유기 동물의 데이터가 필요하여 Python을 사용하여 웹 페이지에서 데이터 크롤링을 하게되었다.
데이터베이스 구축과 python 코드 작성은 통합 개발환경 서비스인 구름 IDE에서 수행하였다.
https://ide.goorm.io/
크롤링을 시작하기 앞서 다음과 같은 패키지를 설치하였다.
1. requests
pip install requests
http의 request를 다루기 위한 패키지이다.
2. Beautiful Soup
pip install BeautifulSoup4
html, xml을 파싱할 때 사용할 패키지이다.
3. mysqlclient
pip install mysqlclient
크롤링 한 데이터를 데이터베이스에 저장하기위한 패키지이다.
필요한 패키지를 모두 설치하였으니 코드를 작성하도록 한다.
import MySQLdb
import requests
from bs4 import BeautifulSoup
conn = MySQLdb.connect(
user="사용자 ID",
passwd="사용자 PW",
host="DB 주소",
db="사용할 DB 이름",
charset="utf8",
use_unicode=True
)
cursor = conn.cursor()
cursor.execute("set names utf8")
url = "크롤링 할 사이트 주소"크롤링 한 데이터를 저장할 데이터베이스를 연결해준다.
https://www.animal.go.kr/front/awtis/protection/protectionList.do?totalCount=5653&pageSize=10&menuNo=1000000060&&page=1#moreBtn 에서 데이터를 크롤링 해왔다.
한글로 된 크롤링 데이터를 바로 데이터베이스에 저장하고자 하니 오류 문구가 출력되었었다.
해당 오류를 아래의 코드로 해결하였다.
cursor.execute("set names utf8")
def crawl(startPage, endPage):
n = 1
for i in range(startPage, endPage):
url_ = url + str(i+1)
webpage = requests.get(url_)
soup = BeautifulSoup(webpage.content, "html.parser")
dataList = soup.find_all(attrs={'class':'txt'})
imgList = soup.find_all(attrs={'class':'thumbnail'})
for img in imgList:
print(n)
imgUrl = "https://www.animal.go.kr/" + img.find('a')['href']
imgname = 'img' + str(n) + '.jpg'
print(imgname)
with urlopen(imgUrl) as f:
with open('./images/'+imgname, 'wb') as h:
i = f.read()
h.write(i)
n += 1
crawlList = []
for data in dataList:
data1 = data.find_all('dd')
crawlList = []
for d in data1:
crawlList.append(d.string)
print(crawlList[1], crawlList[2], crawlList[3], crawlList[4])
sql = "INSERT INTO CrawlData VALUES(NULL, %s, NULL, %s, %s, %s, NULL, NULL)"
val = (crawlList[1], crawlList[2], crawlList[3], crawlList[4])
cursor.execute(sql, val)
conn.commit()
conn.close()위의 코드는 웹 페이지에서 데이터를 크롤링 한 뒤, 데이터베이스에 데이터를 저장한다.
1페이지, 2페이지, ...., n페이지 창을 넘기며 데이터를 모으기 위해 아래와 같은 반복문을 사용하였다.
for i in range(startPage, endPage):
startPage=1, endPage=5라면 1페이지부터 5페이지까지를 차례로 넘기며 데이터를 크롤링하게 된다.
webpage = requests.get(url_)
soup = BeautifulSoup(webpage.content, "html.parser")requests.get() 메소드를 통해 html을 얻은 후, BeautifulSoup을 사용하여 parsing 객체 soup를 생성한다.
dataList = soup.find_all(attrs={'class':'txt'})
imgList = soup.find_all(attrs={'class':'thumbnail'})유기 동물 발견 날짜, 품종, 성별 등의 텍스트 정보는 dataList에 유기 동물의 사진은 imgList에 저장하였다.
for img in imgList:
반복문을 통해 images 폴더 내에 유기 동물의 이미지를 하나씩 저장한다.
for data in dataList:
data1 = data.find_all('dd')
crawlList = []
for d in data1:
crawlList.append(d.string)
print(crawlList[1], crawlList[2], crawlList[3], crawlList[4])
sql = "INSERT INTO CrawlData VALUES(NULL, %s, NULL, %s, %s, %s, NULL, NULL)"
val = (crawlList[1], crawlList[2], crawlList[3], crawlList[4])
cursor.execute(sql, val)
conn.commit()유기 동물의 텍스트 정보를 하나씩 순회하며, crawlList에 담은 다음, 데이터베이스의 테이블 안에 crawlList 내용을 INSERT 한다.
crawl() 함수의 동작이 완료되면, 크롤링 한 데이터 중 텍스트 데이터는 Database 테이블에 저장되고, 이미지 데이터는 해당 디렉터리의 /images 폴더에 저장된다.
이제 /images 폴더에 저장된 이미지 데이터를 Database 테이블에 UPDATE를 수행하도록 한다.
def updateImgToDB(min, max):
for i in range(min, max):
sql = "UPDATE CrawlData SET img=%s WHERE id=%s"
val = ("img"+str(i)+".jpg", i)
cursor.execute(sql, val)
conn.commit()
conn.close()
UPDATE 쿼리문을 사용하여 데이터베이스의 img 열에 이미지 경로를 업데이트하는 작업을 수행한다.
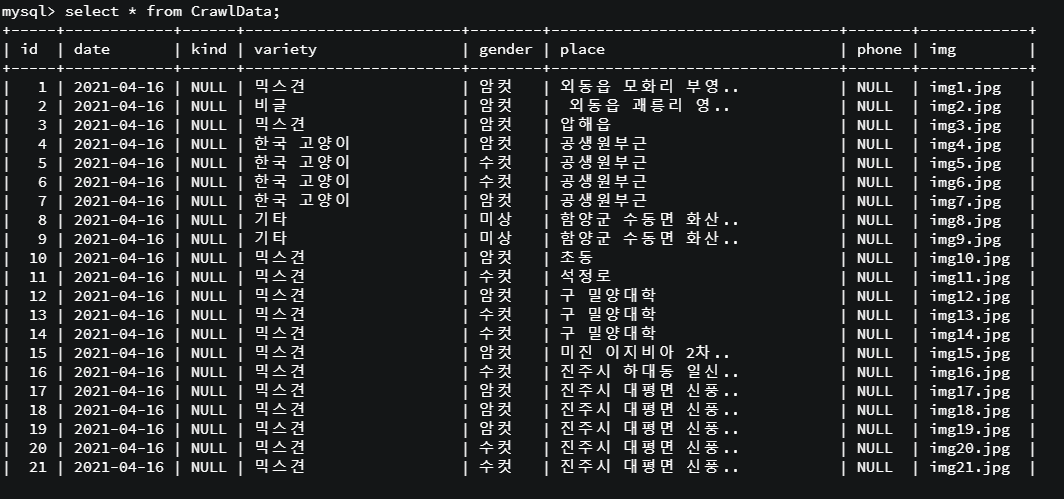
이 작업을 모두 수행한 후의 데이터베이스 테이블 상태이다.
크롤링 한 데이터가 정상적으로 저장되었음을 확인할 수 있다.