저는 아래와 같이 프로젝트에서 역할을 수행하였습니다.
- 데이터베이스 인프라 구축
- 로그데이터 파이프라인
- Airflow
이것들 중에서 로그데이터 파이프라인 구축을 하는 과정을 설명드리겠습니다.
- Django를 통해서 settings.py에 logging을 통해서 로그를 파일 형식으로 저장합니다.
- 로그가 발생하고 로그파일에 갱신될때 log를 알맞은 json형식으로 키를 매핑합니다.
- 매핑된 json형식의 데이터를 3개의 클러스터로 구성된 카프카로 보내게 됩니다.
- 토픽에 저장된 메세지를 알맞은 컨슈머앱에 가게됩니다.
위의 과정중에서 1번에 대한 설명을 기록합니다.
제일먼저 수행한것은 로그를 어떤형식으로 보낼것인지의 고민이었습니다.
먼저 로그를 TCP형식으로 바로 Kafka에 보낼것인지, 아니면 파일형식으로 남기고 그것을 바라보고있는 Logstash가 Kafka로 보낼것이지 선택해야했습니다.
저의 선택은 로그를 파일형식으로 남겨 그것을 Logstash가 Kafka로 보내느것이었습니다.
그러한 이유는 정한 갯수가 넘어가게 된다면 로그파일을 삭제가 아닌 구글 스토리지로 적재를 하게하는것이 목표이기 때문입니다.
😀 Django에 로그 설정
settings.py에 logging을 통해 로그 파일 남기기
def doRollover(self):
if self.stream:
self.stream.close()
self.stream = None
# Call the parent class method to do the actual rollover
super().doRollover()
# Get the current log file
current_log_file = f"{self.baseFilename}.{self.backupCount}"
# Check if the current log file is too large
if os.path.getsize(current_log_file) >= self.maxFileSize:
# Upload the current log file to Google Storage Bucket
dest_blob_name = os.path.join('logs', os.path.basename(current_log_file))
self.upload_to_google_storage(current_log_file, dest_blob_name)
# Remove the current log file
os.remove(current_log_file)
# Create a new log file
self.new_log_file = f"{self.baseFilename}.{self.backupCount + 1}"
self.stream = open(self.new_log_file, 'a')
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'movie_verbose': { # render한 영화에 대한 로그
'format': '{levelname},{asctime},{user_id},{message}',
'style': '{',
'datefmt': '%Y-%m-%d %H:%M:%S',
},
},
'handlers': {
'user_action': {
'level': 'DEBUG',
'class': 'config.settings.GoogleStorageRotatingFileHandler',
'filename': '파일경로/파일이름.log',
'formatter': 'movie_verbose',
'maxBytes': 1024*1024*10,
'backupCount': 10,
'bucket_name': '스토리지 이름',
'credentials_file': '키파일 경로'
},
'other_action': {
'level': 'DEBUG',
'class': 'config.settings.GoogleStorageRotatingFileHandler',
'filename': '파일경로/파일이름.log',
'formatter': 'movie_verbose',
'maxBytes': 1024*1024*10,
'backupCount': None, #초과한 용량의 로그파일을 백업할 횟수
'bucket_name': '스토리지 이름',
'credentials_file': '키파일 경로'
},
},
'loggers': {
'moochu': {
'handlers': ['user_action'],
'level': 'DEBUG',
'propagate': False,
},
'board': {
'handlers': ['other_action'],
'level': 'DEBUG',
'propagate': False,
},
'mypage': {
'handlers': ['other_action'],
'level': 'DEBUG',
'propagate': False,
},
'review': {
'handlers': ['other_action'],
'level': 'DEBUG',
'propagate': False,
},
'search': {
'handlers': ['user_action'],
'level': 'DEBUG',
'propagate': False,
},
},
}
이러한 코드를 통해서 사용자의 행동로그를 user_action과 other_action으로 나누어 파일을 저장하였습니다.
그러면서 로그파일이 10개가 넘어가게 된다면 구글 스토리지로 로그파일이 적재되게 됩니다.
로그를 남겨야되는 기능의 views.py에 로그 심기
import logging
logger=logging.getLogger('search')
def get(self, request):
es = Elasticsearch(['IP:PORT'])
search_word = request.GET.get('search')
if request.user.is_authenticated:
user_id = request.user.id
else:
user_id = None
info_string='search'
logger.info(f'{search_word},{info_string}', extra={'user_id': user_id})
if not search_word:
return Response(status=status.HTTP_400_BAD_REQUEST, data={'message': 'search word param is missing'})
docs = es.search(
index='media3',
body={
"query": {
"multi_match": {
"query": search_word,
"fields": ["id","title"]
}
}
}
)
data_list = trans(docs['hits']['hits'])
logger=logging.getLogger('search') 를 통해서 settings.py에서 선언한 logger를 받아옵니다.
다음은 이렇게 views.py 안에 검색을 하는 기능의 함수안에 request가 들어오게 됩니다.
logger.info(f'{search_word},{info_string}', extra={'user_id': user_id})
그렇게 들어온 request를 통해서 위의 코드를 통해서 원하는 데이터를 조합하여 로그를 만듭니다.
이렇게 만들어진 로그는 아래와 같이 [시간],[유저아이디],[검색어 또는 영화아이디],[로그정보]로 파일에 남겨집니다.
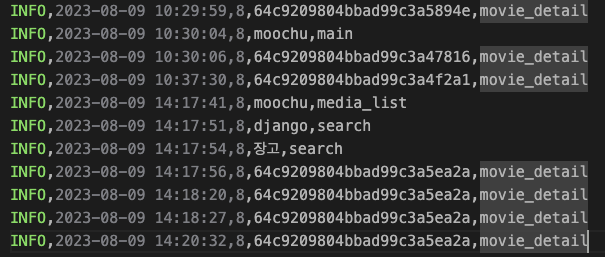
Django에서 전체적인 흐름
- setting.py에서 선언한 Logger를 생성합니다.
logging.getLogger('로거이름')을 통해서 생성합니다. - 로그를 기록합니다.
logger.info(f'{search_word},{info_string}', extra={'user_id': user_id})
