| 구분 | 스택(Stack) | 큐(Queue) |
|---|---|---|
| 자료구조 | LIFO (Last In, First Out) | FIFO (First In, First Out) |
| 연산 | push(삽입), pop(삭제) | enqueue(삽입), dequeue(삭제) |
| 활용 사례 | 함수 호출, 괄호 짝 맞추기, 후위 표기법 계산 등 | 프린터 대기열, 버퍼 관리, 스케줄링 알고리즘 등 |
| 구현 방법 | 배열, 연결리스트 | 배열, 연결리스트 |
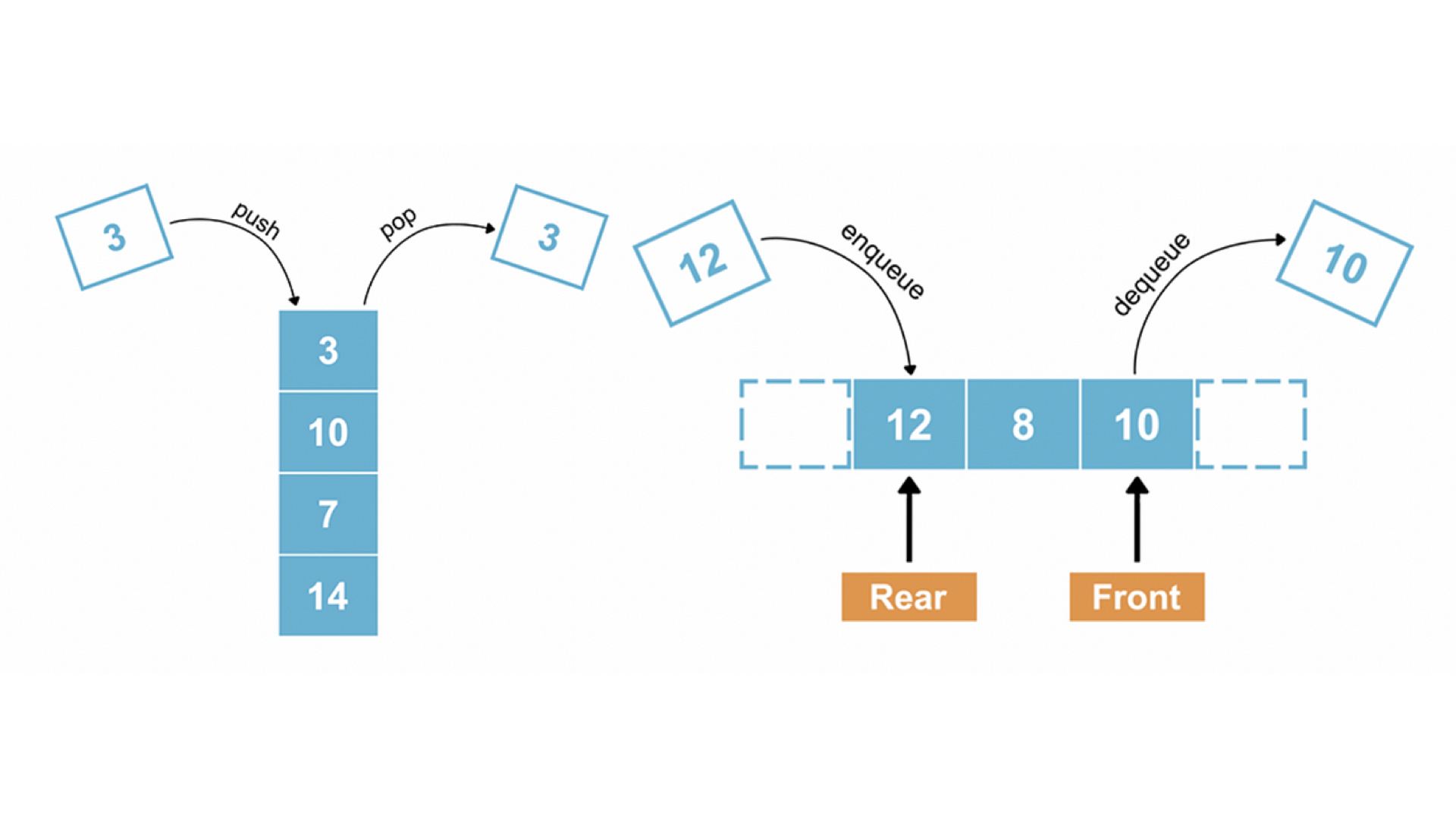
✅ 자료구조의 차이 : LIFO vs FIFO
스택은 LIFO (Last In, First Out) 구조를 가진 자료구조로, 가장 마지막에 삽입된 데이터가 가장 먼저 삭제되는 구조입니다. 반면, 큐는 FIFO (First In, First Out) 구조를 가지며, 가장 먼저 삽입된 데이터가 가장 먼저 삭제되는 구조입니다. 이러한 차이로 인해 스택과 큐는 서로 다른 상황에서 활용됩니다.
✅ 연산의 차이 : push & pop vs enqueue & dequeue
스택은 데이터를 삽입하는 push 연산과 데이터를 삭제하는 pop 연산을 제공합니다. 데이터는 항상 스택의 가장 상단에 추가되거나 제거됩니다. 반면, 큐는 데이터를 삽입하는 enqueue 연산과 데이터를 삭제하는 dequeue 연산을 제공합니다. 데이터는 큐의 뒤쪽에 추가되고, 앞쪽에서 제거됩니다.
📝 활용 사례
스택은 함수 호출, 괄호 짝 맞추기, 후위 표기법 계산 등의 상황에서 사용됩니다. 함수 호출에서는 스택을 사용하여 함수의 매개변수, 지역 변수, 반환 주소를 관리하며, 이를 통해 함수가 실행되는 동안의 상태를 유지합니다. 반면, 큐는 프린터 대기열, 버퍼 관리, 스케줄링 알고리즘 등의 상황에서 사용되며, 데이터가 순차적으로 처리되어야 하는 경우에 적합합니다.
🛠 구현 방법 : 배열 vs 연결리스트
스택과 큐는 배열 또는 연결리스트를 이용하여 구현할 수 있습니다. 배열을 이용한 경우, 데이터의 삽입 및 삭제 시 인덱스를 조절해야 하지만, 메모리 할당이 연속적이라는 장점이 있습니다. 반면, 연결리스트를 이용한 경우, 데이터의 삽입 및 삭제 시 포인터를 조절해야 하지만, 메모리 할당이 비연속적이라는 장점이 있습니다. 구현 방법에 따라 성능과 메모리 관리 측면에서 차이가 있을 수 있으므로, 상황에 맞는 방법을 선택하여 구현해야 합니다.
🔖 스택과 큐의 활용 예시
스택과 큐는 프로그래밍에서 다양한 문제를 해결하는 데 활용됩니다. 스택은 깊이 우선 탐색(DFS) 알고리즘, 역순 문자열 생성, 실행 취소 기능 등에서 사용됩니다. 큐는 너비 우선 탐색(BFS) 알고리즘, 작업 스케줄링, 캐시 구현 등에서 사용됩니다.
⚙️ 성능 및 메모리 관리
스택과 큐의 성능과 메모리 관리 측면에서의 차이는 구현 방식과 사용하는 연산에 따라 달라집니다. 배열을 사용한 스택과 큐는 메모리 할당이 연속적이지만, 연결리스트를 사용한 스택과 큐는 메모리 할당이 비연속적입니다. 이로 인해 배열을 사용한 경우와 연결리스트를 사용한 경우의 메모리 관리 및 할당 방식이 다르며, 이에 따른 성능 차이가 발생할 수 있습니다. 또한, 스택과 큐에서 사용하는 연산(push, pop, enqueue, dequeue)에 따라 성능 차이가 있을 수 있습니다.
스택과 큐는 서로 다른 자료구조와 연산 방식을 가지고 있어 다양한 상황에서 사용되며, 각각의 특성을 이해하고 적절한 구현 방식을 선택하여 사용하는 것이 중요합니다.
