL은 데이터베이스 테이블을 대상으로 쿼리
영속성 컨텍스트
영속성 컨텐스트란 엔티티를 영구 저장하는 환경이라는 뜻이다.
애플리케이션과 데이터베이스 사이에서 객체를 보관하는 가상의 데이터베이스 같은 역할을 한다.
엔티티 매니저(EntityManager)를 통해 엔티티를 저장하거나 조회하면 엔티티 매니저는 영속성 컨텍스트에 엔티티를 보관하고 관리한다.
// 엔티티 매니저 팩토리 애플리케이션 전체에서 공유.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("unit-member");
// 엔티티 매니저 쓰레드간 공유 금지.
EntityManager em = emf.createEntityManager();
// 엔티티 매니저가 엔티티를 연속성 컨테스트에 저장
em.persist(entity);EM(Entity Manager) 메서드
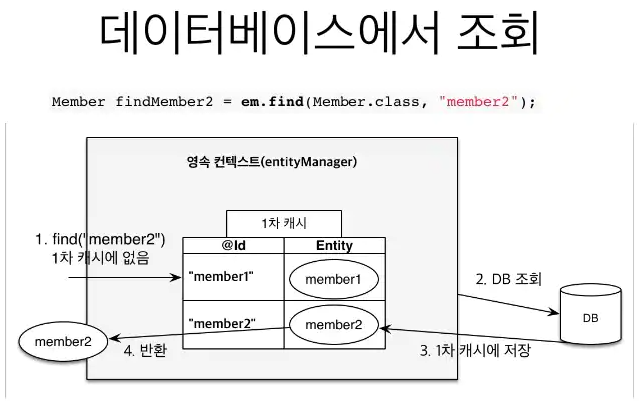
- find() : 영속성 컨텍스트에서 엔티티를 검색, 없으면 DB에서 데이터를 검색, 그리고 영속성 컨텍스트에 저장
- persist() : 엔티티를 영속성 컨텍스트에 저장
- remove() : 엔티티 클래스를 영속성 컨텍스트에서 삭제
- flush() : 영속성 컨텍스트에 저장된 내용을 DB에 반영
Entity 생명 주기
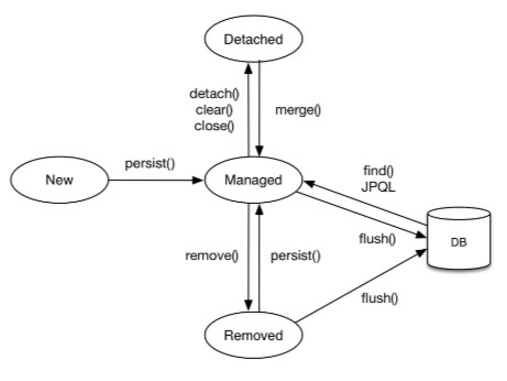
1) 비영속 (new) : 영속성 컨텍스트와 전혀 관계가 없는 상태
// 객체를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");2) 영속 (managed) : 영속성 컨텍스트에 저장된 후 관리되는 상태.
// 객체를 저장한 상태(영속)
em.persist(member); 3) 준영속 (detached) : 영속성 컨텍스트에서 저장되었다가 관리에서 제외한 상태.
// 회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태, 향후 영속상태로 만들기 위해서 merge()가 이용된다.
em.detach(member);4) 삭제 (removed) : 삭제된 상태. flush()가 일어나는 시점에 영속성 컨텍스트와 DB 삭제.
// 객체를 삭제한 상태(삭제)
em.remove(member);영속성 컨텍스트 디테일하게 정리
1) 1차 캐시
영속성 컨텍스트는 내부에 캐시를 가지고 있는데, Map 자료구조로 되어있다.
이 1차 캐시는 비즈니스로직이 복잡할수록 도움이 된다.
성능적인 이점보다는 객체지향적으로 작성할 수 있는 컨셉적인 이점이 있다.
영속상태의 엔티티는 모두 이곳에 저장된다.(persist)
키(key)는 @Id로 매핑한 식별자고 값(value)은 엔티티 인스턴스이다.
1차 캐시의 존재로,
엔티티를 조회하는 쿼리를 날렸을 때 1차 캐시에 있으면 같은 쿼리면 DB까지 거치지 않는다.
없을 경우, DB에 직접 조회하고 영속성컨텍스트에 넣은 다음에 1차캐시에서 가져온다.
영속성 컨텍스트의 1차 캐시는 여러명의 고객이 사용하는 캐시가 아니라 한명의 고객이면서 심지어 하나의 트랜잭션 단위에서 찰나의 순간동안 만 유지되는 것이다. 즉, 1차 캐시는 어플리케이션 전체공유가 아닌 한 트랜잭션 내에서만 공유 되는 것이다.
애플리케이션 전체에서 공유하는 캐시는 2차캐시가 있다.
2) 동일성(identity) 보장
같은 트랜잭션 안에서 똑같은 것을 조회했을 때 == 비교를 하면 동일한 객체인 것이 보장된다.
(값, 주소 모두 같다.)
Member a = em.find(Member.class, "member1");
Member b = em.find(Member.class, "member1");
System.out.println(a == b); // 동일성 비교 true마치 자바 컬렉션에서 가져올 때 똑같은 레퍼런스 객체를 가져오면 주소가 같은 것처럼 말이다.
1차캐시에서 꺼내오는 것 때문에 동일성이 보장되는 것이다.
이로써 JPA는 1차 캐시로 반복 가능한 읽기(REPEATABLE READ) 등급의 트랜잭 션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공할 수 있는 것이다.
3) 트랜잭션을 지원하는 쓰기지연(버퍼)
영속성컨텍스트에는 1차캐시와는 별개로 쓰기지연 sql저장소가 있는데,
예를 들어, insert 구문인 sql을 쓰기지연 sql저장소에 쌓다가 트랜잭션이 끝나면 한꺼번에 보낸다.(flush -> commit())
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
//엔티티 매니저는 데이터 변경시 트랜잭션을 시작해야 한다.
transaction.begin(); // [트랜잭션] 시작
em.persist(memberA);
em.persist(memberB);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다!!!
//커밋하는 순간 데이터베이스에 INSERT SQL을 보낸다.
transaction.commit(); // [트랜잭션] 커밋
4) 변경감지(DirtyChecking)
: 더티 체킹은 Transaction 안에서 엔티티의 변경이 일어나면, 변경 내용을 자동으로 데이터베이스에 반영하는 JPA의 특징이다.
엔티티 수정
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin(); // 트랜잭션 시작
// 영속 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
// 영속 엔티티 데이터 수정
memberA.setUsername("hi");
memberA.setAge(10);
// em.update(member) 이런 코드가 있어야 하지 않을까?
// 트랜잭션 커밋
transaction.commit();
👀 간단 정리
JPA에서 영속성 컨테스트에 대한 내용은 ->
식별자&1차캐시&snapshot(스냅샷)그리고dirty checking(변경감지)으로 정리가 된다.
dirty checking은 영속상태일 때 일어나며, -> 그건 바로 JPA 수정을 할려면@Transactinal안에서 해야된다는 뜻이다!
그리고쓰기지연이란snapshot에서 비교해서 생겨난 update, insert 등 쿼리로 만들어서 저장소에 저장됐다가 한번에 모아서 DB에 반영해주는 것이다.
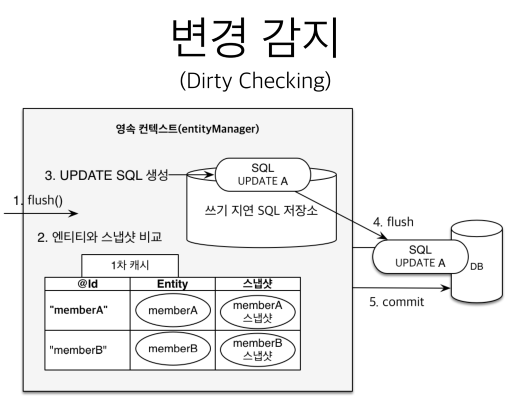
더티채킹(Dirty Checking) 과정
-
더티 체킹은 영속성 컨택스트(Persistence Context) 안에 있는 엔티티를 대상으로 일어납니다.
때문에, detach 되거나(준영속), DB에 반영되기 전 처음 생성된(비영속) 상태의 엔티티는 더티 체킹이 적용되지 않습니다. -
또한
Transaction 안에서만일어나기 때문에,@Transactional 어노테이션등으로 한 트랜잭션으로 묶어주고 변경해야 적용됩니다.
-
영속성컨텍스트의 1차 캐시에는
snapshot이라는 것이 있는데 값을 읽어올 때(find())의 최초상태를 snapshot으로 사진찍듯 찍어둔다. -
commit 직전에 flush(DB 동기화)를 할때
JPA에서 내부적으로entity와 snapshot을 일일이 비교를 해서 변경이 감지되면 update 쿼리를쓰기지연sql저장소에 만들어두고update를 db에 반영(flush)하고commit한다.
영속컨텍스트 snapshot 비교 -> sql쿼리 -> flush -> commit
✅
merge와변경감지(더티채킹)중 실무에서 update처리는변경감지를 사용한다!
merge는 명시되지 않은 것들까지 모든 필드에다 null로 넣을 수 있기 때문에 그렇다. - 김영한
JpaRepository.save() 주의사항
✅ save 는 insert(persist), update(merge) 둘 다 할 수 있다.
// SimplaJpaRepository.save(S entity) 메서드
@Transactional
@Override
public <S extends T> S save(S entity) {
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}1) persist()
entity 식별자의 상태인 id(Long, String..., int, long..) 가 없으면 Transient 상태임을 인지하고, save 로 저장시 persist() -> insert 메소드를 사용하게 된다.
2) merge()
id 가 기존에 존재하면 Detached 상태임을 인지하고, save로 저장시 merge() -> update all 메소드를 사용한다.
즉, 식별자에 @GenerateValue 애노테이션을 설정하였다면, 데이터베이스에 식별자 생성을 위임하기 때문에 save를 호출하는 시점에 새로운 엔티티로 인식하여 우리가 원하던대로
persist가 호출 되겠지만, @Id 만 사용해서 식별자를 직접 할당 하였다면, 이는 save 호출 시점에 새로운 엔티티가 아니므로merge를 호출하게 된다.
만약에 DB에 해당 식별자로 하는 데이터가 이미 들어가 있었다면?
해당 데이터는 파라미터 entity의 값으로 모두 update all 되어버린다.
출처 : https://web-km.tistory.com/46
자, 정리하면,
merge를 사용하면 엔티티에 있는 모든 값을 DB에 다 반영하게 됩니다. 값에 null이 있거나 업데이트를 원하지 않는 값도 모두 반영됩니다.
반면에 변경 감지를 사용하면, 엔티티의 값 중에서 원하는 값만 뽑아서 적용할 수 있습니다.
이런 이유로 merge는 사실 혼란만 가중하고, 사용하지 않는 것을 권장합니다.
merge의 원래 목적은 준영속 상태로 변한 엔티티를 다시 영속상태로 바꾸는 것이 주 목적이지, 이렇게 업데이트 하는 용도가 주 목적은 아닙니다.
추가로 @DynamicUpdate는 너무 다양한 형태의 업데이트 쿼리가 발생하기 때문에, 저는 권장하지 않는 편입니다. - 김영한
flush
(flush -> commit 순)
DB가 commit되기 직전에 영속성컨텍스트에 있던 변경사항과 DB를 동기화하는 과정을 말한다.
=> 영속성컨텍스트에 있는 엔티티와 snapshot으로 일일히 비교
1) flush 발생 시점
- em.flush()를 호출.
- JPQL 실행시.
- 트랜잭션 commit시.
2) 플러시 모드 옵션 설정
em.setFlushMode(FlushModeType.COMMIT)FlushModeType.AUTO
커밋이나 쿼리를 실행할 때 플러시 (기본값)FlushModeType.COMMIT
커밋할 때만 플러시
3) 💥주의사항(플러시는!)
- 영속성 컨텍스트를 비우는 게 아님!
- 영속성 컨텍스트의 변경내용을 데이터베이스에
동기화하는 것!- 트랜잭션이라는 작업 단위가 중요 -> commit 직전에만 flush 하면 됨
@Transactional(readOnly = true)
트랜잭션 읽기(select) 전용 모드의 경우 flush()가 발생하지 않음.
변경 감지 (dirth checking)시 사용되는 스냅샷 비교와 같은 비용을 줄이게 된다.
그럼, 반대로 변경(merge or dirtycheking)을 할려면 이 어노테이션을 쓰면 안된다. @Transactional 을 써라!
결론)
flush는 영속성컨텍스트를 비우지 않으며(비우는 것은 clear이다.)
영속성 컨텍스트의변경내용을DB에 동기화한다. 즉, 변경일 때만 flush 작업을 해주면 되는 것이다!
👀 그럼 clear는?
clear 는 JPA 영속성 컨텍스트를 다 비우는 것이다.
EntityManager em;
영속성 변경 작업 후
em.flush(); // 변경한 내용 쿼리 db에 보냄
em.clear(); // 영속성 컨텍스트 안 1차 캐시 비움준영속 상태(merge vs dirty checking)
✅ 준영속과 비영속의 차이점
영속상태가 되어본 경험이 있느냐이다.
영속상태가 되기 위해서는 식별자가 반드시 필요하다.
따라서 준영속 상태의 엔티티는 식별자가 존재하지만
비영속 상태의 엔테테는 식별자가 존재할 수도, 존재하지 않을 수도 있다.
✅ 준영속상태를 만드는 3가지 방법**
1) em.detach(member)
: 특정 엔티티를 준영속 상태로 전환한다.
2) em.clear()
: 영속성컨텍스트의 1차캐시를 통째로 지운다.(초기화)
3) em.close()
: 영속성컨텍스트를 종료시킨다.
준영속상태일 때,
merge(),dirty checking은 처리를 하는 것이다.??
준영속상태일 때, 다시 영속상태로 돌리려면
merge()를 사용한다.dirty checking은 비영속상태일 사용할 수 없다.
영속상태의 엔티티가 영속성컨텍스트에서 분리되어 영속성 컨텍스트가 제공하는 기능을 사용 못하는 상태.
예를 들어, find를 통해 조회해서 영속성컨테스트에 들어갔고 setter를 통해 더티채킹(=변경감지)이 되는 코드를 작성했을 때
commit하기 전에 detach를 통해 영속성 컨텍스트에서 분리하면 더티채킹이 작동하지 않는다.
연관관계 매핑
-
각각의 단방향 매핑 2개가 있다.
-
외래키를 갖는 쪽(Many쪽)이 주인의 개념을 갖는다. (@JoinColumn)
-
주인 Entity에서만 insert. 주인이 아닌쪽에서는 select만 가능.
: 다만 양쪽 모두에 조인 연관 관계를 추가하도록 권장. -
mappedBy 속성은 "다른 Entity에게 매핑되었다. 나는 주인이 아니다" 라는 의미임.
-
중요한 부분은 주인쪽에 외래키 컬럼을 별도로 설정하지 않는다.
자세한 건 다음 블로그 참조 - https://velog.io/@mooh2jj/JPA-양방향-매핑-코드-구현-정리
참고
