🪼 Milvus
: 벡터 검색에 특화된 오픈소스 벡터 데이터베이스
- 수십억 개의 벡터에 대해 빠르게 유사도 검색을 수행할 수 있도록 설계되어 있다.
구조
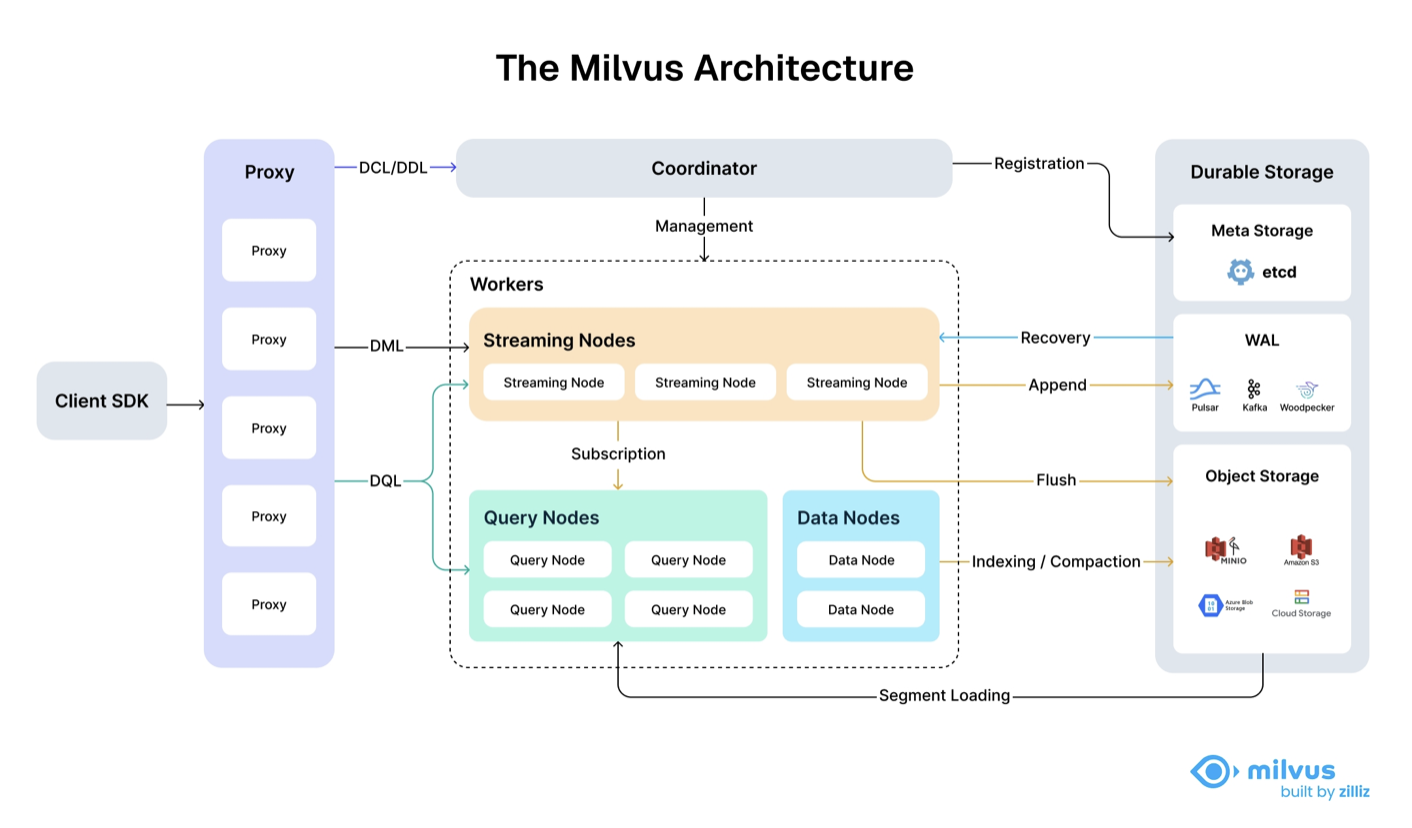
(출처: milvus 공식 문서)
레이어 1: 액세스 레이어
- 사용자가 벡터를 넣거나, 유사도 검색을 요청한다.
- Proxy가 사용자의 API 요청을 수신한다.(상태 비저장형)
- 요청에 이상이 없는지 검사한다.(유효성 검사)
- 중간 결과를 모아서 응답 결과를 정리하고 사용자에게 다시 전송한다.
레이어 2: 코디네이터
- 누가 무엇을 할지, 언제 어떤 데이터를 처리할지 일정과 역할을 관리.
- 데이터 생성, 삭제 요청 처리(DDL)
- 검색 요청이 어느 서버로 가야 빠를지 판단
- 시간이 중요한 작업들의 경우 타임스탬프를 붙인다.
- 항상 1개만 존재한다.
레이어 3: 작업자 노드
코디네이터의 지시를 실제로 따르는 실행자이다.
워커 노드에는 3가지 유형이 있다.
- 스트리밍 노드: 새로 들어온 데이터를 받아 저장 준비&검색 계획
- 쿼리 노드: 저장된 벡터 중 유사한 걸 빠르게 찾아냄
- 데이터 노드: 오래된 데이터 압축, 인덱스를 만들어 정리
레이어 4: 스토리지 (Storage)
데이터 지속성을 담당하는 시스템의 뼈대이다.
모든 데이터가 저장되는 창고이며, 3가지 저장소가 존재한다.
- 메타 스토리지(etcd): 벡터의 정보, 현재 상태, 어떤 데이터가 어디 있는지 정리
- 오브젝트 스토리지(S3 등): 벡터 파일, 인덱스 파일 저장
- WAL(Write-Ahead Log) 스토리지(Kafka 등): 쓰기 전 먼저 기록 ➡️ 중단 시에도 복구가 가능하도록 함.
💭 예시 동작 흐름
- 사용자가 “apple 비슷한 단어” 요청
- Proxy가 요청 받고 유효성 검사
- Coordinator가 누가 처리할지 판단
- Query Node가 벡터 인덱스 보고 비슷한 단어 찾기
- 결과를 모아서 Proxy가 사용자에게 응답
- 모든 저장은 S3 같은 저장소에 있음

개발 공뷰