
동시성 제어가 필요한 상황
동시성 제어를 자바로 해결하는 방식, RDBMS(MySQL), Redis로 해결하는 방식들을 블로그에 작성해봅니다.
동시성 제어를 표현할 코드로 JPA를 이용한 기술로 예제를 만들어 보겠습니다.
재고(stock) 엔티티가 있고 그것을 감소(decrease)시키는 예제입니다.
Stock
@Getter
@Entity
@ToString
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Stock {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private Long quantity;
public Stock(Long productId, Long quantity) {
this.productId = productId;
this.quantity = quantity;
}
public void decrease(Long quantity) { // 재고 감소 메서드
if (this.quantity - quantity < 0) {
throw new RuntimeException("지정한 quantity 초과하였습니다!");
}
this.quantity = this.quantity - quantity;
}
}Test Code를 작성합니다.
재고감소를 하는 요청입니다.
이 테스트에서는 정상적으로 처리가 됩니다. 하지만 동시다발적으로 요청이 온다면 어떻게 될까요?
기본 decrease
@Test
@DisplayName("재고감소 테스트")
public void stock_decrease() {
log.info("stock: {}", stock);
stockService.decrease(1L, 1L);
Stock findStock = stockRepository.findById(1L).orElseThrow();
// 100 - 1 = 99
assertThat(findStock.getQuantity()).isEqualTo(99);
}똑같이 재고감소를 하는 요청을 비동기적으로 처리(동시다발적으로 처리)해보겠습니다. 이 방식은 java 8부터 도입된 Executors 객체를 사용해보겠습니다.
@Test
@DisplayName("동시에_100개_요청")
public void stock_concurrent_request() throws InterruptedException {
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
stockService.decrease(1L, 1L); // StockService decrease sychronized 를 해도 실패
} finally {
latch.countDown();
}
});
}
latch.await(); // 다른 스레드 마칠때까지 대기
Stock findStock = stockRepository.findById(1L).orElseThrow();
log.info("findStock: {}", findStock);
// 100 - (1 * 100) = 0
assertThat(findStock.getQuantity()).isEqualTo(0L);
}동시성 제어 방법
Java synchronized
@Transactional
public synchronized void decrease(Long id, Long quantity) {
// get stock
// decrease: 재고감소
// 저장
Stock stock = stockRepository.findById(id)
.orElseThrow(() -> new RuntimeException("찾는 stock이 없습니다!"));
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
Java synchronized 문제점
서버가 1대일때는 되는듯싶으나 여러대의 서버를 사용하게되면 똑같이 race Condition이 일어나 둘 이상의 스레드가 데이터를 공유하는 문제가 발생한다.
인스턴스단위로 thread-safe가 보장이 되고, 여러서버가 그렇게 될려면, 하나의 스레드만 데이터에 접근할 수 있게 보장해주는 방식을 사용해야 한다.
RDBMS의 Lock 처리(JPA)
특히, 동시성 요청은 여러 스레드들이 공유 데이터들에 접근할 때 생긱는 것인데, 그 대표적인 공유 데이터가 RDBMS의 데이터 내용들이다. 그래서 동시성 해결의 RDBMS 처리방식이 가장 대중적이다.
1) Optimistic Lock
lock 을 걸지않고 문제가 발생할 때 처리합니다.
대표적으로 version column을 만들어서 해결하는 방법이 있습니다.
호출이 적을 때, 그리고 수정이 빈번히 일어나지 않을 때 사용.(update 쿼리가 부가적으로 생기기므로)
로그 -> version 수가 update되는 것을 확인할 수 있다!
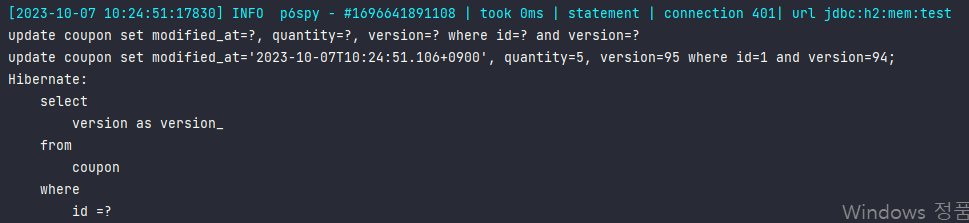
💥 주의사항
@Transactional 처리는 x 하면 무한루프 걸림
낙관적 락은 비관적 락보단 성능이 좋다. 하지만 개발자가 version 처리등 할게 좀 있기 때문에 간단한 경우에만 진행하면 좋은 방식이다.
OptimisticLockStockFacade
@Service
@RequiredArgsConstructor
public class OptimisticLockStockFacade {
final private OptimisticLockService optimisticLockService;
public void decrease(Long id, Long quantity) throws InterruptedException {
while (true) {
try {
optimisticLockService.decrease(id, quantity);
break;
} catch (Exception e) {
Thread.sleep(50);
}
}
}
}OptimisticLockService
@Service
@RequiredArgsConstructor
public class OptimisticLockService {
private final StockRepository stockRepository;
@Transactional
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findByIdWithOptimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}StockRepository
@Lock(value = LockModeType.OPTIMISTIC)
@Query("select s from Stock s where s.id= :id")
Stock findByIdWithOptimisticLock(@Param("id") Long id);Stock
// Stock 엔티티에 필드 추가
@Version
private Long version;2) Pessimistic Lock (exclusive lock)
다른 트랜잭션이 특정 row 의 lock 을 얻는것을 방지합니다.
A 트랜잭션이 끝날때까지 기다렸다가 B 트랜잭션이 lock 을 획득합니다.
특정 row를 update하거나 delete 할 수 있습니다.
일반 select 는 별다른 lock 이 없기때문에 조회는 가능합니다.
수정이 빈번히 많을 때는 optimistic lock보다는 pessimistic lock을 많이 사용합니다.
StockRepository
public interface StockRepository extends JpaRepository<Stock, Long> {
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id = :id")
Stock findByIdWithPessimisticLock(@Param("id") Long id);
}decrease
@Transactional
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findByIdWithPessimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}3) named Lock 활용하기
이름과 함께 lock 을획득합니다. 해당 lock 은 다른세션에서 획득 및 해제가 불가능합니다. 분산락(distributed lock)으로 많이 사용된다.
Redis로 동시성 제어
docker pull redis
docker run --name myredis -d -p 6379:6379 redis1) Lettuce
구현이 간단하다
spring data redis 를 이용하면 lettuce 가 기본이기때문에 별도의 라이브러리를 사용하지 않아도 된다.
spin lock 방식이기때문에 동시에 많은 스레드가 lock 획득 대기 상태라면 redis 에 부하가 갈 수 있다.
2) Redisson
락 획득 재시도를 기본으로 제공한다.
pub-sub 방식으로 구현이 되어있기 때문에 lettuce 와 비교했을 때 redis 에 부하가 덜 간다.
별도의 라이브러리를 사용해야한다.
lock 을 라이브러리 차원에서 제공해주기 떄문에 사용법을 공부해야 한다.
3) 실무에서는 ?
재시도가 필요하지 않은 lock 은 lettuce 활용
재시도가 필요한 경우에는 redisson 를 활용
Redis 분산 락의 장점
1단계: 분산 락이 필요한 이유
기존 문제점:
- 다중 서버 환경에서 동시 요청 처리 시 데이터 무결성 위험
- 파일 업로드와 DB 저장의 원자성 보장 필요
- 같은 사용자의 중복 요청 방지 필요2단계: Redis 분산 락의 핵심 장점
1. 다중 서버 환경 지원
// 일반 synchronized (단일 JVM 내에서만 동작)
synchronized (this) {
// 서버 A에서만 락이 걸림, 서버 B는 동시 실행 가능 → 문제 발생
}
// Redis 분산 락 (모든 서버에서 공유)
RLock lock = redissonClient.getLock("project:create:user:" + email);
// 서버 A, B, C 모두에서 같은 락을 공유 → 진정한 동시성 제어2. 자동 만료 기능 (Deadlock 방지)
// 기존 방식의 위험성
synchronized (lockObject) {
// 서버 장애 시 락이 영원히 해제되지 않음
}
// Redis 분산 락의 안전성
boolean acquired = lock.tryLock(LOCK_WAIT_TIME, LOCK_LEASE_TIME, TimeUnit.SECONDS);
// LOCK_LEASE_TIME(30초) 후 자동으로 락 해제 → Deadlock 방지3. 논블로킹 락 시도
// 블로킹 방식 (응답성 저하)
synchronized (this) {
// 무한 대기 가능
}
// 논블로킹 방식 (사용자 경험 향상)
boolean acquired = lock.tryLock(10, 30, TimeUnit.SECONDS);
if (!acquired) {
// 즉시 사용자에게 피드백 제공
throw new RuntimeException("다른 프로젝트 생성이 진행 중입니다.");
}3단계: 코드 구현의 장점
메모리 효율성
// 사용자별 락 키 생성으로 세밀한 제어
String lockKey = "project:create:user:" + email;
// 사용자 A와 사용자 B는 독립적으로 프로젝트 생성 가능
// 불필요한 대기 시간 최소화안전한 락 해제
finally {
// 현재 스레드가 보유한 락만 해제 (안전성 보장)
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}4단계: 다른 방식과의 비교
| 방식 | 장점 | 단점 |
|---|---|---|
| synchronized | 구현 간단 | 단일 JVM만 지원, Deadlock 위험 |
| DB 락 | 데이터 일관성 보장 | 성능 저하, DB 부하 증가 |
| Redis 분산 락 | 다중 서버 지원, 자동 만료, 높은 성능 | Redis 의존성, 네트워크 지연 |
5단계: 실제 효과
파일 업로드 시나리오에서의 이점
@Transactional
protected ProjectUploadResult executeProjectCreation(ProjectCreateRequest request, String email) {
// 1. DB 저장과 파일 업로드가 하나의 트랜잭션으로 처리
// 2. 중간에 실패 시 모든 작업 롤백
// 3. 동시 요청으로 인한 데이터 중복 방지
return projectService.createProject(request, email);
}결론
Redis 분산 락이 좋은 이유:
- 확장성: 마이크로서비스, 로드밸런싱 환경에서 진정한 동시성 제어
- 안정성: 자동 만료로 Deadlock 방지, 서버 장애 시에도 안전
- 성능: 메모리 기반으로 빠른 락 획득/해제
- 세밀한 제어: 사용자별, 기능별 독립적인 락 관리
- 사용자 경험: 즉시 피드백으로 대기 시간 최소화
특히 파일 업로드와 같이 시간이 오래 걸리는 작업에서는 분산 락의 효과가 극대화됩니다.
참고
- 강의) 인프런
<재고시스템으로 알아보는 동시성이슈 해결방법> - 소스) https://github.com/sangyongchoi/stock-example
