
SpringBatch에 알아야 하는 내용을 정리합니다.
Spring Batch란?
요청이 들어올때 마다 실시간으로 데이터를 처리 하는것이 아닌 일괄적으로 모아서 하는 작업이 바로 배치 (Batch) 작업이라고 합니다.
이러한 특성때문에 배치작업은 일반적으로, 정해진 시간에 대량의 데이터를 일괄적으로 처리한다는 뜻으로 이해하면 됩니다.
가장 유명한 예시는 이커머스 주문 후, 정산 시스템입니다.
ex.
주문 발생일로부터 7일 뒤에 정산
ex.매일 새벽 4시, 어제까지 구매 확정이 난 주문 건들을 모아 수수료를 제외하고 정산 테이블에 데이터를 생성
Batch vs Scehduler
⚠️ 배치가
스케쥴러라는 뜻은 아닙니다!
☑️ 스케쥴러는 batch를 구성하는 하나의 요소일 뿐입니다!
다시말해, 주기적으로 일괄처리할 때 batch에 주기성을 덧붙이는 데 쓰이는 겁니다. ex. cron
✅ 스프링 배치를 이해하는 데 가장 중요한 사진입니다!
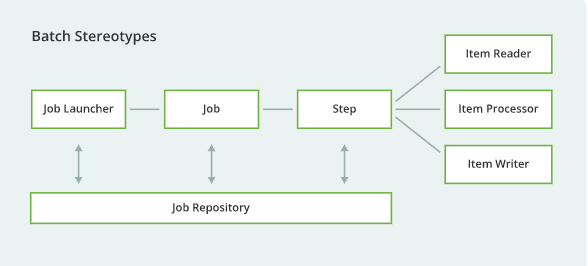
출처: https://spring.io/batch
Batch vs Scheduler의 차이
- 배치(Batch) => 일괄(대량)처리!
사용자와 상호작용 없이여러 개의 작업을 미리 정해진 순서에 따라 중단없이 처리하는 것
-> Spring Batch
ex. 대량의 유저회원들에게 알림 메시지 보내기
-
스케쥴러(Scheduler)
특정한 시간에등록한 작업을 자동으로 실행시키는 것
-> Spring Scheduler, Quarts 등
ex. 새벽 12시에 쿠폰 만료(expired)시간 체크하기
중요 용어
1) JobRepository
배치 처리 과정 중 발생하는 모든 메타데이터를 관리하는 메커니즘입니다. Job이 언제 실행되었고, 어떤 Step이 성공하거나 실패했는지 등의 이력을 DB에 저장하고 조회
작업 로그/장부 이다.
2) JobLauncher
Job을 실행하는 트리거 역할, 배치의 실행버튼
3) Job
전체 배치 작업의 단위
정해진 Step을 실행시킬 작업을 의미로,
Job configuration과 대응되는 단위입니다.
4) Step
Job 내부에서 수행될 독립적으로 실행하고 순서가 지정될 수 있습니다. 1개의 Step 또는 N개의 Step들로 이루어질 수 있습니다.
Job > 여러 Step (2종류: Tasklet, Chunk)
5) 그외 알아두어야 할 용어
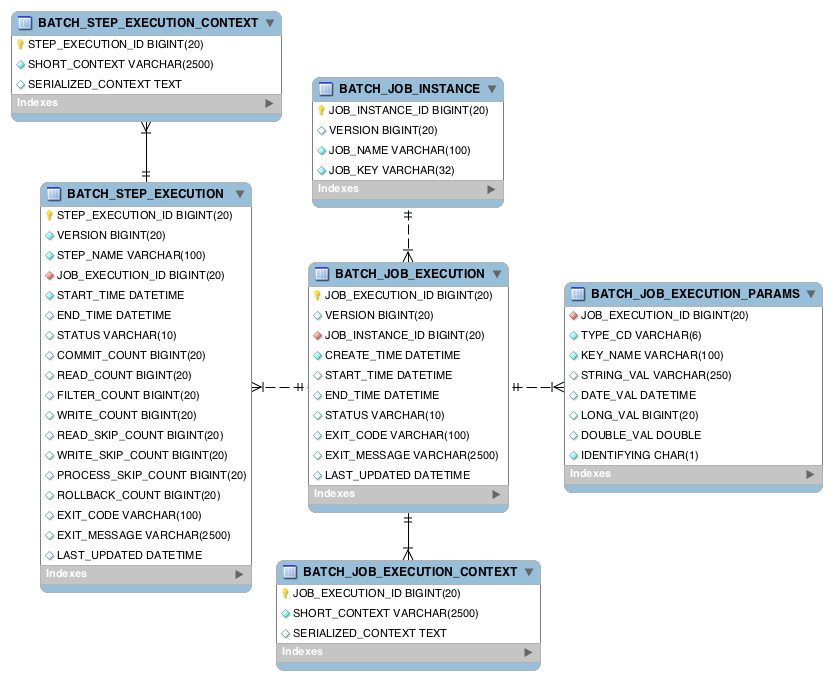
batch 메타 테이블
Spring batch가 제공하는 가장 기본적인 기능으로 배치 작업 하는동안 사용되는 모든 메타정보들 (작업 시간, 파라미터, 정상수행 여부 …)을 기록하여 작업 중에 사용하거나 모니터링 용도로 사용 할 수 있게 해줍니다.
이러한 이유로 Spring batch를 사용하기 위한 ‘첫번째 단계’는 다름이 아닌 메타 데이터 스키마을 구성하는 것 입니다.(application.yml - batch:jdbc:initialize-schema: always)
Spring Batch에서는 DB를 통해 완료/실패 와 같은 상태관리를 합니다.
크게 4가지 상태를 DB에 저장합니다.
1 이전 실행 Job History
2 실패한 Batch와 Parameter / 성공한 Job
3 실행 재개 지점
4 Job 기준 Step현황과 성공/실패 여부
Tasklet vs ✅Chunk
비교 장점
Spring Batch에서 Tasklet과 Chunk 방식은 데이터를 처리하는 "철학" 자체가 다릅니다. 쉽게 말해, "한 번에 한 놈만 패느냐(Tasklet)"와 "줄 세워서 단체로 처리하느냐(Chunk)"의 차이입니다.
상황에 맞게 골라 쓰실 수 있도록 핵심 이유와 차이점을 깔끔하게 정리해 드릴게요!
Tasklet (태스크릿) 방식을 쓰는 이유
Tasklet은 "하나의 단계(Step)에서 단일 작업"을 수행할 때 사용합니다. execute 메서드 하나만 구현하면 되기 때문에 구조가 매우 단순하죠.
- 단순성: 복잡한
Reader-Processor-Writer구조를 짤 필요 없이, 로직을 한곳에 다 때려 넣을 수 있습니다. - 비정형 작업: 대량의 데이터를 읽고 쓰는 게 아니라, 특정 시점에 한 번만 실행하면 되는 작업에 최적화되어 있습니다.
- 예: 파일 삭제, 디렉토리 생성, DB 특정 테이블 초기화, 알림 메세지 한 번 보내기 등.
- 자유도: 개발자가 원하는 모든 로직을 자유롭게 넣을 수 있어, 정해진 틀(Chunk)에 얽매이지 않습니다.
Chunk (청크) 방식을 쓰는 이유
Chunk 방식은 "대량의 데이터를 일정 단위(Chunk)로 나누어 처리"하는 방식입니다. 스프링 배치의 정점이라고 할 수 있죠.
- 메모리 효율성: 1,000만 건의 데이터를 한 번에 메모리에 올리면 서버가 터지겠죠? Chunk 방식은 1,000건씩(Chunk Size) 끊어서 처리하기 때문에 메모리를 효율적으로 씁니다.
- 트랜잭션 관리: "Chunk 단위로 트랜잭션"이 걸립니다. 예를 들어 1만 건 처리 중 5,500번째에서 에러가 나도, 이미 성공한 5,000건은 커밋되고 나머지 500건만 롤백됩니다. (실패 지점부터 재시작 가능!)
- 역할 분담: 데이터를 읽고(
ItemReader), 가공하고(ItemProcessor), 쓰는(ItemWriter) 역할이 명확히 분리되어 유지보수가 쉽고 재사용성이 높습니다.
한눈에 보는 비교표
| 구분 | Tasklet (단일 작업) | Chunk (묶음 작업) |
|---|---|---|
| 핵심 구성 | Tasklet 인터페이스 구현 | Reader + Processor + Writer |
| 처리 방식 | 한 번에 전체 로직 실행 | Chunk 단위로 반복 실행 |
| 데이터 양 | 소량 혹은 데이터와 무관한 작업 | 대량 데이터 처리에 최적화 |
| 트랜잭션 | Step 전체가 하나의 트랜잭션 (보통) | Chunk 단위로 개별 트랜잭션 |
| 주요 용도 | 파일 관리, 단순 쿼리 실행, 로그 기록 | ETL(추출-변환-적재), 대규모 마이그레이션 |
💡 결론: 언제 뭘 써야 할까?
"고민될 때는 데이터 양을 보세요."
- "그냥 DB 테이블 하나 비우고 끝낼 거야." 혹은 "파일 하나 압축해서 옮길 거야."
👉 Tasklet을 선택하세요. 구현이 훨씬 빠릅니다. - "회원 100만 명한테 포인트 지급할 거야." 혹은 "로그 50GB를 읽어서 통계 낼 거야."
👉 무조건 Chunk입니다. 그래야 중간에 멈춰도 처음부터 다시 안 하고, 서버 메모리도 안전합니다.
그래서 스프링배치는 Chunk 지향!
: 간단하게 구성할 때는 Tasklet, 하지만 스프링배치는 Chunk 지향한다는 겁니다!
Task기반 : 하나의 작업 기반으로 실행
Chunk기반 : 하나의 큰 덩어리를 n개씩 나눠서 이 단위로 실행.
✅ 즉, chunk 단위로 commit과 rollback이 이루어지는 것임.
Step의 종류는 아래 3가지입니다.(Chunk 기준)
ItemReaderItemWriterItemProcessor(필수x)
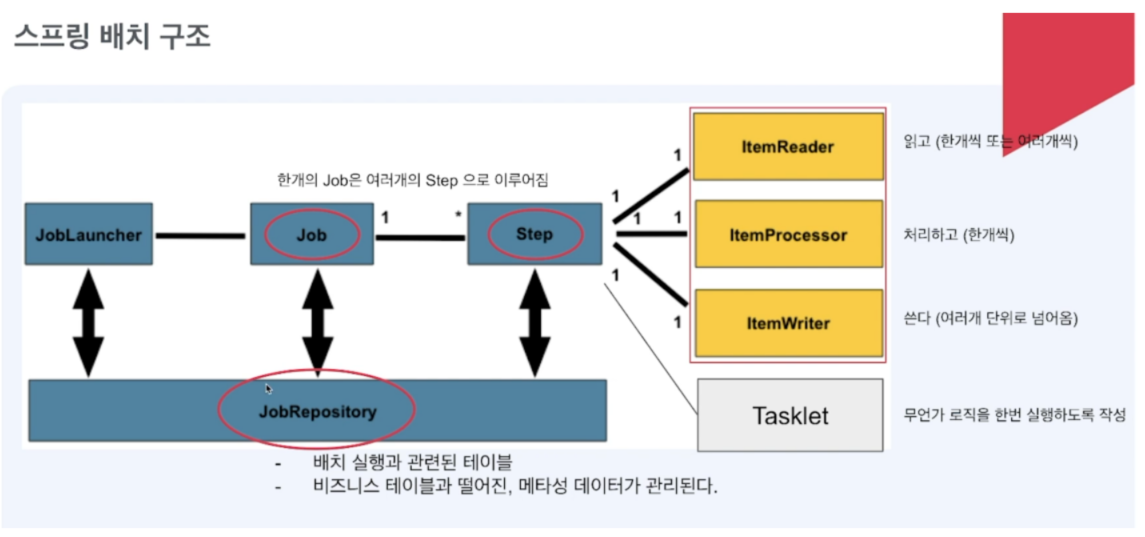
SpringBatch의 Step(Tasklet, Chunk)들은 아래 그림대로 과정을 거칩니다.
-
ItemReader: 단순하게 아이템 하나를 읽는 Strategy이다.
배치 어플리케이션은 데이터를 읽는 것으로 시작,
다양한 DataSource(꼭 db을 말하는 것은 아님!)로부터 데이터를 읽을 수 있는 수 있는 구현체를 잘 정의하는 게 중요하다! -
ItemProcessor: Reader로부터 받아온 Item을 가공하는 담당.
Item이 <I>타입이었다면 <O>타입으로 변경해서 넘길 수 있음.
배치 어플리케이션의핵심 비즈니스 로직이 들어가게 됨.
하지만 따로 가공할 로직이 없다면 만들지 않아도됨(Optional)
프로세서는 개발자가 직접 구현하는 영역이기 때문에 제공되는 구현체의 종류도 Reader에 비해 별로 없음. -
ItemWriter: Reader, Processor로부터 받아온 Item에 대한 마지막 처리 단계(마지막이니void) - db에 저장하거나, 파일로 쓰거나, 이벤트를 발행하거나 등등... 로직을 작성하면 됨.
😀 너무 어렵게 생각하지 말고, 데이터를 읽고 - 가공하여 - 쓰는 루틴을 가진다고 생각하면 됩니다!
JobLauncher와 JobParameter
-
JobLauncher:
JobLauncher는 배치 Job을 실행시키는 역할로,
Job과 Parameter를 받아서 실행하고 JobExecution를 반환합니다.
Spring Batch는 SimpleJobLauncher 라는 단일 JobLauncher 만 제공합니다. 배치 잡이 실행되면 JobInstance가 생성됩니다. -
JobParameter: Spring Batch는 외부 혹은 내부에서 파라미터를 받아 여러 Batch 컴포넌트에서 동적으로 사용할 수 있게 지원하고 있습니다.
- 장점 - 값을 바꾸기 위해 코드를 수정하거나 재배포할 필요가 없다.
java.util.Map<String, JobParameter> 객체의 래퍼(wrapper) 객체입니다. 해당 파라미터는 변환도 가능합니다.
JobParameter를 사용하기 위해선 항상 Spring Batch 전용 Scope를 선언해야 합니다.
크게 @StepScope와 @JobScope 2가지가 있습니다
이 어노테이션들은 지연된 빈 생성(Lazy Bean Creation) 방식입니다.
// SpEL로 선언해서 사용할 수 있습니다.
@Value("#{jobParameters[파라미터명]}")관련블로그 : https://devfunny.tistory.com/476
코드 예시
@Bean
@StepScope
public JdbcPagingItemReader<User> reader(@Value("#{jobParameters['city']}") String city) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("city", city);
return new JdbcPagingItemReaderBuilder<User>()
.name("userReader")
.dataSource(dataSource)
.selectClause("id, name, city")
.fromClause("from users")
.whereClause("where city = :city") // 파라미터 동적 바인딩
.parameterValues(parameterValues)
.rowMapper(new BeanPropertyRowMapper<>(User.class))
.pageSize(100)
.build();
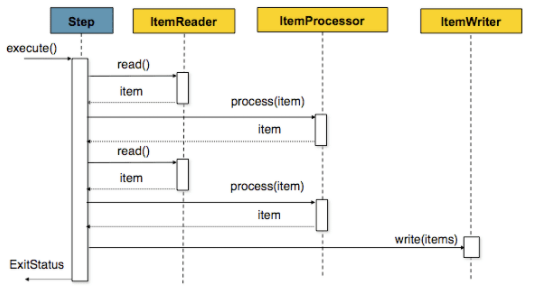
}Chunk Orientation, Batch Transaction 에 대해
스프링 배치는 Chunk 지향 처리입니다. 그리고 Chunk 단위로 트랜잭션을 다룹니다. 그래서 트랜잭션처럼 롤백도 됩니다.
- 읽어야 할 또는, 처리할 아이템이 굉장히 많을때 트랜잭션을 한번에 이어가는 것 보다
일정 주기로 여러번 실행하는 것이 안정적이다.
안정적?
- Fault Tolerant (장애 허용)
- 실패 시 다양한 처리(
ex.rollback)를 할 수 있게 해준다.
https://docs.spring.io/spring-batch/docs/current/reference/html/step.html#chunkOrientedProcessing
Page Size와 Chunk Size
Spring Batch에서 일반적으로 Reader로 PagingItemReader를 많이들 사용합니다.
일반적으로 Page Size와 Chunk Size 는 서로 비슷해보이지만 서로 다른 의미입니다.
Chunk Size: 한번에 처리될 트랜잭션 단위Page Size: 한번에 조회할 Item의 양
ItemReader에서 Read가 이루어지는 경우에 doReadPage(); 코드가 실행됩니다.
Read는 Page Size 단위로 이루어지며 쿼리 실행시 Page의 Size를 지정하기 위한 용도입니다
Chunk는 Item이 처리되는 단위이며 이 때문에 Chunk Size와 Page Size가 다를 경우 불필요한 Read가 발생할 수 있습니다.
Step을 만들 때 지정하는 Chunk 갯수만큼의 인자를 받게 되는 것을 잊으면 안됩니다.
// 예시
Paging Reader의 page_size = 10, Chunk = 100 이라면
Reader가 10번 Page Read를 하고,
Processor 100번 처리할 때마다
Writer를 실행한다.✅ 즉 Chunk Size와 Page Size를 일치 시키는게 보편적으로 좋은 방법입니다
JPA에서의 영속성 컨텍스트가 깨지는 문제도 있을 수 있다고 합니다
관련 블로그 : https://jojoldu.tistory.com/146
Curosr와 Paging에 따른 구현 방식
Cursor 기반 ItemReader 구현체
- JdbcCursorItemReader
- HibernateCursorItemReader
- StoredProcedureItemReader
Paging 기반 ItemReader 구현체
- JdbcPagingItemReader
- HibernatePagingItemReader
- JpaPagingItemReader
구현 예시
@Slf4j
@RequiredArgsConstructor
@Configuration
public class AllReadJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
private final DataSource dataSource;
private static final int CHUNK_SIZE = 4;
private static final int FETCH_SIZE = 4;
@Bean
public Job allReadJob(
Step allReadStep
) {
return jobBuilderFactory.get("allReadJob")
.start(allReadStep)
.build();
}
@Bean
public Step allReadStep(
ItemReader<Schedule> allReadPagingReader,
ItemWriter<Schedule> allReadWriter
) {
return stepBuilderFactory.get("allReadStep")
.<Schedule, Schedule>chunk(CHUNK_SIZE)
.reader(allReadPagingReader)
.writer(allReadWriter)
.allowStartIfComplete(true)
.build();
}
// Cursor 기반 ItemReader 구현체
@Bean
public JdbcCursorItemReader<Schedule> allReadReader() {
return new JdbcCursorItemReaderBuilder<Schedule>()
.verifyCursorPosition(false)
.fetchSize(FETCH_SIZE)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Schedule.class))
.sql("select * from schedules order by id")
.name("jdbcCursorItemReader")
.build();
}
// Paging 기반 ItemReader 구현체
@Bean
public JdbcPagingItemReader<Schedule> allReadPagingReader(
PagingQueryProvider queryProvider) {
return new JdbcPagingItemReaderBuilder<Schedule>()
.pageSize(CHUNK_SIZE)
.fetchSize(FETCH_SIZE)
.dataSource(dataSource)
.rowMapper(new BeanPropertyRowMapper<>(Schedule.class))
.queryProvider(queryProvider)
.name("jdbcCursorItemReader")
.build();
}
@Bean
public PagingQueryProvider queryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProvider = new SqlPagingQueryProviderFactoryBean();
queryProvider.setDataSource(dataSource);
queryProvider.setSelectClause("*");
queryProvider.setFromClause("from schedules");
Map<String, Order> sortKeys = new HashMap<>(1);
sortKeys.put("id", Order.ASCENDING);
queryProvider.setSortKeys(sortKeys);
return queryProvider.getObject();
}
@Bean
public ItemWriter<Schedule> allReadWriter() {
return list -> log.info("write items.\n" +
list.stream()
.map(s -> s.toString())
.collect(Collectors.joining("\n")));
}
}코드 예시
설정
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-batch'
testImplementation 'org.springframework.batch:spring-batch-test'application.yml
spring:
batch:
job:
names: ${job.name:NONE}
jdbc:
initialize-schema: always ## batch 메타 테이블을 생성할려면 always -> never
# main:
# web-application-type: none ## 배치가끝나고 어플리케이션도 끝남.MainApplication.java
@EnableBatchProcessing 추가
@EnableBatchProcessing
@SpringBootApplication
public class MainApplication {
public static void main(String[] args) {
SpringApplication.run(MainApplication.class, args);
}
}기본코드 예시
@Slf4j
@RequiredArgsConstructor
@Configuration
public class SimpleJobConfiguration {
private final JobBuilderFactory jobBuilderFactory; // 생성자 DI 받음
private final StepBuilderFactory stepBuilderFactory; // 생성자 DI 받음
@Bean
public Job simpleJob() { // Job
return jobBuilderFactory.get("simpleJob")
.start(simpleStep1())
.build();
}
@Bean
public Step simpleStep1() { // Step -> tasklet으로 간단하게 실행
return stepBuilderFactory.get("simpleStep1")
.tasklet((contribution, chunkContext) -> {
log.info(">>>>> This is Step1");
return RepeatStatus.FINISHED;
})
.build();
}
}Batch를 시작하는 방법
1) Run Configuration - Program arguments 설정
--spring.batch.job.names=helloJob // application.yml에 지정된 job.name이다.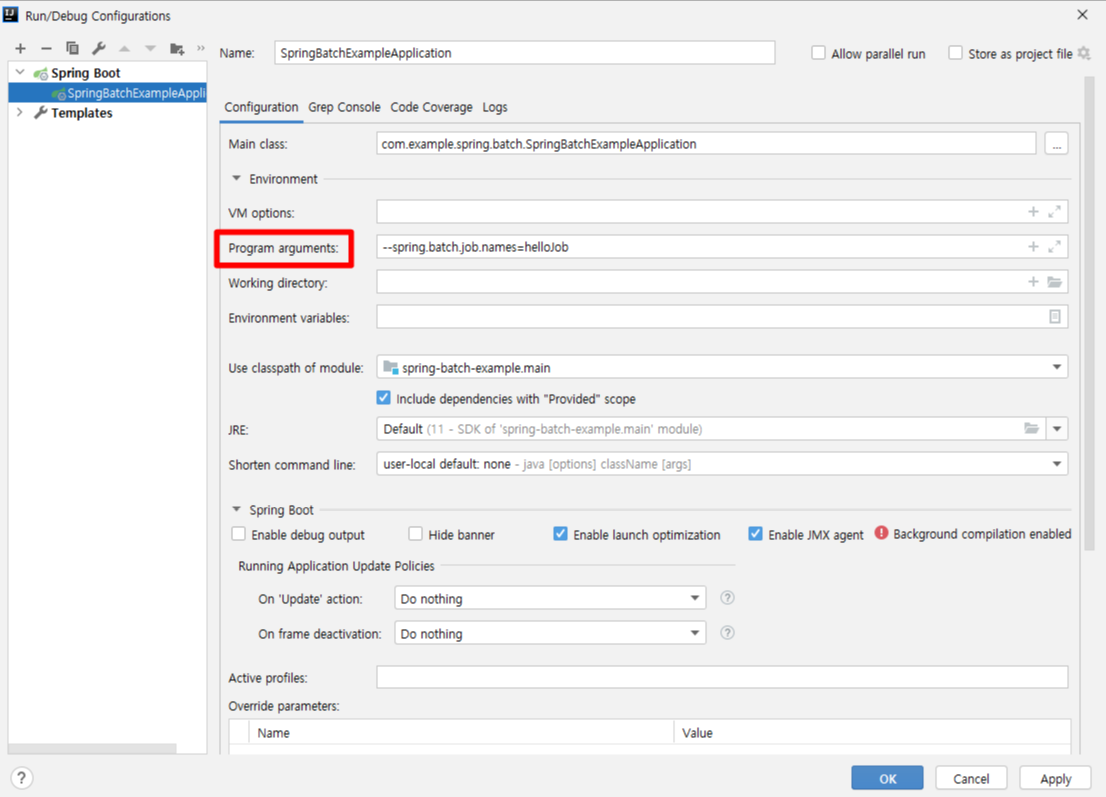
2) BatchController 설정
jobLauncher, JobParameter 기본 개념이 필요하다. 아래 예시정도면 돌아가는 것을 확인할 수 있을 것이다.
@RestController
@RequestMapping("/batch")
@RequiredArgsConstructor
public class BatchController {
private final JobLauncher jobLauncher;
private final Job notificationAlarmJob;
@GetMapping("/job")
public String startJob() throws Exception {
System.out.println("Starting the batch job");
System.out.println("job: " +notificationAlarmJob);
Map<String, JobParameter> parameters = new HashMap<>();
parameters.put("timestamp", new JobParameter(System.currentTimeMillis()));
JobExecution jobExecution = jobLauncher.run(notificationAlarmJob, new JobParameters(parameters));
return "Batch job "+ jobExecution.getStatus();
}
}테스트 작업
테스트할 JobConfig 클래스
@Configuration
@RequiredArgsConstructor
public class HelloJobConfig {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Bean("hellJob")
public Job helloJob(Step helloStep) {
return jobBuilderFactory.get("helloJob")
.incrementer(new RunIdIncrementer())
.start(helloStep)
.build();
}
@JobScope
@Bean("helloStep")
public Step helloStep(Tasklet tasklet) {
return stepBuilderFactory.get("helloStep")
.tasklet(tasklet)
.build();
}
@StepScope
@Bean
public Tasklet tasklet() {
return (contribution, chunkContext) -> {
System.out.println("Hello Spring Batch");
return RepeatStatus.FINISHED;
};
}
}
Test 작업시 필요한 cofing 파일
@Configuration
@EnableBatchProcessing
@EnableAutoConfiguration
public class BatchTestConfig {
}HelloJobConfigTest(Test 파일)
@SpringBatchTest
@SpringBootTest
@ContextConfiguration(classes = {HelloJobConfig.class, BatchTestConfig.class})
public class HelloJobConfigTest {
@Autowired
private JobLauncherTestUtils jobLauncherTestUtils;
@Test
public void success() throws Exception {
// when
JobExecution execution = jobLauncherTestUtils.launchJob();
// then
Assertions.assertEquals(execution.getExitStatus(), ExitStatus.COMPLETED);
}
}그외 학습하면 좋을 내용들
위 내용은 Spring Batch의 핵심 구조(Job, Step, Reader, Processor, Writer)와 Chunk 지향 처리의 기본기를 다룹니다.
실무에서 Spring Batch를 더 깊이 있게 다루기 위해, 블로그 내용 외에 운영 환경과 성능 최적화 관점에서 학습해두면 좋을 주제들를 정리해 보았습니다.
1. 배치의 안정성을 결정하는 '재시도(Retry)'와 '건너뛰기(Skip)'
실무에서는 외부 API 호출 실패나 일시적인 DB 락으로 인해 배치 중단이 자주 발생합니다. 이때 전체를 실패 처리하지 않고 유연하게 대응하는 설정이 중요합니다.
- Skip: 특정 예외 발생 시 해당 데이터만 건너뛰고 다음 데이터를 처리합니다. (예: 데이터 포맷 오류)
- Retry: 네트워크 순단 같은 일시적 오류 시 지정된 횟수만큼 재시도합니다.
- 주의:
Skip과Retry를 무분별하게 사용하면 데이터 정합성이 깨질 수 있으므로, 어떤 예외를 허용할지 정교하게 설계해야 합니다.
2. 성능의 핵심: 멀티 스레드 및 병렬 처리 (Scaling Out)
블로그에서 본 Chunk 처리는 기본적으로 단일 스레드에서 돌아갑니다. 데이터가 수천만 건으로 늘어나면 이를 병렬로 처리해야 합니다.
- Multi-threaded Step: 한 Step 내에서 Chunk 단위로 여러 스레드가 동시에 실행됩니다. (Reader와 Writer가 Thread-safe 해야 함)
- Parallel Steps: 서로 의존성이 없는 여러 Step을 동시에 실행합니다.
- Partitioning: 가장 강력한 기능입니다. 데이터를 범주(예: ID 범위 1~1000, 1001~2000)로 나누어 마스터-슬레이브 구조로 독립적인 작업을 수행합니다.
3. JobParameter와 중복 실행 방지
블로그 예시에서 System.currentTimeMillis()를 파라미터로 넣는 이유를 정확히 이해하는 것이 좋습니다.
- JobInstance:
Job Name+JobParameters의 조합으로 결정됩니다. - 같은 파라미터로 동일한 Job을 실행하면 Spring Batch는 "이미 성공한 작업"으로 간주하고 실행하지 않습니다.
- 실무에서는 배치 재실행 시 실패한 지점부터 다시 시작할지, 아니면 무조건 새로 시작할지에 따라 파라미터 설계(예:
run.id증가 등)를 달리합니다.
4. Zero-Inference 데이터 처리 (Idempotency, 멱등성)
배치 개발 시 가장 중요한 원칙 중 하나는 "몇 번을 실행해도 결과가 같아야 한다"는 것입니다.
- 만약 배치가 중간에 실패해서 다시 돌렸을 때, 이미 처리된 데이터가 중복으로 업데이트되거나 인서트되지 않도록 로직을 짜야 합니다.
- 이를 위해
ItemWriter에서INSERT대신UPSERT(없으면 생성, 있으면 수정)를 하거나, 처리 상태 플래그를 정확히 관리해야 합니다.
5. 배치 메타데이터 테이블의 수명 주기 관리
블로그에서 언급된 BATCH_JOB_INSTANCE, BATCH_STEP_EXECUTION 등의 테이블은 배치가 실행될 때마다 데이터가 쌓입니다.
- 수년 동안 방치하면 메타 데이터 테이블 자체의 조회 성능이 떨어져 배치 전체가 느려집니다.
- 따라서 오래된 배치 이력을 삭제하는 'Purge' 작업도 별도의 배치로 구성하거나 주기적으로 관리해줘야 합니다.
참고
