오늘의 학습 리스트
-
Custom Data Generator를 Keras로 만드는 부분이 나온다.
-
보면 파일 형태로 있는 데이터들을
glob라이브러리를 통해서 전부 filename들을 긁어오고 -
(image, label) 형태로
for loop및zip을 통해 묶어준다. -
중요한 건 그 데이터를
Sequence로서 뿌려주게끔 만들어주는 건데, generatorclass를 만들 때 그것이 가능하게끔tf.keras.utils.Sequence를 상속받는다. -
그리고 그 클래스 내에서 꼭 필요한 메소드들(
__getitem__,__len__,on_epoch_end)를 구현해준다. -
여기서
__getitem__은 배치 사이즈에 맞춰서 데이터를 끊어서 배치화해주는 함수이고, -
__len__은 epoch에서 쓰일 배치 갯수를 나타내주는 함수인 듯하고 -
on_epoch_end는 epoch가 끝날 때 실행해야 하는 것들을 넣어주는 함수인 듯하다. -
class KittiGenerator(tf.keras.utils.Sequence): ''' KittiGenerator는 tf.keras.utils.Sequence를 상속받습니다. 우리가 KittiDataset을 원하는 방식으로 preprocess하기 위해서 Sequnce를 커스텀해 사용합니다. ''' def __init__(self, dir_path, batch_size=16, img_size=(224, 224, 3), output_size=(224, 224), is_train=True, augmentation=None): ''' dir_path: dataset의 directory path입니다. batch_size: batch_size입니다. img_size: preprocess에 사용할 입력이미지의 크기입니다. output_size: ground_truth를 만들어주기 위한 크기입니다. is_train: 이 Generator가 학습용인지 테스트용인지 구분합니다. augmentation: 적용하길 원하는 augmentation 함수를 인자로 받습니다. ''' self.dir_path = dir_path self.batch_size = batch_size self.img_size = img_size self.output_size = output_size self.is_train = is_train self.augmentation = augmentation # load_dataset()을 통해서 kitti dataset의 directory path에서 라벨과 이미지를 확인합니다. self.data = self.load_dataset() def load_dataset(self): # kitti dataset에서 필요한 정보(이미지 경로 및 라벨)를 directory에서 확인하고 로드하는 함수입니다. # 이때 is_train에 따라 test set을 분리해서 load하도록 해야합니다. input_images = glob(os.path.join(self.dir_path, "image_2", "*.png")) label_images = glob(os.path.join(self.dir_path, "semantic", "*.png")) input_images.sort() label_images.sort() assert len(input_images) == len(label_images) data = [ _ for _ in zip(input_images, label_images)] if self.is_train: return data[:-30] return data[-30:] def __len__(self): # Generator의 length로서 전체 dataset을 batch_size로 나누고 소숫점 첫째자리에서 올림한 값을 반환합니다. return math.ceil(len(self.data) / self.batch_size) def __getitem__(self, index): # 입력과 출력을 만듭니다. # 입력은 resize및 augmentation이 적용된 input image이고 # 출력은 semantic label입니다. batch_data = self.data[ index*self.batch_size: (index + 1)*self.batch_size ] inputs = np.zeros([self.batch_size, *self.img_size]) outputs = np.zeros([self.batch_size, *self.output_size]) for i, data in enumerate(batch_data): input_img_path, output_path = data _input = skimage.io.imread(input_img_path) _output = skimage.io.imread(output_path) _output = (_output==7).astype(np.uint8)*1 # road 인 것만 마스킹하는 것 같다. data = { "image": _input, "mask": _output, } augmented = self.augmentation(**data) inputs[i] = augmented["image"]/255 outputs[i] = augmented["mask"] # mask는 현재 0, 1의 값으로만 있는 것으로 파악됨 return inputs, outputs def on_epoch_end(self): # 한 epoch가 끝나면 실행되는 함수입니다. 학습중인 경우에 순서를 random shuffle하도록 적용한 것을 볼 수 있습니다. self.indexes = np.arange(len(self.data)) if self.is_train == True : np.random.shuffle(self.indexes) return self.indexes
-
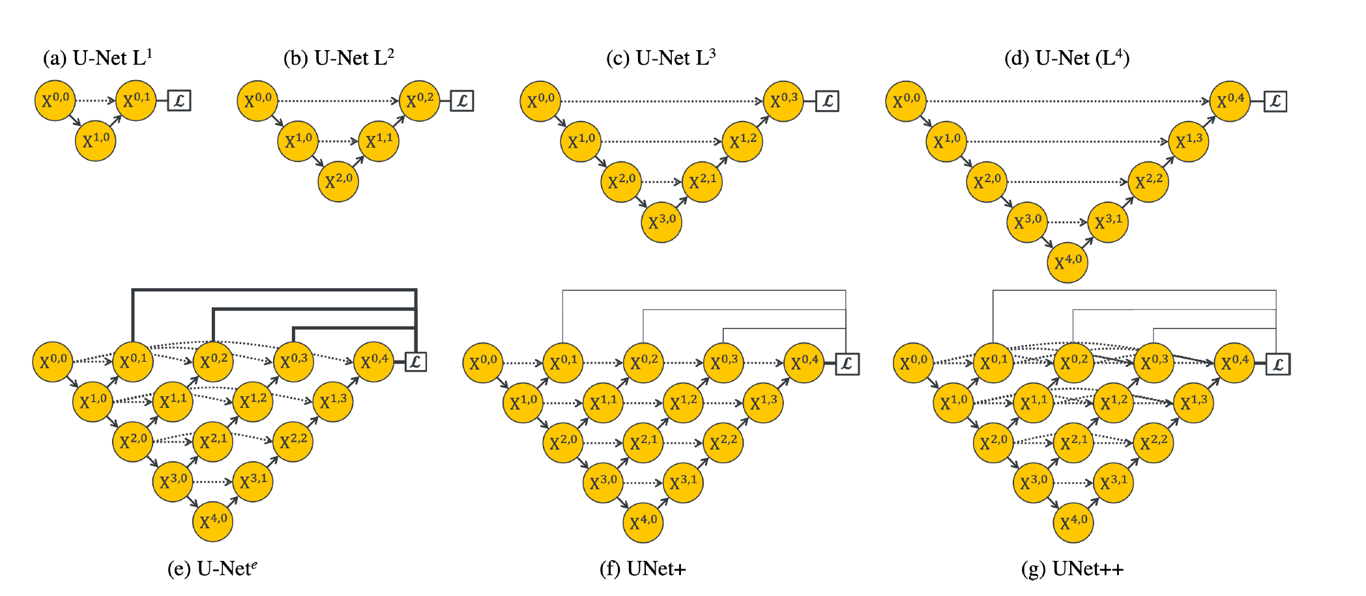
논문 구현
U-Net++
질문
- 어떻게 해서(수학적 증명이 아니라 그냥 직관적인 느낌을 실험해봐서 얻어걸린 것 같지만...) low-level feature map이랑 high-level feature map이랑 합치면 더 segmentation이 잘 되는 걸까...?

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다