
파이썬 패키지 설치하기
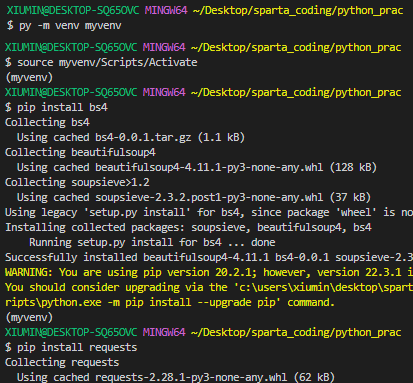
강사님은 저 빨간 블럭 쪽에 인터프리터 선택이 나오던데 나는 안나와 .. 그치만 그거 누르고 python 3.8.6 누르라고 하셨는데 나는 이미 3.8.6 으로 되어있는 것 같으니까 안해줘도 괜찮을 거 같다는 .. 생각.. 해봅니다 .. 잘 됐는지 확인하기 위해서 Run Python File in Terminal 눌러서 확인 한번 해주기. 그리고 작성한 것 처럼 python -m venv venv 쓰고 엔터키 ! (맥은 python3 이라고 쓰기)
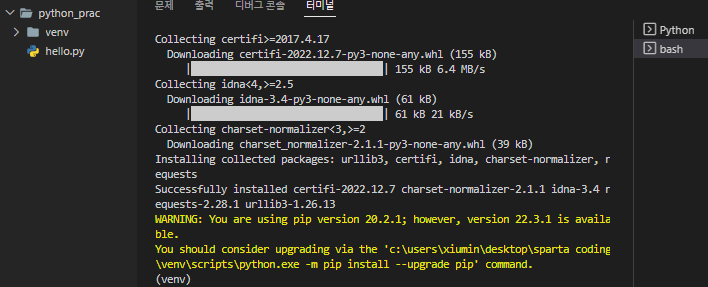
그럼 위 사진 왼쪽 상단처럼 venv 라는 폴더가 생성됨. 그리고 라이브러리를 깔아준 건데, 터미널 창에 pip install requests 이라고 쓰고 엔터키 누르면 위 사진처럼 쭉 나오면 requests 라이브러리 설치 완료 !
자바스크립트에서 fetch의 역할을 하는 것이 파이썬에서는 requests 라는 것 ! 그럼 이제 이 requests 를 사용해보자.
import requests
r = requests.get('http://spartacodingclub.shop/sparta_api/seoulair')
rjson = r.json()
rows = rjson['RealtimeCityAir']['row']
for a in rows:
lo_name = a['MSRSTE_NM']
lo_dust = a['IDEX_MVL']
print(lo_name, lo_dust)requests import 해주고, 2주차에서 했던 미세먼지 API 사용해서 터미널에 출력해보기 ! 뼈대는 거의 동일하다. 여기까지 코딩해주면
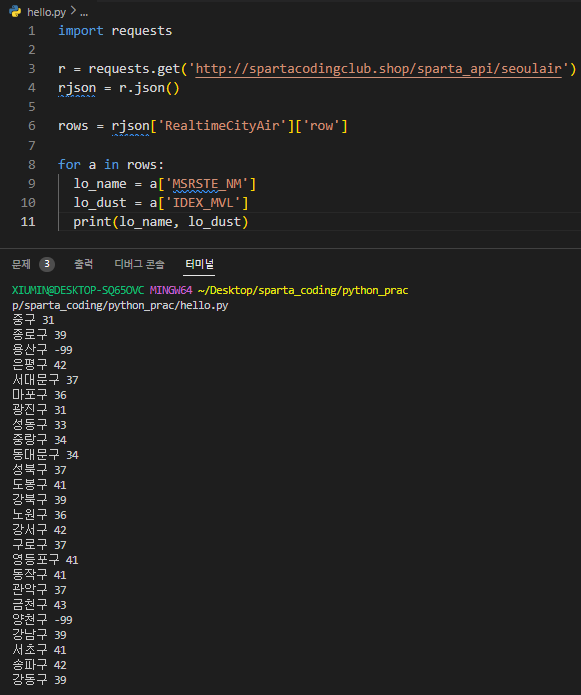
이렇게 출력된다.
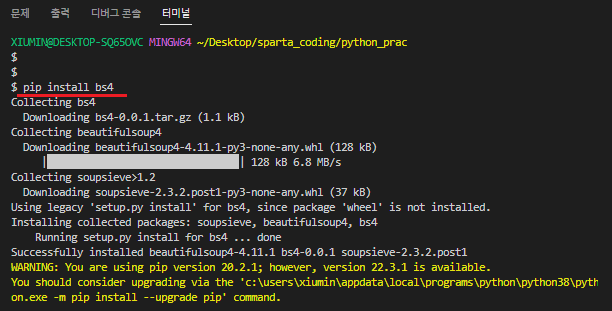
이제 크롤링을 이용해서 인터넷에 있는 데이터를 가지고와서 정리해보는 걸 해보자. 똑같이 터미널에 pip install bs4 입력하고 엔터 쳐서 bs4 라이브러리를 설치해준다. (bs4 는 beautifulsoup4의 약어)
크롤링 ?
웹에 접속해서 데이터를 솎아내서 가지고 오는 것. => 라이브러리가 2개 필요함 ! 첫번째는 웹에 접속하는 라이브러리, 두번째는 솎아내는 친구 (beautifulsoap)
스크랩핑 하기 위해서는 파이썬 패키지를 설치해야 한다고 하셨다. pip install bs4 를 터미널 창에 치면 된다고 했는데 나는 오류 발생 .. ㅠㅠ 분명히 설치되어 있다고 뜨는데 자꾸 from bs4 import BeautifulSoup 이 줄에서 bs4에 밑줄이 쳐져서 modulenotfounderror: no module named 'bs4'이런 식이길래 미친 구글링 시작 .. (3시간 지나서도 수정 못함.. 흑흑) 그래서 그냥 venv 가상환경 폴더 지워버리고 myvenv로 다시 만들고 import 해줬는데 된다. . 내 세시간 돌려줘 ^^ ... 아아아아아아아ㅏㅇㄱ악 나 이거 하느라 오늘 아무것도 못했다구.... 진짜 .. 속상해 ..
아무튼 requests랑 bs4 둘 다 import 해줬습니다 ..
네이버 영화 크롤링 기본 포맷
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작
print(soup)
a = soup.select_one('')print(soup)했더니 터미널에 html 형식으로 쭉 나타났다. 이제 뭘 가져와야 될 지를 코드로 작성해야겠지. a = soup.select_one('') 에서 ' ' 안에 뭔갈 작성하면 a를 솎아낼 수 있는 것.
우리는 네이버 영화 페이지에서 솎아낼 거니까, 네이버 영화 사이트에 들어가서 원하는 영화에 오른쪽 마우스 - Instpect 누르면 아래 사진처럼 나타난다. 나는 클래식을 선택했다. ㅎㅎ 그럼 나타난 클래식 div에서 copy-copy selector를 해준다. 이걸 아까 ' ' 안에 붙여넣기 !
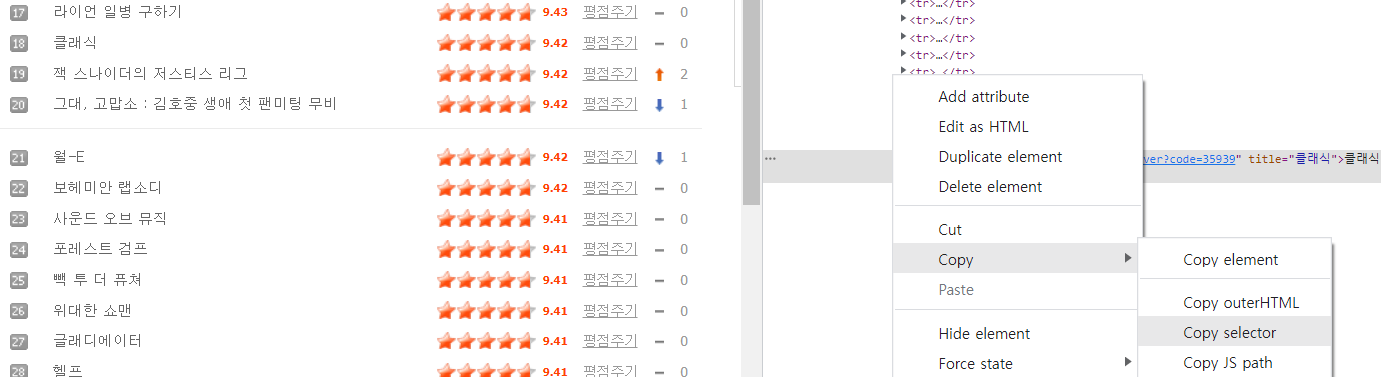 작은 따옴표 안에 아까 복사했던 selector을 넣고 print하면 주석에 단 내용으로 출력이 된다.
작은 따옴표 안에 아까 복사했던 selector을 넣고 print하면 주석에 단 내용으로 출력이 된다.
a = soup.select_one('#old_content > table > tbody > tr:nth-child(20) > td.title > div > a')
print(a) # <a href="/movie/bi/mi/basic.naver?code=35939" title="클래식">클래식</a>
print(a.text) # 클래식
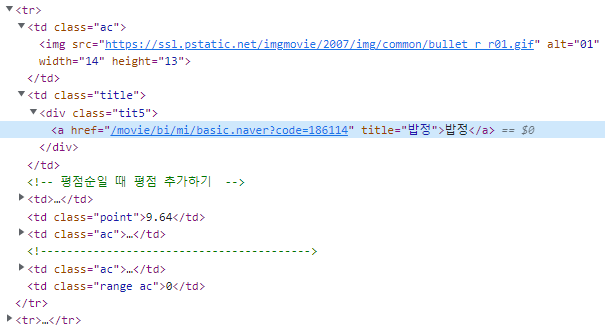
print(a['href']) # /movie/bi/mi/basic.naver?code=35939그럼 이제 영화 랭킹에 있는 모든 영화 제목들을 가지고 오는 걸 해보자. F12 눌러서 개발자도구창 열어서 접혀있는 tr들이 쭉 있는데 하나를 풀어서 보면 아래 사진과 동일. tr태그 아래 td태그 내에 div태그에 영화 제목이 있는 걸 볼 수 있다.
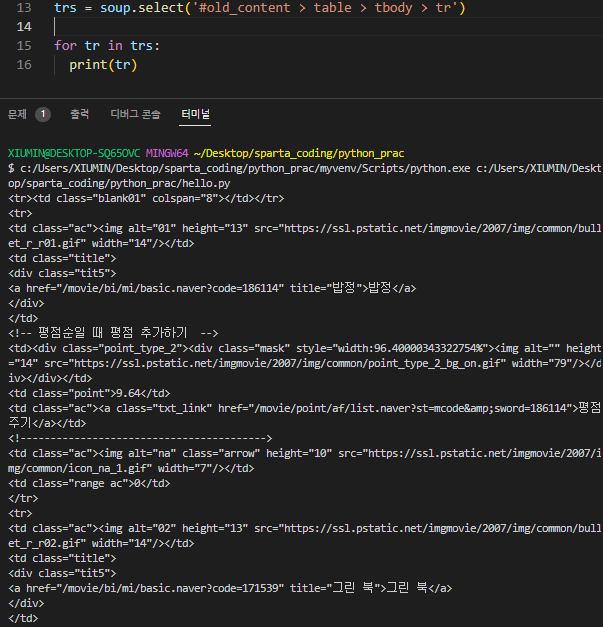
그럼 이 tr들을 어떻게 가져올 수 있을까? 일단 첫번째 tr를 copy-copy selector 하면 #old_content > table > tbody > tr:nth-child(2)가 나오고 두번째 tr도 동일하게 복사하면 #old_content > table > tbody > tr:nth-child(3) 이렇게 복사가 된다. 그럼 우리는 여기서 #old_content > table > tbody > tr 이만큼이 동일하게 반복된다는 걸 알 수 있다. 그럼 코드에서 trs 를 soup에서 '#old_content > table > tbody > tr'이만큼을 선택하겠다 라고 작성하면 tr들이 리스트로 쌓인다. 그럼 이 리스트들을 반복문으로 돌리는 코드까지 작성하면 ↓
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
print(tr)작성된 파일을 터미널에서 실행하면 아래 사진처럼 tr들이 하나씩 나오는 것을 볼 수 있다.
그리고 아까 복사했던 것처럼 a태그를 한번 더 copy-copy selector 한다.
복사된 내용 : #old_content > table > tbody > tr:nth-child(2) > td.title > div > a
아래 코드에서 trs 부분에 이미 #old_content > table > tbody > tr 이까지를 넣어줬으니까 나머지 td.title > div > a 를 반복문을 돌리면 되겠지.
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.title > div > a')
print(title)title이라는 변수는 tr에서 하나씩 선택해오는데 그 선택해오는 내용이 td.title > div > a 라는 코드 작성하고 print하면
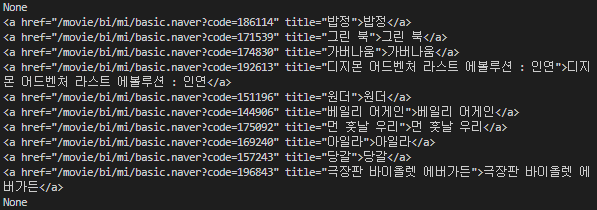 이런 식으로 a 태그가 하나씩 쭉 나온다. 그런데 저기 None은 뭐냐 하니,
이런 식으로 a 태그가 하나씩 쭉 나온다. 그런데 저기 None은 뭐냐 하니,

이 구분선도 tr에 넣어놔서 none이라고 출력이 되는 거였다. 그럼 여기서 none이 아닐 때를 조건으로 거는 조건문을 작성해야 되겠지. 그래서 아래와 같이 코드를 작성했다. a가 None이 아닐 때, a의 text만 가져온다는 조건문 작성하고 반복문으로 돌려줬다. 그럼 결과는
for tr in trs:
a = tr.select_one('td.title > div > a')
if a is not None:
print(a.text)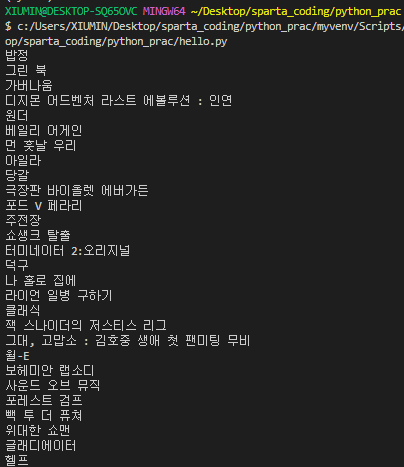
이런 식으로 text(영화 제목)만 쭉 출력되는 걸 볼 수 있다. 그럼 이제 순위, 제목, 별점 이렇게 세가지가 나오는 코드를 작성해보자.
for tr in trs:
movie = tr.select_one('td.title > div > a')
if movie is not None:
title = movie.text
rank = tr.select_one('td > img')['alt']
rate = tr.select_one('td.point').text
print(rank, title, rate)변수 명이 조금 더 의미있으면 좋을 것 같아서 a 대신 movie로 바꿔줬다. 순위 부분을 copy selector 해보니 #old_content > table > tbody > tr:nth-child(2) > td:nth-child(1) > img 이렇게 복사가 됐다. tr까지는 이미 위에 변수에서 작성했으니 td > img만 넣어주면 되는데 < img src="https:// ssl.pstatic.net/imgmovie/2007/img/common/bullet_r_r01.gif" alt="01" width="14" height="13"> 코드를 봤을 때 우리는 순위가 작성된 alt="01" 부분만 가져와야 하니까 ['alt']를 붙여준다. 그럼 순위는 작성 완료. rate도 copy selector 하면 #old_content > table > tbody > tr:nth-child(2) > td.point 이렇게 나오는데, 이미 tr까지는 위 반복문에서 작성되어 있으니까 td.point만 넣으면 된다. element를 보면 < td class="point">9.64< /td> 이렇게 작성되어 있는데 우리는 이 td 안에 text만 가져오고 싶으니까 print(rate.text) 해도 상관은 없지만 가독성을 위해 변수 값에 붙여준다. 그리고 이 3개를 print 해주면 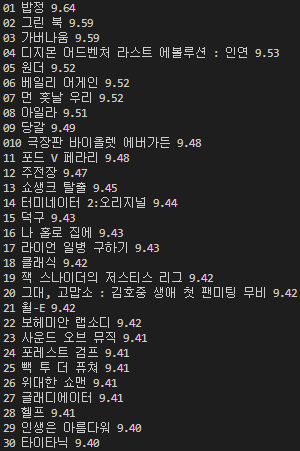 원하던 대로 순위, 제목, 별점이 나오는 것을 확인할 수 있다.
원하던 대로 순위, 제목, 별점이 나오는 것을 확인할 수 있다.
오늘은 여기까지 ! 그리고 내일은 DB에 넣는 방법을 배울 예정 !
