전에 간단하게 Process vs Thread 차이를 정리해보았었다.
여기선 멀티프로세스 vs 멀티쓰레드 서술 형태로 이 둘의 차이를 명료하게 풀어볼려고 한다.
멀티 프로세스 예시
멀티 프로세스는 하나의 작업을 여러 개의 독립적인 프로세스로 나누어 동시에 실행하는 방식입니다. 각 프로세스는 자신만의 메모리 공간을 가지므로, 하나의 프로세스에 문제가 발생해도 다른 프로세스에는 영향을 주지 않아 안정성이 높습니다.
예시: 웹 브라우저
대부분의 최신 웹 브라우저는 멀티 프로세스 구조를 사용합니다.
브라우저 프로세스: 주소 표시줄, 북마크, 확장 프로그램 관리 등 브라우저의 전체적인 UI와 기능을 담당합니다.
렌더러 프로세스: 각 웹 페이지를 표시하는 역할을 합니다. 여러 개의 탭을 열면 각 탭마다 별도의 렌더러 프로세스가 실행됩니다. 특정 웹 페이지의 JavaScript 오류나 과도한 리소스 사용으로 인해 하나의 렌더러 프로세스가 멈추더라도, 다른 탭이나 브라우저 자체는 계속 정상적으로 작동합니다.
플러그인 프로세스: Flash, PDF 뷰어 등과 같은 플러그인을 실행하는 프로세스입니다.
GPU 프로세스: 그래픽 처리 작업을 담당하여 웹 페이지 렌더링 성능을 향상시킵니다.
각각의 탭이나 플러그인이 별도의 프로세스로 실행되기 때문에, 하나의 웹 페이지가 응답하지 않더라도 전체 브라우저가 멈추는 현상을 줄일 수 있습니다.
멀티 스레드 예시
멀티 스레드는 하나의 프로세스 내에서 여러 개의 작은 작업 단위(스레드)를 동시에 실행하는 방식입니다. 스레드는 프로세스의 메모리 공간을 공유하므로, 프로세스 간 통신보다 효율적으로 데이터를 공유할 수 있습니다.
예시: 워드 프로세서 (예: Microsoft Word, Google Docs)
워드 프로세서를 사용하는 동안 여러 가지 작업을 동시에 수행할 수 있습니다.
편집 스레드: 사용자가 키보드로 글자를 입력하거나 마우스로 내용을 수정하는 작업을 처리합니다.
맞춤법 검사 스레드: 백그라운드에서 입력된 내용의 맞춤법을 자동으로 검사하고 오류를 표시합니다.
자동 저장 스레드: 주기적으로 현재 작업 내용을 자동으로 저장하여 데이터 손실을 방지합니다.
인쇄 스레드: 사용자가 인쇄 명령을 내리면 별도의 스레드가 인쇄 작업을 처리하는 동안에도 사용자는 계속해서 문서를 편집할 수 있습니다.
이러한 여러 스레드가 하나의 워드 프로세서 프로그램 내에서 동시에 실행되기 때문에, 사용자는 여러 작업을 기다림 없이 동시에 수행할 수 있어 효율성을 높일 수 있습니다. 예를 들어, 맞춤법 검사가 진행되는 동안에도 계속해서 글을 입력할 수 있습니다.
컨텍스트 스위칭
멀티프로세스는
프로세스마다 완전히 독립된 메모리 공간을 유지하기때문에 프로세스 사이에서 메시지를 주고받아야하는 경우에는 그만큼 구현의 어려움을 겪기도 한다. 즉, 멀티프로세스 기반의 단점은 다음과 같다.
"프로세스 생성이라는 부담스러운 작업과정을 거친다"
"두 프로세스 사이에서의 데이터 교환을 위해서는 별도의 IPC 기법을 적용해야한다"
하지만 이 둘 단점보다 더 큰 단점이 있으니..
바로,
"초당 적게는 수십 번에서 많게는 수천 번까지 일어나는 '컨텍스트 스위칭(Context Switching)'에 따른 부담이다"
컨텍스트 스위칭은 왜 일어나는 걸까?
CPU가(정확히말해서 CPU의 연산장치인 CORE가) 하나뿐인 시스템에서도 둘 이상의 프로세스가 동시에 실행된다.
이는 실행중인 둘 이상의 프로세스들이 CPU의 할당시간을 매우 작은 크기로 쪼개서 서로 나누기 때문에(시분할 시스템, 멀티 태스킹) 가능한일이다. 그런데 CPU의 할당시간을 나누기 위해서는 '컨텍스트 스위칭'이라는 과정을 거쳐야 한다.
더 자세히 설명해보면,
프로그램의 실행을 위해서는 해당 프로세스의 정보가 메인 메모리에 올라와야 한다.
(폰노이만 구조)
때문에 현재 실행중인 A 프로세스의 뒤를 이어서 B 프로세스를 실행시키려면 A 프로세스 관련 데이터를 메인 메모리에서 내리고 B 프로세스 관련 데이터를 메인 메모리로 이동시켜야 한다.
바로 이것이 컨텍스트 스위칭이다. 그런데 이때 A 프로세스 관련 데이터는 하드디스크로 이동하기 때문에(스왑, swap) 컨텍스트 스위칭에는 오랜 시간이 걸리고, 빨리 진행하더라고 한계가 있다.
쓰레드 등장배경
결국 멀티 프로세스의 특징을 유지하면서 단점을 어느 정도 극복하기 위해서 등장한 것이 바로,
'쓰레드(Thread)'이다.
이는 멀티프로세스의 여러 가지의 단점을 최소화하기 위해서, 설계된 일종의 '경량화 된(가벼워진) 프로세스'이다.
쓰레드는 프로세스와 비교해서 다음의 장점을 가진다.
쓰레드의 생성 및 컨텍스트 스위칭은 프로세스의 생성 및 컨텍스트 스위칭보다 빠르다.
쓰레드 사이에서의 데이터 교환에는 특별한 기법이 필요치 않다.
즉, 쓰레드와 프로세스의 차이점
쓰레드는 다음과 같은 고민에 의해 등장하였다.
"둘 이상의 실행 흐름을 갖기위해 프로세스가 유지하고 있는 메모리 영역을 통째로 복사하는 것이 부담스럽다!"
스레드의 컨텍스트 스위칭
그렇다고, 스레드의 컨텍스트 스위칭 비용이 안드는 것은 아니다.
다음 스레드의 컨텍스트 스위칭 과정을 살펴보자.
CPU 코어는 하나만 있다고 가정하자.
스레드A, 스레드B가 있다.
운영체제는 먼저 스레드A를 실행한다. 멀티태스킹을 해야 하기 때문에 스레드A를 계속 실행할 수 없다. 스레드A를 잠시 멈추고, 스레드B를 실행한다. 이후에 스레드A로 그냥 돌아갈 수 없다. CPU에서 스레드를 실행하는데, 스레드A의 코드가 어디까지 수행되었는지 위치를 찾아야 한다. 그리고 계산하던 변수들의 값을 CPU에 다시 불러들여야 한다. 따라서 스레드A를 멈추는 시점에 CPU에서 사용하던 이런 값들을 메모리에 저장해두어야 한다.
그리고 이후에 스레드A
를 다시 실행할 때 이 값들을 CPU에 다시 불러와야 한다.
스레드의 컨텍스트 스위칭 과정에서 이전에 실행 중인 값을 메모리에 잠깐 저장하고, 이후에 다시 실행하는 시점에 저장한 값을 CPU에 다시 불러와야 한다.
결과적으로 스레드라도 멀티태스킹의 과정에서도 컨텍스트 스위칭 과정의 약간의 비용이 발생한다.
메모리 구조 차이
프로세스의 메모리 구조는 전역변수가 할당하는 '데이터(Method) 영역', malloc 함수 등에 의해 동적 할당이 이뤄지는 '힙(Heap)' 그리고 함수의 실행에 사용되는 '스택(Stack)'으로 이뤄진다.
그런데 프로세스들은 이를 완전히 별도로 유지한다.
때문에 프로세스 사이에서는 다음의 메모리 구조를 보인다.
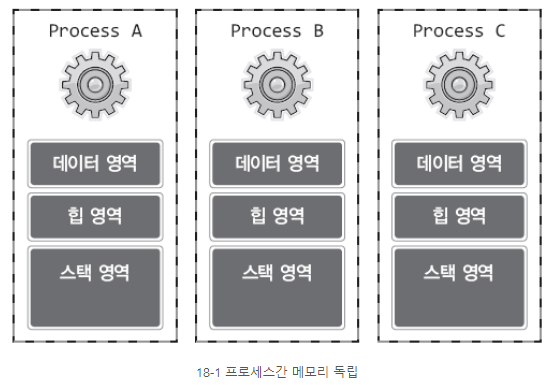
그런데 쓰레드는 다르다!
아래 쓰레드 메모리구조를 보자.
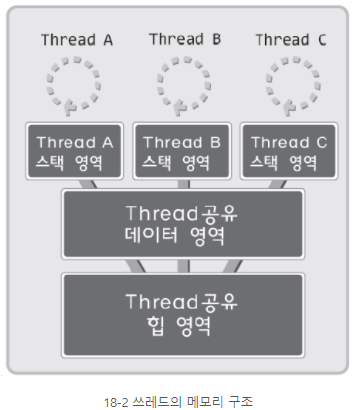
이 그림처럼 쓰레드는 별도의 실행흐름을 유지하되 스택영역만 독립적 유지한다.
그리고 쓰레드는 프로세스 내에서 생성 및 실행되는 구조다.
즉, 프로세스와 쓰레드는 다음과 같이 정의할 수 있다.
- 프로세스 : 운영체제 관점에서 별도의 실행흐름을 구성하는 단위
- 쓰레드 : 프로세스 관점에서 별도의 실행흐름을 구성하는 단위
그림으로 보면서 이해해보면 쉽다.
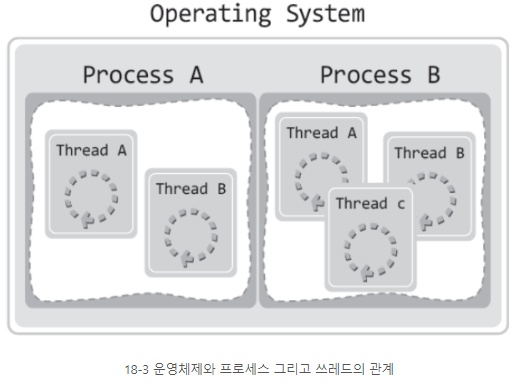
쓰레드의 실행 흐름
POSIX란 Portable Operating System Inerface for Computer Environment의 약자로써 UNIX 계열 운영체제간에 이식성을 높이기 위한 표준 API 규격을 뜻한다. 그리고 쓰레드의 생성방법은 POSIX에 정의된 표준을 근거로 한다. 때문에 리눅스 뿐만아니라 유닉스 계열의 운영체제에서도 대부분 적용 가능하다.
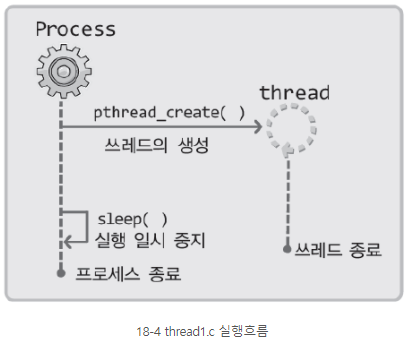
쓰레드는 별도의 실행흐름을 갖기 때문에 쓰레드만의 main 함수를 별도로 정의해야한다. 그리고 이 함수를 시작으로 별도의 실행흐름을 형성해 줄 것을 운영체제에게 요청해야 하는데, 이를 목적을 호출하는 함수(시스템콜)라고 한다.
멀티쓰레드의 활용
바로 서버소켓이다.
자바 프로그램은 클라이언트와 통신하기 위한 스레드를 생성할 수 있으며, 서버는 스레드를 이용하여 곧 들어올 다음 연결을 처리할 준비를 할 수 있다. 스레드는 독립적인 자식 프로세스를 생성하는 것보다 컨텍스트 스위칭이 적어 서버에 훨씬 적은 부하를 주기 때문이다.
사실 일반적인 유닉스 FTP 서버가 속도의 저하 없이 동시에 400 연결 이상을 처리할 수 없는 가장 큰 이유가 많은 프로세스를 생헝할 때 발생하는 부하 때문이다.
반면에 프로토콜이 단순하고 빠르며 대화가 끝날 때 서버가 연결을 종료하는 것(stateless통신, Http통신)이 허용된다면, 클라이언트의 요청마다 스레드를 생성하지 않고 즉시 처리하는 것이 서버에게는 더욱 효과적이다.
실제 쓰레드 구현
운영체제는 특정 포트를 향해 들어오는 연결 요청을 FIFO(fisrt-in, first-out) 큐에 저장한다.
자바는 기본적으로 이 큐의 길이를 50으로 설정하지만, 운영체제마다 다를 수 있다.
큐의 길이가 부족할 경우 큐의 길이를 변경할 수 는 있지만 운영체제가 지원하는 최대 길이 이상으로 큐를 증가시킬 수는 없다. 큐 길이에 관계없이 각 연결을 처리하는 데 상당한 시간이 걸리는 경우에도, 새로운 연결이 들어오는 속도보다 빠르게 큐를 비우고 싶을 것이다.
이 문제를 해결하기 위해서는 큐에 추가되는 새로운 연결을 수용하는 스레드와 분리된 별도의 스레드를 각 연결마다 할당하는 것이다.
아래의 예제는 각각의 연결을 처리하기 위해 새로운 스레드를 생성하는 daytime 서버이다. 이 서버는 하나의 느린 클라이언트가 다른 모든 클라이언트를 블로킹시키지 못하도록한다. 이것이 바로 연결마다 스레드를 할당하는 설계 방법이다.
package network;
import java.io.*;
import java.net.*;
import java.util.Date;
public class T53MultithreadedDaytimeServer {
public final static int PORT = 13;
public static void main(String[] args) {
try(ServerSocket server = new ServerSocket(PORT )){
while(true){
try{
Socket connection = server.accept();
Thread task = new DaytimeThread(connection);
task.start();
}catch(IOException e){}
}
}catch(IOException e){
System.err.println("스타트 서버에 연결할 수 없습니다.");
}
}
private static class DaytimeThread extends Thread{
private Socket connection;
DaytimeThread(Socket connection){
this.connection=connection;
}
public void run(){
try{
Writer out = new OutputStreamWriter(connection.getOutputStream());
Date now = new Date();
out.write(now.toString() + "\r\n");
out.flush();
}catch(IOException e){
System.err.println(e);
}finally{
try{
connection.close();
}catch(IOException e){}
}
}
}
}
리팩토링
위 예제는 동시 다발적인 연결 요청이 무수히 들어올 경우 (디도스 공격 등..) 무한정 스레드를 생성하게 되어, 결국 JVM이 메모리 부족으로 비정상 종료된다.
더 나은 접근 방법은 잠재적인 리소스 사용량을 제한하기 위해 고정된 스레드 풀을 사용하는 것이다.
스레드는 50개 정도면 충분할 것이며, 아래 예제는 다발적인 연결 시도에도 결코 장애가 발생하지 않는다. 다만 연결을 거부하기 시작한다.
package network;
import java.io.*;
import java.net.*;
import java.util.*;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class T54PooledDaytimeServer {
public final static int PORT = 13;
public static void main(String[] args) {
ExecutorService pool = Executors.newFixedThreadPool(50);
try(ServerSocket server = new ServerSocket(PORT )){
while(true){
try{
Socket connection = server.accept();
Callable<Void> task = new DaytimeTask(connection);
pool.submit(task);
}catch(IOException e){}
}
}catch(IOException e){
System.err.println("스타트 서버에 연결할 수 없습니다.");
}
}
private static class DaytimeTask implements Callable<Void> {
private Socket connection;
DaytimeTask(Socket connection) {
this.connection= connection;
}
public Void call(){
try{
Writer out = new OutputStreamWriter(connection.getOutputStream());
Date now = new Date();
out.write(now.toString() + "\r\n");
out.flush();
}catch(IOException e){
System.err.println(e);
}finally{
try{
connection.close();
}catch(IOException e){}
}
return null;
}
}
}
두 예제의 유일한 차이점은 Thread 서브클래스 대신 Callable을 사용했다는 것이다. 그리고 스레드를 직접 생성하지 않고, Callable 객체를 50개의 스레드로 미리 설정된 ExecutorService에 제출한다.
출처: andjjip님 블로그
출처: https://cbts.tistory.com/147 [IT일기장]
