
웹사이트에 정보를 긁어모아 정보를 축출하는 방법은 크롤링(Crawling)이라고 합니다.
전에 Python의 셀레니움을 사용하여 크롤링을 한 적이 있었는데
Java에도 크롤링 셀레니움 라이브러리가 있다는 것을 최근에 알게 되었습니다.
이커머스 회사 사이트에 상품 정보를 긁어모아 자바 스프링부트에 적용한 내용을 정리합니다.
셀레니움 크롤링 라이브러리란?
Selenium은 웹 브라우저를 자동으로 제어하여 웹 페이지에서 데이터를 추출하는 데 사용되는 크롤링 라이브러리입니다. 실제 사용자처럼 브라우저를 조작하여 로그인, 클릭, 스크롤 등의 동작을 수행하고, 원하는 데이터를 선택적으로 추출할 수 있습니다.
✳️ 핵심 기능:
- 웹 브라우저 제어: WebDriver API를 통해 Chrome, Firefox, Edge 등 다양한 브라우저를 자동으로 제어합니다.
- 자동화된 웹 상호 작용: 로그인, 클릭, 스크롤, 입력 등 실제 사용자의 행동을 자동으로 시뮬레이션합니다.
- 데이터 추출: HTML, CSS, JavaScript를 사용하여 원하는 데이터를 선택적으로 추출합니다.
- 다양한 프로그래밍 언어 지원: Java, Python, C#, JavaScript 등 다양한 프로그래밍 언어에서 사용할 수 있습니다.
jsoup vs selenuim
동적 페이지는 셀레니움 라이브러리를 사용해야합니다!
현재 요청한 페이지가 동적페이지 라면, jscoup가 아닌, Selenium 을 사용함!
참고) jsoup vs selenuim
https://heodolf.tistory.com/104
jsoup 예제
- maven 라이브러리
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.17.2</version>
</dependency>
- 실행코드
public class JsoupTest {
public static void main(String[] args) {
String url = "https://sum.su.or.kr:8888/bible/today?base_de=2023-03-23";
try {
Document document = Jsoup.connect(url).get();
Element bibleText = document.getElementById("bible_text");
Element bibleInfoBox = document.getElementById("bibleinfo_box");
System.out.println("bibleText: " + bibleText.text());
System.out.println("bibleInfoBox: " + bibleInfoBox.text());
System.out.println();
// num과 info를 포함하는 요소 찾기
Elements numElements = document.select(".num");
Elements infoElements = document.select(".info");
// num과 info를 포함하는 요소 출력
for (int i =0; i < numElements.size(); i++) {
System.out.println(numElements.get(i).text() + ": " + infoElements.get(i).text());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
동적 페이지 확인은?
브라우저 네트워크 탭에서 정적 페이지 가져와 <- **첫번쩨 페이지에서 Response, Preview 탭에서 확인할 수 있습니다!
현재 사이트에서 보이지 않는 데이터가 있으면 동적인 것을 바로 확인할 있는 단서로는 (javascript를 통한, or iframe을 통한 다른 url 경로가 있을시)가 가장 확실합니다.
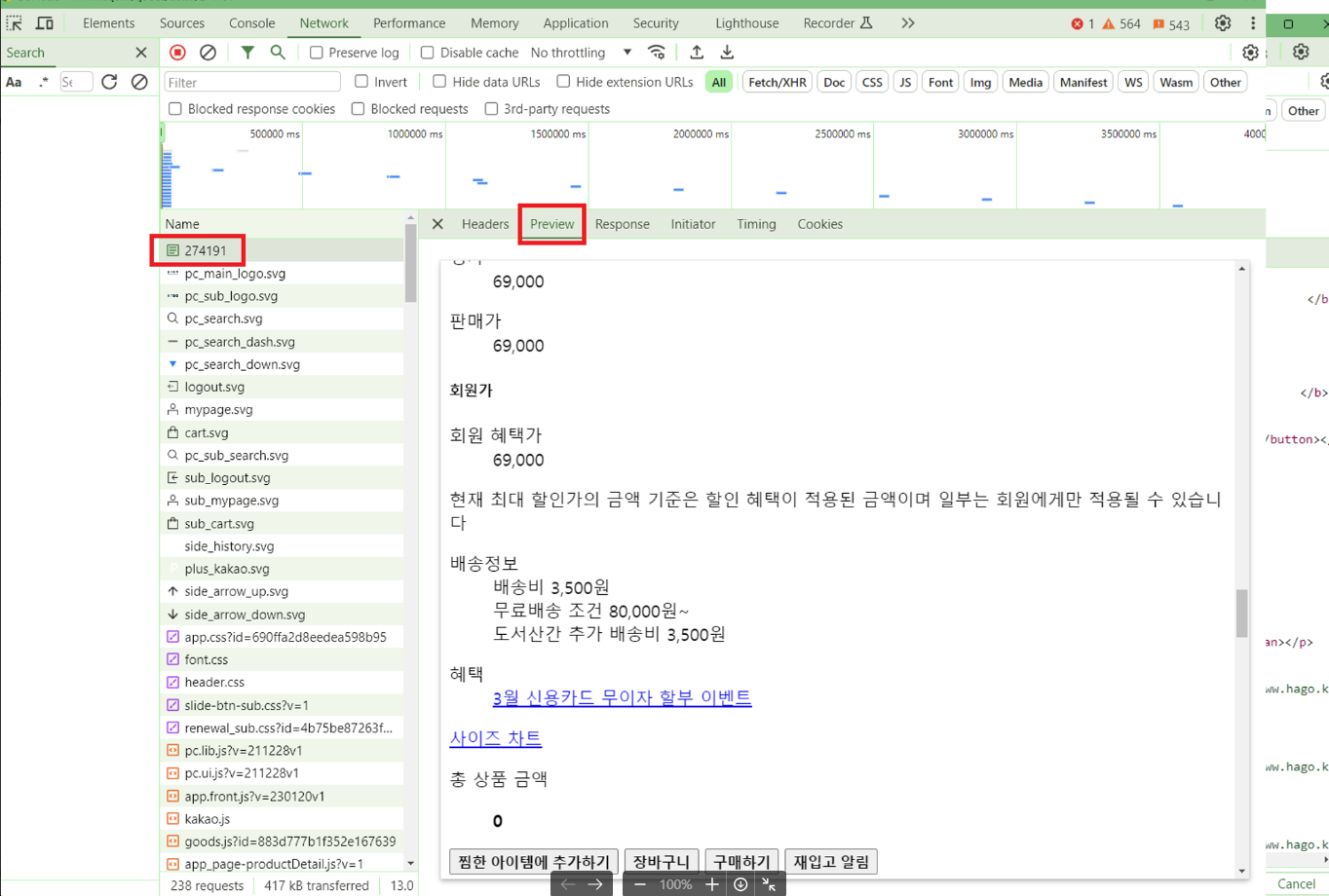
이럴 때는 데이터를 동적으로 가져오는 자체 함수가 있는 셀리니움같은 라이브러리를 사용해야 합니다!
셀레니움 동작
- build.gradle
// selenium
implementation group: 'org.seleniumhq.selenium', name: 'selenium-java', version: '3.141.59'✳️ 셀레니움 4.10 버전 이후 chrom Driver 자동설치가 가능해졌습니다! 아래 ❗ chrome Driver 설치 방법은 쓰지 마세요!
implementation 'org.seleniumhq.selenium:selenium-java:4.10.0'chrome Driver 설치 (개발시, 사용자 사용시 같은 버전이어야)
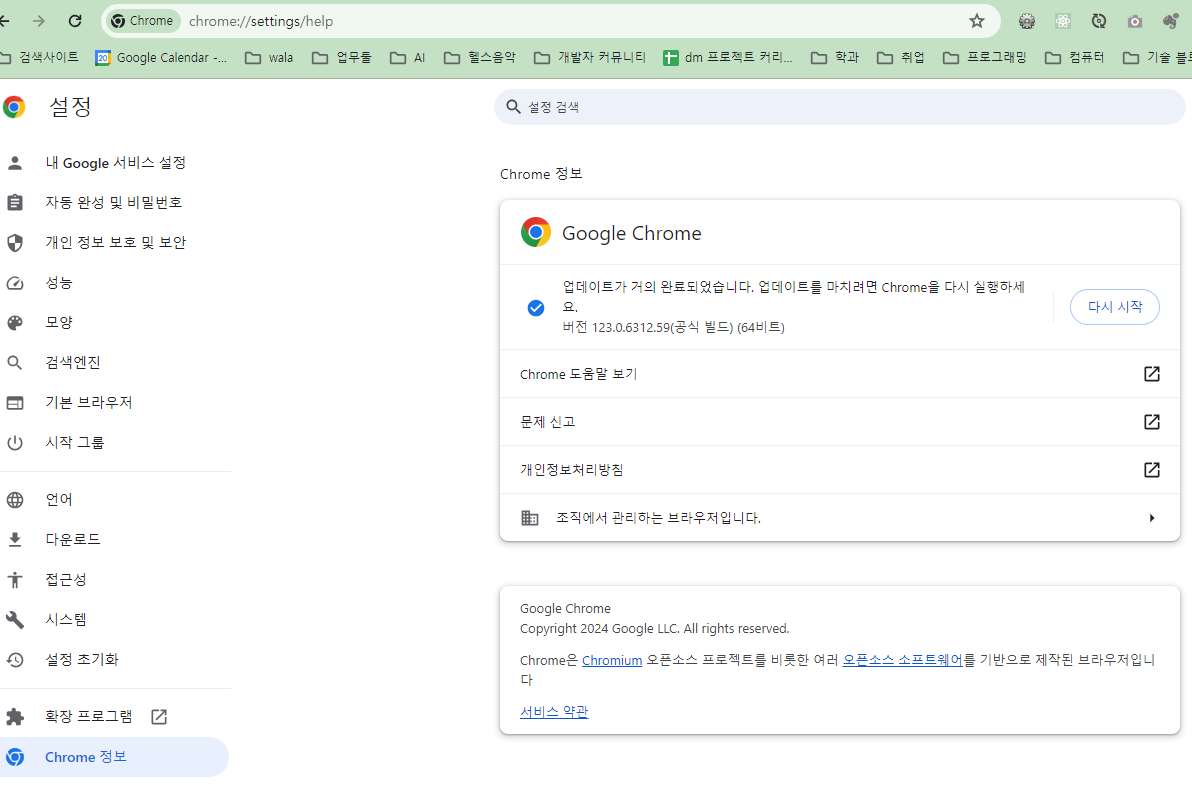
로컬에서 chrome x64 122 버전 식으로, 크롬 버전과 크롬 드라이버 버전이 매칭되게 연동해야 합니다.
✅ 앞자리 수만 같으면 됩니다! ex.122.0.5672.63 → 122로 버전 맞춤
- chrome 버전 확인 → [설정] → [크롬 버전정보] → 업데이트 가능
✅ OS별, 버전별 chromeDriver 설치 페이지
https://googlechromelabs.github.io/chrome-for-testing/#stable
개발시, chromeDriver 설치경로, 테스트시 chromedriver.exe 파일이 필요합니다!

패키지
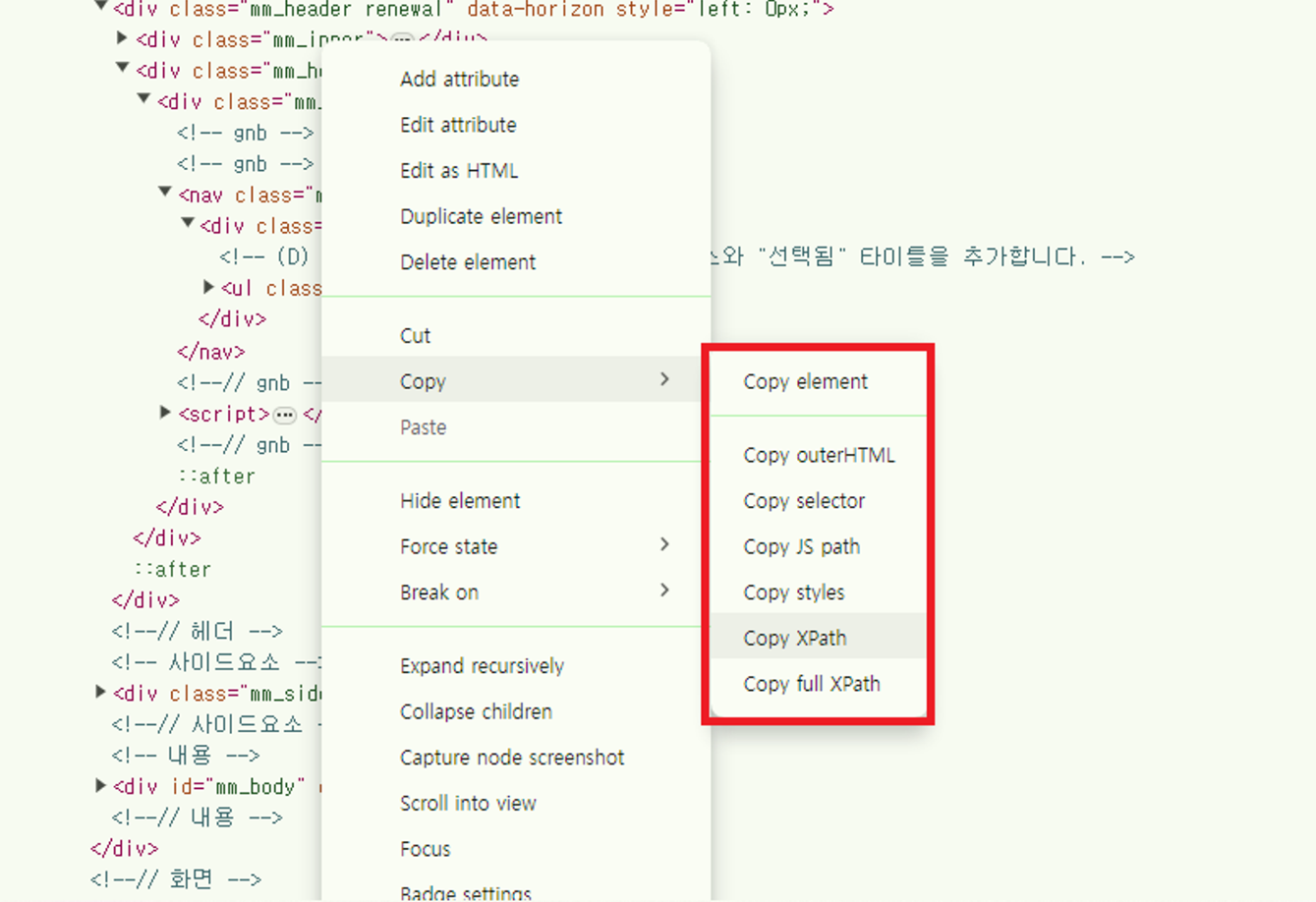
html element 요소 찾기(Xapth)
ex. F12 → ctrl + F → 상세정보 에 맞는 값 찾기
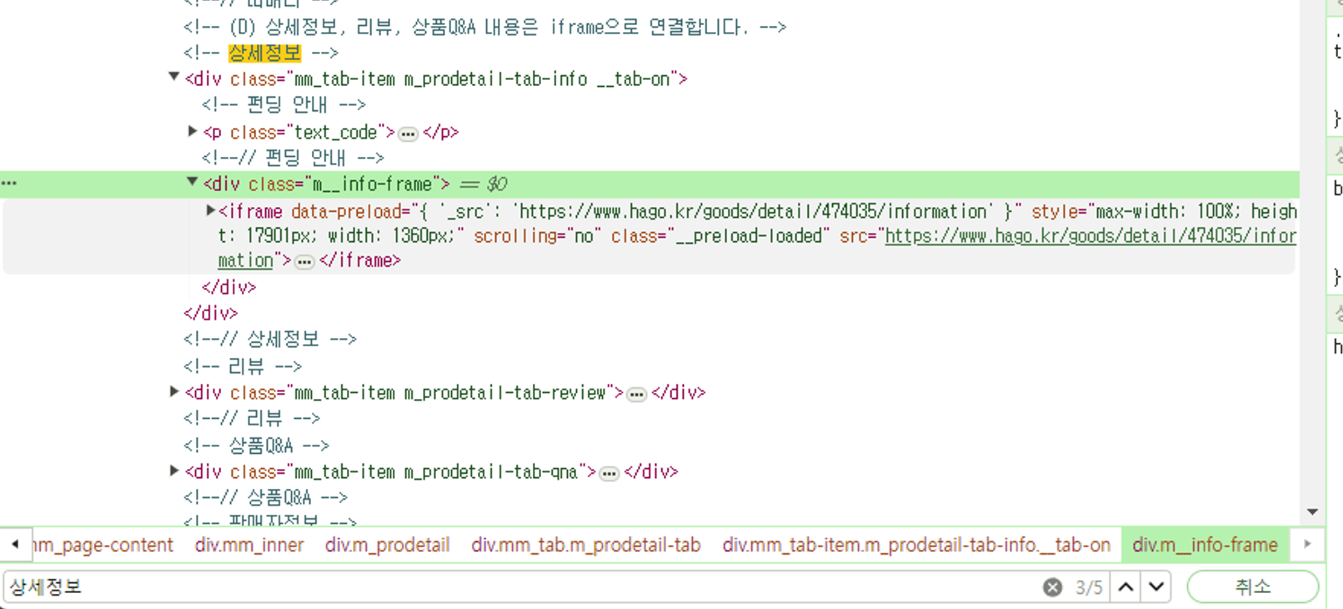
그중 식별이 무조건 되는 Xpath 요소를 복사해서 사용하였습니다.
배포시에는?
AWS EC2서버에서 배포시에도 신경쓰게 많았습니다. chrome, chrome driver를 설치해야 합니다.
운영시 설치경로는

Downloads 폴더 위치 (cd ~ 로 이동)
-
EC2 에 chrome, chrome 드라이버 설치는
- 버전 확인→ 아마존 서버 fedora(redHat) 확인 후 드라이버 위 설치경로 확인한 다음,
-
설치 명령어
Amazon Linux에서 chrome & chromeDriver 설치
wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
sudo yum install ./google-chrome-stable_current_x86_64.rpm
google-chrome --version
# https://googlechromelabs.github.io/chrome-for-testing/#stable 페이지 버전으로
wget -N https://storage.googleapis.com/chrome-for-testing-public/122.0.6261.128/linux64/chromedriver-linux64.zip -P ~/Downloads
unzip ~/Downloads/chromedriver_linux64.zip
# 성공적으로 chromedirver을 설치!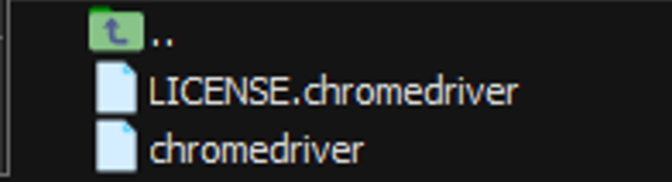
참고)
https://js990317.tistory.com/16
💡 크롤링 차단 예방책
크롤링시, 해당 사이트에서 자동화한 크롤링 봇을 감지해서 차단시킬 수 있습니다.
완전히 방어하는 것은 불가능합니다. 하지만 예방책으로 자동적으로 봇이 아닌 사람처럼 수집하는 것처럼 보이게 하여 robot 탐지 방지에서는 예방할 수 있는 방법은 있습니다.
- 수집하는 시간대를 랜덤으로
/**
* 랜덤 시간만큼 대기
*/
public static void timeSleep(int time1, int time2) {
Random random = new Random();
int randomTime = random.nextInt(time2 - time1 + 1) + time1; // time1부터 time2까지의 랜덤 시간 생성
try {
Thread.sleep(randomTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}- 챗봇 설정 중 봇이 아니게 options 설정
ChromeOptions options = new ChromeOptions();
...
options.addArguments("--disable-blink-features=AutomationControlled"); // 봇으로 인식되지 않도록 설정
// user-agent 설정
options.addArguments("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3");
options.addArguments("Accept-Language\", \"en-US,en;q=0.5"); // 브라우저처럼 요청 헤더 설정
options.addArguments("Accept-Encoding\", \"gzip, deflate, br");
// 프록시로 IP주소 변경
Proxy proxy = new Proxy();
proxy.setHttpProxy("myhttpproxy:3337");
options.setProxy(proxy);
-
headless 지양
일반 브라우저처럼 사용하도록 -
robots.txt 준수
주소/robots.txt 를 브라우저에 치면 크롤링 가능, 불가능한 페이지를 확인 수 있습니다.
크롤링 코드 개선
1) 싱글톤으로 만들기
애플리케이션이 시작될 때 어떤 클래스가 최초 한번만 메모리를 할당하고(Static) 그 메모리에 인스턴스를 만들어 사용하는 디자인패턴을 싱글톤 패턴이라고 합니다.
크롬 드라이버는 한번 생성시, 많은 CPU 사용량과 Memory를 소비합니다. 그래서 한번 할당한 인스턴스로 재사용하는 패턴으로 싱글톤 패턴을 사용하였습니다.
💥 주의점 재사용을 하는데 Thread-safe하기 위해 싱글톤 패턴에는 반드시 synchronized 예약서를 붙여주어야 합니다!
/**
* 크롤링을 통해 상품 정보 추출
*
* @param url 크롤링할 url
* @return 상품 정보
*/
// 동시 크롤링을 막기 위해 synchronized 사용
@TimeTrace
@MemoryUsage
@CPUUsage
public synchronized ProductCrawlingInfoDto getProductInfoByCrawling(String url) {
if (StringUtils.isEmpty(url)) {
throw new CommonException(CRAWLING_URL_EMPTY_CODE, "크롤링 URL이 빈값입니다.");
}
String productStatus = getProductStatus(url);
if (productStatus.equals("품절")) {
throw new CommonException(CRAWLING_SOLD_OUT_ERROR_CODE, "상품이 품절 상태입니다.");
}
if(productStatus.equals("구매불가")) {
throw new CommonException(CRAWLING_SALE_STOPPED_ERROR_CODE, "상품이 구매불가 상태입니다.");
}
try {
return crawlProductInfo(url);
} catch (Exception e) {
log.error("Crawling task failed: {}", e.getMessage());
}
return ProductCrawlingInfoDto.builder().build();
}2) 드라이버 리소스 close 주의점
- 크롬드라이버라는 리소스를 계속 메모리에 상주하지 않기 위해(메모리 릭 방지)
닫아주는 코드가 꼭 필요합니다. 크롬드라이버에서는 실제 닫게 할려면 close() 가 아닌, quit() 메서드를 사용하여야 합니다.
- 행여나
try-with-resources문은 쓰지 말자.
셀레니움 Chrome driver 객체 에 있는 close 메서드 와 중복이 되기에 메서드를 바꾸지 않는 한 에러가 일어난다!
try-catch-finally 로 처리하자!
참고 - https://hello70825.tistory.com/541
ChromeDriverProvider
@Slf4j
public class ChromeDriverProvider {
public static final String WEB_DRIVER_ID = "webdriver.chrome.driver";
public static final String LOCAL_WEB_DRIVER_PATH = "src/main/resources/chromedriver.exe";
public static final String PROD_WEB_DRIVER_PATH = "Downloads/chromedriver-linux64/chromedriver";
private static ChromeDriver instance;
private ChromeDriverProvider() {
// private constructor
}
// 싱글톤 패턴으로 ChromeDriver 객체를 생성
public static synchronized ChromeDriver getChromeDriver() {
if (instance == null || instance.getSessionId() == null) {
instance = createChromeDriver();
}
return instance;
}
/**
* 크롤링을 통해 필요한 크롬 드라이버 객체를 생성한다.
*
* @return 크롬 드라이버 객체
*/
private static ChromeDriver createChromeDriver() {
ChromeDriver driver = null;
try {
Path path = null;
// 1. WebDriver 경로 설정
String osName = System.getProperty("os.name").toLowerCase();
if (osName.contains("nix") || osName.contains("nux") || osName.contains("aix")) {
// 운영 배포서버일시
path = Paths.get(PROD_WEB_DRIVER_PATH);
} else {
// 로컬
path = Paths.get(System.getProperty("user.dir"), LOCAL_WEB_DRIVER_PATH);
}
// 2. WebDriver 경로 설정
System.setProperty(WEB_DRIVER_ID, path.toString());
// 3. WebDriver 옵션 설정
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless"); // Browser를 띄우지 않음
options.addArguments("--disable-gpu"); // GPU를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--no-sandbox"); // Sandbox 프로세스를 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--disable-dev-shm-usage"); // /dev/shm 사용하지 않음, Linux에서 headless를 사용하는 경우 필요함.
options.addArguments("--disable-blink-features=AutomationControlled"); // 봇으로 인식되지 않도록 설정
// 4. WebDriver 객체 생성
driver = new ChromeDriver(options);
log.info("ChromeDriver 객체 생성 완료");
} catch (Exception e) {
log.error("ChromeDriver 객체 생성 Error....{}", e.getMessage());
}
return driver;
}
/**
* 크롬 드라이버 객체를 종료한다.
*/
public static synchronized void quitChromeDriver() {
if (instance != null) {
instance.quit();
instance = null;
}
log.info("ChromeDriver 객체 종료");
}
}