
자바의 특징
- 독립적인 운영
- JVM에서 동작하기 때문에 운영체제에 독립적
- 객체지향 프로그래밍언어(Object Oriented Programing)
- 계층 구조, 캡슐화, 상속, 추상화, 다형성 등을 구현한 객체지향언어
- 메모리를 자동으로 관리
- 가비지컬렉터를 이용해서 불필요한 메모리를 자동으로 제거
- 오픈소스
- 풍부한 라이브러리
- 멀티스레드 구현
- 고통 스레드 API를 통해서 운영체제와 관계없이 멀티스레드 구현
객체지향언어
- 추상화(Abstraction)
- 공통의 속성이나 기능을 묶어서 표현하는 방법
- 예) 동물을 대표하는 Animal Class
- 캡슐화(Encapsulation)
- 높은 응집도(동일한 클래스만 변경)와 낮은 결합도(다른 클래스 간섭 배제)를 유지하는 설계방법
- 데이터 캡슐화 : 필드와 메소드를 클래스로 묶는 방법
- 은닉화 : 외부에서 객체 상태 변경에 제한을 두는 방법(접근제어)
- 예 : Animal Class는 Human Class에서 접근 불가
- 상속(Inheritance)또는 일반화 (Generalization)
- 자식 클래스가 부모 클래스를 물려받고 확장하는 개념
- 예 : Animal Class 를 Dog Class가 상속해서 부모 클래스의 변수와 메서드를 사용
- 자식 클래스가 부모 클래스를 물려받고 확장하는 개념
- 다형성 (Polymorphism)
- 동일 요청에 대해 서로 다른 방식으로 응답할 수 있는 방법
- Overriding : 상속 받은 메소드를 재정의
- Overloading : 동일 클래스의 동일한 메소드가 매개변수의 타입이나 개수에 따라 다르게 동작
OOP의 원칙
5대 원칙으로 SOLID라고 한다
- S : 단일 책임 원칙
- SRP : Single Responsibility Principle
- 객체는 단 하나의 책임만 가져야 한다
- O : 개방 - 폐쇄의 원칙
- OCP : Open Closed Priciple
- 기존의 코드를 변경하지 않으면서 기능을 추가할 수 있도록 설계해야한다
- L : 리스코프 치환 원칙
- LSP : Liskov Substitution Principle
- 자식 클래스는 자신의 부모 클래스에서 가능한 행위를 수행할 수 있어야 한다
- I : 인터페이스 분리 원칙
- ISP : Interface Segregarion Priciple
- 클래스는 자신과 관련 없는 인터페이스는 구현하지 않는다.
- D : 의존 역전 원칙
- DIP : Dependency Iversion Priciple
- 상위 모듈은 하위 모듈에 종속되면 안되고, 둘 다 추상화에 의존해야 한다.
- 예 : 상위 모듈인 자동차를 만드는데 하위 모듈인 스노우 타이어를 참조하지 말고, 상위 모듈인 타이어를 추상화 해서 사용한다 .
OOP를 사용하는 이유
- 코드의 재사용성 증가
- 유지보수의 용이성
- 간결한 코드
- 높은 확장성
- 강한 응집력과 약한 결합력
- 보안성 향상
- 소프트웨어 생산성 향상
접근제어의 종류
접근제어 : 클래스, 인터페이스, 멤버 변수, 메서드의 접근 범위를 제어하는 것
- public : 모든곳에서 접근 가능
- protected : 같은 패키지 내의 클래스와 상속받은 클래스에서 접근 가능
- default : 같은 패키지 내에서만 접근 가능
- private : 클래스 내부에서만 접근 가능

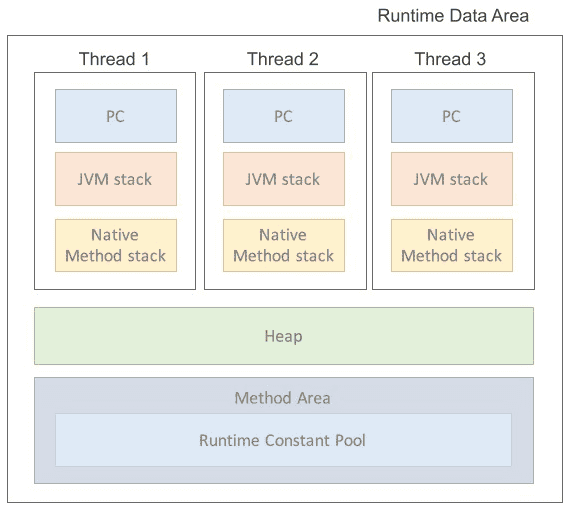
JVM 메모리 영역
- Method Area
- 클래스가 로딩될 때 할당
- 패키지, 클래스, 인터페이스, 생성자, 메소드, 필드, static 변수등을 저장
- 모든 스레드가 공유
- Heap Area
- 런타임 시에 동적으로 할당
- new 키워드로 생성된 객체와 배열이 저장되는 영역
- Heap 영역에 생성된 객체와 배열은 Stack 영역의 변수에서 참조
- Garbage Collector가 참조하지 않는 메모리를 제거
- Stack Area
- 스레드마다 존재, 스레드가 시작될 대 할당
- 지역변수, 파라미터, 리턴값, 연산에 사용되는 값 등이 생성되는 영역
- 메소드를 호출할 때마다 개별적으로 스택이 생성되며 종료시 해제된다
- 선입후출이 구조를 가진다
- 기본 타입 변수는 Stack 영역에 직접 값을 가진다
- 참조 타입 변수는 Method 영역이나 Heap 영역의 참조 주소를 가진다
Static과 non-Static 차이
- Static
- 클래스당 하나의 멤버가 생성되며, 클래스 멤버라고 부른다
- 클래스 로딩시에 자동으로 멤버가 생성
- Method 메모리 영역에 저장
- 동일 클래스의 모든 객체들에 공유
- 전역 변수와 함수를 만들 때 활용
- non-Static
- 객체마다 멤버가 생성되며, 인스턴스 멤버라고 부른다
- 객체 생성 시에 멤버가 생성
- Heap 메모리 영역에 저장
- 객체 내에서만 멤버가 활용
추상 클래스와 인터페이스의 차이
-
추상 클래스는 추상 메서드가 하나 이상 포함되는 클래스로 상속을 통해서 사용
추상 클래스에는 일반 변수와 메서드도 정의가 가능
추상 클래스는 일부 구현된 설계도로 상속 받아서 확장하게된다 -
인터페이스는 추상 메서드로 구성되고 다중 상속이 가능
인터페이스는 기본 설계도로 구현은 모두 따로 해야한다
List, Map, Set의 차이
- List
- 순서와 중복이 허용
- 배열의 크기가 가변적
- 데이터가 커지면 속도저하
- 인덱스로 원소를 접근
- Map
- Key, Value 한쌍으로 저장, 순서가 없다
- Key는 중복될 수 없다
- Value는 중복 허용
- 별도 인덱스가 없다
- 검색속도가 빠르다
- Set
- 순서가 없고, 중복을 허용하지 않는다
- 별도 인덱스가 없다
- 검색속도가 빠르다
프로세스와 스레드의 차이
먼저 프로그램이란 어떤 작업을 하기 위해서 실행할 수 있는 파일을 의미
프로그램이 실행되면 메모리에 올라가며, 프로세스와 스레드에서 작업이 이루어진다
- 순서 : 프로그램 → 프로세스 → 스레드
- 프로세스 (Process)
- 컴퓨터에서 실행되고 있는 프로그램
- 메모리에서 실행되고있는 프로그램의 인스턴스
- 운영 체제로 부터 시스템 자원을 할당 받는 단위
- 스레드 (Thread)
- 프로세스가 할당 받은 자원을 이용하는 실행 단위
- 하나의 프로세스에 여러 스레드가 존재, Heap을 통해 공유 가능
- 자바 스레드(Java Thread)
- 자바 스레드는 JVM에 의해 실해되는 단위 코드 블록
- 멀티 스레드 구현을 통해 성능 향상
- 멀티 프로세스
- 하나의 프로그램을 여러 개의 프로세스로 구성, 각각의 프로세스가 개별 작업을 빠르게 처리
- 문제 발생 시에 다른 프로세스에 영향을 주지 않음
- 프로세스 간에 통신 비용이 크고 복잡
- 멀티 스레스
- 하나의 프로그램을 여러 개의 스레드로 구성하여, 각각의 스레드가 개별 작업을 빠르게 처리
- 자원의 효율성 증대
- 처리 비용 감소 및 응답 시간 단축
- 자원을 공유하면서 동기화 문제 발생 가능
직렬화(Serialization), 역직렬화(Deserialization)
- 직렬화
- 자바 시스템 내부에서 사용되는 객체 또는 데이터를 외부의 시스템에도 사용할수 있도록, 바이트 형태로 데이터를 변환하는 기술
- 객체 데이터를 파일로 저장하거나 Stream 데이터로 전송
- 역직렬화
- 직렬화된 데이터를 다시 자바 객체 형태로 만드는 과정
- 저장된 파일을 읽거나 전송된 Stream 데이터를 원래 형태로 복원
병렬처리
멀티 코어 환경에서 하나의 작업을 각각의 코어가 분할해서 처리하는 방법
작업을 분산해서 처리하기 때문에 빠른 처리가 가능
- 동시성
- 싱글 코어를 이용한 멀티 작업은 멀티 스레드가 번갈아 가며 실행되고 병령처리는 아니다
- 싱글 코어에서는 병렬 처리 보다는 순차 처리가 유리
- 병렬성
- 멀티코어를 이용해서 동시에 멀티 작업을 처리
- 데이터 병렬성 : 전체 데이터를 서브 데이터로 나눠서 병렬처리하는 방법
- 작업 병렬성 : 서로 다른 작업을 병렬로 처리하는 방법
String, StringBuffer, StringBuilder
- String
- 메모리 영역에 생성되며 변경이 불가능
- 문자열이 변경되면, 기존 객체는 남아있고 새로운 인스턴스 생성
- 잦은 문자열 변경은 성능저하를 불러와, 변경이 적은경우에 사용
- 멀티 스레드 환경에서 동기화가 가능
- StringBuffer / StringBuilder
- String과 달리 가변적으로 사용
- 문자열 변경이 발생하면, 기존의 버퍼 크기를 늘린다
- 잦은 문자열 변경에 유효
- StringBuffer는 멀티 스레드환경에서 동기화를 지원, StringBuilder에 비해 성능이 떨어진다
- 결론
- String : 문자열 변경이 적은경우
- StringBuffer : 문자열 변경이 잦은 멀티 스레드 환경
- StringBuilder : 문자열 변경이 잦은 싱글 스레드환경
제너릭
클래스나 메서드 등의 타입을 지정하지 않고, 외부에서 유동적으로 지정
제너릭을 활용하면 효율적이고 안정적인 프로그래밍 가능
- 용도에 맞는 객체 생성이 가능
- 타입을 별도로 변환할 필요가 없다
- 컬렉션 클래스에서 제너릭을 사용해서, 컴파일 과정에서 미리 타입 체크가 가능
박싱, 언박싱
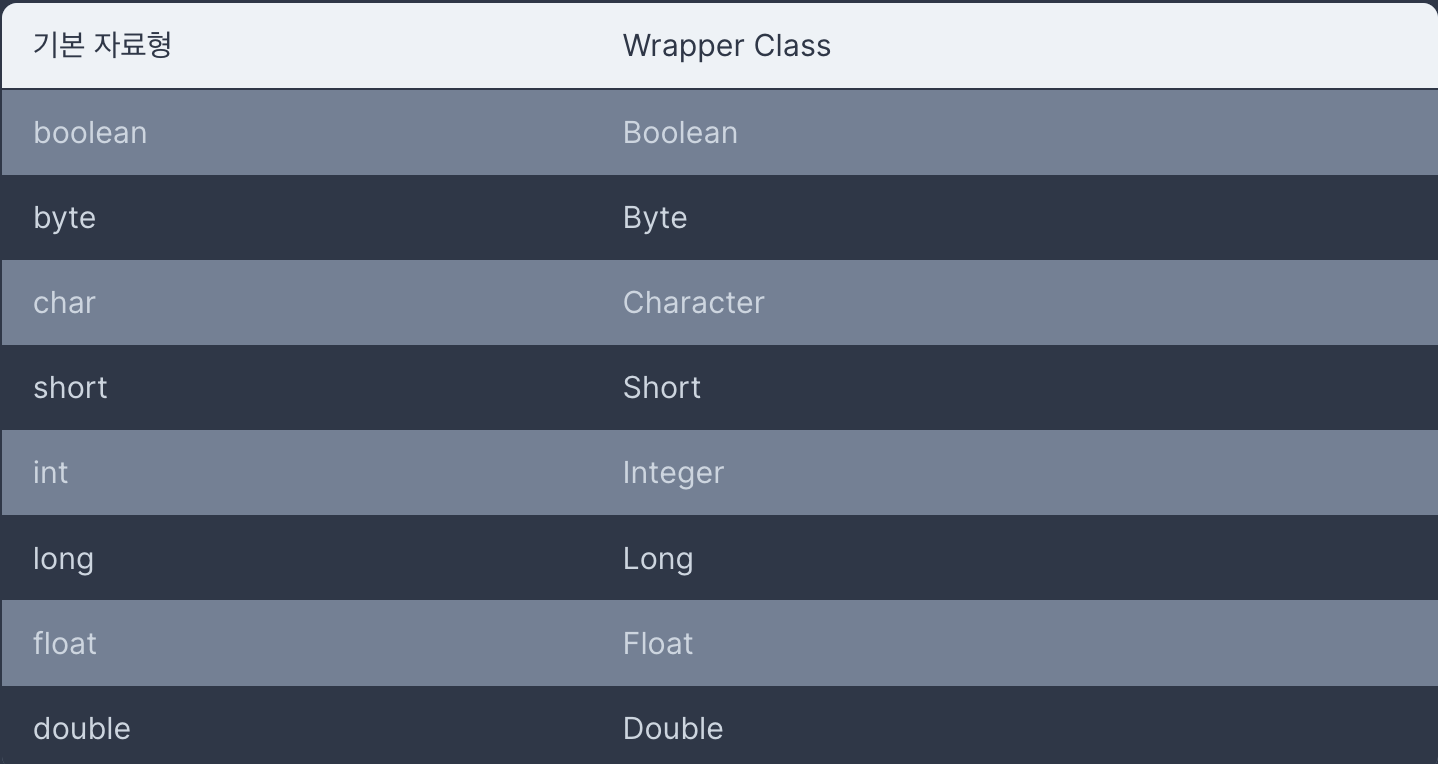
자바의 기본 자료형 (Primiticve Type)에는 Wrapper Class가 있습니다
기본 자료형을 객체로 사용하기 위해, 포장하는 클래스가 Wrapper Class
그리고 컬렉션, 제너릭 등에서는 Wrapper Class만 사용가능
기본 자료형을 Wrapper Class로 변경하면 박싱, 반대면 언박싱
대용량 트래픽 처리방법
대규모 트래픽 처리의 핵심은 분산입니다
거기에 어플리케이션과 디비, 서버 등의 성능향상도 필수
- 서버분산
- 로드 벨런싱 : 스위치를 통해 여러대의 서버로 분산 (온프레미스 환경)
- 오토 스케일링 : 어플리케이션을 모니터링해서 서버의 용량을 자동으로 저정(클라우드 환경)
- 서버 성능
- scale up : 서버의 cpu나 메모리등 성능을 향상
- scale out : 서버의 대수를 증가
- 어플리케이션 개선
- 뷰나 데이터 등 서비스 기능에 따른 캐싱 설정
- 코드 품질 개선 및 비효율 프로세스 제거
- 디비 개선
- 레플리카 : Master DB에는 쓰기, Slave DB에는 읽기 기능을 부여해서 분산
- 디비 정규화, 쿼리 튜닝, 설정 개선
- 로그나 통계 빅데이터는 NoSQL 활용
- 파일서버
- Static : Image, JS, CSS 등 정적 파일 별도 서버 구성 (CDN)
- Upload : 별도 업로드 서버 구성(CDN)
- WEB or WAS 개선
- 서버 설정이나 기능 확장을 통해 성능 개선
- 마이크로 서비스
- RestAPI 시스템을 구축해서 서비스별로 트래픽을 분산
- 분산 캐시 서버 활용
- Memcached, Redis 등으로 요청 분산
- Akamai CDN을 적용해서 캐싱 웹페이지 제공
- 부하 테스트 정책
- 코드나 뭐리 작성후에 일정 수준의 부하 테스트를 통과하지 못하면 배포 금지
- TPS(Transaction Per Second)나 응답 시간 등을 기준
가비지 컬렉터 (Garbage Collector)
자바의 핵심 기능 중에 하나가 바로 JVM을 통한 메모리 관리입니다.
가비지 컬렉션 기능을 통해서 사용하지 않는 메모리 공간을 자동으로 해제합니다
보통의 프로젝트에서는 기본 가비지 컬렉터를 사용합니다.
하지만 기능이나 성능 이슈가 있는 프로젝트는 가비지 컬렉터를 선택할 수 있습니다.
예전의 가비지 컬렉션의 동작 단계는 아래와 같습니다.
이후에 나온 가비지 컬렉터는 다른 방식으로 수행이 됩니다.
- Mark
- 메모리 영역을 스캔하며 사용하지 않는 객체를 식별
- Sweep
- 사용하지 않는 객체의 메모리를 수거하고, 사용하는 객체만 남겨둔 상테
- Compacrion
- 사용하는 객체들은 모으는 단계, 메모리 단편화와 오버헤드 방지를 위한 작업
- Stop the World
- 일시 정지 상태에서 가비지 컬렉션 작업을 진행
가비지 컬렉터의 종류
- Serial GC
- 하나의 스레드가 메모리 관리를 순차적으로 수행
- 메모리와 CPU 리소스가 부족할때 사용
- Mark-Sweep-Compaction 단계를 수행
- 처리 속도가 느리고 Stop-the-world 상태가 길어서 상용 서비스에 비추천
- Parallel GC
- 멀티코어를 지원하고 여러 스레드에서 수행
- Mark-Sweep-Compaction 단계를 여러 스레드에서 빠르게 수행
- Stop the World 시간 단축
- Parallel Old GC
- Parallel GC 에서 Old 영역의 방식을 차별화
- Old 영역은 Mark-Sweep-Compaction 단계를 수행
- CMS GC (Concurrent Mark Sweep)
- 어플리케이션의 응답 속도가 중요한 경우 사용
- 중간중간 Stop the world를 해제해서 정지 시간 최소화
- 다른 GC 방식 보다 메모리와 CPU 사용량 증가
- Initial Mark -> Concurrent Mark -> Remark -> Concurrent Sweep
- Compaction은 메모리 단편화가 심한 경우에만 수행
- G1 GC (Garbage First)
- Java 7부터 사용 가능
- 대용량 메모리와 멀티코어 환경에서 효율적으로 동작
- CMS GC를 대체하기 위한 용도
- 메모리를 동일 사이즈의 여러 리전으로 구분해서 사용
