오늘의 학습 리스트
-
tf-idf
- NLP 전처리 과정을 살피다가 다시 한 번 지나치게 된 개념이다.
- https://wikidocs.net/31698
- 이해한 바에 따르면, 어떤 단어가 정말 많이 등장해도 실제로 많은 문서(혹은 샘플)에 등장하는지를 따져서 그 단어의 중요도를 측정하고 가중치로서 나중에 곱해주는 것 같다.)
- 이게 필요한 이유는 위와 반대되게 엄청 많이 등장한 단어여도 등장하는 샘플 수가 얼마 안 될 경우 일반화 입장에서는 중요한 단어로 인식하지 않는 게 좋을 수도 있기 때문이다.
-
class안에 내가 따로 만든 함수를 또 다른class안의 함수가 쓰고 싶을 땐- https://stackoverflow.com/questions/5615648/how-can-i-call-a-function-within-a-class
- 결론적으로 그냥
함수명을 쓰면 안되고,self.함수명으로 해야지~~~ not defined같은 에러가 안 뜬다.
-
Multinomial Naive Bayes
- https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.MultinomialNB.html?highlight=multinomial%20naive%20bayes#sklearn.naive_bayes.MultinomialNB
- 이름이 Multinomial 이길래 클래스가 multi일 때 쓰는 건가 싶었는데, 그건 아니고 다항, 즉 feature 개수가 multi 일 때 쓰는 분류기인 듯 싶다.(풀잎 팀원 분들 감사감사 ㅎㅎ)
- 보면 Naive Bayes에 베르누이 NB 분류기도 있는데, 아마 feature의 분포에 따라 골라서 쓰는 것 같다.
-
스팸 분류기에서 Naive Bayes 분류기가 많이 쓰이는 이유는
- = 해당 클래스 일 때 해당 단어가 나오는 확률을 구하고
- 나오는 단어들의 그것들을 다 곱해서
그 단어들이 있을 때의 해당 클래스 확률은 이래~를 구해놓는 건데 - 사실 우리가 원하는 건 이다.
- 근데 이걸 Bayes Thero
-
Independent and Identically Distributed
- https://electronicsdo.tistory.com/entry/independent-identically-distribution-%EB%8F%85%EB%A6%BD-%EB%8F%99%EC%9D%BC-%EB%B6%84%ED%8F%AC
- 동전 던지기 생각하면 될 듯(그런데 추출되고 다시 넣는 게 아니라 빠지는 것으로)
-
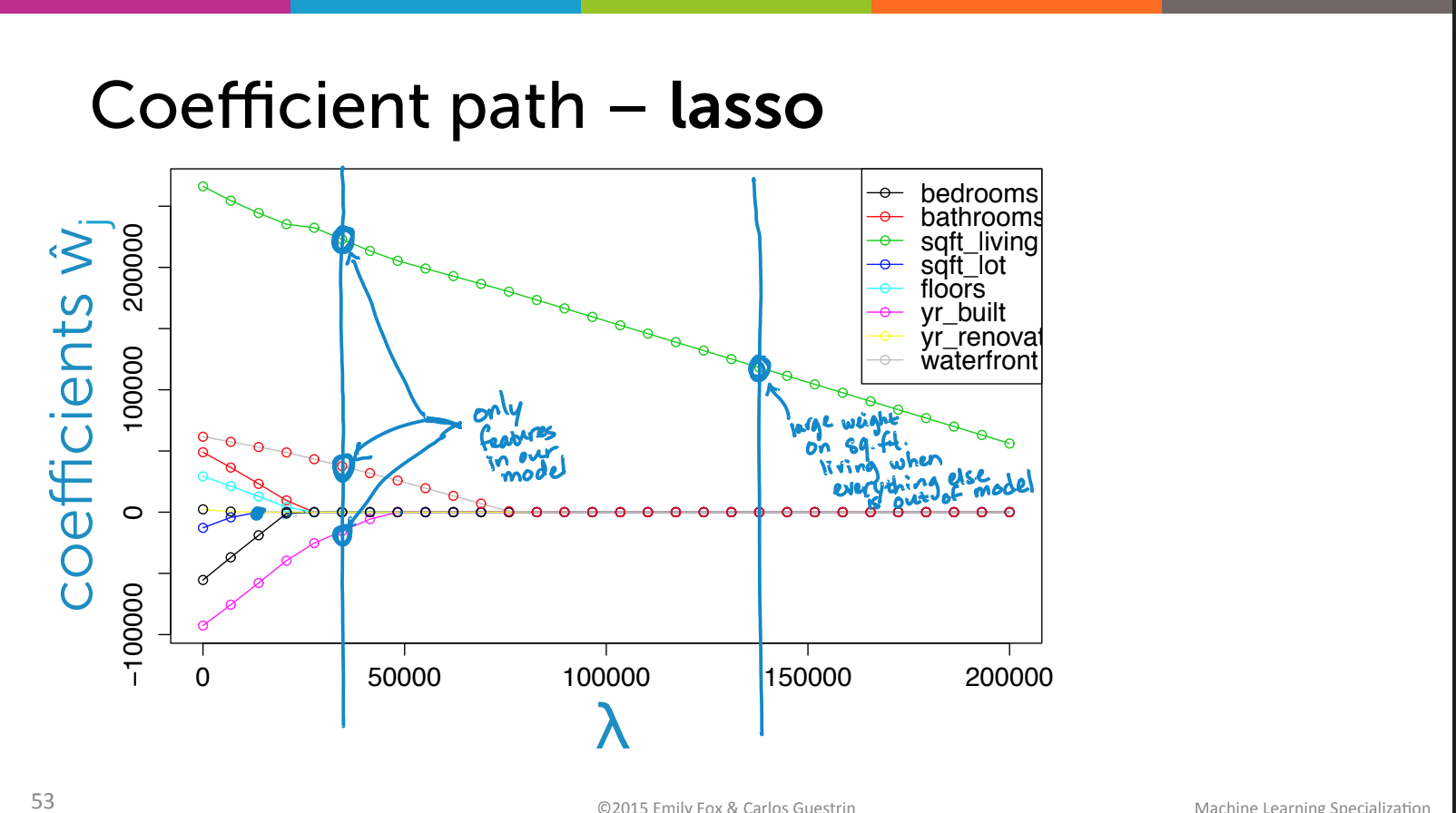
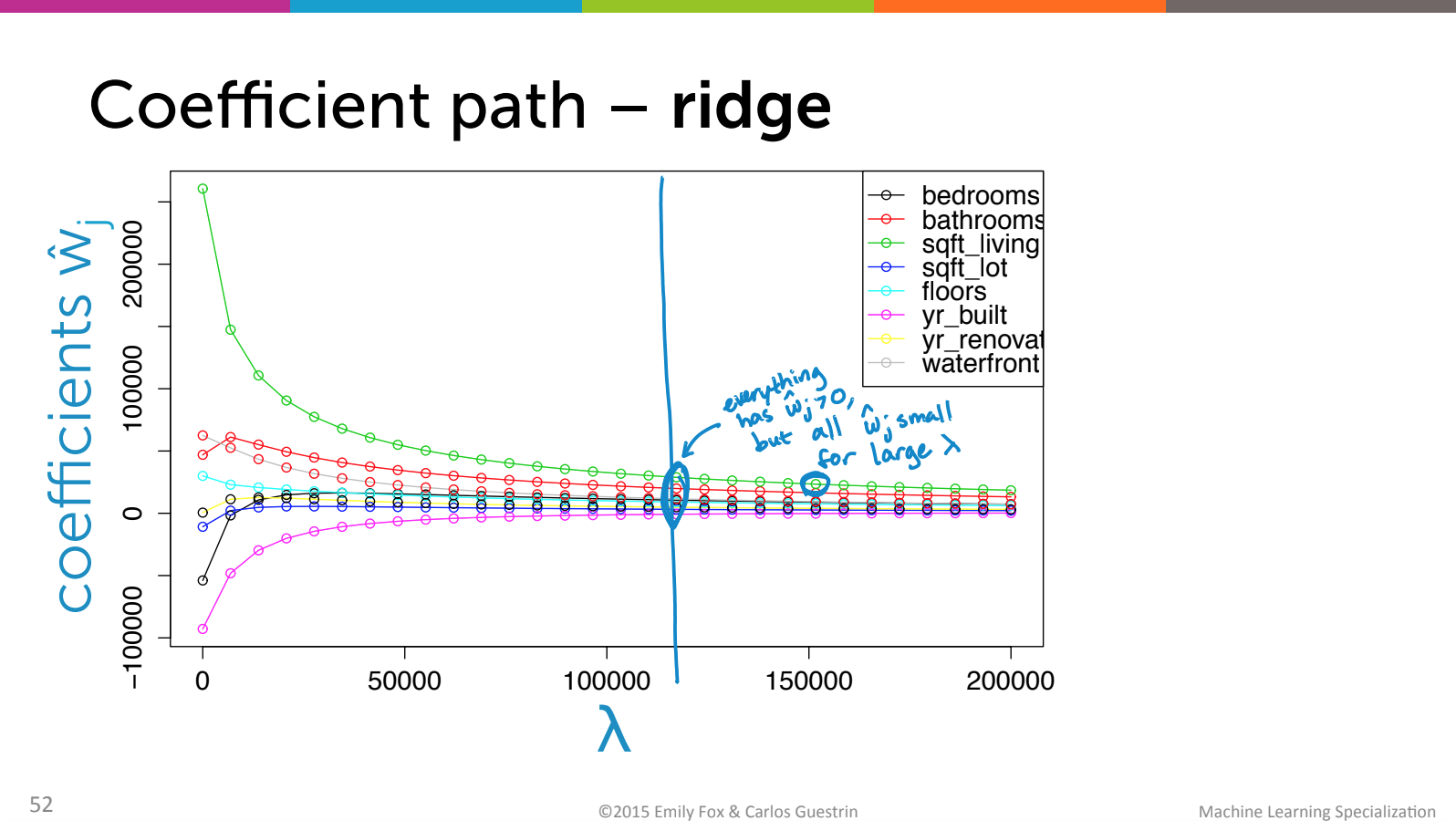
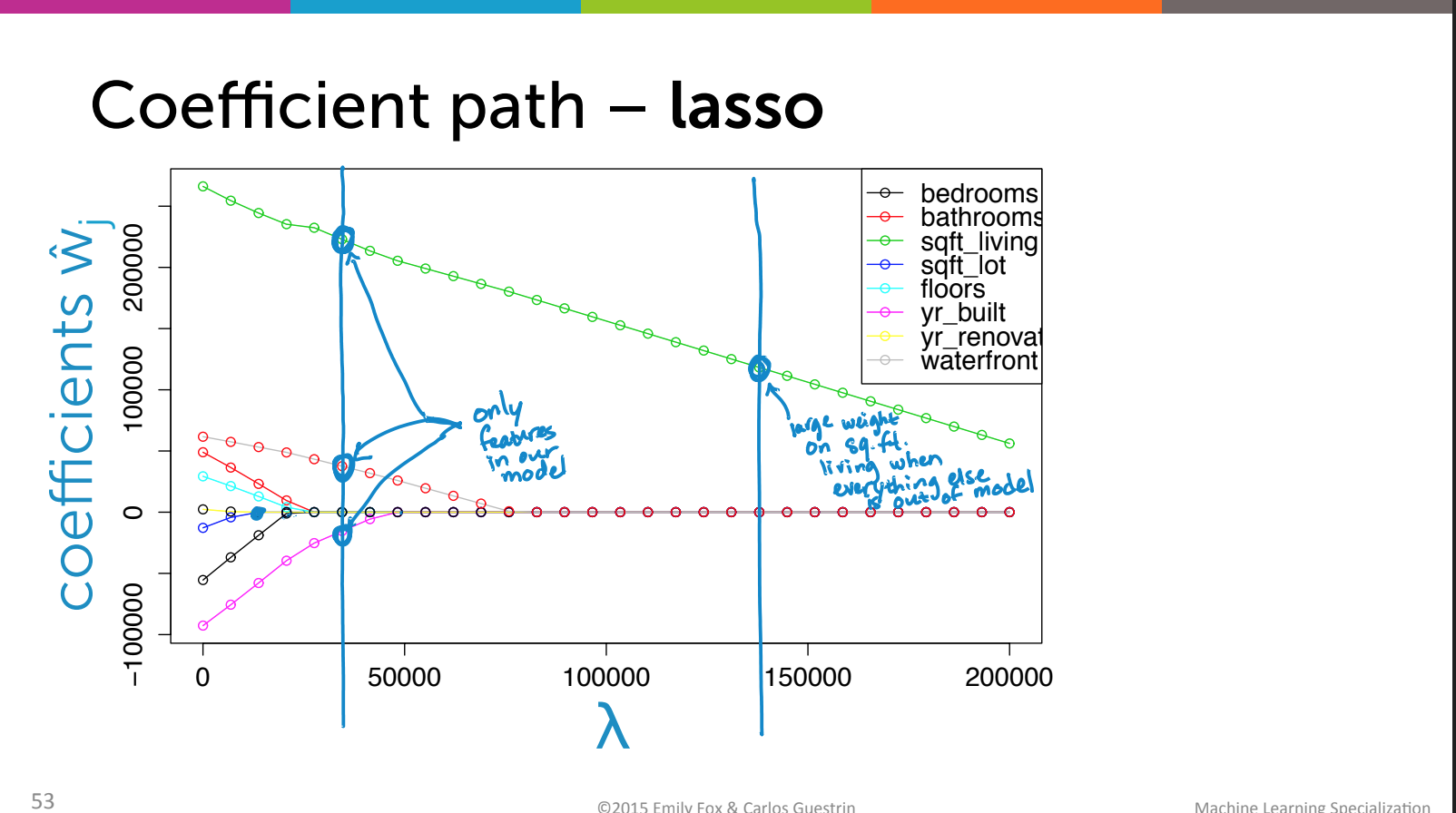
Lasso의 수식에 대한 이해
-
선형성에 대한 이해
- https://brunch.co.kr/@gimmesilver/18
- 파라미터를 선형 결합의 구조로 나타낼 수 있는 경우가 선형 모델
- 선형 모델은 선형 결합의 형태이기에 변수에 대한 가중치, 즉 영향을 해석하기 쉽다.
- 반면 선형 결합 형태는 유연성이 부족하기 때문에(만들 수 있는 방법에 한계가 있다) 복잡한 데이터를 표현하기엔 역부족
- 그래서 비선형 모델이 복잡한 데이터를 갖고 예측을 하기에는 좋음
-
모델마다의 알고리즘을 알아야 하겠다.
- 예를 들어 어떤 분류 문제에서 너무 낡은 알고리즘 같아서 Naive Bayes 분류기를 제외했다가 마지막에 그냥 추가를 했는데, 성능과 fit 시간이 제일 좋았단다.(일구님 감사합니당)
Hands On Machine Learning(Chapter 4 연습문제)
- 4번 문제
- 학습률이 점진적으로 작아지는 게 아니라면 SGD 같은 기법들은 결코 global minima에 도달하지 못할 것이다.
- 동연님의 질문 : 파라미터가 같은 모델이 진짜로 만들어질 수 있을까?
- 대다수의 대답 : 없을 것 같다.

'어떻게든 자야겠어'라는 저 아이를 닮고 싶습니다