Thread란?
실행중인 프로그램을 프로세스라 부르고, 그 프로세스의 실행단위가 스레드이다.
컴퓨터 CPU core가 사실, Thread 단위로 작업을 처리한다.
그리고 프로그램이 돌아가면서 여러가지 작업을 동시에 할 수 있는 것이 스레드이다.
작업관리자창에서 프로세스에 대한 스레드를 확인할 수도 있다.
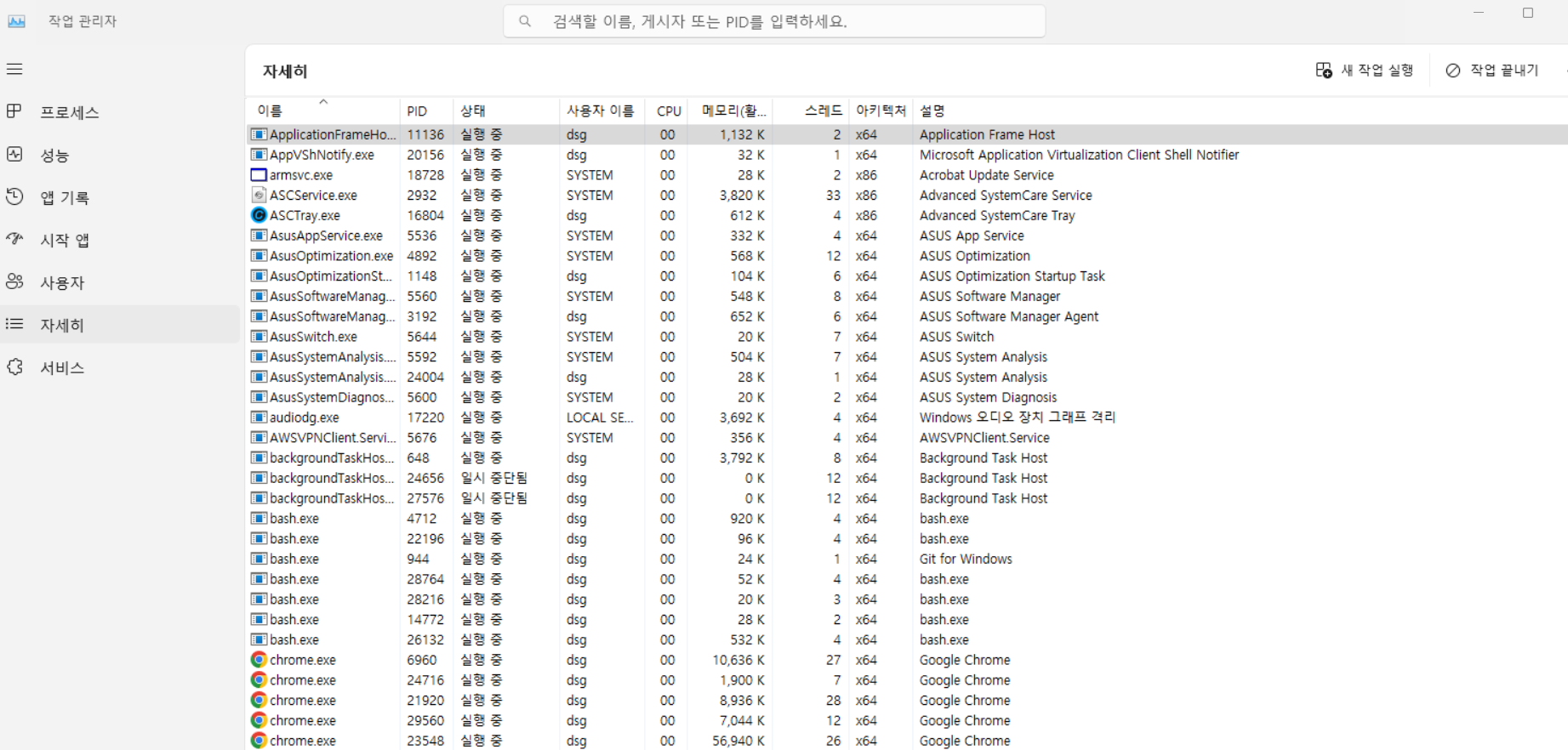
나오게 하는 방법 - 자세히 > 오른쪽 클릭 > 열선택 > 스레드 클릭 하면 나타난다.
그래서 스레드가 많아지면 프로그램 내에서 할 수 있는 것들이 많아져
스레드가 많으면 많을수록 좋은 것이 아닌가? 이렇게 생각할 수 있다.
하지만 스레드가 생성되면서 비용이 들어간다는 것을 잊으면 안된다!
컨텍스트 스위칭이 일어나 Memory Leak(메모리 누수)이 생기고 그러면서 cpu 오버헤드 비용이 든다.
즉, 스레드는 생성비용이 상당히 크다. 그러면서 요청에 대한 응답시간이 늘어날 가능성이 커지는 것이다.
그 과정을 보면,
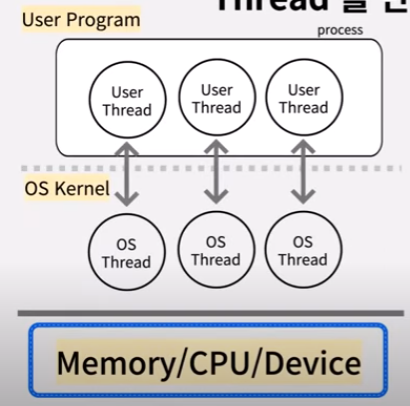
Java는 One-to-One Threading-Model로 Thread를 생성한다.
User Thread(Process의 스레드) 생성시
OS Thread(OS 레벨의 스레드) 와 연결해야 한다.
새로운 Thread를 생성할 때마다 OS Kernel의 작업이 필요하다.
그래서 Thread 생성비용이 많이 드는 것이다.
작업 요청이 들어올 때마다 Thread를 생성하면 최종적인 요청 처리 시간이 증가하는 것이다.
자, 그러니 Thread를 너무 많이 생성하면! 상당한 문제가 있다는 것을 알게 되었다.
Thread Pool이란?
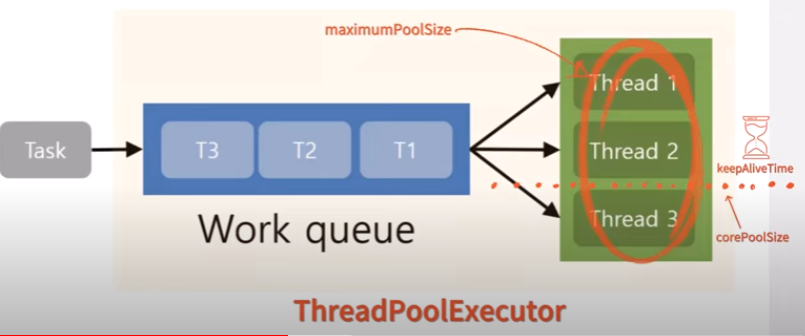
위와 같은 이유로 Thread는 생성비용이 커 너무 많이 만들어 두면 위험하다. 그래서 이를 해결하기 위한 아이디어가 Pool이다. 미리 Thread를 만들어 둔 뒤 재사용할 수 있게 하는 것이다.
쉽게 말하면, 일꾼(스레드)들을 미리 모아놓은 작업장"이라고 생각하시면 편하다.
요청이 올 때마다 일꾼을 새로 고용하는 것보다, 이미 대기하고 있는 일꾼에게 일을 맡기는 것이 훨씬 빠르다. 스레드 풀이 바로 그런 역할을 하는 것이다.
그리고 사용할 Thread 개수를 제한하기 때문에 무제한적으로 스레드가 생성되는 것을 방지하는 것도 가능하다.
자 결론,
여러개의 작업을 동시에 처리하면서도 안정적으로 처리하고 싶은 때 Thread Pool은 효과적이다.
Thread Pool을 활용한 WAS, Tomcat
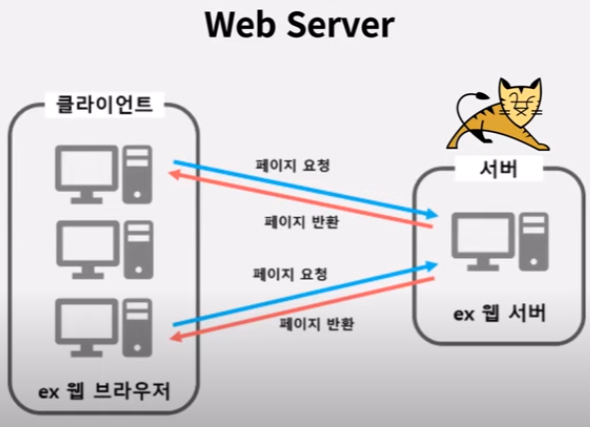
- SpringBoot 의 내장 Servelt 컨테이너 중 하나
Servelt 컨테이너의 자세한 내용은 다음 블로그를 참조 - https://velog.io/@mooh2jj/WAS는-서블릿-컨테이너 - SpringBoot 최신 버전에는 Tomcat9 버전을 사용중
- Java 기반의 WAS
- Java는 자체 스레드 풀 구현체를 가지고 있다.
그 구현한 구현체가 ThreadPoolExecutor이다.
org.apache.tomcat.util.threads.ThreadPoolExecutor
스레드풀 생성(ThreadPoolExecutor)
application.yml
server:
tomcat:
threads:
max: 200 # 생성할 수 있는 thread의 총 개수
min-spare: 10 # 항상 활성화 되어있는(idle) thread의 개수
accept-count: 100 # 작업 큐의 사이즈
1) Max-Connections
: Tomcat이 최대로 동시에 처리할 수 있는 Connection의 개수
Web 요청이 들어오면 Tomcat의 Connector가 Connection 을 생성하면서 요청된 작업을 Thread Pool의 Thread에 연결한다.
2) Accept-Count
: Max-Connections 이상의 요청이 들어왔을 때 사용하는 대기열 Queue의 사이즈
Max-Connections와 Accept-Count 이상의 요청이 들어왔을 때 추가적으로 들어오는 요청은 거절 될 수 있다.
이 두가지 설정은 스레드 최대 사이즈 및 core size 를 변경할 수 있도록 해줍니다. 톰캣 9.0의 디폴트 옵션은 각각 200개, 25개 인데 스프링부트(ServerProperties)에선 200개, 10개를 디폴트 값으로 잡았습니다.
어떻게 Tomcat 설정을 하면 어플리케이션 설계를 잘 할 수 있을까?
보통은 어플리케이션 성능 개선을 위해서는 DBCP 설정을 주로 튜닝해서 개선한다. 하지만 Thread Pool 도 개선해야 되는 상황들이 있다!
⭐Thread Pool 튜닝이 필요한 경우
- CPU바운드 작업(CPU 연산이 많은 작업) - 예: 데이터 변환, 파일 처리
- I/O 바운드 작업(네트워크 요청이 많은 작업) - 예: 외부 API 호출
- 멀티스레드 환경에서 동시성 제어가 필요한 경우
CPU 바운드 vs I/O 바운드 작업에 따른 스레드 풀 크기 결정 공식
(N_threads = N_cores * (1 + W/C))도 있으니 참고하시면 좋습니다.
참고 블로그) https://www.baeldung.com/java-thread-pool-sizing
application.yml 파일 내 설정
server:
tomcat:
threads:
max: 28 #최대 스레드 개수
min-spare: 28 #최소 액티브 상태인 스레드 개수
accept-count: 200 #스레드가 전부 사용중일 때 대기 큐에 넣을 수 있는 요청 개수-
server.tomcat.threads.max
: Thread Pool에서 사용할 최대 스레드 개수, ✅ 기본값은 200 -
server.tomcat.threads.min-spare
: Thread Pool에서 최소한으로 유지할 Thread 개수, ✅ 기본값은 10 -
server.tomcat.max-connections
: 동시에 처리할 수 있는 최대 Connection 의 개수, ✅ 기본값은 8192
: 사실상 서버의 실질적인 동시 요청처리개수라고 생각할 수 있다. -
server.tomcat.accept-count
: max-connections 이상의 요청이 들어왔을 때 사용하는 요청 대기열 Queue 의 사이즈 ✅ 기본값은 100
: 부적절한 요청들을 필터링하는 데 필요!
☘ 서버 어플리케이션의 품질은 동시에 처리할 수 있는 요청 개수와 관련있다!
잘못된 시나리오 예상
💥 잘못된 설정으로 생겨날 수 있는 시나리오는 2가지이다.
1) 요청수에 비해 너무 많게 설정 -> 놀고 있는 스레드가 많아져 메모리,cpu 자원 비효율 증대
2) 너무 적게 설정 -> 동시 처리 요청수가 줄어든다. 평균응답시간, TPS 감소
- Non-Blocking IO에서는 최대 Thread 개수보다 적거나 같은 수의 connections을 설정하면 비효율적인 설정이 될 수 있다. (tomcat8 이후 버전에서는 Non-blocking IO이며, N Connection-1Thread)
💡 DBCP 튜닝도 고려
✅ DB 조회 속도를 개선하려면 DBCP 튜닝이 더 효과적이에요.
✅ Thread Pool은 애플리케이션 내부의 작업을 최적화하는 데 사용하는 것이 좋아요.
✅ DB 서버의 부하를 고려하면서 DBCP와 Thread Pool을 함께 조정하면 최적의 성능을 얻을 수 있어요!
실제 튜닝하는 과정이 궁금하다면!, 다음 블로그 참고하면 좋을 것 같다.
https://velog.io/@blackarea/부하테스트와-Thread-Pool-DBCP설정
Spring 비동기 처리 AsyncConfig
⭐ AsyncConfig는 스프링 프레임워크내에서 비동기 처리를 위해 스스레드풀을 만드는 방법이 있다.
@EnableAsync 를 사용하여 빈으로 등록하는 방식이 다음과 같다.
@Configuration
@EnableAsync
public class AsyncConfig {
/**
* spring에서 관리하는 스레드 풀을 생성하는 메서드
* @return 스레드 풀을 생성하는 TaskExecutor
* ⭐Spring 관리 생명주기로 종료 시 자동 정리
*/
@Bean
public TaskExecutor taskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2); // 기본적으로 항상 유지되는 코어 스레드 수 (2개)
executor.setMaxPoolSize(5); // 최대 생성 가능한 스레드 수 (5개)
executor.setQueueCapacity(25); // 대기 큐 용량 (25개 작업까지 대기 가능)
executor.setKeepAliveSeconds(60); // 유휴 스레드 60초 후 제거
executor.setThreadNamePrefix("async-"); // 스레드 이름에 "async-"" prefix 추가로 디버깅 용이성 증가
executor.initialize();
return executor;
}
@Bean(name = "excelTaskExecutor")
public TaskExecutor excelTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2); // Excel 처리용 코어 스레드 수
executor.setMaxPoolSize(5); // Excel 처리용 최대 스레드 수
executor.setQueueCapacity(100); // Excel 처리 대기 큐 용량
executor.setKeepAliveSeconds(60); // 유휴 스레드 60초 후 제거
executor.setThreadNamePrefix("excel-"); // Excel 처리 스레드 식별용 prefix
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); // 거부 정책 설정 CallerRunsPolicy는 작업이 거부되면 현재 스레드가 해당 작업을 실행하도록 함
executor.initialize();
return executor;
}
} 작성한 코드의 설정 값들을 하나씩 뜯어보겠습니다.
1. setCorePoolSize(2): 코어 스레드 수
의미: "항상 유지되는 기본 일꾼의 수"입니다. 아무리 일이 없어도 이 수만큼의 일꾼들은 항상 대기하고 있습니다.
기준: 동시성(Concurrency)을 기준으로 설정합니다.
CPU 바운드 작업: 주로 계산 작업처럼 CPU를 많이 사용하는 작업입니다. 이 경우, 코어 스레드 수는 서버의 CPU 코어 수와 비슷하게 설정하는 것이 좋습니다. 만약 4코어 CPU라면 4로 설정하는 식입니다. 스레드 수가 CPU 코어 수를 초과하면, 오히려 스레드 간의 컨텍스트 스위칭(일꾼이 이 일 했다 저 일 했다 하는 전환) 때문에 성능이 저하될 수 있습니다.
I/O 바운드 작업: 데이터베이스 접근, 파일 읽기/쓰기, 외부 API 호출 등처럼 CPU를 기다리는 시간이 많은 작업입니다. 이 경우, 스레드가 I/O 작업을 기다리는 동안 다른 스레드가 CPU를 사용할 수 있으므로, CPU 코어 수보다 훨씬 크게 설정해도 괜찮습니다.
2. setMaxPoolSize(5): 최대 스레드 수
의미: "작업장이 수용할 수 있는 최대 일꾼의 수"입니다. 일이 많아지면 코어 스레드 수 이상으로 일꾼을 임시로 고용할 수 있지만, 이 수를 초과할 수는 없습니다.
기준: 예상되는 최대 부하와 시스템의 메모리를 고려하여 설정합니다.
스레드 하나가 생성될 때마다 일정량의 메모리(스택 메모리 등)를 사용합니다. maxPoolSize를 너무 크게 설정하면, 급작스러운 부하 시 수백 개의 스레드가 생성되어 서버의 메모리를 모두 점유하고 OOM(Out of Memory) 오류를 일으킬 수 있습니다.
corePoolSize와 maxPoolSize의 차이가 크면, 급격한 부하 증가에 유연하게 대처할 수 있지만, 메모리 사용량도 함께 증가한다는 점을 명심해야 합니다.
3. setQueueCapacity(25): 대기 큐 용량
의미: "일꾼이 모두 바쁠 때, 작업을 대기시킬 수 있는 줄의 길이"입니다. 새로운 요청이 들어왔는데 모든 일꾼이 바쁘면, 이 줄에 서서 기다리게 됩니다.
기준: 예상되는 요청의 평균 수와 시스템의 안정성을 고려하여 설정합니다.
큐가 꽉 차면, 새로운 요청은 거절(Rejected)됩니다.
대기 큐가 너무 크면, 오래 대기하는 요청이 발생할 수 있습니다. 예를 들어, 큐 용량이 1,000이고 처리 시간이 긴 작업이 많다면, 나중에 들어온 요청은 한참을 기다려야 합니다.
setQueueCapacity의 값은 corePoolSize, maxPoolSize와 함께 스레드 풀의 동작 방식을 결정합니다.
corePoolSize까지 스레드가 생성됩니다.
corePoolSize의 모든 스레드가 바쁘면, 작업은 큐에 쌓입니다.
큐가 가득 차면, maxPoolSize까지 스레드가 추가로 생성됩니다.
maxPoolSize에 도달하고 큐도 가득 차면, 작업은 거절됩니다.
4. setKeepAliveSeconds(60): 유휴 스레드 제거 시간
의미: "일감이 없어서 빈둥거리는 일꾼을 몇 초 후에 해고할지"를 정하는 시간입니다. corePoolSize를 초과하여 임시로 고용된 일꾼들에게만 적용됩니다.
기준: 자원 효율성과 응답 속도를 고려하여 설정합니다.
이 시간이 짧으면, 임시 스레드가 빠르게 정리되어 메모리를 절약할 수 있습니다.
이 시간이 길면, 작업량이 다시 증가했을 때 빠르게 대처할 수 있어 응답 속도가 빨라집니다.
5. setThreadNamePrefix("async-"): 스레드 이름 접두사
의미: "스레드 이름 앞에 붙는 별명"입니다. 예를 들어 "async-1", "async-2"처럼 이름이 붙습니다.
기준: 디버깅의 용이성을 위해 설정합니다.
로그나 스레드 덤프를 확인할 때, 어떤 스레드가 어떤 작업을 처리하는지 한눈에 파악할 수 있어 문제를 해결하는 데 큰 도움이 됩니다.
6. setRejectedExecutionHandler(...): 작업 거절 시 처리 정책
의미: "모든 일꾼이 바쁘고 대기 줄도 꽉 찼을 때, 새로 들어온 작업을 어떻게 처리할지"를 정하는 정책입니다.
기준: 애플리케이션의 중요도와 안정성을 고려하여 선택합니다.
ThreadPoolExecutor.AbortPolicy: 기본값입니다. 작업을 거절하고 RejectedExecutionException 예외를 발생시킵니다. (작업을 버리는 정책)
ThreadPoolExecutor.CallerRunsPolicy: 작업을 요청한 스레드(호출자)가 직접 처리하게 만듭니다. 서버의 부하를 줄이면서 요청 처리를 보장합니다. excelTaskExecutor에 이 정책을 사용하신 것은 매우 좋은 판단입니다! Excel 작업은 중요하고, 거절되면 곤란하기 때문에 이 정책을 사용하면 부하가 많을 때라도 처리를 보장할 수 있습니다.
ThreadPoolExecutor.DiscardPolicy: 조용히 작업을 버립니다. 예외가 발생하지 않습니다.
ThreadPoolExecutor.DiscardOldestPolicy: 대기 큐에서 가장 오래된 작업을 버리고, 새로운 작업을 큐에 넣습니다.
💡 Excel 처리용 스레드 풀에 대한 조언
excelTaskExecutor에 setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy())를 사용하신 것은 아주 훌륭합니다. 이는 "Excel 작업은 중요하므로, 스레드 풀이 너무 바쁘면 요청한 스레드(보통 HTTP 요청을 받은 메인 스레드)가 직접 처리하도록 하겠다"는 의미입니다.
이렇게 하면 서버에 순간적으로 부하가 몰릴 때, 메인 스레드가 잠깐 멈춰서 Excel 작업을 처리하게 되므로 응답 속도가 느려질 수는 있지만, 작업 유실을 막고 안정성을 보장할 수 있습니다.
📌 참고 블로그) https://mangkyu.tistory.com/425
Spring @EnableAsync 처리 방식
Spring 프레임워크에서 @EnableAsync 로 스레드풀을 만들고 비동기 처리를 하는 두 가지 방식이 있다.
- 옵션1 : 옵션 1: @Async 어노테이션 추가 (권장)
@Async("excelTaskExecutor") // excelTaskExecutor 빈을 사용하도록 명시
public CompletableFuture<ExcelUploadResultDTO> processExcelAsync(List<ProductDTO.Request> dtoList) {
ExcelUploadResultDTO result = excelService.registerBatch(dtoList, null, null);
return CompletableFuture.completedFuture(result);
}옵션 2: CompletableFuture.supplyAsync() 사용 (명시적 비동기)
public CompletableFuture<ExcelUploadResultDTO> processExcelAsync(List<ProductDTO.Request> dtoList) {
return CompletableFuture.supplyAsync(() -> {
return excelService.registerBatch(dtoList, null, null);
}, excelTaskExecutor);
}두 가지 방식 중 어떤 것을 사용하든 비동기 처리는 가능하지만, 일반적으로 Spring의 @Async를 사용하는 것이 코드가 더 간결하고 Spring의 관리 기능을 더 잘 활용할 수 있습니다.
참고

좋은 글 감사합니다 늘 잘보고있습니다 :)